NNDL 实验七 循环神经网络(3)LSTM的记忆能力实验
文章目录
-
- 6.3 LSTM的记忆能力实验
-
- 6.3.1 模型构建
-
- 6.3.1.1 LSTM层
- 6.3.1.2 模型汇总
- 6.3.2 模型训练
-
- 6.3.2.1 训练指定长度的数字预测模型
- 6.3.2.2 多组训练
- 6.3.2.3 损失曲线展示
- 【思考题1】LSTM与SRN实验结果对比,谈谈看法。
- 6.3.3 模型评价
-
- 6.3.3.1 在测试集上进行模型评价
- 6.3.3.2 模型在不同长度的数据集上的准确率变化图
- 【思考题2】LSTM与SRN在不同长度数据集上的准确度对比,谈谈看法。
- 6.3.3.3 LSTM模型门状态和单元状态的变化
- 【思考题3】分析LSTM中单元状态和门数值的变化图,并用自己的话解释该图。
- 全面总结RNN
- 总结
- 参考链接
6.3 LSTM的记忆能力实验
使用LSTM模型重新进行数字求和实验,验证LSTM模型的长程依赖能力。
 具体计算分为三步:
具体计算分为三步:
(1)计算三个“门”
(2)计算内部状态
(3)计算输出状态
通过学习这些门的设置,LSTM可以选择性地忽略或者强化当前的记忆或是输入信息,帮助网络更好地学习长句子的语义信息。
在本节中,我们使用LSTM模型重新进行数字求和实验,验证LSTM模型的长程依赖能力。
6.3.1 模型构建
使用第6.1.2.4节中定义Model_RNN4SeqClass模型,并构建 LSTM 算子.
只需要实例化 LSTM ,并传入Model_RNN4SeqClass模型,就可以用 LSTM 进行数字求和实验。
6.3.1.1 LSTM层
- 自定义LSTM算子
import torch.nn.functional as F
import torch
import torch.nn as nn
# 声明LSTM和相关参数
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, Wi_attr=None, Wf_attr=None, Wo_attr=None, Wc_attr=None,
Ui_attr=None, Uf_attr=None, Uo_attr=None, Uc_attr=None, bi_attr=None, bf_attr=None,
bo_attr=None, bc_attr=None):
super(LSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 初始化模型参数
if Wi_attr==None:
Wi= torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wi = torch.tensor(Wi_attr, dtype=torch.float32)
self.W_i = torch.nn.Parameter(Wi)
if Wf_attr==None:
Wf=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wf = torch.tensor(Wf_attr, dtype=torch.float32)
self.W_f = torch.nn.Parameter(Wf)
if Wo_attr==None:
Wo=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wo = torch.tensor(Wo_attr, dtype=torch.float32)
self.W_o =torch.nn.Parameter(Wo)
if Wc_attr==None:
Wc=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wc = torch.tensor(Wc_attr, dtype=torch.float32)
self.W_c = torch.nn.Parameter(Wc)
if Ui_attr==None:
Ui = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Ui = torch.tensor(Ui_attr, dtype=torch.float32)
self.U_i = torch.nn.Parameter(Ui)
if Uf_attr == None:
Uf = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Uf = torch.tensor(Uf_attr, dtype=torch.float32)
self.U_f = torch.nn.Parameter(Uf)
if Uo_attr == None:
Uo = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Uo = torch.tensor(Uo_attr, dtype=torch.float32)
self.U_o = torch.nn.Parameter(Uo)
if Uc_attr == None:
Uc = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Uc = torch.tensor(Uc_attr, dtype=torch.float32)
self.U_c = torch.nn.Parameter(Uc)
if bi_attr == None:
bi = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bi = torch.tensor(bi_attr, dtype=torch.float32)
self.b_i = torch.nn.Parameter(bi)
if bf_attr == None:
bf = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bf = torch.tensor(bf_attr, dtype=torch.float32)
self.b_f = torch.nn.Parameter(bf)
if bo_attr == None:
bo = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bo = torch.tensor(bo_attr, dtype=torch.float32)
self.b_o = torch.nn.Parameter(bo)
if bc_attr == None:
bc = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bc = torch.tensor(bc_attr, dtype=torch.float32)
self.b_c = torch.nn.Parameter(bc)
# 初始化状态向量和隐状态向量
def init_state(self, batch_size):
hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)
cell_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)
return hidden_state, cell_state
# 定义前向计算
def forward(self, inputs, states=None):
# inputs: 输入数据,其shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = inputs.shape
# 初始化起始的单元状态和隐状态向量,其shape为batch_size x hidden_size
if states is None:
states = self.init_state(batch_size)
hidden_state, cell_state = states
# 执行LSTM计算,包括:输入门、遗忘门和输出门、候选内部状态、内部状态和隐状态向量
for step in range(seq_len):
# 获取当前时刻的输入数据step_input: 其shape为batch_size x input_size
step_input = inputs[:, step, :]
# 计算输入门, 遗忘门和输出门, 其shape为:batch_size x hidden_size
I_gate = F.sigmoid(torch.matmul(step_input, self.W_i) + torch.matmul(hidden_state, self.U_i) + self.b_i)
F_gate = F.sigmoid(torch.matmul(step_input, self.W_f) + torch.matmul(hidden_state, self.U_f) + self.b_f)
O_gate = F.sigmoid(torch.matmul(step_input, self.W_o) + torch.matmul(hidden_state, self.U_o) + self.b_o)
# 计算候选状态向量, 其shape为:batch_size x hidden_size
C_tilde = F.tanh(torch.matmul(step_input, self.W_c) + torch.matmul(hidden_state, self.U_c) + self.b_c)
# 计算单元状态向量, 其shape为:batch_size x hidden_size
cell_state = F_gate * cell_state + I_gate * C_tilde
# 计算隐状态向量,其shape为:batch_size x hidden_size
hidden_state = O_gate * F.tanh(cell_state)
return hidden_state
Wi_attr = [[0.1, 0.2], [0.1, 0.2]]
Wf_attr = [[0.1, 0.2], [0.1, 0.2]]
Wo_attr = [[0.1, 0.2], [0.1, 0.2]]
Wc_attr = [[0.1, 0.2], [0.1, 0.2]]
Ui_attr = [[0.0, 0.1], [0.1, 0.0]]
Uf_attr = [[0.0, 0.1], [0.1, 0.0]]
Uo_attr = [[0.0, 0.1], [0.1, 0.0]]
Uc_attr = [[0.0, 0.1], [0.1, 0.0]]
bi_attr = [[0.1, 0.1]]
bf_attr = [[0.1, 0.1]]
bo_attr = [[0.1, 0.1]]
bc_attr = [[0.1, 0.1]]
lstm = LSTM(2, 2, Wi_attr=Wi_attr, Wf_attr=Wf_attr, Wo_attr=Wo_attr, Wc_attr=Wc_attr,
Ui_attr=Ui_attr, Uf_attr=Uf_attr, Uo_attr=Uo_attr, Uc_attr=Uc_attr,
bi_attr=bi_attr, bf_attr=bf_attr, bo_attr=bo_attr, bc_attr=bc_attr)
inputs = torch.as_tensor([[[1, 0]]], dtype=torch.float32)
hidden_state = lstm(inputs)
print(hidden_state)
运行结果:

- nn.LSTM
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = 8, 20, 32
inputs = torch.randn(size=[batch_size, seq_len, input_size])
# 设置模型的hidden_size
hidden_size = 32
torch_lstm = nn.LSTM(input_size, hidden_size)
self_lstm = LSTM(input_size, hidden_size)
self_hidden_state = self_lstm(inputs)
torch_outputs, (torch_hidden_state, torch_cell_state) = torch_lstm(inputs)
print("self_lstm hidden_state: ", self_hidden_state.shape)
print("torch_lstm outpus:", torch_outputs.shape)
print("torch_lstm hidden_state:", torch_hidden_state.shape)
print("torch_lstm cell_state:", torch_cell_state.shape)
运行结果:
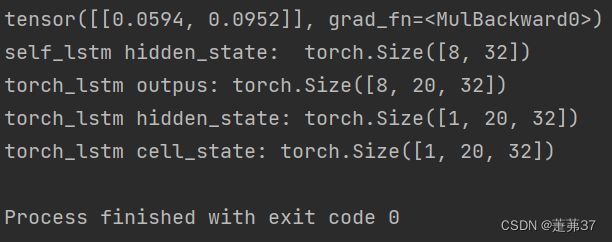
可以看到,自己实现的LSTM由于没有考虑多层因素,因此没有层次这个维度,因此其输出shape为[8, 32]。同时由于在以上代码使用Paddle内置API实例化LSTM时,默认定义的是1层的单向SRN,因此其shape为[1, 8, 32],同时隐状态向量为[8,20, 32].
