Pytorch实现YOLOv3目标检测
本教程使用的代码需要运行在 Python 3.5 和 PyTorch 0.3 版本之上。
原文链接:
上文:https://www.jiqizhixin.com/articles/2018-04-23-3
下文:https://www.jiqizhixin.com/articles/042602
你可以在以下链接中找到所有代码:
https://github.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch
文章目录
- 一,YOLO工作原理
-
- 1,全卷积神经网络
- 2,输出
- 3, 锚点框
- 4, 预测
-
- 预测包括:
-
- 1.中心坐标 b x , b y b_x,b_y bx,by
- 2,边界框维度
- 3,目标置信度
- 4,类别置信度
- 5,多尺度预测
- 6,输出处理
- 二,创建YOLO网络层级 class Darknet
-
- 1,配置文件
- 三,实现网络的前向传播 forward
-
- 1,定义网络
- 2,实现网络的前向传播
- 3,变换输出
- 4,重新访问检测层
- 5,测试前向传播
- 6,预加载权重
- 四,目标置信度阈值和非极大值抑制
-
-
- 1,置信度阈值设置和非极大值抑制
- 2,目标置信度阈值
- 3,执行非极大值抑制
- 4,计算IOU
- 5,写出预测
-
- 五,设计输入和输出管道
-
-
- 1,创建命令行参数
- 2,加载网络
- 3,读取输入图像
- 4,创建batch
- 5,检测循环
- 6,在图像上输出边界框
- 7,在视频网络摄像头上检测
-
一,YOLO工作原理
1,全卷积神经网络
FCN 75个卷积层,跳过连接和上采样,不适用任何形式的池化,使用步幅为2的卷积层对特征图进行下采样。这有助于防止通常由池化导致的低级特征的丢失。
作为 FCN,YOLO 对于输入图像的大小并不敏感。然而,在实践中,我们可能想要持续不变的输入大小,这就涉及我们的训练问题,我们希望按批次处理图像(批量图像由 GPU 并行处理,这样可以提升速度),我们就需要固定所有图像的高度和宽度。这就需要将多个图像整合进一个大的批次(将许多 PyTorch 张量合并成一个)。
2,输出
输出是预测值,因为YOLO是解决的是回归问题,注意:YOLO 的的预测通过卷积层实现(是全卷积神经网络)核心尺寸为:s x s(B x(5+Class)) s为窗口个数,b为 anchor box个数,Class为类别个数。
我们对图像进行网格的划分,sx s,s怎么取值呢?YOLOv3的输入图像大小是416416,网络步幅是32,特征图的维度会是1313。所以将图像分为13x13个网格。预测过程如下所示:
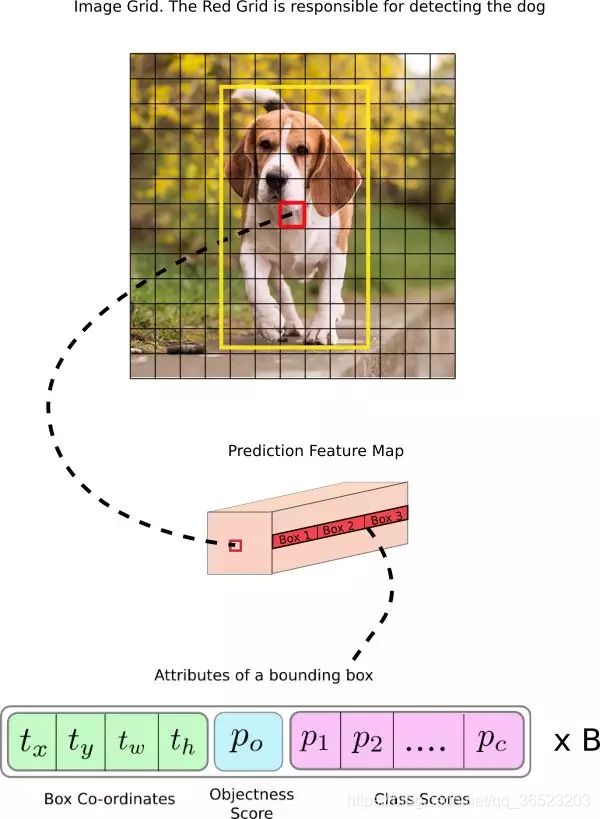
输入图像中红色框中包含了真值对象框中心的网格会作为负责预测对象的单元格。其中包含了黄色的真值框的中心。红色框被作为检测狗的单元,这个单元格可以预测三个边界框(Anchor),这三个的标签怎么分配呢?那个锚点的IOU最大,哪个框的置信度的标签为1,其他为0.
