2022_AAAI_Meta-Learning for Online Update of Recommender Systems
[论文阅读笔记]2022_AAAI_Meta-Learning for Online Update of Recommender Systems
论文下载地址: chrome-extension://ibllepbpahcoppkjjllbabhnigcbffpi/https://homangab.github.io/papers/metarecsys.pdf
发表期刊:AAAI
Publish time: 2022
作者及单位:
- Minseok Kim1, Hwanjun Song2, Y ooju Shin1, Dongmin Park1, Kijung Shin1, Jae-Gil Lee1*
- 1KAIST,2NA VER AI Lab, {minseokkim, yooju.shin, dongminpark, kijungs, jaegil}@kaist.ac.kr, [email protected]
数据集: 正文中的介绍 附录中的介绍
- Adressa (Gulla et al. 2017),
- Amazon (Ni, Li, and McAuley 2019),
- Yelp https://www.kaggle.com/yelp-dataset/yelp-dataset
代码:
其他:
其他人写的文章
简要概括创新点: (很理论的一篇文章)前人只考虑了W或者lr,本文将2者同时考虑
- In this paper, we propose MeLON, a meta-learning based novel online recommender update strategy that supports two-directional flexibility. (在本文中,我们提出了一种基于元学习的在线推荐更新策略,该策略支持双向灵活性。)
- It is featured with an adaptive learning rate for each parameter-interaction pair for inducing a recommender to quickly learn users’ up-to-date interest. (它的特点是每个参数交互对具有自适应学习率,以诱导推荐快速了解用户的最新兴趣。)
- The procedure of MeLON is optimized following a meta-learning approach: (通过元学习方法优化了MeLON的过程:)
- it learns how a recommender learns to generate the optimal learning rates for future updates. (它学习推荐如何为将来的更新生成最佳学习率。)
- Specifically, MeLON first enriches the meaning of each interaction based on previous interactions and identifies the role of each parameter for the interaction; (具体来说,MeLON首先根据之前的交互作用丰富每个交互作用的含义,并确定每个参数对交互作用的作用;)
- and then combines these two pieces of information to generate an adaptive learning rate. (然后将这两条信息结合起来,生成自适应学习率。)
Abstract
- (1) Online recommender systems should be always aligned with users’ current interest to accurately suggest items that each user would like. (在线推荐系统应该始终与用户当前的兴趣保持一致,以准确地推荐每个用户想要的项目。)
- (2) Since user interest usually evolves over time, the update strategy should be flexible to quickly catch users’ current interest from continuously generated new user-item interactions. (由于用户兴趣通常会随着时间的推移而变化,更新策略应该灵活,以便从不断生成的新用户项交互中快速捕获用户当前的兴趣。)
- (3) Existing update strategies focus either on the importance of each user-item interaction or the learning rate for each recommender parameter, but such one-directional flexibility is insufficient to adapt to varying relationships between interactions and parameters. (现有的更新策略要么关注每个用户项交互的重要性,要么关注每个推荐参数的学习率,但这种单向灵活性不足以适应交互和参数之间的不同关系。)
- (4) In this paper, we propose MeLON, a meta-learning based novel online recommender update strategy that supports two-directional flexibility. (在本文中,我们提出了一种基于元学习的在线推荐更新策略,该策略支持双向灵活性。)
- It is featured with an adaptive learning rate for each parameter-interaction pair for inducing a recommender to quickly learn users’ up-to-date interest. (它的特点是每个参数交互对具有自适应学习率,以诱导推荐快速了解用户的最新兴趣。)
- The procedure of MeLON is optimized following a meta-learning approach: (通过元学习方法优化了MeLON的过程:)
- it learns how a recommender learns to generate the optimal learning rates for future updates. (它学习推荐如何为将来的更新生成最佳学习率。)
- Specifically, MeLON first enriches the meaning of each interaction based on previous interactions and identifies the role of each parameter for the interaction; (具体来说,MeLON首先根据之前的交互作用丰富每个交互作用的含义,并确定每个参数对交互作用的作用;)
- and then combines these two pieces of information to generate an adaptive learning rate. (然后将这两条信息结合起来,生成自适应学习率。)
- (5) Theoretical analysis and extensive evaluation on three real-world online recommender datasets validate the effectiveness of MeLON. (理论分析和对三个真实在线推荐数据集的广泛评估验证了该方法的有效性。)
1 Introduction
-
(1) The widespread of mobile devices enables a large number of users to connect to a variety of online services, such as video streaming (Davidson et al. 2010), shopping (Linden, Smith, and Y ork 2003), and news (Gulla et al. 2017), where each user seeks only a few items out of a myriad of items in services. (移动设备的广泛使用使大量用户能够连接到各种在线服务,例如视频流(Davidson et al.2010)、购物(Linden、Smith和Y ork,2003)和新闻(Gulla et al.2017),在这些服务中,每个用户只需从众多服务项目中寻找几项。)
- To keep users involved, online services struggle to meet each user’s needs accurately by deploying personalized recommender systems (Koren 2008), which suggest the items potentially interesting to him/her. (为了让用户参与进来,在线服务努力通过部署个性化推荐系统(Koren 2008)来准确满足每个用户的需求,该系统建议用户可能感兴趣的项目。)
- In an online setting where a user’s current interest changes constantly, the online recommender should catch up each user’s up-to-date interest to prevent its service from being stale (He et al. 2016). (在用户当前兴趣不断变化的在线环境中,在线推荐者应该关注每个用户的最新兴趣,以防止其服务过时(He等人,2016)。)
- To this end, recommender models are updated continuously in response to new user-item interactions. (为此,推荐模型会不断更新,以响应新的用户项目交互。)
-
(2) In modern online recommender systems, fine-tuning has been widely employed to update models since it is infeasible to re-train the models from scratch whenever new user-item interactions come in. (在现代在线推荐系统中,微调被广泛用于更新模型,因为每当出现新的用户项交互时,从头开始重新训练模型是不可行的。)
- Specifically, pre-trained models (i.e., snapshots trained on past user-item interactions) are fine-tuned based only on new user-item interactions. (具体来说,预先训练的模型(即,根据过去的用户项交互训练的快照)仅基于新的用户项交互进行微调。)
- Fine-tuning not only requires less computational cost but also has sufficient capability to reflect up-to-date information (Zhang et al. 2020). However, because few-shot incoming user-item interactions are very sparse in the user-item domain (Finn et al. 2019), the standard fine-tuning scheme would not suit online recommender systems to quickly adapt to up-to-date user interest. Therefore, the key challenge is to overcome this data sparsity for fine-tuning. (微调不仅需要较少的计算成本,而且有足够的能力反映最新信息(Zhang等人,2020)。然而,由于在用户项域中很少有用户项交互(Finn et al.2019),标准微调方案不适合在线推荐系统快速适应最新的用户兴趣。因此,关键的挑战是克服这种数据稀疏性进行微调。)
-
(3) To cope with this challenge, previous researches have been actively studied in two directions. (为了应对这一挑战,以前的研究已经从两个方向进行了积极的研究。)
- Importance reweighting adjusts the importance of each new user-item interaction (He et al. 2016; Shu et al. 2019). These methods receive the loss of a new user-item interaction from a recommender as a supervisory signal and then determine how much the recommender should be fine-tuned by each user-item interaction. (重要性重新加权调整每个新用户项交互的重要性(He等人2016;Shu等人2019)。这些方法接收来自推荐者的新用户项交互的loss作为监督信号,然后确定每个用户项交互应该对推荐者进行多少微调。)
- Meta-optimization controls how much each recommender parameter should be fine-tuned from new user-item interactions (Zhang et al. 2020). These methods determine a parameter-wise optimization strategy such as a learning rate, given the loss of the new user-item interactions and each parameter’s previous optimization history. (元优化控制每个推荐者参数应该从新的用户项交互中微调多少(Zhang等人,2020)。考虑到新用户项交互的损失和每个参数以前的优化历史,这些方法确定了参数优化策略,例如 学习率。)
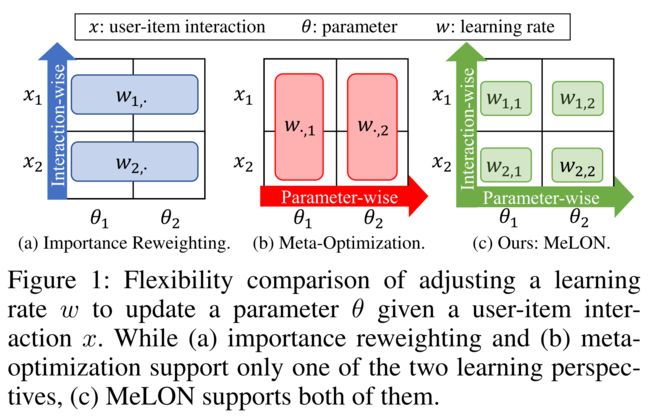
-
(4) These two orthogonal approaches focus on different aspects on learning: (这两种正交方法侧重于学习的不同方面:)
- importance reweighting focuses on the impact of each user-item interaction, as shown in Figure 1(a), (重要性重估侧重于每个用户项交互的影响,如图1(a)所示,)
- while meta-optimization focuses on that of each parameter, as shown in Figure 1(b). (而元优化侧重于每个参数的优化,如图1(b)所示。)
- That is, both approaches support the one-directional flexibility in the either data or parameter perspective. (也就是说,这两种方法都支持数据或参数透视图中的单向灵活性。)
- If we regard fine-tuning at each time period as a distinct task (Zhang et al. 2020), the role of each parameter in a recommender varies for different user-item interactions, because it is well known that an explanatory factor (i.e., parameter) in a neural network has different relevance toward different tasks(Bengio, Courville, and Vincent 2013). (如果我们将每个时间段的微调视为一项不同的任务(Zhang et al.2020),则推荐者中每个参数的作用因不同的用户项交互而不同,因为众所周知,神经网络中的 解释因子 (即参数)与不同的任务具有不同的相关性(Bengio、Courville和Vincent,2013)。)
- Thus, we contend that the flexibility in both data and parameter perspectives should be achieved. (因此,我们主张应实现数据和参数视角的灵活性。)
- However, the two existing approaches lack this level of flexibility, possibly leading to sub-optimal recommendation quality. (然而,现有的两种方法缺乏这种灵活性,可能导致次优推荐质量。)
-
(5) In this paper, we propose, MeLON (Meta-Learning for ONline recommender update), a novel online recommender update strategy that supports the flexibility in both data and parameter perspectives. (在本文中,我们提出了一种新的在线推荐者更新策略,即MELLO(在线推荐者更新的元学习),它支持数据和参数方面的灵活性。)
- It learns to adaptively adjust the learning rate of each parameter for each new user-item interaction, as illustrated in Figure 1( c). (它学习为每个新用户项交互自适应调整每个参数的学习速率,如图1(c)所示。)
- Because the optimality of a learning rate depends on how much informative on both perspectives and how to exploit them, we derive three research objectives: (由于学习率的最佳性取决于两个视角的信息量以及如何利用它们,因此我们得出三个研究目标:)
- (i) how to describe the importance of the task with a new user-item interaction, (如何通过新的用户项交互来描述任务的重要性,)
- (ii) how to identify the role of each parameter for the task, (如何确定任务中每个参数的作用,)
- then (iii) how to determine the optimal learning rate for each pair of interactions and parameters based on their mutual relevance. (如何根据相互关联性确定每对交互和参数的最佳学习率。)
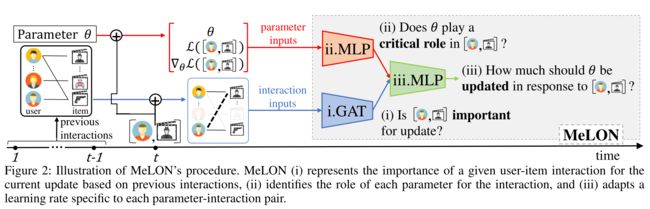
-
(6) Corresponding to the three research questions, MeLON goes through the following three steps, as shown in Figure 2.
