07组第二次作业 深度学习和pytorch基础
07组第二次作业 深度学习和pytorch基础
1.视频学习 20020007118 张泽峰
1.1绪论
人工智能的前景比较广阔,人才缺口比较大。
专家系统
早期的人工智能依赖于专家系统
通过一些专家的定义 人工的归纳出一些准则,机器通过这些准测去进行判断
专家学习->机器学习
不在又人(专家)去定义这个准测,而是又数据通过一些算法,得到一些准测,机器通过这些准测在进行区别或划分
机器学习定义:
从数据中学习
监督学习vs无监督学习
区别:数据有无被标记 无监督模型数据没标注
半监督模型
部分数据被标记
强化学习
奖励反馈,使用未标记的数据,每一步都有反馈。
人工智能>机器学习>深度学习

特征设计的时候从人到了机器
到深度学习的时候,出现了分层的概念,在特征之间也有多层
深度学习的能与不能
深度学习的十点不能

1.算法不稳定,
2.难以调试,无法纠错
3.层级符合度高,参数不透明
4.对数据的依赖性强
5.专注直观感知问题,对开放性推理问题没有解决方案
6.机器偏见难以避免
1.2深度学习概述
生物神经元和神经网络的共同点
1.多输入单输出
2.空间整合 时间整合
3.双向输入 促进和抑制
4.阈值特性 到达一定才会激活
激活函数
没有激活函数相当于矩阵相乘 会得到线性结果
单层感知器
无法解决非线性问题 第一次低谷
多层感知器
多个单层的组合,可以解决一些复杂问题
神经网络每一层的作用
将多参数的数据非线性变换到一个超平面上,最后线性可分.
梯度消失
多层神经网络可以看成一个复合的非线性多元函数

前向传播过程中,得到的残差过小,落在激活函数的饱和区,无法传递到前几层
第二次没落
梯度下将
沿负梯度的方向更新可以是函数值下降
误差反向传播
通过计算残差,得到反馈
逐层预训练
对参数进行一个初始化
对函数进行一个三层的训练,取中间结果进行下一层的训练
自编码器
没有额外的监督学习,把自己当作输出结果
自编码器一般是个多层神经网络
最早应用与降维

受限波尔兹曼机
模型:两层的神经网络 二分图
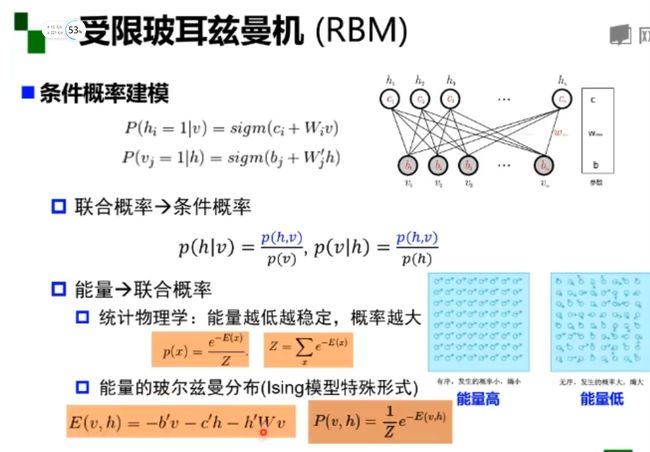
能量分布得出的条件概率
2. 代码练习
2.1 pytorch 基础练习


