Project joee 算法开发日志(一)
目录
- 一. 下载并安装TensorRT
-
- 1.1 下载安装TensorRT
- 1.2 验证TensorRT安装是否成功
- 二. 安装并测试Windows预测库
-
- 2.1 安装cuda11.0_cudnn8.0_avx_mkl-trt7.2.1.6 预测库
- 2.2 测试精度损失
- 2.3 推理速度测试
- 三. 总结
开发机器配置:
CPU: AMD5800 8core 16Thread
GPU: NVIDIA GTX1080Ti 11GB
内存: 48GB
系统:Win10 专业版
一. 下载并安装TensorRT
首先需要安装加速包CUDA10.2和补丁包Cudnn 8,安装完毕后再进行TensorRT安装。
1.1 下载安装TensorRT
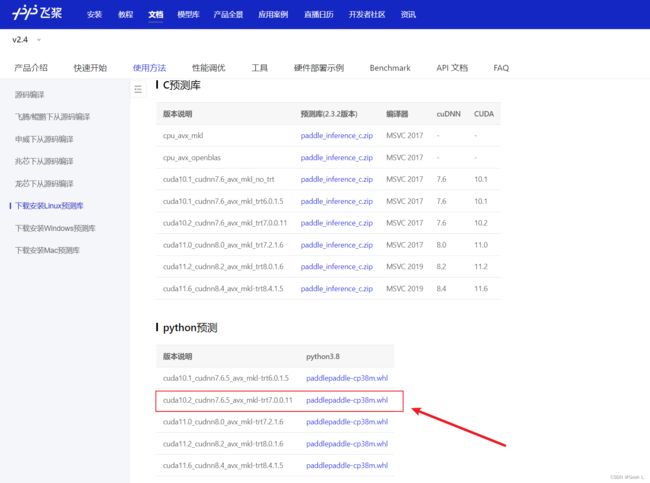
进入英伟达官网,选择和自己机器适配的TensorRT包,10系显卡使用CUDA10.2的加速效果会比较好,因此事先安装的是CUDA10.2版本。paddle官方给出的搭配是TensorRT7.0.0.11搭配CUDA10.2搭配cuDNN7.6.5。
TensorRT下载地址 NVIDIA TensorRT 8.x Download | NVIDIA Developer:
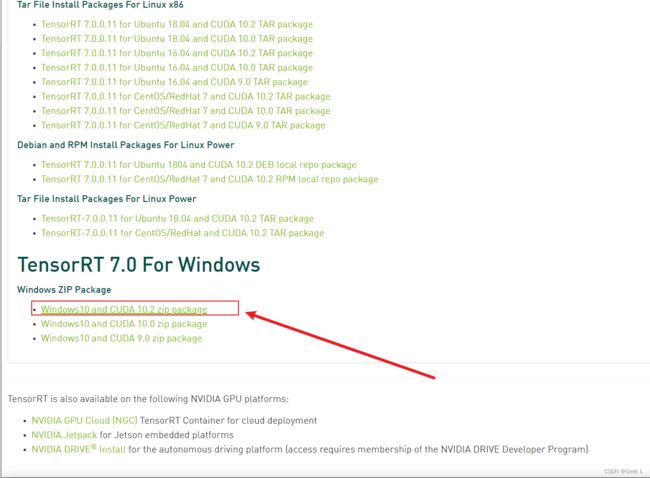
TensorRT的zip解压后内部如图:

接下来安装TensorRT文件夹中的.whl文件:
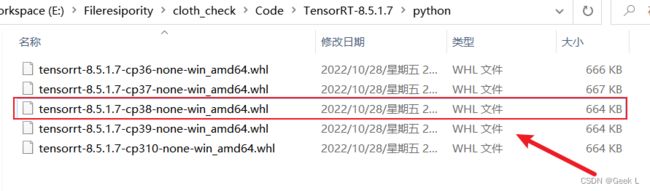



1.2 验证TensorRT安装是否成功
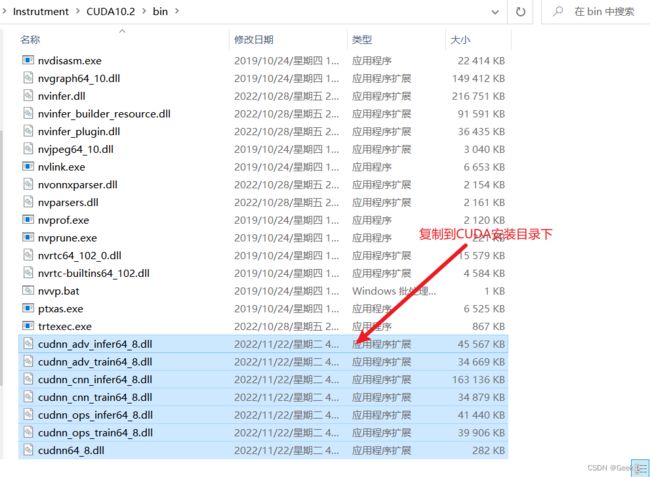
首先将lib中这几个dll复制到CUDA安装目录下:

