A Unified Model for Opinion Target Extraction and Target Sentiment Prediction(20.11.17)
A Unified Model for Opinion Target Extraction and Target Sentiment Prediction
一种统一的意见目标提取和目标情感预测模型
Abstract
- Target-based sentiment analysis involves opinion target extraction and target sentiment classification.
基于目标的情感分析包括意见目标提取和目标情绪分类。 - However, most of the existing works usually studied one of these two subtasks alone, which hinders their practical use.
然而,现有的研究大多只研究这两个子任务中的一个子任务,这就阻碍了它们的实际应用。 - This paper aims to solve the complete task of target-based sentiment analysis in an end-to-end fashion, and presents a novel unified model which applies a unified tagging scheme.
本文旨在以端到端的方式解决基于目标的情感分析的全部任务,并提出了一种采用统一标记方案的新型统一模型。 - Our framework involves two stacked recurrent neural networks: The upper one predicts the unified tags to produce the final output results of the primary target-based sentiment analysis; The lower one performs an auxiliary target boundary prediction aiming at guiding the upper network to improve the performance of the primary task.
我们的框架涉及两个堆叠的递归神经网络:上层神经网络预测统一的标签,以产生基于目标的主要情感分析的最终输出结果; 下层执行辅助目标边界预测,旨在引导上层网络提高主要任务的性能。 - To explore the inter-task dependency, we propose to explicitly model the constrained transitions from target boundaries to target sentiment polarities. We also propose to maintain the sentiment consistency within an opinion target via a gate mechanism which models the relation between the features for the current word and the previous word. We conduct extensive experiments on three benchmark datasets and our framework achieves consistently superior results.
为了探究任务间的依赖性,我们建议对从目标边界到目标情感极性的约束过渡进行显式建模。 我们还建议通过门机制来维持观点目标内的情感一致性,该机制对当前单词和先前单词的特征之间的关系进行建模。 我们在三个基准数据集上进行了广泛的实验,我们的框架取得了始终如一的出色结果。
一、Introduction

二、Our Proposed Framework
- 2.1 Task Definition
1)We formulate the complete Target-Based Sentiment Analysis (TBSA) task as a sequence labeling problem, and employ a unified tagging scheme: YS={B-POS, I-POS, E-POS, S-POS, B-NEG, I-NEG, E-NEG, S-NEG, B-NEU, I-NEU, E-NEU, S-NEU, O}.
我们将完整的基于目标的情感分析(TBSA)任务描述为一个序列标注问题,并采用了一个统一的标注方案: YS={B-POS, I-POS, E-POS, S-POS, B-NEG, I-NEG, E-NEG, S-NEG, B-NEU, I-NEU, E-NEU, S-NEU, O}.
2)Except O, each tag contains two parts of tagging information: the boundary of target mention, and the target sentiment.
除O之外,每个标签都包含标签信息的两个部分:目标提及的边界和目标情感。
3)For example, B-POS denotes the beginning of a positive target mention, and S-NEG denotes a single-word negative opinion target.For a given input sequence X ={x1,…,xT} with length T, our goal is to predict a tag sequence YS={y1S,…,yTS}, where yiS∈ YS
例如,B-POS表示肯定目标提及的开始,而S-NEG表示单个单词否定目标。对于长度为T的给定输入序列X = {x1,…,xT},我们的目标是预测标签序列Y S = {y1 S,…,yT S},其中 yi S∈Y S. - 2.1 Model Description
Overview:
- As shown in Figure 1, on the top of two stacked RNNs with LSTM cells, our framework designs three tailor-made components, depicted in detail with the callouts, to explore three important intuitions in the task of TBSA.
如图1所示,在两个带有LSTM单元的堆叠RNN的顶部,我们的框架设计了三个量身定制的组件,并用标注详细描述了这些组件,以探索TBSA任务中的三个重要任务。 - Specifically, the upper LSTMS is for the complete TBSA task and it predicts the unified tags as output, while the lower LSTMT is for the auxiliary task and predicts the boundary tags of target mentions.
具体来说,上层LSTMS用于完成TBSA任务,预测统一标签作为输出;下层LSTMT用于辅助任务,预测目标提及的边界标签。 - The boundary prediction from LSTMT is used to guide LSTMS to make better predictions over the unified tags for the complete task.