以上讨论的单元格是预测特征图上的单元格,我们将输入图像分割成网格后,确定预测特征图的哪个单元格负责预测对象。
3, 锚点框
预测边界框的宽度和高度看起来非常合理,但在实践中,训练会带来不稳定的梯度。所以,现在大部分目标检测器都是预测对数空间变换,或者预测与预训练默认边界框之前的偏移。
4, 预测
输出结果 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h ) (tx,ty,tw,th),转换得到预测到的边界框:
b x = s i g m o i d ( t x ) + c x b_x=sigmoid(t_x)+c_x bx=sigmoid(tx)+cx
b y = s i g m o i d ( t y ) + c y b_y=sigmoid(t_y)+c_y by=sigmoid(ty)+cy
b w = p w e t w b_w=p_we^{t_w} bw=pwetw
b h = p h e t h b_h=p_he{t_h} bh=pheth
预测包括:
1.中心坐标 b x , b y b_x,b_y bx,by
注意:我们使用sigmoid函数进行中心坐标预测,输出在0-1之间。原因如下:正常情况下不是预测中心坐标的确切坐标,而是预测:
1,与预测目标的网络单元左上角相关的偏移;
2,使用特征图单元的维度(1)进行归一化的偏移。
以我们的图像为例。如果中心的预测是 (0.4, 0.7),则中心在 13 x 13 特征图上的坐标是 (6.4, 6.7)(红色单元的左上角坐标是 (6,6))。
但是,如果预测到的 x,y 坐标大于 1,比如 (1.2, 0.7)。那么中心坐标是 (7.2, 6.7)。注意该中心在红色单元右侧的单元中,或第 7 行的第 8 个单元。这打破了 YOLO 背后的理论,因为如果我们假设红色框负责预测目标狗,那么狗的中心必须在红色单元中,不应该在它旁边的网格单元中。
因此,为了解决这个问题,我们对输出执行 sigmoid 函数,将输出压缩到区间 0 到 1 之间,有效确保中心处于执行预测的网格单元中。
2,边界框维度
得出的预测 b w b_w bw和 b h b_h bh使用图像的高宽进行归一化。即,如果包含目标的框的预测 b x b_x bx和 b y b_y by是(0.3,0.8),那么13x13特征图的实际宽高是(13x 0.3,13x0.8)
3,目标置信度
Object 分数表示目标在边界框内的概率。红色网格和相邻网格的 Object 分数应该接近 1,而角落处的网格的 Object 分数可能接近 0。
objectness 分数的计算也使用 sigmoid 函数,因此它可以被理解为概率。
4,类别置信度
检测到属于某个类别的概率。在v3之前,YOLO需要对类别分数执行softmax函数操作。V3舍弃了这种设计,作者选择使用sigmoid函数, 主要体现在可以实现多标签分类。出现类别女性和人,多标签更符合需求。
5,多尺度预测
分别在尺度13 x 13,26 x26,52 x52上执行检测。在每个尺度上,每个单元使用 3 个锚点预测 3 个边界框,锚点的总数为 9。v3中每个尺度上平均检测三个锚点。
这种方式可以帮助YOLOv3在检测较小目标时取得更好的性能,52X52的特征图上采样的感受野更小,所以有利于检测小目标。
6,输出处理
我们的输出预测的边界框有((52x52)+(26x26)+(13x13))x3=10647个边界框,但是图像中只有少数目标,将检测框减少至个数。
1,目标框置信度:将目标框置信度低于阈值的边界框过滤忽略。
2,非极大值抑制:解决同意图像目标多次检测问题,将最大阈值附近的框删除或降低置信度。
二,创建YOLO网络层级 class Darknet
代码说明:YOLO网络的创建在darknet.py文件中,同时补充了util.py文件,会包含多种需要调用的函数。会将所有这些文件保存在检测器文件下后,就能使用git追踪他们的改变。
1,配置文件
cfg文件描述了网络架构。和caffe中的prototxt文件类似。配置文件说明:
1.卷积层:
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
2.跳过连接
[shortcut]
from=-3
activation=linear
跳过连接与残差网络中使用的结构相似,参数 from 为-3 表示捷径层的输出会通过将之前层的和之前第三个层的输出的特征图与模块的输入相加而得出。
3.上采样
[upsample]
stride=2
通过参数 stride 在前面层级中双线性上采样特征图。
4.路由层
[route]
layers = -4
[route]
layers = -1,
参数Layer有一个或两个值。当只有一个值时,它输出这一层通过该值索引的特征图。在我们设置为-4,所以层级将输出路由层之前第四层的特征图。两个值的话是将该两层级间的特征图拼接。
5.YOLO
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80 类别
num=9 锚点框个数
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
YOLO 层级对应于上文所描述的检测层级。参数 anchors 定义了 9 组锚点,但是它们只是由 mask 标签使用的属性所索引的锚点。这里,mask 的值为 0、1、2 表示了第一个、第二个和第三个使用的锚点。而掩码表示检测层中的每一个单元预测三个框。总而言之,我们检测层的规模为 3,并装配总共 9 个锚点。
6,Net
[net]
#Testing
batch=1
subdivisions=1
#Training
#batch=64
#subdivisions=16
width= 320
height = 320
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
配置文件中存在另一种块 net,不过我不认为它是层,因为它只描述网络输入和训练参数的相关信息,并未用于 YOLO 的前向传播。但是,它为我们提供了网络输入大小等信息,可用于调整前向传播中的锚点。
7,解析配置文件,生成网络结构
通过对cfg文件的解析,生成对应的网络结构、anchor。
首先,我们定义了一个pares_cfg函数,该函数使用配置文件的路径作为输入。
def parse_cfg(cfgfile):
"""
Takes a configuration file
Returns a list of blocks. Each blocks describes a block in the neural
network to be built. Block is represented as a dictionary in the list
"""
file = open(cfgfile, 'r')
lines = file.read().split('\n') # store the lines in a list
lines = [x for x in lines if len(x) > 0] # get read of the empty lines
lines = [x for x in lines if x[0] != '#'] # get rid of comments
lines = [x.rstrip().lstrip() for x in lines] # get rid of fringe whitespaces
block = {}
blocks = []
for line in lines:
if line[0] == "[": # This marks the start of a new block
if len(block) != 0: # If block is not empty, implies it is storing values of previous block.
blocks.append(block) # add it the blocks list
block = {} # re-init the block
block["type"] = line[1:-1].rstrip()
else:
key,value = line.split("=")
block[key.rstrip()] = value.lstrip()
blocks.append(block)
return blocks
解析过程中,我们将这些词典(由代码中的变量 block 表示)添加到列表 blocks 中。我们的函数将返回该 block。
列表中有 5 种类型的层。PyTorch 为 convolutional 和 upsample 提供预置层。我们将通过扩展 nn.Module 类为其余层写自己的模块。
函数create_modules使用 parse_cfg 函数返回的 blocks 列表,同时使用变量 net_info,来存储该网络的信息。函数返回 return (net_info, module_list)。其中 nn.ModuleList。这个类几乎等同于一个包含 nn.Module 对象的普通列表。
然而,当添加 nn.ModuleList 作为 nn.Module 对象的一个成员时,所有 nn.ModuleList 内部的 nn.Module 对象(模块)的 parameter 也被添加作为 nn.Module 对象(即我们的网络,添加 nn.ModuleList 作为其成员)的 parameter。根据其中的参数定义网络块
nn.Sequential 类被用于按顺序地执行 nn.Module 对象的一个数字。得到add_module函数
下面我们定义一个卷积层和上采样层:
#首先 将卷积核的信息解析出来,包括卷积核大小,步长,padding等
if (x["type"] == "convolutional"):
#Get the info about the layer
activation = x["activation"]
try:
batch_normalize = int(x["batch_normalize"])
bias = False
except:
batch_normalize = 0
bias = True
filters= int(x["filters"])
padding = int(x["pad"])
kernel_size = int(x["size"])
stride = int(x["stride"])
if padding:
pad = (kernel_size - 1) // 2
else:
pad = 0
#定义并添加卷积层
conv=nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias = bias)#参数说明:prev_filters:输入维度,filters:输出维度,kernel_size:卷积核大小,stride:步长 ,pad:补0方式,dilation kernel间距
#添加
module.add_moudle("conv_{0}".format(),conv)
BN与激活,上采样
#Add the Batch Norm Layer
if batch_normalize:
bn = nn.BatchNorm2d(filters)#对卷积层输出进行归一化
module.add_module("batch_norm_{0}".format(index), bn)
#Check the activation.