- First, because exploiting the connections from the new user-item interaction is very helpful to mitigate the data sparsity issue, MeLON employs a graph attention network (GAT) (V eliˇ ckovi´ c et al. 2018) to represent the importance of each new user-item interaction along with previous user-item interactions. (首先,因为利用来自新用户项交互的连接非常有助于缓解数据稀疏性问题,所以瓜使用了一个图注意网络(GAT)(V eliˇckovièc et al.2018)来表示每个新用户项交互以及之前的用户项交互的重要性。)
- Then, an explicit neural mapper dynamically captures the role of a parameter, assessing its contribution to the new user-item interaction by the loss and gradient. (然后,显式神经映射器动态捕捉参数的作用,通过损失和梯度评估其对新用户项交互的贡献。)
- Last, the two representations—for an interaction and a parameter—are jointly considered to generate the optimal learning rate specific to the interaction-parameter pair. (最后,将交互和参数的两种表示结合起来考虑,以生成特定于交互参数对的最佳学习速率。)
- MeLON repeats the three steps for every online update, following the learning-to-learn philosophy of meta-learning. That is, the meta-model MeLON learns to provide the learning rates such that the recommender model updated using those learning rates quickly grasps what users want now and succeeds recommendations for them in the future. (MeLON在每次在线更新时都会重复这三个步骤,遵循元学习的“学会去学习”理念。也就是说,元模型学习提供学习率,这样使用这些学习率更新的推荐者模型就可以快速掌握用户现在想要的内容,并在将来为他们成功推荐。)
-
(7) The effectiveness of MeLON is extensively evaluated on two famous recommender algorithms using three real-world online service datasets in a comparison with six update strategies. In short, the results show that MeLON successfully improves the recommendation accuracy by up to 29.9% in term of HR@5. Such capability of MeLON is empowered by two-directional flexibility under learning-to-learn strategy, which is further supported by the theoretical analysis and ablation study. (通过使用三个真实的在线服务数据集,并与六种更新策略进行比较,对两种著名的推荐算法的有效性进行了广泛的评估。简而言之,结果表明,根据预测结果,MeLON成功地将推荐准确率提高了29.9%HR@5. MeLON的这种能力是通过学习策略下的双向灵活性来增强的,这一点得到了理论分析和实验研究的进一步支持。)
2 Preliminary and Related Work
-
(1) Online recommenders build a pre-trained model using previous user-item interactions, and the pre-trained model is continuously updated in response to incoming user-item interactions. (在线推荐人使用之前的用户项交互建立预先训练的模型,并且预先训练的模型会不断更新以响应传入的用户项交互。)
- A deep neural network (DNN) is widely used for a recommender, and it is updated for each mini-batch(Ruder 2016) to quickly adapt to users’ up-to-date interest. (深度神经网络(DNN)广泛用于推荐,并针对每个小批量(Ruder 2016)进行更新,以快速适应用户的最新兴趣。)
- Let x = ( t , u , i ) x = (t, u, i) x=(t,u,i) denote a user-item interaction between a user u u u and an item i i i at time t t t. (表示用户 u u u和项目 i i i在 t t t时的用户项目交互。)
- Suppose that a mini-batch B t \mathcal{B}_t Bt consists of n n n new user-item interactions at time t t t.
- Then, the recommender at time t t t, parameterized by Θ t = { θ t , 1 , . . . , θ t , M } \Theta_t = \{ θ_{t,1}, . . . , θ_{t,M} \} Θt={θt,1,...,θt,M} where M M M is the total number of parameters, is updated by
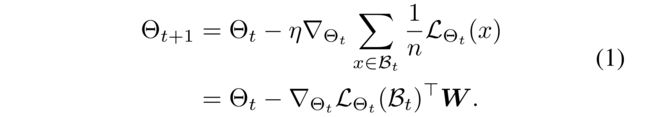
- Here, η \eta η is a learning rate,(学习率)
- and L Θ t ( B t ) ∈ R n \mathcal{L}_{Θ_t}(\mathcal{B}_t) \in R^n LΘt(Bt)∈Rn denotes the loss of new user-item interactions in the mini-batch B t \mathcal{B}t Bt by the recommender model Θ t Θ_t Θt under any objective function L \mathcal{L} L such as mean squared error (MSE) or Bayesian personalized ranking (BPR) (Rendle et al. 2009).
- The learning rate matrix W ∈ R n × M W \in R^{n×M} W∈Rn×M is used to represent the learning rate for a parameter θ m θ_m θm in response to each user-item interaction x x x, where all the learning rates (i.e., all elements of W W W) are typically set equally to w = η n w = \frac{\eta}{n} w=nη.
-
(2) Then, the overall performance is derived by evaluating each recommender snapshot for a given mini-batch at each time step, (然后,通过在每个时间步对给定小批量的每个推荐者快照进行评估,得出总体性能,)
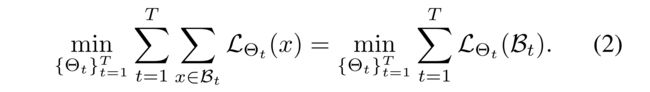
-
(3) The two directions—importance reweighting and meta-optimization—for online recommender updates are characterized by the construction of the learning rate matrix W W W. (在线推荐更新的重要性重估和元优化两个方向的特征是学习率矩阵 W W W的构造。)
2.1 Importance Reweighting (重要性重估)
-
(1) Instead of assigning the equal importance 1 / n 1/n 1/n to each user-item interaction as in Eq. (1), importance reweighting (He et al. 2016; Shu et al. 2019) assigns a different importance determined by a reweighting function ϕ I ( ⋅ ) \phi^I(·) ϕI(⋅), (重要性重新加权(He等人2016年;Shu等人2019年)没有像等式(1)中那样为每个用户项交互分配同等重要性 1 / n 1/n 1/n,而是分配了由重新加权函数 ϕ I ( ⋅ ) \phi^I(·) ϕI(⋅)确定的不同重要性,)
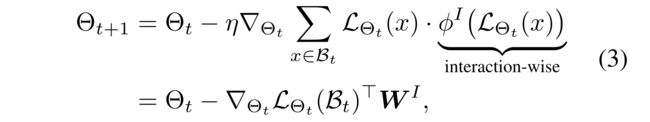
- where ϕ I ( ⋅ ) \phi^I(·) ϕI(⋅) receives the loss of each user-item interaction as its input. (接收每个用户项交互的loss作为其输入。)
- That is, W I ∈ R n × M W^I \in R^{n×M} WI∈Rn×M is constructed such that each row has the same value returned by ϕ I ( ⋅ ) \phi^I(·) ϕI(⋅). (其构造使得每一行都具有由 ϕ I ( ⋅ ) \phi^I(·) ϕI(⋅)返回的相同值.)
-
(2) The representative methods differ in the detail of ϕ I ( ⋅ ) \phi^I(·) ϕI(⋅), as follows: (有代表性的方法在 ϕ I ( ⋅ ) \phi^I(·) ϕI(⋅)的细节上有所不同,如下所示:)
- eALS (He et al. 2016) applies a heuristic rule that assigns a weight for each new user-item interaction. Typically, a high weight is set to learn the current user interest. (应用启发式规则,为每个新用户项交互分配权重。通常,设置高权重以了解当前用户的兴趣。)
- MWNet (Shu et al. 2019) maintains an external meta-model that adaptively assesses the importance of a given user-item interaction for model update that lets the updated model minimize the loss on meta-data (e.g., next recommendation in online update). (维护一个外部元模型,该模型自适应地评估给定用户项交互对模型更新的重要性,从而使更新后的模型将元数据loss降至最低(例如,在线更新中的下一个建议)。)
-
(3) However, this scheme does not support the varying role of a parameter for different tasks. (然而,该方案不支持参数在不同任务中的不同作用。)
2.2 Meta-Optimization (元优化)
-
(1) On the other hand, meta-optimization(Ravi and Larochelle 2017; Li et al. 2017; Du et al. 2019; Zhang et al. 2020) aims at adjusting the learning rate of each recommender parameter θ t , m θ_{t,m} θt,m via a learning rate function ϕ P ( ⋅ ) \phi^P(\cdot) ϕP(⋅),
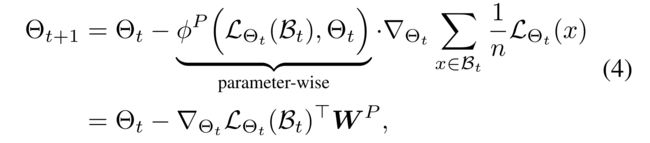
- where the function ϕ P ( ⋅ ) \phi^P(·) ϕP(⋅) receives the training loss of a mini-batch and the recommender parameters Θ t Θ_t Θt as its input.
