Python神经网络手写数字识别代码&解释
使用了数据集MNIST中的部分数据。
1、读取数据集内容
#打开文件并获取其中的内容
data_file=open("mnist_train.csv",'r')
#open()函数打开文件,第一个参数时文件的路径,第二个参数可选,"r"表示只读
data_list=data_file.readlines()
#使用与文件句柄data_file相关的readlines()函数,将文件中所有行读入变量data_list,此处文件很小,可以这么用,否则要逐行读取
data_file.close()
#关闭文件2、部分代码含义
len(data_list)
#列表长度为100,len()函数告诉我们列表的大小data_list[0]
#第一个值表示数字 5 ,之后的784(28x28)个数字是构成图像像素的颜色值,这些值介于0到255之间
3、为了使用imshow()函数绘制数字矩形数组,首先要将使用逗号分隔的数字列表转换成合适的数组:
(1)将由逗号分割,长的文本字符串值,查分成单个值,在逗号处进行分割
(2)忽略第一个值,这是标签,将剩余的28x28=784个值转换成28列28行的数组
(3)绘制数组!
import numpy
import matplotlib.pyplot #画图
%matplotlib inline
#使图像出现在这个页面,而不是弹出新的页面all_values=data_list[0].split(',')
#接收datat_list[0],这是第一条记录,根据逗号,将这一长串进行拆分,split()函数是执行拆分任务的,其中有一个参数告诉函数根据哪个符号进行拆分
image_array=numpy.asfarray(all_values[1:]).reshape((28,28))
#核心是all_values列表,方括号[1:]表示采用除了列表第一个元素外的所有值,也就是忽略第一个标签值,只剩下784个值
#numpy.asfarray()表示将文本字符串转换为实数,并创建这些数字的数组,最后一项.reshape(28,28)确保数字列表每28个元素折返一次,形成28x28的方形矩阵
matplotlib.pyplot.imshow(image_array,cmap='Greys',interpolation='None')
#绘图,选择灰度调色板——cmap="Greys(灰度)"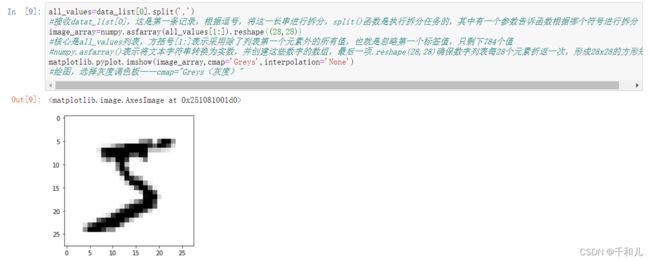
all_values=data_list[1].split(',')
#接收datat_list[0],这是第一条记录,根据逗号,将这一长串进行拆分,split()函数是执行拆分任务的,其中有一个参数告诉函数根据哪个符号进行拆分
image_array=numpy.asfarray(all_values[1:]).reshape((28,28))
#核心是all_values列表,方括号[1:]表示采用除了列表第一个元素外的所有值,也就是忽略第一个标签值,只剩下784个值
#numpy.asfarray()表示将文本字符串转换为实数,并创建这些数字的数组,最后一项.reshape(28,28)确保数字列表每28个元素折返一次,形成28x28的方形矩阵
matplotlib.pyplot.imshow(image_array,cmap='Greys',interpolation='None')
#绘图,选择灰度调色板——cmap="Greys(灰度)"
4、准备训练数据
将输入颜色值从较大的0到255的范围缩放至较小的0.01到1.0的范围(不能为0,否则会造成更新权重失败)
scaled_input=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
print(scaled_input)
#将0到255范围的原始输入值除以255,得到0到1范围的输入值,之后乘以0.99,变为0.0到0.99,之后再加上0.01,得到0.01到1.00
5、要求神经网络对图像进行分类,分配正确的标签,这些标签是0-9十个数字中的一个。
着意味着神经网络应该又10个输出层节点,每个节点对应可能的答案或标签。
onodes=10
targets=numpy.zeros(onodes)+0.01
#使用numpy.zeros()创建0填充的数组
targets[int(all_values[0])]=0.99
#int(all_values[0] 标签‘0’转换为整数0 标签‘5’转换为整数5
print(targets)
6、完整代码
import numpy
import scipy.special
#from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot
%matplotlib inline
#sc = StandardScaler()
#为了使用transform,fit_transform进行数据预处理而引入的包
#完整的神经网络代码
class neuralNetwork:
def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate):
#初始化神经网络
