SSRNet 点云重建 代码采坑记录
目录
- 前言
- ubuntu,python和tensorflow环境准备
- 下载SSRNet,Open3D
- 安装所需的包
-
- 安装python包:joblib0.11和trimesh
- 安装编译特定仓库的C++的Open3D (py3d?):
- 数据集下载
- 数据集配置
- 可能的报错
-
- TypeError: softmax() got an unexpected keyword argument 'axis'
- NameError: name 'scan' is not defined
- OOM when allocating tensor
- ZeroDivisionError: float division by zero
- 缺Open3D : read_point_cloud not found
- 解决了报错后正式运行
-
- 训练集和测试集
- 掉线继续跑,log的保存
- 关于进度打印的小建议:
- 采坑过程(可跳过)
-
- 数据集配置,库的安装
- 总结遇到过的报错
前言

论文链接:CVPR2020l
github代码链接:https://github.com/wenbingtao/SSRNet
tangent conv:https://github.com/tatarchm/tangent_conv
作者在论文中提到使用了tangent conv, 强烈建议参考。
由于SSRNet的git仓库readme文件写的比较简略,看完后可以先浏览一遍tangent conv的,遇到问题也可以参考tangent conv的issues
ubuntu,python和tensorflow环境准备
ubuntu下的docker环境,直接pull官方tensorflow的镜像,新建contianer。
从百度网盘下载里面的groundtruth数据集,放到服务器上。
作者说的python3.6,tf1.3,我就在官网搜索:
https://hub.docker.com/r/tensorflow/tensorflow/tags/?page=1&name=1.3
最后用的这个:
docker pull tensorflow/tensorflow:1.3.0-gpu-py3
下下来之后发现他的python是3.5的,但好像没影响,可以用。
接下来的操作都在这个container中进行。
注意,这个环境里默认的pyhthon是python2,我们后面用到python命令的时候,都用python3就行。
不熟悉docker的朋友可以先自学一下。我主要看的菜鸟教程,个人笔记在下面:
docker初学笔记
通过指定docker在宿主机中的共享路径,pycharm远程连接宿主机,编辑docker环境中的代码
下载SSRNet,Open3D
git clone https://github.com/wenbingtao/SSRNet.git
git clone https://github.com/tatarchm/Open3D
安装所需的包
安装python包:joblib0.11和trimesh
!!!!注意了,joblib版本高了不行,亲测有效的是0.11!!!!!
pip install joblib==0.11
pip install trimesh
安装编译特定仓库的C++的Open3D (py3d?):
参考https://github.com/tatarchm/tangent_conv
注意不要自己pip install py3d, 一定要使用这个git仓库的版本。
$ git clone https://github.com/tatarchm/Open3D.git
$ cd Open3D
$ util/scripts/install-deps-ubuntu.sh
如果是root,会报错:sudo: not found。只需删掉sudo即可
$ sudo apt-get update
$ sudo apt-get install vim
$ vim install-deps-ubuntu.sh
i , 修改(删去sudo),Esc,:wq!回车
$ util/scripts/install-deps-ubuntu.sh
接下来就可以正常build
$ mkdir build
$ cd build
$ cmake ../src
$ make
这样会在build文件夹里生成build的结果。
打开
build完成后配置一下路径。
修改SSRNet/util/path_config.py这个文件夹。
把open3D_path改成自己的Open3D//build/lib/所在的路径。
tcpath不确定要不要弄。
修改后运行:
python3 util/path_config.py
数据集下载
百度网盘下载readme里面给出的ground truth。
如果要从本地下载,然后fps传到服务器的话,建议传压缩包,然后在服务器上解压,会更快。
数据集配置
首先确定自己要用的config.json文件,比如自带的experiments/dn/config.json。
进去一看,
“co_train_file”:“experiments/stl/train.txt”,
“co_test_file”:“experiments/stl/validation.txt”,
于是要确保这两个文件夹存在。没有的话就新建。
这两个txt的内容分别是train和validation所用的数据文件夹。
比如我的是这样的:
根目录下新建文件夹,并把groundtruth1和2底下的文件夹放进去:
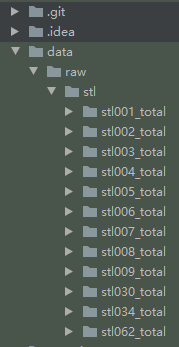

为了尽快跑通,可以先在train和validation里各放一个,确定能跑通后,再把其他的加进来。
比如train里面只写stl007-total。
validation里面只写stl007-total。
如果想复现原作者的结果,其论文中说:

