神经网络搭建笔记(三)之循环神经网络
循环神经网络
1、循环神经网络和卷积神经网络简单对比
循环神经网络RNN:借助循环核(cell)提取特征后,送入后续网络(如全连接网络Dense)进行预测等操作。RNN借助循环核从时间维度提取信息,循环核参数时间共享。
卷积神经网络CNN:借助卷积核(kernel)提取特征后,送入后续网络(如全连接网络Dense)进行分类、目标检测等操作。CNN借助卷积核从空间维度提取信息,卷积核参数空间共享。
2、详解循环神经网络
要搞懂循环神经网络,就得先搞懂循环核是什么及其操作原理。循环核的示意图如下:
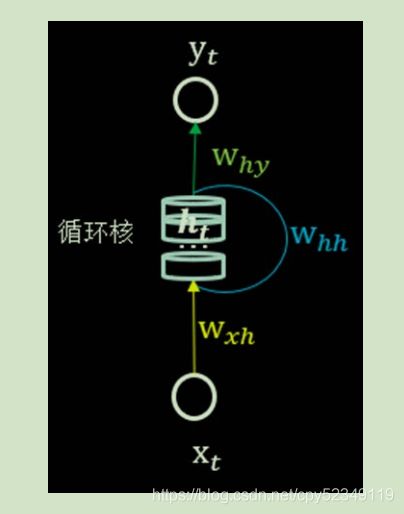
循环核具有记忆力,通过不同时刻的参数共享,实现了对时间序列的信息提取。每个循环核有多个记忆体,对应图中的多个小圆柱。记忆体内存储着每个时刻的状态信息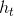 ,这里
,这里![]() 。其中,
。其中,![]() 、
、![]() 为权重矩阵,bh为偏置项,
为权重矩阵,bh为偏置项,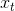 为当前时刻的输入特征,
为当前时刻的输入特征, 为记忆体上一时刻存储的状态信息,tanh为激活函数。
为记忆体上一时刻存储的状态信息,tanh为激活函数。
当前时刻循环核的输出特征![]() ,其中
,其中![]() 为权重矩阵、by为偏置项、softmax为激活函数,其实就相当于一层全连接。
为权重矩阵、by为偏置项、softmax为激活函数,其实就相当于一层全连接。
在训练过程中,记忆体的个数可由我们任意指定,从而改变记忆容量。当记忆体的个数被指定、输入输出 维度被指定,周围这些待训练参数的维度也就被限定了。
维度被指定,周围这些待训练参数的维度也就被限定了。
在前向传播时,记忆体内存储的状态信息在每个时刻都被刷新,而三个参数矩阵![]() 和两个偏置项bh、by自始至终都是固定不变的。
和两个偏置项bh、by自始至终都是固定不变的。
在反向传播时,三个参数矩阵和两个偏置项由梯度下降法更新。
进一步了解循环核,让循环核按时间步展开,就是把循环核按照时间轴方向展开,则有如下图:
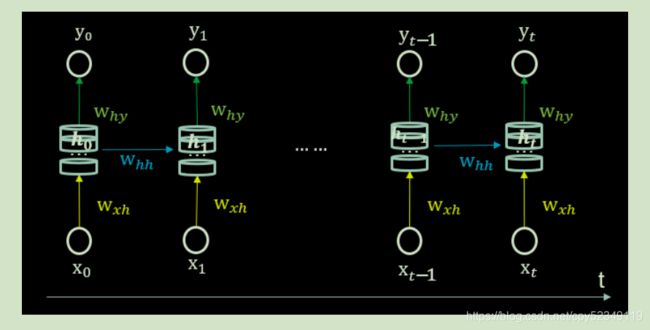
可见每个时刻记忆体状态信息ht被刷新(输入新的数据),记忆体周围的参数矩阵和两个偏置项是固定不变的,我们训练优化的就是这些参数矩阵。训练完成后,使用效果最好的参数矩阵执行前向传播,然后输出预测结果。其实这和我们人类的预测是一致的:我们脑中的记忆体每个时刻都根据当前的输入而更新,当前的预测推理是根据我们以往的知识积累固化下来的“参数矩阵”进行的推理判断。
至此我们大致明白了循环神经网络的整个训练过程,从输入到循环层,再从循环层到输出,最终目的是为了训练出最优的参数矩阵以实现最好的预测。而循环层类比于卷积层,也可以有多个循环层以提取足够的特征,但又不像卷积那么复杂,需要考虑批标准化、最大池化等操作。
3、代码实现
得到循环神经网络的前向传播结果之后,和其他神经网络模型基本类似,会定义损失函数,使用反向传播梯度下降法训练模型。而唯一的区别在于,由于它每个时刻的节点都可能有一个输出,故循环神经网络的总损失为所有时刻(或部分时刻)的损失加总。
在tensorflow中我们可以调用函数SimpleRNN实现循环神经网络的训练。tf.keras.layers.SimpleRNN(神经元个数,activation='激活函数',return_sequences=是否每个时刻输出ht到下一层)
- 神经元个数,即循环核记忆体的个数
- return_sequences:在输出序列中,返回最后时间步的输出值ht还是返回全部时间步的输出。False返回最后时刻,True返回全部时刻。当下一层依然是RNN层,通常是True,否则为False。
循环神经网络最典型的应用就是利用历史数据预测下一时刻将发生什么,即根据以前见过的历史规律做预测。如输入一个字母预测下一个字母----->输入a预测出b、输入b预测出c、输入c预测出d、输入d预测出e、输入e预测出a。下面我们用代码来实现这一循环神经网络预测过程(应用六步法)。
# 一、import相关模块
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense,SimpleRNN
from matplotlib import pyplot as plt
# 二、区分训练集和测试集
input_words = "abcde"