这些基础的代码,复制粘贴进去跑了一遍,第二次使用了,孰能生巧
里面一下操作是线性代数里面的
2.2 螺旋数据分类

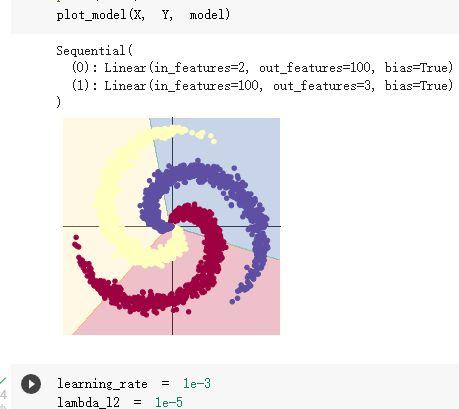
这里是线性模型,可以看出分类的准确度不是很好,大约与一半都在错误区间里

当我们增加神经层后,并在两个神经层里添加一个relu函数,发现分类明显准确度高了很多
但并不是神经层越多效果就越好,当神经层多了之后可能出现过拟合的现象
博客作业
张俊博 20020007100
一.视频学习心得问题及总结
1.绪论
最大的感受就是:确实现在人工智能的发展很快,从一个概念到逐步迈向现实大概也就几十年的时间,这一段的学习给我留下最深印象的就是几种学习模式:监督学习、深度学习、机器学习。
现如今机器能够通过大量图片、经验来逐渐优化自己的模型,这种自我学习的模式已经很令人惊讶了,如今我更加期待今后所要发展成的仅仅通过几张图片就可以自己建立出恰当的数据模型的深度学习模式但是机器学习也不是万能的,机器学习也有力所不能及之事:算法输出不稳定、对开放性推理问题无能为力等等。
2.深度学习概述
生物神经元引入了M-P神经元这种构想无疑是天才的,确实给了我很大的震撼。对于浅层神经网络的学习,由生物神经元到单层感知器、多层感知器,再学到激励函数、反向传播和梯度消失,也算是在我心中画出了一个大致的框架。
对于目前需要得到处理的许多数据而言,两层神经网络的自编码器还不足以得到一种理想化的结果。为了得到更好的数据表示,就需要采取更深层的神经网络。然而增加学习深度更容易造成“梯度消失”,而且多层网络容易陷入局部极值,难以找到更优解,难以训练,也正是由此,目前乃至将来的很长一段时间,三层神经网络结构依旧是深度学习的主流,要想采用更深层的神经网络架构,就必须采取措施来抑制梯度消失。
问题总结:1.不是很懂万有逼近定理。(如果一个隐层包含足够多的神经元,三层(单隐层)前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数)?
2.感觉有些的东西都是听起来云里雾里的,比如激励函数,是怎么想到的呢,属实是佩服那些大佬。
二.代码练习
1.pytorch 基础练习
pytorch练习分为两个部分(1)定义数据 (2)定义操作
(1)定义数据
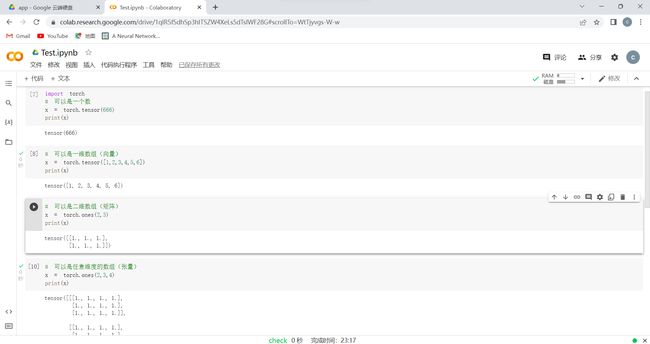
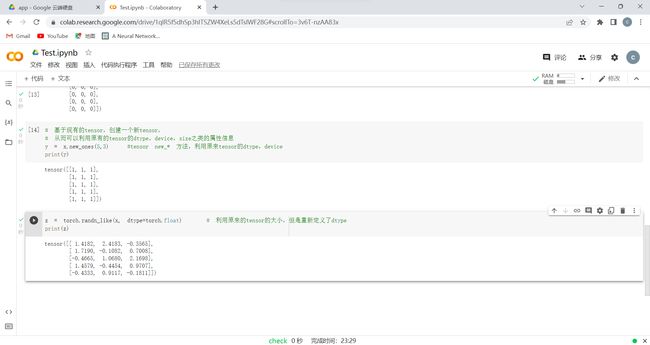
一般定义数据使用torch.Tensor , tensor是数字各种形式的总称,比如:数字、向量、矩阵、任意维度的数组。

