制作自己的COCO格式数据集,附代码!
最近做了一个细胞检测的练习项目。之前的思路是参考其他大神的代码,后来发现其他人的代码有很多自定义的内容,包括读取的数据格式等等,小白表示看不懂![]() 所以改变思路,用最简单的方法——选择mmdetection2.0中自带的Faster RNN网络进行训练。但是网络对数据格式有要求,有VOC、COCO等几种格式,我选择了COCO格式。
所以改变思路,用最简单的方法——选择mmdetection2.0中自带的Faster RNN网络进行训练。但是网络对数据格式有要求,有VOC、COCO等几种格式,我选择了COCO格式。
一、COCO2017数据集格式
COCO_ROOT #根目录
├── annotations # 存放json格式的标注
│ ├── instances_train2017.json
│ └── instances_val2017.json
└── train2017 # 存放图片文件
│ ├── 000000000001.jpg
│ ├── 000000000002.jpg
│ └── 000000000003.jpg
└── val2017
├── 000000000004.jpg
└── 000000000005.jpgCOCO所有目标框标注都放在json文件中,json文件解析出来是一个字典,格式如下:
{
"info": info,
"images": [image],
"annotations": [annotation],
"categories": [categories],
"licenses": [license],
} 制作自己的数据集的时候info和licenses是不需要的。只需要images,annotations和categories三个字段即可。
其中images是一个字典的列表,储存图像的文件名,高宽和id,id是图象的编号,在annotations中也用到,是唯一的。有多少张图片,该列表就有多少个字典。
# json['images'][0]
{
'file_name': '000000397133.jpg',
'height': 427,
'width': 640,
'id': 397133
} categories表示所有的类别,有多少类就定义多少,类别的id从1开始,0为背景。格式如下:
[
{'supercategory': 'person', 'id': 1, 'name': 'person'},
{'supercategory': 'vehicle', 'id': 2, 'name': 'bicycle'},
{'supercategory': 'vehicle', 'id': 3, 'name': 'car'},
{'supercategory': 'vehicle', 'id': 4, 'name': 'motorcycle'},
{'supercategory': 'vehicle', 'id': 5, 'name': 'airplane'},
{'supercategory': 'vehicle', 'id': 6, 'name': 'bus'},
{'supercategory': 'vehicle', 'id': 7, 'name': 'train'},
{'supercategory': 'vehicle', 'id': 8, 'name': 'truck'},
{'supercategory': 'vehicle', 'id': 9, 'name': 'boat'}
# ....
] annotations是检测框的标注,一个bounding box的格式如下:
{'segmentation': [[]],
'area': 240.000,
'iscrowd': 0,
'image_id': 289343,
'bbox': [0., 0., 60., 40.],
'category_id': 1,
'id': 1768} 其中segmentation是分割的多边形,我对这个键的含义不是很懂,而且我用到的标注只有bbox,所知直接设置成了[[]],注意一定是两个列表嵌套,area是分割的面积,bbox是检测框的[x, y, w, h]坐标,category_id是类别id,与categories中对应,image_id图像的id,id是bbox的id,每个检测框是唯一的,有几个bbox,annotations里就有几个字典。
二、现有标注格式
使用的数据来自阿里天池宫颈癌风险检测竞赛的数据集,经过预处理后获得图像及其对应的json文件标注信息,如下所示:
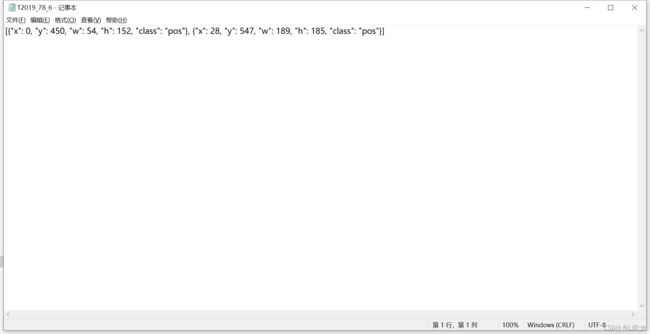
三、格式转换
1.建立目录
按照COCO数据集格式建立目录,这一步很简单,没啥可说的。
2.生成train和val图片名文本文件
from glob import glob
import random
# 该目录存储图片数据
patch_fn_list = glob('D:/data/TianChi/Train/roi_train_total/*.jpg')
# 返回存储图片名的列表,不包含图片的后缀
patch_fn_list = [fn.split('\\')[-1][:-4] for fn in patch_fn_list]
# 将图片打乱顺序
random.shuffle(patch_fn_list)
# 按照7:3比例划分train和val
train_num = int(0.7 * len(patch_fn_list))
train_patch_list = patch_fn_list[:train_num]
valid_patch_list = patch_fn_list[train_num:]
# produce train/valid/trainval txt file
split = ['train_total', 'val_total', 'trainval_total']
for s in split:
# 存储文本文件的地址
save_path = 'D:/data/TianChi/Train/' + s + '.txt'
if s == 'train':
with open(save_path, 'w') as f:
for fn in train_patch_list:
# 将训练图像的地址写入train.txt文件
f.write('%s\n' % fn)
elif s == 'val':
with open(save_path, 'w') as f:
for fn in valid_patch_list:
# 将验证图像的地址写入val.txt文件
f.write('%s\n' % fn)
elif s == 'trainval':
with open(save_path, 'w') as f:
for fn in patch_fn_list:
# 将所有图像名的编号写入trainval.txt文件
f.write('%s\n' % fn)
print('Finish Producing %s txt file to %s' % (s, save_path))3.将图片移动至对应目录下
import shutil
def my_move(datadir, trainlistdir,vallistdir,traindir,valdir):
# 打开train.txt文件
fopen = open(trainlistdir, 'r')
# 读取图片名称
file_names = fopen.readlines()
for file_name in file_names:
file_name=file_name.strip('\n')
# 图片的路径
traindata = datadir + file_name+'.jpg'