- That is, W P ∈ R n × M W^P \in R^{n×M} WP∈Rn×M is constructed such that each column has the same value returned by ϕ P ( ⋅ ) \phi^P(·) ϕP(⋅). Again, the representative algorithms differ in the detail of ϕ P ( ⋅ ) \phi^P(·) ϕP(⋅), as follows:
-
S2Meta (Du et al. 2019) exploits MetaLSTM (Ravi and Larochelle 2017) to decide how much to forget a parameter’s previous knowledge and to learn new user-item interactions via the gating mechanism of LSTM (Hochreiter and Schmidhuber 1997). (利用MetaLSTM(Ravi和Larochelle 2017)来决定忘记参数之前的知识的程度,并通过LSTM的选通机制学习新的用户项交互(Hochreiter和Schmidhuber 1997)。)
-
MetaSGD (Li et al. 2017) maintains one learnable parameter for each model parameter to adjust its learning rate based on the loss. (为每个模型参数维护一个可学习参数,以根据损失调整其学习率。)
-
SML (Zhang et al. 2020) maintains a convolutional neural network (CNN)-based meta-model with pretrained and fine-tuned parameters. It decides how much to combine the knowledge for previous interactions and that for new user-item interactions for each parameter. (维护一个基于卷积神经网络(CNN)的元模型,具有预训练和微调的参数。它决定了在多大程度上结合以前交互的知识和每个参数的新用户项交互的知识。)
Contrary to importance reweighting, this scheme does not support the varying importance of user-item interactions.
2.3 Difference from Previous Work
- (1) While previous update strategies achieve only one-directional flexibility, i.e., ϕ 1 D ∈ { ϕ I , ϕ P } \phi^{1D} \in \{\phi^I, \phi^P\} ϕ1D∈{ϕI,ϕP}, we aim at developing an online update strategy ϕ 2 D \phi^{2D} ϕ2D that provides two-directional flexibility for the learning rates to be adaptive in both data and parameter perspectives, (而之前的更新策略只能实现单向灵活性, 例如 ϕ 1 D ∈ { ϕ I , ϕ P } \phi^{1D} \in \{\phi^I, \phi^P\} ϕ1D∈{ϕI,ϕP},我们的目标是开发一种在线更新策略 ϕ 2 D \phi^{2D} ϕ2D,该策略为学习率提供双向灵活性,使其在数据和参数方面都具有自适应性 )
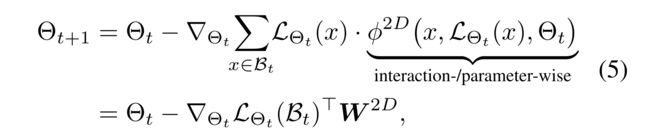
- where the function receives an individual user-item interaction, the training loss of the interaction, and the recommender parameters Θ t \Theta_t Θt as its input, which are essential ingredients to be adaptive to both user-item interactions and parameters. (函数接收单个用户项交互、交互的训练损失和推荐参数 Θ t \Theta_t Θt作为其输入,这是适应用户项交互和参数的基本要素。)
- That is, W 2 D ∈ R n × M W^{2D} \in R^{n×M} W2D∈Rn×M is constructed such that each entry can be filled with a different value returned by ϕ 2 D ( ⋅ ) \phi^{2D}(·) ϕ2D(⋅) even when either a user-item interaction or parameter is identical to other entries as in Figure 1(c ), (也就是说, W 2 D ∈ R n × M W^{2D} \in R^{n×M} W2D∈Rn×M的构造使得每个条目都可以用 ϕ 2 D ( ⋅ ) \phi^{2D}(·) ϕ2D(⋅)返回的不同值填充,即使用户项交互或参数与图1(c )中的其他条目相同,)
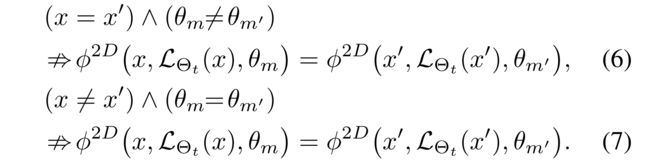
3 Methodology: MeLON
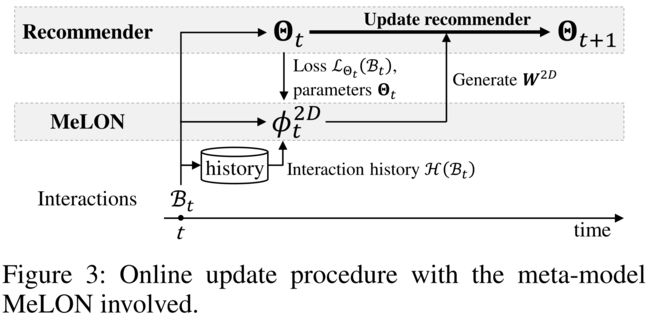
- (1) MeLON is a meta-model that determines the optimal learning rate for each recommender parameter regarding a user-item interaction. (MeLON是一个元模型,它决定了每个推荐参数在用户项目交互中的最佳学习率。)
- Figure 3 shows the collaboration between a recommender model and the meta-model MeLON. (图3显示了推荐模型和元模型之间的协作。)
- For each iteration of online update, a recommender model provides its parameters Θ t Θ_t Θt and the loss L Θ t ( B t ) \mathcal{L}_{Θ_t}(\mathcal{B}_t) LΘt(Bt) of the current batch B t \mathcal{B}t Bt to MeLON; (对于在线更新的每次迭代,推荐模型都会提供其参数 Θ t Θ_t Θt 以及当前批次 B t \mathcal{B}t Bt的损失 L Θ t ( B t ) \mathcal{L}_{Θ_t}(\mathcal{B}_t) LΘt(Bt)提供给MeLON)
- then, additionally using the previous interaction history, MeLON provides the learning rate matrix W 2 D W^{2D} W2D, which is learned to reduce L Θ t ( B t ) \mathcal{L}_{Θ_t}(\mathcal{B}_t) LΘt(Bt) as much as possible, to the recommender model; (然后,另外使用之前的交互历史,MeLON提供了学习率矩阵 W 2 D W^{2D} W2D,该矩阵被学习以尽可能多地减少 L Θ t ( B t ) \mathcal{L}_{Θ_t}(\mathcal{B}_t) LΘt(Bt);)
- finally, the recommender model is updated using W 2 D W^{2D} W2D for B t \mathcal{B}_t Bt. Please refer to the Section A of the supplementary material for more details. (最后,使用 B t \mathcal{B}_t Bt的 W 2 D W^{2D} W2D更新推荐模型 . 有关更多详细信息,请参阅补充材料的A部分。)
- The internal procedure of MeLON is described according to the three research questions: (根据这三个研究问题,描述了MeLON的内部加工过程)
- (i) representing the relevance between a user and an item for each user-item interaction, (表示每个用户项交互的用户和项之间的相关性,)
- (ii) representing the role of each parameter for a user-item interaction, (表示用户项交互的每个参数的角色)
- and (iii) determining the learning rate for each pair of user-item interactions and parameters. (确定每对用户项交互和参数的学习率。)
3.1 Step I: Representing User-Item Interaction (表示用户项交互)
- (1) Because a single user-item interaction may not contain sufficient information, we utilize the information from the previous interaction history by adding the users and items connected to the user-item interaction. (由于单个用户项交互可能不包含足够的信息,我们通过添加连接到用户项交互的用户和项目来利用以前交互历史中的信息。)
- (2) More specifically, the latent representation of the user-item interaction is derived using a graph attention network(GAT) on the bipartite graph that represents the interactions between users and items received until the current time. (更具体地说,用户项目交互的潜在表示是使用二部图上的 图注意网络(GAT) 导出的,该二部图表示用户与当前时间之前接收到的项目之间的交互。)
- (3) The bipartite graph for a user-item interaction x x x is constructed from the users and items in the interaction history in Definition 1. (用户项交互 x x x的二部图由定义1中交互历史中的用户和项构成。)
Definition 1. (INTERACTION HISTORY) (交互历史)
-
(1) Given a user-item interaction x = ( t , u , i ) x = (t, u, i) x=(t,u,i), the user interaction history of u u u is the set of items interacted with u u u before t t t, H u s e r ( x ) = { i ′ ∣ ∃ ( t ′ , u , i ′ ) ∈ X s . t . t ′ < t } \mathcal{H}_{user}(x) = \{ i^{'} | \exists (t^{'}, u, i^{'}) \in \mathcal{X} s.t. t^{'}< t \} Huser(x)={i′∣∃(t′,u,i′)∈Xs.t.t′<t},
- where X \mathcal{X} X is the entire set of user-item interactions; (这里的 X \mathcal{X} X是用户项交互的集合;)
-
similarly, the item interaction history of i i i is the set of users interacted with i i i before t t t, H i t e m ( x ) = { u ′ ∣ ∃ ( t ′ , u ′ , i ) ∈ X s . t . t ′ < t } \mathcal{H}_{item}(x) = \{u^{'} | \exists (t^{'}, u^{'}, i) \in \mathcal{X} s.t. t^{'} < t\} Hitem(x)={u′∣∃(t′,u′,i)∈Xs.t.t′<t}.
-
(2) For the bipartite graph, the users in H u s e r ( x ) \mathcal{H}_{user}(x) Huser(x) constitute the user side, and the items in H i t e m ( x ) \mathcal{H}_{item}(x) Hitem(x) constitute the item side. (对于二部图, H u s e r ( x ) \mathcal{H}_{user}(x) Huser(x)中的用户构成用户端,以及 H i t e m ( x ) \mathcal{H}_{item}(x) Hitem(x)中的项构成项目侧。)
- Here, each user (or item) node is represented by the user (or item) embedding used in the recommender model. (这里,每个用户(或项目)节点由推荐模型中使用的用户(或项目)嵌入表示。)
- An edge is created for each of the previous user-item interactions, and its weight is determined by the attention score between them. (为之前的每个用户项交互创建一个边缘,其权重由它们之间的注意分数决定。)
- Then, a user (or item) embedding is extended using the connections to the other side on the bipartite graph, as specified in Definition 2. (然后,根据定义2中的规定,使用到二部图另一侧的连接来扩展用户(或项目)嵌入。)
Definition 2. (EXTENDED EMBEDDING) (扩展嵌入)
-
(1) Given a user-item interaction x = ( t , u , i ) x = (t, u, i) x=(t,u,i), let e u e_u eu and e i ′ e_{i^{'}} ei′ be the embeddings of u u u and i ′ ∈ H u s e r ( x ) i^{'} \in \mathcal{H}_{user}(x) i′∈Huser(x). Then, the extended embedding of u , e ~ u u, \tilde{e}_u u,e~u, is defined as
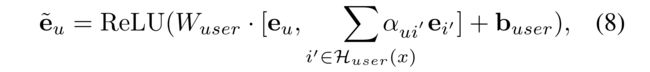
- where W u s e r W_{user} Wuser and b u s e r b_{user} buser are a learnable weight matrix and a bias vector .
