吴恩达深度学习课程学习笔记10
Seq2seq
你可以把机器翻译想成是建立一个条件语言模型。下图中第一个模型是前两周所建立的模型,这个模型可以让你能够估计句子的可能性,这就是语言模型所做的事情,你可以用它来生成一个新的句子。而机器翻译模型就是下图中的第二个模型那样的,绿色部分表示encoder网络,紫色表示decoder网络,而decoder网络和上方的语言模型几乎一摸一样,机器翻译模型其实和语言模型非常相似,不同在于语言模型,总是以零向量开始,而encoder网络会计算出一系列向量来表示这个输入的句子,有了这个输入的句子,decoder网络就可以以这个句子开始,而不是以零向量开始。所以把它叫作条件语言模型。相比于语言模型输出任意句子的概率,翻译模型会输出句子的英文翻译,这取决于输入的法语句子。

图2-1 语言模型和翻译模型对比图
所以当你使用这个模型来进行机器翻译时,你并不是从得到的分布中进行随机采样,而是你要找到一个英文句子y使得条件概率最大化。

所以在开发机器翻译系统时,你需要做的一件事就是,想出一个算法,用来找出合适的y值,使得该项最大化。而解决这种问题最通用的算法就是束搜索(Beam Search)。至于为什么不用贪心搜索,贪心搜索它是一种来自计算机科学的算法,生成第一个词的分布以后,它将会根据你的条件语言模型,挑选出最有可能的第一个词进入你的机器翻译模型中,在挑选第一个词之后,你将会继续挑选出最有可能的第二个词,然后继续挑选出最有可能的第三个词,这种算法就叫做贪心搜索。但是你真正需要的是一次性挑选出整个单词序列,来使得整体的概率最大化,所以这种贪心算法其实并不管用。
在英语中各种词汇的组合数量还有很多,不可能去计算出每一种组合的可能性,所以这时最常用的办法就是用一个近似的搜索算法。这个近似的搜索算法做的就是尽力挑选出句子y使得条件概率最大化,尽管它不能保证找到的y值一定可以使概率最大化,但这已经足够了。
Beam search
集束搜索算法首先做的就是挑选出要输出的英语翻译中的第一个单词,贪婪算法只会考虑最有可能的那一个单词,然后继续,而集束搜索则会考虑多个选择。集束算法会有一个参数B,叫作集束宽,这个例子中把这个集束宽设为3,这样就意味着集束搜索不会只考虑一个可能结果,而是一次会考虑3个,首先输出最有可能的三个选项,然后集束搜索算法会把结果存到计算机内存里以便后面尝试用这三个词。
集束算法接下来会针对每个第一个单词考虑第二个单词是什么,由于集束宽为3,假设词汇表里有10000个单词,那么最终我们会有3*10000个可能的结果,你要做的就是评估这30000个选择,按照第一个词和第二个词的概率然后选出前3个。如此类推,最终这个过程的输出,一次增加一个单词,集束搜索最终会找到一个句子直至句尾符号的出现。
当B=1时,集束算法就相当于贪婪算法了。
改进的定向搜索算法
长度归一化就是对束搜索算法稍作调整的一种方式,帮助你得到更好的结果。下图所示是我们之前见到的乘积概率,如果计算这些都小于1的概率,很多小于1的数乘起来,会得到很小很小的数字,会造成数值下溢,导致电脑的浮点表示不能精确地储存。
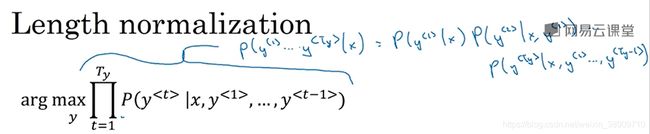
图2-2 条件概率运算图
因此在实践中我们不会最大化这个乘积,而是取log值,那么乘积就会变成log求和,最大化这个log求和的概率值,这样我们会得到一个数值上更稳定的算法,不容易出现四舍五入的误差

图2-3 优化后的目标函数
对于目标函数我们还可以做一些改变使得机器翻译的表现更好,参照原来的目标函数,如果一个句子很长,那么这个句子的概率会很低,所以这个目标函数有一个缺点就是可能不自然地倾向于简短的翻译结果,它更偏向短的输出。所以对这个算法的另一个改变也可以使它表现得更好,也就是我们不再最大化这个目标函数了,我们可以通过除以翻译结果的单词数量把它归一化,如下所示。这样很明显地减少了对输出长的结果的惩罚。