创建张量有多种方式,也可以创建出各种类型的张量。

2)定义操作
实际上就是利用tensor进行各种运算:加减乘除、布尔运算、线性运算、跟矩阵有关的运算等等
。

2.螺旋数据分类

从这三个图像上看,是逐步对螺旋数据分类模型进行优化。
第一个图像:参数的随机初始化使得正向传播与反向传播的结果出现差异,成功完成了学习不同特征的目的,也最终得到了图像一。
第二个图像与第三个图像相比可以明显的发现图二的数据分割线是直线,而图三的数据分割线是曲线(跟随这螺旋的弯曲而弯曲),其关键原因就在于图三增加了一个激活函数。
而这个激活函数实现了非线性转换,使得其数据分类准确率上升,由原来的0.504——>>0.949,最终呈现的图像结果也就不同了。
2022年秋季《软件工程》作业报告
| 姓名和学号? | 钱程志,20060012028 |
|---|---|
| 本实验属于哪门课程? | 中国海洋大学22秋《软件工程》 |
| 实验名称? | 第二次作业:深度学习和pytorch基础 |
视频学习心得及问题总结
这里我就记录了一些学习笔记,以及学习过程中的思考
一、绪论
1、图灵测试
这是我听到的第一个很感兴趣的话题,听到这个测试之后,我也思考了很久,怎么才能分辨出人和机器呢,放在十年之前,我都不会对这个问题的答案有意思犹豫,但是近几年人工智能的快速发展,像siri,小爱同学,天猫精灵,小度小度等聊天软件已经越来越智能化。
我又去上网搜了一下,2015年11月,《Science》杂志封面刊登了一篇重磅研究:人工智能终于能像人类一样学习,并通过了图灵测试。测试的对象是一种AI系统,研究者分别进行了展示它未见过的书写系统(例如,藏文)中的一个字符例子,并让它写出同样的字符、创造相似字符等任务。个人觉得,当人工智能有了自主学习这个功能,其与人类的差别只会越来越小,甚至以后可能会仅剩下意识和感情,科幻片的场景可能真的会到来。人类改何去何从呢?值得思考!
2、人工智能三个层面:计算智能,感知智能,认知智能
3、人工智能>机器学习>深度学习
4、知识工程(专家学习)vs机器学习:机器学习自动学习,减少人工繁琐工作,提高信息处理效率,减少了人工规则主观性,可信度高
5、机器学习定义:
(1)计算机系统能够利用经验提高自身的性能
(2)机器学习本质时一个基于经验数据的函数估计问题
(3)提取重要模式、趋势,并理解数据,即从数据中学习
机器学习三个过程:建模,策略,算法
6、模型 从三分维度划分模型:
(1)数据标记:监督学习模型、半监督学习模型、无监督学习模型、强化学习模型
监督学习:样本有标记,从数据中学习标记分界面,适用于预测数据标记
无监督学习:样本没有标记,从数据中学习模式,适用于描述数据
半监督学习:部分数据标记已知
强化学习:数据标记未知,但知道与输出目标相关的反馈,使用与决策类问题
(2)数据分布:参数模型、非参数模型
参数模型:对数据分布进行假设,待求解的数据模式/映射可以用一组有限且固定数目的参数进行刻画
非参数模型:不对数据分布进行假设,数据的所有统计特性都来源于数据本身
(3)建模对象:判别模型,生成模型
判别模型:直接学习P(Y|X)
生成模型:先从数据中学习联合概率,再利用贝叶斯公式
7、深度学习“不能”
(1)算法输出不稳定,容易被攻击
(2)模型复杂度高,难以纠错和调试
(3)模型层级复合程度高,参数不透明
(4)端对端训练方式对数据依赖性高,模型增量性强
(5)专注直观感知类问题,对开放性推理问题无能为力
(6)人类知识无法有效引入监督,机器偏见难以避免
二、神经网络基础
(一)浅层神经网络
1、激活函数
例如:S性函数、双极S性函数、ReLU修正线性单元、Leaky ReLU
2、
(1)单层感知器->多层感知器
(2)单隐层神经网络可视化
万有逼近定理:如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层 -输出)能以任意精度逼近任意预定的连续函数。
(3)双隐层感知器逼近非连续函数
3、神经网络每一层的作用
神经网络学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投影到线性可分的空间去分类/回归
增加节点数:增加维度,即增加线性转换能力
增加层数:增加激活函数的次数,即增加非线性转换次数
4、神经网络的参数学习:误差反向传播
(1)复合函数的链式求导
(2)三层前馈网络的BP算法
5、深层神经网络的问题:梯度消失
6、逐层预训练
三、问题
对最后的深层神经网络问题:梯度消失还是没有很理解
代码练习
一、pytorch基础练习
PyTorch是一个python库,它主要提供了两个高级功能:
- GPU加速的张量计算
- 构建在反向自动求导系统上的深度神经网络
1. 定义数据