#It is either Linear or a Leaky ReLU for YOLO
if activation == "leaky":
activn = nn.LeakyReLU(0.1, inplace = True)
module.add_module("leaky_{0}".format(index), activn)
#If it's an upsampling layer
#We use Bilinear2dUpsampling 线性插值采样
elif (x["type"] == "upsample"):
stride = int(x["stride"])
upsample = nn.Upsample(scale_factor = 2, mode = "bilinear")#上采样 参数说明:size :不同的输入类型指定的输出大小,scale_factor:指定输出为输入的倍数。out=in*scale_factor,mode:可使用上采样算法,align_corners:如果为True,输入的像素将与输出张量对齐
module.add_module("upsample_{}".format(index), upsample)
路由层(Router Layer)/捷径层(shortcut Layer)
#If it is a route layer
elif (x["type"] == "route"):
x["layers"] = x["layers"].split(',')
#Start of a route
start = int(x["layers"][0])
#end, if there exists one.
try:
end = int(x["layers"][1])
except:
end = 0
#Positive anotation
if start > 0:
start = start - index
if end > 0:
end = end - index
route = EmptyLayer()
module.add_module("route_{0}".format(index), route)
if end < 0:
filters = output_filters[index + start] + output_filters[index + end]
else:
filters= output_filters[index + start]
#shortcut corresponds to skip connection
elif x["type"] == "shortcut":
shortcut = EmptyLayer()
module.add_module("shortcut_{}".format(index), shortcut)
空的层的作用?
#定义如下
class EmptyLayer(nn.Module):
def __init__(self):
super(EmptyLayer, self).__init__()
1,拼接操作前初始化空的层,拼接操作的代码相当简单,torch.cat
在路由层之后的卷积层会把它的卷积核应用到之前层的特征图(可能是拼接的)上。
以下的代码更新了 filters 变量以保存路由层输出的卷积核数量。
if end < 0:
#If we are concatenating maps
filters = output_filters[index + start] + output_filters[index + end]
else:
filters= output_filters[index + start]
捷径层也使用空的层,因为它还要执行一个非常简单的操作(加)。没必要更新 filters 变量,因为它只是将前一层的特征图添加到后面的层上而已。
YOLO层
对[YOLO]进行解析,并定义一个新的层DetectionLayer,报存用于检测边界框的锚点。
检测层定义如下:
class DetectionLayer(nn.Module):
def __init__(self, anchors):
super(DetectionLayer, self).__init__()
self.anchors = anchors
#Yolo is the detection layer
elif x["type"] == "yolo":
mask = x["mask"].split(",")
mask = [int(x) for x in mask]
anchors = x["anchors"].split(",")
anchors = [int(a) for a in anchors]
anchors = [(anchors[i], anchors[i+1]) for i in range(0, len(anchors),2)]
anchors = [anchors[i] for i in mask]
detection = DetectionLayer(anchors)
module.add_module("Detection_{}".format(index), detection)
在这个回路结束时,我们做了一些统计。
module_list.append(module)
prev_filters = filters#输出矩阵成为下一层的输入
output_filters.append(filters)
结束了creat_modules函数后,获得包含net_info和module_list的元组。
测试代码
在 darknet.py 后通过输入以下命令行测试代码,运行文件。
blocks = parse_cfg("cfg/yolov3.cfg")
print(create_modules(blocks))
三,实现网络的前向传播 forward
1,定义网络
class Darknet(nn.Module):
def __init__(self, cfgfile):
super(Darknet, self).__init__()
self.blocks = parse_cfg(cfgfile)
self.net_info, self.module_list = create_modules(self.blocks)
这里,我们对 nn.Module 类别进行子分类,并将我们的类别命名为 Darknet。我们用 members、blocks、net_info 和 module_list 对网络进行初始化。
2,实现网络的前向传播
forward 主要有两个目的。一,计算输出;二,尽早处理的方式转换输出检测特征图。转换之后,这些不同尺度的检测图就能够串联,不然会因为不同维度不可能实现串联 。
def forward(self, x, CUDA):
modules = self.blocks[1:]
outputs = {} #We cache the outputs for the route layer
这里我们迭代使用self.block[1:] 而不是 self.blocks,因为 self.blocks的第一个元素是net块,它不参与前向传播。
1,首先获得模块的类型 module_type
if module_type == "convolutional" or module_type == "upsample":
x = self.module_list[i](x)
卷积层和上采样层
如果该模块是一个卷积层或上采样层,那么前向传播应该按如下方式工作:
if module_type == "convolutional" or module_type == "upsample":
x = self.module_list[i](x)#卷积或采样后得到输出
路由层/捷径层
路由层将特征图沿深度级联起来,torch.cat参数设为1。在Pytorch中,卷积层的输出输入的格式为(B *C *H *W),代码如下所示
elif module_type == "route":
layers = module["layers"]
layers = [int(a) for a in layers]
if (layers[0]) > 0:
layers[0] = layers[0] - i
if len(layers) == 1:
x = outputs[i + (layers[0])]
else:
if (layers[1]) > 0:
