2022.6.12 第十次周报
目录
一、Why we need Explainable ML?
1.Correct answersIntelligent
2.Interpretable V.S. Powerful
3.Goal of Explainable ML?
二、Local Explanation:Explain the Decision
1.Which component is critical?
2.Limitation
Noisy Gradient
Gradient Saturation
3.How a network processes the input data?
Visualization
Probing
三、Global Explaination:Explain the Whole Model
1.What does a filter detect?
2.What does a digit look like for CNN?
3.Constraint from Generator
一、Why we need Explainable ML?
1.Correct answers Intelligent
Intelligent
法律要求贷款发行人解释其模型。
医疗诊断模式是对人类生命负责的。它会是一个黑匣子吗?
如果在法庭上使用模型,我们必须确保模型以非歧视性的方式运行。
如果自动驾驶汽车突然出现异常行为,我们需要解释为什么。
2.Interpretable V.S. Powerful
我们可以基于解释改进ML模型一些模型本质上是可解释的。
例如,线性模型(从权重中,您知道要素的重要性)
但不是很强大。
深度网络难以解释。深度网络是黑匣子...但比线性模型更强大。
是否有一些模型可以同时解释和强大?
决策树怎么样?
3.Goal of Explainable ML?
完全了解 ML 模型的工作原理?
说白了,就是我们需要一个理由让身边的人满意。
二、Local Explanation:Explain the Decision
1.Which component is critical?
既然我们想要知道机器如何判断,这个问题其实等价于,机器把哪些所谓的特征看的很重要,是这些特征的出现很大程度的影响了机器的判断。
那我们要做的就是,把我们的这些所谓的组成部分来进行修改或者移除等等,来查看影响的效果即可。

在图像中的组成要素其实我们大致就可以看作是“一块区域”,这也是CNN的基本假设。那我们就可以移除一部分,然后来记录移除这个部分的影响。如下图,就是将一部分区域涂灰,然后再进行预测,预测的效果在图的下方,与上图涂灰区域的中心对应,预测效果越差就越是冷色调。那我们就可以说明,冷色调的部分很大程度上影响了机器最后判断,也就是所谓的机器学到的内容。
例如下面第三张图中,机器识别出来了狗。如果我们不采用这种方法,我们完全可以不信机器真的是看到了狗才识别出来的,而是把左面的人看成了狗;而采用这种方法,我们看出如果图片中抹去了狗的部分,那机器完全不会在这张图中找到狗,那就说明了机器确实是学到了狗的相关特征。

我们可以从另一个角度来去寻找机器更看重哪些信息。对于比较重要的信息,按道理更有可能是对最后的结果影响越大,那么相当于就是,如果输入信息有改变,那么对结果的改变就会更大;如果我们把这个思想取极限,那么就是导数了。根据每个值对目标值得偏微分,我们可以画出一个Saliency Map。
如下图所示,导数越大的地方越明亮。当然,我们这里是计算结果对N个要素的求导而不是单纯的对每个像素求导,因为明显一个像素的改变不会影响结果,也不算是一个特征。
2.Limitation
Noisy Gradient
我们就加入了一些肉眼看不到的噪声,也没有改变机器分类的结果,但机器所关注到的部分改变了很多,这就说明了这种方法并不是完全可靠的,而且机器学到的内容可能还是很杂,不是我们想要的效果。处理方式是,那我们就对原来的图片加入一个高斯分布的噪音,形成n张图片,然后把这n张图片取平均,来作为说明每个部分的效果。这种方法也被称作SmoothGrad。这里有一个小误区,那就是这样多次加噪声取平均,只是可以更好的说明到底哪个地方的影响力大,而如果是为了用于训练分类器的话,多次取平均与就一次加噪声效果是一样的。

