NoSql 数据库 —— Redis 数据库学习
前言:
实现一个项目,无论项目多复杂,核心的功能就是增删改查。可以使用的到技术,比如 Java 基础语法,jsp,servlet,html,jdbc…………可以实现其基础功能。项目随着需求的变化,而不断升级,此时强调的是可扩展能力,如果使用普通实现功能的技术比较麻烦,那么衍生出的就是 Spring,SpringMVC,MyBatis 等框架技术来解决扩展性问题。当项目功能完成且具备扩展能力,此时就会产生性能问题,随着解决此类问题的技术就是:NoSql、java 线程、Nginx…………
目录:
1、NoSql 使用的两个场景
2、NoSql 数据库概述
3、redis 安装
4、五大数据类型
5、配置文件
6、订阅与发布
7、redis 6 之后的新类型
8、jedis
9、springboot 整合 redis
10、事务和锁机制
11、事务冲突
12、持久化
13、主从复制
14、集群
15、redis 应用问题
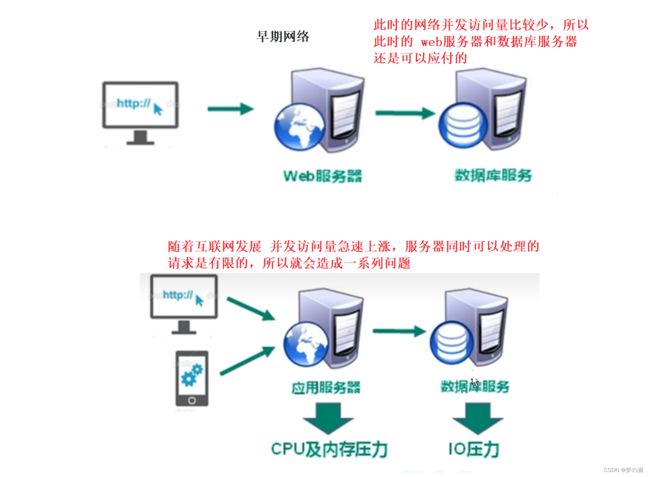
1、NoSql 的两个使用场景
-
情况一、session 复制问题:

-
情况二、高并发量访问数据库
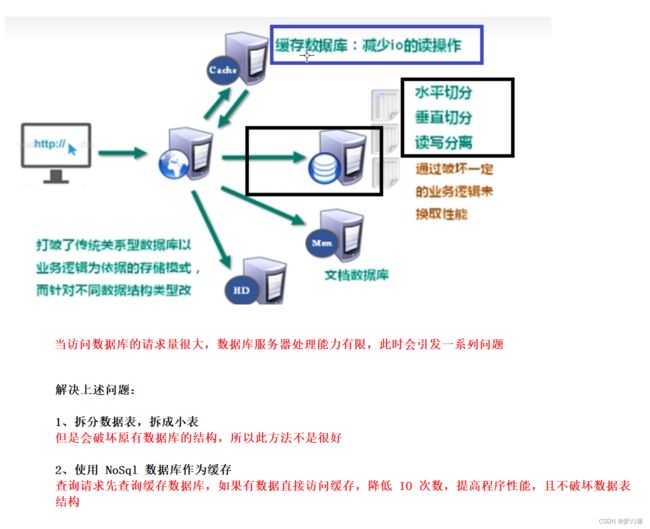
2、Nosql 数据库概述
- NoSql (Not only sql)不仅仅是 sql ,泛指非关系型数据库,Nosql 不依赖业务逻辑,而是以 key -value 键值对的方式进行储存的,因此大大增强了数据库的扩展能力。
- Nosql 的适用场景:高并发对数据的读写,海量数据读写,对数据高可扩展性。但是 Nosql 不支持 ACID(事务的四个特性),不遵循 sql 标准,性能远超过 sql
- Nosql 典型的一个数据库就是 redis 数据库:数据存在内存中,支持持久化(主要用于备份恢复),除了支持简单的 kv 模式,还支持多种数据结构,一般是作为缓存数据库辅助持久化的数据库
3、在 Linux 系统下实现 redis 的安装
-
redis 官方下载安装包 官方链接
- 1、直接把安装包,拖到 Linux 操作系统中,我这边是云服务,拖到 opt 目录下
cd /opt

- 2、安装 gcc
yum install gcc
- 3、回到 opt 目录下,解压刚刚拷贝进来的安装包
tar -zxvf + 安装包的名字
- 4、进入到解压出来的 redis 文件,使用 make 指令进行编译
make
- 5、在后台启动 redis 服务器,参考此博客 后台启动 redis 服务器
- 6、进入 redis 客户端验证服务器是否启动成功
redis-cli
- 7、输入 ping 指令,服务器返回 pong 证明服务器启动成功

- redis 支持多种数据类型,支持持久化,redis 端口号 6379
- 单线程 + 多路 IO 复用(使用单线程的方式实现多线程的效果)
- 图解:单线程 + 多路 IO 复用