所以我们用123456做training,789做validation。百度网盘里还给了的30,34和62可以做test。
可能的报错
TypeError: softmax() got an unexpected keyword argument ‘axis’
Traceback (most recent call last):
File "ssr.py", line 17, in <module>
run_net(config, "train")
File "util/model.py", line 627, in run_net
nn.build_vertex_model(par.batch_size)
File "util/model.py", line 416, in build_vertex_model
self.output_softmax = tf.nn.softmax(v_pred, axis=1)
TypeError: softmax() got an unexpected keyword argument 'axis'
这个报错的原因是keras版本,作者用的版本中这个关键词是axis,我现在这个版本关键词应为dim。
百度说要降低keras版本
https://blog.csdn.net/weixin_43108122/article/details/100040988
pip install keras==2.1
python3 ssr.py experiments/dn/config.json --train
我改了还是没用,解决方法是把这个axis改为dim
NameError: name ‘scan’ is not defined
python3 ssr.py experiments/dn/config.json --train
joblib.externals.loky.process_executor._RemoteTraceback:
“”"
Traceback (most recent call last):
File “/usr/local/lib/python3.5/dist-packages/joblib/externals/loky/process_executor.py”, line 418, in _process_worker
r = call_item()
File “/usr/local/lib/python3.5/dist-packages/joblib/externals/loky/process_executor.py”, line 272, in call
return self.fn(*self.args, **self.kwargs)
File “/usr/local/lib/python3.5/dist-packages/joblib/_parallel_backends.py”, line 608, in call
return self.func(*args, **kwargs)
File “/usr/local/lib/python3.5/dist-packages/joblib/parallel.py”, line 256, in call
for func, args, kwargs in self.items]
File “/usr/local/lib/python3.5/dist-packages/joblib/parallel.py”, line 256, in
for func, args, kwargs in self.items]
File “util/cloud.py”, line 417, in get_vertex_scan_part_out
num_scales = len(scan.clouds)
NameError: name ‘scan’ is not defined
“”"
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File “ssr.py”, line 17, in
run_net(config, “train”)
File “util/model.py”, line 629, in run_net
nn.precompute_vertex_validation_batches()
File “util/model.py”, line 111, in precompute_vertex_validation_batches
vertex_batch_array = get_vertex_batch_array(test_scan, self.par)
File “util/cloud.py”, line 639, in get_vertex_batch_array
delayed(get_vertex_scan_part_out)(par, pts[i]) for i in range(0, arr_size))
File “/usr/local/lib/python3.5/dist-packages/joblib/parallel.py”, line 1017, in call
self.retrieve()
File “/usr/local/lib/python3.5/dist-packages/joblib/parallel.py”, line 909, in retrieve
self._output.extend(job.get(timeout=self.timeout))
File “/usr/local/lib/python3.5/dist-packages/joblib/_parallel_backends.py”, line 562, in wrap_future_result
return future.result(timeout=timeout)
File “/usr/lib/python3.5/concurrent/futures/_base.py”, line 405, in result
return self.__get_result()
File “/usr/lib/python3.5/concurrent/futures/_base.py”, line 357, in __get_result
raise self._exception
NameError: name ‘scan’ is not defined
解决办法:
(是tangent conv的一个issue:https://github.com/tatarchm/tangent_conv/issues/11)
是joblib版本不行。得用0.11
pip uninstall joblib
pip install joblib==0.11
中间一度怀疑是python版本问题, 但其实不是:
怀疑是python版本吧。升级一下?
sudo apt-get install --reinstall ca-certificates
add-apt-repository ppa:jonathonf/python-3.6
还是不行
OOM when allocating tensor