接下来,我们可以将自己实现的LSTM与Paddle内置的LSTM在输出值的精度上进行对比,这里首先根据Paddle内置的LSTM实例化模型(为了进行对比,在实例化时只保留一个偏置,将偏置bihbih设置为0),然后提取该模型对应的参数,进行参数分割后,使用相应参数去初始化自己实现的LSTM,从而保证两者在参数初始化时是一致的。
- 将自定义LSTM与pytorch内置的LSTM进行对比
import torch
torch.seed()
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size, hidden_size = 2, 5, 10, 10
inputs = torch.randn([batch_size, seq_len, input_size])
# 设置模型的hidden_size
torch_lstm = nn.LSTM(input_size, hidden_size, bias=True)
# 获取torch_lstm中的参数,并设置相应的paramAttr,用于初始化lstm
print(torch_lstm.weight_ih_l0.T.shape)
chunked_W = torch.split(torch_lstm.weight_ih_l0.T, split_size_or_sections=10, dim=-1)
chunked_U = torch.split(torch_lstm.weight_hh_l0.T, split_size_or_sections=10, dim=-1)
chunked_b = torch.split(torch_lstm.bias_hh_l0.T, split_size_or_sections=10, dim=-1)
Wi_attr = chunked_W[0]
Wf_attr = chunked_W[1]
Wc_attr = chunked_W[2]
Wo_attr = chunked_W[3]
Ui_attr = chunked_U[0]
Uf_attr = chunked_U[1]
Uc_attr = chunked_U[2]
Uo_attr = chunked_U[3]
bi_attr = chunked_b[0]
bf_attr = chunked_b[1]
bc_attr = chunked_b[2]
bo_attr = chunked_b[3]
self_lstm = LSTM(input_size, hidden_size, Wi_attr=Wi_attr, Wf_attr=Wf_attr, Wo_attr=Wo_attr, Wc_attr=Wc_attr,
Ui_attr=Ui_attr, Uf_attr=Uf_attr, Uo_attr=Uo_attr, Uc_attr=Uc_attr,
bi_attr=bi_attr, bf_attr=bf_attr, bo_attr=bo_attr, bc_attr=bc_attr)
# 进行前向计算,获取隐状态向量,并打印展示
self_hidden_state = self_lstm(inputs)
torch_outputs, (torch_hidden_state, _) = torch_lstm(inputs)
print("torch SRN:\n", torch_hidden_state.detach().numpy().squeeze(0))
print("self SRN:\n", self_hidden_state.detach().numpy())
运行结果:
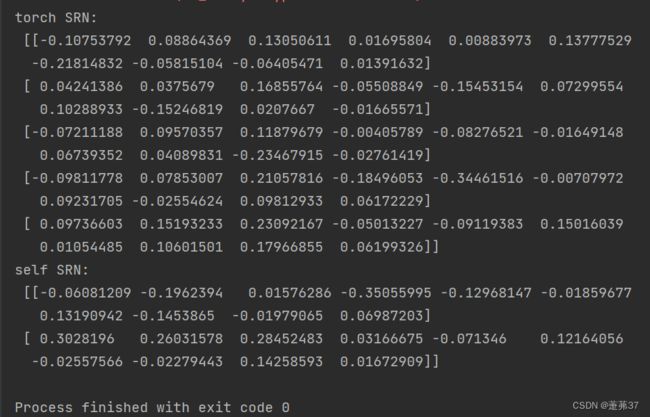
可以看到,两者的输出基本是一致的。另外,还可以进行对比两者在运算速度方面的差异。代码实现如下:
import time
# 这里创建一个随机数组作为测试数据,数据shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = 8, 20, 32
inputs = torch.randn([batch_size, seq_len, input_size])
# 设置模型的hidden_size
hidden_size = 32
self_lstm = LSTM(input_size, hidden_size)
torch_lstm = nn.LSTM(input_size, hidden_size)
# 计算自己实现的SRN运算速度
model_time = 0
for i in range(100):
strat_time = time.time()
hidden_state = self_lstm(inputs)
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
end_time = time.time()
model_time += (end_time - strat_time)
avg_model_time = model_time / 90
print('self_lstm speed:', avg_model_time, 's')
# 计算torch内置的SRN运算速度
model_time = 0
for i in range(100):
strat_time = time.time()
outputs, (hidden_state, cell_state) = torch_lstm(inputs)
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
end_time = time.time()
model_time += (end_time - strat_time)
avg_model_time = model_time / 90
print('torch_lstm speed:', avg_model_time, 's')
运行结果:

可以看到,由于PyTorch底层采用了C++实现并进行优化,Paddle框架内置的LSTM运行效率远远高于自己实现的LSTM。
6.3.1.2 模型汇总
在本节实验中,我们将使用6.1.2.4的Model_RNN4SeqClass作为预测模型,不同在于在实例化时将传入实例化的LSTM层。
6.3.2 模型训练
6.3.2.1 训练指定长度的数字预测模型
本节将基于RunnerV3类进行训练,首先定义模型训练的超参数,并保证和简单循环网络的超参数一致. 然后定义一个train函数,其可以通过指定长度的数据集,并进行训练. 在train函数中,首先加载长度为length的数据,然后实例化各项组件并创建对应的Runner,然后训练该Runner。同时在本节将使用4.5.4节定义的准确度(Accuracy)作为评估指标,代码实现如下:
import os
import random
import torch
import numpy as np
# 训练轮次
num_epochs = 500
# 学习率
lr = 0.001
# 输入数字的类别数
num_digits = 10
# 将数字映射为向量的维度
input_size = 32
# 隐状态向量的维度
hidden_size = 32
# 预测数字的类别数
num_classes = 19
# 批大小
batch_size = 8
# 模型保存目录
save_dir = "./checkpoints"
# 可以设置不同的length进行不同长度数据的预测实验
def train(length):
print(f"\n====> Training LSTM with data of length {length}.")
np.random.seed(0)
random.seed(0)
# 加载长度为length的数据
data_path = f"./datasets/{length}"
train_examples, dev_examples, test_examples = load_data(data_path)
train_set, dev_set, test_set = DigitSumDataset(train_examples), DigitSumDataset(dev_examples), DigitSumDataset(test_examples)
train_loader = DataLoader(train_set, batch_size=batch_size)
dev_loader = DataLoader(dev_set, batch_size=batch_size)
test_loader = DataLoader(test_set, batch_size=batch_size)
# 实例化模型
base_model = LSTM(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 指定优化器
optimizer = torch.optim.Adam(lr=lr, params=model.parameters())
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = torch.nn.CrossEntropyLoss()
# 基于以上组件,实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 进行模型训练
model_save_path = os.path.join(save_dir, f"best_lstm_model_{length}.pdparams")
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=100, log_steps=100, save_path=model_save_path)
return runner
涉及到的函数:
DigitSumDataset()
from torch.utils.data import Dataset,DataLoader
import torch
class DigitSumDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, idx):
example = self.data[idx]
seq = torch.tensor(example[0], dtype=torch.int64)
label = torch.tensor(example[1], dtype=torch.int64)
return seq, label
def __len__(self):
return len(self.data)
load_data()
import os
# 加载数据
def load_data(data_path):
# 加载训练集
train_examples = []
train_path = os.path.join(data_path, "train.txt")
with open(train_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
train_examples.append((seq, label))
# 加载验证集
dev_examples = []
dev_path = os.path.join(data_path, "dev.txt")
with open(dev_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
dev_examples.append((seq, label))
# 加载测试集
test_examples = []
test_path = os.path.join(data_path, "test.txt")
with open(test_path, "r", encoding="utf-8") as f:
for line in f.readlines():
# 解析一行数据,将其处理为数字序列seq和标签label
items = line.strip().split("\t")
seq = [int(i) for i in items[0].split(" ")]
label = int(items[1])
test_examples.append((seq, label))
return train_examples, dev_examples, test_examples
Embedding()
class Embedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super(Embedding, self).__init__()
self.W = nn.init.xavier_uniform_(torch.empty(num_embeddings, embedding_dim),gain=1.0)
def forward(self, inputs):
# 根据索引获取对应词向量
embs = self.W[inputs]
return embs
emb_layer = Embedding(10, 5)
inputs = torch.tensor([0, 1, 2, 3])
emb_layer(inputs)
Model_RNN4SeqClass()
# 基于RNN实现数字预测的模型
class Model_RNN4SeqClass(nn.Module):
def __init__(self, model, num_digits, input_size, hidden_size, num_classes):
super(Model_RNN4SeqClass, self).__init__()
# 传入实例化的RNN层,例如SRN
self.rnn_model = model
# 词典大小
self.num_digits = num_digits
# 嵌入向量的维度
self.input_size = input_size
# 定义Embedding层
self.embedding = Embedding(num_digits, input_size)
# 定义线性层
self.linear = nn.Linear(hidden_size, num_classes)
def forward(self, inputs):
# 将数字序列映射为相应向量
inputs_emb = self.embedding(inputs)
# 调用RNN模型
hidden_state = self.rnn_model(inputs_emb)
# 使用最后一个时刻的状态进行数字预测
logits = self.linear(hidden_state)
return logits
RunnerV3()
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y.long()) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y.long()).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)
Accuracy()
class Accuracy():
def __init__(self, is_logist=True):
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, dim=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.tensor((outputs >= 0), dtype=torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.tensor((outputs >= 0.5), dtype=torch.float32)
else:
# 多分类时,使用'torch.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1)
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
6.3.2.2 多组训练
接下来,分别进行数据长度为10, 15, 20, 25, 30, 35的数字预测模型训练实验,训练后的runner保存至runners字典中。
lstm_runners = {}
lengths = [10, 15, 20, 25, 30, 35]
for length in lengths:
runner = train(length)
lstm_runners[length] = runner
运行结果:
====> Training LSTM with data of length 10.