来自LSTM T的边界预测用于指导LSTM S,以针对整个任务对统一标签进行更好的预测.
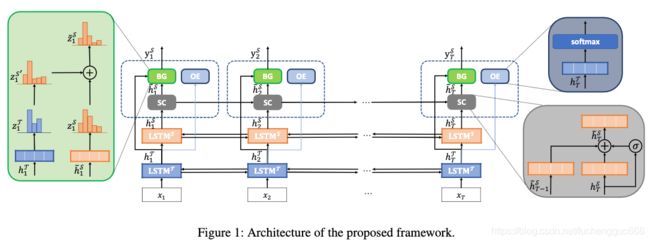
- The three key components are named Boundary Guidance(BG) component,Sentiment Consistency (SC) component and Opinion-Enhanced (OE) Target Word Detection component.
这三个关键组件分别是’边界引导(BG)'组件、'情感一致性(SC)'组件和’观点增强型(OE)目标词检测’组件。 - The BG component takes the advantages of the boundary information provided by the auxiliary task to guide the LSTMS for predicting the unified tags more accurately. The SC component is empowered with a gate mechanism to explicitly integrate the features of the previous word into the current prediction, aiming at maintaining the sentiment consistency within a multi-word opinion target.
BG组件利用辅助任务提供的边界信息的优势来指导LSTMS,以更准确地预测统一标签。 SC组件具有门机制,可以将前一个单词的特征显式集成到当前的预测中,旨在在多单词观点目标内保持情感一致性。 - In order to provide boundary information of higher quality, the OE component, following the oberservation that “opinion targets and opinion words always cooccur”, performs another auxiliary binary classification task to determine if the current word is a target word.
为了提供更高质量的边界信息,OE组件在观察到“意见目标和意见词总是同时出现”之后,执行另一辅助二进制分类任务以确定当前词是否是目标词。 - 2.3 Target Boundary Guided TBSA目标边界引导的TBSA
1)We employ LSTMS with softmax decoding layer for the prediction of the tag sequence. It is observed that the boundary tag can provide important clues for the unified tag prediction.
我们使用带有Softmax解码层的LSTMS对标签序列进行预测。 观察到边界标签可以为统一标签预测提供重要线索.
2)For example, if the current boundary tag isB, denoting the beginning of an opinion target, then the corresponding unified tag can only be B-POS, B-NEG or B-NEU. Thus, we introduce an additional network LSTMT for the target boundary prediction, where the valid tag set YT is{B,I,E,S,O}. We link these two LSTM layers so that the hidden representations generated by the LSTMT can be directly fed to LSTMS as guidance information. Specifically, their hidden representations htT ∈ RdimhT^^ and htS ∈ RdimhS^^ at the t-th time step(t∈[1,T]) are calculated as follows:
例如,如果当前边界标签为B,表示意见目标的开始,则对应的统一标签只能是B-POS、B-NEG或B-NEU。 因此,我们引入了一个额外的网络LSTMT用于目标边界预测,其中有效的标签集YT是{B,I,E,S,O}。 我们将这两个LSTM层链接起来,以便LSTMT生成的隐藏表示可以直接作为指导信息提供给LSTMS。 具体地说,它们在第t个时间步长(t∈[1,T])的隐藏表示htT∈RdimhT和htS∈RdimhS计算如下:
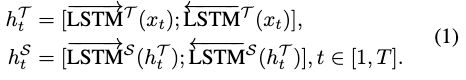
3)The probability scores ztT ∈R|YT|over the boundary tags are calculated by a fully-connected softmax layer.
边界标签上的概率得分ztT∈R|YT|由完全连接的Softmax层计算: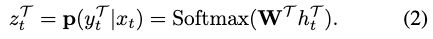
where the Softmax denotes the softmax activation function and WT is the model parameter. Similarly, the scores over the unified tags ztS∈R|YS| are obtained as below:
其中,Softmax表示Softmax激活函数,WT是模型参数。 同样,统一标签ztS∈R|ys|的得分如下:
4)As mentioned above, the boundary information is supposed to be useful for improving the performance of LSTMS. (Zhang, Zhang, and Vo 2015) incorporated such boundary information by adding hard boundary constraints in the decoding step of the CRFs model. However, their pre-diction results are not promising. One reason is that their model employs a hard constraint which is prone to propagating the errors from the tagger of the boundary detection task and thus it decreases the performance of the TBSA tagger.
