超越所有Anchor-free方法!PP-YOLOE-R:一种高效的目标检测网络
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
后台回复【PPYOLO】获取论文、代码等更多资料!
超越所有Anchor-free方法!PP-YOLOE-R:一种高效的目标检测网络
PP-YOLOE-R是基于PP-YOLOE的高效anchor-free旋转目标检测器,作者在PP-YOLOE-R中引入了一系列有用的技巧,以提高检测精度,同时减少额外参数和计算成本PP YOLOE-R-I和PP YOLOE-R-x在DOTA 1.0数据集上分别达到78.14和78.28 mAP,使用单尺度训练和测试,这几乎优于所有其它旋转目标检测器。通过多尺度训练和测试,PP-YOLOE-R-l和PP-YOLOE-0-x进一步将检测精度提高到80.02和80.73 mAP。在这种情况下,PP-YOLOE-R-x超越了所有anchor-free方法,并展示了与anchor-based的两阶段SOTA模型相比的竞争性能。此外,PP-YOLOER是部署友好的,PP-YOLOE-R-s/m/l/x在RTX 2080 Ti上分别达到69.8/55.1/48.3/37.1 FPS(使用TensorRT和FP16精度)。
1领域应用背景
检测任意方向的目标对于理解遥感图像具有重要意义,并引起了越来越多的关注,由于物体的尺度和方向的巨大变化,旋转目标检测仍然具有挑战性。受益于水平目标检测的快速发展,越来越多的旋转目标检测器[2,5,7,24,6,16,13,10,8,11,20]出现,它们主要源自相应的水平物体检测器[14,17,18,28]。在这些旋转目标检测器中,有方向目标的表示可以大致分为三种方式,即具有五个参数的旋转边界框、具有八个参数的四边形和一组关键点。
目前,基于五参数表示的旋转目标检测器主导了这一研究领域。尽管取得了令人满意的结果,但直接五参数回归仍然存在一些理论问题,如边界不连续性问题。边界不连续性问题主要由角度的周期性和边缘的交换能力引起,而后者与旋转边界框的特定定义(如长边定义)有关。有许多工作被提出来解决边界不连续性问题,如[15,25,26,27,22,23]。[15,25,26,27]将旋转边界框建模为高斯分布,并提出计算友好的基于IoU的损失作为可微SkewIoU损失的替代,以避免直接角度回归。[22,23]将角度预测视为分类,并设计平滑标签以避免边界不连续问题。充分借鉴了先进水平和有方向检测器的优秀思想,论文提出了PPYOLOE-R,一种基于PP-YOLOE的高效anchor-free旋转目标检测器!
与PP-YOLOE相比,PPYOLOE-R的主要变化可归结为四个方面:
(1) 引入ProbIoU损失作为回归损失,以避免边界不连续问题;
(2) 在任务对齐学习的基础上引入了旋转任务对齐学习,以适合旋转对象检测;
(3) 设计了一个解耦的角度预测头,并通过DFL损失直接学习角度的一般分布,以获得更准确的角度预测;
(4) 通过添加可学习门控单元来控制来自前一层的信息量,对重参数化机制进行了轻微修改;
因此,PP-YOLOE-R在DOTA 1.0数据集上的速度和精度权衡方面达到了SOTA。PPYOLOE-R-l和PP-YOLOE-R-x通过单尺度训练和测试分别达到78.14和78.28 mAP。通过多尺度训练和测试,PP-YOLOE-R-l和PP-YOLOE-0-x进一步将检测精度分别提高到80.02和80.73 mAP。在保持高精度的同时,PP-YOLOE-R-l可以在1024×1024分辨率下以TensorRT和FP16精度实现48.3 FPS的速度,此外,PP-YOLOE-R-s和PP-YOLOE-R-m也具有优异的性能,适用于计算能力相对较低的边缘设备,代码可以在PaddleDetection上找到。
