Focal Self-attention for Local-Global Interactions inVision Transformers
Focal Self-attention for Local-Global Interactions in Vision Transformers
Jianwei Yang1, Chunyuan Li1, Pengchuan Zhang1, Xiyang Dai2, Bin Xiao2, Lu Yuan2, Jianfeng Gao1
1 Microsoft Research at Redmond, 2 Microsoft Cloud + AI
https://arxiv.org/pdf/2107.00641.pdf
目录
Abstract
Introduction
Method
Abstract
Recently, Vision Transformer and its variants have shown great promise on various computer vision tasks. The ability of capturing short- and long-range visual dependencies through self-attention is the key to success.
But it also brings challenges due to quadratic computational overhead, especially for the high-resolution vision tasks (e.g., object detection). Many recent works have attempted to reduce the computational and memory cost and improve performance by applying either coarse-grained global attentions or fine-grained local attentions. However, both approaches cripple the modeling power of the original self-attention mechanism of multi-layer Transformers, thus leading to sub-optimal solutions.
In this paper, we present focal self-attention, a new mechanism that incorporates both fine-grained local and coarse-grained global interactions. In this new mechanism, each token attends its closest surrounding tokens at fine granularity and the tokens far away at coarse granularity, and thus can capture both short- and long-range visual dependencies efficiently and effectively. With focal self-attention, we propose a new variant of Vision Transformer models, called Focal Transformer, which achieves superior performance over the state-of-the-art (SoTA) vision Transformers on a range of public image classification and object detection benchmarks.
In particular, our Focal Transformer models with a moderate size of 51.1M and a larger size of 89.8M achieve 83.5% and 83.8% Top-1 accuracy, respectively, on ImageNet classification at 224 × 224. When employed as the backbones, Focal Transformers achieve consistent and substantial improvements over the current SoTA Swin Transformers [44] across 6 different object detection methods. Our largest Focal Transformer yields 58.7/58.9 box mAPs and 50.9/51.3 mask mAPs on COCO mini-val/test-dev, and 55.4 mIoU on ADE20K for semantic segmentation, creating new SoTA on three of the most challenging computer vision tasks.
1. 背景介绍:Transformer 的成功和特点。
最近,Vision Transformer 及其变体在各种计算机视觉任务中显示出了巨大的前景。通过自注意力捕捉短距离和长距离视觉依赖的能力是成功的关键。
2. 研究动机:Transformer 在 CV 中的问题,现有方法怎么解决的,但这些方法又存在什么问题。
但它由于二次方计算复杂度,特别是对高分辨率视觉任务 (例如,目标检测) 提出了巨大挑战。最近的许多工作都试图通过应用粗粒度的全局注意力或细粒度的局部注意力来降低计算和内存成本并提高性能。然而,这两种方法都削弱了多层变压器原始自注意机制的建模能力,从而导致次优解决方案。
3. 研究方法:核心思想,具体方法,应用范畴。
本文提出了 focal self-attention,这是一种结合了细粒度局部交互和粗粒度全局交互的新机制。
在这个新的机制中,每个 token 以细粒度关注其最近的周围 token,以粗粒度关注其远的周围 token,从而可以有效地捕获短期和长期的可视依赖关系。
基于焦点自注意,提出了 focal Transformer,在一系列公共图像分类和目标检测基准上实现了优于先进的 (SoTA) ViT 的性能。
4. 实验结果:在图像分类,目标识别,语义分割对结果。
图像分类方面,Focal Transformer 模型的中等尺寸为 51.1M,较大尺寸为 89.8M,在 224 × 224 的 ImageNet 分类精度上分别达到 83.5% 和 83.8% 的 Top-1 精度。
目标检测方面,当 Focal Transformer 被用作 backbone 时,在 6 种不同的目标检测方法上,Focal Transformer 比当前的 SoTA Swin Transformer [44]实现了一致和实质性的改进。
语义分割方面,最大的 Focal Transformer 在 COCO mini-val/test-dev上产生58.7/58.9 box mAPs 和 50.9/51.3 mask mAPs,在 ADE20K上产生 55.4 mIoU,在三个最具挑战性的计算机视觉任务上创建新的SoTA。
Introduction
Nowadays, Transformer [60] has become a prevalent model architecture in natural language processing (NLP) [22, 6]. In the light of its success in NLP, there is an increasing effort on adapting it to computer vision (CV) [48, 51]. Since its promise firstly demonstrated in Vision Transformer (ViT) [23], we have witnessed a flourish of full-Transformer models for image classification [57, 63, 67, 44, 80, 59], object detection [9, 91, 84, 20] and semantic segmentation [61, 65]. Beyond these static image tasks, it has also been applied on various temporal understanding tasks, such as action recognition [41, 83, 11], object tracking [15, 62], scene flow estimation [39].
