TransReID学习记录
1、TransReID论文链接
原文:TransReID: Transformer-based Object Re-Identification
代码:GitHub - damo-cv/TransReID: [ICCV-2021] TransReID: Transformer-based Object Re-Identification
作者:阿里巴巴&浙江大学
本文是罗浩大佬把视觉Transformer的ViT应用在ReID领域的研究工作,在多个ReID基准数据集上取得了超过CNN的性能。成功刷榜的VIT reid。
论文思路:
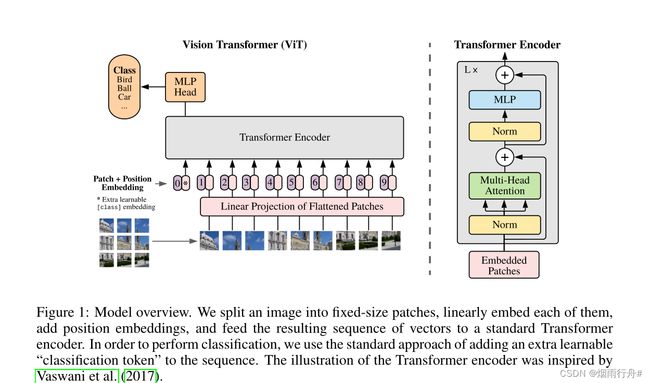
1、Overlapping Patches
本文的思想核心,在Swin Transformer中提到如果仅仅是平分图像为多个patch,那么由于自注意力的原因,导致边界信息被丢下。在下面代码中,本文提出了Overlapping Patches,相比较平分patch有很大的优势
# 接下来要把图片转换成Patch,一种做法是直接把Image转化成Patch,另一种做法是把Backbone输出的特征转化成Patch。
class PatchEmbed(nn.Module):
""" Image to Patch Embedding 图片切块分为patch 按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版
Transformer 中的 sincossincossincos 编码,而是直接设置为可学习的 Positional Encoding。对训练好的 Positional Encoding 进行可视化
位置越接近,往往具有更相似的位置编码。此外,出现了行列结构,同一行/列中的 patch 具有相似的位置编码。 embed_dim怎么计算得到的
"""
# 1) 直接把Image转化成Patch:
# 输入的x的维度是:(B, C, H, W)
# 输出的PatchEmbedding的维度是:(B, 14*14, 768),768表示embed_dim,14*14表示一共有196个Patches。
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
# kernel_size=块大小,即每个块输出一个值,类似每个块展平后使用相同的全连接层进行处理
# 输入维度为3,输出维度为块向量长度
# 与原文中:分块、展平、全连接降维保持一致
# 输出为[B, C, H, W]
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# [B, C, H, W] -> [B, C, H*W] ->[B, H*W, C]
x = self.proj(x).flatten(2).transpose(1, 2)
# 展平为位置序列,.transpose(1, 2)与.transpose(2,1)在实现结果上是没有区别的
return x
# 2) 把Backbone输出的特征转化成Patch:
# 输入的x的维度是:(B, C, H, W)
# 得到Backbone输出的维度是:(B, feature_size, feature_size, feature_dim)
# 输出的PatchEmbedding的维度是:(B, feature_size, feature_size, embed_dim),一共有feature_size * feature_size个Patches。
class HybridEmbed(nn.Module):
""" CNN Feature Map Embedding 混合嵌入
Extract feature map from CNN, flatten, project to embedding dim.
从CNN提取特征图,展平,投影到嵌入dim。
"""