self.inodes=inputnodes
#输入层节点数
self.hnodes=hiddennodes
#隐藏层节点数
self.onodes=outputnodes
#输出层节点数目
#创建两个链接权重矩阵
#正太分布的中心设定为0.0,使用下一层节点数的开方作为标准方差来初始化权重,即pow(self.hnodes,-0.5),最后一个参数是numpy数组的形状大小
self.wih=numpy.random.normal(0.0,pow(self.hnodes,-0.5),(self.hnodes,self.inodes))
self.who=numpy.random.normal(0.0,pow(self.onodes,-0.5),(self.onodes,self.hnodes))
#或者可以选择简单一点的创建链接权重矩阵的方法
#self.wih=(numpy.random.rand(self.hnodes,self.inodes)-0.5)
#self.who=(numpy.random.rand(self.onodes,self.hnodes)-0.5)
#减去0.5得到-0.5—0.5之间的权重
self.lr=learningrate
#学习率
self.activation_function=lambda x:scipy.special.expit(x)
#使用lambda来创建函数,这个函数接受了x,返回scipy.special.expit(x),这就是S函数(激活函数)
#使用lambda创建的函数是没有名字的,一般称其为匿名函数,这里给它分配了一个名字activation_function(),因此,当想要使用S函数时,调用这个函数即可
pass
def train(self,inputs_list,targets_list):#target_list目标值
#训练网络,反向传播误差
#训练网络分两个部分:针对给定的训练样本输出,这与query()函数上所做内容没什么区别;将计算得到的输出与所需输出对比,使用差值来指导网络权重的更新
inputs=numpy.array(inputs_list,ndmin=2).T
#将输入的列表转换为矩阵并且转置,数组的维度是2(2维数组表示矩阵)
targets=numpy.array(targets_list,ndmin=2).T
#将targets_list变成numpy数组(维度为2),也即是矩阵
hidden_inputs=numpy.dot(self.wih,inputs)
hidden_outputs=self.activation_function(hidden_inputs)
final_inputs=numpy.dot(self.who,hidden_outputs)
final_outputs=self.activation_function(final_inputs)
#以上部分与query()部分使用完全相同的方式从输入层前馈信号到最终输出层
output_errors=targets-final_outputs
#输出层输出误差为预期目标输出值与实际计算得到的输出值的差
hidden_errors=numpy.dot(self.who.T,output_errors)
#计算隐藏层节点反向传播的误差:隐藏层与输出层之间链接权重的转置点乘输出层输出误差,为隐藏层输出误差
#对于在隐藏层和输出层之间的权重,我们使用output_errors进行优化。
#对于输入层和隐藏层之间的权重,我们使用计算得到的hidden_errors进行优化
self.who+=self.lr*numpy.dot((output_errors*final_outputs*(1.0-final_outputs)),numpy.transpose(hidden_outputs))
self.wih+=self.lr*numpy.dot((hidden_errors*hidden_outputs*(1.0-hidden_outputs)),numpy.transpose(inputs))
#利用更新权重的公式进行计算,得到新的权重
pass
def query(self,inputs_list):
#查询网络,计算输出
inputs=numpy.array(inputs_list,ndmin=2).T
#将inputs_list变成numpy数组(维度为2),也即是矩阵
hidden_inputs=numpy.dot(self.wih,inputs)
#输入层与隐藏层链接权重矩阵点乘输入矩阵,得到隐藏层的输入矩阵
hidden_outputs=self.activation_function(hidden_inputs)
#调用S函数,得到隐藏层的输出
final_inputs=numpy.dot(self.who,hidden_outputs)
#隐藏层与输出层的链接权重点乘隐藏层的输出矩阵,得到输入层的输入矩阵
final_outputs=self.activation_function(final_inputs)
#调用S函数,得到输出层的输出
return final_outputs
#返回输出的输出矩阵
input_nodes=784
#28x28=784,即手写图像的像素个数
hidden_nodes=200