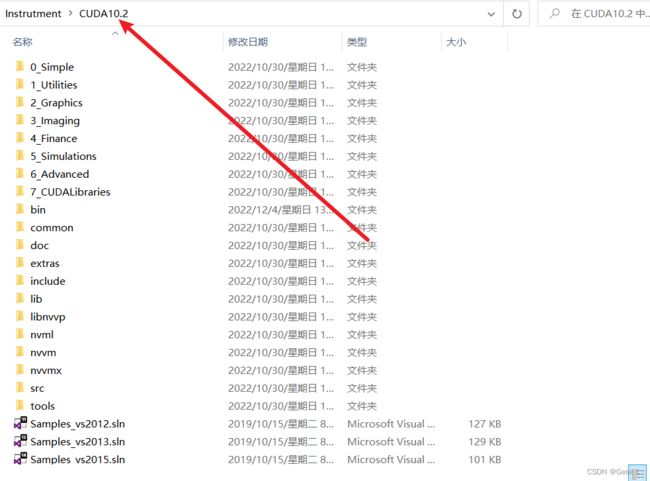
在cmd中打开Python查看trt的版本:
import tensorrt as trt
print(trt.__version__)
出现下面这种报错是因为Cudnn这个补丁包版本不对,或者没有正确地将dll包拷贝到CUDA安装目录下:
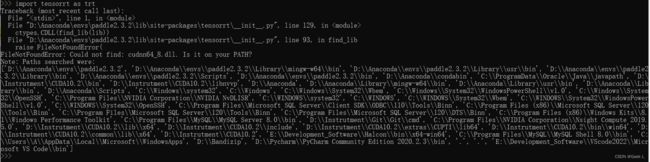
解决办法:重新下载Cudnn8.x,复制cudnn64_8.dll到CUDA安装目录下:


可以看到不再报错:

如果安装了Pytorch,还可以运行TensortRT文件夹下的sample.py对TensorRT的加速效果进行测试:
cd samples/python/network_api_pytorch_mnist
python sample.py
二. 安装并测试Windows预测库
2.1 安装cuda11.0_cudnn8.0_avx_mkl-trt7.2.1.6 预测库
安装:
pip install paddlepaddle_gpu-2.3.2-cp38-cp38-win_amd64.whl
2.2 测试精度损失
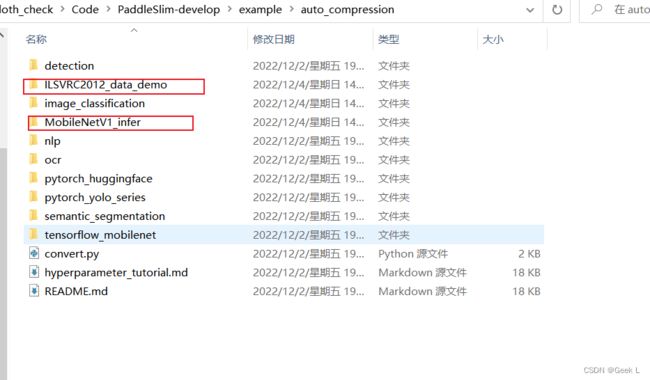
下载MobileNet预测模型
下载ImageNet小型数据集
把这两个文件下载下来放到auto_compression目录下:
测试压缩前模型的精度:
python ./image_classification/eval.py
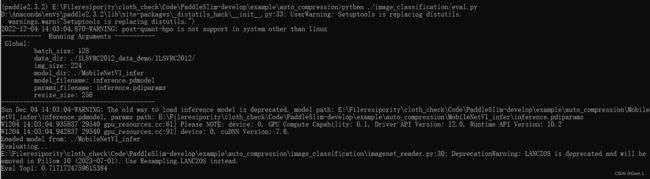
运行自动化压缩:
# 导入依赖包
import paddle
from PIL import Image
from paddle.vision.datasets import DatasetFolder
from paddle.vision.transforms import transforms
from paddleslim.auto_compression import AutoCompression
paddle.enable_static()
# 定义DataSet
class ImageNetDataset(DatasetFolder):
def __init__(self, path, image_size=224):
super(ImageNetDataset, self).__init__(path)
normalize = transforms.Normalize(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.120, 57.375])
self.transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(image_size), transforms.Transpose(),
normalize
])
def __getitem__(self, idx):
img_path, _ = self.samples[idx]
return self.transform(Image.open(img_path).convert('RGB'))
def __len__(self):
return len(self.samples)
# 定义DataLoader
train_dataset = ImageNetDataset("./ILSVRC2012_data_demo/ILSVRC2012/train/")
image = paddle.static.data(
name='inputs', shape=[None] + [3, 224, 224], dtype='float32')
train_loader = paddle.io.DataLoader(train_dataset, feed_list=[image], batch_size=32, return_list=False)
# 开始自动压缩
ac = AutoCompression(
model_dir="./MobileNetV1_infer",
model_filename="inference.pdmodel",
params_filename="inference.pdiparams",
save_dir="MobileNetV1_quant",
###config={"QuantPost": {}, "HyperParameterOptimization": {'ptq_algo': ['avg'], 'max_quant_count': 3}},
config={"QuantAware": {}, "Distillation": {}}, ### 如果您的系统为Windows系统, 请使用当前这一行配置
train_dataloader=train_loader,
eval_dataloader=train_loader)
ac.compress()
运行结果:

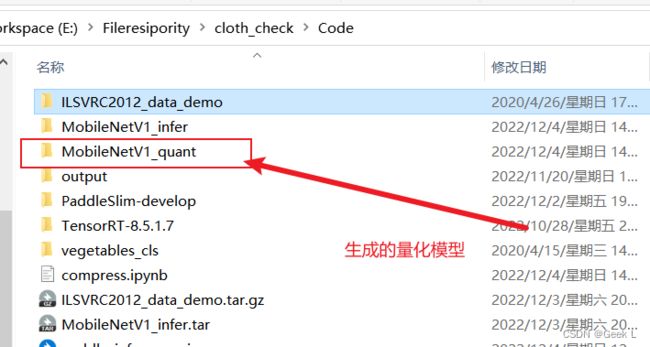
把生成的量化模型放在auto_compression目录下:

测试量化模型的精度:
python ./image_classification/eval.py --model_dir=MobileNetV1_quant
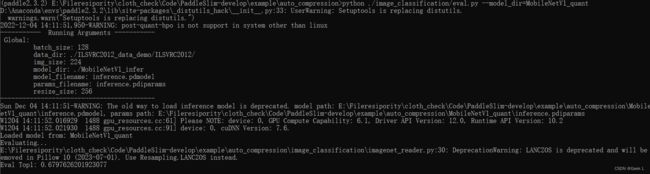
可以看到精度降为0.68左右,还可以接受。
2.3 推理速度测试
测试FP32模型的速度
python ./image_classification/paddle_inference_eval.py --model_path=./MobileNetV1_infer --use_gpu=True --use_trt=True
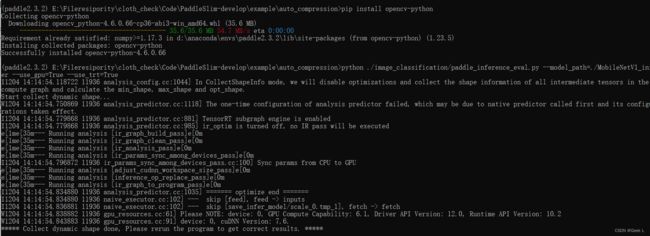
注意我这里是因为下载了cuDNNv7.6和v8.7两个版本但显示的是7.6,所以在CUDA安装目录下要用cuDNNv7.6的文件把cuDNNv8.7覆盖掉。
经过测试发现必须在cuDNN8.x提供的环境下,运行TensorRT7.x的程序才能正常进行,虽然有些反常识,但可能是工程师向后兼容造成的,这里不予理会。
测试FP32模型的速度

测试FP16模型的速度
python ./image_classification/paddle_inference_eval.py --model_path=./MobileNetV1_infer --use_gpu=True --use_trt=True --use_fp16=True
因为1080Ti不支持半精度浮点数运算,因此此项测试目前无效:

测试INT8模型的速度:
python ./image_classification/paddle_inference_eval.py --model_path=./MobileNetV1_quant/ --use_gpu=True --use_trt=True --use_int8=True
因为1080Ti不支持INT8整形运算,因此此项测试目前也无效:

三. 总结
模型自动化压缩工具ACT(Auto Compression Toolkit)提供了一种高效、端到端的方式来进行模型量化、蒸馏、剪枝及超参搜索等,可任意搭配使用,加速理论速度为1~4倍。