AAAI22参会见闻与论文杂谈

By 元戎感知组
今天主要和大家分享的是今年2月底参加的AAAI22的一些见闻以及一些感兴趣的论文杂谈。再次安利一下我们组最新的一篇被AAAI22接收的点云全景分割的oral paper Sparse Cross-scale Attention Network for Efficient LiDAR Panoptic Segmentation,没看过的小伙伴可以点击链接到之前的文章里查看哦。

AAAI22会议见闻
作为人工智能的顶会之一,2022年的AAAI又创造了该会议的历史投稿新高,一共收到了9251 篇投稿,其中 9020 篇投稿进入了评审环节,但是最后的接受率则是历届最低,只有15.0%,1349篇论文被接受,真是越来越“卷”了。
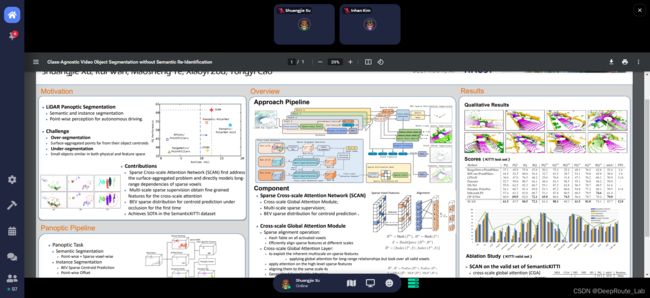
由于疫情的原因,这次大会以线上会议的形式在虚拟空间内举行,这也是最近一些AI会议的常用操作了。图里就是这次AAAI的主会场了,入口外是一个虚拟公园,进入后左边的红色建筑、右边的蓝色建筑都是这次的会场的入口电梯。每个会场中除了有赞助商的位置外,还各有6组海报进行轮流展示,以及2个会议室。

AAAI22的虚拟公园
根据官方的日程表选择你想要看的海报后,进入相应的建筑,来到对应的海报展位,靠近后就会弹出选项,确认后就可以进入到全屏的poster页面,类似一个小型的会议,你可以和海报的主持人进行沟通提问,还是挺方便的。下图是小编在日常“接客”。如果是Oral的话就是在海报两侧的会议室,会有提前录好的视频进行播放,如果作者在还可以进行在线提问。
海报答疑
会议的情况就基本介绍到这里啦,下面会介绍下在会上四处“晃悠”看到的个人比较感兴趣的工作,主要集中在自动驾驶3D感知相关的工作,大家有兴趣可以一起来看下~
AAAI22 3D目标检测论文盘点
AAAI22接收了不少和3D相关的论文,这里小编根据个人兴趣着重介绍下面3篇,主要是和3D detection相关,能够提升现有网络的性能或是解决一些棘手的感知问题。
AFDetV2: Rethinking the Necessity of the Second Stage for Object Detection from Point Clouds 【1】
AFDetV2 是Real-Time 3D Detection of the Waymo Open Dataset Challenge 2021的第一名。主要的改进点是从second stage得到的启发。
我们为什么需要second stage, 一般来说有两种理由:
- 点云的特征可以恢复因voxelization, striding operations或者lack of receptive field而损失的位置信息;
- 物体检测框的回归和物体的分类是两个独立的Head,因此分类置信度可能不能对齐回归的精度
作者通过实验,验证了只用一阶段的voxel-wise特征也可以得到足够精确的物体框回归,因此二阶段的主要贡献来源于分类score的提升,使得分类和回归的精度对齐匹配。基于这个观察,作者提出了一个性能可以媲美二阶段网络的一阶段3D检测器,主要提出了:
1. 把之前的卷积替换为self calibrated convolution block
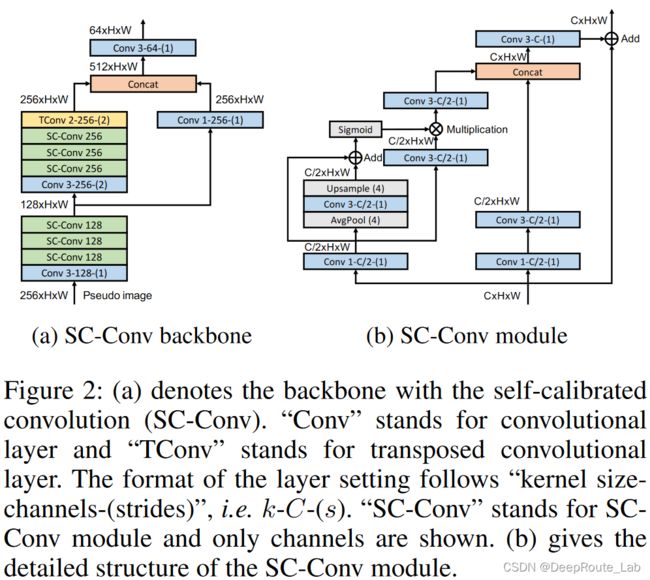
2. 增加一个IoU alignment head,并且和原始的分类score进行简单的融合
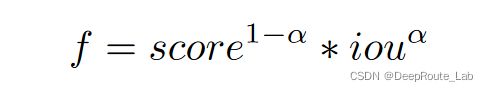
3. Keypoint auxiliary supervision:add another heatmap that predicts 4 corners and the center of every object in BEV during training

