大数据知识图谱的系统工程观
1 引言
知识图谱是由节点和边组成的语义网络[1]。节点可以是实体,如:一个人、一本书等,或抽象的概念,如:人工智能、知识图谱等。边可以是实体的属性,如:姓名、书名,或实体之间的关系,如:朋友、配偶。知识图谱的早期理念来自于Web之父Tim Berners Lee于1998年提出的Semantic Web[2][3],其最初理想是把基于文本链接的万维网转化成基于实体链接的语义网。
1989年,万维网之父、图灵奖获得者Tim Berners-Lee提出构建一个全球化的以“链接”为中心的信息系统(Linked Information System)。任何人都可以通过添加链接把自己的文档链入其中。他认为以链接为中心和基于图的组织方式,比起基于树的层次化组织方式,更加适合于互联网这种开放的系统。这一思想逐步被人们实现,并演化发展成为今天的World Wide Web。
1994年,Tim Berners-Lee 又提出,Web不应该仅仅只是网页之间的互相链接。实际上,网页中所描述的都是现实世界中的实体和人脑中的概念。网页之间的链接实际包含有语义,即这些实体或概念之间的关系,然而机器却无法有效的从网页中识别出其中蕴含的语义。他于1998年提出了Semantic Web的概念[4]。Semantic Web仍然基于图和链接的组织方式,只是图中的节点代表的不只是网页,而是客观世界中的实体(如:人、机构、地点等),而超链接也被增加了语义描述,具体标明实体之间的关系(如:出生地是、创办人是等)。相对于传统的网页互联网,Semantic Web的本质是知识的互联网或事物的互联网(Web of Things)。
在Semantic Web被提出之后,出现了一大批新兴的语义知识库。如作为谷歌知识图谱后端的Freebase[5],作为IBM Waston后端的DBPedia[6]和Yago[7],作为Amazon Alexa后端的True Knowledge,作为苹果Siri后端的Wolfram Alpha,以及Schema.ORG[8],目标成为世界最大开放知识库的WikiData[9]等。尤其值得一提的是,2010年谷歌收购了早期语义网公司MetaWeb,并以其开发的Freebase为数据基础之一,于2012年正式推出了称为知识图谱的搜索引擎服务。随后,知识图谱逐步在语义搜索[10][11]、智能问答[12][13][14]、辅助语言理解[15][16]、辅助大数据分析[17][18][19]、增强机器学习的可解释性[20]、结合图卷积辅助图像分类[21][22]等很多领域发挥出越来越重要的作用。
如图1所示,本质而言,知识图谱旨在从数据中识别、发现和推断事物、概念之间的复杂关系,是事物关系的可计算模型。知识图谱的构建涉及知识建模、关系抽取、图存储、关系推理、实体融合等多方面的技术,而知识图谱的应用则涉及到语义搜索、智能问答、语言理解、决策分析等多个领域。构建并利用好知识图谱需要系统性的利用好涉及知识表示、数据库、自然语言处理、机器学习等多个方面技术。本文尝试从信息系统工程的观点总结知识图谱的内涵和外延,核心的技术要素及技术流程,并从智能问答、语言理解、智能推理、数据库、推荐系统、区块链等多个相关领域进行了发展趋势总结与分析。
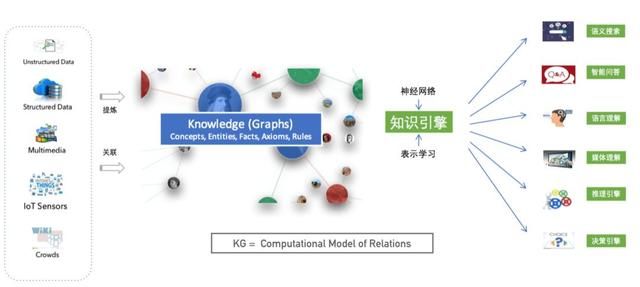
图 1 知识图谱:事物关系的可计算模型
2 从信息系统工程的观点看知识图谱
2.1 知识图谱的规模化发展
知识图谱并非突然出现的新技术,而是历史上很多相关技术相互影响和继承发展的结果,这包括语义网络、知识表示、本体论、Semantic Web、自然语言处理等,有着来自Web、人工智能和自然语言处理等多方面的技术基因。从早期的人工智能发展历史来看,Semantic Web是传统人工智能与Web融合发展的结果,是知识表示与推理在Web中的应用;RDF/OWL都是面向Web设计实现的标准化的知识表示语言;而知识图谱则可以看做是Semantic Web的一种简化后的商业实现。