第一段,ViT 大趋势:
目前,Transformer 已成为自然语言处理 (natural language processing, NLP) 中流行的模型体系结构[22,6]。鉴于其在自然语言处理中的成功,人们越来越努力地将其适应于计算机视觉 (CV)[48,51]。自 Vision Transformer (ViT) 首次展示其前景以来,见证了在图像分类,目标检测和语义分割等方面的全 Transformer 模型的蓬勃发展。除了这些静态图像任务,它还应用于各种时间理解任务,如动作识别,目标跟踪,场景流估计。
In Transformers, self-attention is the key component making it unique from the widely used convolutional neural networks (CNNs) [38]. At each Transformer layer, it enables the global contentdependent interactions among different image regions for modeling both short- and long-range dependencies. Through the visualization of full self-attentions, we indeed observe that it learns to attend local surroundings (like CNNs) and the global contexts at the same time (See the left side of Fig. 1).
Nevertheless, when it comes to high-resolution images for dense predictions such as object detection or segmentation, a global and fine-grained self-attention becomes non-trivial due to the quadratic computational cost with respect to the number of grids in feature maps.
Recent works alternatively exploited either a coarse-grained global self-attention [63, 67] or a fine-grained local self-attention [44, 80, 59] to reduce the computational burden. However, both approaches cripple the power of the original full self-attention i.e., the ability to simultaneously model short- and long-range visual dependencies, as demonstrated on the left side of Fig. 1.

第二段,背景及动机:分为三个层次
1. ViT 介绍:在 Transformers 中,自注意力是其独特于广泛使用的卷积神经网络的关键组成部分。在每个 Transformer 层,它支持不同图像区域之间的全局内容相关交互,以建模短距离和长距离依赖关系。通过可视化,作者确实观察到 Transformer 学会了同时关注局部环境和全局语境 (见图1左侧)。
2. 关键问题:然而,当涉及到用于密集预测 (如目标检测或分割) 的高分辨率图像时,由于特征地图中网格数量的二次方计算成本,全局和细粒度的自注意力就变得不那么重要了。
3. 研究现状:最近的研究要么利用粗粒度的全局自注意 [63,67],要么利用细粒度的局部自注意[44,80,59] 来减少计算负担。然而,这两种方法都削弱了最初的完全自注意力的能力,即同时建模短距离和长距离视觉依赖关系的能力,如图 1 左边所示。
[63] Wenhai Wang, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv, 2021.
[67] Haiping Wu, et al. Cvt: Introducing convolutions to vision transformers. arXiv, 2021.
[44] Ze Liu, et al. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv, 2021.
[80] Pengchuan Zhang, et al. Multiscale vision longformer: A new vision transformer for high-resolution image encoding. arXiv, 2021.
[59] Ashish Vaswani, et al. Scaling local self-attention for parameter efficient visual backbones. In 2021 CVPR, pages 12894–12904, 2021.
基本都是 arXiv 的文章,可见这个研究方向之火热!
In this paper, we present a new self-attention mechanism to capture both local and global interactions in Transformer layers for high-resolution inputs. Considering that the visual dependencies between regions nearby are usually stronger than those far away, we perform the fine-grained self-attention only in local regions while the coarse-grained attentions globally. As depicted in the right side of Fig. 1, a query token in the feature map attends its closest surroundings at the finest granularity as itself. However, when it goes to farther regions, it attends to summarized tokens to capture coarse-grained visual dependencies. The further away the regions are from the query, the coarser the granularity is. As a result, it can effectively cover the whole high-resolution feature maps while introducing much less number of tokens in the self-attention computation than that in the full self-attention mechanism. As a result, it has the ability to capture both short- and long-range visual dependencies efficiently. We call this new mechanism focal self-attention, as each token attends others in a focal manner. Based on the proposed focal self-attention, a series of Focal Transformer models are developed, by 1) exploiting a multi-scale architecture to maintain a reasonable computational cost for high-resolution images [63, 67, 44, 80], and 2) splitting the feature map into multiple windows in which tokens share the same surroundings, instead of performing focal self-attention for each token [59, 80, 44].