layers[1] = layers[1] - i
map1 = outputs[i + layers[0]]
map2 = outputs[i + layers[1]]
x = torch.cat((map1, map2), 1)#沿深度进行合并
elif module_type == "shortcut":
from_ = int(module["from"])
x = outputs[i-1] + outputs[i+from_]
YOLO检测层
YOLO 的输出是一个卷积特征图,包含沿特征图深度的边界框属性。边界框属性由彼此堆叠的单元格预测得出。因此,如果你需要在 (5,6) 处访问单元格的第二个边框,那么你需要通过 map[5,6, (5+C): 2*(5+C)] 将其编入索引。这种格式对于输出处理过程(例如通过目标置信度进行阈值处理、添加对中心的网格偏移、应用锚点等)很不方便。
另一个问题是由于检测是在三个尺度上进行的,预测图的维度将是不同的。虽然三个特征图的维度不同,但对它们执行的输出处理过程是相似的。如果能在单个张量而不是三个单独张量上执行这些运算,就太好了。
3,变换输出
为了解决这些问题,我们引入了函数 predict_transform。变换输出:将预测输出的值转换程出入图像符合的数据,在输入图像中标出检测的目标。
predict_transform 使用 5 个参数:prediction(我们的输出)、inp_dim(输入图像的维度)、anchors(锚点框)、num_classes(种类数量 )、CUDA flag(可选)。

每个网格(比如(0,0))对应三个检测输出向量,变换所需代码入下:
batch_size = prediction.size(0)
stride = inp_dim // prediction.size(2)
grid_size = inp_dim // stride
bbox_attrs = 5 + num_classes
num_anchors = len(anchors)
prediction = prediction.view(batch_size, bbox_attrs*num_anchors, grid_size*grid_size)
prediction = prediction.transpose(1,2).contiguous()
prediction = prediction.view(batch_size, grid_size*grid_size*num_anchors, bbox_attrs)
根据检测特征图的步幅分割锚点。
anchors = [(a[0]/stride, a[1]/stride) for a in anchors]
需要根据第一部分讨论的公式,将输出变换。
1,对(x,y)坐标和目标分数执行Sigmoid操作。
#Sigmoid the centre_X, centre_Y. and object confidencce
prediction[:,:,0] = torch.sigmoid(prediction[:,:,0])
prediction[:,:,1] = torch.sigmoid(prediction[:,:,1])
prediction[:,:,4] = torch.sigmoid(prediction[:,:,4])
#2,3是偏移
2,将网格偏移添加到中心坐标预测中:
#Add the center offsets
grid = np.arange(grid_size)
a,b = np.meshgrid(grid, grid)
x_offset = torch.FloatTensor(a).view(-1,1)
y_offset = torch.FloatTensor(b).view(-1,1)
if CUDA:
x_offset = x_offset.cuda()
y_offset = y_offset.cuda()
x_y_offset = torch.cat((x_offset, y_offset), 1).repeat(1,num_anchors).view(-1,2).unsqueeze(0)
prediction[:,:,:2] += x_y_offset
3,将锚点应用到边界框维度中:
#log space transform height and the width
anchors = torch.FloatTensor(anchors)
if CUDA:
anchors = anchors.cuda()
anchors = anchors.repeat(grid_size*grid_size, 1).unsqueeze(0)
prediction[:,:,2:4] = torch.exp(prediction[:,:,2:4])*anchors
4,对类别置信度使用Sigmoid函数
prediction[:,:,5: 5 + num_classes] = torch.sigmoid((prediction[:,:, 5 : 5 + num_classes]))
5,最后将检测图的大小调整与输入图像大小一致。边界框属性根据特征图的大小而定(比如 13*13).如果输入图像大小是 416 x 416,那么我们将属性乘 32,或乘 stride 变量。
prediction[:,:,:4] *= stride
#最后返回结果
return prediction
4,重新访问检测层
不同尺寸的特征图无法级联,我们将输出张量把边界框呈现为行,级联就比较可行了。
在forward函数定义:
elif module_type == 'yolo':
anchors = self.module_list[i][0].anchors
#Get the input dimensions
inp_dim = int (self.net_info["height"])
#Get the number of classes
num_classes = int (module["classes"])
#Transform
x = x.data
x = predict_transform(x, inp_dim, anchors, num_classes, CUDA)
if not write: #if no collector has been intialised.
detections = x
write = 1
else:
detections = torch.cat((detections, x), 1)
outputs[i] = x
返回结果:
return detections
5,测试前向传播
将一张图作为测试数据,输入,得到对应的输出:
下载图像:https://github.com/ayooshkathuria/pytorch-yolo-v3/raw/master/dog-cycle-car.png
定义函数
def get_test_input():
img = cv2.imread("dog-cycle-car.png")
img = cv2.resize(img, (416,416)) #Resize to the input dimension
img_ = img[:,:,::-1].transpose((2,0,1)) # BGR -> RGB | H X W C -> C X H X W
img_ = img_[np.newaxis,:,:,:]/255.0 #Add a channel at 0 (for batch) | Normalise
img_ = torch.from_numpy(img_).float() #Convert to float
img_ = Variable(img_) # Convert to Variable
return img_
#测试
model = Darknet("cfg/yolov3.cfg")
inp = get_test_input()
pred = model(inp)
print (pred)
会得到如下输出:
( 0 ,.,.) =
16.0962 17.0541 91.5104 ... 0.4336 0.4692 0.5279
15.1363 15.2568 166.0840 ... 0.5561 0.5414 0.5318
14.4763 18.5405 409.4371 ... 0.5908 0.5353 0.4979
⋱ ...