图 2从语义网络到知识图谱
在人工智能的早期发展流派中,符号派(Symbolism)侧重于模拟人的心智,研究怎样用计算机符号来表示人脑中的知识和模拟心智的推理过程;连接派(Connectionism)侧重于模拟人脑的生理结构,即人工神经网络。符号派一直以来都处于人工智能研究的核心位置。近年来,随着数据的大量积累和计算能力大幅提升,深度学习在视觉、听觉等感知处理中取得突破性进展,进而又在围棋等博弈类游戏、机器翻译等领域获得成功,使得人工神经网络和机器学习获得了人工智能研究的核心地位。深度学习在处理感知、识别和判断等方面表现突出,能帮助构建聪明的AI,但在模拟人的思考过程、处理常识知识和推理,以及理解人的语言方面仍然举步维艰。
符号派关注的核心是知识的表示和推理(KRR:Knowledge Representation and Reasoning)。早在1960年,认知科学家Allan M. Collins提出用语义网络(Semantic Network)来研究人脑的语义记忆。WordNet[23]是典型的语义网络,它定义了名词、动词、形容词和副词之间的语义关系,例如动词之间的蕴含关系(如:“打鼾”蕴含着“睡眠”)等。WordNet被广泛应用于语义消歧等自然语言处理领域。
1970 年,随着专家系统的提出和商业化发展,知识库构建和知识表示更加得到重视。专家系统的基本想法是:专家是基于大脑中的知识来进行决策,因此,人工智能的核心应该是用计算机符号来表示这些知识,并通过推理机模仿人脑对知识进行处理。依据专家系统的观点,计算机系统应该由知识库和推理机两部分组成,而不是由函数等过程性代码组成。早期专家系统最常用的知识表示方法包括基于框架的语言(Frame-based Languages)和产生式规则(Production Rules)等。框架语言主要用于描述客观世界的类别、个体、属性及关系等,较多的被应用于辅助自然语言理解。产生式规则主要用于描述类似于IF-THEN的逻辑结构,适合于刻画过程性知识。
知识图谱与传统专家系统时代的知识工程有显著的不同。与传统专家系统时代主要依靠专家手工获取知识不同,现代知识图谱的显著特点是规模巨大,无法单一依靠人工和专家构建。传统的知识库,如由Douglas Lenat从1984年开始创建的常识知识库Cyc仅包含700万条 的事实描述(Assertion)。Wordnet主要依靠语言学专家定义名词、动词、形容词和副词之间的语义关系,目前包含大约20万条的语义关系。由著名人工智能专家Marvin Minsky于1999年起开始构建的ConceptNet[24]常识知识库依靠了互联网众包、专家创建和游戏三种方法,但早期ConceptNet规模在百万级别,最新的ConceptNet 5.0也仅包含2800万RDF三元组关系描述。现代知识图谱如谷歌和百度的知识图谱都已经包含超过千亿级别的三元组,阿里巴巴于2017年8月份发布的仅包含核心商品数据的知识图谱也已经达到百亿级别。DBpedia已经包含约30亿RDF三元组,多语种的大百科语义网络BabelNet包含19亿的RDF三元组[25],Yago3.0包含1.3亿元组,Wikidata已经包含4265万条数据条目,元组数目也已经达到数十亿级别。截止目前,开放链接数据项目Linked Open Data 统计了其中有效的2973个数据集,总计包含大约1494亿三元组。
现代知识图谱对知识规模的要求源于“知识完备性”难题。冯诺依曼曾估计单个个体的大脑中的全量知识需要2.4*1020个bits来存储[26]。客观世界拥有不计其数的实体,人的主观世界还包含有无法统计的概念,这些实体和概念之间又具有更多数量
