NLP《Tranformer和Self-Attention》
一:自注意力模型
上一篇文章《seq2seq》中我们学习到了attention机制,它可以看到全局的信息,并且它也可以正确地去关注到相关的有用的信息。
原始的encoder是以RNN为基础的,RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为(编码为)定长的向量而保存所有的有效信息,所以随着所需处理的句子的长度的增加,这种结构的效果会显著下降。
从encoder到特定向量C过程中,会存在信息丢失问题,因为那么多丰富的语言,怎么可能用一个特定长度的向量表示的下呢?很难吧。之前的模型很容易由于梯度消失,距离过长导致长期依赖失效,也就是有用信息丢失。而且注意力分散,导致有用信息和无用信息无法更好区分不开。
所以,attention解决了信息提取的问题,既关注全局信息,也正确把握关键信息。这其实也是一种方法论。我关注全部,但是每一部分我关注多少?
以上纯属回顾
但是这就完美了么?虽然使用了Attention机制,只解决了encoder关键信息提取的问题(从全局出发,保证关键信息能被正确关注到,而不是使用一个向量C来试图包含所有信息(理论上显然太勉强)),但是还是基于RNN模型的啊,RNN模型只能被递归运算,无法做到并行化,我们也看到了,也许注意力就是最后集中在部分,而非全局,那么理应能够被并行化计算,加快运算速度才对。
一个想法就是CNN,CNN可以做到并行化计算,似然能这样,单每一层只关注局部信息,只有在更高层才能关注到更广一点的信息,或者是全局信息,这很明显带来了另外的计算量,顾此失彼。想一想人家seq2seq的attention机制,虽然是递归运算的,但是也就是一层就可以得到全局信息。
有没有两全其美的做法呢?即可以用attention机制去获得全局信息,正确关注到应该被关注的部分,还可以并行化计算。这就是self-attention的工作了。
显然不能使用RNN结构,这个结构天然就是递归。
所以我们一起来看看self-attention做的工作吧。
如下图所示:



这一层就这么愉快表示了。并且Wq,Wk,Wv矩阵都是学习来的,权值共享的。
但是一般呢,我们还会做出一些优化。
1:假如位置信息,因为我们看到上述式子,输入的词向量之间的位置信息丢失了。“我爱你”和“爱我你”是输出一样的结果,这显然也不符合思维的,因此需要加入位置向量信息。
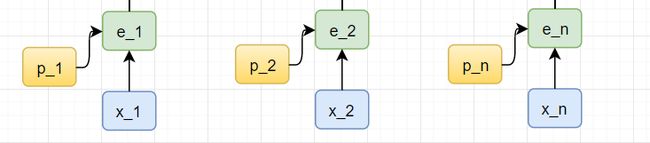
所以Step 1需要做适量修改,增加一步位置向量相关的操作:
![]()
其中P={p1,p2,p3,…,pn},维度和E是一样的,且每个元素取值是-1~1之间。
这样一来将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
2:多头self-attention(muti-head self-attention)
简单来说呢,我们希望能从不能的角度去看待位置的注意力。
实现也简单,就是设置多个完全独立的Wq,Wk,Wv矩阵,多组独立运算,分别得到自己的输出B。假设我有H个头。也就是有H组Wq,Wk,Wv矩阵,分别独立地进行运算。

最后将这H个B对应位置输出拼接起来,做一个线性变换即可。得,第i个位置输出是。

W_O也是学习到的。
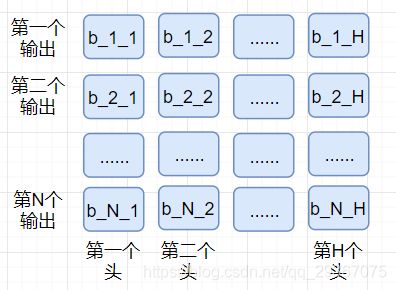
如上图所示,将多个头的值concat一起,每一行拼接后形成新的第几个输出,每一列是单个头的所有N个输出。
多头拓展了专注于不同位置的能力。
Self-attention完全依赖注意力机制来刻画输入和输出之间的全局依赖关系,而且不使用递归运算的RNN网络了。这样的好处就是:
第一:可以有效的防止RNN存在的梯度消失的问题从而导致的有用信息丢失问题(这也是基本的attention机制的好处),既可以考虑全局信息,也能正确关注到应该关注的关键信息。
第二:是允许所有的字全部同时训练(RNN的训练是迭代的,一个接一个的来,当前这个字过完,才可以进下一个字),即训练并行,大大加快了计算效率。
切记,此结构只用于替换RNN的一个层结构。

