ResNet
ResNet
2015
resnet解决问题:当网络层数增加,网络退化,网络不能很好地被优化。
resnet主要思想:

H(x)=F(x)+x,H(x)是期望输出,普通网络我们直接学习得到H(x),残差网络我们学习得到F(x).
x和y维度相同:
y = F ( x , W i ) + x y = F(x, {Wi}) + x y=F(x,Wi)+x
x和y维度不同:
y = F ( x , W i ) + W s x . y = F(x, {Wi}) + Wsx. y=F(x,Wi)+Wsx.
残差网络其余操作:增加网络层数(152层);
网络深度
网络深度增加,能够提取到更多low/mid/high-level的特征,网络模拟性能越好。
1、梯度爆炸:误差梯度不断累积导致权重出现重大更新,造成模型不稳定,无法利用训练数据学习;
2、梯度消失:梯度特别小,模型无法更新;
解决梯度消失:
1、更换激活函数ReLU,正数部分等于1,负数部分等于0;
2、BN层,解决反向传播中的梯度问题;把每一层的输出进行归一化到β均值、γ标准差的正态分布上,去除数据绝对差异、扩大相对差异,适用分类问题;
解决梯度爆炸:
1、残差结构;
2、正则化:在损失函数中加入正则项;
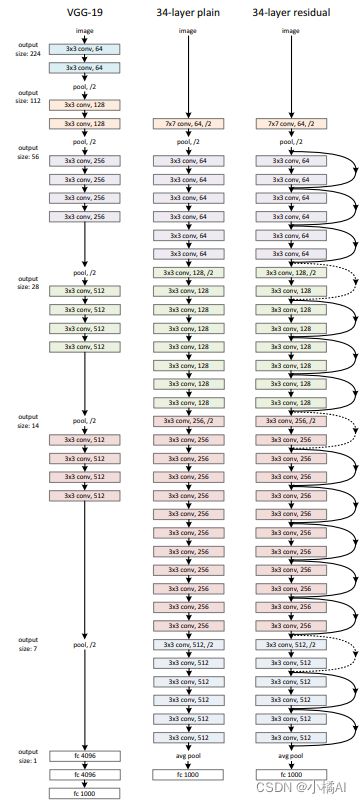
网络结构
为了保证每一层的时间复杂度,如果输入输出维度相同,就设置卷积数量不变;如果输出维度减半,卷积数加倍。
在简单网络上增加捷径,如果两边维度相同,直接可以加捷径,就是图中的实线;维度增加,要么补零,要么作一次矩阵变换,就是图中的虚线,stride=2可以把高和宽变为原来的一半,卷积核个数改变channel维数 ;每一层conv都由conv_1完成下采样过程。
随机梯度SGD:batch size 256;学习率从0.1开始,误差稳定后除10;0.0001权重衰减;0.9动量,不适用dropout。
实验结论
实验优化
1、18vs34层基准网络,确实发现了网络退化问题;
2、优化难题不可能是因为梯度消失,因为网络中使用了BN层;
3、18vs34层残差网络,resnet确实可以解决网络退化问题;
4、34 plain vs 34 残差,resnet减少了训练误差,在深度网络上有更好的学习性能;
5、零填充<矩阵变换补差(仅使用于维度上升)<矩阵变换补差(所有的捷径),但三者差距不大,说明这个不是提升重点,而且矩阵变换引入了更多变量,性能变好正常;
6、更深瓶颈结构Bottleneck:多增加一层卷积,因为残差网络的复杂度低,所以更深的网络复杂度可以接受;不改变残差块输入输出维度,不然时间复杂度和模型大小会加倍;1*1改变了输入的维度,channel=256变成了64(64个卷积核);
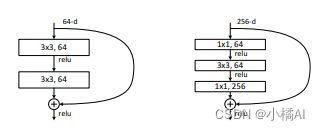
7、50层残差网络:用Bottleneck替换所有的双层残差块,并用矩阵变换作维度上升补差;101/152层都是增加更多的Bottleneck块;
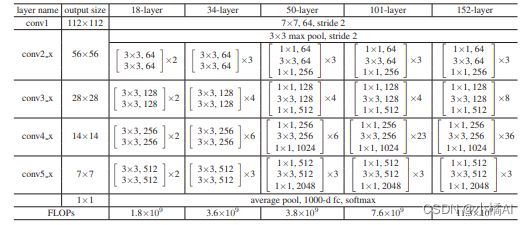
8、不同深度18、34、50、101、152、152的残差网络融合达到了最好结果。
9、残差函数有更小的反馈,比其他简单函数更接近于0;
实验不足
1、深度的plain网络会有指数级低的收敛速度,会影响训练误差的减少;
2、千层网络的测试误差上升,可能是因为过拟合,后续可以增加dropout;
2016
主要思想
研究残差构建的传播公式,让前向/后向信号可以直接从一个块传播到任何其他块,恒等映射直接跳过连接和after-addtition activation;
主要贡献:实验验证恒等映射的重要性,任何在捷径上的操作都是多余的;提出新的残差块单元,使得训练更容易并且提高泛化能力。
残差块改变:在恒等映射那块减去了ReLU,权重前面增加BN和ReLU组成的预激活;
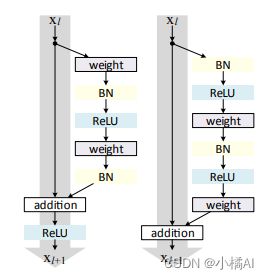
总体公式:h表示恒等映射,f是addition之后的操作;

改进后的残差块:h(xl)=xl,f(yl)=yl;
![]()
由于捷径上不做任何操作,因此任意层之间可以传递信号;

由此推出反向传递:
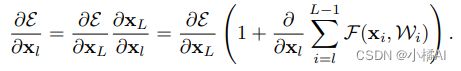
针对输入输出维度不同的单元:
1、这样的单元比较少,取决于图像大小;
2、没有产生指数级影响;
3、推导只在符合条件的残差块运行。
实验过程
针对捷径
验证捷径上不做任何操作,优于其他操作;
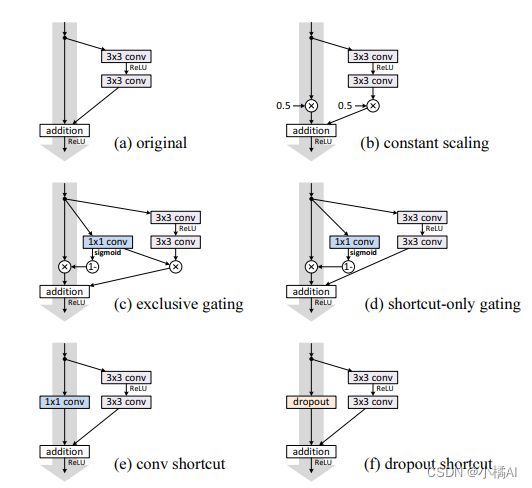
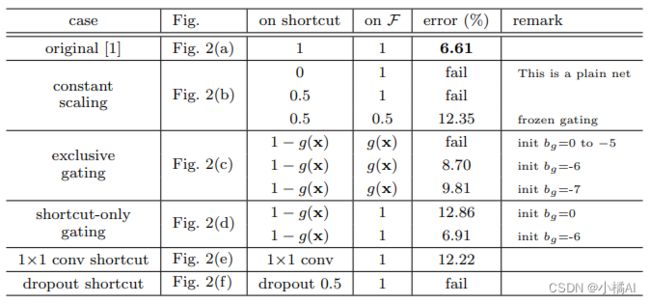