的复杂关系,导致大多数知识图谱都面临知识不完全的困境。在实际的领域应用场景中,知识不完全也是困扰大多数语义搜索、智能问答、知识辅助的决策分析系统的首要难题。
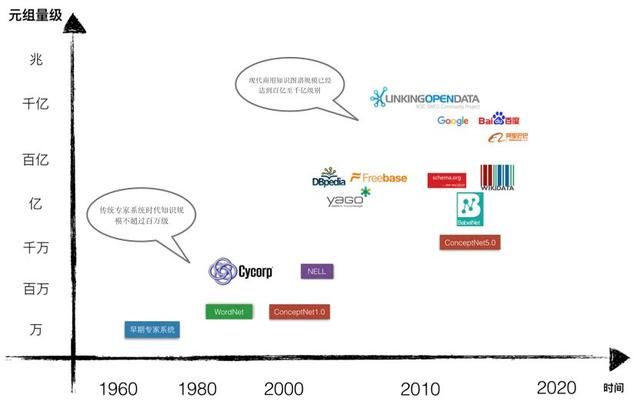
图 3 现代知识图谱的规模化发展
2.2 规模化的知识图谱系统工程
规模化的知识图谱工程要求系统性的综合多方面的技术手段。如图 4所示,知识图谱工程的核心流程包括:知识建模、知识抽取、知识融合、知识推理、知识检索、知识分析等核心环节。一般的技术流程包括:首先确定知识表示模型,然后根据数据来源选择不同的知识获取手段导入知识,接下来需要综合利用知识推理、知识融合、知识挖掘等技术对所构建的知识图谱进行质量提升,最后根据场景需求设计不同的知识访问与呈现方法,如:语义搜索、问答交互、图谱可视化分析等。下面简要概述这些技术流程的核心技术要素。
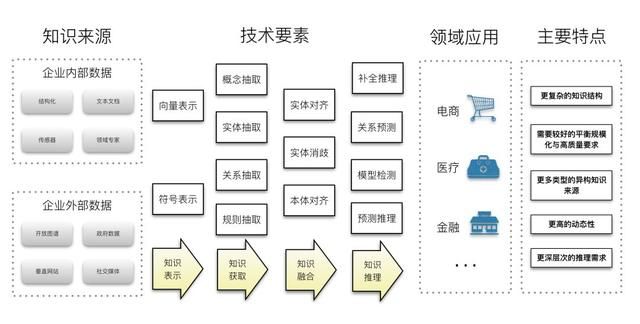
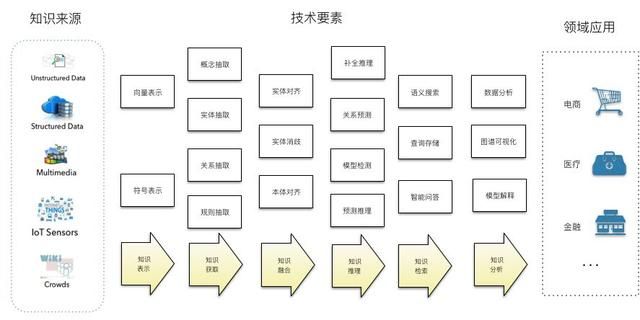
图 4 规模化的知识图谱系统工程
● 知识来源
可以从多种来源来获取知识图谱数据,这包括:文本、结构化数据库、多媒体数据、传感器数据和人工众包等。每一种数据源的知识化都需要综合各种不同的技术手段。 例如,对于文本数据源就需要综合各种自然语言处理技术(实体识别、实体链接、关系抽取、事件抽取等)来实现从文本中抽取知识。
结构化数据库如各种关系型数据库,也是最常使用的数据来源之一。 通常已有的结构化数据库不能直接作为知识图谱使用,而需要通过定义结构化数据到本体模型之间的语义映射,再通过编写语义翻译工具来实现结构化数据到知识图谱的转化。此外,还需要综合采用实体消歧、数据融合、知识链接等技术提升数据的规范化水平和增强数据之间的关联。
语义技术也被用来对传感器所产生的数据进行语义化。这包括对物联设备进行抽象,定义符合语义标准的数据接口;对传感数据进行语义封装和对传感数据增加上下文语义描述等。
人工众包是获取高质量知识图谱的重要手段。例如:WikiData和Schema.org都是较为典型的知识众包技术手段。此外,还可以开发针对文本、图像等多种媒体数据的语义标注工具辅助人工进行知识获取。
● 知识表示与Schema工程
知识表示(Knowledge Representation)是指用计算机符号描述和表示人脑中的知识,以支持机器模拟人的心智进行推理的方法与技术。知识表示决定了图谱构建的产出目标,即知识图谱的语义描述框架(Description Framework)、Schema与本体(Ontology)、知识交换语法(Syntax)和实体命名及ID体系。
基本描述框架定义知识图谱的基本数据模型(Data Model)和逻辑结构(Structure),如W3C的RDF(Resource Description Framework)。Schema与本体定义知识图谱的类集、属性集、关系集和词汇集。交换语法定义知识实际存在的物理格式,如Turtle、JSON等。实体命名及ID体系定义实体的命名原则及唯一标示规范等。
从知识图谱的知识类型来分,包括:词(Vocabulary)、实体(Entity)、关系(Relation)、事件(Events)、术语体系(Taxonomy)、规则(Rules)等。词一级的知识以词为中心,并定义词之间的关系,如WordNet、ConceptNet等。实体一级的知识以实体为中心,并定义实体之间的关系、描述实体的术语体系等。事件是一种复合的实体。
W3C的RDF把三元组(Triple)作为基本的数据模型,其基本的逻辑结构包含主语(Subject)、谓词(Predicate)、宾语(Object)三个部分。虽然不同知识库的描述框架的表述有所不同,但本质上都包含实体、实体的属性和实体之间的关系几个方面的要素。