411.2625 412.0660 9.0127 ... 0.5054 0.4662 0.5043
412.1762 412.4936 16.0449 ... 0.4815 0.4979 0.4582
412.1629 411.4338 34.9027 ... 0.4306 0.5462 0.4138
[torch.FloatTensor of size 1x10647x85]
形状为 110064785 ,85=(5+c)
6,预加载权重
1,下载预训练权重
wget https://pjreddie.com/media/files/yolov3.weights
2,理解权重文件
首先权重属于两种层: 归一化层和卷积层。这些层的权重储存顺序和配置文件中定义层级的顺序完全相同。所以,,如果一个 convolutional 后面跟随着 shortcut 块,而 shortcut 连接了另一个 convolutional 块,则你会期望文件包含了先前 convolutional 块的权重,其后则是后者的权重。
权重的存储方式,卷积层也分没有BN层和右BN层的区别
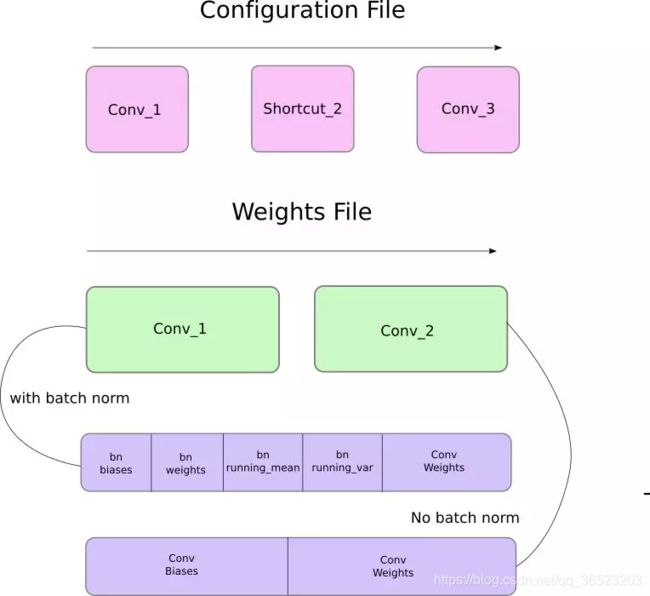
加载权重:函数 load_weights:
def load_weights(self, weightfile):
#Open the weights file
fp = open(weightfile, "rb")
#The first 5 values are header information
# 1. Major version number
# 2. Minor Version Number
# 3. Subversion number
# 4,5. Images seen by the network (during training)
header = np.fromfile(fp, dtype = np.int32, count = 5)
self.header = torch.from_numpy(header)
self.seen = self.header[3]
#第一个160比特的权重文件保存了5个int32值,他们构成了文件的标头
#之后的比特代表权重,按上述顺利排列。权重被保存为float32或32位浮点数。我们来加载np.ndarray中的剩余权重。
weights = np.fromfile(fp, dtype = np.float32)
ptr = 0
#现在,我们迭代的加载权重文件到网络的模块上。
for i in range(len(self.module_list)):
module_type = self.blocks[i + 1]["type"]
#If module_type is convolutional load weights
#Otherwise ignore.
if module_type == "convolutional":#卷积神经网络
model = self.module_list[i]
try:
batch_normalize = int(self.blocks[i+1]["batch_normalize"])
except:
batch_normalize = 0
conv = model[0]
#查看是否有bn层,如果有,按照以下方式加载权重
if (batch_normalize):
bn = model[1]
#Get the number of weights of Batch Norm Layer
num_bn_biases = bn.bias.numel()
#Load the weights
bn_biases = torch.from_numpy(weights[ptr:ptr + num_bn_biases])
ptr += num_bn_biases
bn_weights = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_mean = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
bn_running_var = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
ptr += num_bn_biases
#Cast the loaded weights into dims of model weights.
bn_biases = bn_biases.view_as(bn.bias.data)
bn_weights = bn_weights.view_as(bn.weight.data)
bn_running_mean = bn_running_mean.view_as(bn.running_mean)
bn_running_var = bn_running_var.view_as(bn.running_var)
#Copy the data to model
bn.bias.data.copy_(bn_biases)
bn.weight.data.copy_(bn_weights)
bn.running_mean.copy_(bn_running_mean)
bn.running_var.copy_(bn_running_var)
else:#没有bn层的卷积层
#Number of biases
num_biases = conv.bias.numel()
#Load the weights
conv_biases = torch.from_numpy(weights[ptr: ptr + num_biases])
ptr = ptr + num_biases
#reshape the loaded weights according to the dims of the model weights
conv_biases = conv_biases.view_as(conv.bias.data)
#Finally copy the data
conv.bias.data.copy_(conv_biases)
#Let us load the weights for the Convolutional layers
#最后,我们加载卷积层的权重
num_weights = conv.weight.numel()
#Do the same as above for weights
conv_weights = torch.from_numpy(weights[ptr:ptr+num_weights])
ptr = ptr + num_weights
conv_weights = conv_weights.view_as(conv.weight.data)
conv.weight.data.copy_(conv_weights)
通过以上函数加载DarkNet对象中的权重
model = Darknet("cfg/yolov3.cfg")
model.load_weights("yolov3.weights")
通过模型构建和权重加载,我们终于可以开始进行目标检测了。未来,我们还将介绍如何利用 objectness 置信度阈值和非极大值抑制生成最终的检测结果。
四,目标置信度阈值和非极大值抑制
1,置信度阈值设置和非极大值抑制
我们必须使我们的输出满足 objectness 分数阈值和非极大值抑制(NMS),以得到后文所说的「真实(true)」检测结果。这里在util.py文件创建名为write_results函数。
def write_results(prediction, confidence, num_classes, nms_conf = 0.4):
#函数的输入为预测结果,置信度(目标分数阈值)、num_classes为类别数,nms_conf(非极大值抑制 IOU阈值)
2,目标置信度阈值
我们的预测张量包含有关 B x 10647 边界框的信息。对于有低于一个阈值的 objectness 分数的每个边界框,我们将其每个属性的值(表示该边界框的一整行)都设为零。
conf_mask = (prediction[:,:,4] > confidence).float().unsqueeze(2)
prediction = prediction*conf_mask
3,执行非极大值抑制
我假设你已经理解 IoU(Intersection over union)和非极大值抑制(Non-maximum suppression)的含义了。如果你还不理解,请参阅文末提供的链接。
已经知道边界框的中心坐标以及边界框的高度和宽度决定的。但是,使用每个框的两个对角坐标能更轻松的计算两个框的IoU.所以将我们的框的(中心x,y 高度,亮度)属性转换成(左上角x,y右下角x,y)