第三段,方法描述:
本文提出了一种新的自注意力机制来捕获高分辨率输入的 Transformer 层中的局部和全局交互。考虑到距离较近的区域之间的视觉依赖性往往强于距离较远的区域之间的视觉依赖性,本文的方法只在局部区域执行细粒度的自注意力,而在全局区域执行粗粒度的自注意力。如图 1 右侧所示,feature map 中的 query token 以最细的粒度与其周围的环境保持一致。但是,当它到达更远的区域时,它会注意 summarized tokens 以捕获粗粒度的可视依赖关系。区域离 query 越远,粒度就越粗。结果表明,与完全自注意力机制相比,该方法可以有效覆盖整个高分辨率特征图,同时在自注意力计算中引入的 token 数量要少得多。因此,它能够有效地捕获短距离和长距离的视觉依赖关系。这种新机制称之为 焦点自注意力 focal self-attention,因为每个 token 都以 focal 的方式关注其它 token。根据提出的 focal self-attention,本文开发一系列 Focal Transformer 模型,通过 1) 利用多尺度结构保持一个合理的计算成本高分辨率图像,和 2) 分裂的特征映射到多个窗口,其中 token 共享相同的环境,而不是对每个 token 进行集中的自注意力。
We validate the effectiveness of the proposed focal self-attention via a comprehensive empirical study on image classification, object detection and segmentation. Results show that our Focal Transformers with similar model sizes and complexities consistently outperform the SoTA Vision Transformer models across various settings.
Notably, our small Focal Transformer model with 51.1M parameters can achieve 83.5% top-1 accuracy on ImageNet-1K, and the base model with 89.8M parameters obtains 83.8% top-1 accuracy. When transferred to object detection, our Focal Transformers consistently outperform the SoTA Swin Transformers [44] for six different object detection methods. Our largest Focal Transformer model achieves 58.9 box mAP and 51.3 mask mAP on COCO test-dev for object detection and instance segmentation, respectively, and 55.4 mIoU on ADE20K for semantic segmentation. These results demonstrate that the focal self-attention is highly effective in modeling the local-global interactions in Vision Transformers.
最后,实验结果:
通过对图像分类、目标检测和分割的综合实证研究,验证了该方法的有效性。结果表明,Focal Transformer 在具有相似的模型尺寸和复杂性情况下,在各种设置中始终优于 SoTA Vision Transformer 模型。
参数为 51.1M 的 small Focal Transformer 模型在 ImageNet-1K 上可以达到 83.5% 的 top-1 精度,而参数为 89.8M 的基本模型可以达到 83.8% 的 top-1 精度。 Focal transformer 在六种不同的目标检测方法中始终优于 SoTA Swin transformer[44]。 对象检测和实例分割,Largest Focal Transformer 模型在 COCO 测试开发上实现了 58.9 box mAP 和51.3 mask mAP。用于语义分割,在 ADE20K 上实现了 55.4 mIoU。
Method
Model architecture
To accommodate the high-resolution vision tasks, our model architecture shares a similar multi-scale design with [63, 80, 44], which allows us to obtain high-resolution feature maps at earlier stages. As shown in Fig. 2, an image
is first partitioned into patches of size 4 × 4, resulting in H/4 × W/4 visual tokens with dimension 4 × 4 × 3.
Then, we use a patch embedding layer which consists of a convolutional layer with filter size and stride both equal to 4, to project these patches into hidden features with dimension d.
Given this spatial feature map, we then pass it to four stages of focal Transformer blocks. At each stage i ∈ {1, 2, 3, 4}, the focal Transformer block consists of Ni focal Transformer layers.
After each stage, we use another patch embedding layer to reduce the spatial size of feature map by factor 2, while the feature dimension is increased by 2.
For image classification tasks, we take the average of the output from last stage and send it to a classification layer.
For object detection, the feature maps from last 3 or all 4 stages are fed to the detector head, depending on the particular detection method we use.
The model capacity can be customized by varying the input feature dimension d and the number of focal Transformer layers at each stage {N1, N2, N3, N4}.

