Python 余弦相似性应用
本文旨在对两个未知类型的文本进行余弦相似度分析,判断哪个文本属于军事类
理论知识
- 对于二维空间,根据空间向量点积公式:
![]()
- 假设向量a,b的坐标分别为(x1,y1),(x2,y2),则有:
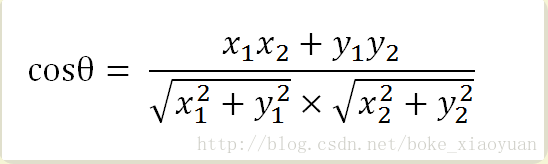
假设将向量A,B扩展到多维,向量A (A1,A2,Ai,····,An,),向量 B(B1,B2,Bi,····,Bn,) 则有:
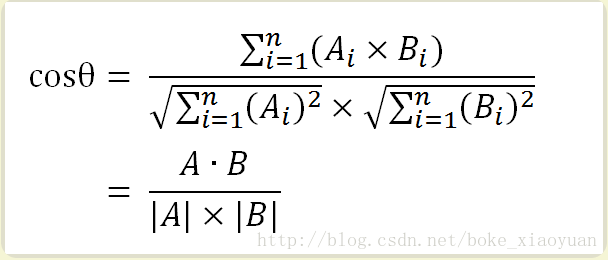
- 余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越接近(文档越相似);接近于0,表示两个向量近乎于正交;越趋近于-1,他们的方向越相反。
代码应用
- 所使用文件如下:
- military_sample.txt 关于军事的样本文本
- military_unknow.txt 关于军事的未分类测试文本
- meeting_unknow.txt 关于会议的未分类文本
- stop_word.txt 停用词表
- 步骤:
- 1)用 Python 编写余弦相似度函数
def get_cossimi(x,y):
myx=np.array(x)
myy=np.array(y)
cos1=np.sum(myx*myy)
cos21=np.sqrt(sum(myy*myy))
cos22=np.sqrt(sum(myx*myx))
return (cos1/float(cos22*cos21))
- 2)对军事样本文本进行数据预处理(分词、去除停用词,计算每个词的词频)
try:
sample0=open('../cosine_similarity/military_sample.txt','r',encoding='utf-8')
sample=sample0.read()
finally:
sample0.close()
sample_cut=jieba.cut(sample)
try:
stop0=open('../cosine_similarity/stop_word.txt','r',encoding='utf-8')
stop=stop0.read()
finally:
stop0.close()
stop=stop.split('\n')
#计算每个词条的词频
test_words={}
all_words={}
for myword in sample_cut:
if myword.strip() not in stop:
test_words.setdefault(myword,0)
all_words.setdefault(myword,0)
all_words[myword]+=1dict.setdefault(key,default=None)方法:
–遍历字典,如果字典中不存在key,将会添加键并设置值为默认值;如果存在,则什么影响都木有3)读取两个待分类文本,并进行中文分词
#读取第一个待分类数据,并分词
try:
military_unknow0=open('../cosine_similarity/military_unknow.txt','r',encoding='utf-8')
military_unknow=military_unknow0.read()
finally:
military_unknow0.close()
military_unknow_cut=jieba.cut(military_unknow)
#读取第二个待分类数据,并分词
try:
meeting_unknow0=open('../cosine_similarity/meeting_unknow.txt''r',encoding='utf-8')
meeting_unknow=meeting_unknow0.read()
finally:
meeting_unknow0.close()
meeting_unknow_cut=jieba.cut(meeting_unknow)
#去除停用词,生成词频
military_unknow_word=copy.deepcopy(test_words)
for myword in military_unknow_cut:
if myword.strip() not in stop:
if myword in military_unknow_word:
military_unknow_word[myword]+=1
meeting_unknow_word=copy.deepcopy(test_words)
for myword in meeting_unknow_cut:
if myword.strip() not in stop:
if myword in meeting_unknow_word:
meeting_unknow_word[myword]+=1copy.deepcopy (object) 方法:
–deepcopy()是将别的对象复制过来,自己形成一个新的对象,原对象的改变并不会影响到这个新的对象。4)计算并且输出两个待分类文本与样本文本的余弦相似度
sample_data=[]
military_data=[]
meeting_data=[]
for key in all_words.keys():
sample_data.append(all_words[key])
military_data.append(military_unknow_word[key])
meeting_data.append(meeting_unknow_word[key])
military_similarity=get_cossimi(sample_data,military_data)
meeting_similarity=get_cossimi(sample_data,meeting_data)