[Evaluate] dev score: 0.09000, dev loss: 2.86460
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.09000
[Train] epoch: 5/500, step: 200/19000, loss: 2.48144
[Evaluate] dev score: 0.10000, dev loss: 2.84022
[Evaluate] best accuracy performence has been updated: 0.09000 --> 0.10000
[Train] epoch: 7/500, step: 300/19000, loss: 2.46724
[Evaluate] dev score: 0.10000, dev loss: 2.83455
[Train] epoch: 10/500, step: 400/19000, loss: 2.41858
[Evaluate] dev score: 0.10000, dev loss: 2.83207
[Train] epoch: 13/500, step: 500/19000, loss: 2.45705
[Evaluate] dev score: 0.76000, dev loss: 1.38295
[Train] epoch: 484/500, step: 18400/19000, loss: 0.00069
[Evaluate] dev score: 0.76000, dev loss: 1.38330
[Train] epoch: 486/500, step: 18500/19000, loss: 0.00040
[Evaluate] dev score: 0.77000, dev loss: 1.38700
[Evaluate] best accuracy performence has been updated: 0.76000 --> 0.77000
[Train] epoch: 489/500, step: 18600/19000, loss: 0.00067
[Evaluate] dev score: 0.77000, dev loss: 1.38891
[Train] epoch: 492/500, step: 18700/19000, loss: 0.00050
[Evaluate] dev score: 0.77000, dev loss: 1.39004
[Train] epoch: 494/500, step: 18800/19000, loss: 0.00053
[Evaluate] dev score: 0.77000, dev loss: 1.39317
[Train] epoch: 497/500, step: 18900/19000, loss: 0.00069
[Evaluate] dev score: 0.77000, dev loss: 1.39381
[Evaluate] dev score: 0.77000, dev loss: 1.39583
[Train] Training done!
====> Training LSTM with data of length 15.
[Train] epoch: 0/500, step: 0/19000, loss: 2.83505
[Train] epoch: 2/500, step: 100/19000, loss: 2.78581
[Evaluate] dev score: 0.07000, dev loss: 2.86551
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.07000
[Train] epoch: 5/500, step: 200/19000, loss: 2.49482
[Evaluate] dev score: 0.10000, dev loss: 2.84367
[Evaluate] best accuracy performence has been updated: 0.07000 --> 0.10000
[Train] epoch: 7/500, step: 300/19000, loss: 2.48387
[Evaluate] dev score: 0.10000, dev loss: 2.83747
[Train] epoch: 10/500, step: 400/19000, loss: 2.40902
[Evaluate] best accuracy performence has been updated: 0.79000 --> 0.80000
[Train] epoch: 418/500, step: 15900/19000, loss: 0.00319
[Evaluate] dev score: 0.80000, dev loss: 1.25397
[Train] epoch: 421/500, step: 16000/19000, loss: 0.00458
[Evaluate] dev score: 0.80000, dev loss: 1.25535
[Train] epoch: 423/500, step: 16100/19000, loss: 0.00265
[Evaluate] dev score: 0.80000, dev loss: 1.25759
[Train] epoch: 426/500, step: 16200/19000, loss: 0.00167
[Evaluate] dev score: 0.80000, dev loss: 1.25949
[Train] epoch: 428/500, step: 16300/19000, loss: 0.00092
[Evaluate] dev score: 0.80000, dev loss: 1.26127
[Train] epoch: 431/500, step: 16400/19000, loss: 0.00161
[Evaluate] dev score: 0.80000, dev loss: 1.26405
[Train] epoch: 434/500, step: 16500/19000, loss: 0.00154
[Evaluate] dev score: 0.80000, dev loss: 1.26565
[Train] epoch: 436/500, step: 16600/19000, loss: 0.00068
[Evaluate] dev score: 0.80000, dev loss: 1.26796
[Train] epoch: 439/500, step: 16700/19000, loss: 0.00132
[Evaluate] dev score: 0.80000, dev loss: 1.27097
[Train] epoch: 442/500, step: 16800/19000, loss: 0.00164
[Evaluate] dev score: 0.80000, dev loss: 1.27273
[Train] epoch: 444/500, step: 16900/19000, loss: 0.00087
[Evaluate] dev score: 0.80000, dev loss: 1.27552
[Train] epoch: 447/500, step: 17000/19000, loss: 0.00130
[Evaluate] dev score: 0.80000, dev loss: 1.27835
[Train] epoch: 450/500, step: 17100/19000, loss: 0.00409
[Evaluate] dev score: 0.80000, dev loss: 1.28007
[Train] epoch: 452/500, step: 17200/19000, loss: 0.00074
[Evaluate] dev score: 0.80000, dev loss: 1.28351
[Train] epoch: 455/500, step: 17300/19000, loss: 0.00037
[Evaluate] dev score: 0.80000, dev loss: 1.28587
[Train] epoch: 457/500, step: 17400/19000, loss: 0.00081
[Evaluate] dev score: 0.80000, dev loss: 1.28809
[Train] epoch: 460/500, step: 17500/19000, loss: 0.00078
[Evaluate] dev score: 0.80000, dev loss: 1.29226
[Train] epoch: 463/500, step: 17600/19000, loss: 0.00063
[Evaluate] dev score: 0.80000, dev loss: 1.29375
[Train] epoch: 465/500, step: 17700/19000, loss: 0.00081
[Evaluate] dev score: 0.80000, dev loss: 1.29866
[Train] epoch: 468/500, step: 17800/19000, loss: 0.00133
[Evaluate] dev score: 0.80000, dev loss: 1.30044
[Train] epoch: 471/500, step: 17900/19000, loss: 0.00188
[Evaluate] dev score: 0.80000, dev loss: 1.30269
[Train] epoch: 473/500, step: 18000/19000, loss: 0.00104
[Evaluate] dev score: 0.80000, dev loss: 1.30722
[Train] epoch: 476/500, step: 18100/19000, loss: 0.00080
[Evaluate] dev score: 0.80000, dev loss: 1.30969
[Train] epoch: 478/500, step: 18200/19000, loss: 0.00039
[Evaluate] dev score: 0.80000, dev loss: 1.31293
[Train] epoch: 481/500, step: 18300/19000, loss: 0.00066
[Evaluate] dev score: 0.80000, dev loss: 1.31794
[Train] epoch: 484/500, step: 18400/19000, loss: 0.00054
[Evaluate] dev score: 0.80000, dev loss: 1.31867
[Train] epoch: 486/500, step: 18500/19000, loss: 0.00031
[Evaluate] dev score: 0.80000, dev loss: 1.32285
[Train] epoch: 489/500, step: 18600/19000, loss: 0.00053
[Evaluate] dev score: 0.80000, dev loss: 1.32626
[Train] epoch: 492/500, step: 18700/19000, loss: 0.00063
[Evaluate] dev score: 0.80000, dev loss: 1.32818
[Train] epoch: 494/500, step: 18800/19000, loss: 0.00034
[Evaluate] dev score: 0.80000, dev loss: 1.33328
[Train] epoch: 497/500, step: 18900/19000, loss: 0.00036
[Evaluate] dev score: 0.80000, dev loss: 1.33515
[Evaluate] dev score: 0.80000, dev loss: 1.33826
[Train] Training done!
====> Training LSTM with data of length 20.
