我从拉斯维加斯回来了
上周发了一篇文章《很想去一趟拉斯维加斯》,给大家介绍了re:Invent这个云计算的大Party,由于疫情原因,没法到现场参加,只能在线上观看,今天给大家分享一下这次大会在数据方面发布的一些新产品:
研究表明,未来三年(到2024年)企业创建的数据量将超过过去30年创建的所有数据量。数据的规模在不断扩大的同时,其种类也变得越来越多样化。数据旅程的各个阶段都需要由云原生数据基础设施来实现赋能,以提升系统的效率、可用性和可扩展性,并降低成本。
企业需要全面了解其业务的真实情况,才能让数据帮助企业在整个价值流程之中创造价值。数据一体化融合需要让企业打破数据孤岛,并以一种一体化的方式实现数据的共享与安全访问,以解锁不同企业用户和不同目的的数据价值。在进行扩展之前,需要先了解三个概念:
数据质量:将数据集中到一起进行分析处理,可以更加深入了解数据的内涵并获取价值,但是如果不谨慎处理数据质量的话,数据很快就会像沼泽一样把价值淹没。数据质量问题不仅仅是技术问题,也可能出现在业务和管理的过程中。所以,要想提高数据质量,就必须懂行业、懂组织、懂业务。
数据重力:用户添加使用现有数据层的应用程序时,是一个自我延续的循环过程。每次添加应用程序时,数据层都会得到扩展以适应新应用程序,随着数据层的增长,会逐渐将更多的应用程序吸引到单个共享数据层。数据重力不是将数据推向应用和服务,而是将应用和服务推向数据,而解决这个问题,需要强大的数据架构来进行支撑,同时也需要引入数据治理解决方案。
数据孤岛:在一个由数据驱动的组织中,数据属于组织资产,团队和应用程序可以从他们选择的工具中控制所需的所有数据的访问,并将数据投入工作。而各个子系统内所存储占有的数据就像一个个孤岛,难以和企业内部的其他数据进行连接互动,这样的情况被称为“数据孤岛”。简单来说,就是企业内部的数据间缺乏关联性,彼此无法兼容,可以设立贯穿组织各个部门,各个团队相的渠道路径,打破数据孤岛。

数据质量是所有决策的前提条件
在2022 re:Invent大会上,亚马逊云科技推出了Amazon Glue Data Quality,能够将手动的数据质量处理工作的时间从几天缩短到几小时,它可以自动计算统计数据、推荐质量规则、监控并在检测到质量下降时向用户发出警报。在数据对业务产生影响之前识别丢失、陈旧或不良数据,并使这个流程保持极简。

可控是数据融合的必要条件
在2022 re:Invent大会上,亚马逊云科技发布了 Amazon Lake formation 集中管控Amazon Redshift data sharing的预览版本。用户可以轻松地在内部使用中心管理,管理不同的查询、数据访问权限、为数据设置各种各样的安全规则。用户可以使用 Amazon Lake Formation API 和控制台查看、修改、审核 Amazon Redshift 数据共享中的表格和视图的权限。

针对机器学习治理(ML Governance),亚马逊云科技发布了Amazon SageMaker ML Governance 的三个新功能:Role Manager、Model Cards和Momdel Dashboard。新功能可以帮助企业制定机器学习的相关规则,Role Manger 可以简化授权的流程;Model Cards简化了模型管理的全生命周期,Model Dashboard让用户可以一站式了解已部署到生产中的模型的表现。

亚马逊云科技首个端到端的数据治理工具
在整体的数据治理上,亚马逊云科技则重点推出了Amazon DataZone 服务,这一套解决方案重点在于解决跨组织边界的大规模共享、搜索和发现数据。通过这个全新的工具,企业内部数据应用的工作流程得到了优化:跨团队可以无缝协作,并以自助服务方式访问数据和分析工具,大幅提高效率;整个过程中使用基于Web的应用程序实现数据个性化视图,轻量化且快捷;企业管理者还能够根据相应的法规以及公司内部的规章,一站式管理数据和各种访问权限。

