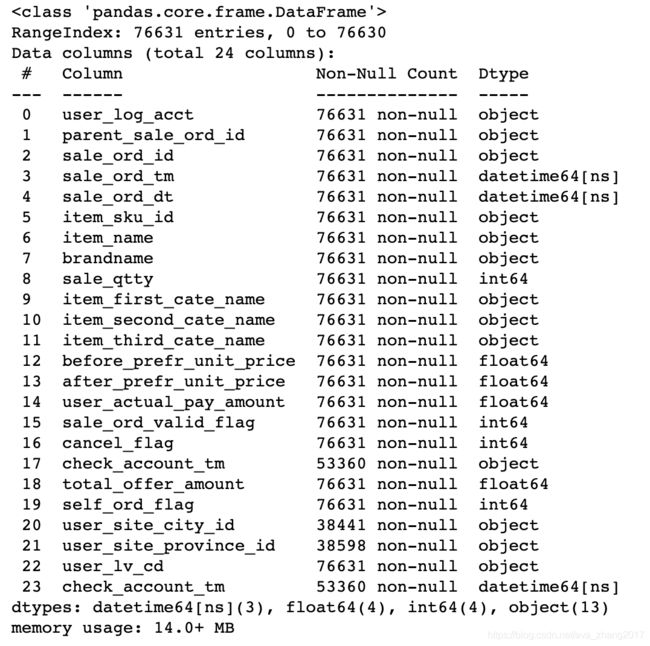
订单数据分析-实战
1. 京东订单数据准备
1.1 京东订单数据介绍
- 2020年5月25日
- 10%抽样数据
- 大家电-家用电器-冰箱
- 70K+
1.2 数据清洗
- 缺失值处理
用户城市和省份信息有部分缺失,部分订单的订单中支付时间为空值 - 数据逻辑错误
- 格式内容一致性
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from matplotlib.ticker import FuncFormatter
plt.rcParams['font.sans-serif']=['SimHei']
import warnings
warnings.filterwarnings('ignore')
order = r"/Users/zhangqin/Documents/python学习/笔记整理/京东数据分析/课件/京东订单实战/course_order_d.csv"
df = pd.read_csv(order,sep='\t', encoding="utf-8", dtype=str)
#查看缺失值
df.isnull().sum().sort_values(ascending = False)

#转换数据类型
df["sale_qtty"] = df["sale_qtty"].astype("int")
df["sale_ord_valid_flag"] = df["sale_ord_valid_flag"].astype("int")
df["cancel_flag"] = df["cancel_flag"].astype("int")
df["self_ord_flag"] = df["self_ord_flag"].astype("int")
df['before_prefr_unit_price'] = df['before_prefr_unit_price'].astype('float')
df['after_prefr_unit_price'] = df['after_prefr_unit_price'].astype('float')
df['user_actual_pay_amount'] = df['user_actual_pay_amount'].astype('float')
df['total_offer_amount'] = df['total_offer_amount'].astype('float')
df.loc[:,'check_account_tm '] = pd.to_datetime(df.loc[:,'check_account_tm'])
df.loc[:,'sale_ord_tm'] = pd.to_datetime(df.loc[:,'sale_ord_tm'])
df.loc[:,'sale_ord_dt'] = pd.to_datetime(df.loc[:,'sale_ord_dt'])
#缺失值&异常值处理
df = df[df["before_prefr_unit_price"]>=288]#筛选优惠前的价格在288元以上的数据
df = df.drop_duplicates(subset=["sale_ord_id"],keep="first")#按照订单去除重复项
df["user_site_city_id"] = df["user_site_city_id"].fillna("Not Given")
df["user_site_province_id"] = df["user_site_province_id"].fillna("Not Given")
df["total_actual_pay"] = df["sale_qtty"]*df["after_prefr_unit_price"]
2. 订单数据分析的基本思路
2.1 数据监控
对于订单数据,在业务中最常见的是使用可视化报表来监测订单关键指标的变化,并在一定维度上进行下钻
| 数据指标 | 维度细分 |
|---|---|
| 订单总量 | 有效订单、取消订单、待支付订单 |
| GMV(所有有效订单的总交易额) | … |
| 实际销售额 | … |
| 客单价 | … |
| 商品销售数量 | … |
| 用户数 | … |
| 复购率 | … |
| 支付时长 | … |
| 数据维度 | 具体解释 |
|---|---|
| 商品维度 | 不同类目的商品、同一类目不同净值的商品… |
| 时间维度 | 趋势变化、节假日及特殊日期 |
| 地区维度 | 商品偏好 |
| 用户维度 | 用户行为、用户画像 |
2.2 不同图表类型的应用场景
- 柱状图:适用场景是二维数据集(每个数据点包括两个值:x和y),但只有一个维度需要比较,用于显示一段时间内的数据变化或显示各项数据之间的比较情况,可以很好的反映数据的差异,但是只适用于规模不太大的数据
- 条形图:和柱状图类似,但是能更好的把重点放在选哟比较的维度上
- 堆积型的柱状图和条形图:不仅可以直观的看出每个系列的值,还能反映出系列的总和,尤其是当需要看某一单位的综合以及各系列值的比重时最适合
- 饼图:显示各项的大小与各项总和的比例。适用于简单的占比比例图,在不要求数据精细的情况下使用。
- 折线图:适合二维的大数据集,还是和多个二维数据集的比较。容易反映出数据变化的趋势。
- 散点图和气泡图:显示若干数据系列中各数值之间的关系,类似XY轴,判断两变量之间是否存在某种关联。散点图适用于三维数据集但是只需要比较其中的两个维度,如果再增加一个维度就可以使用气泡图
- 热力图:以特殊高亮的形式显示访客热衷的页面区域和访客所在的地理区域的图示,常用于地图和网站分析
- 漏斗图:体现数据的转化关系
3. 订单数据分析的具体操作
3.1 宏观分析
- 宏观把握订单的总体特征
##取消订单数
df1 = df.groupby(["cancel_flag"],as_index=False)["sale_ord_id"].count()
df1["percent"] = df1["sale_ord_id"]/df["sale_ord_id"].count()
fig = plt.figure(figsize=(6,8))
explode = (0,0.1)
plt.style.use("ggplot")
plt.pie(df1["percent"],labels=["未取消","取消"],autopct="%1.2f%%",explode=explode)
plt.title("取消订单总揽")
plt.show()