[Train] epoch: 0/500, step: 0/19000, loss: 2.83505
[Train] epoch: 2/500, step: 100/19000, loss: 2.76947
[Evaluate] dev score: 0.10000, dev loss: 2.85964
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.10000
[Train] epoch: 5/500, step: 200/19000, loss: 2.48617
[Evaluate] dev score: 0.10000, dev loss: 2.83813
[Train] epoch: 7/500, step: 300/19000, loss: 2.48167
[Evaluate] dev score: 0.10000, dev loss: 2.83235
[Train] epoch: 10/500, step: 400/19000, loss: 2.40573
[Evaluate] dev score: 0.10000, dev loss: 2.82994
[Train] epoch: 13/500, step: 500/19000, loss: 2.46062
[Evaluate] dev score: 0.10000, dev loss: 2.82841
[Train] epoch: 15/500, step: 600/19000, loss: 2.36476
[Evaluate] dev score: 0.10000, dev loss: 2.82848
[Train] epoch: 18/500, step: 700/19000, loss: 2.50661
[Evaluate] dev score: 0.10000, dev loss: 2.82729
[Train] epoch: 21/500, step: 800/19000, loss: 2.69739
[Evaluate] dev score: 0.10000, dev loss: 2.82654
[Train] epoch: 23/500, step: 900/19000, loss: 2.67164
[Evaluate] dev score: 0.10000, dev loss: 2.82587
[Train] epoch: 26/500, step: 1000/19000, loss: 2.73424
[Evaluate] dev score: 0.11000, dev loss: 2.82421
[Evaluate] best accuracy performence has been updated: 0.10000 --> 0.11000
[Train] epoch: 28/500, step: 1100/19000, loss: 3.44213
[Evaluate] dev score: 0.12000, dev loss: 2.82406
[Evaluate] best accuracy performence has been updated: 0.11000 --> 0.12000
[Train] epoch: 31/500, step: 1200/19000, loss: 2.81749
[Evaluate] dev score: 0.72000, dev loss: 1.76485
[Evaluate] best accuracy performence has been updated: 0.71000 --> 0.72000
[Train] epoch: 352/500, step: 13400/19000, loss: 0.00286
[Evaluate] dev score: 0.73000, dev loss: 1.77673
[Evaluate] best accuracy performence has been updated: 0.72000 --> 0.73000
[Train] epoch: 355/500, step: 13500/19000, loss: 0.03924
[Evaluate] dev score: 0.73000, dev loss: 1.77541
[Train] epoch: 357/500, step: 13600/19000, loss: 0.01049
[Evaluate] dev score: 0.73000, dev loss: 1.77870
[Train] epoch: 360/500, step: 13700/19000, loss: 0.01205
[Evaluate] dev score: 0.73000, dev loss: 1.78517
[Train] epoch: 363/500, step: 13800/19000, loss: 0.00505
[Evaluate] dev score: 0.73000, dev loss: 1.78481
[Train] epoch: 365/500, step: 13900/19000, loss: 0.00416
[Evaluate] dev score: 0.73000, dev loss: 1.78524
[Train] epoch: 368/500, step: 14000/19000, loss: 0.00970
[Evaluate] dev score: 0.73000, dev loss: 1.78913
[Train] epoch: 371/500, step: 14100/19000, loss: 0.00992
[Evaluate] dev score: 0.73000, dev loss: 1.78916
[Train] epoch: 373/500, step: 14200/19000, loss: 0.03927
[Evaluate] dev score: 0.73000, dev loss: 1.79077
[Train] epoch: 376/500, step: 14300/19000, loss: 0.01398
[Evaluate] dev score: 0.72000, dev loss: 1.79417
[Train] epoch: 378/500, step: 14400/19000, loss: 0.01049
[Evaluate] dev score: 0.72000, dev loss: 1.79497
[Train] epoch: 381/500, step: 14500/19000, loss: 0.01269
[Evaluate] dev score: 0.72000, dev loss: 1.79722
[Train] epoch: 384/500, step: 14600/19000, loss: 0.01123
[Evaluate] dev score: 0.72000, dev loss: 1.79931
[Train] epoch: 386/500, step: 14700/19000, loss: 0.00823
[Evaluate] dev score: 0.72000, dev loss: 1.80139
[Train] epoch: 389/500, step: 14800/19000, loss: 0.00241
[Evaluate] dev score: 0.72000, dev loss: 1.80689
[Train] epoch: 392/500, step: 14900/19000, loss: 0.02594
[Evaluate] dev score: 0.72000, dev loss: 1.80951
[Train] epoch: 394/500, step: 15000/19000, loss: 0.01275
[Evaluate] dev score: 0.72000, dev loss: 1.81205
[Train] epoch: 397/500, step: 15100/19000, loss: 0.00252
[Evaluate] dev score: 0.72000, dev loss: 1.81857
[Train] epoch: 400/500, step: 15200/19000, loss: 0.03170
[Evaluate] dev score: 0.72000, dev loss: 1.81997
[Train] epoch: 402/500, step: 15300/19000, loss: 0.00160
[Evaluate] dev score: 0.72000, dev loss: 1.82440
[Train] epoch: 405/500, step: 15400/19000, loss: 0.00837
[Evaluate] dev score: 0.72000, dev loss: 1.82802
[Train] epoch: 407/500, step: 15500/19000, loss: 0.00461
[Evaluate] dev score: 0.72000, dev loss: 1.82951
[Train] epoch: 410/500, step: 15600/19000, loss: 0.00497
[Evaluate] dev score: 0.72000, dev loss: 1.83551
[Train] epoch: 413/500, step: 15700/19000, loss: 0.00222
[Evaluate] dev score: 0.72000, dev loss: 1.83732
[Train] epoch: 415/500, step: 15800/19000, loss: 0.00176
[Evaluate] dev score: 0.72000, dev loss: 1.84012
[Train] epoch: 418/500, step: 15900/19000, loss: 0.00433
[Evaluate] dev score: 0.72000, dev loss: 1.84767
[Train] epoch: 421/500, step: 16000/19000, loss: 0.00421
[Evaluate] dev score: 0.71000, dev loss: 1.85009
[Train] epoch: 423/500, step: 16100/19000, loss: 0.01154
[Evaluate] dev score: 0.71000, dev loss: 1.85613
[Train] epoch: 426/500, step: 16200/19000, loss: 0.00394
[Evaluate] dev score: 0.71000, dev loss: 1.86571
[Train] epoch: 428/500, step: 16300/19000, loss: 0.00451
[Evaluate] dev score: 0.71000, dev loss: 1.86908
[Train] epoch: 431/500, step: 16400/19000, loss: 0.00580
[Evaluate] dev score: 0.71000, dev loss: 1.87763
[Train] epoch: 434/500, step: 16500/19000, loss: 0.00293
[Evaluate] dev score: 0.71000, dev loss: 1.88435
[Train] epoch: 436/500, step: 16600/19000, loss: 0.00434
[Evaluate] dev score: 0.71000, dev loss: 1.88968
[Train] epoch: 439/500, step: 16700/19000, loss: 0.00134
[Evaluate] dev score: 0.71000, dev loss: 1.89978
[Train] epoch: 442/500, step: 16800/19000, loss: 0.00893
[Evaluate] dev score: 0.71000, dev loss: 1.90282
[Train] epoch: 444/500, step: 16900/19000, loss: 0.00361
[Evaluate] dev score: 0.71000, dev loss: 1.90847
[Train] epoch: 447/500, step: 17000/19000, loss: 0.00119
[Evaluate] dev score: 0.70000, dev loss: 1.91738
[Train] epoch: 450/500, step: 17100/19000, loss: 0.01069
[Evaluate] dev score: 0.70000, dev loss: 1.91850
[Train] epoch: 452/500, step: 17200/19000, loss: 0.00080
[Evaluate] dev score: 0.70000, dev loss: 1.92626
[Train] epoch: 455/500, step: 17300/19000, loss: 0.00269
[Evaluate] dev score: 0.70000, dev loss: 1.93184
[Train] epoch: 457/500, step: 17400/19000, loss: 0.00176
[Evaluate] dev score: 0.71000, dev loss: 1.93430
[Train] epoch: 460/500, step: 17500/19000, loss: 0.00212
[Evaluate] dev score: 0.71000, dev loss: 1.94325
[Train] epoch: 463/500, step: 17600/19000, loss: 0.00098
[Evaluate] dev score: 0.71000, dev loss: 1.94598
[Train] epoch: 465/500, step: 17700/19000, loss: 0.00076
[Evaluate] dev score: 0.71000, dev loss: 1.95027
[Train] epoch: 468/500, step: 17800/19000, loss: 0.00193
[Evaluate] dev score: 0.71000, dev loss: 1.95995
[Train] epoch: 471/500, step: 17900/19000, loss: 0.00128
[Evaluate] dev score: 0.71000, dev loss: 1.95994
[Train] epoch: 473/500, step: 18000/19000, loss: 0.00349
[Evaluate] dev score: 0.71000, dev loss: 1.96585
[Train] epoch: 476/500, step: 18100/19000, loss: 0.00139
[Evaluate] dev score: 0.71000, dev loss: 1.97238
[Train] epoch: 478/500, step: 18200/19000, loss: 0.00186
[Evaluate] dev score: 0.71000, dev loss: 1.97150
[Train] epoch: 481/500, step: 18300/19000, loss: 0.00246
[Evaluate] dev score: 0.71000, dev loss: 1.97660
[Train] epoch: 484/500, step: 18400/19000, loss: 0.00103
[Evaluate] dev score: 0.71000, dev loss: 1.97730
[Train] epoch: 486/500, step: 18500/19000, loss: 0.00174
[Evaluate] dev score: 0.71000, dev loss: 1.97380
[Train] epoch: 489/500, step: 18600/19000, loss: 0.00062
[Evaluate] dev score: 0.71000, dev loss: 1.97653
[Train] epoch: 492/500, step: 18700/19000, loss: 0.00298
[Evaluate] dev score: 0.71000, dev loss: 1.97168
[Train] epoch: 494/500, step: 18800/19000, loss: 0.00130
[Evaluate] dev score: 0.71000, dev loss: 1.97103
[Train] epoch: 497/500, step: 18900/19000, loss: 0.00053
[Evaluate] dev score: 0.71000, dev loss: 1.97714
[Evaluate] dev score: 0.71000, dev loss: 1.97366
[Train] Training done!