整体结构描述:从 embedding 获得到 focal Transformer block 堆叠模式
1. 为了适应高分辨率视觉任务,本文的模型架构与 [63,80,44] 共享类似的多尺度设计,即如图 2 所示,首先将图像分割成大小为 4 × 4 的 patches,得到 H/4 × W/4 个视觉 token,尺寸为 4 × 4 × 3。
2. 然后,使用一个由滤波器大小和步幅都为 4 的卷积层组成的 patch embedding 层,将这些 patch 投射到维数为 d 的隐藏特征中。
3. 给定这个空间特征映射,将其传递到 focal Transformer block 的四个阶段。在每个阶段i∈{1,2,3,4},focal Transformer block 由 Ni focal Transformer 层组成。
4. 在每个阶段之后,使用另一个 patch embedding layer 将 feature map 的空间大小减少 2 倍,同时feature dimension 增加 2 倍。
5. 对于图像分类任务,取最后一阶段输出结果的平均值,然后将其发送到分类层。
6. 对于目标检测,最后 3 个或所有 4 个阶段的特征映射被送入检测器头部,这取决于使用的特定检测方法。
7. 模型容量可以通过改变输入特征维数 d 和每个阶段 {N1, N2, N3, N4} 的 focal Transformer 层数来定制。
Standard self-attention can capture both short- and long-range interactions at fine-grain, but it suffers from high computational cost when it performs the attention on high-resolution feature maps as noted in [80]. Take stage 1 in Fig. 2 as the example. For the feature map of size H/4 × W/4 ×d, the complexity of self-attention is O(( H/4 × W/4 ) 2d), resulting in an explosion of time and memory cost considering min(H, W) is 800 or even larger for object detection. In the next, we describe how we address this with the proposed focal self-attention.
过度段:引出提出 focal self-attention 的一个动机
标准的自注意力可以捕获细粒度的短距离和长距离交互,在高分辨率 feature map 上进行注意计算时,它的计算成本较高。以图 2 中的阶段 1 为例。对于大小为 H/4 × W/4 × d 的特征图,自注意力的复杂度为 O((H/4 × W/4)^2 d),考虑最小 (H, W) 为 800 甚至更大的目标检测,导致时间和内存成本的爆炸。在接下来的文章中,将描述如何通过提出的 focal self-attention 来解决这个问题。
Focal Self-attention
In this paper, we propose focal self-attention to make Transformer layers scalable to high-resolution inputs. Instead of attending all tokens at fine-grain, we propose to attend the fine-grain tokens only locally, but the summarized ones globally. As such, it can cover as many regions as standard self-attention but with much less cost. In Fig. 3, we show the area of receptive field for standard self-attention and our focal self-attention when we gradually add more attended tokens. For a query position, when we use gradually coarser-grain for its far surroundings, focal self-attention can have significantly larger receptive fields at the cost of attending the same number of visual tokens than the baseline.
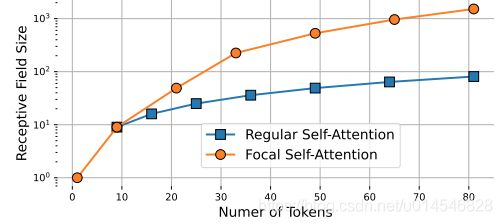
本文提出了 focal self-attention,使 Transformer 层可扩展到高分辨率输入。本文不建议在细粒度上参加所有的 token,而是建议只在局部加入细粒度 token,而在全局上加入 summarized token。因此,它可以覆盖与标准的 self-attention 一样多的地区,但成本要低得多。图 3 展示了标准 self-attention 的接受域区域和本文方法逐渐添加更多被注意 token 时的 focal self-attention 区域。对于一个 query 位置,当对其远处的环境使用逐渐粗粒度的方法时,focal self-attention 可以有更大的接受域。
最后那句,没理解啥意思。
Our focal mechanism enables long-range self-attention with much less time and memory cost, because it attends a much smaller number of surrounding (summarized) tokens. In practice, however, extracting the surrounding tokens for each query position suffers from high time and memory cost since we need to duplicate each token for all queries that can get access to it. This practical issue has been noted by a number of previous works [59, 80, 44] and the common solution is to partition the input feature map into windows. Inspired by them, we resort to perform focal self-attention at the window level. Given a feature map of x ∈ R^{M×N×d} with spatial size M × N, we first partition it into a grid of windows with size sp × sp. Then, we find the surroundings for each window rather than individual tokens. In the following, we elaborate the window-wise focal self-attention.