- Here, α u i ′ α_{ui^{'}} αui′ indicates the attention score for i ′ i^{'} i′ and is derived by the GAT, as follows:
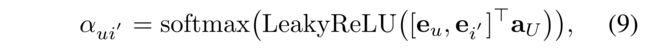
- where a U a_U aU is a learnable attention vector .
- In addition, the extended embedding of an item i , e ~ i i, \tilde{e}_i i,e~i, is defined in the same way to the opposite direction. (定义方式与对立方向一样。)
-
(2) Last, the two extended embeddings, e ~ u \tilde{e}_u e~u and e ~ i \tilde{e}_i e~i, are concatenated and gone through a linear mapping to learn the relevance between the user and the item, as specified in Definition 3. As a result, the interaction representation contains not only the rich information about a user and an item but also the relevance between them. (最后是两个扩展嵌入, e ~ u \tilde{e}_u e~u 和 e ~ i \tilde{e}_i e~i , 按照定义3的规定,连接并通过线性映射来了解用户和项目之间的相关性。因此,交互表示不仅包含关于用户和项目的丰富信息,还包含它们之间的相关性。)
Definition 3. (INTERACTION REPRESENTATION) (交互表示)
- Given a user-item interaction x = ( t , u , i ) x = (t, u, i) x=(t,u,i), let e ~ u \tilde{e}_u e~u 和 e ~ i \tilde{e}_i e~i be the extended embeddings of u u u and i i i, respectively.
- The interaction representation of x x x, h x h_x hx, is defined by
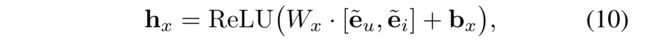
- where W x W_x Wx and b x b_x bx are a learnable weight matrix and a bias vector.
3.2 Step II: Representing Parameter Role (表示参数角色)
-
(1) Because it is well known that a parameter in a neural network has different relevance toward different tasks (user-item interactions in our study) (Bengio, Courville, and Vincent 2013), (因为众所周知,神经网络中的一个参数对不同的任务(我们研究中的用户-项目交互)具有不同的相关性(Bengio、Courville和Vincent 2013),)
- we contend that a parameter has a different role for each user-item interaction. (我们认为,参数对每个用户项交互都有不同的作用。)
- The role of a parameter can be roughly defined as its degree of impact on users (or items) of common characteristics. (参数的作用大致可以定义为其对具有共同特征的用户(或项目)的影响程度。)
- For example, a specific parameter may have a high impact on action films, while another parameter may have a high impact on romance films. (例如,一个特定参数可能对动作片有很大影响,而另一个参数可能对爱情片有很大影响。)
-
(2) To help find a parameter role, the latent representation of a parameter is derived using three types of information: (为了帮助找到参数角色,使用三种类型的信息导出参数的潜在表示形式:)
- the current value of a parameter θ t , m θ_{t,m} θt,m, (参数的当前值)
- the loss L Θ t ( x ) \mathcal{L}_{Θ_t}(x) LΘt(x) of a recommender model for a given user-item interaction x x x, (损失 L Θ t ( x ) \mathcal{L}_{Θ_t}(x) LΘt(x)对于给定用户项交互 x x x的推荐模型,)
- and the gradient ∇ θ t , m L Θ t ( x ) \nabla_{\theta_{t,m}} \mathcal{L}_{\Theta_t}(x) ∇θt,mLΘt(x) of the loss with respect to the parameter. (与参数有关的loss的梯度。)
-
The loss represents how much the recommender model parameterized by Θ t \Theta_t Θt has not learned that user-item interaction. (损失代表了由 Θ t \Theta_t Θt参数化的推荐模型的数量 尚未学习用户项交互。)
- Each gradient represents how much the corresponding parameter needs to react to that loss; (每个梯度表示对应的参数需要对该损失做出多少反应;)
- we expect that relevant parameters usually have higher gradients than irrelevant ones. (我们期望相关参数通常比无关参数具有更高的梯度。)
- Thus, putting them together, they can serve as useful information for determining a parameter role. (因此,将它们放在一起,可以作为确定参数角色的有用信息。)
-
(3) Symmetric to the interaction representation in Definition 3, the role representation is obtained through a multi-layer perceptron (MLP), as specified in Definition 4. (与定义3中的交互表示对称,角色表示通过多层感知器(MLP) 获得,如定义4所述。)
- Because the magnitude of the loss and gradient varies across the pair of interactions and parameters, we apply a preprocessing technique (Ravi and Larochelle 2017; Andrychowicz et al. 2016) to adjust the scale of the loss and gradient as well as to separate their magnitude and sign. (由于损失和梯度的大小在一对相互作用和参数之间变化,我们采用预处理技术(Ravi and Larochelle 2017;Andrychowicz et al.2016)来调整损失和梯度的规模,以及分离它们的大小和符号。)
- As a result, the output of the MLP, h θ t , m h_{θ_{t,m}} hθt,m, is regarded to represent the role of θ t , m θ_{t,m} θt,m with respect to the given user-item interaction x x x. (因此,MLP的输出, h θ t , m h_{θ_{t,m}} hθt,m , 被认为 θ t , m θ_{t,m} θt,m的角色表示,当提及给定的用户项目交互 x x x)
Definition 4. (ROLE REPRESENTATION) (角色表示)
- Given a parameter θ t , m θ_{t,m} θt,m and a user-item interaction x x x, the role representation of θ t , m θ_{t,m} θt,m, h θ t , m h_{θ_{t,m}} hθt,m is defined by (给定一个参数 θ t , m θ_{t,m} θt,m以及用户项交互 x x x, θ t , m θ_{t,m} θt,m的角色表示, h θ t , m h_{θ_{t,m}} hθt,m定义为)
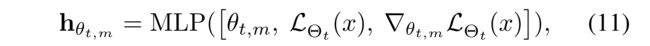
- where the MLP consists of L L L linear mapping layers each followed by the ReLU activation function. (其中,MLP由 L L L个线性映射层组成,每个层后跟ReLU激活函数。)
3.3 Step III: Adapting Learning Rate (自适应学习率)
- (1) The resulting two representations, h x h_x hx and h θ t , m h_{θ_{t,m}} hθt,m, respectively, contain rich information about the importance of the user-item interaction x x x and the role of the parameter θ t , m θ_{t,m} θt,m.
- Hence, we employ a linear mapping layer which fuses the two representations and adapts the learning rate w x , θ t , m l r w^{lr}_{x,θ_{t,m}} wx,θt,mlr to the given interaction-parameter pair, as follows: (因此,我们采用了一个线性映射层,它融合了这两种表示,并调整学习率 w x , θ t , m l r w^{lr}_{x,θ_{t,m}} wx,θt,mlr对于给定的交互参数对,如下所示:)
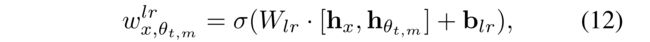
- where σ \sigma σ is a sigmoid function.