1、b缩放捷径或权重,误差很大;
2、对于c来说,1*1卷积操作g(x) = σ(Wgx + bg),超参数偏差bg对于训练影响很大;g(x)越接近于0,捷径部分就越接近于恒等映射,但权重部分就会被压缩,为了分离门对权重的影响,就实验了d;
3、d仅对捷径作门操作,bg影响依旧很大,也是g(x)接近于0时,误差比较好;
4、e直接对捷径作卷积,在34层resnet中有比较好的行为,但是110层,训练误差很大;堆叠网络层过多时,卷积也会影响信号传播;
5、f对捷径作dropout,类似于b对捷径作缩放操作,期望是0.5,阻碍信号传播。
总结:捷径上任何操作都会影响信号传播,门和卷积还引入更多的参数,本应有更强的表达能力但实际上训练误差却增加了,表示模型退化是因为优化问题而不是表达能力。
针对预激活
resnet164采用了Bottleneck结构;
对于整个网络来说,after-addition activation就是下一个残差块的预激活,因此后激活和预激活没有差别。但对于权重分支来说,就有两种设计,如d和f。

1、b多增加BN,捷径上增加操作,性能变差;
2、c的捷径部分不做其他操作,但ReLU层会导致权重部分只有非负值,但残差函数值域应该是实数域;前向传递信号会单调递增,影响表达能力;
3、d是仅ReLU预激活,发现和a性能差不多,是因为ReLU没有和BN层连接,没有完全利用BN;
实验总结
1、200层resnet在ImageNet上有更好的性能,没有出现过拟合;
2、预激活的好处:由于捷径上没有任何操作,针对网络退化的好处更明显;BN作预激活提高了模型的正则化;
3、捷径上有操作时,当网络深度增加,对网络影响增大;如果有ReLU操作,由于权重被ReLU调整至大于0,因此ReLU操作发生不多,但当有1000层时,截断更为频繁,说明此时权重部分大小非常负;
4、捷径上没有操作,信号在两个残差块之间可以直接传播,训练损失下降很快,而且能达到最低损失;
5、由于预激活,所有输入送入权重之前都会进行归一化,减少了过拟合问题;之前版本虽然也有归一化操作,但是加上了捷径部分之后就直接送入权重了;
2017ResNeXt
主要思想
VGG/resnet成功表明堆叠相同结构的基本构件,可以构建深层网络,取得比较好的结果;
提取特征由深度学习网络完成,人力目的在设计更好的网络结构;但超参数增多,宽度、滤波器大小、步长,针对不同数据集超参数设置都不同,就很麻烦;简单堆叠构件可以减少对超参数的选取;
Inception网络
设计网络拓扑结构,以极低的复杂度实现较高的精度;
主要思想是拆分-转换-合并,该架构的解空间是单个大层在高维嵌入上运行的子空间;
拆分-转换-合并表达能力能够接近大且密集的层,但计算复杂度会低;
缺点:针对新的数据集,如何设置超参数需要探索;
resNext
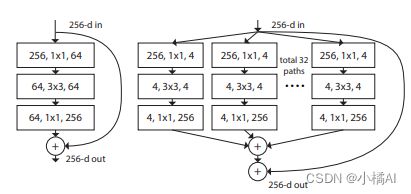
1、在保证复杂度不增加的情况下,增加基数可以提高模型性能,此处基数是32;
2、提高基数比提高网络深度和宽度都要有效;
3、利用更少的计算代价实现相同的效果。
实验过程
resnext每个残差块都有相同的拓扑结构,当生成相同大小的空间图,块之间共享超参数;当空间图被下采样2倍,块的宽度乘以2;
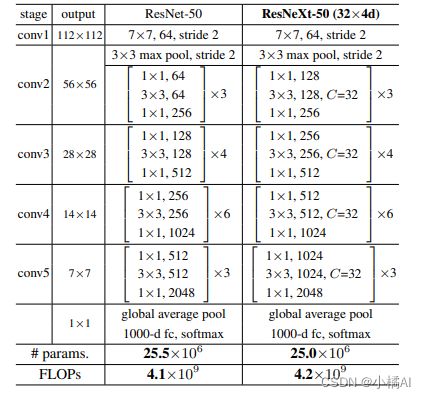
问题:这两个网络的参数怎么会是一个数量级?
组卷积分为a组,参数量会减少a倍。conv部分,前两个卷积核个数增加,但中间用的都是组卷积,32*4d,将卷积核分为32组,每组4d个,所以卷积核个数增加保证参数量差不多。
resnet实现
实验问题:
1、pytorch的ImageFloder函数
ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
# root 图片路径,图片类型时jpg
# transform 对PIL Image进行转换,输入是使用loader读取图片的返回对象
# target_transform 对label进行转换
# loader 给定路径后如何读取文件,默认读取为RGB格式的PIL Image对象
2、cifar10数据集解压后是二进制文件,每个batch都是训练图片,每个批次由10000张训练图片,需要通过官方的数据集解压训练和测试的文件。
其实torch提供了如何使用tar文件进行训练,不需要用到ImageFloder。
train_dataset = torchvision.datasets.CIFAR10(root=os.path.join(image_path), train=True, download=False, transform=data_transform["train"])
3、载入预训练模型参数