====> Training LSTM with data of length 25.
[Train] epoch: 0/500, step: 0/19000, loss: 2.83505
[Train] epoch: 2/500, step: 100/19000, loss: 2.77655
[Evaluate] dev score: 0.10000, dev loss: 2.86074
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.10000
[Train] epoch: 5/500, step: 200/19000, loss: 2.49976
[Evaluate] dev score: 0.10000, dev loss: 2.84144
[Train] epoch: 7/500, step: 300/19000, loss: 2.49110
[Evaluate] dev score: 0.10000, dev loss: 2.83578
[Train] epoch: 10/500, step: 400/19000, loss: 2.41369
[Evaluate] dev score: 0.10000, dev loss: 2.83335
[Train] epoch: 13/500, step: 500/19000, loss: 2.46401
[Evaluate] dev score: 0.10000, dev loss: 2.83232
[Train] epoch: 15/500, step: 600/19000, loss: 2.38640
[Evaluate] dev score: 0.10000, dev loss: 2.83254
[Train] epoch: 18/500, step: 700/19000, loss: 2.51424
[Evaluate] dev score: 0.40000, dev loss: 3.61628
[Evaluate] best accuracy performence has been updated: 0.38000 --> 0.40000
[Train] epoch: 394/500, step: 15000/19000, loss: 0.08060
[Evaluate] dev score: 0.36000, dev loss: 3.71179
[Train] epoch: 397/500, step: 15100/19000, loss: 0.04139
[Evaluate] dev score: 0.35000, dev loss: 3.81133
[Train] epoch: 400/500, step: 15200/19000, loss: 0.19323
[Evaluate] dev score: 0.37000, dev loss: 3.83067
[Train] epoch: 402/500, step: 15300/19000, loss: 0.03759
[Evaluate] dev score: 0.35000, dev loss: 3.85875
[Train] epoch: 405/500, step: 15400/19000, loss: 0.01963
[Evaluate] dev score: 0.36000, dev loss: 3.86882
[Train] epoch: 407/500, step: 15500/19000, loss: 0.03708
[Evaluate] dev score: 0.35000, dev loss: 3.88566
[Train] epoch: 410/500, step: 15600/19000, loss: 0.03960
[Evaluate] dev score: 0.36000, dev loss: 3.90958
[Train] epoch: 413/500, step: 15700/19000, loss: 0.01620
[Evaluate] dev score: 0.36000, dev loss: 3.92829
[Train] epoch: 415/500, step: 15800/19000, loss: 0.02653
[Evaluate] dev score: 0.36000, dev loss: 3.95439
[Train] epoch: 418/500, step: 15900/19000, loss: 0.01211
[Evaluate] dev score: 0.36000, dev loss: 3.96535
[Train] epoch: 421/500, step: 16000/19000, loss: 0.02010
[Evaluate] dev score: 0.36000, dev loss: 3.98574
[Train] epoch: 423/500, step: 16100/19000, loss: 0.01403
[Evaluate] dev score: 0.36000, dev loss: 4.00418
[Train] epoch: 426/500, step: 16200/19000, loss: 0.10261
[Evaluate] dev score: 0.33000, dev loss: 3.87917
[Train] epoch: 428/500, step: 16300/19000, loss: 0.50658
[Evaluate] dev score: 0.24000, dev loss: 4.19479
[Train] epoch: 431/500, step: 16400/19000, loss: 0.77854
[Evaluate] dev score: 0.37000, dev loss: 3.88633
[Train] epoch: 434/500, step: 16500/19000, loss: 0.05411
[Evaluate] dev score: 0.32000, dev loss: 4.37722
[Train] epoch: 436/500, step: 16600/19000, loss: 0.04985
[Evaluate] dev score: 0.35000, dev loss: 3.95593
[Train] epoch: 439/500, step: 16700/19000, loss: 0.04037
[Evaluate] dev score: 0.36000, dev loss: 4.05939
[Train] epoch: 442/500, step: 16800/19000, loss: 0.06667
[Evaluate] dev score: 0.37000, dev loss: 4.01447
[Train] epoch: 444/500, step: 16900/19000, loss: 0.03957
[Evaluate] dev score: 0.37000, dev loss: 4.12112
[Train] epoch: 447/500, step: 17000/19000, loss: 0.03272
[Evaluate] dev score: 0.34000, dev loss: 4.04134
[Train] epoch: 450/500, step: 17100/19000, loss: 0.13312
[Evaluate] dev score: 0.33000, dev loss: 4.29661
[Train] epoch: 452/500, step: 17200/19000, loss: 0.07697
[Evaluate] dev score: 0.32000, dev loss: 4.34585
[Train] epoch: 455/500, step: 17300/19000, loss: 0.01970
[Evaluate] dev score: 0.32000, dev loss: 4.23175
[Train] epoch: 457/500, step: 17400/19000, loss: 0.02952
[Evaluate] dev score: 0.34000, dev loss: 4.00266
[Train] epoch: 460/500, step: 17500/19000, loss: 0.03060
[Evaluate] dev score: 0.37000, dev loss: 4.19442
[Train] epoch: 463/500, step: 17600/19000, loss: 0.00943
[Evaluate] dev score: 0.35000, dev loss: 4.11684
[Train] epoch: 465/500, step: 17700/19000, loss: 0.01985
[Evaluate] dev score: 0.37000, dev loss: 4.13914
[Train] epoch: 468/500, step: 17800/19000, loss: 0.01026
[Evaluate] dev score: 0.37000, dev loss: 4.16462
[Train] epoch: 471/500, step: 17900/19000, loss: 0.01614
[Evaluate] dev score: 0.36000, dev loss: 4.19717
[Train] epoch: 473/500, step: 18000/19000, loss: 0.00953
[Evaluate] dev score: 0.35000, dev loss: 4.21827
[Train] epoch: 476/500, step: 18100/19000, loss: 0.01507
[Evaluate] dev score: 0.37000, dev loss: 4.23882
[Train] epoch: 478/500, step: 18200/19000, loss: 0.02248
[Evaluate] dev score: 0.37000, dev loss: 4.26983
[Train] epoch: 481/500, step: 18300/19000, loss: 0.02343
[Evaluate] dev score: 0.37000, dev loss: 4.28182
[Train] epoch: 484/500, step: 18400/19000, loss: 0.01243
[Evaluate] dev score: 0.37000, dev loss: 4.30134
[Train] epoch: 486/500, step: 18500/19000, loss: 0.00708
[Evaluate] dev score: 0.37000, dev loss: 4.32320
[Train] epoch: 489/500, step: 18600/19000, loss: 0.00910
[Evaluate] dev score: 0.37000, dev loss: 4.33397
[Train] epoch: 492/500, step: 18700/19000, loss: 0.02776
[Evaluate] dev score: 0.37000, dev loss: 4.35447
[Train] epoch: 494/500, step: 18800/19000, loss: 0.01732
[Evaluate] dev score: 0.37000, dev loss: 4.36823
[Train] epoch: 497/500, step: 18900/19000, loss: 0.01365
[Evaluate] dev score: 0.37000, dev loss: 4.38031
[Evaluate] dev score: 0.37000, dev loss: 4.41117
[Train] Training done!