● 知识抽取
知识抽取按任务可以分为概念抽取、实体识别、关系抽取、事件抽取和规则抽取等。传统专家系统时代的知识主要依靠专家手工录入,难以扩大规模。现代知识图谱的构建通常大多依靠已有的结构化数据资源进行转化形成基础数据集,再依靠自动化知识抽取和知识图谱补全技术从多种数据来源进一步扩展知识图谱,并通过人工众包来进一步提升知识图谱的质量。
结构化和文本数据是目前最主要的知识来源。从结构化数据库中获取知识一般使用现有的D2R工具[27],如 Triplify、D2RServer、OpenLink、SparqlMap、Ontop等。从文本中获取知识主要包括实体识别和关系抽取。以关系抽取为例,典型的关系抽取方法可以分为:基于特征模板的方法[28-30],基于核函数的监督学习方法[31-39],基于远程监督的方法[40][47],和基于深度学习的监督或远程监督方法,如简单CNN、MP-CNN、MWK-CNN、PCNN、PCNN+Att、和MIMLCNN等[42-46]。远程监督的思想是,利用一个大型的语义数据库来自动获取关系类型标签。这些标签可能是含有噪声的,但是大量的训练数据一定程度上可以抵消这些噪声。另外一些工作通过多任务学习等方法将实体和关系做联合抽取[47-48]。最新的一些研究则利用强化学习来减少人工标注和自动降低噪音[49]。
● 知识融合
在构建知识图谱时,可以从第三方知识库产品或已有结构化数据获取知识输入。例如,关联开放数据项目(Linked Open Data)会定期发布其经过积累和整理的语义知识数据,其中既包括前文介绍过的通用知识库 DBpedia和 Yago,也包括面向特定领域的知识库产品,如 MusicBrainz和DrugBank等。当多个知识图谱进行融合,或者将外部关系数据库合并到本体知识库时需要处理两个层面的问题:A. 通过模式层的融合,将新得到的本体融入已有的本体库中,以及新旧本体的融合;B.数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余。
数据层的融合是指实体和关系(包括属性)元组的融合,主要是实体匹配(或者对齐),由于知识库中有些实体含义相同但是具有不同的标识符,因此需要对这些实体进行合并处理[91-92]。此外,还需要对新增实体和关系进行验证和评估,以确保知识图谱的内容一致性和准确性,通常采用的方法是在评估过程中为新加入的知识赋予可信度值,据此进行知识的过滤和融合。实体对齐的任务包括实体消歧和共指消解,即判断知识库中的同名实体是否代表不同的含义以及知识库中是否存在其他命名实体与之表示相同的含义。实体消歧(entity disambiguation)专门用于解决同名实体产生歧义问题的,通常采用聚类法,其关键问题是如何定义实体对象与指称项之间的相似度,常用方法有:空间向量模型(词袋模型)[56]、语义模型[57]、社会网络模型[58]、百科知识模型[59]和增量证据模型[60]。一些最新的工作利用知识图谱嵌入方法进行实体对齐,并引入人机协作方式提升实体对齐的质量[61-62]。
本体是针对特定领域中Schema定义、概念模型和公理定义而言的,目的是弥合词汇异构性和语义歧义的间隙,使沟通达成共识。这种共识往往是通过一个反复的过程达到,每次迭代都是一次共识的修改。因此,本体对齐通常带来的是共识模式的演化和变化,本体对齐的主要问题之一也可以转化为怎样管理这种演化和变化[63]。常见的本体演化管理框架有KAON[64]、Conto-diff[65]、OntoView等。
● 知识图谱补全
常用的知识图谱补全方法包括:基于本体推理的补全方法,如基于描述逻辑的推理[66-68],以及相关的推理机实现如:RDFox、Pellet , RACER , HermiT , TrOWL等。这类推理主要针对TBox,即概念层进行推理,也可以用来对实体级的关系进行补全。