4、Redis 中常用的五大数据类型
- 前置知识 Redis 键
- 指令 1 :
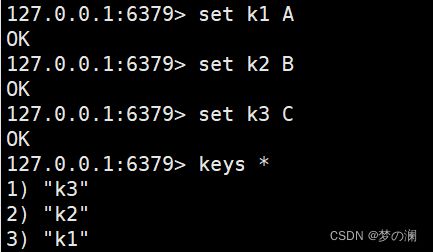
keys *查询当前数据库(Redis 有很多数据库,默认的数据库的其 0 号库)的所有 key 值,未插入数据时为空

- 指令 2 :
set key value设置键值对,向数据库插入数据后,再次使用keys *指令查询数据库中的key值
- 指令 3:
exists + (key名字),查询当前 key 是否在数据库中,返回 1 在,返回 0 不在 - 指令 4:
type + (key名字),查询当前 key 的数据类型,可以看到刚刚定义的 key 是 string 类型

- 指令 5:
del + key 名删除此 key

- 指令 6:
unlink + key名根据 value 选择非阻塞删除,使用此指令不是真正的删除此 key ,真正删除操作需要在后续的异步操作

- 指令 7:
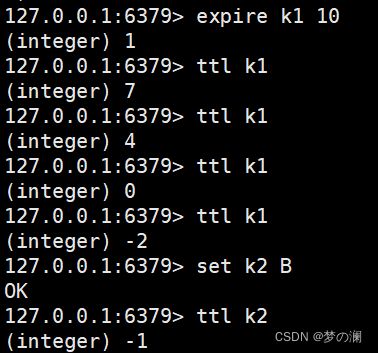
expire + key名设置 key 值的过期时间,通过 ttl + key 名检测当前 key 值多少秒过期,-1 表示永不过期,-2 表示已过期
- 指令 8:
select + 数据库号表示切换数据库,下面就是切换数据库为 1 号数据库

- 指令 9:
dbsize查询当前数据库的 key 的数量

- 指令 10:flushdb 清空当前库 + flushall 通杀全部库
- 指令 1 :
- 类型 1 :String,这里类型指的是 value,key 固定为 string 类型
Redis 字符串(String)是 Redis 中基本数据类型,一个 key 对应一个 value,String 类型是
二进制安全的。意味 redis 的 string 可以包含任意数据,比如 jpg 图片或者序列化的对象。一个 Redis 中字符串 value 最多512 M
-
String 类型中的基本指令:
- ①、set 和 get,设置 key / 获取 key 对应的 value
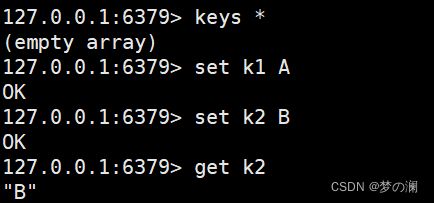
- ②、append 字符串追加

- ③、strlen 获取 value 值的长度

- ④、setnx 只有在 key 不存在设置 key 的值,一般的 set 指令会覆盖原有的 value 值

- ⑤、incr + key 名 / decr + key 名 自增 or 自减,自增 or 自减操作都是原子的,多个线程的自增 or 自减不会对数据最后的结果产生影响
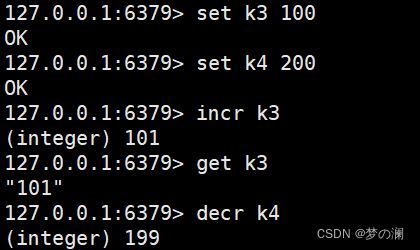
- ⑥、incrby / decrby + key + 指定步长 增加 or 减少

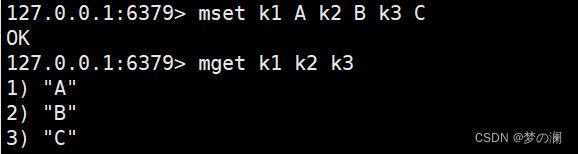
- ⑦、多个 key value 的存储与获取 mset mget
- ⑧、设置起始位置的复写该位置的字符串,获取指定起始位置的字符串 getrange setrange

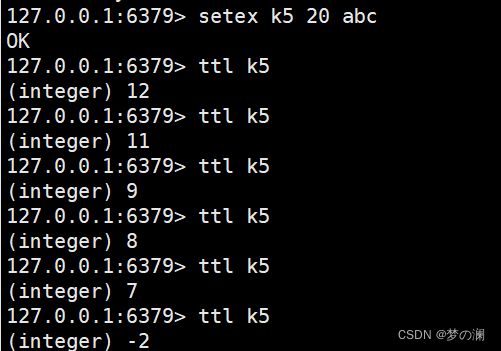
- ⑨、设置键值并设置键值的过期时间 setex + key + 秒数 + value
- ⑩、getset 将对应 k 值设置为新值,并返回旧值

- ①、set 和 get,设置 key / 获取 key 对应的 value
- String 类型的数据结构:String 的数据结构为简单动态字符串。是可以修改的字符串,类似于 java 中的 ArrayList,采取预分配冗余空间的方式来减少内存的频繁分配。如下图,内部的 capacity 一般要高于字符串的长度,当字符串的长度小于 1M,扩容都是以现有的大小进行 2 倍扩容的,当字符串的长度超过 1M 时,扩容每次只会扩容 1M,字符串的最大长度为 512M

