Learning Pixel-level segmantic affinity with image-level supervision for weakly supervised segmentat
Abstract.
缺少分割的label是阻碍语义分割发展的一个主要因素,为了缓解这个问题,我们提出了一个新的框架结构通过class label去产生segmentation label.在这个弱监督里,被训练的models会去分割local discriminative parts而不会分割整个区域。作者的解决办法是将local responses传播到附近的相同语义的区域。我们提出了一个Deep Neural Network(DNN) 被叫做 AffinityNet,这个网络会去预测一对相邻像素的affinity,随机漫步和从网络结构里得出来的affinities就可以实现,semantic propagation。更重要的是,训练AffinityNet的监督是最初的discrimination part segmentation,而这些最初的分割虽然对于标注是不完整的,但是对于学习semantic affinities却是很有效的。因此整个框架仅仅只会依赖image-level class labels而不需要额外的数据和标注。在PASCAL VOC 2012上,DNN通过作者的方法产生的segmentation labels来进行学习,会比其他弱监督的methods要更好。
1.Introduction.
Deep Neural Networks(DNN)的发展使得语义分割向前迈了一大步。尽管DNNs取得了很大的成功,但是为了使语义分割能应用在uncontrolled和realistic的环境中,我们仍然有很远的路要走。缺乏数据集使最主要的一个阻碍。由于pixel-level segmentation labels的标注会十分耗时间,耗人力,现存的的datasets常常会遭受缺乏标注的样本和class多种多样的困扰。这就使得卷积这个方法被限制在了一个小范围的物体类别的范围。
弱监督的方法就是用来解决上述存在的问题,让语义分割更加具有可扩展性。弱监督方法的共同动机就是使用bounding box和 scribles这样的方法,这些方法都会比pixel-level弱,但是在规模很大的数据集上会比较容易得到。在各种各样的弱监督的方法中,image-level class label被广泛的应用在了语义分割上。然而,image-label的supervision去处理语义分割问题,本来就是一个病态问题,因为image-label仅仅只会暗示图中有没有包含这种类别的物体,但是却不能定位物体的位置和描述物体的形状。
在作者的这篇论文中,综合了一些其他的evidences去计算location和shape的信息(这些信息都是在image-label这个弱监督中缺少的信息)。Class Activation Map是一种可以找到物体定位信息的一种著名的方法,这种方法可以通过研究隐藏单元对于DNN分类结果的贡献,突出目标物体的局部具有判别特征的区域。被CAM突出的具有判别性的区域然后被作为seeds,然后去传播到整个物体。
在这篇文章种,作者提出了一种简单有效的方法,去补偿缺失的物体形状的信息,并且不需要额外的数据和监督。我们这个结构里的最重要的部分就是AffinityNet(这个结构是一个DNN,读入一张图片,然后去预测相邻像素的affinities)。给一张图片和他的CAMs,我们首先构建一个neighborhood graph(where each pixel is connected to its neighbors within a certain radius),然后去计算semantic affinities。作者通过Random Walk去扩散CAMs:在edges上的,鼓励去传播到有相同语义的附近区域,而惩罚传播到不同语义的区域。这样的扩散方法Rondom Walk很显著的修正了CAMs很好的还原了物体的形状。作者用这样的处理过程去训练图片合成他们的segmentation lable,然后生成的segmentationlabels被用作去训练model

现在仍有一个问题及时怎样去学习AffinityNet而不需要额外的信息和额外的监督。我们发现CAMs在一个图片上的一个区域里可以很好的预测像素之间的affinity,于是我们用CAMs作为监督去训练AffinityNet。
网络训练的步骤如上图所示,首先根据图片的image-label计算出CAMs然后,用CAMs得到affinity lables,用affinity label和原始的train image去训练AfinityNet这个网络结构(图一),然后在根据训练好的AffinityNet和Random Walk去产生对应图片的segmentation lables(图二),最后根据segmentation labels和train images去训练Seg Net。
作者这篇paper有以下三个贡献:
1)在仅有image-level class label的条件下,作者提出了一个新颖的结构DNN(AffinityNet)预测了high-level semantic affinities in a pixel-level
2)和大多数之前的弱监督方法不同,作者的方不依赖于现成的技术,而是充分理由特征学习,通过端到端的训练AffinityNet
3)在PASCAL VOC 2012的数据集上,我们取得了很好的结果。
3.Our Framework
two parts:1)合成segmentation labels 2)训练seg net分割物体
three network:1)A network computing CAMs 2)AffinityNet 3)segmentation model
3.1Computing CAMs
architectures: classification network + global average pooling + fully connected layer ;这个网络结构用image-level labels去训练。

![]() ,
,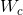 是和类c相联系的分类权重,
是和类c相联系的分类权重,![]() 代表着在feature map上,在GAP之前,(x,y)这个位置的特征向量。
代表着在feature map上,在GAP之前,(x,y)这个位置的特征向量。![]() 然后会被normalized,所以
然后会被normalized,所以![]() ------>
------> ![]() /
/![]()
![]() .对于任何与groundtruths无关的类别
.对于任何与groundtruths无关的类别![]() ,我们都会使它的的
,我们都会使它的的![]() 的得分为零。
的得分为零。
同时我们也会计算背景的activation map:![]()
3.2Learning AffinityNet
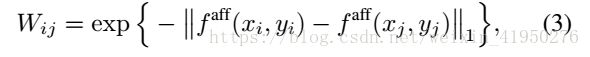
其中AffinityNet被设计来预测一个卷积特征图![]() 的affinities,特别的在features i和features j 之间的semantic affinity 用
的affinities,特别的在features i和features j 之间的semantic affinity 用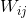 来表示
来表示
3.2.1Generating semantic affinity labels
用image-level labels去训练AffinityNet的时候,我们用CAMs作为train data 的监督。CAMs虽然不是很准确,但是却可以得到可信赖的semantic affinity
我们最基本的思想就是从CAMs里,寻找物体的confident areas和background,然后对于训练样本的这些区域进行采样。为了估计物体的confident areas,对Eq.(2)我们首先用 去加强背景,所以在CAMs中背景的得分都很低。在用CRF对CAMs进行refinement之后,我们就可以收集相关坐标的得分,如果这些得分比其他类的高,那么这个区域就是confident areas。然后background随后也可以用同样的方式计算得到。
去加强背景,所以在CAMs中背景的得分都很低。在用CRF对CAMs进行refinement之后,我们就可以收集相关坐标的得分,如果这些得分比其他类的高,那么这个区域就是confident areas。然后background随后也可以用同样的方式计算得到。

3.2.2 AffinityNet Training
对feature map上每一个特征向量都进行affinity的学习也是没有必要的,于是我们引入了下面这个函数,控制学习的区域:
![]()
作者把待分析的P给分解为两个部分:

上面代表正区域,下面代表负区域。然后将 继续分解为
继续分解为![]() 和
和
损失函数:

3.3 Revising CAMs Using AffinityNet
这里又有一个公式;

这公式讲的是如何从affinity来引导Random Walk去完善CAMs,这里介绍一下公式里的一些量。W是 affinity matrix,他的对角元素都是1.T是transition probability matrix
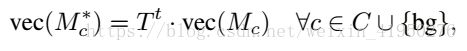
这个公式讲的是把得出来的矩阵用在CAMs上改善initial CAMs
4.Network Architectures
4.1 Backbone Network
这篇论文里的三个DNN的结构都是以ResNet38为基础的,
4.2Details of DCNNs in our framework
1)Network computing CAMs:在Backbone后加上 一个3x3convolution layer with 512 channels+global average pooling layer+ fully connected layer
2)