【Neo4j的简单搭建与使用】
文章目录
- Neo4j简介
- Neo4j安装(MAC)
- Neo4j使用
-
- 1. 基本的增删改查
- 详细查询
- 项目经验
-
- 创建节点并使边带权重
-
- 学习案例
- 项目实践
- 学习Neo4j
-
- Creating nodes
-
- 1. Creating Order nodes
- 2. Creating Product nodes
- 2. Creating Supplier nodes
- 3. Creating Employee nodes
- 4. Creating Category nodes
- Creating the relationships between the nodes
-
- 1. Creating relationships between orders and employees
- 2. Creating relationships between products and suppliers
- 3. Create relationships between products and categories
- 4. Creating relationships between employees
- Querying the Graph
Neo4j简介
Neo4j是一个高性能的, NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j安装(MAC)
- 下载
下载Neo4j Community Edition,下载地址:http://neo4j.org/download。
由于是mac下载,直接下载dmg文件。
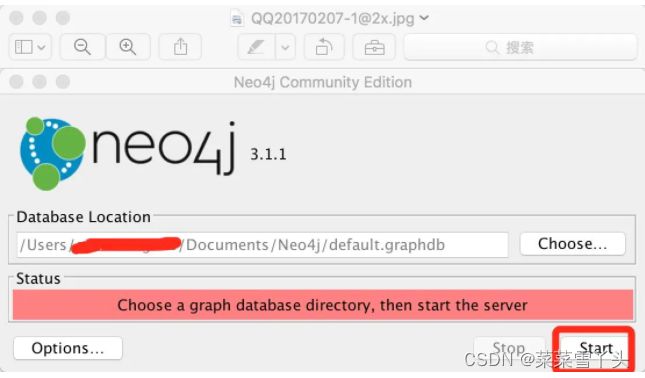
- 运行
安装Neo4j Community Edition并打开,配置运行数据存储路径,配置完毕后点击start启动。
3. Neo4j的远程可视化操作
打开 options ,找到 .neo4j.conf,取消以下代码的注释
dbms.connectors.default_listen_address=0.0.0.0
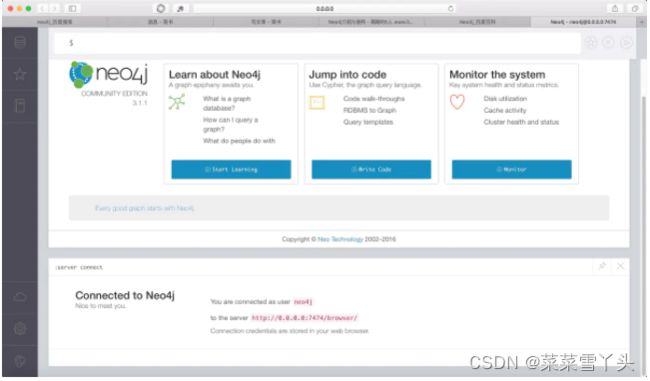
- 浏览器打开
如果配置了第三步的Neo4j的远程可视化操作,则访问http://0.0.0.0:7474/browser/,没有就直接访问 http://localhost:7474/browser/。
Neo4j使用
1. 基本的增删改查
- 插入节点
插入一个Person类别的节点,且这个节点有一个属性name,属性值为Andres。
CREATE (n:Person {name : 'Andres'});
- 插入边
插入一条 a 到 b 的有向边,且边的类别为Follow。
MATCH (a:Person),(b:Person)
WHERE a.name = 'Node A' AND b.name = 'Node B'
CREATE (a)-[r:Follow]->(b);
- 更新节点
更新一个Person类别的节点,设置新的name。
MATCH (n:Person { name: 'Andres' })
SET n.name = 'Taylor';
- 删除节点
Neo4j中如果一个节点有边相连,是不能单单删除这个节点的。
MATCH (n:Person { name:'Taylor' })
DETACH DELETE n;
- 删除边
MATCH (a:Person)-[r:Follow]->(b:Person)
WHERE a.name = 'Node A' AND b.name = 'Node B'
DELETE r;
- 查询最短路径
MATCH (ms:Person { name:'Node A' }),(cs:Person { name:'Node B' }), p = shortestPath((ms)-[r:Follow]-(cs)) RETURN p;