-
List 列表
- 前置知识:List 采取的是一个键多个值的方式进行存储的,也就是一个 key 对应多个 value,并且列表可以按照插入顺序排序,可以在列表头部或者尾部插入数据。其底层其实是一个双向链表,对两端的操作性能很高,通过索引下标的操作中间的结点性能较差

- 常用命令:
- ①、lpush / rpush 从左 / 右端插入,类似于链表的头插和尾插,lrang + start + end 从左边开始读

- ②、lpop 、 rpop 从左边或者右边取出一个值,值在键在,值没有了键也随之销毁

- ③、lindex 通过索引下标找到数据,类似于 Java 中数组通过下标找到元素

- ④、linsert + key + after / before + 原值 + 新值 在原值的前面或者后面插入数据

- ⑤、Irem + key + n + value 从左边删除第 n 个数值

- ⑥、lset + key + index + value 将 index 位置的数值改变为 value

- ①、lpush / rpush 从左 / 右端插入,类似于链表的头插和尾插,lrang + start + end 从左边开始读
- 列表的数据结构:
Redis 中的 List 采用的是 quickList (快速链表),一开始在列表中的数据比较少的时候,会使用一块连续的内存空间,这个结构是 zipList(压缩链表),它将所有的元素紧挨在一起进行放置,分配的是一块连续的空间,当数据量较多的时候才会改成 quickList 因为普通的链表需要附加的指针空间太大,会比较浪费空间。Redis 将链表和 zipList 结合起来组成了 quickList 也就是多个 zipList 使用双指针串联起来,既满足了插入删除的高效,也节省了空间
-
Set 类型
- 前置知识:
Set 中提供了可以判断值是否在 set 中的接口,这是 List 中没有的,Set 是一个无序不重复集合,其底层是一个 value 为 null 的 hash 表,所以添加删除查找的时间复杂度都是 O(1)
- 基本指令:
- sadd + key + value + value +…… / smembers + key 存储键值对 / 查看对应 key 的 value 值

顺便通过此指令检测 set 的不重复的特性:

- ②、sismember + key + value 判断此 value 是否在当前 key 中,0 不在,1在
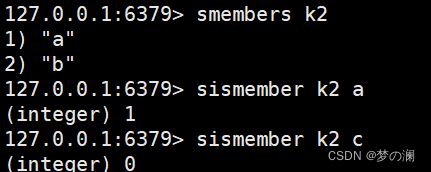
- ③、scard + key 返回该集合的元素个数

- ④、srem + key + member 删除 key 中值为 member 的值

- ⑤、spop + key 随机吐出一个值
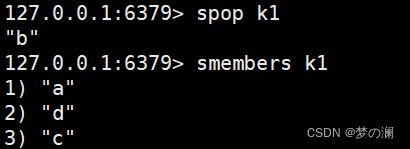
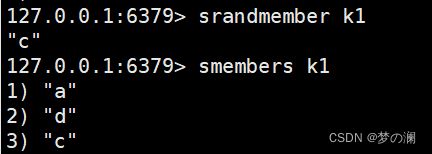
- ⑥、srandmember + key 随机取出一个值,不是吐出,该值还是在 key 中
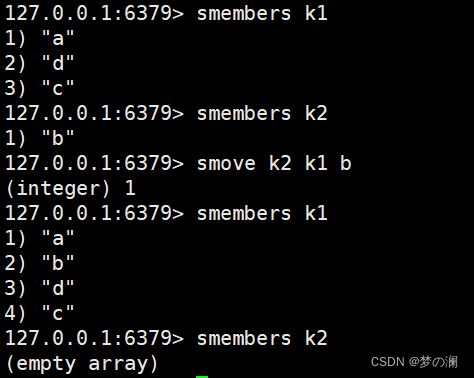
- ⑦、smove + k1 + k2 + 移动的数值(k1 向 k2 移动)
- ⑧、sinter(两个 set 的交集)、sunion(两个 set 的并集)、sdiff(两个 set 的差集,差集只有对应长度的差集,超过某一个 set 的长度的值不算)

- sadd + key + value + value +…… / smembers + key 存储键值对 / 查看对应 key 的 value 值
- 底层数据结构:
Redis 的 set 机构和 Java 的 set 结构类似,内部使用的也是 hash 结构,所有的 value 值都是指向同一个内部值
-
Hash 类型:
- 前置知识:
Hash 是一个键值对集合,Redis 的 Hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合存储对象,就像 Java 的 map 一样