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
# FIXME这是确定输出特性的确切尺寸的一种简单但最可靠的方法
# map for all networks, the feature metadata has reliable channel and stride info, but using
# stride to calc feature dim requires info about padding of each stage that isn't captured.
# 对于所有网络,功能元数据都有可靠的通道和步幅信息,但使用步幅到计算功能dim需要有关未捕获的每个阶段填充的信息。
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))
if isinstance(o, (list, tuple)):
o = o[-1] # last feature if backbone outputs list/tuple of features
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
if hasattr(self.backbone, 'feature_info'):
feature_dim = self.backbone.feature_info.channels()[-1]
else:
feature_dim = self.backbone.num_features
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Conv2d(feature_dim, embed_dim, 1) # projection 映射,投影
def forward(self, x):
x = self.backbone(x)
if isinstance(x, (list, tuple)):
x = x[-1] # last feature if backbone outputs list/tuple of features
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class PatchEmbed_overlap(nn.Module):
""" Image to Patch Embedding with overlapping patches
"""
def __init__(self, img_size=224, patch_size=16, stride_size=20, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
stride_size_tuple = to_2tuple(stride_size)
self.num_x = (img_size[1] - patch_size[1]) // stride_size_tuple[1] + 1 # python中“//”是一个算术运算符,表示整数除法,
# 它可以返回商的整数部分(向下取整) (224-16)//20+1=10+1=11
self.num_y = (img_size[0] - patch_size[0]) // stride_size_tuple[0] + 1
print('using stride: {}, and patch number is num_y{} * num_x{}'.format(stride_size, self.num_y, self.num_x))
num_patches = self.num_x * self.num_y # 总的patch数
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride_size)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.InstanceNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
x = x.flatten(2).transpose(1, 2) # [64, 8, 768]
return x
2、Position Embeddings.
本文的Position Embeddings.并不是原创新的,也是采用了VIT中最常用的方法。
Fixed Positional Encodings:即将各个位置的标志设定为固定值,一般是采用不同频率的Sin函数来表示。
Learnable Positional Encoding:即训练开始时,初始化一个和输入token数目一致的tensor,这个tensor会在训练过程中逐步更新
# posemb代表未插值的位置编码权值,posemb_tok为位置编码的token部分,posemb_grid为位置编码的插值部分。
# 首先把要插值部分posemb_grid给reshape成(1, gs_old, gs_old, -1)的形式,再插值成(1, gs_new, gs_new, -1)的形式,
# 最后与token部分在第1维度拼接在一起,得到插值后的位置编码posemb。
def resize_pos_embed(posemb, posemb_new, hight, width):
# Rescale the grid of position embeddings when loading from state_dict. Adapted from
# https://github.com/google-research/vision_transformer/blob/00883dd691c63a6830751563748663526e811cee/vit_jax/checkpoint.py#L224
ntok_new = posemb_new.shape[1]
posemb_token, posemb_grid = posemb[:, :1], posemb[0, 1:]
ntok_new -= 1
gs_old = int(math.sqrt(len(posemb_grid)))
print('Resized position embedding from size:{} to size: {} with height:{} width: {}'.format(posemb.shape,
posemb_new.shape, hight,
width))
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(posemb_grid, size=(hight, width), mode='bilinear')
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, hight * width, -1)
posemb = torch.cat([posemb_token, posemb_grid], dim=1)
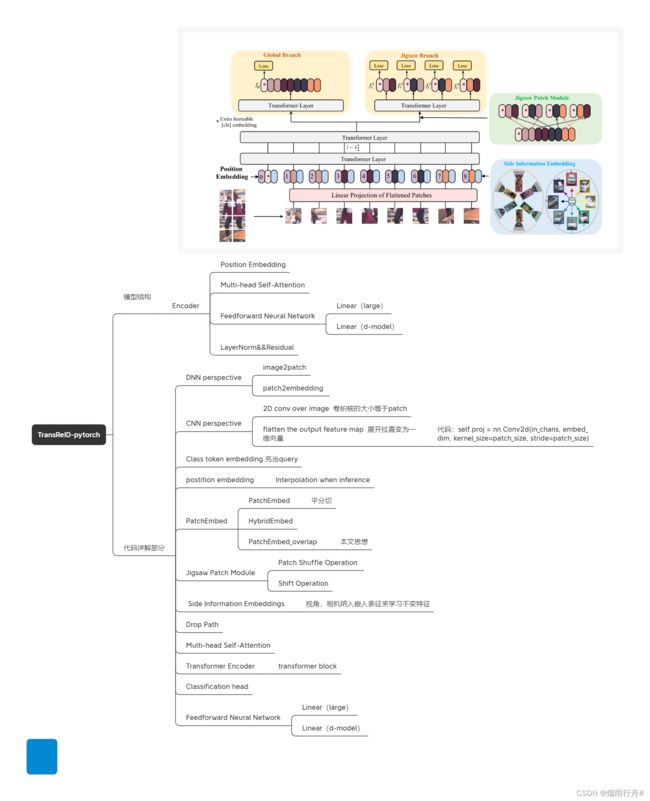
return posemb3、Jigsaw Patch Module
我们提出了一个拼图补丁模块(JPM)来打乱补丁嵌入,然后将它们重新组合成不同的部分,每个部分包含整个图像的多个随机补丁嵌入。此外,在训练中引入额外的扰动也有助于提高目标ReID模型的鲁棒性。