- 查询两个节点之间的关系
MATCH (a:Person { name:'Node A' })-[r]->(b:Person { name:'Node B' })
RETURN type(r);
- 查询一个节点的所有Follower
MATCH (:Person { name:'Taylor' })-[r:Follow]->(Person)
RETURN Person.name;
详细查询
请查看The Neo4j Cypher Manual v4.4
项目经验
1.将关系模型映射到图数据库:
当从关系模型导出图模型时,您应该记住以下准则:
行是一个节点,表名是一个标签名,联接或外键是一种关系。
注意:Neo4j不存储空值。CSV文件中的Null或空字段可以跳过,或替换为加载CSV中的默认值。
创建节点并使边带权重
学习案例
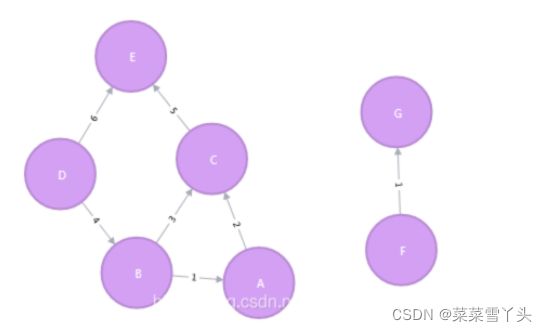
例1:
CREATE (a:Place {id: 'A'}),
(b:Place {id: 'B'}),
(c:Place {id: 'C'}),
(d:Place {id: 'D'}),
(e:Place {id: 'E'}),
(f:Place {id: 'F'}),
(g:Place {id: 'G'}),
(d)-[:LINK {cost:4}]->(b),
(d)-[:LINK {cost:6}]->(e),
(b)-[:LINK {cost:1}]->(a),
(b)-[:LINK {cost:3}]->(c),
(a)-[:LINK {cost:2}]->(c),
(c)-[:LINK {cost:5}]->(e),
(e)-[:LINK {cost:10}]->(c),
(f)-[:LINK {cost:1}]->(g);
#s = '({0}) - [:LINK cost:{1}] -> ({2})'.format('a',10, 'c')
效果:
例2:
CREATE(Shanghai:City{name:'上海'}),
(Suzhou:City{name:'苏州'}),
(Wuxi:City{name:'无锡'}),
(Nanjing:City{name:'南京'}),
(Ningbo:City{name:'宁波'}),
(Shanghai)-[:Neighbor {distance:80}]->(Suzhou),
(Shanghai)-[:Neighbor {distance:120}]->(Wuxi),
(Shanghai)-[:Neighbor {distance:300}]->(Nanjing) ,
(Shanghai)-[:Neighbor {distance:250}]->(Ningbo);
//无权重:
CREATE (Shanghai)-[:Neighbor]->(Suzhou) CREATE (Shanghai)-[:Neighbor]->(Wuxi) CREATE (Shanghai)-[:Neighbor]->(Nanjing) CREATE (Shanghai)-[:Neighbor]->(Ningbo)
//加权重:
CREATE (Shanghai)-[:Neighbor {distance:80}]->(Suzhou) CREATE (Shanghai)-[:Neighbor {distance:120}]->(Wuxi) CREATE (Shanghai)-[:Neighbor {distance:300}]->(Nanjing) CREATE (Shanghai)-[:Neighbor {distance:250}]->(Ningbo)
项目实践
1.问题
qid的数据不可能一条一条的创建,需要通过csv文件导入,那么导入时的cost(也就是边的次数)怎么写进去?
