PyTorch中的nn.Conv1d、nn.Conv2d以及文本卷积
PyTorch中的nn.Conv1d、nn.Conv2d以及文本卷积
- 简单理解文本处理时的卷积原理
- 一维卷积nn.Conv1d
-
- 定义
- 参数说明
- 代码示例
- 涉及论文及图解
- 二维卷积nn.Conv2d
-
- 定义
- 参数说明
- 代码示例
- 图解
- 总结
简单理解文本处理时的卷积原理
大多数 NLP 任务的输入不是图像像素,而是以矩阵表示的句子或文档。矩阵的每一行对应一个标记,通常是一个单词,但它也可以是一个字符。也就是说,每一行都是代表一个单词的向量。通常这些向量是像 word2vec 或 GloVe 这样的词嵌入(低维表示),但是它们也可以是将单词索引到词汇表中的一个 one-hot 向量。对于使用 100 维嵌入的 10 个字的句子,我们将有一个 10×100 的矩阵作为我们的输入。这就是是我们的“图像”。
在计算机视觉上,我们的过滤器在图像的局部区域上滑动,但是在 NLP 中,我们通常使用滑过整行矩阵(单词)的过滤器。因此,我们的滤波器的“宽度”通常与输入矩阵的宽度相同。对于矩阵的宽度其实就是一个单词转化为的词向量的长度,然后这个滤波器相当于一次遍历多个词向量,而且可以有不同的滤波器。高度或区域大小可能会有所不同,通常使用一次滑动 2-5 个字的窗口。
一维卷积nn.Conv1d一般用于文本数据,只对宽度进行卷积,对高度不卷积。通常,输入大小为word_embedding_dim * max_length,其中,word_embedding_dim为词向量的维度,max_length为句子的最大长度。卷积核窗口在句子长度的方向上滑动,进行卷积操作。
一维卷积nn.Conv1d
定义
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
参数说明
in_channels:在文本应用中,即为词向量的维度out_channels:卷积产生的通道数,有多少个out_channels,就需要多少个一维卷积(也就是卷积核的数量)kernel_size:卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为kernel_size * in_channelspadding:对输入的每一条边,补充0的层数
代码示例
输入:批大小为32,句子的最大长度为35,词向量维度为256
目标:句子分类,共2类
conv1 = nn.Conv1d(in_channels=256, out_channels=100, kernel_size=2)
input = torch.randn(32, 35, 256)
input = input.permute(0, 2, 1)
output = conv1(input)
假设window_size = [3, 4, 5, 6],基于上述代码,具体计算过程如下:
1.原始输入大小为(32, 35, 256),经过permute(0, 2, 1)操作后,输入的大小变为(32, 256, 35);
2.使用1个卷积核进行卷积,可得到1个大小为32 x 100 x 1的输出,共4个卷积核,故共有4个大小为32 x 100 x 1的输出;
3.将上一步得到的4个结果在dim = 1上进行拼接,输出大小为32 x 400 x 1;
4. view操作后,输出大小变为32 x 400;
5.全连接,最终输出大小为32 x 2,即分别预测为2类的概率大小。
涉及论文及图解
Yoon Kim在2014年发表的论文Convolutional Neural Networks for Sentence Classification中给出如下的图,一个用于 NLP 的卷积神经网络可能看起来像这样。
用于句子分类的卷积神经网络(CNN)体系结构图。 这里描述了三个过滤器的大小:2,3和4,每个大小都有2个过滤器。 每个过滤器对句子矩阵执行卷积并生成(可变长度)特征映射。 然后在每个特征图上执行1-max池化,即记录来自每个特征图的最大数。 因此,从六个特征图生成一元特征向量,并且这六个特征被连接以形成倒数第二层的特征向量。 最后的softmax层接收这个特征向量作为输入,并用它来分类句子;这里我们假设二进制分类,因此描述了两种可能的输出状态。