如上所述,边界信息应该有助于提高LSTMS的性能。 (Zhang,Zhang,and Vo 2015)通过在CRF模型的解码步骤中添加硬边界约束来纳入这种边界信息。 然而,他们的预测结果并不乐观。 一个原因是他们的模型采用了硬约束,容易从边界检测任务的标记器传播错误,从而降低了TBSA标记器的性能。
5)Different from their way of imposing hard constraints, our proposed BG component can absorb the boundary in-formation via boundary guided transition and automatically determine its proportions in the final tagging decision based on the confidence of the target boundary tagger.
与它们施加硬约束的方式不同,我们提出的BG组件可以通过边界引导转换来吸收边界信息,并基于目标边界标签者的置信度自动确定其在最终标注决策中的比例。
Firstly, the BG component encodes the constraints into a transition matrix Wtr∈R|YT|×|YS|. As we have no prior knowledge about the transition probabilities between the boundary tags and the unified tags, we initially set them equally as follows:
首先,BG组件将约束编码到转换矩阵WTR∈R|YT|×|YS|中。由于我们对边界标签和统一标签之间的转换概率没有任何先验知识,因此我们将它们初始设置如下: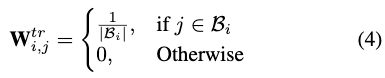
6)where Bi is the set of valid unified tags coherent with the boundary tag i. In this transition matrix, a non-zero element, e.g.,WtrB,B-POS, denotes the probabilities of the unified tags given the boundary tag, and a zero element, e.g.,WtrB,I-NEG, suggests that the unified tag cannot be inferred through this transition. After encoding the constraints, the next step is to guide the unified tag prediction with the boundary information. We directly propagate such information to the TBSA tagger by mapping the probability scores of the boundary tag ztT to the unified tag space. The transition-based sentiment score ztS′ ∈ R|YS| is obtained as follows:
其中,Bi是与边界标签i一致的有效统一标签的集合。在该转换矩阵中,非零元素(例如,WTRB,B-POS)表示给定边界标签的统一标签的概率,而零元素(例如,WTRB,I-NEG)表示不能通过该转换推断出统一标签。 在对约束进行编码之后,下一步是使用边界信息来指导统一标签预测。 我们通过将边界标签ztT的概率得分映射到统一标签空间,将这些信息直接传播给TBSA标记器。 基于过渡的情绪得分ztS‘∈R|ys|如下所示:
![]()
where the transition operation is equivalent to the linear combination of the row vectors in the transition matrix Wtr.
其中过渡操作等效于过渡矩阵W tr中行向量的线性组合。
Assuming ztT = [1,0,0,0,0](i.e., taking the tagB), the result of the transition is exactly the row vector WBtr,:. As the unified tag can be partially derived from the boundary tag, a natural question is how to determine the proportions of the transition-based unified tagging scores ztS′.
假设ztT=1,0,0,0,0,转换的结果正好是行向量wbtr,:。 由于统一标签可以从边界标签部分派生出来,因此一个自然的问题是如何确定基于转换的统一标签得分ztS‘的比例。
Intuitively, if the target boundary score ztT is nearly uniform, suggesting that the boundary tagger is not confident to its prediction, the obtained distribution over the unified tags, i.e.,zS′t, will also be close to a uniform distribution and has little meaningful information for the sentiment prediction.