2.目前进展
加载csv文件,导入节点数据(不带权重)
LOAD CSV WITH HEADERS FROM 'file:///question.csv' AS row MERGE (question:Question{qID:row.qID}) ON CREATE SET question.qName=row.qName;
或者
LOAD CSV WITH HEADERS FROM 'file:///qid_qname.csv' AS row MERGE (question:Question{qName:row.qName}) ON CREATE SET question.qID=row.qID;
查看节点数据
MATCH(q:Question) return q LIMIT 10;
后面涉及项目内部,不再举例
学习Neo4j
Creating nodes
1. Creating Order nodes
执行此代码块以在数据库中创建订单节点:
// Create orders
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/orders.csv' AS row
MERGE (order:Order {orderID: row.OrderID})
ON CREATE SET order.shipName = row.ShipName;
如果已将CSV文件放入import folder,则应使用以下代码语法从本地目录加载CSV文件:
// Create orders
LOAD CSV WITH HEADERS FROM 'file:///orders.csv' AS row
MERGE (order:Order {orderID: row.OrderID})
ON CREATE SET order.shipName = row.ShipName;
这段代码在数据库中创建830个订单节点。
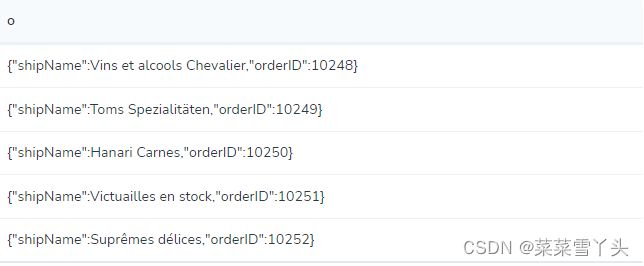
通过执行以下代码,可以查看数据库中的一些节点:
MATCH (o:Order) return o LIMIT 5;
部分图展示如下:

表视图包含节点属性的以下值:
2. Creating Product nodes
执行此代码块以在数据库中创建产品节点:
// Create products
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/products.csv' AS row
MERGE (product:Product {productID: row.ProductID})
ON CREATE SET product.productName = row.ProductName, product.unitPrice = toFloat(row.UnitPrice);
这段代码在数据库中创建77个产品节点。
通过执行以下代码,可以查看数据库中的一些节点:
MATCH (p:Product) return p LIMIT 5;
部分图展示如下:

2. Creating Supplier nodes
执行此代码块以在数据库中创建供应商节点:
// Create suppliers
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/suppliers.csv' AS row
MERGE (supplier:Supplier {supplierID: row.SupplierID})
ON CREATE SET supplier.companyName = row.CompanyName;
这段代码在数据库中创建29个供应商节点。
通过执行以下代码,可以查看数据库中的一些节点:
MATCH (s:Supplier) return s LIMIT 5;
部分图展示如下:
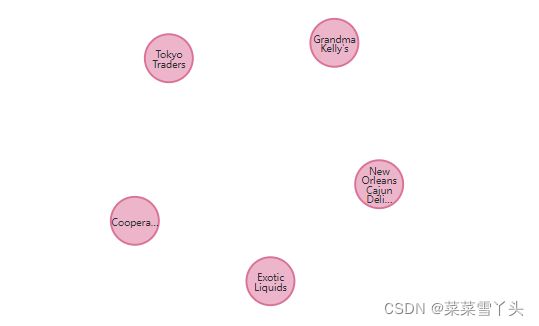
3. Creating Employee nodes
执行此代码块以在数据库中创建员工节点:
// Create employees
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/employees.csv' AS row
MERGE (e:Employee {employeeID:row.EmployeeID})
ON CREATE SET e.firstName = row.FirstName, e.lastName = row.LastName, e.title = row.Title;
这段代码在数据库中创建9个员工节点。
通过执行以下代码,可以查看数据库中的一些节点:
MATCH (e:Employee) return e LIMIT 5;
部分图展示如下:
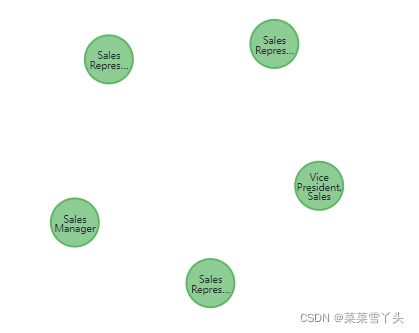
4. Creating Category nodes
// Create categories