另外一类的知识补全算法实现基于图结构和关系路径特征的方法,如基于随机游走获取路径特征的PRA算法[69],基于子图结构的SFE算法[70],基于层次化随机游走模型的PRA算法[71]。这类算法的共同特点是通过两个实体节点之间的路径,以及节点周围的图的结构提取特征,并通过随机游走等算法降低特征抽取的复杂度,然后叠加线性的学习模型来进行关系的预测。此类算法依赖于图结构和路径的丰富程度。
更为常见的补全实现是基于表示学习和知识图谱嵌入的链接预测[73-80],简单的如前面所介绍最基本的翻译模型、组合模型和神经元模型等。这类简单的嵌入模型一般只能实现单步的推理。更为复杂一些的模型,如向量空间中引入随机游走模型的方法,在同一个向量空间中将路径与实体和关系一起表示出来再进行补全的模型[81-82]。
文本信息也被用来辅助实现知识图谱的补全[50-55]。例如Jointly(w)、Jointly(z) 、DKRL、TEKE、SSP等方法将文本中的实体和结构化图谱中的实体对齐,然后利用双方的语义信息来辅助实现关系预测或抽取。这类模型一般包含3个部分:三元组解码器、文本解码器和联合解码器。三元组解码器将知识图谱中的实体和关系转化为低维向量;文本解码器则是要从文本语料库中学习实体(词)的向量表示;联合解码器的目的是要保证实体/关系和词的嵌入向量位于相同的空间中并且集成实体向量和词向量。
● 知识检索与知识分析
基于知识图谱的知识检索的实现形式主要包括语义检索和智能问答。传统搜索引擎依靠网页之间的超链接来实现网页的搜索,而语义搜索是直接对事物进行搜索,如人物、机构、地点等。这些事物可能来自于文本、图片、视频、音频、IoT设备等各种信息资源。而知识图谱和语义技术提供了关于这些事物的分类、属性和关系的描述,使得搜索引擎可以直接对事物进行索引和搜索。
知识图谱和语义技术也被用来辅助做数据分析与决策。例如,大数据公司PLANTIR基于本体融合和集成多种来源的数据,通过知识图谱和语义技术增强数据之间的关联,使得用户可以用更加直观的图谱方式对数据进行关联挖掘与分析。近年来,描述性数据分析(DECLARATIVE DATA ANALYSIS)受到越来越多的重视[83]。描述性数据分析是指依赖数据本身的语义描述来实现数据分析的方法。不同于计算性数据分析主要以建立各种数据分析模型,如深度神经网络,描述性数据分析突出预先抽取数据的语义,建立数据之间的逻辑,并依靠逻辑推理的方法(如DATALOG)来实现数据分析[84]。
3 发展趋势与展望
3.1 知识图谱的系统工程思维
知识图谱本身可以看做是一种新型的信息系统基础设施。从数据维度,知识图谱要求用更加规范的语义来提升企业数据的质量,用链接数据(Linked Data)的思想提升企业数据之间的关联度,终极目标是将非结构、无显示关联的粗糙数据逐步萃取提炼为结构化、高度关联的高质量知识。每个企业都应该将知识图谱作为一种面向数据的信息系统基础设施进行持续性建设。
从技术维度,知识图谱的构建涉及知识表示、关系抽取、图数据存储、数据融合、推理补全等多方面的技术,而知识图谱的利用涉及语义搜索、知识问答、自动推理、知识驱动的语言及视觉理解、描述性数据分析等多个方面。要构建并利用好知识图谱也要求系统性的综合利用好来自于知识表示、自然语言处理、机器学习、图数据库、多媒体处理等多个相关领域的技术,而非单个领域的单一技术。因此,未来一个发展趋势是,知识图谱的构建和利用都应注重系统思维。
3.2大规模的知识图谱嵌入与基于表示学习的可微分推理
知识图谱对规模的扩展需求使得知识表示技术逐渐发生了多方面的变化:1)从以强逻辑为中心向以按需增强语义表达能力的变化;2)从较为注重TBox概念型知识转化为更加注重ABox事实型知识;3)从以离散的符号逻辑表示向以连续的向量空间表示方向发展。