现在我们就可以试图把所有RNN的结构够可以替换成 self-attention结构了。
这样一来就可以并行化计算了,可以使用GPU进行加速处理。
这个结构是Transformer结构中提出来的,将被大量使用在Transformer结构中。
二:transformer模型
下面我们来学习一下大名鼎鼎的Transformer机制。
Seq-2-Seq的主要还是encoder-decoder的结构,但是内部结构之前是RNN和CNN。效果好点的呢,就是之前学习的,增加了Attention机制的seq-2-seq了。
现在为了并行化计算,有利于GPU加速,直接使用self-attention替换掉了RNN结构。
如下图所示:
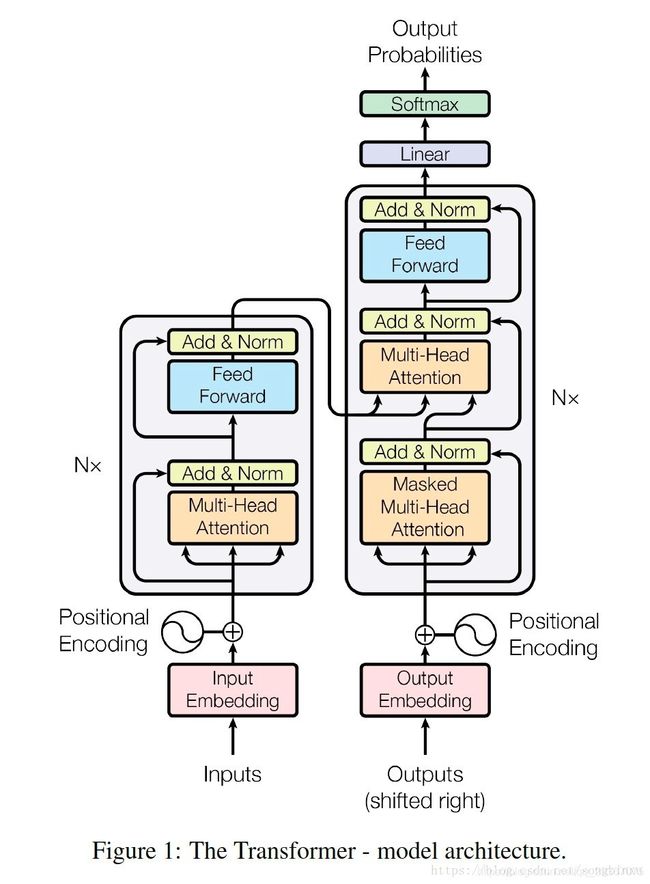
整体而言,是由一个encoders部分和一个decoders部分组成的,解码器最后有一个线性层和一个softmax层,输出对应词语的one-hot向量。
Encoders部分:
是由N个小编码器堆叠而成。
每个小编码器又是由一个多头self-attention层,和一个小的FFNN(前馈神经网络)组成。
Decoders部分:
是由N个小解码器堆叠而成。
每个小解码器又是由一个masked多头self-attention层,一个encoder-decoder多头 self-attention层,和一个小的FFNN(前馈神经网络)组成。
下面我们仔细讲解各个层:
0)Add && Norm Layer(相加归一层)
这个结构在后面很多层都有用到,因此我们先讲解这个层,方便定义符号和讲解。
先是一个残差计算。一点就是借鉴残差网络的思路,因为在应用中这个网络很深,残差结构的好多之前也学习过,防止网络过深,梯度消失,导致前面的参数无法很好更新。

然后还要做归一化操作,也就是类似于batch-normorlize的操作,目的就是归一化数据特征的分布,使其分布服从N(0~1),有利于收敛速度加快,这个在学习batch-norm的时候也学习过的,计算过程也很类似。

1)Muti-Head Self-Attention Layer(多头self-attention层)
这个不用多讲了,因为本文第一章节最开始就学习了这个计算过程。
![]()
加上相加归一层