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/categories.csv' AS row
MERGE (c:Category {categoryID: row.CategoryID})
ON CREATE SET c.categoryName = row.CategoryName, c.description = row.Description;
这段代码在数据库中创建8个分类节点。
通过执行以下代码,可以查看数据库中的一些节点:
MATCH (c:Category) return c LIMIT 5;
部分图展示如下:

Creating the relationships between the nodes
1. Creating relationships between orders and employees
先执行下列代码来 Create relationships between orders and products
// Create relationships between orders and products
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/orders.csv' AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (product:Product {productID: row.ProductID})
MERGE (order)-[op:CONTAINS]->(product)
ON CREATE SET op.unitPrice = toFloat(row.UnitPrice), op.quantity = toFloat(row.Quantity);
这段代码在数据库中创建2155个关系。
通过执行以下代码,可以查看数据库中的这些关系:
MATCH (o:Order)-[]-(p:Product)
RETURN o,p LIMIT 10;
部分图展示如下:

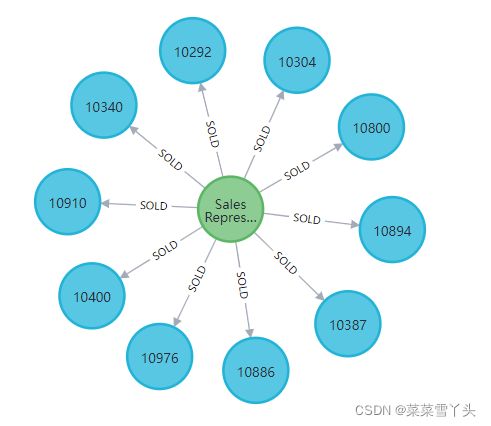
再执行下列代码来 Create relationships between orders and employees
// Create relationships between orders and employees
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/orders.csv' AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (employee:Employee {employeeID: row.EmployeeID})
MERGE (employee)-[:SOLD]->(order);
这段代码在数据库中创建830个关系。
通过执行以下代码,可以查看数据库中的这些关系:
MATCH (o:Order)-[]-(e:Employee)
RETURN o,e LIMIT 10;
部分图展示如下:
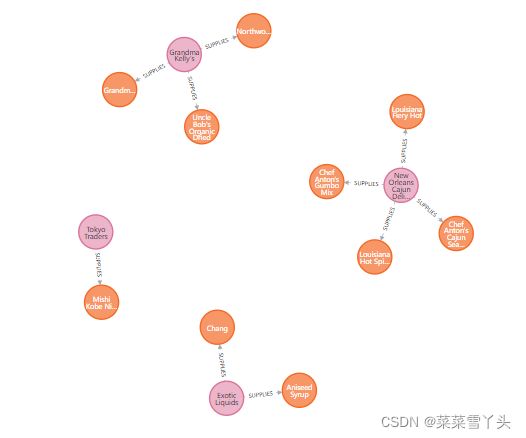
2. Creating relationships between products and suppliers
// Create relationships between products and suppliers
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/products.csv
' AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (supplier:Supplier {supplierID: row.SupplierID})
MERGE (supplier)-[:SUPPLIES]->(product);
这段代码在数据库中创建77个关系。
通过执行以下代码,可以查看数据库中的这些关系:
MATCH (s:Supplier)-[]-(p:Product)
RETURN s,p LIMIT 10;
部分图展示如下:
3. Create relationships between products and categories
// Create relationships between products and categories
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/products.csv
' AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (category:Category {categoryID: row.CategoryID})
MERGE (product)-[:PART_OF]->(category);
这段代码在数据库中创建77个关系。
通过执行以下代码,可以查看数据库中的这些关系:
MATCH (c:Category)-[]-(p:Product)
RETURN c,p LIMIT 10;