- Hence, we employ a linear mapping layer which fuses the two representations and adapts the learning rate w x , θ t , m l r w^{lr}_{x,θ_{t,m}} wx,θt,mlr to the given interaction-parameter pair, as follows: (因此,我们采用了一个线性映射层,它融合了这两种表示,并调整学习率 w x , θ t , m l r w^{lr}_{x,θ_{t,m}} wx,θt,mlr对于给定的交互参数对,如下所示:)
- (2) The learning rate is likely to be high if the user-item interaction is important while the parameter plays a key role to the interaction, so that the parameter is quickly adapted to the interaction. (如果用户项交互很重要,而参数对交互起着关键作用,那么学习率可能会很高,因此参数会快速适应交互。)
- Then, the learning rate is used to update the current parameter θ t , m θ_{t,m} θt,m for the user-item interaction x x x, as follows: (然后,使用学习率来更新当前参数 θ t , m θ_{t,m} θt,m对于用户项交互 x x x,如下所示:)
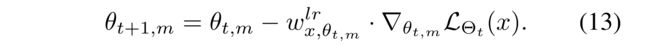
- Then, the learning rate is used to update the current parameter θ t , m θ_{t,m} θt,m for the user-item interaction x x x, as follows: (然后,使用学习率来更新当前参数 θ t , m θ_{t,m} θt,m对于用户项交互 x x x,如下所示:)
4 Theoretical Analysis on Update Flexibility (更新灵活性的理论分析)
-
(1) Our suggested online update strategy MeLON, ϕ 2 D \phi^{2D} ϕ2D, leaves a question of how much benefit it can bring compared with the previous two strategies ϕ I \phi^I ϕI and ϕ P \phi^P ϕP. (我们建议的在线更新策略 ϕ 2 D \phi^{2D} ϕ2D留下了一个问题,即与前两种策略 ϕ I \phi^I ϕI 和 ϕ P \phi^P ϕP相比,它能带来多少益处。)
- As an effort to resolve it, we present a theoretical analysis of the advantage of flexible update in terms of rank, where the rank of a learning rate matrix r a n k ( W ) rank(W) rank(W) demonstrates how flexible an update can be via W W W. (为了解决这一问题,我们从秩的角度对灵活更新的优势进行了理论分析,其中学习率矩阵秩 r a n k ( W ) rank(W) rank(W)表明了通过 W W W更新的灵活性。)
- That is, when its rank can be higher, W W W can support more flexible updates of parameters in response to new interactions. (也就是说,当其排名可以更高时, W W W可以支持更灵活的参数更新,以响应新的交互。)
- The previous strategies limit the rank to 1 since, as discussed above, they provide an identical learning rate either to every interaction or to every parameter. (前面的策略将排名限制为1,因为如上所述,它们为每个交互或每个参数提供相同的学习率。)
- In MeLON, the rank can be higher since the learning rates are adapted to each interaction-parameter pair. (在MeLON中,等级可以更高,因为学习率适用于每个交互参数对。)
- In this regard, we show that previous strategies may suffer from large optimality gap with an optimal learning rate matrix W ∗ W^∗ W∗, while the gap can be reduced by MeLON. (在这方面,我们表明,以前的策略可能存在较大的最优性差距,最优学习率矩阵为 W ∗ W^∗ W∗, 而 MeLON可以缩小这种差距。)
-
(2) We denote the recommender parameters updated by W W W as Θ ^ \hat{\Theta} Θ^ and the optimal parameters as Θ ∗ Θ^∗ Θ∗. (我们将 W W W更新的推荐参数表示为 Θ ^ \hat{\Theta} Θ^, 最佳参数表示为 Θ ∗ Θ^∗ Θ∗)
- Then, the optimality gap between the two sets of parameters ∥ Θ ∗ − Θ ^ ∥ 2 \parallel \Theta^∗−\hat{\Theta}\parallel_2 ∥Θ∗−Θ^∥2 is dependent on the gap between the learning rate matrices ∥ W ∗ − W ∥ 2 \parallel W^∗− W \parallel_2 ∥W∗−W∥2 in terms of spectral norm as follows: (然后,两组参数之间的最优性差 ∥ Θ ∗ − Θ ^ ∥ 2 \parallel \Theta^∗−\hat{\Theta}\parallel_2 ∥Θ∗−Θ^∥2取决于学习率矩阵之间的差距 ∥ W ∗ − W ∥ 2 \parallel W^∗− W \parallel_2 ∥W∗−W∥2. 以谱域的形式,如下所示:)
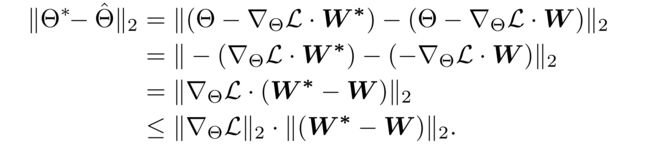
- Then, the optimality gap between the two sets of parameters ∥ Θ ∗ − Θ ^ ∥ 2 \parallel \Theta^∗−\hat{\Theta}\parallel_2 ∥Θ∗−Θ^∥2 is dependent on the gap between the learning rate matrices ∥ W ∗ − W ∥ 2 \parallel W^∗− W \parallel_2 ∥W∗−W∥2 in terms of spectral norm as follows: (然后,两组参数之间的最优性差 ∥ Θ ∗ − Θ ^ ∥ 2 \parallel \Theta^∗−\hat{\Theta}\parallel_2 ∥Θ∗−Θ^∥2取决于学习率矩阵之间的差距 ∥ W ∗ − W ∥ 2 \parallel W^∗− W \parallel_2 ∥W∗−W∥2. 以谱域的形式,如下所示:)
-
(3) Then, a lower bound of ∥ W ∗ − W ∥ 2 \parallel W^∗− W \parallel_2 ∥W∗−W∥2 is obtained from the singular values σ \sigma σ of W ∗ W^∗ W∗, as formalized in Lemma 1.
Lemma 1.
(Eckart and Y oung 1936) Given W ∗ W^∗ W∗ with its singular value decomposition U Σ V UΣV UΣV and k ∈ { 1 , ⋅ ⋅ ⋅ , r a n k ( W ∗ ) − 1 } k \in \{1,· · · , rank(W^∗) − 1\} k∈{1,⋅⋅⋅,rank(W∗)−1}, (给出 W ∗ W^∗ W∗和它的奇异值分解)
- let W k ∗ = ∑ r = 1 k σ r U r V r W^∗_k = \sum^{k}_{r=1}\sigma_rU_rV_r Wk∗=∑r=1kσrUrVr,
- where σ r \sigma_r σr is the r r r-th largest singular value. (是第 r r r个大的奇异值。)
- Then, W k ∗ W^∗_k Wk∗ is the best rank-k approximation of W ∗ W^∗ W∗ in terms of spectral norm, ( W k ∗ W^∗_k Wk∗是最好的秩k的 W ∗ W^∗ W∗近似,以谱域的形式)
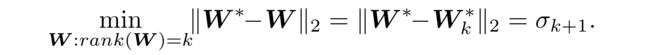
Proof. See (Eckart and Y oung 1936).
- Based on Lemma 1, we show that a flexible update strategy ϕ 2 D \phi^{2D} ϕ2D can enjoy smaller optimality gap than the previous strategies, which are one-directionally flexible. (基于引理1,我们证明了一种灵活的更新策略 ϕ 2 D \phi^{2D} ϕ2D比之前的策略具有更小的优化差距,后者在方向上是灵活的。)
Lemma 2.
For W I W^I WI and W P W^P WP (see Eq. (3) and Eq. (4)), r a n k ( W I ) = r a n k ( W P ) = 1 rank(W^I) = rank(W^P) = 1 rank(WI)=rank(WP)=1 holds.
Proof.
- Every column of WI equals to ϕ I ( L Θ t ( x ) ) ∈ R n \phi^I (\mathcal{L}_{\Theta_t}(x)) \in R^n ϕI(LΘt(x))∈Rn,
- and every row of W P W^P WP equals to ϕ P ( L Θ t ( B t ) , Θ t ) ∈ R M \phi^P(\mathcal{L}_{\Theta_t}(\mathcal{B}_t),\Theta_t ) \in R^M ϕP(LΘt(Bt),Θt)∈RM.
- Hence, r a n k ( W I ) = r a n k ( W P ) = 1 rank(W^I) = rank(W^P) = 1 rank(WI)=rank(WP)=1 holds.
Theorem 3.
For W 1 D ∈ W I , W P W^{1D} \in {W^I,W^P} W1D∈WI,WP (see Eq. (3) and Eq. (4)) and W2D(see Eq. (5)), the following inequality holds:
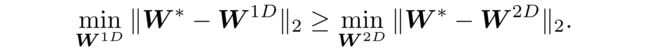
Proof.
-
Lemma 1, Lemma 3, and W 1 D ∈ { W I , W P } W^{1D} \in \{W^I, W^P\} W1D∈{WI,WP} imply m i n W 1 D ∥ W ∗ − W 1 D ∥ = σ 2 min_{W^{1D}} \parallel W^∗− W^{1D} \parallel = \sigma_2 minW1D∥W∗−W1D∥=σ2.
-
On the other hand, r a n k ( W 2 D ) ≥ 1 rank(W^{2D}) ≥ 1 rank(W2D)≥1,(1:Specifically, by Eq. (6) and Eq. (7), r a n k ( W 2 D ) rank(W^{2D}) rank(W2D) is not necessarily one and can be greater than one.)
-
Thus, by Lemma 1, m i n W 2 D ∥ W ∗ − W 2 D ∥ ≤ σ 2 min_{W^{2D}} \parallel W^∗ - W^{2D} \parallel ≤ \sigma_2 minW2D∥W∗−W2D∥≤σ2, which concludes the proof, holds.
-
In the experiments, we empirically validate the advantage of the two-directional flexibility of W 2 D W^{2D} W2D. (在实验中,我们实证验证了 W 2 D W^{2D} W2D的双向灵活性的优势。)
5 Evaluation
Our evaluation was conducted to support the following: (我们的评估旨在支持以下内容:)
- The performance improvement by MeLON is consistent for various datasets and recommenders. (对于不同的数据集和推荐, MeLon的性能改进是一致的。)
- MeLON helps recommenders quickly adapt to users’ up-to-date interest over time. (MeLON帮助推荐人快速适应用户的最新兴趣)
- The two-directional flexibility in MeLON is very effective for recommendation. (MeLON的双向灵活性对推荐非常有效。)
- The training overhead of MeLON is affordable. (MeLON的训练开销是可以负担的。)
5.1 Experiment Settings
5.1.1 Datasets.
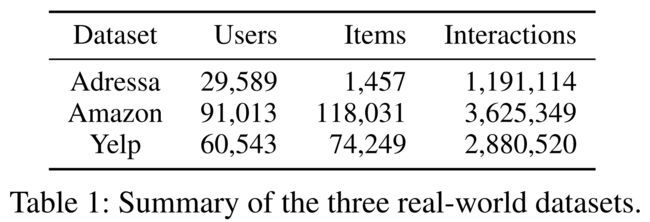
- We used three real-world online recommendation benchmark datasets:
- Adressa (Gulla et al. 2017),
- Amazon (Ni, Li, and McAuley 2019),
- and Yelp 2,
- as summarized in Table 1.
- The duration that a user’s interest persists varies across datasets; (用户兴趣持续的时间因数据集而异;)
- relatively short duration for news in Adressa, typically longer duration for locations in Yelp, and in-between them for products in Amazon. (Adressa中的新闻持续时间相对较短,Yelp中的位置通常持续时间较长,Amazon中的产品则介于两者之间。)
5.1.2 Algorithms and Implementation Details. (算法和实现细节。)
- (1) For the base recommender, we used two popular personalized recommender algorithms: (对于基本推荐,我们使用了两种流行的个性化推荐算法)
- BPR (Koren, Bell, and V olinsky 2009; Rendle et al. 2009)
- and NCF (He et al. 2017).
- (2) For the online training strategy, we compared MeLON with six update methods, namely (对于在线培训策略,我们比较了六种更新方法,即)
- Default, eALS (He et al. 2016),
- MWNet (Shu et al. 2019),
- MetaSGD (Li et al. 2017),
- S2Meta (Du et al. 2019),
- and SML (Zhang et al. 2020).
- “Default” is the standard fine-tuning strategy, and the remaining methods are based on either importance reweighting or meta-optimization. (“默认”是标准的微调策略,其余方法基于重要性重新加权或元优化。)
- (3) Hence, 14 combinations of two recommenders and seven update strategies were considered for evaluation. The experiment setting was exactly the same for all the combinations. (因此,评估时考虑了两个推荐者和七个更新策略的14种组合。所有组合的实验设置都完全相同。)
5.1.3 Evaluation Metrics.
-
(1) We used two widely-used evaluation metrics, (我们使用了两个广泛使用的评估指标)
- hit rate (HR)
- and normalized discounted cumulative gain (NDCG).