子问题:focal self-attention 中存在的新问题
本文的 focal 机制能够以更少的时间和记忆成本实现长距离的 self-attention,因为它只关注较少数量的周围 (总结) token。然而,在实践中,为每个 query 位置提取周围的 token 会耗费大量的时间和内存,因为需要为所有能够访问它的 query 复制每个 token。这个实际问题已经被许多以前的作品注意到了,常见的解决方案是将输入特征映射划分到窗口中。在这些工作的启发下,本文诉诸于在窗口层面进行 focal self-attention。对于 x ∈ R^{M×N×d} 空间大小为 M×N 的特征映射,首先将其划分为一个大小为 sp × sp 的窗口网格。然后,寻找每个窗口的周围环境,而不是单个 token。下面将详细阐述窗口式的 focal self-attention。
Window-wise Attention
An illustration of the proposed window-wise focal self-attention is shown in Fig. 4. We first define three terms for clarity:
• Focal levels L – the number of granularity levels we extract the tokens for our focal self-attention. In Fig. 1, we show 3 focal levels in total for example.
• Focal window size
– the size of sub-window on which we get the summarized tokens at level l ∈ {1, ..., L}, which are 1, 2 and 4 for the three levels in Fig. 1.
• Focal region size
– the number of sub-windows horizontally and vertically in attended regions at level l, and they are 3, 4 and 4 from level 1 to 3 in Fig. 1.

术语说明:
图 4 显示了基于窗口的 focal self-attention 示意图。为了清晰起见,首先定义三个术语:
• Focal levels L - focal self-attention 提取 token 的粒度级别的数量。在图 1 中,总共显示了 3 个Focal levels。
• Focal 窗口大小 ![]() -子窗口的大小,在其上得到 l 级 ∈{1,…, L},对于图 1 中的三个级别,
-子窗口的大小,在其上得到 l 级 ∈{1,…, L},对于图 1 中的三个级别, ![]() 分别为 1、2、4。
分别为 1、2、4。
• Focal 区域大小 ![]() - 在第 1 级被关注的区域中,水平和垂直方向上的子窗口数量,在图 1 中从第 1 级到第 3 级,它们分别是 3、4 和4。
- 在第 1 级被关注的区域中,水平和垂直方向上的子窗口数量,在图 1 中从第 1 级到第 3 级,它们分别是 3、4 和4。
With the above three terms {L,
有了以上三个术语 {L, ![]() ,
, ![]() },可以指定 focal self-attention 模块,进行如下两个主要步骤:
},可以指定 focal self-attention 模块,进行如下两个主要步骤:
- Sub-window pooling
Assume the input feature map
, where M × N are the spatial dimension and d is the feature dimension. We perform sub-window pooling for all L levels. For the focal level l, we first split the input feature map x into a grid of sub-windows with size
to pool the sub-windows spatially by:
池化操作:
假设输入特征映射 ![]() ,其中 M×N 为空间维数,d 为特征维数。为所有的 L 层执行子窗口池化。对于 focal 级别 l,首先将输入特征映射 x 分割成大小为
,其中 M×N 为空间维数,d 为特征维数。为所有的 L 层执行子窗口池化。对于 focal 级别 l,首先将输入特征映射 x 分割成大小为 ![]() ×
×![]() 的子窗口网格。然后使用一个简单的线性层
的子窗口网格。然后使用一个简单的线性层 ![]() 对子窗口进行空间池化,即公式(1)。
对子窗口进行空间池化,即公式(1)。
The pooled feature maps
at different levels l provide rich information at both fine-grain and coarse-grain. Since we set
额外说明:
在不同层次 l 上的集合特征映射 ![]() 提供了丰富的细粒度和粗粒度信息。因为对于第一 focal level 设置
提供了丰富的细粒度和粗粒度信息。因为对于第一 focal level 设置 ![]() 为 1,级与输入特征映射具有相同粒度,所以不需要执行任何子窗口池化。考虑到 focal 窗口的大小通常很小 (在本文的设置中最大为 7),由这些子窗口池化引入的额外参数的数量是相当微不足道的。
为 1,级与输入特征映射具有相同粒度,所以不需要执行任何子窗口池化。考虑到 focal 窗口的大小通常很小 (在本文的设置中最大为 7),由这些子窗口池化引入的额外参数的数量是相当微不足道的。
- Attention computation
Once we obtain the pooled feature maps

To perform focal self-attention, we need to first extract the surrounding tokens for each query token in the feature map. As we mentioned earlier, tokens inside a window partition
share the same set of surroundings. For the queries inside the i-th window
, we extract the
keys and values from
and
around the window where the query lies in, and then gather the keys and values from all L to obtain
and
, where s is the sum of focal region from all levels, i.e.,,
. Note that a strict version of focal self-attention following Fig. 1 requires to exclude the overlapped regions across different levels. In our model, we intentionally keep them in order to capture the pyramid information for the overlapped regions.