部分图展示如下:
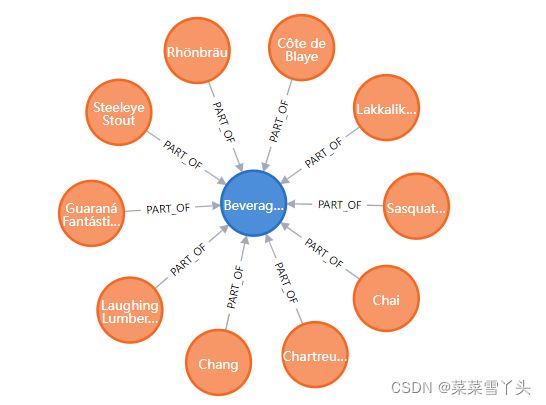
4. Creating relationships between employees
// Create relationships between employees (reporting hierarchy)
LOAD CSV WITH HEADERS FROM 'https://gist.githubusercontent.com/jexp/054bc6baf36604061bf407aa8cd08608/raw/8bdd36dfc88381995e6823ff3f419b5a0cb8ac4f/employees.csv' AS row
MATCH (employee:Employee {employeeID: row.EmployeeID})
MATCH (manager:Employee {employeeID: row.ReportsTo})
MERGE (employee)-[:REPORTS_TO]->(manager);
这段代码在数据库中创建8个关系。
通过执行以下代码,可以查看数据库中的这些关系:
MATCH (e1:Employee)-[]-(e2:Employee)
RETURN e1,e2 LIMIT 10;
部分图展示如下:
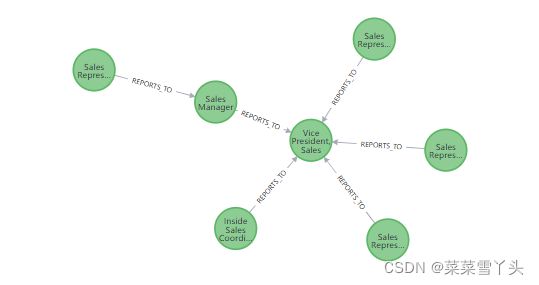
Querying the Graph
- 查找使用订购产品销售订单的员工样本
MATCH (e:Employee)-[rel:SOLD]->(o:Order)-[rel2:CONTAINS]->(p:Product)
RETURN e, rel, o, rel2, p LIMIT 25;
- 查找特定产品的供应商和类别
MATCH (s:Supplier)-[r1:SUPPLIES]->(p:Product {productName: 'Chocolade'})-[r2:PART_OF]->(c:Category)
RETURN s, r1, p, r2, c;
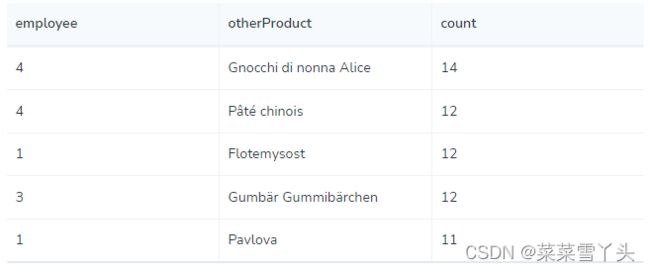
- 哪位员工的“Chocolade”和其他产品的交叉销售数量最高?
MATCH (choc:Product {productName:'Chocolade'})<-[:CONTAINS]-(:Order)<-[:SOLD]-(employee),
(employee)-[:SOLD]->(o2)-[:CONTAINS]->(other:Product)
RETURN employee.employeeID as employee, other.productName as otherProduct, count(distinct o2) as count
ORDER BY count DESC
LIMIT 5;
查询结果:
5. 员工是如何组织的?谁向谁报告?
MATCH (e:Employee)<-[:REPORTS_TO]-(sub)
RETURN e.employeeID AS manager, sub.employeeID AS employee;
查询结果:

- 哪些员工相互间接汇报?
MATCH path = (e:Employee)<-[:REPORTS_TO*]-(sub)
WITH e, sub, [person in NODES(path) | person.employeeID][1..-1] AS path
RETURN e.employeeID AS manager, path as middleManager, sub.employeeID AS employee
ORDER BY size(path);
查询结果:

- 层级结构的每一部分都下了多少命令?
MATCH (e:Employee)
OPTIONAL MATCH (e)<-[:REPORTS_TO*0..]-(sub)-[:SOLD]->(order)
RETURN e.employeeID as employee, [x IN COLLECT(DISTINCT sub.employeeID) WHERE x <> e.employeeID] AS reportsTo, COUNT(distinct order) AS totalOrders
ORDER BY totalOrders DESC;
查询结果:

Neo4j学习链接:
- Neo4j Browser/Visual tour:https://neo4j.com/docs/browser-manual/current/visual-tour/
- Developer Guides Data Import How-To: Desktop CSV Import:https://neo4j.com/developer/desktop-csv-import/
- How-To: Import Northwind Dataset:https://neo4j.com/developer/guide-importing-data-and-etl/