====> Training LSTM with data of length 30.
[Train] epoch: 0/500, step: 0/19000, loss: 2.83505
[Train] epoch: 2/500, step: 100/19000, loss: 2.78386
[Evaluate] dev score: 0.12000, dev loss: 2.86110
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.12000
[Train] epoch: 5/500, step: 200/19000, loss: 2.50157
[Evaluate] dev score: 0.10000, dev loss: 2.83898
[Train] epoch: 7/500, step: 300/19000, loss: 2.49030
[Evaluate] dev score: 0.10000, dev loss: 2.83275
[Train] epoch: 10/500, step: 400/19000, loss: 2.41555
[Evaluate] dev score: 0.10000, dev loss: 2.83050
[Train] epoch: 13/500, step: 500/19000, loss: 2.47067
[Evaluate] dev score: 0.10000, dev loss: 2.82899
[Train] epoch: 15/500, step: 600/19000, loss: 2.37797
[Evaluate] dev score: 0.10000, dev loss: 2.82922
[Train] epoch: 18/500, step: 700/19000, loss: 2.51159
[Evaluate] dev score: 0.10000, dev loss: 2.82841
[Train] epoch: 21/500, step: 800/19000, loss: 2.68927
[Evaluate] dev score: 0.10000, dev loss: 2.82814
[Train] epoch: 23/500, step: 900/19000, loss: 2.67566
[Evaluate] dev score: 0.10000, dev loss: 2.82848
[Train] epoch: 26/500, step: 1000/19000, loss: 2.72234
[Evaluate] dev score: 0.10000, dev loss: 2.82783
[Train] epoch: 28/500, step: 1100/19000, loss: 3.48299
[Evaluate] dev score: 0.10000, dev loss: 2.82849
[Train] epoch: 31/500, step: 1200/19000, loss: 2.78354
[Evaluate] dev score: 0.10000, dev loss: 2.82815
[Train] epoch: 34/500, step: 1300/19000, loss: 3.00769
[Evaluate] dev score: 0.10000, dev loss: 2.82761
[Train] epoch: 36/500, step: 1400/19000, loss: 3.04156
[Evaluate] dev score: 0.10000, dev loss: 2.82860
[Train] epoch: 39/500, step: 1500/19000, loss: 2.79295
[Evaluate] dev score: 0.10000, dev loss: 2.82796
[Train] epoch: 42/500, step: 1600/19000, loss: 3.26870
[Evaluate] dev score: 0.10000, dev loss: 2.82775
[Train] epoch: 44/500, step: 1700/19000, loss: 2.69724
[Evaluate] dev score: 0.10000, dev loss: 2.82910
[Train] epoch: 47/500, step: 1800/19000, loss: 2.58157
[Evaluate] dev score: 0.10000, dev loss: 2.82889
[Train] epoch: 50/500, step: 1900/19000, loss: 4.11195
[Train] epoch: 457/500, step: 17400/19000, loss: 0.00965
[Evaluate] dev score: 0.86000, dev loss: 0.68678
[Train] epoch: 460/500, step: 17500/19000, loss: 0.00763
[Evaluate] dev score: 0.87000, dev loss: 0.68706
[Train] epoch: 463/500, step: 17600/19000, loss: 0.01124
[Evaluate] dev score: 0.87000, dev loss: 0.68583
[Train] epoch: 465/500, step: 17700/19000, loss: 0.01042
[Evaluate] dev score: 0.87000, dev loss: 0.68894
[Train] epoch: 468/500, step: 17800/19000, loss: 0.00819
[Evaluate] dev score: 0.87000, dev loss: 0.68902
[Train] epoch: 471/500, step: 17900/19000, loss: 0.00186
[Evaluate] dev score: 0.86000, dev loss: 0.68932
[Train] epoch: 473/500, step: 18000/19000, loss: 0.00879
[Evaluate] dev score: 0.87000, dev loss: 0.69464
[Train] epoch: 476/500, step: 18100/19000, loss: 0.00581
[Evaluate] dev score: 0.87000, dev loss: 0.69183
[Train] epoch: 478/500, step: 18200/19000, loss: 0.01392
[Evaluate] dev score: 0.86000, dev loss: 0.69212
[Train] epoch: 481/500, step: 18300/19000, loss: 0.00584
[Evaluate] dev score: 0.87000, dev loss: 0.69869
[Train] epoch: 484/500, step: 18400/19000, loss: 0.01406
[Evaluate] dev score: 0.87000, dev loss: 0.69551
[Train] epoch: 486/500, step: 18500/19000, loss: 0.01131
[Evaluate] dev score: 0.87000, dev loss: 0.69632
[Train] epoch: 489/500, step: 18600/19000, loss: 0.00420
[Evaluate] dev score: 0.87000, dev loss: 0.70490
[Train] epoch: 492/500, step: 18700/19000, loss: 0.00802
[Evaluate] dev score: 0.88000, dev loss: 0.70548
[Evaluate] best accuracy performence has been updated: 0.87000 --> 0.88000
[Train] epoch: 494/500, step: 18800/19000, loss: 0.00547
[Evaluate] dev score: 0.88000, dev loss: 0.70771
[Train] epoch: 497/500, step: 18900/19000, loss: 0.00443
[Evaluate] dev score: 0.88000, dev loss: 0.71215
[Evaluate] dev score: 0.88000, dev loss: 0.72060
[Train] Training done!
====> Training LSTM with data of length 35.
[Train] epoch: 0/500, step: 0/19000, loss: 2.83505
[Train] epoch: 2/500, step: 100/19000, loss: 2.77430
[Evaluate] dev score: 0.12000, dev loss: 2.85861
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.12000
[Train] epoch: 5/500, step: 200/19000, loss: 2.49744
[Evaluate] dev score: 0.10000, dev loss: 2.83670
[Train] epoch: 7/500, step: 300/19000, loss: 2.48664
[Evaluate] dev score: 0.10000, dev loss: 2.83080
[Train] epoch: 10/500, step: 400/19000, loss: 2.42468
[Evaluate] dev score: 0.10000, dev loss: 2.82865
[Train] epoch: 13/500, step: 500/19000, loss: 2.45966
[Evaluate] dev score: 0.10000, dev loss: 2.82730
[Train] epoch: 15/500, step: 600/19000, loss: 2.37259
[Evaluate] dev score: 0.10000, dev loss: 2.82764
[Train] epoch: 18/500, step: 700/19000, loss: 2.50715
[Evaluate] dev score: 0.10000, dev loss: 2.82672
[Train] epoch: 21/500, step: 800/19000, loss: 2.69640
[Evaluate] dev score: 0.10000, dev loss: 2.82642
[Train] epoch: 23/500, step: 900/19000, loss: 2.66457
[Evaluate] dev score: 0.11000, dev loss: 2.82679
[Train] epoch: 26/500, step: 1000/19000, loss: 2.64764
[Evaluate] dev score: 0.10000, dev loss: 2.82769
[Train] epoch: 28/500, step: 1100/19000, loss: 3.42332
[Evaluate] best accuracy performence has been updated: 0.86000 --> 0.89000
[Train] epoch: 476/500, step: 18100/19000, loss: 0.04217
[Evaluate] dev score: 0.88000, dev loss: 0.37585
[Train] epoch: 478/500, step: 18200/19000, loss: 0.04331
[Evaluate] dev score: 0.88000, dev loss: 0.37485
[Train] epoch: 481/500, step: 18300/19000, loss: 0.05118
[Evaluate] dev score: 0.88000, dev loss: 0.37668
[Train] epoch: 484/500, step: 18400/19000, loss: 0.06765
[Evaluate] dev score: 0.88000, dev loss: 0.37357
[Train] epoch: 486/500, step: 18500/19000, loss: 0.03764
[Evaluate] dev score: 0.89000, dev loss: 0.38093
[Train] epoch: 489/500, step: 18600/19000, loss: 0.04673
[Evaluate] dev score: 0.88000, dev loss: 0.38495
[Train] epoch: 492/500, step: 18700/19000, loss: 0.06683
[Evaluate] dev score: 0.88000, dev loss: 0.38080
[Train] epoch: 494/500, step: 18800/19000, loss: 0.05129
[Evaluate] dev score: 0.89000, dev loss: 0.38528
[Train] epoch: 497/500, step: 18900/19000, loss: 0.03119
[Evaluate] dev score: 0.89000, dev loss: 0.38632
[Evaluate] dev score: 0.89000, dev loss: 0.38519
[Train] Training done!