-
(2) Given a recommendation list, (给出一份推荐列表)
- HR measures the rate of true user-interacted items in the list, (HR测量列表中真实用户交互项目的比率,)
- while NDCG additionally considers the ranking of the user-interacted items. (而NDCG还考虑了用户交互项目的排名。)
-
(3) The two metrics were calculated for top@5, top@10, and top@20 items, respectively.
-
(4) For each mini-batch on prequential evaluation, a recommender estimates the rank of each user’s 1 interacted item and randomly-sampled 99 non-interacted items, and this technique is widely used in the literature (He et al. 2016; Du et al. 2019) because it is time-consuming to rank all non-interacted items. (对于后续评估中的每个小批量,推荐人会估计每个用户的1个交互项目和随机抽样的99个非交互项目的排名,这种技术在文献中被广泛使用(He等人2016;Du等人2019),因为对所有非交互项目进行排名非常耗时。)
-
Please see Section B of the supplementary material for more details of the experiment settings. (有关实验设置的更多细节,请参见补充材料B部分。)
5.2 Overall Performance Comparison
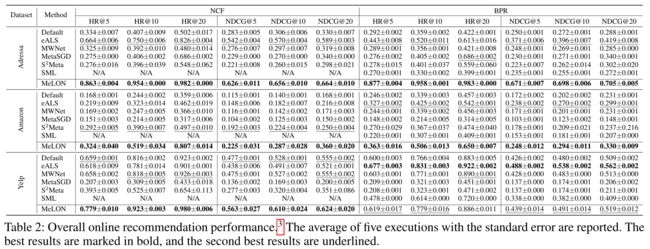
- (1) Table 2 shows the top-k recommendation performance with varying update strategies for the three datasets. (表2显示了三个数据集在不同更新策略下的top-k推荐性能。)
- (2) Overall, MeLON greatly boosts the recommendation performance compared with the other update strategies in general. (总体而言,与其他更新策略相比,甜瓜极大地提高了推荐性能)
- It outperforms the other update strategies with NCF in terms of HR@5 by up to 29.9%, 10.9%, and 18.2% in Adressa, Amazon, and Yelp, respectively. (在性能方面,它优于NCF的其他更新策略HR@5在Adressa、Amazon和Yelp分别高达29.9%、10.9%和18.2%。)
- This benefit is attributed to the two-directional flexibility of MeLON, which successfully adapts learning rates on each interaction-parameter pair. (这种优势归功于MeLON的双向灵活性,它成功地适应了每个交互参数对的学习率。)
- That is, MeLON considers the importance of the user-item interaction as well as the role of the parameter, while the compared strategies consider only either of them. (也就是说,MeLON考虑用户项目交互的重要性以及参数的作用,而比较策略只考虑其中的任何一个。)
5.2.1 Flexibility Gap. (灵活性隔阂,差距)
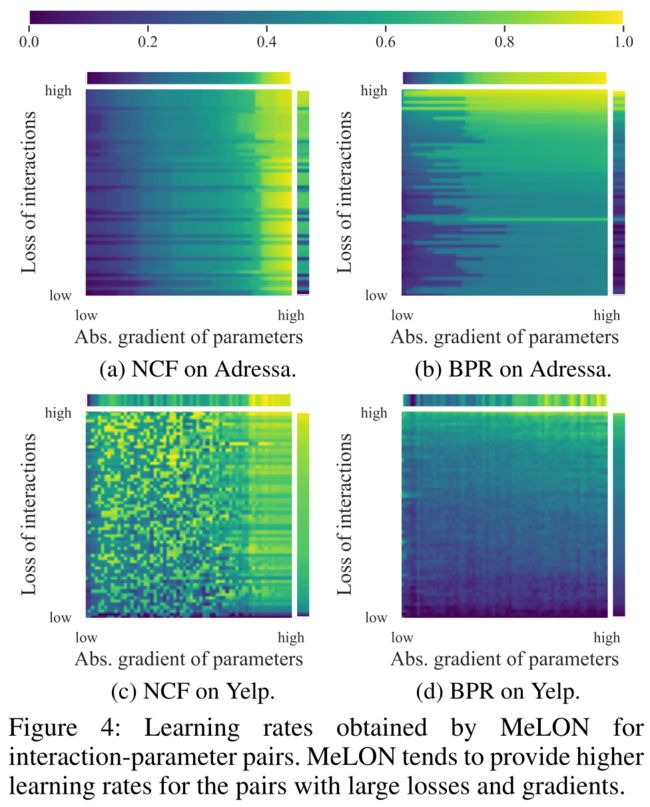
- (1) Figure 4 displays the learning rate matrix of all interaction-parameter pairs in MeLON when trained on Adressa and Yelp. (图4显示了在Adressa和Yelp上训练时,MeLON中所有交互参数对的学习率矩阵。)
- Here, each square matrix displays the two-directional learning rates ( W 2 D W^{2D} W2D) for all interaction-parameter pairs. (这里,每个方阵显示所有交互参数对的两个方向学习率( W 2 D W^{2D} W2D)
- On the other hand, the top and right bars are the averages along one axis, which can be considered as the one-directional learning rates ( W 1 D W^{1D} W1D). (另一方面,顶部和右侧栏是沿一个轴的平均值,可以认为是单向学习率( W 1 D W^{1D} W1D)
- The learning rates in the square matrix are flexibly determined for each interaction-parameter pair, and high learning rates are assigned when the loss or gradient is high. (对于每个交互参数对,灵活地确定平方矩阵中的学习率,当损失或梯度较大时,分配较高的学习率。)
- A row or column does not stick to the same learning rate, and this visualization clearly demonstrates the necessity of the two-directional flexibility. (一行或一列并不能保持相同的学习速度,这种可视化清楚地表明了双向灵活性的必要性。)
- The gap between the learning rate in W 2 D W^{2D} W2D and that in W 1 D W^{1D} W1D in Figure 4 is directly related to how quickly a recommender adapts to up-to-date user interests, which in turn leads to the performance difference between MeLON and the previous update strategies. ( W 2 D W^{2D} W2D和图4中 W 1 D W^{1D} W1D的学习率之间的差距与推荐者适应最新用户兴趣的速度直接相关,这反过来又导致了MeLON和以前的更新策略之间的性能差异。)
5.2.2 In-Depth Comparison. (深入比较)
-
(1) We provide interesting observations for the online update strategies: (我们为在线更新策略提供了有趣的观察结果:)
- Importance reweighting works well for datasets where a user’s interest changes slowly (e.g., Yelp); (对于用户兴趣变化缓慢(例如Yelp)的数据集,重要性重新加权效果良好;)
- Meta-optimization works well for datasets where a user’s interest changes quickly (e.g., Adressa); (元优化适用于用户兴趣变化迅速的数据集(如Adressa);)
- MeLON works well for both types of datasets (甜瓜对这两种类型的数据集都适用)
-
(2) Specifically, in terms of HR@20, an importance reweighting strategy, MWNet, enhances the recommendation performance in Yelp, but shows worse performance in Adressa than Default. (具体来说HR@20, MWNet是一种重要的重估策略,它提高了Yelp中的推荐性能,但在Adressa中的性能比默认值差。)
- In contrast, an opposite trend is observed for the two meta-optimization strategies, MetaSGD and S2Meta. (相比之下,两种元优化策略MetaSGD和S2Meta的趋势相反。)
-
(4) Thus, we conjecture that, for time-sensitive user interest, such as news in Adressa, it is more important to focus on the parameter roles, which could be associated with the topics in this dataset. (因此,我们推测,对于时间敏感的用户兴趣,例如Adressa中的新闻,更重要的是关注参数角色,这可能与该数据集中的主题相关。)
- On the other hand, for time-insensitive user interest, such as places in Yelp, it would be better to focus on the interaction itself. (另一方面,对于时间不敏感的用户兴趣,比如Yelp中的位置,最好关注交互本身。)
- This claim can be further supported by the different trends in Figure 4, where horizontal (i.e., parameter-wise) lines are more visible in the Adressa dataset, but vertical (i.e., interaction-wise) lines are more visible in the Yelp dataset. (图4中的不同趋势进一步支持了这一说法,其中水平线(即参数方向)在Adressa数据集中更为明显,而垂直线(即交互方向)在Yelp数据集中更为明显。)
5.3 Performance Trend over Time (随时间变化的性能趋势)
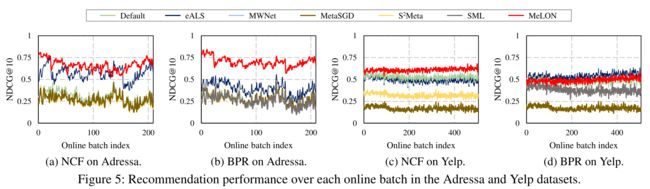
- (1) Figure 5 shows the NDCG@10 performance trend of seven update strategies over each online test batch of the Adressa and Yelp datasets. (图5显示了NDCG@10Adressa和Yelp数据集的每个在线测试批次中七种更新策略的性能趋势。)
- (2) Overall, only MeLON consistently adheres to the highest performance (close to the highest in Figure 5(d)) compared with other update strategies during the entire test period. (总的来说,在整个测试期间,与其他更新策略相比,只有MeLON始终保持最高的性能(接近图5(d)中的最高性能)。)
- (3) The performance gap between MeLON and the others widens especially in Addressa because its news data becomes quickly outdated and needs more aggressive adaptation for better recommendation. (MeLON和其他产品之间的性能差距扩大了,尤其是在Addressa,因为它的新闻数据很快就会过时,需要更积极的调整以获得更好的推荐。)
- (4) In this regard, eALS also shows better performance than others since it always assigns high weights for new user-item interactions. (在这方面,eALS也显示出比其他系统更好的性能,因为它总是为新用户项交互分配高权重。)