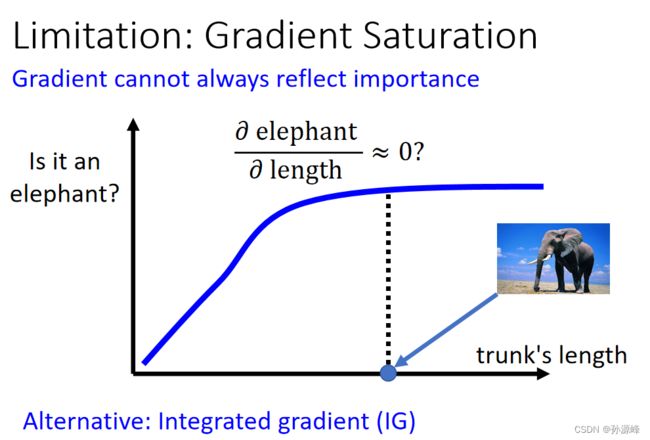
Gradient Saturation
信息冗余现象 ,如下图所示,横轴是鼻子长度而纵轴是说判断为大象的概率。显然,鼻子长是大象的一个极其显著的特点,这里的曲线我们也可以确定机器是关注到这一点的了;但是鼻子长到足够明显了的时候,再长貌似就没有必要了,即信息冗余。如果我们在这个时候看梯度,那竟然几乎是0,也就是说梯度是饱和的(Gradient Saturation),从而和我们的想法相矛盾。如果我们要考虑到对应的前面的梯度,那就只能是连接原点和这个点,就转化成了所谓的移除要素,而不是轻微的改变这个要素了。
3.How a network processes the input data?
那么,一个network是如何处理输入的数据的呢?
1.用人眼观察
2.用probing
Visualization

Probing

三、Global Explaination:Explain the Whole Model
1.What does a filter detect?
假设已经训练好一个CNN,将一张图片X经过Convolution层之后,得到一个feature map。
以filter1为例,通过filter1得到的feature map中大的值可以理解为filter1检测到的该图片的主要特征

现在我们想知道,对于任意一张图片,filter1想要看的pattern到底长什么样的。 所以我们要创造一张图片,这张图片包含filter1所要detect的pattern。 通过看图片中的内容,就可以知道filter1到底负责detect什么东西。
怎么找这张图片呢?
假设filter1对应的feature map中的每个特征值为M ,找到一个X,让 M的总和最大,记录这个X为X*。 通过观察X*长什么样子就可以推断出filter1可以detect一张图片中的什么特征。 
2.What does a digit look like for CNN?
以手写数字为例, 我们现在想找到一个X,让输出的某一类别的可能性越高越好。 从下图可以看出,让整个网络输出的某一类别的可能性最高,对应是并不是我们的手写数字 而是一堆什么都不知道的杂讯,没有办法看到数字。
我们其实是希望,我们最后生成的这些图片,应该是尽量像数字的,从而这就成为了正则化项。比如上图中我们看到,白色像素的点还是太多了,而所有的手写数字图片中,白色的亮点都是比较少的,因此我们就可以在这里加入正则化项,使得我们的整体越暗越好(换句话说就是白色亮点越少越像数字),最后的结果如下图所示,还是有一定效果的。当然,这一定不是最好的正则化方式,但如果我们人去定义的话,我们很难去找到一个更有说服力的正则化方式。
3.Constraint from Generator
如果想要看到非常清晰的资料,我们可以使用generator。
我们本来是想找x,然后我们又知道x = G(Z),所以我们退而求其次,找 Z,找到 Z*之后,再用image generator(比如GAN,VAE等)生成x*。
这个是如何起限制作用的呢?
我们知道,我们加上限制,就是想要使找出来的x*尽量地能被人看懂,或者说能尽量地让人看起来它是yi的,而不是一堆人看不懂的东西(比如上面数字识别那个例子,右边就比左边更像正常的图片)。而image generator本来就是生成图片的,也就是说z丢进image generator后输出的x,是人能看懂的图片,这样也就达到了我们限制的目的。