-
基本指令:
- ①、hset / hget 存储键值对 / 取键值对

- ②、一次设置多个 field 和 value 的映射

- ③、hexists + key + field 判断当前 field 是否在 key 中 0 不在 1 在

- ④、hkeys 列出 hash 集合中的所有 field / hvals 列出 hash 集合中所有的 value

- ④、hincrby + key + field + 增加的步长:为指定的 key 对应 field 映射的 value 值加上步长

- ⑤、hsetnx + key + field + value 设置 key 中 field 映射 value 值为 value,此 field 先前一定不存在
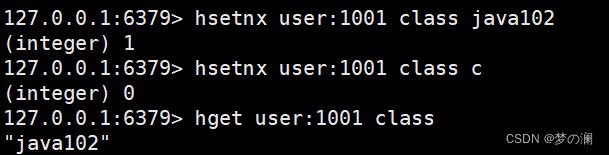
- ①、hset / hget 存储键值对 / 取键值对
-
Hash 的数据结构:
有两种,zipList,hashtable,当 field - value 长度比较短个数较少时,使用 zipList,否则使用 hashtable
-
Zset 有序 set 集合
- 前置知识:
Zset 和 set 的区别不大,也是一个包含不重复元素的集合,不同之处就是每个成员添加了一个 score 属性,这个评分被用来按从最高或者最低进行排序,集合的成员是唯一的,评分不是唯一的
- 基本指令:
- ①、zadd + key + score + value / zrange + key(withscores 带分数) 添加 / 取出元素
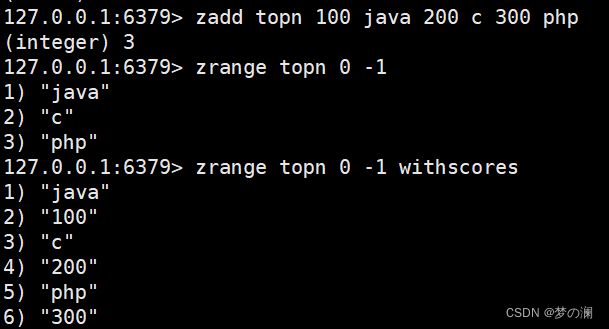
- ②、zrangebyscore + key + min + max 返回 min到 max区间的 score 对应所有 value

- ③、zrevrangebyscore + key + max+ min 返回 max 到 min 区间的 score 对应所有 value

- ④、zincrby + key + increment + member 为当前 key 的 score + 上 increment

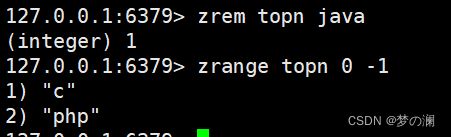
- ⑤、zrem + key + value 删除指定 value
- ⑥、zcount + key + 范围 统计集合范围中的 元素 个数

- ⑦、zrank + key + value 返回在集合中所在位置

- ①、zadd + key + score + value / zrange + key(withscores 带分数) 添加 / 取出元素
- Zset 的底层数据结构:
- Zset 一方面等价与 Java 中的 HashMap 可以给每个元素赋予一个权重,另一方面又类似于 TreeSet 内部按照 score 进行排序,又可以通过 score 的范围获取元素的列表
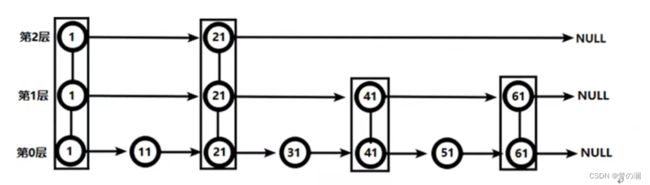
- Zset 底层使用两个数据结构:hash 保证每个 value 和 score 进行映射,跳跃表,跳跃表目的在于给元素 value 排序,根据 score 的范围来获取元素列表(类似于一颗搜索树,可以根据数据范围快速定位一个数据元素)
5、Redis 的配置文件
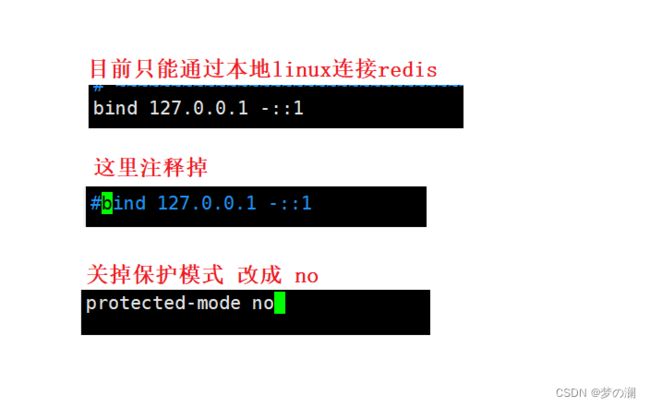
- 一定要配置密码,请参考 redis 设置密码
6、Redis 的发布和订阅
- Redis 发布订阅是一种消息通信模式,发送者发送消息,订阅者接收消息,Redis 客户端可以接收订阅任意数量的频道
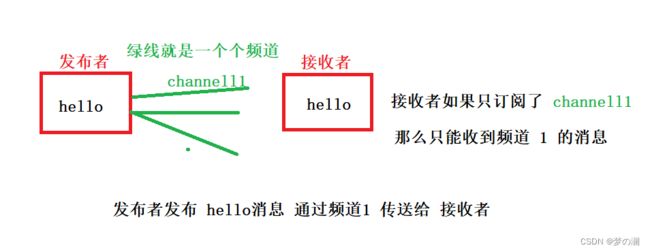
- 代码演示:

7、Redis 6 之后的新类型
-
①、bitemap:
- 不是一个真的数据类型而是一个站在 String 类型上面向比特位操作的集合,其可以对字符串的位进行操作。bitemap 的使用和字符串类型不同,可以把 bitemap 想象成一个以位为单位的数组,数组每个单元存储 0 或 1 数组下标加偏移量

bitemap 和 set 集合比较:
- 假设网站有 1 亿用户,每天独立访问的用户用 5千万

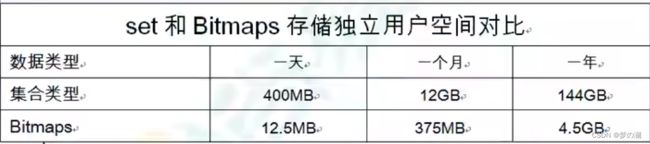
- 可以看出当用户量比较大时,bitemap 对于空间的消耗较 set 来说要小很多
- 当然,当用户量比较少的时候,bitemap 也是会占用空间,比如活跃的用户量只有 10 万,此时 bitmap 就不合适,因为大部分位置是 0,反而比 set 只存储活跃用户量占用空间
-
bitemap 的基本指令:
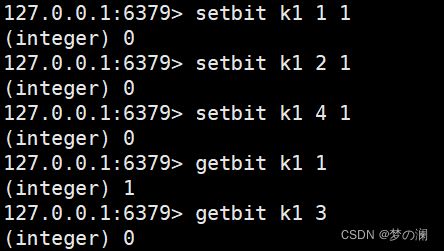
- ①、setbit + key + offerset + value / getbit + key + offerset 设置当前 key 偏移量为 offerset 的二进制位为 1 / 获取当前 key 偏移量为 offerset 的位置的二进制位情况(是 0 还是 1)
- ②、bitcount + key 返回当前 key 对应的 bitmap 数组中有多少个 1

- ③、bitop and(or / not / xor)使多个 Bitemap 进行与或非异或的操作

- ①、setbit + key + offerset + value / getbit + key + offerset 设置当前 key 偏移量为 offerset 的二进制位为 1 / 获取当前 key 偏移量为 offerset 的位置的二进制位情况(是 0 还是 1)
- HyperLogLog 类型:
- 在实际业务中常用统计方面的需求,并且有时还需要统计不重复元素的个数(基数问题),在 MySQL 表中,使用 distinct count 计算不重复个数
- 在 Redis 中可以使用 hash set bitmap 来进行统计,但是随着数据量增加,这三种方式占用空间会越来越大,对于非常大的数据集是不可行的。所以考虑降低一定的精度来进行存储,Redis 退出 HyperLogLog。
- HyperLogLog 只需要花费 12 kb 的大小就能存储 2 ^ 64 个不同的基数(不重复的数),相对节省了很大的空间
- 常见指令:
- pfadd + key + ele 值(可以有多个)—— 存储 key 和 多个 value 值(自动去重) / 计算出 key 中的数据个数

- pfmerge + 目标 key + 源 key 将源 key 拷贝到目标 key 中

- pfadd + key + ele 值(可以有多个)—— 存储 key 和 多个 value 值(自动去重) / 计算出 key 中的数据个数
- Geospatial 类型
提供经纬设置,查询,范围查询,距离查询,经纬度 Hash 等常见操作
- 常见指令:
-
①、geoadd + key + 经 + 纬 + 名字 / geopos + key + 名字 添加元素 / 获取对应位置的经纬度


-
②、geodist + key + 两个名字 + 单位 两个地址计算出两个地址之间的距离

-
8、Jedis 通过 java 去操作 Redis
- 通过 Jedis 来操作虚拟机中的 Redis,类似于 java 中通过 JDBC 来操作 Mysql 一样
- 首先创建 Maven 工程:
- 然后在 xml 文件中引入 jedis 的依赖
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
</dependencies>
- 创建 jedis 类,绑定虚拟机的 ip 地址和 Redis 的端口号,并进行测试(注意这里一定要按照上面的方式修改 redis 的配置文件,并且在云服务上放行 6379 端口,注意你的 redis 一定要设置密码)
public static void main(String[] args) {
JedisShardInfo shardInfo = new JedisShardInfo("redis:///*使用你云服务器的 ip 地址*/:6379");
shardInfo.setPassword("/*使用你redis的的密码*/");
//创建 jedis 类
Jedis jedis = new Jedis(shardInfo);
//测试
String value = jedis.ping();
System.out.println(value);
}
- 测试成功,返回 pong