2)FFNN Layer
这是一个 Position-wise 前向神经网络,encoder和decoder的每一层都包含一个前向神经网络,激活函数顺序是线性、RELU、线性。
![]()
加上相加归一层

3)Masked Muti-Head Self-Attention Layer
我们给词汇表增加如下词汇
< BOS>:句子开始
< EOS>:句子结尾
< UNK>:未知词汇
作为翻译的时候,比如从“我有一只猫”翻译到“I have a cat”
并行计算,先从encoder一次性计算结束,等待decoer递归迭代运算,此时decoder有点像是RNN了。每一次输入的序列都是把上一次输出的序列。
比如第一次先输入< BOS>,输出< I> ,落下去。
比如第二次先输入< I>,输出< have> ,落下去。
比如第三次先输入< I have >,输出< a> ,落下去。
比如第四次先输入< I have a >,输出< cat>,落下去。
比如第五次先输入< I have a cat >,输出< EOS>
翻译任务的话,遇到了EOS就终止了。
因此decoder每次输入的句子的长度是不一致的。怎么办呢?有多长取多长,这一层只被允许处理输出序列中更靠前的那些位置。在softmax步骤前,它会把后面的位置都是无效的,因为都没有诞生呢,无效的都给隐去(把它们设为-inf,softmax层计算后就是权值为0,也就是不关心)。因此对于不存在的序列我们就不关心了。只看存在的序列,如下图所示啊,这是前俩过程。
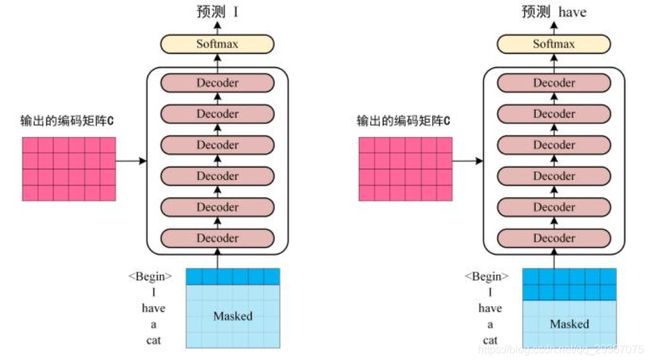
其他步骤都是和正常的self-attention的一致的,再加上加法归一层。
4)encoder-decoder Muti-Head Self-Attention Layer
这一层的目的就是给encoder最后生成的结果C做self-attention操作,也就是对encoder的每一层的都关注多少注意力,也就是充分利用原始句子的信息来影响自己的输出。
Encoder最后成功的矩阵C,每一行都是输入词汇的计算输出。有多少输入词汇,C就有多少行,这个矩阵会给每一个小decoder都传过去,让每一个小decoder都去对这个结果进行注意力运算。
唯一不同的是,attention过程中K和V矩阵的生成变了。
正常的self-attention的QKV矩阵都是E自己生成的,现在却变成了,E只产生Q矩阵,而是用C来生成K和V矩阵。
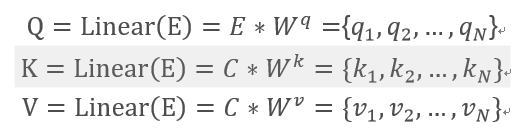
其他步骤都是和正常的self-attention的一致的。再加上加法归一层。
5)最终的Liner Layer和sofatmax Layer
这一层就是最后输出一个词汇的输出层了,此层的输入到输出如下:
![]()
最后输出是一个词汇的one-hot向量,输出到终结,否则落下去到下一次计算。
6)损失函数依然是交叉熵损失函数,这个不多讲了,之前在学习语言模型和词向量的时候都学习过的。下面说两个训练小技巧。
a)LabelSmooth,对于词语数量巨大的话,不要将one-hot向量标记为非0即1,非1即0,而可以试图将1改为0.95,剩下的0.05由任意五个词汇平分,每一个是0.01,。
b)学习率变化:可以尝试用如下的学习率变化趋势来学习模型。简单的说,就是先让学习率线性增长到某个最大的值,然后再按指数的方式衰减,如下图。

7)总结
核心就是transformer结构,这种结构完全依赖于注意力机制,取代了基于Encoder-Decoder的循环层,并且引入了位置嵌入,Multi-Head Attention机制。
优点就是,可解释性强,且容易并行计算,继承了attention机制的好处。