直观地,如果目标边界得分zt T几乎是均匀的,则表明边界标记器对其预测没有信心,则在统一标记上获得的分布zS’t也将接近均匀分布,并且 对于情绪预测几乎没有有意义的信息。
to avoid such un-informative boundary transitions, we calculate a proportion score αt∈ R based on the confidence ct of the target boundary tagger:
为了避免这种非信息性的边界过渡,我们基于目标边界标记器的置信度ct计算比例分数αt∈R:

where the hyper-parameter denotes the maximum proportions that the boundary-based scores ztS′ occupy in the tagging decision. Obviously, ct will be down-weighted if the boundary scores are uniformly distributed. The maximum confidence value is reached if ztT is a one-hot vector. The final scores are obtained by combining the boundary-based and model-based unified tagging scores:
其中超参数表示基于边界的得分zt S’在标记决策中所占的最大比例。 显然,如果边界分数均匀分布,则ct将被加权。 如果zt T是one-hot向量,则达到最大置信度值。 通过结合基于边界和基于模型的统一标记得分来获得最终得分:
![]()
- 2.4 Maintaining Sentiment Consistency保持情绪一致性
- In the traditional target sentiment classification task, the sentiments towards the different words in a given multi-word opinion target are assumed to be identical. However, in the complete TBSA task, such sentiment consistency is not guaranteed since the task is formulated as a sequence tagging/labeling problem.Taking the sentence in Table 1 as an example, there is still some possibility that the word “Processor” is labeled with an E-NEG tag due to the independent tagging decisions made by LSTMs. To maintain the sentiment consistency within the same opinion target, we propose to predict the current unified tag using both of the features from the current and the previous time steps. Specifically, we design a Sentiment Consistency (SC) component with a gate mechanism to combine these two feature vectors:
在传统的目标情感分类任务中,假定给定多词观点目标中针对不同单词的情感是相同的。 但是,在完整的TBSA任务中,由于该任务被表述为序列标记/标签问题,因此不能保证这种情感一致性。以表1中的句子为例,仍然有可能标记“ Processor”一词 由于LSTM做出了独立的标记决定,因此带有E-NEG标记。 为了在同一意见目标内保持情感一致性,我们建议使用当前和先前时间步骤中的两个功能来预测当前统一标签。 具体来说,我们设计了带有门机制的情感一致性(SC)组件,以结合这两个特征向量:
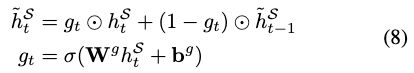
- where Wg and bg are learnable parameters of the SC component, and denotes the element-wise multiplication. σ is the sigmoid function. Through the gating, the previous features are considered in the current predictions and such indirect bi-gram dependency can help reduce the probability that the words within the same target hold different sentiments.
其中W g和b g是SC分量的可学习参数,并表示逐元素乘法。 σ是Sigmod函数。 通过门控,当前预测中考虑了先前的特征,这种间接的二元语法依赖性可以帮助降低同一目标内的单词持有不同情感的可能性
- 2.5 Auxiliary Target Word Detection辅助目标次检测
A good boundary tagger for opinion targets is crucial for producing the boundary information of high quality. Here, we introduce the OE component to learn a more robust boundary tagger from an-other view of the training data. As defined in (Pontiki 2014; Pontiki 2015; Pontiki 2016), opinion targets are always collocated with opinion words. Inspired by this, we regard the word as a target word if there is at least one opinion word within the context window of fixed-sizes of this word. Then, we train an auxiliary token-level classifier for discriminating target words and non-target words based on the distantly supervised labels and the boundary representations htT are further refined with such supervision signals. The computational process of the OE component is below:
一个好的意见目标边界标记器是产生高质量边界信息的关键。在这里,我们引入OE组件,从训练数据的另一个角度学习更健壮的边界标记器。如(Pontiki 2014;Pontiki 2015;Pontiki 2016)所定义,意见目标总是与意见词搭配。受此启发,如果在固定大小的上下文窗口中至少有一个意见词,我们将该词视为目标词。然后,我们训练了一个辅助的令牌级分类器来区分目标词和非目标词,并利用这些监督信号进一步细化了边界表示htT。OE组件的计算过程如下:
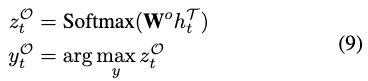
Wo是模型参数。 - 2.5 Model Traning
- 整个框架可以使用基于梯度的方法进行有效训练,采用wo r d/token级交叉熵误差作为损失函数。

- where I is the symbol of task indicator and its possible values are T,S, andO. II(y) represents the one-hot vector with the y-th component being 1 and y tI,g is the gold standard tag for the task I at the time step t. Then, the losses from the main TBSA task and the two auxiliary tasks are aggregated to form the training objectiveJ(θ)of the framework.