- 之后就可以通过 jedis 来实现对 redis 的操作
9、SpringBoot 整合 redis
- 1、引入依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
- 2、引入配置
#Redis本地服务器地址,注意要开启redis服务,即那个redis-server.exe
spring.redis.host=你redis的地址 我的是云服务器的地址
#Redis服务器端口,默认为6379.若有改动按改动后的来
spring.redis.port=6379
#Redis服务器连接密码,默认为空,若有设置按设置的来
spring.redis.password=
#连接池最大连接数,若为负责则表示没有任何限制
spring.redis.jedis.pool.max-active=20
#连接池最大阻塞等待时间,若为负责则表示没有任何限制
spring.redis.jedis.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=0
- 3、在 config 类中引入对 redis 的配置,固定写法直接复制
package com.example.demo.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
/**
* Created with IntelliJ IDEA.
* Description:
* User: Lenovo
* Date: 2022-10-12
* Time: 9:43
*/
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
- 4、使用 controller 类进行测试,输入二级地址后就可以查看到结果
package com.example.demo.controller;
import com.example.demo.config.RedisConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* Created with IntelliJ IDEA.
* Description:
* User: Lenovo
* Date: 2022-10-12
* Time: 9:50
*/
@RestController
@RequestMapping("/testRedis")
public class RedisController {
@Autowired
private RedisTemplate redisTemplate;
@RequestMapping("/redis")
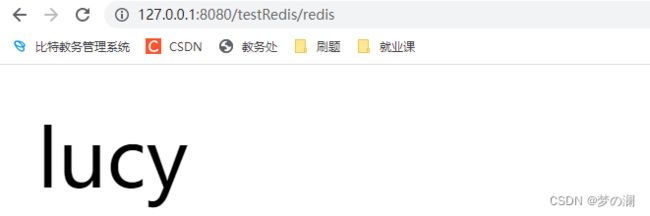
public String testRedis(){
redisTemplate.opsForValue().set("name","lucy");
String name = (String)redisTemplate.opsForValue().get("name");
return name;
}
}
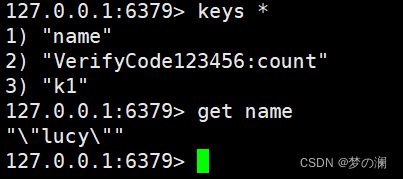
redis 中也有这个 key
10、Redis 的事务和锁机制
-
Redis 的事务和 MySql 的完全不一样
-
Redis 中的事务:是一个单独的隔离操作,事务中所有的指令都会序列化,按顺序执行,在事务执行过程中,其他客户端的指令不会打断指令。
-
Redis 事务的主要作用就是为了串联多个命令,防止其他命令插队
-
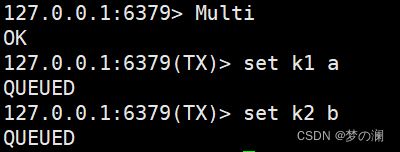
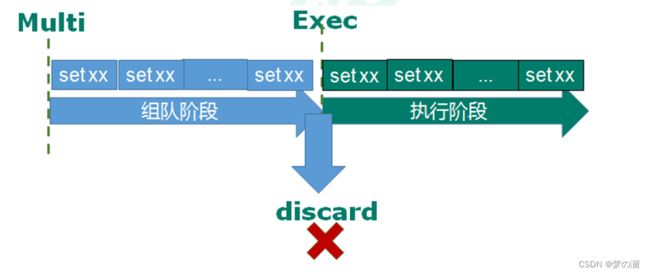
三个指令:Multi、Exec、Discard
- ①、Multi:开启事物,开启事物后,之后的命令返回的都是 queue 代表命令正在排队,并没有执行
- ②、Exce:执行命令