基于anchor方式的旋转目标检测器。基于anchor的旋转目标检测器具有类似于水平目标检测器的one-stage和two-stage方法。RoI Transformer提出了一种RRoI学习器,以预测旋转GT相对于预测HRoI的偏移。Oriented R-CNN设计了一个面向轻量级的RPN,以生成面向高质量的proposal。ReDet引入了ReCNN来获得旋转等变特征图,并引入了RiRoI Align来提取RRoI的特征。S2ANet和R3Det都采用了用于检测有方向目标的单级框架,S2ANet提出了基于可变形卷积网络的对齐卷积层(ACL),而R3Det设计了基于插值的特征细化模块(FRM),以缓解特征失准!
Anchor-free旋转目标检测器。anchor-free旋转目标检测器主要基于中心点或一组关键点,DAFNe提出了oriented中心度和中心到角预测策略,而FCOSR专注于基于FCOS的标签分配策略,以提高检测性能。CFA和oriented RepPoints通过基于RepPoints预测九个代表点间接预测oriented边界框!
标签分配。标签分配的目的是区分阳性和阴性样本,可以分为静态策略和动态策略。在训练过程中,动态标签分配利用模型的输出作为选择正样本和负样本的基础,而静态标签分配根据基本事实和预定义规则确定正样本和阴性样本。FCOSR提出了椭圆中心采样方法、模糊样本分配策略和多级采样模块,以缓解采样不足的问题。[8] 提出了形状自适应选择(SA-S)来根据样本的形状来调整IoU阈值,G-Rep用归一化高斯分布距离代替IoU作为分配指示符。DAL引入了考虑空间匹配的先验和动态选择正样本的特征对齐能力的匹配度,类似地,Oriented RepPoints设计了一种质量度量来分配样本。由于丧失角度的周期性和边缘的交换能力,基于直接回归的旋转物体检测器存在边界不连续性问题。CSL和DCL以分类方式预测角度,为了避免边界不连续问题,GWD、ProbIoU、KLD和KFIoU将旋转边界框转换为2D高斯分布,并构建两个高斯分布的距离度量,以测量两个旋转边界框的相似性。GWD利用Gaussian Wasserstein距离来近似SkewIoU,而ProbIoU利用Bhattacharyya系数来测量两个旋转边界框的相似性。KLD计算两个高斯分布之间的Kullback-Leibler散度(KLD)作为回归损失,此外,KFIoU通过采用卡尔曼滤波器根据其定义模拟SkewIoU,实现了与SkewIoU的trend-level alignment!
2PP-YOLOE-R
如图2所示,PPYOLOE-R的整体结构与PP-YOLOE的相似,PP-YOLOE-R以相对较少的参数和基于PP-YOLOE的计算为代价,提高了旋转边界框的检测性能。在本节中,将详细介绍对旋转边界框所做的更改。
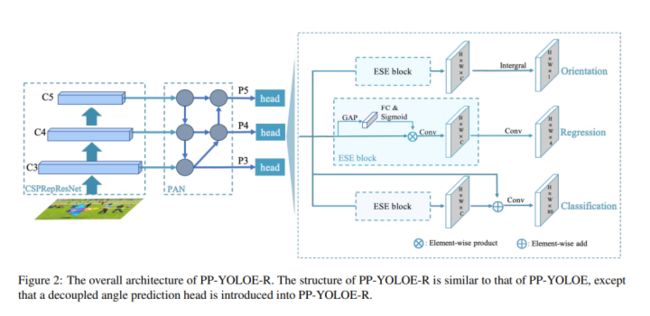
基线。依据FCOSR,将FCOSR Assigner和ProbIoU损失引入PP-YOLOE作为基线,采用FCOSR Assigner根据预定义的规则将GT分配给三个特征图,并将ProbIoU损失用作回归损失。论文基线的主干和neck与PP-YOLOE保持相同,而head的回归分支被修改为直接预测五个参数旋转边界框(x,y,w,h,θ),论文的基线在单尺度训练和测试中达到75.61 mAP,如表1所示。
旋转任务对齐学习。任务对齐学习由任务对齐标签分配和任务对齐loss组成,任务对齐标签分配构造任务对齐度量,以从候选锚点中选择正样本(坐标落入任何真值框中),任务对齐度量计算如下:

解耦角度预测头。在回归分支中,大多数旋转目标检测器预测五个参数(x,y,w,h,θ)来表示oriented目标,然而,论文假设预测θ需要与预测(x,y,w,h)不同的特征。为了验证这一假设,作者设计了一个解耦角度预测头,如图2所示,分别预测θ和(x,y,w,h),角度预测头由信道关注层和卷积层组成,非常轻便。通过引入解耦角度预测头,检测精度提高了0.54mAP至77.24mAP,如表1所示。
利用DFL进行角度预测。采用ProbIoU损失作为回归损失,共同优化(x,y,w,h,θ),为了计算ProbIoU损失,旋转的边界框被转换为高斯边界框。当旋转边界框大致为方形时,旋转边界框的方向无法确定,因为高斯边界框中的方向继承自椭圆表示。为了克服这个问题,论文引入了DFL来预测角度,与学习Dirac delta分布的范数不同,DFL旨在学习角度的一般分布。作者将角度离散化为偶数间隔ω,并以积分的形式获得预先给定的θ,其公式如下:

RepVGG的可学习门控单元。RepVGG提出了一种由3×3 conv、1×1 conv和快捷路径组成的多分支架构,RepVGG的训练时间信息流程可制定如下:

f(x)是3×3 conv,g(x) 则是1×1 conv,虽然RepVGG相当于卷积层,但在训练期间使用RepVGG会更好地收敛。作者将此结果归因于RepVGG的设计引入了有用的先验知识。受此启发,在RepVGG中引入了一个可学习的门控单元,以控制来自前一层的信息量。这种设计主要针对微小目标或密集目标,以自适应地融合具有不同感受野的特征,其公式如下:
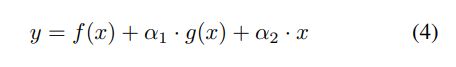
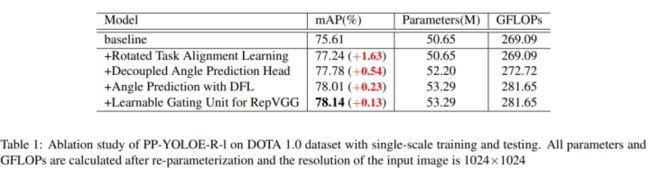
ProbIoU损失。通过将旋转边界框建模为高斯边界框,两个高斯分布的Bhattacharyya系数用于测量ProbIoU中两个旋转边界框的相似性。GWD、KLD和KFIoU也是基于高斯边界盒的相似性度量。为了验证ProbIoU损失的影响,论文选择KLD损失进行实验,因为KLD损失是尺度不变的,并且适用于无锚方法。如表3所示,用KLD损耗代替ProbIoU损耗会导致性能从78.14mAP显著下降到76.03mAP,这表明ProbIoU损耗更适合我们的设计。

3实验
DOTA是一个用于识别方向的目标检测大规模遥感数据集,包含15类,由2806幅航空图像组成,大小约为4000×4000像素,188282个实例,具有各种尺度、方向和形状。随机选择一半的航空图像作为训练集,1/6作为验证集,1/3作为测试集。对于单尺度训练和测试,论文将原始图像裁剪成1024×1024块,重叠256像素。对于多尺度训练和测试,将原始图像按0.5、1.0和1.5的比例调整大小,然后裁剪成1024×1024块,重叠500像素。
PP-YOLOE-R采用CSPRepResNet作为主干,PAN作为neck,提取P3、P4和P5金字塔特征用于旋转目标检测。在训练中使用了动量=0.9和weight decay=5e-4的随机梯度下降(SGD)。初始学习率设置为0.008,warmup 1000次迭代,预热后使用余弦学习率。在训练过程中,还采用了衰减=0.9998的指数移动平均(EMA)策略。数据增强采用随机翻转,并采用FCOSR之后的两步旋转增强方法来生成随机增强数据。
与其它SOTA检测器的比较
论文在DOTA 1.0数据集上进行了广泛的实验,实验结果如表2所示。通过单尺度训练和测试,PP-YOLOE-R-l和PP-YOLOE-0-x分别达到78.14和78.28 mAP,这几乎超过了所有旋转目标检测网络。通过多尺度训练和测试,PP YOLOE-R-l和PP YOLOE-R-x进一步将检测精度提高到80.02和80.73 mAP。PP-YOLOE-R-x优于所有anchor-free方法,仅比具有最高精度的两级anchor-based的模型低0.2 mAP。此外,PP-YOLOE-R-s和PP-YOLOE-R-m可以通过多尺度训练和测试获得79.42和79.71 mAP,考虑到这两个模型的参数和GLOPS,这是极好的结果。在保持高精度的同时,PP-YOLOE-R避免使用特殊运算符,如可变形卷积或旋转RoI对齐,以便在各种硬件上友好部署。因此,PP-YOLOE-R可以使用TensorRT轻松加速,而大多数其他SOTA模型目前不容易使用TensorRT进行部署。在1024×1024的输入分辨率下,PP-YOLOE-R-s/m/l/x在RTX 2080Ti上可以达到32.2/23.7/19.5/13.7 FPS。凭借TensorRT和FP-16精度,PP-YOLOE-R-s/m/l/x可以进一步分别加速至69.8/55.1/48.3/37.1 FPS。
4参考
[1] PP-YOLOE-R: An Efficient Anchor-Free Rotated Object Detector.
往期回顾
最新冠军方案开源 | MOTRv2:YOLOX与MOTR合力打造最强多目标跟踪!(旷视&上交)

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