#对于一个问题应该设多少隐藏层,并不存在一个最佳方法,最好的方法是进行实验,直到找出适合你要解决问题的一个数字
output_nodes=10
#输出十个数字
learning_rate=0.1
#学习率
n=neuralNetwork(input_nodes,hidden_nodes,output_nodes,learning_rate)
#打开文件并获取其中的内容
training_data_file=open("mnist_train.csv",'r')
#open()函数打开文件,第一个参数时文件的路径,第二个参数可选,"r"表示只读
training_data_list=training_data_file.readlines()
#使用与文件句柄data_file相关的readlines()函数,将文件中所有行读入变量data_list,此处文件很小,可以这么用,否则要逐行读取
training_data_file.close()
#关闭文件
epochs=5
#5个世代,训练一次称为一个世代
for e in range(epochs):
#训练五次
for record in training_data_list:
#遍历所有训练集中的数据
all_values=record.split(',')
#接收record,根据逗号,将这一长串进行拆分,split()函数是执行拆分任务的,其中有一个参数告诉函数根据哪个符号进行拆分
inputs=(numpy.asfarray(all_values[1:])/255.0*0.99)+0.01
#将0到255范围的原始输入值除以255,得到0到1范围的输入值,之后乘以0.99,变为0.0到0.99,之后再加上0.01,得到0.01到1.00
targets=numpy.zeros(output_nodes)+0.01
#使用numpy.zeros()创建0填充的数组
targets[int(all_values[0])]=0.99
#int(all_values[0] 标签‘0’转换为整数0 标签‘5’转换为整数5
print(inputs)
print(targets)
n.train(inputs,targets)
#训练数据
pass
pass
#获取测试记录
test_data_file=open("mnist_test.csv",'r')
test_data_list=test_data_file.readlines()
test_data_file.close()
#测试神经网络
scorecard=[]
#记分卡,在每条测试之后都会更新
for record in test_data_list:
all_values=record.split(',')
#拆分文本
correct_label=int(all_values[0])
#记下第一个数字
print(correct_label,"correct label")
inputs=(numpy.asfarray(all_values[1:])/255.0 * 0.99)+0.01
#调整剩下的值,使之适合查询神经网络
outputs=n.query(inputs)
#将神经网络的回答保存在outputs中
label=numpy.argmax(outputs)
#numpy.argmax()函数可以找出数组的最大值,并告诉我们最大值的位置
print(label,"network's answer")
#将计算得出的标签与已知正确标签对比,如果相同,在记分表后面加1,如果不同,在记分表后面,加0
if(label==correct_label):
scorecard.append(1)
else:
scorecard.append(0)
pass
pass
#计算准确率
scorecard_array=numpy.asarray(scorecard)
#转换为数组
print("performance = ",scorecard_array.sum() / scorecard_array.size)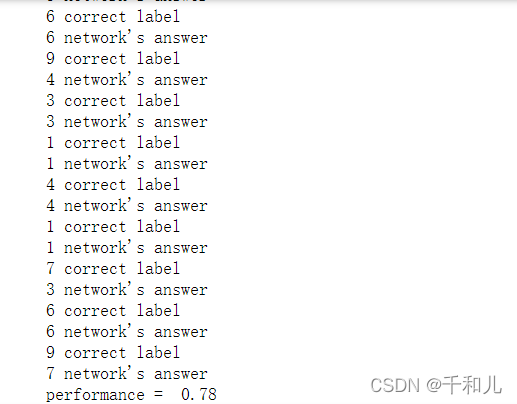
准确率:78%(可能是训练集和测试集使用的数据太少了)
应该。。。还行?
刚开始把训练函数注释了,导致准确率一直在10%左右,看了好久才发现那个注释号,悲伤。
--------------------------------------------------------------------------------------------------------------------------------
确实是测试数据太少了,这次用了两千多训练数据,准确率为99%

不过,数据太多,jupyter跑着跑着就崩了,解决方法可以参考:Jupyter处理大量数据导致内存溢出 网页崩溃的解决办法_Cmmm丶的博客-CSDN博客_jupyter内存溢出
但是数据再多一点还是会崩![]()
-------------------------------------------------------------------------------------------------------------
本文使用到的数据集如下:
链接:百度网盘 请输入提取码
提取码:g9qq