2. 定义操作
凡是用Tensor进行各种运算的,都是Function
最终,还是需要用Tensor来进行计算的,计算无非是
- 基本运算,加减乘除,求幂求余
- 布尔运算,大于小于,最大最小
- 线性运算,矩阵乘法,求模,求行列式
基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等具体在使用的时候可以百度一下
布尔运算包括: gt/lt/ge/le/eq/ne,topk, sort, max/min
线性计算包括: trace, diag, mm/bmm,t,dot/cross,inverse,svd 等

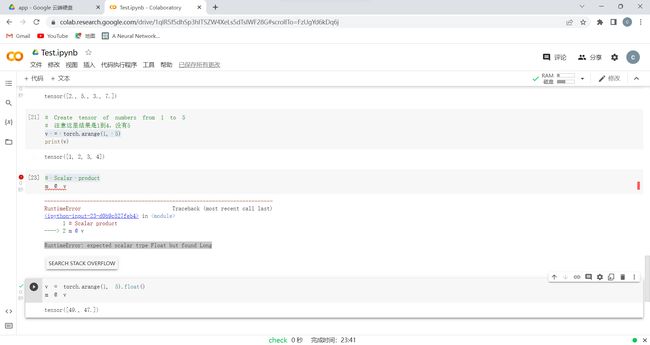
###这里按照给出的代码敲,却出错了,上网查询后发现tensor的默认类型是floattensor,需要进行类型转换



3、感悟体会
因为我学过python数值分析课程,对numpy,matplotlib库以及有了一定的了解,所以对于torch库下的各类方法掌握得比较快,加上上过人工智能先导,srdp也学过,总体掌握还是可以的hhh。
二、螺旋数据分类
Spiral classifciation
下载绘图函数到本地

引入基本的库,然后初始化重要参数

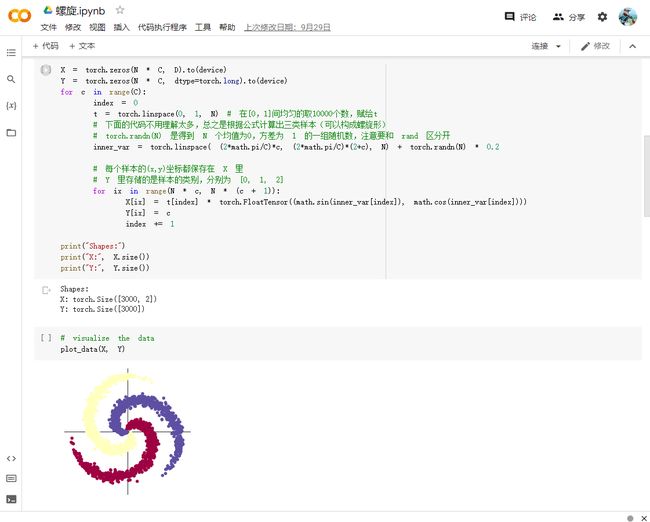
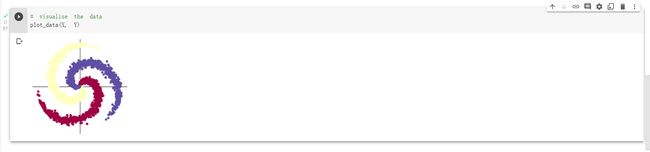
初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签。 结合代码可以看到,X的为一个 NxC 行, D 列的矩阵。C 类样本,每类样本是 N个,所以是 N*C 行。每个样本的特征维度是2,所以是 2列。
在 python 中,调用 zeros 类似的函数,第一个参数是 y方向的,即矩阵的行;第二个参数是 x方向的,即矩阵的列,大家得注意下,不要搞反了。下面结合代码看看 3000个样本的特征是如何初始化的。