尽管以连续向量表示为基础的知识图谱嵌入日益得到重视,但其在实际应用过程中却仍然面临较大的困难。这包括:A. 极大规模的知识图谱嵌入的训练及向量化知识图谱的存储计算问题;B.嵌入过程带来的信息丢失问题及少样本数据训练不充分的问题。对于问题A,要求更多的考虑结合数据库技术及大数据存储技术来解决大规模知识图谱带来的性能问题,而非单一的考虑参数的规模。对于问题B,则需要考虑更多的叠加逻辑规则和先验知识来引导知识图谱嵌入的训练过程。
另外一个发展趋势是基于学习的可微分推理。可微分推理通过统计学习将推理所依赖的元素参数化,从而使得推理的过程可微。可微分推理通常需要同时对结构和参数进行学习,因而复杂度和难度都很高。但一旦实现,其意义是可以实现从大量数据中归纳总结推理过程,且这些通过大数据总结归纳出的推理过程可以用来产生新的知识。
3.3少样本、无监督的知识获取
知识图谱的规模化构建需求对知识获取带来如下几个方面的变化:1)从单一人工获取到更多的依靠大数据和机器学习来实现自动化知识抽取;2)从单一来源变化为综合从结构化、半结构化、文本、传感器等多个来源,通过多任务相融合实现联合知识获取;3)从依靠少数专家到依靠互联网群体众包协同获取。
大规模对自动化知识获取提出了更高的要求。未来主要发展趋势包括:1) 融合深度学习与远程监督,降低自动化抽取对特征工程和监督数据的依赖;2)通过强化学习降低抽取的的噪音,减少对标注数据的依赖;3) 融合多种类型的数据通过多任务学习进行联合知识抽取;4) 有机的结合人工众包提高知识抽取的质量和加强监督信号。较好的平衡人工和自动化抽取,尽可能降低机器对标注数据和特征工程的依赖,并综合多种来源的知识进行联合抽取,特别是发展少样本、无监督和自监督的方法,是未来实现大规模知识获取的关键因素。
3.4区块链与去中心化的知识图谱
语义网的早期理念实际上包含三个方面:知识的互联、去中心化的架构和知识的可信。知识图谱在一定程度上实现了“知识互联”的理念,然而在去中心化的架构和知识可信两个方面都仍然没有较好的解决方案出现。
对于去中心化,相比起现有的多为集中存储的知识图谱,语义网强调知识是以分散的方式互联和相互链接,知识的发布者拥有完整的控制权。近年来,国内外已经有研究机构和企业开始探索将区块链技术去实现去中心化的知识互联。这包括去中心化的实体ID管理、基于分布式账本的术语及实体命名管理、基于分布式账本的知识溯源、知识签名和权限管理等。
知识的可信与鉴真也是当前很多知识图谱项目所面临的挑战和问题。由于很多知识图谱数据来源广泛,且知识的可信度量需要作用到实体和事实级别,怎样有效的对知识图谱中的海量事实进行管理、追踪和鉴真,也成为区块链技术在知识图谱领域的一个重要应用方向。
此外,将知识图谱引入到智能合约(Smart Contract)中,可以帮助解决目前智能合约内生知识不足的问。例如PCHAIN[148]引入知识图谱(Knowledge Graph)Oracle机制,解决传统智能合约数据不闭环的问题。
4 结束语
互联网促成了大数据的集聚,大数据进而促进了人工智能算法的进步。新数据和新算法为规模化知识图谱构建提供了新的技术基础和发展条件,使得知识图谱构建的来源、方法和技术手段都发生极大的变化。知识图谱作为知识的一种形式,已经在语义搜索、智能问答、数据分析、自然语言理解、视觉理解、物联网设备互联等多个方面发挥出越来越大的价值。AI浪潮愈演愈烈,而作为底层支撑的知识图谱赛道也从鲜有问津到缓慢升温,虽然还谈不上拥挤,但作为通往未来的必经之路,注定会走上风口。互联网科技发展蓬勃兴起,人工智能时代来临,抓住下一个风口。为帮助那些往想互联网方向转行想学习,却因为时间不够,资源不足而放弃的人。我自己整理的一份最新的大数据进阶资料和高级开发教程,大数据学习群:86884+++7735 欢迎进阶中和进想深入大数据的小伙伴加入。