#有效订单数
df2 = df[(df["sale_ord_valid_flag"]==1)&(df["cancel_flag"]==0)&(df["before_prefr_unit_price"]!=0)]
order_valid = df2["sale_ord_id"].count()#有效订单总数
order_paid = df2["sale_ord_id"][df2["user_actual_pay_amount"]!=0].count()#支付订单数
order_unpaid = df2["sale_ord_id"][df2["user_actual_pay_amount"]==0].count()
lables = ["支付","未支付"]
data =[order_paid,order_unpaid]
explode = (0,0.1)
fig = plt.figure(figsize=(6,8))
plt.pie(data,labels=lables,autopct="%1.2f%%",explode=explode)
plt.title("有效订单总揽")
plt.show()

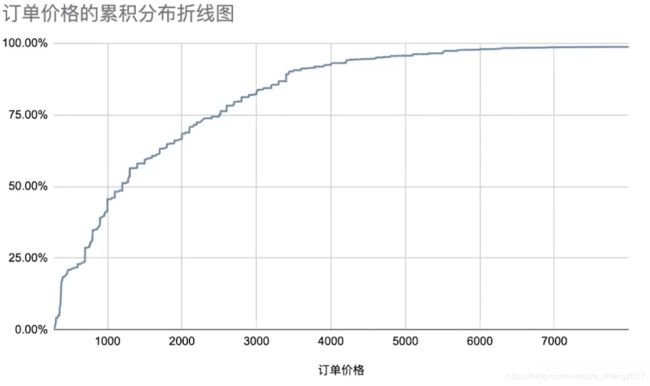
- 订单价格的累积分布折线图:订单价格降序排列,计算累计人数,计算累计人数占比,绘制折线图
#订单价格分布
price_series = df2["after_prefr_unit_price"]
price_series_num = price_series.count()
hist,bin_edges = np.histogram(price_series,bins=80)#生成直方图函数
hist_sum = np.cumsum(hist)
hist_per = hist_sum/price_series_num
bin_edges_plot = np.delete(bin_edges,0)
plt.figure(figsize=(20,8),dpi=80)
plt.xlabel("订单价格")
plt.ylabel("百分比")
def to_percent(temp,position):
return "%1.0f"%(100*temp)+"%"
plt.gca().yaxis.set_major_formatter(FuncFormatter(to_percent))
#是坐标轴设置为百分比函数
plt.plot(bin_edges_plot,hist_per,color="blue")
3.2 微观分析
- 从时间维度来对订单数据进行拆分:有效订单量、人均有效订单量、客单价、平均订单价格
- 大型活动一般在0点、20-24点时会有爆发,因此具体分析0时价格累积分布折线图和20时价格累积分布折线图
- 对比0时与其他时间的优惠订单数和订单价格
- 从地区维度对订单数据进行拆分:比较各省份的订单数、客单价
- 从地区维度和品牌维度结合,地区对品牌的特殊偏好,单价最贵的top4订单占比、各个品牌的平均占有价格和市场占有率