Pytorch加载模型model.load_state_dict()问题,Unexpected key(s) in state_dict
希望将训练好的模型加载到新的网络上。如上面题目所描述的,PyTorch在加载之前保存的模型参数的时候,遇到了问题。
版权声明:本文为CSDN博主「是否龙磊磊真的一无所有」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_32998593/article/details/89343507
Unexpected key(s) in state_dict: "module.features. ...".,Expected ".features....". 直接原因是key值名字不对应。
表明了加载过程中,期望获得的key值为feature...,而不是module.features....。这是由模型保存过程中导致的,模型应该是在DataParallel模式下面,也就是采用了多GPU训练模型,然后直接保存的。
You probably saved the model using nn.DataParallel, which stores the model in module, and now you are trying to load it without . You can either add a nn.DataParallel temporarily in your network for loading purposes, or you can load the weights file, create a new ordered dict without the module prefix, and load it back.
解决上面的问题有三个办法:
1. 对load的模型创建新的字典,去掉不需要的key值"module".
-
# original saved file with DataParallel
-
state_dict = torch.load(
'checkpoint.pt')
# 模型可以保存为pth文件,也可以为pt文件。
-
# create new OrderedDict that does not contain `module.`
-
from collections
import OrderedDict
-
new_state_dict = OrderedDict()
-
for k, v
in state_dict.items():
-
name = k[
7:]
# remove `module.`,表面从第7个key值字符取到最后一个字符,正好去掉了module.
-
new_state_dict[name] = v
#新字典的key值对应的value为一一对应的值。
-
# load params
-
model.load_state_dict(new_state_dict)
# 从新加载这个模型。
2. 直接用空白''代替'module.'
-
model.load_state_dict({k.replace(
'module.',
''):v
for k,v
in torch.load(
'checkpoint.pt').items()})
-
-
# 相当于用''代替'module.'。
-
#直接使得需要的键名等于期望的键名。
3. 最简单的方法,加载模型之后,接着将模型DataParallel,此时就可以load_state_dict。
如果有多个GPU,将模型并行化,用DataParallel来操作。这个过程会将key值加一个"module. ***"。
-
model = VGG()
# 实例化自己的模型;
-
checkpoint = torch.load(
'checkpoint.pt', map_location=
'cpu')
# 加载模型文件,pt, pth 文件都可以;
-
if torch.cuda.device_count() >
1:
-
# 如果有多个GPU,将模型并行化,用DataParallel来操作。这个过程会将key值加一个"module. ***"。
-
model = nn.DataParallel(model)
-
model.load_state_dict(checkpoint)
# 接着就可以将模型参数load进模型。
4. 总结
从出错显示的问题就可以看出,key值不匹配,因此可以选择多种方法,将模型参数加载进去。 这个方法通常会在load_state_dict过程中遇到。将训练好的一个网络参数,移植到另外一个网络上面,继续训练。或者将训练好的网络checkpoint加载进模型,再次进行训练。可以打印出model state_dict来看出两者的差别。
-
model = VGGNet()
-
params=model.state_dict()
#获得模型的原始状态以及参数。
-
for k,v
in params.items():
-
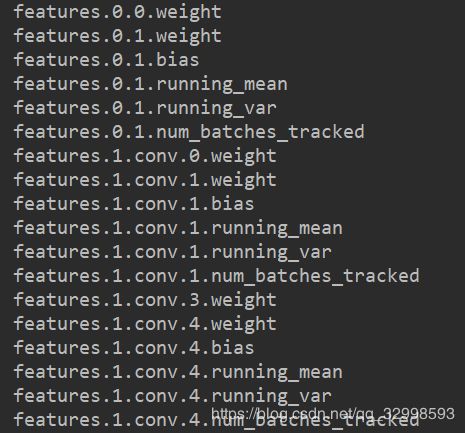
print(k)
#只打印key值,不打印具体参数。
features.0.0.weight
features.0.1.weight
features.1.conv.3.weight
features.1.conv.4.num_batches_tracked
-
model = VGGNet()
-
checkpoint = torch.load(
'checkpoint.pt', map_location=
'cpu')
-
# Load weights to resume from checkpoint。
-
# print('**************************************')
-
# 这个方法能够直接打印出你保存的checkpoint的键和值。
-
for k,v
in checkpoint.items():
-
print(k)
-
print(
"*****************************************")
-
输出结果为:
module.features.0.0.weight",
"module.features.0.1.weight",
"module.features.0.1.bias
可以看出不匹配,模型的参数中,key值不同,多了module。