box_corner = prediction.new(prediction.shape)
box_corner[:,:,0] = (prediction[:,:,0] - prediction[:,:,2]/2)
box_corner[:,:,1] = (prediction[:,:,1] - prediction[:,:,3]/2)
box_corner[:,:,2] = (prediction[:,:,0] + prediction[:,:,2]/2)
box_corner[:,:,3] = (prediction[:,:,1] + prediction[:,:,3]/2)
prediction[:,:,:4] = box_corner[:,:,:4]
每张图像中的真实检测结果的数量可能存在差异。比如,一个大小的3的batch中有1,2,3这3张图像,它们各自有 5、2、4 个「真实」检测结果。因此,一次只能完成一张图像的置信度阈值设置和 NMS。也就是说,我们不能将所涉及的操作向量化,而且必须在预测的第一个维度(包含一个 batch 中图像的索引)上循环。
batch_size = prediction.size(0)
write = False
for ind in range(batch_size):
image_pred = prediction[ind] #image Tensor
#confidence threshholding
#NMS
进入循环后,我们清楚的说明下。每个边界框都有85个属性,其中80个分数。此时,我们只关心走最大值的类别分数。增加最大值的索引,以及那一类别的类别数的分数。
max_conf, max_conf_score = torch.max(image_pred[:,5:5+ num_classes], 1)
max_conf = max_conf.float().unsqueeze(1)
max_conf_score = max_conf_score.float().unsqueeze(1)
seq = (image_pred[:,:5], max_conf, max_conf_score)
image_pred = torch.cat(seq, 1)
再将置信度小于阈值的设为0的边界框删除:
non_zero_ind = (torch.nonzero(image_pred[:,4]))
try:
image_pred_ = image_pred[non_zero_ind.squeeze(),:].view(-1,7)
except:
continue
#For PyTorch 0.4 compatibility
#Since the above code with not raise exception for no detection
#as scalars are supported in PyTorch 0.4
if image_pred_.shape[0] == 0:
continue
获取一张图像中所检测到的类别。
#Get the various classes detected in the image
img_classes = unique(image_pred_[:,-1]) # -1 index holds the class index
定义函数unique的函数来获取任意给定图像中存在的类别,然后执行非极大值抑制NMS
def unique(tensor):
tensor_np = tensor.cpu().numpy()
unique_np = np.unique(tensor_np)
unique_tensor = torch.from_numpy(unique_np)
tensor_res = tensor.new(unique_tensor.shape)#开辟新空间
tensor_res.copy_(unique_tensor)
return tensor_res
#执行极大值抑制,按照类别执行NMS
for cls in img_classes:
#perform NMS
#get the detections with one particular class
cls_mask = image_pred_*(image_pred_[:,-1] == cls).float().unsqueeze(1)
class_mask_ind = torch.nonzero(cls_mask[:,-2]).squeeze()
image_pred_class = image_pred_[class_mask_ind].view(-1,7)
#sort the detections such that the entry with the maximum objectness
#confidence is at the top
conf_sort_index = torch.sort(image_pred_class[:,4], descending = True )[1]
image_pred_class = image_pred_class[conf_sort_index]
idx = image_pred_class.size(0) #Number of detections
#执行NMS
for i in range(idx):
#Get the IOUs of all boxes that come after the one we are looking at
#in the loop
try:
ious = bbox_iou(image_pred_class[i].unsqueeze(0), image_pred_class[i+1:])
except ValueError:
break
except IndexError:
break
#Zero out all the detections that have IoU > treshhold
iou_mask = (ious < nms_conf).float().unsqueeze(1)
image_pred_class[i+1:] *= iou_mask
#Remove the non-zero entries
non_zero_ind = torch.nonzero(image_pred_class[:,4]).squeeze()
image_pred_class = image_pred_class[non_zero_ind].view(-1,7)
batch_ind = image_pred_class.new(image_pred_class.size(0), 1).fill_(ind) #Repeat the batch_id for as many detections of the class cls in the image
seq = batch_ind, image_pred_class
这里,我们使用函数bbox_iou。执行非极大值抑制,第一个输入是边界框行,这是由循环中的变量 i 索引的。bbox_iou 的第二个输入是多个边界框行构成的张量。
bbox_iou 函数的输出是一个张量,其中包含通过第一个输入代表的边界框与第二个输入中的每个边界框的 IoU。
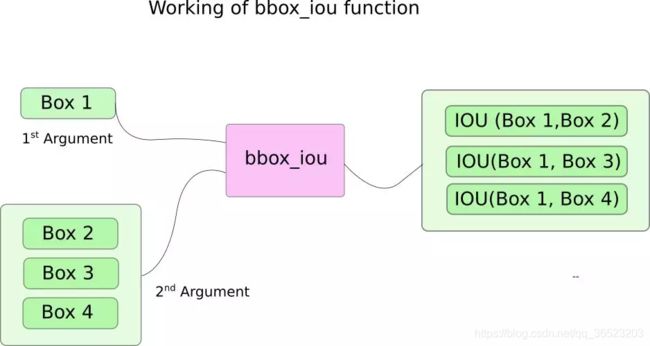
Box1为该类别置信度最大的边界框。如果我们有2个同样类别的边界框且它们的IOU大于一个阈值,那么就去掉其中类别置信度较低的那个。我们已经对边界框进行了排序,其中有更高置信度的在上面。
4,计算IOU
bbox_iou函数
def bbox_iou(box1, box2):
"""
Returns the IoU of two bounding boxes
"""
#Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:,0], box1[:,1], box1[:,2], box1[:,3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:,0], box2[:,1], box2[:,2], box2[:,3]
#get the corrdinates of the intersection rectangle
inter_rect_x1 = torch.max(b1_x1, b2_x1)
inter_rect_y1 = torch.max(b1_y1, b2_y1)
inter_rect_x2 = torch.min(b1_x2, b2_x2)
inter_rect_y2 = torch.min(b1_y2, b2_y2)
#Intersection area
inter_area = (inter_rect_x2 - inter_rect_x1 + 1)*(inter_rect_y2 - inter_rect_y1 + 1)