Behind the Curtain: Learning Occluded Shapes for 3D Object Detection 【2】
由于外部挡物(external occlusion)和自遮挡(self occlussion),点云在不同物体可以采样得到完全不同的点云形态,如下图所示:

这会带来两个问题:
- 遮挡使得物体的点云表现形式不同,有可能导致误检;
- 会导致shape missing,导致遮挡状态下预测的bbox的质量很低。
如果遮挡问题不存在会是怎样的呢?作者使用shape matching将相似车型的点云补到被遮挡的车上,发现在KITTI上性能可以逼近到100%,因此影响detection的一个主要原因是遮挡问题。
为了解决这个问题,作者提出了BtcDet来学习物体形状先验,并估计点云中部分遮挡的完整物体形状。BtcDet首先识别出受遮挡和信号缺失影响的区域。在这些区域中,模型预测了probability of occupancy,表明一个区域是否包含物体形状。结合这个概率图,BtcDet可以生成高质量的3D proposals。最后,将probability of occupancy集成到一个proposal refinement模块中,生成最终的物体检测框。

遮挡问题是线上一个比较难解决的点,尤其是当远处大车被遮挡后会导致物体框的大小和位置跳变。作者提供了一个解决这个问题的方案,还是挺有启发的。
Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds 【3】
这篇文章关注了感知领域一个发展的方向,即使用图像和lidar的fusion特征、使用时序特征,并且同时进行Detection和Tracking的任务。
本文提出的3D DetecTrack通过对相机和激光雷达融合得到的空间特征进行加权时间聚合来构造时空特征。然后,检测器使用到上一个时间步骤为止所维护的tracklet中的信息重新配置初始检测结果。Tracker基于Detector产生的时空特征,利用图神经网络(GNN)将被检测的目标与之前跟踪的目标关联起来。

最近CVPR的论文也有很多类似的工作,即Joint 3D Object Detection and Tracking,这也是一个新的值得探索的方向
总结
参加会议最重要的是可以和众多研究者一起交流研究方向,并且可以从论文的发表来捕捉研究方向演变的蛛丝马迹。除了上面的一些论文,还有其他很多值得一读的论文,比如SASA【4】,做的是point based 3D detection,这个方向最近的CVPR也有很多工作在做。再比如上面说的Occlusion和Joint 3D Object Detection and Tracking等方向,都是为了很好的结合产业方向的研究领域,期待有新的work出现。文末附上了文中出现的文章以及相关的一些AAAI22的文章,大家感兴趣可以去看下~
【1】Hu, Yihan; Ding, Zhuangzhuang; Ge, Runzhou; Shao, Wenxin; Huang, Li; Li, Kun; Liu, Qiang. "AFDetV2: Rethinking the Necessity of the Second Stage for Object Detection from Point Clouds." AAAI. 2022.
【2】Xu, Qiangeng; Zhong, Yiqi; Neumann, Ulrich. "Behind the Curtain: Learning Occluded Shapes for 3D Object Detection." AAAI. 2022.
【3】Koh, Junho; Kim, Jaekyum; Yoo, Jinhyuk; Kim, Yecheol; Kum, Dongsuk; Choi, Jun Won. "Joint 3D Object Detection and Tracking Using Spatio-Temporal Representation of Camera Image and LiDAR Point Clouds." AAAI. 2022.
【4】Chen, Chen; Chen, Zhe; Zhang, Jing; Tao, Dacheng. "SASA: Semantics-Augmented Set Abstraction for Point-based 3D Object Detection." AAAI. 2022.
【5】Liu, Xianpeng; Xue, Nan; Wu, Tianfu. "Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection." AAAI. 2022.
【6】He, Qingdong; Wang, Zhengning; Zeng, Hao; Zeng, Yi; Liu, Yijun. "SVGA-Net: Sparse Voxel-Graph Attention Network for 3D Object Detection from Point Clouds." AAAI. 2022.
【7】Song, Nan; Jiang, Tianyuan; Yao, Jian. "JPV-Net: Joint Point-Voxel Representations for Accurate 3D Object Detection." AAAI. 2022.
【8】Zhao, Na; Lee, Gim Hee. "Static-Dynamic Co-Teaching for Class-Incremental 3D Object Detection." AAAI. 2022.