从https://download.pytorch.org/models/resnet34-333f7ec4.pth下载官方resnet34的模型权重;
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file {} does not exist." .format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 10) #此处的10就是cifar10的类别
net.to(device)
#resnet预训练模型的最后全连接层类别数是1000,所以刚开始定义网络时,不能用net=resnet34(10)
#如果想要直接定义net=resnet34(10),需要删去预训练全连接层
4、torchvision.transform函数
torchvision.transforms.Compose(transforms)
#将多个transfrom组合起来使用,tranforms是由transform构成的列表;
transforms.Compose([
transforms.CenterCrop(size), #对图片进行中心切割,integet切出size*size图片,tuple切出相应大小图片
transforms.RandomCrop(size,padding=0), #切割中心随机
transforms.RandomHorizontalFlip, #随机水平翻转图片,概率为0.5
transforms.RandomSizedCrop(size,interpolation=2), #随机切图片,再resize成size大小
transforms.Pad(padding,fill=0), #将图片的边填充padding像素,用fill填充
transforms.ToTensor(), #将取值范围是[0.255]的图片PIL.image转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloadTensor
])
Cifar10是一个有10个类别的图片数据集,其中图片分辨率只有28,所以提前对图片有处理;
"train": transforms.Compose([transforms.RandomCrop(32,padding=4), #填充成32*32
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])]),
"val": transforms.Compose([transforms.Resize(32),
transforms.CenterCrop(32),#刚开始没有看这个函数,将size设置为10,导致测试性能很差
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])}
5、网络收敛不好,val准确率低
观察网络结构,可以看到stride有2^5操作,如果是32操作最后余1;但stride太大会造成信息遗漏,导致无法有效提炼数据背后特征;
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False)
#输入大小是(N,in_channels,H,W)=(N,3,32,32)
#输出大小是(N,64,16,16)
#卷积步长为2,则长宽/2;
#padding让图像边的点被卷积时有数据;
o u t ( N i , C o u t j ) = b i a s ( C o u t j ) + ∑ C i n − 1 k = 0 w e i g h t ( C o u t j , k ) ⨂ i n p u t ( N i , k ) out(N_i, C_{out_j})=bias(C_{out_j})+\sum^{C_{in}-1}{k=0}weight(C{out_j},k)\bigotimes input(N_i,k) out(Ni,Coutj)=bias(Coutj)+∑Cin−1k=0weight(Coutj,k)⨂input(Ni,k)
self.bn1 = nn.BatchNorm2d(self.in_channel) #对数据进行标准化操作,输入输出维度相同
self.relu = nn.ReLU(inplace=True) #激活函数时ReLU,而且覆盖运算,输入输出维度相同
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
#padding是每一条边补0的层数
#输入(N,64,16,16),输出(N,64,8,8)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