其中I是任务指示符的符号,它的可能值是T、S和O。II(y)表示one-hot向量,其中y-th分量为1,y tI,g是时间步长t时任务I的黄金标准标记。然后,将来自主TBSA任务和两个辅助任务的损失聚合起来,形成框架的训练目标j(θ)

三、Experiments
- 3.1 Dataset
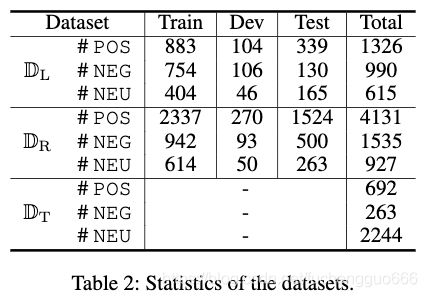
评价指标根据精确匹配来衡量标准精确度(P)、召回率(R)和F1分数,这意味着只有当输出片段与目标提及的黄金标准跨度和相应的情绪完全匹配时,才认为输出片段是正确的。
- 3.2 Experiment Settings
- Word Embeddings
- Weight Initializations
- Optimization
- Others
- 3.3 Results and Analysis
- Main Results
- Effectiveness of the Proposed Components拟议组成部分的有效性
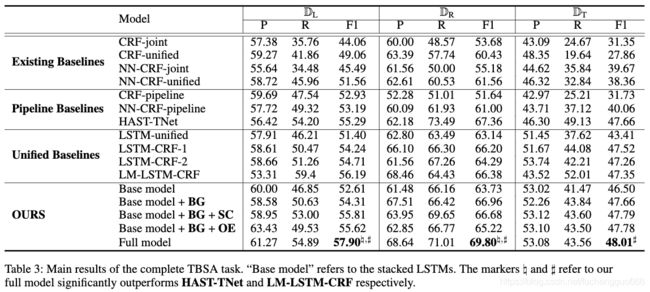
1).To investigate the effectiveness of the designed components, we con-duct ablation study on the proposed framework and the results are listed in the last block of the Table 3.
为了研究设计组件的有效性,我们对建议的框架进行了消融研究,结果列在表3的最后一个方框中。
2).Let us start the discussion from the base model, namely, the stacked LSTMs.
让我们从’基础模型(即堆叠的LSTM)'开始讨论。
We find that the base model always gives superior performance compared to the LSTM-unified. This result indicates that the boundary information predicted by the auxiliary LSTM indeed increases the F1 score of the complete TBSA task.
我们发现,与LSTM-unified模型相比,base模型的性能更优越。结果表明,辅助LSTM预测的边界信息确实提高了完成TBSA任务的F1分数。
With the help of the BG component, the performances are improved more significantly and the way we impose the boundary constraints proves effective for yielding more true positives.
在BG组件的帮助下,性能得到了显着改善,并且我们施加边界约束的方法被证明可以有效地产生更多的正值。
Another interesting finding is that introducing the component SC or OE individually into the “Base model + BG” does not bring in too much gains on F1 measure and even hurts the prediction performance on D_R.
另一个有趣的发现是,将分量SC或OE单独引入“基础模型+ BG”不会在F1度量上带来太多收益,甚至会损害D_R的预测性能
But putting them together, i.e., the “Full model”, leads to the new state-of-the-art result. This result illustrates the necessity of both of the SC and OE components in the boundary guided TBSA.
但是将它们放在一起,即“完整模型”,就可以得出最新的最新结果。 该结果说明在边界引导的TBSA中SC和OE组件都是必要的。
Considering the “Base model +BG+SC”,the quality of the boundary information may not be accurate without the clues from the OE component, and thus, the SC component tends to incorrectly align the sentiments of both the target words and non-target words.
考虑到“基本模型+ BG + SC”,如果没有OE组件的提示,边界信息的质量可能不准确,因此,SC组件往往会错误地对齐目标词和非目标词的情感话。
For the “Base model +BG+OE”, the quality of the boundary information obtained from the LSTMT is improved but the sentiments of the words within the same target are not fully consistent compared to the “Full model” armed with SC component.
对于“基本模型+BG+OE”,从LSTMT获得的边界信息质量有所提高,但同一目标内的词的情感与使用SC分量的“全模型”不完全一致。
In summary, the SC component and the OE component are complementary to some extent when they are added into the boundary-guided “Base model +BG”.