Finally, we follow [44] to include a relative position bias and compute the focal self-attention for Qi by:
where
is the learnable relative position bias.
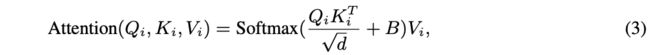
注意力计算过程:
1. 得到所有 L 级的集合特征映射后,用三个线性投影层计算在第 1 level 的 query,和所有 level 的 key 和 value,这和传统 self-attention 一样(公式(2))。
2. 为了执行 focal self-attention,首先需要为 feature map 中的每个 query token 提取周围的 token。窗口分区 ![]() 中的 token 共享同一组环境。对于第 i 窗口
中的 token 共享同一组环境。对于第 i 窗口 ![]() 内的 query,从窗口 query 所在窗口周围的
内的 query,从窗口 query 所在窗口周围的 ![]() and
and ![]() 提取
提取 ![]() 的 key 和 value,然后收集所有的 key 和 value L,得到
的 key 和 value,然后收集所有的 key 和 value L,得到 ![]() 和
和 ![]() 。
。
严格的说,focal self-attention 后,需要排除不同层次的重叠区域。在本文的模型中,有意地保留重叠区域,以捕获重叠区域的金字塔信息。
3. 最后,在计算注意力是,加上了相对位置偏置,公式(3)。
Complexity Analysis
For the input feature map
, we have
sub-windows at focal level l. For each sub-window, the pooling operation in Eq.1 has the complexity of
. Aggregating all sub-windows brings us
. Then for all focal levels, we have the complexity of
in total, which is independent of the sub-window size at each focal level. Regarding the attention computation in Eq. 3, the computational cost for a query window
, and
for the whole input feature map. To sum up, the overall computational cost for our focal self-attention becomes
. In an extreme case, one can set
to ensure global receptive field for all queries (including both corner and middle queries) in this layer.
Model Configuration
We consider three different network configurations for our focal Transformers. Here, we simply follow the design strategy suggested by previous works [63, 67, 44], though we believe there should be a better configuration specifically for our focal Transformers. Specifically, we use similar design to the Tiny, Small and Base models in Swin Transformer [44], as shown in Table 1. Our models take 224 × 224 images as inputs and the window partition size is also set to 7 to make our models comparable to the Swin Transformers. For the focal self-attention layer, we introduce two levels, one for fine-grain local attention and one for coarse-grain global attention. Expect for the last stage, the focal region size is consistently set to 13 for the window partition size of 7, which means that we expand 3 tokens for each window partition. For the last stage, since the whole feature map is 7 × 7, the focal region size at level 0 is set to 7, which is sufficient to cover the entire feature map. For the coarse-grain global attention, we set its focal window size same to the window partition size 7, but gradually decrease the focal region size to get {7, 5, 3, 1} for the four stages. For the patch embedding layer, the spatial reduction ratio pi for four stages are all {4, 2, 2, 2}, while Focal-Base has a higher hidden dimension compared with Focal-Tiny and Focal-Small.
考虑了三种不同的网络配置:Tiny、Smal l和 Base 模型相似的设计,如表 1 所示。模型采用 224x224 图像作为输入,窗口分区大小设置为 7。
对于 focal self-attention layer,引入了两个层次,一个是细粒度局部注意,一个是粗粒度全局注意。除了最后一个阶段,focal 区域大小始终设置为 13,而窗口分区大小为 7,这意味着为每个窗口分区展开 3 个 tokens。在最后一阶段,由于整个 feature map 为7x7,所以将 level 0 的 focal region size 设置为 7,足以覆盖整个 feature map。对于粗粒度全局注意,将其焦点窗口大小设置为与窗口分区大小 7 相同,但逐步减小 focal 区域大小,四个阶段为 {7,5,3,1}。对于 patch embedding 层,四个阶段的空间缩减比均为 {4,2,2,2},而 Focal-Base 的隐藏维数高于 Focal-Tiny和 Focal-Small。