1. 构建线性模型分类
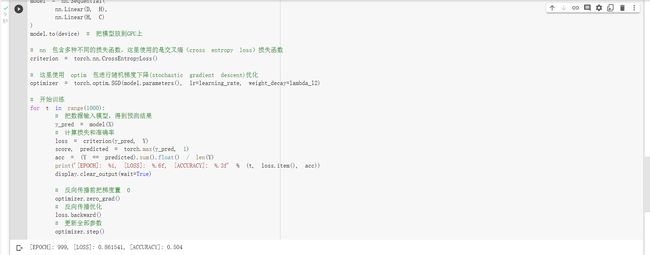
这里对上面的一些关键函数进行说明:
使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。
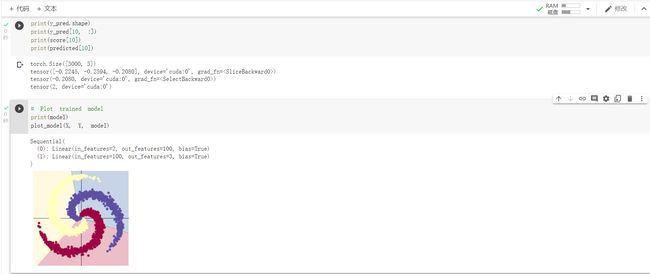
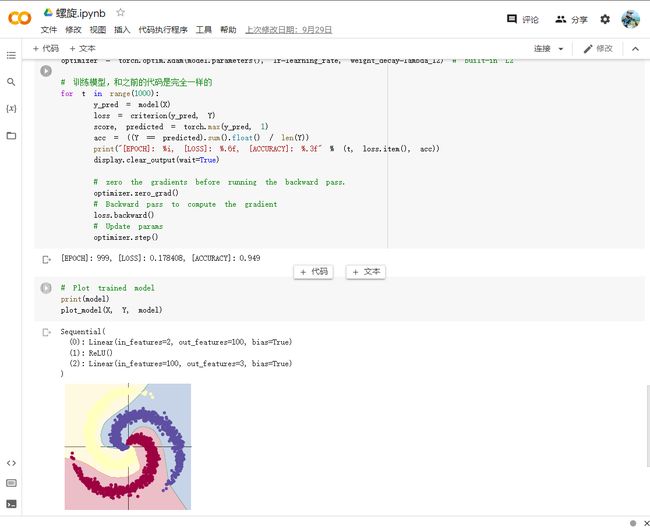
上面使用 print(model) 把模型输出,可以看到有两层:
- 第一层输入为 2(因为特征维度为主2),输出为 100;
- 第二层输入为 100 (上一层的输出),输出为 3(类别数)
从上面图示可以看出,线性模型的准确率最高只能达到 50% 左右,对于这样复杂的一个数据分布,线性模型难以实现准确分类。
2. 构建两层神经网络分类