- (5) On the other hand, in the Yelp dataset where the user’s interest may not change quickly, all the update strategies show small performance fluctuations. (另一方面,在Yelp数据集中,用户的兴趣可能不会迅速改变,所有更新策略都显示出较小的性能波动。)
5.4 Ablation Study on Two-Directional Flexibility (双向灵活性的消融研究)
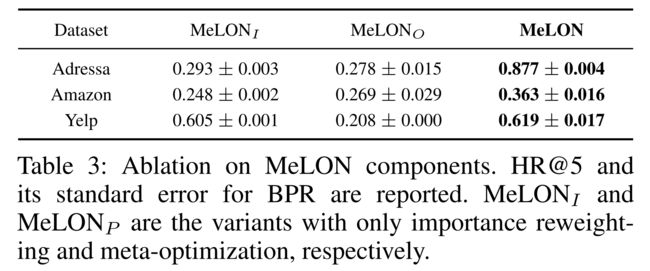
- (1) We conduct an ablation study to examine the two-directional flexibility of MeLON by using its two variants with partial flexibility: (我们进行了一项烧蚀研究,以检测MeLON的双向灵活性,使用其两个具有部分灵活性的变体)
- (i) MeLONI, an importance reweighting variant without parameter-wise inputs and (MeLONI,一种无参数输入)
- (ii) MeLONP, a meta-optimization variant without interaction-wise inputs. (MeLONP,一个没有交互输入的元优化变体。)
- (2) Table 3 shows the performance of the two variants along with the original MeLON on the three datasets. Of course, MeLON is far better than the variants. (表3显示了这两个变种以及原始瓜在三个数据集上的性能。当然,甜瓜比变种要好得多。)
- (3) In addition, the performance of MeLONI is similar to those of the importance reweighting strategies (e.g., MWNet) in Table 2, while MeLONP shows the results similar to the meta-optimization strategies (e.g., S2Meta). (此外,MeLONI的性能类似于表2中的重要性重新加权策略(如MWNet),而MeLONP的结果类似于元优化策略(如S2Meta)。)
- (4) Therefore, the power of MeLON is attained when the two-directional flexibility is accompanied. (因此,当两个方向的灵活性同时存在时,MeLON的力量就达到了。)
5.5 Elapsed Time for Online Update (在线更新所用的时间)
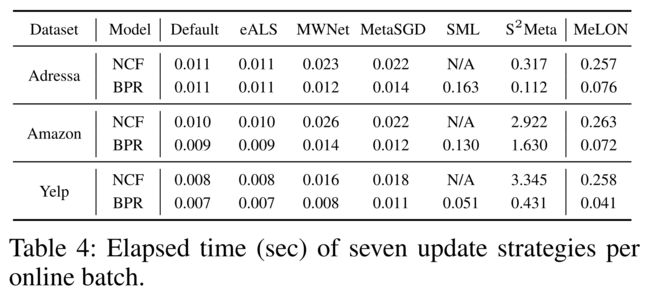
- (1) Table 4 shows the average elapsed time of the seven update strategies per online batch update. (表4显示了每次在线批量更新七种更新策略的平均运行时间。)
- (2) Overall, all the update strategies including MeLON show affordable update time except S2Meta which consumes even seconds in Yelp and Amazon. (总的来说,所有的更新策略,包括MeLON,都显示出价格合理的更新时间,除了S2Meta,它在Yelp和Amazon中甚至需要几秒钟。)
- (3) That is, MeLON is still capable of handling multiple recommender updates within a second, which is fast enough for online recommender training. (也就是说,MeLON仍然能够在一秒钟内处理多个推荐更新,这对于在线推荐训练来说已经足够快了。)
- (4) The speed of MeLON is improved by its selective parameter update; (通过参数的选择性更新,提高了MeLON的速度)
- given a user-item interaction, MeLON updates only the parameters involved with the recommender’s computation for the interaction. This technique helps MeLON maintain its competitive update speed, despite the use of a meta-model which is believed to be time-consuming. (给定一个用户项交互,MeLON只更新推荐计算交互所涉及的参数。尽管元模型的使用被相信是耗时的,但这种技术有助于保持其具有竞争力的更新速度。)
6 Conclusion
- (1) In this paper, we proposed MeLON, a meta-learning-based highly flexible update strategy for online recommender systems. (在本文中,我们提出了一种基于元学习的 在线 推荐系统的高度灵活的更新策略)
- MeLON provides learning rates adaptively to each parameter-interaction pair to help recommender systems be aligned with up-to-date user interests. (MeLON为每个参数交互对 提供自适应学习率,以帮助推荐系统与最新的用户兴趣保持一致。)
- To this end, MeLON
- first represents the meaning of a user-item interaction and the role of a parameter using a GAT and a neural mapper. (首先使用GAT和神经映射器表示用户项交互的含义和参数的作用。)
- Then, the adaptation layer exploits the two representations to determine the optimal learning rate. (然后,自适应层利用这两种表示来确定最佳学习速率。)
- (2) Extensive experiments were conducted using three real-world online service datasets, and the results confirmed the higher accuracy of MeLON by virtue of its two-directional flexibility as validated in the ablation study and theoretical analysis. (使用三个真实的在线服务数据集进行了广泛的实验,结果证实了MeLON由于其双向灵活性而具有更高的准确性,这在消融实验和理论分析中得到了验证。)
Acknowledgement
References
Supplementary Material for Paper 2570: Meta-Learning for Online Update of Recommender Systems
A. Online Recommender Training (在线推荐训练)
-
(1) While an online recommender can be trained on new user-item interactions with adaptive learning rates by the meta-model MeLON, the optimality condition varies with time. (虽然在线推荐可以通过元模型接受新用户项目交互的训练,并具有自适应学习率,但最优性条件随时间而变化。)
- Therefore, MeLON should be continuously updated along with the recommender to avoid being stale. (因此,MeLON应该随着推荐不断更新,以避免陈腐。)
- To this end, as shown in Figure 6, for every incoming mini-batch B t \mathcal{B}_t Bt, we first conduct two steps to train the meta-model ϕ 2 D \phi^{2D} ϕ2D before updating the recommender model Θ \Theta Θ, following the common update procedure of meta-learning (Ren et al. 2018; Shu et al. 2019). (为此,如图6所示,对于每个传入的小批量 B t \mathcal{B}_t Bt , 按照元学习的常见更新程序(Ren等人2018;Shu等人2019),在更新推荐模型 Θ \Theta Θ之前,我们首先执行两个步骤来训练元模型 ϕ 2 D \phi^{2D} ϕ2D。)
- Note that Figure 6 is made more detailed by clarifying the two steps for ϕ 2 D \phi^{2D} ϕ2D, compared with Figure 3 (in the main paper). (请注意,与图3(在主要论文中)相比,图6通过阐述 ϕ 2 D \phi^{2D} ϕ2D的两个步骤而变得更详细。)
-
1. Recommender model preliminary update: (推荐模型初步更新:)
- For the users and items in the new mini-batch B t \mathcal{B}_t Bt at each iteration, we (在每次迭代中,对于新的mini-batch B t \mathcal{B}_t Bt中的用户和项目,我们)
- first derive their last interactions B t l a s t B^{last}_t Btlast before the current interaction. (首先推导出它们最后的相互作用 B t l a s t B^{last}_t Btlast,在当前交互之前。)
- Then, using the current meta-model ϕ t 2 D \phi^{2D}_t ϕt2D, the parameter Θ t \Theta_t Θt of the recommender model is updated on the latest interactions B B B last t t t to create a model with Θ ~ \tilde{\Theta} Θ~ by (然后,使用当前的元模型 ϕ t 2 D \phi^{2D}_t ϕt2D,推荐模型的 参数 Θ t \Theta_t Θt更新为最近一次的交互 B B B,上一次 t t t,以创建具有 Θ ~ \tilde{\Theta} Θ~的模型)
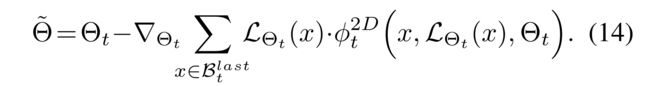
-
2. Meta-model update: (元模型更新:)
- Because Θ ~ \tilde{Θ} Θ~ obtained by Eq. (14) is widely known as an inspection on the efficacy of the current meta-model (Ren et al. 2018; Shu et al. 2019), the feedback from Θ ~ \tilde{\Theta} Θ~ is exploited to update the meta-model on the incoming mini-batch B t \mathcal{B}_t Bt by (因为由式(14)得出的 Θ ~ \tilde{Θ} Θ~被广泛认为是对当前元模型有效性的检验(Ren等人2018年;Shu等人2019年),)
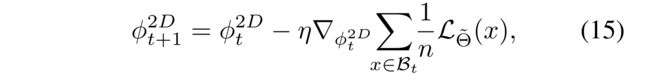
- where η \eta η is a learning rate for meta-model.