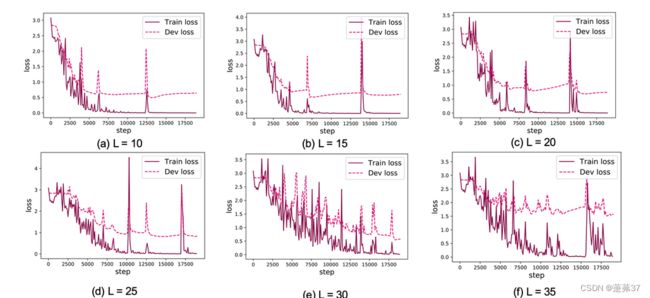
6.3.2.3 损失曲线展示
分别画出基于LSTM的各个长度的数字预测模型训练过程中,在训练集和验证集上的损失曲线,代码实现如下:
# 画出训练过程中的损失图
for length in lengths:
runner = lstm_runners[length]
fig_name = f"./images/6.11_{length}.pdf"
plot_training_loss(runner, fig_name, sample_step=100)
plot_training_loss():
import matplotlib.pyplot as plt
def plot_training_loss(runner, fig_name, sample_step):
plt.figure()
train_items = runner.train_step_losses[::sample_step]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color='#e4007f', label="Train loss")
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color='#f19ec2', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='large')
plt.xlabel("step", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
运行结果:
L=10

L=15

L=20
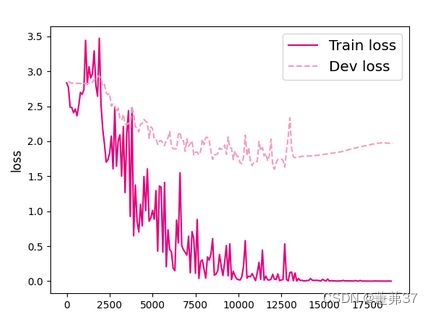
L=25

L=30

L=35
上次实验运行结果:
【思考题1】LSTM与SRN实验结果对比,谈谈看法。
LSTM模型在不同长度数据集上进行训练后的损失变化,同SRN模型一样,随着序列长度的增加,训练集上的损失逐渐不稳定,验证集上的损失整体趋向于变大,这说明当序列长度增加时,保持长期依赖的能力同样在逐渐变弱。LSTM模型在序列长度增加时,收敛情况比SRN模型更好,确率也要优于SRN。因为LSTM的设计就是通过门控机制来解决SRN的长程依赖问题,即随着训练时间的加长以及网络层数的增多,很容易出现梯度爆炸或梯度消失,导致无法处理较长序列数据,从而无法获取长距离数据的信息。
6.3.3 模型评价
6.3.3.1 在测试集上进行模型评价
使用测试数据对在训练过程中保存的最好模型进行评价,观察模型在测试集上的准确率. 同时获取模型在训练过程中在验证集上最好的准确率,实现代码如下:
lstm_dev_scores = []
lstm_test_scores = []
for length in lengths:
print(f"Evaluate LSTM with data length {length}.")
runner = lstm_runners[length]
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"best_lstm_model_{length}.pdparams")
runner.load_model(model_path)
# 加载长度为length的数据
data_path = f"./datasets/{length}"
train_examples, dev_examples, test_examples = load_data(data_path)
test_set = DigitSumDataset(test_examples)
test_loader = DataLoader(test_set, batch_size=batch_size)
# 使用测试集评价模型,获取测试集上的预测准确率
score, _ = runner.evaluate(test_loader)
lstm_test_scores.append(score)
lstm_dev_scores.append(max(runner.dev_scores))
for length, dev_score, test_score in zip(lengths, lstm_dev_scores, lstm_test_scores):
print(f"[LSTM] length:{length}, dev_score: {dev_score}, test_score: {test_score: .5f}")
运行结果:
Evaluate LSTM with data length 20.
Evaluate LSTM with data length 25.
Evaluate LSTM with data length 30.
Evaluate LSTM with data length 35.
[LSTM] length:10, dev_score: 0.77, test_score: 0.77000
[LSTM] length:15, dev_score: 0.8, test_score: 0.82000
[LSTM] length:20, dev_score: 0.73, test_score: 0.76000
[LSTM] length:25, dev_score: 0.4, test_score: 0.31000
[LSTM] length:30, dev_score: 0.88, test_score: 0.88000
[LSTM] length:35, dev_score: 0.89, test_score: 0.82000
6.3.3.2 模型在不同长度的数据集上的准确率变化图
接下来,将SRN和LSTM在不同长度的验证集和测试集数据上的准确率绘制成图片,以方面观察。
import matplotlib.pyplot as plt
plt.plot(lengths, lstm_dev_scores, '-o', color='#e8609b', label="LSTM Dev Accuracy")
plt.plot(lengths, lstm_test_scores,'-o', color='#000000', label="LSTM Test Accuracy")
#绘制坐标轴和图例
plt.ylabel("accuracy", fontsize='large')
plt.xlabel("sequence length", fontsize='large')
plt.legend(loc='lower left', fontsize='x-large')
fig_name = "./images/6.12.pdf"
plt.savefig(fig_name)
plt.show()
运行结果:
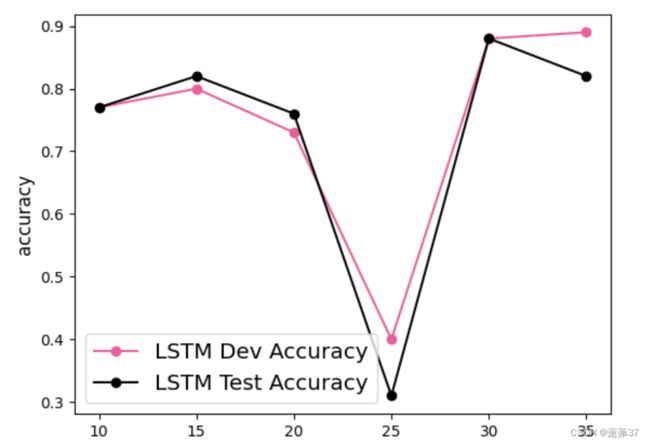
上次实验运行结果:

【思考题2】LSTM与SRN在不同长度数据集上的准确度对比,谈谈看法。
随着数据集长度的增加,LSTM模型和SRN模型的准确率降低,但是LSTM模型的准确率显著高于SRN模型,说明LSTM模型保持长期依赖的能力要优于SRN模型。
1.随着数据集长度的增加,LSTM模型和SRN模型在验证集和测试集上的准确率整体均趋向于降低;
2.LSTM模型的准确率显著高于SRN模型,表明LSTM模型保持长期依赖的能力要优于SRN模型。SRN随着数据集长度的增加,其准确率不断下降,说明SRN对于之前的关键信息已经遗忘,所以造成了准确率不断下降。
6.3.3.3 LSTM模型门状态和单元状态的变化
LSTM模型通过门控机制控制信息的单元状态的更新,这里可以观察当LSTM在处理一条数字序列的时候,相应门和单元状态是如何变化的。首先需要对以上LSTM模型实现代码中,定义相应列表进行存储这些门和单元状态在每个时刻的向量。
# 声明LSTM和相关参数
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, Wi_attr=None, Wf_attr=None, Wo_attr=None, Wc_attr=None,
Ui_attr=None, Uf_attr=None, Uo_attr=None, Uc_attr=None, bi_attr=None, bf_attr=None,
bo_attr=None, bc_attr=None):
super(LSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 初始化模型参数
if Wi_attr==None:
Wi=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wi = torch.tensor(Wi_attr, dtype=torch.float32)
self.W_i = torch.nn.Parameter(Wi)
if Wf_attr==None:
Wf=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wf = torch.tensor(Wf_attr, dtype=torch.float32)
self.W_f = torch.nn.Parameter(Wf)
if Wo_attr==None:
Wo=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wo = torch.tensor(Wo_attr, dtype=torch.float32)
self.W_o =torch.nn.Parameter(Wo)
if Wc_attr==None:
Wc=torch.zeros(size=[input_size, hidden_size], dtype=torch.float32)
else:
Wc = torch.tensor(Wc_attr, dtype=torch.float32)
self.W_c = torch.nn.Parameter(Wc)
if Ui_attr==None:
Ui = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Ui = torch.tensor(Ui_attr, dtype=torch.float32)
self.U_i = torch.nn.Parameter(Ui)
if Uf_attr == None:
Uf = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Uf = torch.tensor(Uf_attr, dtype=torch.float32)
self.U_f = torch.nn.Parameter(Uf)
if Uo_attr == None:
Uo = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Uo = torch.tensor(Uo_attr, dtype=torch.float32)