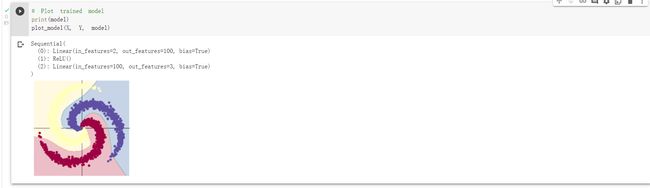
大家可以看到,在两层神经网络里加入 ReLU 激活函数以后,分类的准确率得到了显著提高。大家可以看到,在两层神经网络里加入 ReLU 激活函数以后,分类的准确率得到了显著提高。
问题:
对各类激励函数的实现方法还是没有很懂,希望老师上课讲一讲。
2022年秋季《软件工程》作业报告
| 姓名和学号? | 杨帅宇,20170001085 |
|---|---|
| 本实验属于哪门课程? | 中国海洋大学22秋《软件工程》 |
| 实验名称? | 第二次作业:深度学习和pytorch基础 |
一、视频学习心得及问题总结
中学时听闻李世石输给alphaGO时我其实并没有特别的惊讶,因为我并不理解这代表着什么,我以为这跟我拿着象棋软件打开最高难度赢了爷爷一样,只不过是电脑学会了更精妙的棋谱罢了。后来,随着我对数学和计算机的逐渐了解,我才意识到了这是一件多么伟大的事情:围棋与象棋的变式差异简直天壤之别,甚至在科幻小说中,围棋都被认为电脑绝对不可能战胜人类的(以前在《科幻世界》上看过一篇,机器下赢了许多人 ,最后老棋王出山才赢了机器,现在看来也是保守了)。
深度学习是一个从结果出发的方法,这跟人类一般处理事情的办法是相反的,我们在做事时,都会搞清楚每一步再去完成它,而深度学习则是在直到答案后,不断的往这个答案上靠近,有点像数学中的二分法,最终也无法得到一个准确的值,但却会非常的接近。这其中经过的计算便成了一个黑盒,使得我们无法了解它到底是怎么算的。
而计算机神经网络则是实现深度学习的算法,它设置了许多神经点,在给出问题和结果后不断地训练,得到正确答案会加强这条路径地权重,反之则减少,最后得到最合理的答案。但是神经网络也有问题,如果给的训练素材不够好,得到的结果也一定是“垃圾”结果,就比如谷歌机器人在网上学习后满口脏话、用白人训练的图像识别软件将黑人识别为大猩猩等。另一方面,如果训练的一部分出错,我们也难以找到错误的具体位置,毕竟这是一个黑盒。
二、代码练习
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nDicaIqw-1664631039276)(C:\Users\31833\Desktop\软工实验1\实验1-1\图3.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-96s25CeB-1664631039277)(C:\Users\31833\Desktop\软工实验1\实验1-1\图4.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3iyhp37S-1664631039277)(C:\Users\31833\Desktop\软工实验1\实验1-2\图5.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EwVyYJ3A-1664631039277)(C:\Users\31833\Desktop\软工实验1\实验1-2\图6.png)]
出现的问题:
这个答案上靠近,有点像数学中的二分法,最终也无法得到一个准确的值,但却会非常的接近。这其中经过的计算便成了一个黑盒,使得我们无法了解它到底是怎么算的。
而计算机神经网络则是实现深度学习的算法,它设置了许多神经点,在给出问题和结果后不断地训练,得到正确答案会加强这条路径地权重,反之则减少,最后得到最合理的答案。但是神经网络也有问题,如果给的训练素材不够好,得到的结果也一定是“垃圾”结果,就比如谷歌机器人在网上学习后满口脏话、用白人训练的图像识别软件将黑人识别为大猩猩等。另一方面,如果训练的一部分出错,我们也难以找到错误的具体位置,毕竟这是一个黑盒。
二、代码练习
[外链图片转存中…(img-nDicaIqw-1664631039276)]
[外链图片转存中…(img-96s25CeB-1664631039277)]
[外链图片转存中…(img-3iyhp37S-1664631039277)]
[外链图片转存中…(img-EwVyYJ3A-1664631039277)]
出现的问题:
实验1中有一步出现报错,原因是数据的类型不匹配,查询后得到解决方法,在赋值后面加一个类型转变的语句,把long型改为float型,这样在下一步的报错就消失了,不知道为什么制作教程的大佬没遇到这样的问题,是因为版本更新了吗?