实现数据的一体化融合,无需关注数据的存储位置
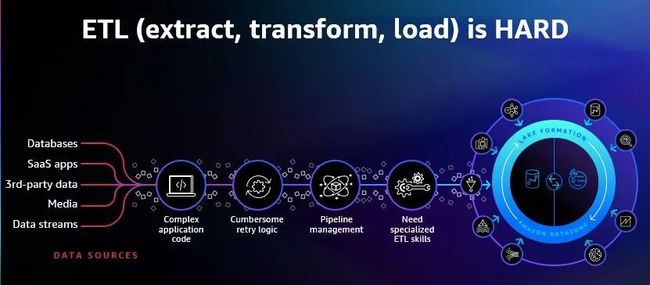
亚马逊云科技 CEO Adam Selipsky 多次强调了 ETL对于数据工程师工作的挑战,它代表了大数据任务中数据抽取、转换和加载等一系列工作。在大数据任务中,ETL 经常会花费整个项目的 1/3 的时间。亚马逊云科技希望消灭 ETL,让用户只需要专注于自己的业务逻辑。
为了实现数据“无感知的”流动,亚马逊云科技推出了Zero ETL,帮助企业执行机器学习,移动数据。Zero ETL不是一个服务,而是一个由多个服务组成的解决方案集合,其中涉及到了Amazon Glue,Amazon Redshift,Amazon MSK,Amazon Appflow,Amazon Athena,Amazon DataExchange。客户可以基于自身需求选取合适的Zero ETL服务进行自己的端到端数据之旅,实践数据一体化融合。Zero ETL进一步降低了数据融合的成本,实现近乎0投入的数据一体化融合,打造敏捷见解。
利用Amazon Redshift auto-copy from S3的自动复制,用户可以从 Amazon S3 平台上自动复制数据,将文件注入到Amazon Redshift当中,自动把新的文档根据客户的解决方案还有第三方的资源,整合起来使用。

不仅仅是从Amazon S3的自动复制,此次还发布了重磅产品Amazon Aurora zero-ETL to Amazon Redshift 的集成,可以不管数据在那个地方都可以开展数据分析和机器学习。因为 Zero ETL 可以无缝链接所有数据源,不管在亚马逊云科技还是在第三方的任何应用方面。
Amazon Aurora zero-ETL to Amazon Redshift,允许企业将PB级事务数据上使用Amazon Redshift实现近乎实时的分析和机器学习,而不必构建和维护复杂的数据管道来执行提取、转换和加载(ETL)操作;让使用 Amazon Aurora 数据库和 Amazon Redshift 数据仓库的客户能够快速将数据应用于自家机器学习服务 Amazon SageMaker 打造 AI 应用,而无需自定义数据管道。这将使得企业可以节省大量的不必要的冗余投入,专注于数据分析本身。

在re:Invent 2022 上,亚马逊云科技发布了Amazon AppFlow支持50多个连接器。Amazon AppFlow 是一项完全托管的集成服务,使用户能够在软件即服务 (SaaS) 应用程序与 Amazon S3 和 Amazon Redshift 等亚马逊云科技服务之间安全地传输数据。随着企业越来越依赖 SaaS 服务来实现关键任务工作流,他们面临着从不断增长的服务生态系统中收集数据到集中位置以使用分析和机器学习获得业务洞察力的挑战。借助 Amazon AppFlow,用户无需编写代码即可在数分钟内轻松设置数据流。

同时亚马逊云科技还通过Amazon SageMaker打造了新的数据源准入的解决方案,也就是Data Wrangler, 借助 Amazon SageMaker Data Wrangler,用户可以简化数据准备和功能工程的过程,并完成数据准备工作流程的每个步骤,包括通过单个可视界面进行数据选择、清理、探查和可视化。使用 Amazon SageMaker Data Wrangler 的数据选择工具,可以从各种数据来源中选择所需的数据,然后单击一下即可导入。Zero ETL进一步降低了数据融合的成本,让用户实现近乎0投入的数据一体化融合, 打造敏捷见解。

亚马逊云科技为数据的一体化融合扫清了数据质量保障、部门数据共享和降低数据融合成本三大数据治理障碍。16年来的云计算技术积淀,推动亚马逊云科技所有的数据服务都致力于帮助企业更好地利用数据发挥关键作用。
想了解更多 2022 re:Invent 全球大会新发布,点击阅读原文,观看回放。