#Union Area
b1_area = (b1_x2 - b1_x1 + 1)*(b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1)*(b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area)(a and b /(a+b-(a and b)))
return iou
5,写出预测
write_results 函数输出一个形状为 Dx8 的张量output;其中 D 是所有图像中的「真实」检测结果,每个都用一行表示。每一个检测结果都有 8 个属性,即:该检测结果所属的 batch 中图像的索引、4 个角的坐标、objectness 分数、有最大置信度的类别的分数、该类别的索引。后面也是根据这些信息将检测结果画出来。
我们没有初始化输出的结果,除非有检测结果要保存,一旦被初始化,后面的检测结果将与之连接。函数中使用write标签来表示张量是否初始化了,在类别的迭代的循环结束时,我们将所有的检测结果输出。
batch_ind = image_pred_class.new(image_pred_class.size(0), 1).fill_(ind)
#Repeat the batch_id for as many detections of the class cls in the image
seq = batch_ind, image_pred_class
if not write:
output = torch.cat(seq,1)#第一个结果进行初始化
write = True
else:
out = torch.cat(seq,1)
output = torch.cat((output,out))#后面的和前面的结果进行连接起来
五,设计输入和输出管道
在这一部分,我们将为我们的检测器构建输入和输出流程。这涉及到从磁盘读取图像,做出预测,使用预测结果在图像上绘制边界框,然后将它们保存到磁盘上。我们也会介绍如何让检测器在相机馈送或视频上实时工作。
在我们的检测器文件中创建一个 detector.py 文件,在上面导入必要的库。该文件实现单张图像的目标检测。vedio.py实现对视频的检测和检测结果输出。
1,创建命令行参数
def arg_parse():
"""
Parse arguements to the detect module
"""
parser = argparse.ArgumentParser(description='YOLO v3 Detection Module')
parser.add_argument("--images", dest = 'images', help =
"Image / Directory containing images to perform detection upon",
default = "imgs", type = str)
parser.add_argument("--det", dest = 'det', help =
"Image / Directory to store detections to",
default = "det", type = str)
parser.add_argument("--bs", dest = "bs", help = "Batch size", default = 1)
parser.add_argument("--confidence", dest = "confidence", help = "Object Confidence to filter predictions", default = 0.5)
parser.add_argument("--nms_thresh", dest = "nms_thresh", help = "NMS Threshhold", default = 0.4)
parser.add_argument("--cfg", dest = 'cfgfile', help =
"Config file",
default = "cfg/yolov3.cfg", type = str)
parser.add_argument("--weights", dest = 'weightsfile', help =
"weightsfile",
default = "yolov3.weights", type = str)
parser.add_argument("--reso", dest = 'reso', help =
"Input resolution of the network. Increase to increase accuracy. Decrease to increase speed",
default = "416", type = str)
return parser.parse_args()
args = arg_parse()
images = args.images
batch_size = int(args.bs)
confidence = float(args.confidence)
nms_thesh = float(args.nms_thresh)
start = 0
CUDA = torch.cuda.is_available()
其中重要的标签包括images指定输入图像或图像目录),det(保存检测结果的目录)reso(输入图像的分辨率,可用于在速度与精度间的权衡),cfg(替代配置文件)和weightfile(预训练权重)
2,加载网络
类别名
文件coco.names保存类别名
将类别文件加载到程序中。
num_classes = 80 #For COCO
classes = load_classes("data/coco.names")
def load_classes(namesfile):
fp = open(namesfile, "r")
names = fp.read().split("\n")[:-1]
return names
初始化网络并载入权重
#Set up the neural network
print("Loading network.....")
model = Darknet(args.cfgfile)
model.load_weights(args.weightsfile)#载入权重
print("Network successfully loaded")
model.net_info["height"] = args.reso
inp_dim = int(model.net_info["height"])
assert inp_dim % 32 == 0
assert inp_dim > 32
#If there's a GPU availible, put the model on GPU
if CUDA:
model.cuda()
#Set the model in evaluation mode
model.eval()
3,读取输入图像
从磁盘读取图像或从目录读取多张图像。图像的路径存储在一个名为 imlist 的列表中。
read_dir = time.time()
#Detection phase
try:
imlist = [osp.join(osp.realpath('.'), images, img) for img in os.listdir(images)]
except NotADirectoryError:
imlist = []
imlist.append(osp.join(osp.realpath('.'), images))
except FileNotFoundError:
print ("No file or directory with the name {}".format(images))
exit()
如果保存检测结果的目录(由det标签定义)不存在,就创建一个。
if not os.path.exists(args.det):
os.makedirs(args.det)
使用opencv加载图像,通道是BGR PyTorch 的图像输入格式是(batch x 通道 x 高度 x 宽度),因此,我们在 util.py 中写了一个函数 prep_image 来将 numpy 数组转换成 PyTorch 的输入格式。
load_batch = time.time()
loaded_ims = [cv2.imread(x) for x in imlist]
def prep_image(img, inp_dim):
"""
Prepare image for inputting to the neural network.