图2-4 归一化后的条件概率对数求和
在实践中有一个探索性的方法,相比于直接除Ty,有时会用一个更柔和的方法,就是在Ty上加上指数α ,α 可以约等于0.7

图2-5 探索性的条件概率对数求和公式
对于如何选择束宽B:B越大,你考虑的选择越多,你找到的句子可能越好,但是B越大,你的算法的计算代价越大,因为你要把很多可能选择保存起来。在实际产品中,经常可以看到把束宽设到10。在科研中,人们想压榨出全部性能这样有个最好的结果用来发论文,也经常看到大家用束宽为1000或者3000的,这也是取决于特定的应用和特定的领域。
定向搜索的误差分析
单纯获取更多的训练数据可能并不能得到预期的表现结果,相同地,单纯增大束宽,也可能得不到你想要的结果。
举个例子,如下图所示,第一行是人工翻译的结果y*![]() ,第二行是翻译模型给出的翻译结果y
,第二行是翻译模型给出的翻译结果y![]() ,你要做的就是计算出p(y*|x)
,你要做的就是计算出p(y*|x)![]() 和p(y|x)
和p(y|x)![]() 。若py*x>p(y|x)
。若py*x>p(y|x)![]() ,因此你能够得出束搜索算法实际上不能够给你一个能使pyx
,因此你能够得出束搜索算法实际上不能够给你一个能使pyx![]() 最大化的y值。可以得出结论是束搜索算法出错了。如果py*x
最大化的y值。可以得出结论是束搜索算法出错了。如果py*x![]() ,这种情况下是RNN模型出了问题,值得在RNN模型上花更多的时间。
,这种情况下是RNN模型出了问题,值得在RNN模型上花更多的时间。
像这样,在验证集上如下图所示做误差分析,计算出束搜索算法和RNN出错的比例,通过这个比例你就能知道谁是产生更多错误的原因。并且只有当你发现是束搜索算法造成大部分错误时,才值得花费努力,增大集束宽度。相反地,如果你发现RNN出错的比例更高,那么你可以进行更深层次的分析,来决定是需要增加正则化还是获取更多的训练数据亦或是尝试一个不同的网络结构。

图2-6 定向搜索误差分析示例图
注意力模型
主要结构如下图所示,编码器部分主要是基于Bi-RNN,每一时间步的输出![]() 。在译码器部分,每一个时间步的输入
。在译码器部分,每一个时间步的输入![]() 。其中
。其中![]() 是译码器时间步t对于编码器各时间步'
是译码器时间步t对于编码器各时间步'![]() 的输出的权重。
的输出的权重。![]() 一般是用译码器前一个时间步的隐藏层状态
一般是用译码器前一个时间步的隐藏层状态![]() 和编码器各时间步的输出
和编码器各时间步的输出![]() 作为输入,训练一个神经网络得出。
作为输入,训练一个神经网络得出。
这个算法的一个缺点就是它的算法复杂度是![]() ,若你有Tx个输入,Ty个输出,那么注意力参数的总数就会是Tx × Ty,所以这个算法有着三次方的消耗。但是在机器翻译的应用上,输入和输出的句子一般不会太长,可能三次方的消耗是可以接受的,但也有很多研究工作尝试去减少这样的消耗。
,若你有Tx个输入,Ty个输出,那么注意力参数的总数就会是Tx × Ty,所以这个算法有着三次方的消耗。但是在机器翻译的应用上,输入和输出的句子一般不会太长,可能三次方的消耗是可以接受的,但也有很多研究工作尝试去减少这样的消耗。
图2-7 注意力模型
语音辨识
音频数据的常见预处理步骤就是运行这个原始的音频片段,然后生成一个声谱图。在语音识别中,通常输入的时间步数量要比输出的时间步的数量多出很多。举个例子,比如你有一段10秒的音频,并且特征是100赫兹的,即每秒有100个样本,于是这10秒的音频片段就会有1000个输入,就是简单地用100赫兹乘上10秒,所以有1000个输入。
CTC(Connectionist Temporal Classification)损失函数的一个基本规则是将空白符之间的重叠的字符折叠起来。这样一来你的神经网络就可以有1000个输出了,因为很多这种重复的字符和很多插入在其中的空白符到了最后都会短上很多。通过允许神经网络有重复的字符和插入的空白符,使得它能强制输出1000个字符,甚至你可以输出1000个y值来表示这段19个字符长的输出。

图2-8 CTC损失函数示例图
触发字检测
现在有一个这样的RNN结构,我们要做的就是把一个音频片段计算出它的声谱图特征,得到特征向量x1, x2, x3,…,然后把它放到RNN中,最后要做的就是定义目标标签y。假如音频中的某一点说了一个触发字,那么就可以把该触发字之前的标签都设为0,然后把这个点的目标标签设为1。这样的标记对于RNN来说能取得不错的效果,不过该算法有一个明显的缺点就是它构建了一个很不平衡的训练集,0的数量比1多太多了。解决方法就是比起只在一个时间步上去输出1,其实可以在输出变回0之前多次输出1或说在固定的一段时间内输出多个1。这样的话就稍微提高了1和0的比例。

图2-9 触发字检测的标记设置示例图