(1)Patch Shuffle Operation
(2)Shift Operation
# The first m patches(except for [cls] token) are moved to the end,
# Patch Shuffle Operation The shifted patches are further shuffled by the patch shuffle
# operation with k groups.
def shuffle_unit(features, shift, group, begin=1):
batchsize = features.size(0)
dim = features.size(-1)
# Shift Operation
feature_random = torch.cat([features[:, begin - 1 + shift:], features[:, begin:begin - 1 + shift]], dim=1)
x = feature_random
# The first m patches(except for [cls] token) are moved to the end,
# Patch Shuffle Operation The shifted patches are further shuffled by the patch shuffle
# operation with k groups.
try:
x = x.view(batchsize, group, -1, dim)
except:
x = torch.cat([x, x[:, -2:-1, :]], dim=1)
x = x.view(batchsize, group, -1, dim)
x = torch.transpose(x, 1, 2).contiguous() ##相邻
x = x.view(batchsize, -1, dim)
return x
4、 Side Information Embeddings
class TransReID(nn.Module):
""" Transformer-based Object Re-Identification
这里把VIT写成了TransReID
"""
def __init__(self, img_size=224, patch_size=16, stride_size=16, in_chans=3, num_classes=1000, embed_dim=768,
depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., camera=0,
view=0,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, local_feature=False, sie_xishu=1.0):
# 得到分块后的Patch的数量:
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.local_feature = local_feature
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed_overlap(
img_size=img_size, patch_size=patch_size, stride_size=stride_size, in_chans=in_chans,
embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
# 一开始定义成(1, 1, 768),之后再变成(B, 1, 768)。
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 定义位置编码:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.cam_num = camera
self.view_num = view
self.sie_xishu = sie_xishu # 侧信息嵌入(SIE)
# Initialize SIE Embedding
if camera > 1 and view > 1:
self.sie_embed = nn.Parameter(torch.zeros(camera * view, 1, embed_dim))
trunc_normal_(self.sie_embed, std=.02)
print('camera number is : {} and viewpoint number is : {}'.format(camera, view))
print('using SIE_Lambda is : {}'.format(sie_xishu))
elif camera > 1:
self.sie_embed = nn.Parameter(torch.zeros(camera, 1, embed_dim))
trunc_normal_(self.sie_embed, std=.02)
print('camera number is : {}'.format(camera))
print('using SIE_Lambda is : {}'.format(sie_xishu))
elif view > 1:
self.sie_embed = nn.Parameter(torch.zeros(view, 1, embed_dim))
trunc_normal_(self.sie_embed, std=.02)
print('viewpoint number is : {}'.format(view))
print('using SIE_Lambda is : {}'.format(sie_xishu))
print('using drop_out rate is : {}'.format(drop_rate))
print('using attn_drop_out rate is : {}'.format(attn_drop_rate))
print('using drop_path rate is : {}'.format(drop_path_rate))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
# 把12个Block连接起来
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)5、transformer block
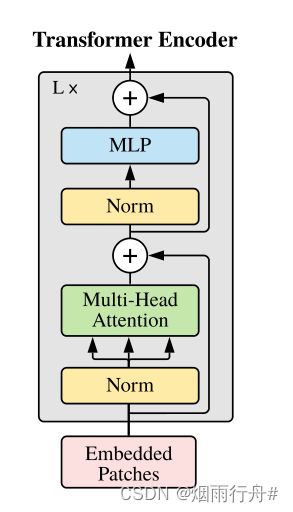
一共有 12个transformer block
# 先进行Norm,再Attention;进行drop path 再进行Norm,再通过FFN (MLP)。
class Block(nn.Module):