#输出(N,out_channel,4,4)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
#输出(N,out_channel,2,2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
#输出(N,out_channel,1,1)
[epoch 10] train_loss: 0.642 val_accuracy: 0.773;
将第一个卷积层的步长改为1:[epoch 10] train_loss: 0.463 val_accuracy: 0.821,可以看到效果更好,所以可能是分辨率太低,步长小一点会好一点。
参考学长意见,删去maxpool进一步实验:[epoch 10] train_loss: 0.348 val_accuracy: 0.843,效果进一步提升,所以是差不多就是stride问题;
至此实验出现过的问题完结。
实验代码总结
model.py
首先关注model,有两种残差块,搭建完全按照论文中结构搭建。
基本残差块:
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
out += identity #捷径
out = self.relu(out) #最后进行一次relu操作
瓶颈残差块:
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
out += identity #捷径
out = self.relu(out) #最后进行一次relu操作
整体网络搭建:
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
#block_num数组是每层残差块个数
train.py
数据处理在实验过程中已有详述,此处不再赘述;
train_dataset = datasets.CIFAR10(root=os.path.join(image_path), train=True, download=False, transform=data_transform["train"])
label_list = train_dataset.class_to_idx
batch_size = 256
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True, num_workers=nw)
网络相关
net = resnet18()
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 10) #因为原网络最后全连接层有1000类,我们将其转换成cifar10类
net.to(device)
loss_function = nn.CrossEntropyLoss() #损失函数
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.001) #优化函数
save_path = './resNet34.pth'
net.train()
net.eval()
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y,val_labels.to(device)).sum().item()
val_accurate = acc / val_num
其他的一些点:应该是原代码作者的一些不必要操作;
dict:字典序,
cla_dict = dict((val, key) for key, val in label_list.items())
#从label中得到字典序
json
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
#json.dumps将python对象编码成json字符串
#json.loads将json字符串解码为python对象
dim=1)[1]
acc += torch.eq(predict_y,val_labels.to(device)).sum().item()
val_accurate = acc / val_num
一些不必要操作;
dict:字典序,
```python
cla_dict = dict((val, key) for key, val in label_list.items())
#从label中得到字典序
json
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
#json.dumps将python对象编码成json字符串
#json.loads将json字符串解码为python对象