- ①、Multi:开启事物,开启事物后,之后的命令返回的都是 queue 代表命令正在排队,并没有执行
-
③、Discard:中断事物

-
事物的错误处理:
- ①、当排队阶段发生错误,整个事物都会被打断,都不会执行

- ②、当执行过程中出现错误,哪个有错误哪个不执行,其他的正常

- ①、当排队阶段发生错误,整个事物都会被打断,都不会执行
11 、事物的冲突问题
-
事物冲突:三个人同时操作一个账户的金额,同时查询都是有 10 ¥,用户 1 取 8 ¥,用户 2 取 4 ¥,用户 3 去 2 ¥,按说每个用户看到都是 10 ¥ 如果取钱操作应该成功,但是这样就会使账户成负数了,这显然是不合理的,随着用户取走钱,对应其他用户所取钱的范围就应该减少
-
解决方法:
- 1、悲观锁:直接是传统的上锁,用户 1 操作金额加锁,其他用户需要等到锁释放才可以操作账户。这样就保证了账户金额的正常取出
- 2、乐观锁:不加锁,而是采取版本号机制,最初数据库中的账户金额设置一个初始版本号,每个用户都可以读到金额和初始版本号,如果哪个用户对金额进行了修改,对应的数据库中的版本号就会进行 + 1,其他用户再进行操作的时候,就会比对这个版本号,如果和之前拿到的版本号一致,就证明没有其他用户修改金额,当前用户可以进行金额修改,否则当前事务终止,然后需要从数据库中重新读金额和版本号再进行后续的操作。乐观锁没有采用锁的方式来保证事务的冲突,所以效率相对更高
-
watch 监视当前 key 是否被其他命令修改过,如果修改过,当前事务中断
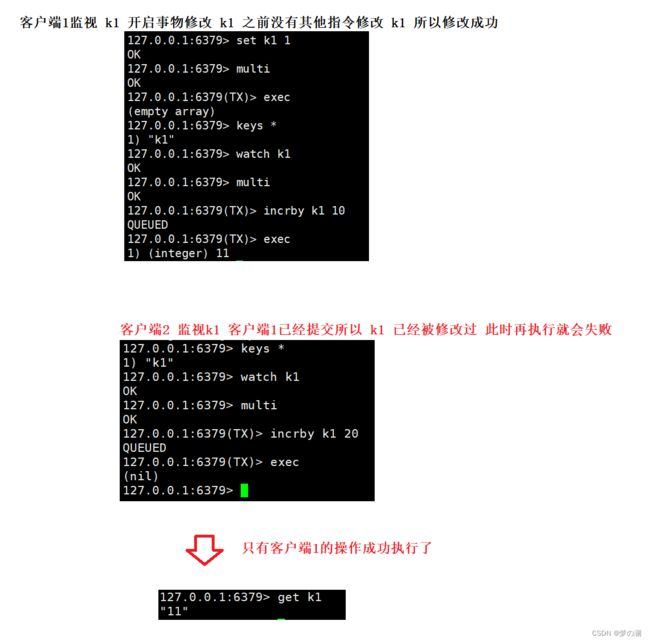
-
unwatch 指令清除对 key 的监视
-
Redis 事务的三个特性
- ①、单独的隔离性:事务中的所有命令都会被序列化,按顺序执行,事务执行过程中,不会被其他的客户端的指令打断
- ②、不具备隔离性:事务在排队中没有真正的执行,所以不存在像是 Mysql 那样的脏读脏写的问题
- ③、不保证原子性:事务在排队过程中如果有操作失败,整体事务失败,但是在事务执行的过程中如果有操作失败,只是失败的操作会不执行,其他正常执行,不会进行整体的回滚
12、Redis 中的持久化操作
- 之前说过,Redis 是基于内存的数据库,但是统一 redis 也可以把数据写到内存中去
- Redis 提供的两种不同的持久化方式:
- ①、RDB:在指定时间间隔内将内存中的数据集快照写入磁盘。持久化过程:先创建一个子进程(fork),先创建一个临时文件,子进程先将数据持久化到临时文件中,最后再将临时文件中复制到磁盘中 dump.rdb。
- 这样的目的:子进程将数据先备份到临时文件的目的是为了防止后期 redis 数据库挂掉,导致前面的数据没有持久化成功,通过子进程将数据备份到临时表中,即是 redis 服务器挂掉,也可以实现前面数据的持久化,保证数据的完整性和安全性

- RDB 的优势:
- ①、适合大规模的数据恢复
- ②、对数据完整性要求不高
- ③、节省磁盘空间
- ④、恢复速度快
- RDB 的劣势:
- ①、子进程 fork 内存中的被复制了一份到临时文件中,需要考虑 2 倍膨胀性
- ②、RDB 采用写时复制技术,数据庞大时还是比较消耗性能的
- ③、在备份周期一定时间间隔内做一次备份,如果 redis 服务器意外 down 掉,就会丢失最后一次快照后的所有修改
- 这样的目的:子进程将数据先备份到临时文件的目的是为了防止后期 redis 数据库挂掉,导致前面的数据没有持久化成功,通过子进程将数据备份到临时表中,即是 redis 服务器挂掉,也可以实现前面数据的持久化,保证数据的完整性和安全性
- ②、AOF(默认不开启)
- AOF 以日志的方式来记录每个写操作,不记录读操作,记录的是每个写操作的指令和数据,只许追加文件不可以修改文件,redis 启动初期就会读取该文件重新构建数据
- AOF 和 RDB 同时开启,系统会默认去取 AOF 的数据,启动方式:appendonly no 修改 no 为 yes
- AOF 文件如果损坏,可以通过指令 redis-check-aof–fix appendonly.aof 恢复
- AOF 两个参数:
- ①、AOF 同频设置:appendfsync always 每次 Redis 的写入操作都会被记录到日志文件中,数据完整性好但是性能差。appendfsync everysec 每秒进行一次数据的写入,如果服务器宕机,本秒的数据可能会丢失。appendfsync no redis 不主动写入文件,把同步时机交给操作系统
- ②、Rewrite压缩:当 AOF 文件大小 > 64 M,就会把多条指令压缩成一条指令来节省空间。比如:

- AOF 持久化流程:客户端的写操作会被追加到 AOF 缓冲区中。AOF 缓冲区根据 AOF 的持久化策略,将操作同步到 AOF 中,AOF 文件的大小超过重写策略或者手动重写时,会对 AOF 文件进行 rewrite 操作。redis 重启时,会重新 load 加载 AOF 文件中写操作到达数据恢复的目的
- AOF 的优势:
- ①、备份机制稳健,丢失数据的概率低
- ②、支持修复 AOF 文件,防止误操作
- 劣势:
- ①、比 RDB 更占用空间,AOF 中记录数据和写操作指令
- ②、恢复速度更慢
- ③、每次都写都同步的话,有一定的性能压力
- ④、存在个别 BUG ,造成不能恢复
- ①、RDB:在指定时间间隔内将内存中的数据集快照写入磁盘。持久化过程:先创建一个子进程(fork),先创建一个临时文件,子进程先将数据持久化到临时文件中,最后再将临时文件中复制到磁盘中 dump.rdb。
- AOF 和 RBD 使用:
- ①、官方建议两个都使用
- ②、当对数据不敏感,采用 RDB
- ③、不建议单独使用 AOF,会出现 BUG
- ④、单单做内存缓存,可以都不使用
13、主从复制
- 主从复制是什么:主机更新数据后根据配置和策略,自动同步到备机的 master / slave 机制,Master 以写为主,Slave 以读为主
- 能干什么:一台主机多台从机。读写分离,性能扩展(分担主机的压力),容灾快速恢复(从机挂了,可以快速切换到其他从机进行其对应的操作)
- 通过指令:slaveof < ip >< port > 绑定主机,从机重启后变成主机,原有数据不会消失,但是主机重启后还是主机,并且隶属于此主机的从机也不会消失
- 主从复制原理:
- 当从服务器连上主服务器后,会向主服务器发送一个进行数据同步的消息(告诉主服务要进行数据同步)。主服务器接受到同步消息之后,会把主服务器的数据进行持久化,rdb 文件,然后主服务器将 rdb 文件发送给从机,从机从 rdb 文件中读取数据。后面每次主服务器进行写操作都会主动和从机进行同步
- 主从复制的三种方式:
- ①、一主二仆:就是上面基本的主从复制方式
- ②、薪火相传:上一个 slave 可以是下一个 slave 的主机,减少 master 的写压力
- ③、反客为主:当一个 master 宕机后,后面的 slave 可以立刻升级为主机,其后面的 salve 不用做任何修改
- 哨兵模式:
- 反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从机变长主机。从机根据 slave-priority 优先级设置哪个从机为主机。原主机重启后变成从机
- 故障恢复过程:

14、Redis 集群
- Redis 集群是将多个服务器组建成一个无中心集群,每个服务器都可以是集群的入口。服务器之间请求是可以相互进行转发的,通过这样的模式来解决(容量不足,redis扩容问题以及并发写操作,redis如何分摊)。通过集群实现水平扩容,多个 redis 分摊数据量,假设公有 N 个数据量,每个 redis 只需要存储 1 / N 的数据量即可
- 这三组六个机器怎样进行分配:尽量保证每个主数据库运行在不同的 ip 地址,每个从库和主库不在一个 ip 地址上
- Redis 集群共有 16384 个插槽,如果此时一个命令 set k1 a 就会先计算 k1 的插槽位置后再将 k1 插入到服务器中,哪个服务器作为入口都可以,计算插槽位置后切换对应插槽范围的服务器。如果通过 mset 加入多个值,需要定义一个组名(确保唯一)就会根据此组名来进行插槽位置的寻找

- 如果集群中一个主机宕机了,从机可以升级为主机继续进行服务,不会影响到整个集群。如果主机和从机都挂掉了,那么需要依据配置文件中的 cluster-require-full-coverage 看其是否为 yes 如果是 yes 那么整个集群就会挂掉,如果是 no 那么该插槽内的数据全都不能使用,也无法存储
- 集群的好处:实现扩容、分摊压力、无中心配置相对简单
- 集群的不足:redis 集群方法出现的较晚,很多公司采取了其他的集群方案,迁移的复杂度比较高
15、Redis 应用问题
-
缓存穿透
- 应用服务器压力变大了,大量请求从客户端发来,正常情况下先去查询缓存,如果没有数据再去数据库中查找,而缓存穿透,就是大部分数据在缓存中不存在,都去查数据库造成数据库压力急剧增大,redis 内部正常运行,没有起到缓存的作用,这就是缓存穿透的现象
- 出现的原因:redis 查询不到数据、出现很多非正常的 url 访问(网址不正确)
- 解决方法:对空值缓存进行缓存(如果一个查询返回是空,将这个空结果进行缓存,设置空结果的过期时间很短) 、设置白名单(使用 bitmap 设置可以访问的 id)、采取布隆过滤器、进行事实监控(如果一个客户端频繁发来无用数据,将这个客户端拉黑,让其无法访问)
-
缓存击穿
- 现象:数据库的访问压力瞬时增大,redis 里面没有出现大量的 key 过期,redis 正常运行,数据库崩溃
- 出现原因:redis 某个 key 过期了,大量访问使用这个 key
- 解决方法:预先设置一些热门数据(加长其过期时间),实时监控 redis 中的数据(监控哪个数据频繁访问到,修改其过期时间),使用锁(效率低)
-
缓存雪崩:
- 原因:在极少时间段,查询大量 key 的集中过期情况
- 解决:采取多级缓存架构(redis + nginx + 其他缓存)、使用锁或者队列、设置过期标志更新缓存(记录缓存数据是否过期,如果过期会触发其他线程来更新 key 的缓存)、将缓存失效时间分散开(减少同一时间失效 key 的数量)
-
分布式锁
- 由于分布式系统多线程、多进程并且分布在不同机器上,原有的单机并发锁策略失效,而是需要对整个分布式集群加锁,就需要使用到分布式锁
- 使用 setnx 可以加锁,使用 del 释放锁。如果锁一直没有释放,设置 key 的过期时间,自动释放。如果上锁之后出现异常,就无法设置过期时间,采用一般上锁一遍设置过期时间即可(set k1 value nx ex + 过期时间)