self.U_o = torch.nn.Parameter(Uo)
if Uc_attr == None:
Uc = torch.zeros(size=[hidden_size, hidden_size], dtype=torch.float32)
else:
Uc = torch.tensor(Uc_attr, dtype=torch.float32)
self.U_c = torch.nn.Parameter(Uc)
if bi_attr == None:
bi = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bi = torch.tensor(bi_attr, dtype=torch.float32)
self.b_i = torch.nn.Parameter(bi)
if bf_attr == None:
bf = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bf = torch.tensor(bf_attr, dtype=torch.float32)
self.b_f = torch.nn.Parameter(bf)
if bo_attr == None:
bo = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bo = torch.tensor(bo_attr, dtype=torch.float32)
self.b_o = torch.nn.Parameter(bo)
if bc_attr == None:
bc = torch.zeros(size=[1,hidden_size], dtype=torch.float32)
else:
bc = torch.tensor(bc_attr, dtype=torch.float32)
self.b_c = torch.nn.Parameter(bc)
# 初始化状态向量和隐状态向量
def init_state(self, batch_size):
hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)
cell_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)
return hidden_state, cell_state
# 定义前向计算
def forward(self, inputs, states=None):
# inputs: 输入数据,其shape为batch_size x seq_len x input_size
batch_size, seq_len, input_size = inputs.shape
# 初始化起始的单元状态和隐状态向量,其shape为batch_size x hidden_size
if states is None:
states = self.init_state(batch_size)
hidden_state, cell_state = states
# 定义相应的门状态和单元状态向量列表
self.Is = []
self.Fs = []
self.Os = []
self.Cs = []
# 初始化状态向量和隐状态向量
cell_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)
hidden_state = torch.zeros(size=[batch_size, self.hidden_size], dtype=torch.float32)
# 执行LSTM计算,包括:隐藏门、输入门、遗忘门、候选状态向量、状态向量和隐状态向量
for step in range(seq_len):
input_step = inputs[:, step, :]
I_gate = F.sigmoid(torch.matmul(input_step, self.W_i) + torch.matmul(hidden_state, self.U_i) + self.b_i)
F_gate = F.sigmoid(torch.matmul(input_step, self.W_f) + torch.matmul(hidden_state, self.U_f) + self.b_f)
O_gate = F.sigmoid(torch.matmul(input_step, self.W_o) + torch.matmul(hidden_state, self.U_o) + self.b_o)
C_tilde = F.tanh(torch.matmul(input_step, self.W_c) + torch.matmul(hidden_state, self.U_c) + self.b_c)
cell_state = F_gate * cell_state + I_gate * C_tilde
hidden_state = O_gate * F.tanh(cell_state)
# 存储门状态向量和单元状态向量
self.Is.append(I_gate.detach().numpy().copy())
self.Fs.append(F_gate.detach().numpy().copy())
self.Os.append(O_gate.detach().numpy().copy())
self.Cs.append(cell_state.detach().numpy().copy())
return hidden_state
接下来,需要使用新的LSTM模型,重新实例化一个runner,本节使用序列长度为10的模型进行此项实验,因此需要加载序列长度为10的模型。
# 实例化模型
base_model = LSTM(input_size, hidden_size)
model = Model_RNN4SeqClass(base_model, num_digits, input_size, hidden_size, num_classes)
# 指定优化器
optimizer = torch.optim.Adam(lr=lr, params=model.parameters())
# 定义评价指标
metric = Accuracy()
# 定义损失函数
loss_fn = torch.nn.CrossEntropyLoss()
# 基于以上组件,重新实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
length = 10
# 加载训练过程中效果最好的模型
model_path = os.path.join(save_dir, f"best_lstm_model_{length}.pdparams")
runner.load_model(model_path)
接下来,给定一条数字序列,并使用数字预测模型进行数字预测,这样便会将相应的门状态和单元状态向量保存至模型中. 然后分别从模型中取出这些向量,并将这些向量进行绘制展示。代码实现如下:
import seaborn as sns
import matplotlib.pyplot as plt
def plot_tensor(inputs, tensor, save_path, vmin=0, vmax=1):
tensor = np.stack(tensor, axis=0)
tensor = np.squeeze(tensor, 1).T
plt.figure(figsize=(16,6))
# vmin, vmax定义了色彩图的上下界
ax = sns.heatmap(tensor, vmin=vmin, vmax=vmax)
ax.set_xticklabels(inputs)
ax.figure.savefig(save_path)
# 定义模型输入
inputs = [6, 7, 0, 0, 1, 0, 0, 0, 0, 0]
X = torch.as_tensor(inputs.copy())
X = X.unsqueeze(0)
# 进行模型预测,并获取相应的预测结果
logits = runner.predict(X)
predict_label = torch.argmax(logits, dim=-1)
print(f"predict result: {predict_label.numpy()[0]}")
# 输入门
Is = runner.model.rnn_model.Is
plot_tensor(inputs, Is, save_path="./images/6.13_I.pdf")
# 遗忘门
Fs = runner.model.rnn_model.Fs
plot_tensor(inputs, Fs, save_path="./images/6.13_F.pdf")
# 输出门
Os = runner.model.rnn_model.Os
plot_tensor(inputs, Os, save_path="./images/6.13_O.pdf")
# 单元状态
Cs = runner.model.rnn_model.Cs
plot_tensor(inputs, Cs, save_path="./images/6.13_C.pdf", vmin=-5, vmax=5)
运行结果:
输入门:
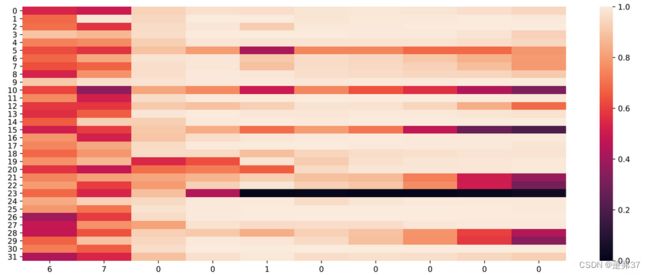 输出门:
输出门:
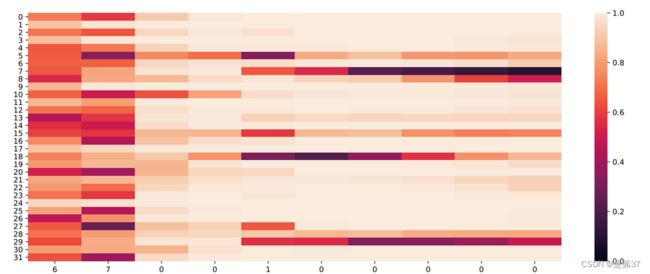
遗忘门:
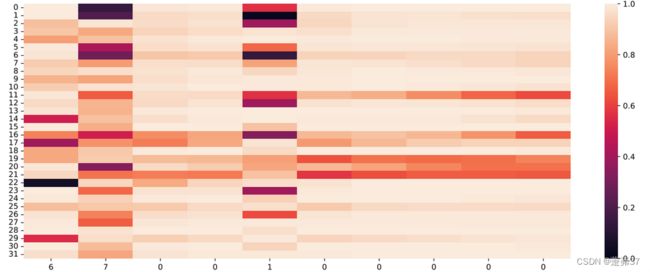
单元状态:

【思考题3】分析LSTM中单元状态和门数值的变化图,并用自己的话解释该图。
色阶图中,横坐标为输入数字,纵坐标为相应门或单元状态向量的维度,颜色的深浅表示数值的大小。可以看到,输入门大小为0时,颜色差不多相近大小近似一致,表明对于0元素进行过滤,过滤掉不需要的信息,避免输入信息的变化给当前模型带来困扰;当遗忘门遇到数字1后,遗忘门数值在一些维度上变小,表明对某些信息进行了遗忘;随着序列的输入,输出门和单元状态在某些维度上数值变小,在某些维度上数值变大,表明输出门在根据信息的重要性选择信息进行输出,同时单元状态也在保持着对文本预测重要的一些信息。
全面总结RNN
总结
通过本次实验,我更加理解了LSTM的原理和LSTM记忆能力,同时LSMT还可以调整输入对某些不重要的信息进行遗忘。我们也对SRN和LSTM也进行了对比,发现了LSTM相对于SRN对于时间序列的强大的记忆功能。随着序列的输入,输出门和单元状态在某些维度上数值变小,在某些维度上数值变大,表明输出门在根据信息的重要性选择信息进行输出,同时单元状态也在保持着对文本预测重要的一些信息。本次实验收获很多,对于LSTM的理解更加深刻了。
参考链接
老师博客
8. 循环神经网络 — 动手学深度学习 2.0.0-beta1 documentation (d2l.ai)