print (military_similarity)
print (meeting_similarity)- 5)完整代码:
#-*-coding : utf-8 -*-
import pandas as pd
import jieba
import copy
import numpy as np
#自定义余弦相似度函数
def get_cossimi(x,y):
myx=np.array(x)
myy=np.array(y)
cos1=np.sum(myx*myy)
cos21=np.sqrt(sum(myy*myy))
cos22=np.sqrt(sum(myx*myx))
return (cos1/float(cos22*cos21))
#读取样本文本,分词
try:
sample0=open('../cosine_similarity/military_sample.txt','r',encoding='utf-8')
sample=sample0.read()
finally:
sample0.close()
sample_cut=jieba.cut(sample)
try :
stop0=open('../cosine_similarity/stop_word.txt','r',encoding='utf-8')
stop=stop0.read()
finally:
stop0.close()
stop=stop.split('\n')
test_words={}
all_words={}
for myword in sample_cut:
if myword.strip() not in stop:
test_words.setdefault(myword,0)
all_words.setdefault(myword,0)
all_words[myword]+=1
#读取待分类文本
#第一个分类数据,并分词
try:
military_unknow0=open('../cosine_similarity/military_unknow.txt','r',encoding='utf-8')
military_unknow=military_unknow0.read()
finally:
military_unknow0.close()
military_unknow_cut=jieba.cut(military_unknow)
#读取第二个分类数据,并分词
try:
meeting_unknow0=open('../cosine_similarity/meeting_unknow.txt','r',encoding='utf-8')
meeting_unknow=meeting_unknow0.read()
finally:
meeting_unknow0.close()
meeting_unknow_cut=jieba.cut(meeting_unknow)
#对待分类文本进行停用词处理,生成词频特征码
military_unknow_word=copy.deepcopy(test_words)
for myword in military_unknow_cut:
if myword.strip() not in stop:
if myword in military_unknow_word:
military_unknow_word[myword]+=1
meeting_unknow_word=copy.deepcopy(test_words)
for myword in meeting_unknow_cut:
if myword.strip() not in stop:
if myword in meeting_unknow_word:
meeting_unknow_word[myword]+=1
#计算并输出样本与待分类文本的余弦相似度
sample_data=[]
military_data=[]
meeting_data=[]
for key in all_words.keys():
sample_data.append(all_words[key])
military_data.append(military_unknow_word[key])
meeting_data.append(meeting_unknow_word[key])
military_similarity=get_cossimi(sample_data,military_data)
meeting_similarity=get_cossimi(sample_data,meeting_data)
print ("军事样本文本词频统计:")
print (sample_data)
print ("军事未分类文本词频统计:")
print(military_data)
print ("会议未分类文本词频统计:")
print (meeting_data)
print('------------------------------------')
print('------------------------------------')
print ('【 military_unknow 】与样本【 military_sample 】的相似度为:%f'%military_similarity)
print ('【 meeting_unknow 】与样本【 military_sample 】的相似度为:%f'%meeting_similarity)- 最后结果:

- 根据上面的代码执行结果,还是令人满意的,meeting_unknow.txt 与military_sample.txt 的相似度为0.48;military_unknow.txt与 military_sample.txt的相似度为0.19,因此,military_know归为军事类