# 把图片移动至traindir路径下
# 若想复制可将move改为copy
shutil.move(traindata, traindir)
# 同上
fopen = open(vallistdir, 'r')
file_names = fopen.readlines()
for file_name in file_names:
file_name=file_name.strip('\n')
valdata = datadir + file_name+'.jpg'
shutil.move(valdata, valdir)
# 图片存储地址
datadir=r'D:\data\TianChi\Train\roi_uniform_hue\\'
# 存储训练图片名的txt文件地址
trainlistdir=r'D:\data\TianChi\Train\ImageSets\Main\train.txt'
# 存储验证图片名的txt文件地址
vallistdir=r'D:\data\TianChi\Train\ImageSets\Main\val.txt'
# coco格式数据集的train2017目录
traindir=r'D:\data\TianChi\Train\COCO_ROOT\train2017'
# coco格式数据集的val2017目录
valdir=r'D:\data\TianChi\Train\COCO_ROOT\val2017'
my_move(datadir, trainlistdir,vallistdir,traindir,valdir)4.生成json文件
import json
import glob
import cv2 as cv
import os
class tococo(object):
def __init__(self, jpg_paths, label_path, save_path):
self.images = []
self.categories = []
self.annotations = []
# 返回每张图片的地址
self.jpgpaths = jpg_paths
self.save_path = save_path
self.label_path = label_path
# 可根据情况设置类别,这里只设置了一类
self.class_ids = {'pos': 1}
self.class_id = 1
self.coco = {}
def npz_to_coco(self):
annid = 0
for num, jpg_path in enumerate(self.jpgpaths):
imgname = jpg_path.split('\\')[-1].split('.')[0]
img = cv.imread(jpg_path)
jsonf = open(self.label_path + imgname + '.json').read() # 读取json
labels = json.loads(jsonf)
h, w = img.shape[:-1]
self.images.append(self.get_images(imgname, h, w, num))
for label in labels:
# self.categories.append(self.get_categories(label['class'], self.class_id))
px,py,pw,ph=label['x'],label['y'],label['w'],label['h']
box=[px,py,pw,ph]
print(box)
self.annotations.append(self.get_annotations(box, num, annid, label['class']))
annid = annid + 1
self.coco["images"] = self.images
self.categories.append(self.get_categories(label['class'], self.class_id))
self.coco["categories"] = self.categories
self.coco["annotations"] = self.annotations
# print(self.coco)
def get_images(self, filename, height, width, image_id):
image = {}
image["height"] = height
image['width'] = width
image["id"] = image_id
# 文件名加后缀
image["file_name"] = filename+'.jpg'
# print(image)
return image
def get_categories(self, name, class_id):
category = {}
category["supercategory"] = "Positive Cell"
# id=0
category['id'] = class_id
# name=1
category['name'] = name
# print(category)
return category
def get_annotations(self, box, image_id, ann_id, calss_name):
annotation = {}
w, h = box[2], box[3]
area = w * h
annotation['segmentation'] = [[]]
annotation['iscrowd'] = 0
# 第几张图像,从0开始
annotation['image_id'] = image_id
annotation['bbox'] = box
annotation['area'] = float(area)
# category_id=0
annotation['category_id'] = self.class_ids[calss_name]
# 第几个标注,从0开始
annotation['id'] = ann_id
# print(annotation)
return annotation
def save_json(self):
self.npz_to_coco()
label_dic = self.coco
# print(label_dic)
instances_train2017 = json.dumps(label_dic)
# 可改为instances_train2017.json
f = open(os.path.join(save_path+'\instances_val2017.json'), 'w')
f.write(instances_train2017)
f.close()
# 可改为train2017,要对应上面的
jpg_paths = glob.glob('D:\data\TianChi\Train\COCO_ROOT\\val2017\*.jpg')
# 现有的标注文件地址
label_path = r'D:\data\TianChi\Train\roi_label\\'
# 保存地址
save_path = r'D:\data\TianChi\Train\COCO_ROOT\annotations'
c = tococo(jpg_paths, label_path, save_path)
c.save_json()至此就完成了COCO数据格式的转换,就可以用来跑模型了。上述程序仅适用于本人使用的数据集,大家可根据自己的数据进行修改,想了解更多关于COCO数据集格式的信息可参考目标检测 – 解析VOC和COCO格式并制作自己的数据集