内存不够,把batch改小一点,在config.json 里面
“tt_batch_size”:300000,
这个数值看着改小一点。
另外,如果有多片GPU,默认代码是用第0块,可以看一下自己的哪块GPU比较空闲,指定一下,参考:
https://blog.csdn.net/qq_38451119/article/details/81065675
ZeroDivisionError: float division by zero
valid_validation_batches_num 0
Loading snapshot model-0
Reading PLY: [========================================] 100%
Traceback (most recent call last):
File “ssr.py”, line 17, in
run_net(config, “train”)
File “util/model.py”, line 632, in run_net
nn.train()
File “util/model.py”, line 488, in train
self.validate(iter_i)
File “util/model.py”, line 532, in validate
print("Accuracy: " + str(avg_acc), "label2_accuracy: ", str(avg_label2_acc/len(acc)),
ZeroDivisionError: float division by zero
似乎是batchsize太小了,导致validation batches num 直接为0了。把batchsize改大一点。
缺Open3D : read_point_cloud not found
open3D没编译和配置好,参考上文进行配置。
解决了报错后正式运行
训练集和测试集
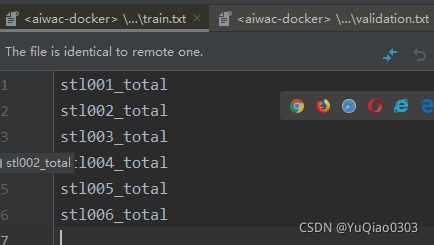
先把train和validation所用的样本写好,train是123456,validation是789.
掉线继续跑,log的保存
默认情况下,终端关闭,其内的进程也会停止,所以如果我们和服务器的连接断了,代码就不跑了。
解决办法是用nohup,即no hang up.
nohup python3 ssr.py experiments/dn/config.json --test >>2021_11_27_21_04.txt &
tailf 2021_11_27_21_04.txt
第一行是说我们断开连接也继续后台执行,输出内容输出到txt文件中。
第二行是说实时在终端打印txt文件的内容。
nohup: 连接断开继续跑模型,log记录在本地
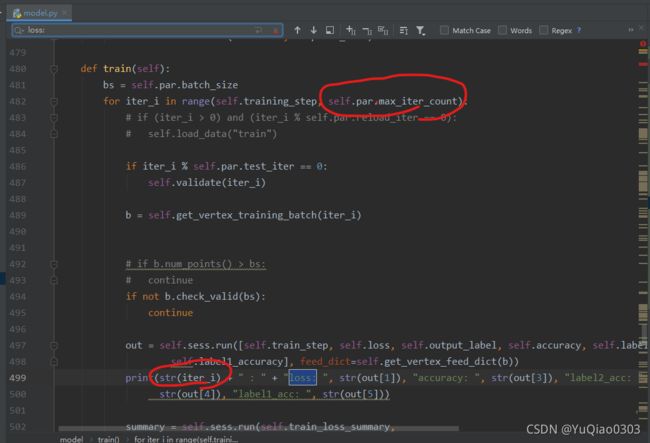
关于进度打印的小建议:
这里输出一些内容,建议第一个iter_i后面加上/maxitercount,
不然也不知道跑道哪里了。
采坑过程(可跳过)
数据集配置,库的安装
python3 ssr.py experiments/dn/config.json --train
ImportError: No module named ‘joblib’
于是
pip install joblib
pip install trimesh
接下来
ImportError: No module named ‘py3d’
FileNotFoundError: [Errno 2] No such file or directory: ‘experiments/stl/validation.txt’
于是把他自己好像生成的叫train.txt和validation.txt的文件放到相应目录下。
FileNotFoundError: [Errno 2] No such file or directory: ‘data/raw/stl/scan1/batch_centers.txt’
结合以下几点:
- 目前train.txt和validation.txt里面的内容都只有五个字符:“scan1”
- ground truth
里面有若干stl_total, 每个total里面都有这个batch_centers.txt

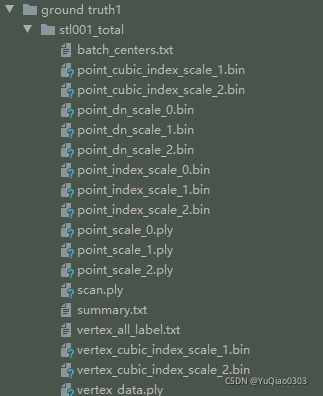
可知需要往这里面填上我们的数据集,指定那几个total是train,哪几个是validation。
data/raw/stl/scan1/batch_centers.txt
我个人选择新建这个文件夹并把东西放进去,而不是修改json文件,因为现在我们的groundtruth1和2是分开的,总是要挪的。
(注意新建文件夹的时候最好用docker容器外面的用户,如果在docker容器中用命令行新建文件夹,docker外的用户可能没有权限)
总结遇到过的报错
- 缺Open3D : read_point_cloud not found,见上文
- (train的时候) name scan not found,见上文
- OOM:减小batch,见上文
- (test的时候) name scan not found: 我个人test的时候也遇到了这个报错。发现是我的原因,之前试图解决的时候改了一些代码,把global scan这一行注释了,取消注释即可。
- OOM:我后来又报了一次这个错。解决方案是查看显存情况,发现0号GPU几乎满了,1号几乎空着,就指定用1号。见上文:https://blog.csdn.net/qq_38451119/article/details/81065675