总之,将SC组件和OE组件添加到边界引导的“基本模型+ BG”中在某种程度上是互补的
以上总结其实就是想说Base model + BG+SC+OE缺一不可。
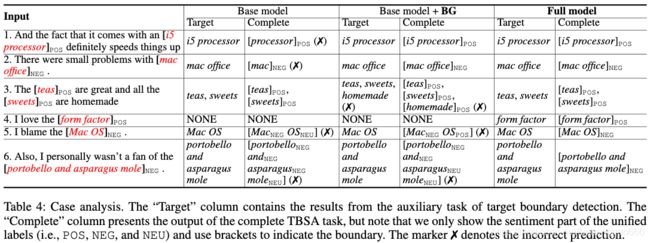
- Case Analysis
1).Table 4 gives some prediction examples of the base model (i.e., the stacked LSTMs) and the models empowered with our proposed components.
表4给出了基本模型(即堆叠的LSTM)和我们提出的组件支持的模型的一些预测示例。
2).As observed in the first input and the second input, the “Base model” correctly predicts the target boundary but it fails to produce the right target sentiments, suggesting that linking the two LSTMs for the target boundary prediction and the TBSA task is still insufficient for exploiting the boundary information to improve the performance of the complete TBSA.
正如第一次输入和第二次输入所观察到的,“base模型”正确地预测了目标边界,但未能产生正确的目标情绪,结果表明,将两个LSTMs用于目标边界预测和TBSA任务相结合仍不足以充分利用边界信息来提高TBSA的性能。
3).The “Base model+BG” and the “Full model”, where the boundary constraints are properly imposed via our BG component, can correctly handle these two cases.
“base模型+BG”和“full模型”通过我们的’BG组件’适当地施加边界约束,可以正确地处理这两种情况。
4).Although the boundary information can guide the model to predict the sentiment more accurately, there is the possibility that only using the BG component (i.e., “Base model+BG”) inherits the errors from the lower boundary detection task, e.g., the third and the fourth input. Thus, the boundary information of high quality is crucial for improving the upper TBSA task and our OE component can serve as a simple but effective solution.
尽管边界信息可以指导模型更准确地预测情绪,但是有可能仅使用BG组件(即“base模型+ BG”)继承了较低边界检测任务(例如第三和第四种输入)的错误。因此,高质量的边界信息对于改善上层TBSA任务至关重要,我们的’ OE组件 '可以作为一种简单而有效的解决方案。
5).Besides, we find that maintaining sentiment consistency within the same target mention, especially for whose with several words (e.g., “portobello and asparagus mole”in the last input), is difficult for the “Base model” and “Base model+BG”, while our “Full model” alleviates this issue by employing the SC component to make predictions based on the features from the current and the previous time step.
此外,我们发现,对于“base模型”和“base模型+BG”而言,在同一目标提及范围内,尤其是在多个词(如最后一个输入词为“portobello and asparagus mole”)的情况下,保持情绪一致性比较困难,而我们的“完整模型”则通过使用’SC组件’来根据当前和上一个时间步的特征进行预测来缓解这一问题。
- Impact of ∈ and s
1)Here, we investigate the impacts of the maximum proportion∈ of the boundary-based scores and the window sizes on the prediction performance.
在这里,我们研究了基于边界的分数的最大比例∈和窗口大小对预测性能的影响。
2)Specifically, the experiments are conducted on the development set of D_R, the largest benchmark dataset. We varyfrom 0.3 to 0.7, increased by 0.1, and two extreme values 0.0 and 1.0 are also included. The range of the window sizes is 1 to 5. According to the results given in Figure 2, we observe that the best results are obtained at ∈ =0.5. The ∈ value basically affects the importance of the sentiment scores from the BG component in the final tagging decision and 0.5 is a good trade-off between absorbing boundary information and eliminating noises.