CNN的一个重要论点是,它们很快。非常快。卷积是计算机图形的核心部分,并在 GPUs 上的硬件级别上实现。与 n-grams 相比,CNNs 在表达方面也是有效的。有了大量的词汇,计算超过 3-grams 的任何东西都可能很快变得昂贵。即使是 Google 也不提供超过 5-grams 的任何东西。卷积过滤器自动学习好的表征,而不需要表示整个词汇表。我认为,第一层中的许多学习过滤器捕获与 n-gram 非常相似(但不限于)的特征,但是以更紧凑的方式表示它们。
二维卷积nn.Conv2d
一般来说,二维卷积nn.Conv2d用于图像数据,对宽度和高度都进行卷积。
定义
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
参数说明
in_channels:在文本应用中,即为词向量的维度out_channels:卷积产生的通道数,有多少个out_channels,就需要多少个一维卷积(也就是卷积核的数量)kernel_size:卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为kernel_size * in_channelspadding:对输入的每一条边,补充0的层数
代码示例
假设现有大小为32 x 32的图片样本,输入样本的channels为1,该图片可能属于10个类中的某一类。CNN框架定义如下:
class CNN(nn.Module):
def __init__(self):
nn.Model.__init__(self)
self.conv1 = nn.Conv2d(1, 6, 5) # 输入通道数为1,输出通道数为6
self.conv2 = nn.Conv2d(6, 16, 5) # 输入通道数为6,输出通道数为16
self.fc1 = nn.Linear(5 * 5 * 16, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self,x):
# 输入x -> conv1 -> relu -> 2x2窗口的最大池化
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
# 输入x -> conv2 -> relu -> 2x2窗口的最大池化
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
# view函数将张量x变形成一维向量形式,总特征数不变,为全连接层做准备
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
图解
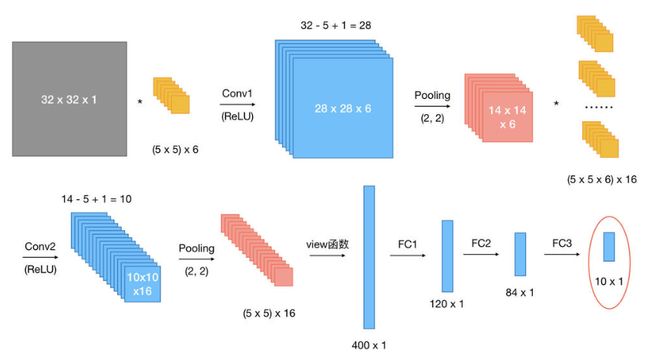
网络整体结构:[conv + relu + pooling] * 2 + FC * 3
原始输入样本的大小:32 x 32 x 1
- 第一次卷积:使用
6个大小为5 x 5的卷积核,故卷积核的规模为(5 x 5) x 6;卷积操作的stride参数默认值为1 x 1,32 - 5 + 1 = 28,并且使用ReLU对第一次卷积后的结果进行非线性处理,输出大小为28 x 28 x 6; - 第一次卷积后池化:kernel_size为
2 x 2,输出大小变为14 x 14 x 6; - 第二次卷积:使用
16个卷积核,故卷积核的规模为(5 x 5 x 6) x 16;使用ReLU对第二次卷积后的结果进行非线性处理,14 - 5 + 1 = 10,故输出大小为10 x 10 x 16; - 第二次卷积后池化:kernel_size同样为
2 x 2,输出大小变为5 x 5 x 16; - 第一次全连接:将上一步得到的结果铺平成一维向量形式,5 x 5 x 16 = 400,即输入大小为
400 x 1,W大小为120 x 400,输出大小为120 x 1; - 第二次全连接:W大小为84 x 120,输入大小为
120 x 1,输出大小为84 x 1; - 第三次全连接:W大小为
10 x 84,输入大小为``84 x 1,输出大小为10 x 1,即分别预测为10类的概率值。
总结
1.在PyTorch中,池化操作默认的stride大小与卷积核的大小一致;
2.如果池化核的大小为一个方阵,则仅需要指明一个数,即kernel_size参数为常数n,表示池化核大小为n x n。