word_to_id = {"a":0 , "b":1 , "c":2 , "d":3 , "e":4}
# 由于字母为类别型变量,这里做了独热编码的处理
id_to_onehot = {0:[1.,0.,0.,0.,0.],1:[0.,1.,0.,0.,0.],2:[0.,0.,1.,0.,0.],
3:[0.,0.,0.,1.,0.],4:[0.,0.,0.,0.,1.]}
x_train = [id_to_onehot[word_to_id['a']],id_to_onehot[word_to_id['b']],
id_to_onehot[word_to_id['c']],id_to_onehot[word_to_id['d']],
id_to_onehot[word_to_id['e']]]
y_train = [word_to_id['b'],word_to_id['c'],word_to_id['d'],word_to_id['e'],word_to_id['a']]
#将训练集和测试集按照指定的随机种子打乱
np.random.seed(123)
np.random.shuffle(x_train)
np.random.seed(123)
np.random.shuffle(y_train)
tf.random.set_seed(123)
'''使x_train符合SimpleRNN的输入要求:[送入样本数,循环核展开时间步数,每个时间步输入特征数]
这里是整个数据集送入,样本数是len(x_train);每输入一个字母即输出一个结果,循环核时间展开步数为1;表示为热度编码输入特征数为5个,则每个时间步输入特征数为5'''
x_train = np.reshape(x_train,(len(x_train),1,5))
y_train = np.array(y_train)
# 三、model=tf.keras.Sequential搭建神经网络框架
model = tf.keras.Sequential([SimpleRNN(3),Dense(5,activation='softmax')])
# 四、在model.compile中配置训练方法
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 五、执行训练过程
history = model.fit(x_train,y_train,batch_size=32,epochs=100)
# 六、model.summary
model.summary()
执行后训练之后,可以看下训练的accuracy和loss曲线
# 显示acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
loss = history.history['loss']
plt.figure(figsize=(10,6))
plt.subplot(1,2,1)
plt.plot(acc,label="TrainingSet's Acc")
plt.title("TrainingSet Acc")
plt.legend()
plt.subplot(1,2,2)
plt.plot(loss,label="TrainingSet's Loss")
plt.title("TrainingSet Loss")
plt.legend()
plt.show()最后,对于训练好的模型我们加以模拟预测,以考究模型的可用性和准确性
# 进行模拟预测
predNum = int(input("input the number of test alphabet:"))
for i in range(predNum):
alphabet1 = input("input test alphabet:")
alphabet = id_to_onehot[word_to_id[alphabet1]]
# 使alphabet符合SimpleRNN的输入要求:[输入样本数,时间展开步数,输入特征数]
alphabet = np.reshape(alphabet,(1,1,5))
result = model.predict([alphabet])
pred = np.argmax(result,axis=1)
pred = int(pred)
tf.print(alphabet1 + "——>" + input_words[pred])模拟预测如下,基本可实现精准预测。

本文参考:北京大学课程《人工智能实践:Tensorflow笔记》