具体来说,实验是在最大基准数据集D_R的开发集上进行的。 我们从0.3到0.7变化,增加了0.1,并且还包括两个极限值0.0和1.0。 窗口大小的范围是1到5。根据图2中给出的结果,我们观察到在 ∈ = 0.5时可获得最佳结果。 该∈ 值基本上会影响来自BG组件的情绪分数在最终标记决策中的重要性,而0.5是在吸收边界信息和消除噪声之间的良好折衷。
3)We also observe that a moderate value of s(i.e.,s= 3) is the best for the TBSA task, probably because too larges may enforce the model to attend the larger context and increase the possibility of associating with irrelevant opinion words, on the other hand, too smalls is likely not sufficient to involve the potential opinion words.
我们还观察到,适度的s值(即s=3)对TBSA任务是最好的,这可能是因为太大的值可能会使模型适应更大的上下文,增加与不相关的观点词相关的可能性,另一方面,太小的值可能不足以包含潜在的观点词。
四、Related Works
- As mentioned in Introduction, Target-based Sentiment Analysis are usually divided into two sub-tasks, namely, the Opinion Target Extraction task (OTE) and the Target Sentiment Classification (TSC) task.
如引言中所述,基于目标的情感分析通常分为两个子任务,即意见目标提取任务(OTE)和目标情感分类(TSC)任务。 - Although these two sub-tasks are treated as separate tasks and solved individually in most cases, for more practical applications, they should be solved in one framework. Given an input sentence, the output of a method should contain not only the extracted opinion targets, but also the sentiment predictions towards them. Some previous works attempted to discover the relationship between these two sub-tasks and gave a more integrated solution for solving the complete TBSA task.
虽然在大多数情况下,这两个子任务被视为单独的任务并单独解决,但为了更实际的应用,它们应该在一个框架中解决。在给定输入语句的情况下,方法的输出不仅要包含提取的意见目标,还要包含对这些目标的情感预测。以前的一些工作试图发现这两个子任务之间的关系,并给出了一个更完整的解决方案来解决完整的TBSA任务。 - Concretely, (Mitchell et al. 2013) employed Conditional Random Fields (CRF) together with hand-crafted linguistic features to detect the boundary of the target mention and predict the sentiment polarity. (Zhang, Zhang, and Vo 2015) further improved the performance of the CRF based method by introducing a fully connected layer to consolidate the linguistic features and word embeddings. However, they found that a pipeline method can beat both of the model with joint training and the unified model.
具体地说,(米切尔等。2013)使用条件随机场(CRF)和hand-crafted语言特征检测目标提及的边界和预测情绪极性。通过引入一个全连接层来巩固语言特征和词嵌入,进一步提高了基于 CRF 的方法的性能。然而,他们发现pipeline方法可以打败联合训练模型和统一模型。 - In this paper, we reexamine the task, and proposed a new unified solution which outperforms all previous reported methods.
在本文中,我们重新审视了这一任务,并提出了一个新的统一解决方案,其性能优于以往所有报告的方法。
五、Conclusions
1.We investigate the complete task of Target-Based Sentiment Analysis (TBSA), which is formulated as a sequence tagging problem with a unified tagging scheme in this paper.
本文研究了基于目标的情感分析(TBSA)的完整任务,该任务被描述为一个具有统一标记方案的序列标注问题。
2. The basic architecture of our framework involves two stacked LSTMs for performing the auxiliary target boundary detection and the complete TBSA task respectively.On top of the base model, we designed two components to take the advantage of the target boundary information from the auxiliary task and maintain the sentiment consistency of the words within the same target.
我们框架的基本架构包括两个堆叠的LSTM,分别用于执行辅助目标边界检测和完整的TBSA任务。在基础模型之上,我们设计了两个组件以利用辅助任务中的目标边界信息,并保持同一目标内单词的情感一致性。
3. To ensure the quality of the boundary information, we employ an auxiliary opinion-based target word detection component to refine the predicted target boundaries.
为了保证边界信息的质量,我们采用了基于辅助意见的目标词检测组件来细化预测的目标边界。
4. Experimental results and case studies well illustrate the effectiveness of our proposed framework, and a new state-of-the-art result of this task is achieved. We publicly release our implementation at https://github.com/lixin4ever/E2E-TBSA.
实验结果和案例研究很好地说明了我们提出的框架的有效性,并且获得了这项任务的最新成果。 我们在以下位置公开发布我们的实施 https://github.com/lixin4ever/E2E-TBSA.