# Transformer Encoder Block
# |_________________________________________| |__________________|
# Embedded Patches ==> Layer Norm ==> Muliti-Head Attention + ==> Layer Norm ==> MLP + ==>
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
# Multi-head Self-attention
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
# DropPath
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
# Multi-head Self-attention, Add, LayerNorm
x = x + self.drop_path(self.attn(self.norm1(x)))
# Feed Forward, Add, LayerNorm
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
6、 Attention
# 注意力模块,也是多头注意力模块num_heads=8,8个头,初始化的超参数有 维度,多头的数目,qkv的偏置,随机drop
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
# 注意:比例因子在我的原始版本中是错误的,可以手动设置为与上一个权重兼容
# 计算 q,k,v 的转移矩阵
self.scale = qk_scale or head_dim ** -0.5
# # 输出 Q K V
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
# 最终的线性层
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
# 线性变换
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# 分割 query key value
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# Scaled Dot-Product Attention
# Matmul + Scale
attn = (q @ k.transpose(-2, -1)) * self.scale # @是一个操作符,表示矩阵-向量乘法
# SoftMax
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# Matmul
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
# 线性变换
x = self.proj(x)
x = self.proj_drop(x)
return x7、Drop Path
本文使用了Drop Path来提高模型的鲁棒性
DropPath正则化_烟雨行舟#的博客-CSDN博客
参考这篇
8、Class Token
为什么输入的tokens里要加一个额外的Learnable Embedding?
因为transformer输入为一系列的patch embedding,输出也是同样长的序列patch feature,但是最后进行类别的判断时不知道用哪一个feature,需要一个代表总体的feature,简单方法可以用avg pool,把所有的patch feature都考虑算出image feature。但是作者没有用这种方式,而是引入一个class token,在输出的feature后加上一个线性分类器就可以实现分类。class token在训练时随机初始化,然后通过训练学习得到。
参考原文链接:Vision Transformer(ViT) --TransReID学习记录(一)_陈朔怡的博客-CSDN博客_transreid代码
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 定义位置编码:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.cam_num = camera
self.view_num = view
self.sie_xishu = sie_xishu # 侧信息嵌入(SIE)
# Initialize SIE Embedding
if camera > 1 and view > 1:
self.sie_embed = nn.Parameter(torch.zeros(camera * view, 1, embed_dim))
trunc_normal_(self.sie_embed, std=.02)
print('camera number is : {} and viewpoint number is : {}'.format(camera, view))
print('using SIE_Lambda is : {}'.format(sie_xishu))
elif camera > 1:
self.sie_embed = nn.Parameter(torch.zeros(camera, 1, embed_dim))
trunc_normal_(self.sie_embed, std=.02)
print('camera number is : {}'.format(camera))
print('using SIE_Lambda is : {}'.format(sie_xishu))
elif view > 1:
self.sie_embed = nn.Parameter(torch.zeros(view, 1, embed_dim))
trunc_normal_(self.sie_embed, std=.02)
print('viewpoint number is : {}'.format(view))
print('using SIE_Lambda is : {}'.format(sie_xishu))
print('using drop_out rate is : {}'.format(drop_rate))
print('using attn_drop_out rate is : {}'.format(attn_drop_rate))
print('using drop_path rate is : {}'.format(drop_path_rate))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
# 把12个Block连接起来
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# Classifier head 表示层输出维度是representation_size,分类头输出维度是num_classes
self.fc = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
trunc_normal_(self.pos_embed, std=.02)
self.apply(self._init_weights)