Returns a Variable
"""
img = cv2.resize(img, (inp_dim, inp_dim))#将输入图像resize到标准大小
img = img[:,:,::-1].transpose((2,0,1)).copy()#图像转换成RGB
img = torch.from_numpy(img).float().div(255.0).unsqueeze(0)
return img
除了转换后的图像,我们也将维护一个原始图像的列表,以及一个包含原始图像的维度的列表im_dim_list。
#PyTorch Variables for images
im_batches = list(map(prep_image, loaded_ims, [inp_dim for x in range(len(imlist))]))
#List containing dimensions of original images
im_dim_list = [(x.shape[1], x.shape[0]) for x in loaded_ims]
im_dim_list = torch.FloatTensor(im_dim_list).repeat(1,2)
if CUDA:
im_dim_list = im_dim_list.cuda()
4,创建batch
将图像数据分batch_size带下进行存储。
leftover = 0
if (len(im_dim_list) % batch_size):
leftover = 1
if batch_size != 1:
num_batches = len(imlist) // batch_size + leftover
im_batches = [torch.cat((im_batches[i*batch_size : min((i + 1)*batch_size,
len(im_batches))])) for i in range(num_batches)]
5,检测循环
在batch上迭代,生成预测结果。将执行检测到的所有图像的预测张量(形状为DX8)连接起来。等待所有的batch检测结束输出。
对于每个 batch,我们都会测量检测所用的时间,即测量获取输入到 write_results 函数得到输出之间所用的时间。在 write_prediction 返回的输出中,其中一个属性是 batch 中图像的索引。我们对这个特定属性执行转换,使其现在能代表 imlist 中图像的索引,该列表包含了所有图像的地址。
在那之后,我们 print 每个检测结果所用的时间以及每张图像中检测到的目标。
如果 write_results 函数在 batch 上的输出是一个 int 值(0),也就是说没有检测结果,那么我们就继续跳过循环的其余部分。
write = 0
start_det_loop = time.time()
for i, batch in enumerate(im_batches):
#load the image
start = time.time()
if CUDA:
batch = batch.cuda()
prediction = model(Variable(batch, volatile = True), CUDA)
prediction = write_results(prediction, confidence, num_classes, nms_conf = nms_thesh)
end = time.time()
if type(prediction) == int:
for im_num, image in enumerate(imlist[i*batch_size: min((i + 1)*batch_size, len(imlist))]):
im_id = i*batch_size + im_num
print("{0:20s} predicted in {1:6.3f} seconds".format(image.split("/")[-1], (end - start)/batch_size))
print("{0:20s} {1:s}".format("Objects Detected:", ""))
print("----------------------------------------------------------")
continue
prediction[:,0] += i*batch_size #transform the atribute from index in batch to index in imlist
if not write: #If we have't initialised output
output = prediction
write = 1
else:
output = torch.cat((output,prediction))
for im_num, image in enumerate(imlist[i*batch_size: min((i + 1)*batch_size, len(imlist))]):
im_id = i*batch_size + im_num
objs = [classes[int(x[-1])] for x in output if int(x[0]) == im_id]
print("{0:20s} predicted in {1:6.3f} seconds".format(image.split("/")[-1], (end - start)/batch_size))
print("{0:20s} {1:s}".format("Objects Detected:", " ".join(objs)))
print("----------------------------------------------------------")
if CUDA:
torch.cuda.synchronize()
6,在图像上输出边界框
先检查下有没有预测输出,没有直接结束程序。
try:
output
except NameError:
print ("No detections were made")
exit()
测试
在终端上运行:
python detect.py --images dog-cycle-car.png --det det
会在终端显示运行结果
Loading network.....
Network successfully loaded
dog-cycle-car.png predicted in 2.456 seconds
Objects Detected: bicycle truck dog
----------------------------------------------------------
SUMMARY
----------------------------------------------------------
Task : Time Taken (in seconds)
Reading addresses : 0.002
Loading batch : 0.120
Detection (1 images) : 2.457
Output Processing : 0.002
Drawing Boxes : 0.076
Average time_per_img : 2.657
----------------------------------------------------------
在det目录中保存的一张名为 det_dog-cycle-car.png 的图像:

7,在视频网络摄像头上检测
要在视频或网络摄像头上运行这个检测器,代码基本可以保持不变,只是我们不会在 batch 上迭代,而是在视频的帧上迭代。
在视频上运行该检测器的代码可以在我们的 GitHub 中的 video.py 文件中找到。这个代码非常类似 detect.py 的代码,只有几处不太一样.
1,数据读取
视频帧的读取
videofile = "video.avi" #or path to the video file.
cap = cv2.VideoCapture(videofile)
#cap = cv2.VideoCapture(0) for webcam
assert cap.isOpened(), 'Cannot capture source'
frames = 0
2,我们以在图像上类似的迭代方式在帧上迭代
因为我们不必再处理 batch,而是一次只处理一张图像,所以很多地方的代码都进行了简化。因为一次只处理一帧。这包括使用一个元组替代 im_dim_list 的张量,然后对 write 函数进行一点小修改。
每次迭代,我们都会跟踪名为 frames 的变量中帧的数量。然后我们用这个数字除以自第一帧以来过去的时间,得到视频的帧率。
我们不再使用 cv2.imwrite 将检测结果图像写入磁盘,而是使用 cv2.imshow 展示画有边界框的帧。如果用户按 Q 按钮,就会让代码中断循环,并且视频终止
frames = 0
start = time.time()
while cap.isOpened():
ret, frame = cap.read()
if ret:
img = prep_image(frame, inp_dim)
# cv2.imshow("a", frame)
im_dim = frame.shape[1], frame.shape[0]
im_dim = torch.FloatTensor(im_dim).repeat(1,2)
if CUDA:
im_dim = im_dim.cuda()
img = img.cuda()
output = model(Variable(img, volatile = True), CUDA)
output = write_results(output, confidence, num_classes, nms_conf = nms_thesh)
if type(output) == int:
frames += 1
print("FPS of the video is {:5.4f}".format( frames / (time.time() - start)))
cv2.imshow("frame", frame)
key = cv2.waitKey(1)
if key & 0xFF == ord('q'):
break
continue
output[:,1:5] = torch.clamp(output[:,1:5], 0.0, float(inp_dim))
im_dim = im_dim.repeat(output.size(0), 1)/inp_dim
output[:,1:5] *= im_dim
classes = load_classes('data/coco.names')
colors = pkl.load(open("pallete", "rb"))
list(map(lambda x: write(x, frame), output))
cv2.imshow("frame", frame)
key = cv2.waitKey(1)
if key & 0xFF == ord('q'):
break
frames += 1
print(time.time() - start)
print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
else:
break