- Because Θ ~ \tilde{Θ} Θ~ obtained by Eq. (14) is widely known as an inspection on the efficacy of the current meta-model (Ren et al. 2018; Shu et al. 2019), the feedback from Θ ~ \tilde{\Theta} Θ~ is exploited to update the meta-model on the incoming mini-batch B t \mathcal{B}_t Bt by (因为由式(14)得出的 Θ ~ \tilde{Θ} Θ~被广泛认为是对当前元模型有效性的检验(Ren等人2018年;Shu等人2019年),)
-
3. Recommender model update:
- Finally, the parameter Θ t \Theta_t Θt of the recommender model is updated using the updated meta-model ϕ t + 1 1 D \phi^{1D}_{t+1} ϕt+11D on the mini-batch B t \mathcal{B}_t Bt by
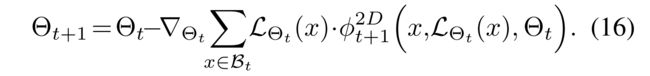
- Finally, the parameter Θ t \Theta_t Θt of the recommender model is updated using the updated meta-model ϕ t + 1 1 D \phi^{1D}_{t+1} ϕt+11D on the mini-batch B t \mathcal{B}_t Bt by
-
(2) Note that MeLON selectively performs the update of recommender parameters involved in the recommender’s computation for each interaction. Therefore, the required update time for MeLON is comparable to other update strategies, such as SML and S2Meta, as empirically confirmed in the evaluation results. (请注意,对于每一次交互,MeLON都会选择性地更新推荐计算中涉及的推荐参数。因此,MeLON所需的更新时间与其他更新策略(如SML和S2Meta)相当,这在评估结果中得到了实证证实。)


-
(3) The online training procedure of MeLON is described in Algorithm 1. When a recommender is deployed online, the algorithm conducts the three steps for every new incoming mini-batch of user-item interactions: (算法1描述了MeLON的在线训练过程。当在线部署推荐程序时,该算法会对每个新传入的小批量用户项交互执行三个步骤:)
- (1) a preliminary update of the recommender model (Lines 5–6) on the last interactions of the users and items in the current mini-batch, (推荐人模型(第5-6行)的初步更新,关于当前小批量中用户和项目的最后交互,)
- (2) an update of the meta-model on a new mini-batch (Lines 7–8), (在新的迷你批次(第7-8行)上更新元模型,)
- and (3) an update of the recommender model on the new mini-batch (Lines 10–11). We additionally learn a forgetting rate for the current parameter to help quick adaptation by forgetting previous outdated information (Ravi and Larochelle 2017). The above procedure repeats for every incoming mini-batch during online service. (在新的小批量(第10-11行)上更新推荐模型。此外,我们还了解了当前参数的遗忘率,以便通过遗忘以前过时的信息来帮助快速适应(Ravi和Larochelle 2017)。在线服务期间,上述程序对每个进入的小批量重复。)
-
(4)Before a recommender is deployed online, both the recommender and the meta-model are typically pre-trained on the past user-item interactions in an offline manner. Differently from the online training, we first randomly sample a mini-batch B of user-item interactions to derive the interactions Blast. Then, in each iteration, the recommender and the meta-model are updated in the same way as in the online learning. The model is trained for a fixed number of epochs, 100 in our experiments. Once the offline training completes, we can deploy the recommender and the meta-model in the online recommendation environment. (在在线部署推荐程序之前,推荐程序和元模型通常都是以离线方式对过去的用户项交互进行预训练的。与在线培训不同的是,我们首先随机抽取一小批用户项交互,以获得交互效果。然后,在每次迭代中,推荐者和元模型都会以与在线学习相同的方式进行更新。该模型是针对固定数量的epoch进行训练的,在我们的实验中为100个。一旦离线训练完成,我们就可以在在线推荐环境中部署推荐者和元模型。)
B. Details of Experiment Settings (实验设置的详细信息)
Four reproducibility, the source code of MeLON as well as the datasets are provided as the supplementary material. (作为补充材料,提供了四种再现性、MeLON的源代码以及数据集。)
Datasets
-
The explicit user ratings in the Yelp dataset and three Amazon datasets are converted into implicit ones, following the relevant researches (Koren 2008; He et al. 2017); that is, if a user rated an item, then the rating is considered as a positive user-item interaction. For requential evaluation on online recommendation scenarios, we follow a commonly-used approach (He et al. 2016); (根据相关研究,将Yelp数据集和三个亚马逊数据集中的显式用户评分转换为隐式用户评分(Koren 2008;He等人,2017);也就是说,如果用户对某个项目进行了评分,那么该评分将被视为积极的用户项目交互。对于在线推荐场景的频繁评估,我们采用了一种常用的方法(He等人,2016);)
-
we sort the interactions in the dataset in chronological order, and divide them into three parts—offline pre-training data, online validation data, and online test data. (我们按照时间顺序对数据集中的交互进行排序,并将其分为三部分:离线预训练数据、在线验证数据和在线测试数据)
-
Online validation data is exploited to search the hyperparameter setting of the recommenders and update strategies and takes up 10% of test data. Because user-item interactions are very sparse, we preprocess the datasets, following the previous approaches (He et al. 2017; Zhang et al. 2020); for all datasets, users and items involved with less than 20 interactions are filtered out. (利用在线验证数据搜索推荐者的超参数设置和更新策略,占测试数据的10%。由于用户项交互非常稀疏,我们按照之前的方法(He等人2017;Zhang等人2020)对数据集进行预处理;对于所有数据集,涉及少于20次交互的用户和项目都会被过滤掉。)
-
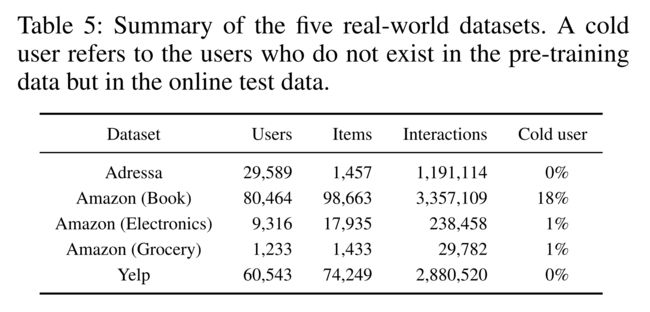
Table 5 summarizes the profiles of the five datasets used in the experiments, where the details are as follows. (表5总结了实验中使用的五个数据集的概况,详情如下。)
-
Adressa news dataset (Gulla et al. 2017) contains user interactions with news articles for one week. We use the first 95% of data as offline pre-training data, the next 0.5% as online validation data, and the last 4.5% as online test data. (新闻数据集(Gulla et al.2017)包含一周内用户与新闻文章的互动。我们使用前95%的数据作为离线预训练数据,接下来的0.5%作为在线验证数据,最后4.5%作为在线测试数据。)
-
Amazon review dataset (Ni, Li, and McAuley 2019) contains user reviews for the products purchased in Amazon. Among various categories, we adopt three frequently-used categories,
- Book(Wang et al. 2019),
- Electronics(Zhou et al. 2018),
- and Grocery and Gourmet F ood(Wang et al. 2020), which vary in the size of interactions and the number of users and items.
- Because there exists almost no overlap among the categories, we perform evaluation on each category and report the average. Due to the difference in size, we apply different data split ratios for each category. (评论数据集(Ni、Li和McAuley 2019)包含在亚马逊购买的产品的用户评论。在各种类别中,我们采用了三种常用类别:书籍(Wang等人2019年)、电子产品(Zhou等人2018年)和食品杂货和美食(Wang等人2020年),它们在互动的规模、用户和物品的数量上各不相同。由于类别之间几乎不存在重叠,我们对每个类别进行评估并报告平均值。由于大小不同,我们对每个类别应用不同的数据分割比率。)
- Book: 95%(pre-training): 0.5%(validation): 4.5%(test)
- Electronics: 90%(pre-training):1%(validation):9%(test)
- Grocery: 80%(pre-training): 2%(validation): 18%(test)
-
Yelp review dataset contains user reviews for venues, such as bars, cafes, and restaurants. We use the first 95% of data as offline pre-training data, the next 0.5% as online validation data, and the last 4.5% as online test data. (review dataset包含对酒吧、咖啡馆和餐厅等场所的用户评论。我们使用前95%的数据作为离线预训练数据,接下来的0.5%作为在线验证数据,最后4.5%作为在线测试数据。)
Recommender Baseline Models
-
For online recommenders, we use two famous personalized recommender algorithms: BPR (Koren, Bell, and V olinsky 2009; Rendle et al. 2009) and NCF (He et al. 2017). (对于在线推荐,我们使用了两种著名的个性化推荐算法:BPR(Koren、Bell和V olinsky,2009;Rendle等人,2009)和NCF(He等人,2017)。)
- BPR: To handle implicit feedback, the Bayesian personalized ranking (BPR) uses the identifiers of a user and an item to estimate the user’s interest on the item by multiplying the user embedding vector e u e_u eu and the item embedding vector e i e_i ei. (为了处理隐式反馈,贝叶斯个性化排名(BPR)使用用户和项目的标识符,通过乘以用户嵌入向量 e u e_u eu和项目嵌入向量 e i e_i ei来估计用户对项目的兴趣。)
- NCF: Neural collaborative filtering(NCF) maintains a generalized BPR and a multi-layer perceptron that have user and item vectors respectively. The results of these two components are later fused by a neural layer to predict a user’s interest on an item. (神经协同过滤(NCF)维护一个广义BPR和一个多层感知器,分别具有用户和项目向量。这两个组件的结果随后被神经层融合,以预测用户对某个项目的兴趣。)
-
To train these recommender algorithms based on implicit feedback data, we employ a ranking loss(Rendle et al. 2009); for a positive item in a user-item interaction, we randomly sample another negative item that the user has not interacted before, and train a recommender algorithm to prioritize the positive item over the negative item. (为了基于隐式反馈数据训练这些推荐算法,我们采用了排名损失(Rendle等人,2009);对于用户项交互中的一个积极项,我们随机抽取另一个用户以前没有交互过的消极项,并训练一个推荐算法,将积极项优先于消极项。)
Configuration
For fair comparison, we follow the optimal hyperparameter settings of the baselines as reported in the original papers, and optimize uncharted ones using HR@5 on validation data. All the experiments are performed with a batch size 256 and trained for 100 epochs. The number of updates on the default update strategy is fixed to be 1 to align with other compared strategies. The experiments are repeated 5
times varying random seeds, and we report the average as well as the standard error. For the graph attention in the first component of MeLON, we randomly sample 10 neighbors per target user or item. Besides, for the MLP which learns the parameter roles, the number of hidden layers (L) is set to be 2. To optimize a recommender under the default and sample reweighting strategies, we use Adam (Kingma and Ba 2015) with a learning rate η = 0.001 and a weight decay 0.001. Note that a recommender trained with the meta-optimization strategies is optimized by a meta-model, while the meta-model is optimized with Adam during the meta-update in Eqs. (14) and (15). Our implementation is written in PyTorch, and the experiments were conducted on Nvidia Titan RTX. (为了公平比较,我们遵循原始论文中报告的基线的最佳超参数设置,并使用HR@5关于验证数据。所有的实验都是以256的批量进行的,并经过100个时代的训练。默认更新策略的更新次数固定为1,以与其他比较策略保持一致。实验重复5次时间变化的随机种子,我们报告平均值和标准误差。对于MeLON第一个成分中的图形注意,我们随机抽取每个目标用户或项目的10个邻居。此外,对于学习参数角色的MLP,隐藏层的数量(L)设置为2。为了在默认和样本重新加权策略下优化推荐,我们使用了学习率η=0.001、权重衰减为0.001的Adam(Kingma和Ba 2015)。请注意,使用元优化策略训练的推荐人通过元模型进行优化,而元模型在Eqs中的元更新期间使用Adam进行优化。(14) 和(15)。我们的实现是用Python编写的,实验是在Nvidia Titan RTX上进行的。)