CVPR代码复现(ML-GCN论文阅读以及Keras(多标签分类)代码实现)
1.前言及初衷
在ML-GCN论文中,作者指出传统卷积特征中缺乏了标签信息,因此利用GCN来生成标签信息,并将标签信息叠加到视觉特征中,来提升多标签分类的结果。由于在实验中用的数据集是自建数据集,这些数据集无法分享给大家,本文只给大家分享代码。由于Keras的便利性,相信很多人都会使用这个库,但是Keras由于封装性太强,可能很多人都不会利用该库去完成一些比较特殊的任务,本文只是给大家提供一种利用Keras来完成特殊任务的思路,希望可以对大家日后的工作和学业有所帮助。
2.论文分析及其代码编写
2.1 神经网络构建
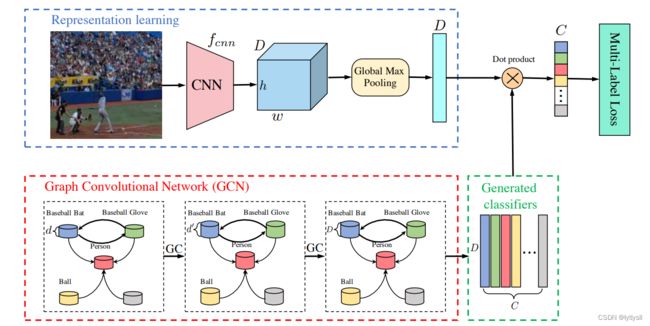
在论文中,作者提到他们的神经网络结构,神经网络的左侧是2层图卷积,右侧是传统的CNN网络结构,可以是任何神经网络,如ResNet、VGGNet、AleaxNet等。整体神经网络框架比较简单,在有了这些信息后就可以构建神经网络了,model.py内容如下:
def Conv_LeakyReLU(inputs,filters,kernel_size,strides=1):
x=Conv2D(filters=filters,kernel_size=kernel_size,strides=strides,padding="same")(inputs)
x=Dropout(0.5)(x)
x=BatchNormalization()(x)
x=LeakyReLU(0.2)(x)
return x
def GraphConv_LeakyReLU(inputs,units,support=1):
x=GraphConvolution(units=units,support=support)(inputs)
x=LeakyReLU(0.2)(x)
return x
def ML_GCN(inputs_shape1, inputs_shape2,inputs_shape3,num_class):
inputs1 = Input(inputs_shape1,name="image")
inputs2 = Input(inputs_shape2,name="word_embding")
inputs3=[Input(inputs_shape3,name="adj_martix")]
inputs4=Reshape((7,7))(inputs3[0])
x1 = Conv_LeakyReLU(inputs=inputs1, filters=128, kernel_size=3, strides=2)
x1 = Conv_LeakyReLU(inputs=x1, filters=256, kernel_size=3,strides=2)
x1 = Conv_LeakyReLU(inputs=x1, filters=512, kernel_size=3, strides=2)
x1 = Conv_LeakyReLU(inputs=x1, filters=1024, kernel_size=3,strides=2)
x1 = GlobalMaxPooling2D()(x1)
x2=Dropout(0.5)(inputs2[0])
x2=GraphConv_LeakyReLU(inputs1=[x2]+[inputs4[0]],units=512)
x2=Dropout(0.5)(x2)
x2 = GraphConv_LeakyReLU(inputs1=[x2]+[inputs4], units=1024)
x2=Permute((2,1))(x2)
x=Lambda(lambda x:tf.matmul(x[0],x[1]))([x1,x2])
x=GlobalMaxPooling1D()(x)
x=Activation("sigmoid")(x)
x = Model(inputs=[inputs1,inputs2]+inputs3, outputs=x)
return x
上述代码中Conv_LeakyReLU函数是将Conv和LeakyReLU做了简单的封装,GraphConv_LeakyReLU函数是将GCN和LeakyReLu做了简单的封装,而ML_GCN就是这篇论文的主要结构了。
在ML_GCN的代码中,我们可以看到有3个输入分别是图片、词向量和邻接矩阵。代码中的x1对应的是论文中右侧的CNN网络,在这里就简单用了4层CNN。本次实验使用的图片大小为*(224,224,3),在经过GMP层之前,卷积层输出的Tensor形状为(14,14,1024),在经过GMP层后,输出Tensor形状为(None,1024).
代码中x2对应的是论文中左侧的GCN网络,在这里仅用了2层GCN*。由于原论文中使用的是coco数据集,输入的词向量的形状为*(80,300),邻接矩阵的形状为(80,80),在经过GCN后输出的Tensor形状为(None,80,1024).在论文中,这个地方困扰了我很久,为什么将CNN特征和GCN特征进行矩阵相乘就是我们最终的分类器,其实也很简单,大家只需要将CNN输出Tensor形状想象成(1,1024),GCN输出Tensor形状想象成(80,1024),那很自然的就可以想到只需要将GCN输出Tensor形状进行转置,(1024,80),然后再将CNN特征和GCN特征进行矩阵乘法就可以得到(1,80)的Tensor*,即我们的分类器。所以在代码中,两个GCN层后,将特征转置,然后进行矩阵乘法,此时得到的Tensor形状为*(None,None,80),此时在经过一个GMP1D降维,然后在经过sigmoid激活函数即可,至此,神经网络结构搭建完成。
Note: 这里面Reshape((7,7))是因为自建数据集只有7个类,而论文中使用的coco数据集有80,就要将它写成Reshape((80,80))*
2.2 词向量和邻接矩阵构建
由于论文中使用的是由Glove训练好的词向量,只需要在网上将Glove词向量下载即可,然后将对应的类别取出写入新的txt文件即可。在这里不在赘述,后续仔细讲讲邻接矩阵的构建,论文中的邻接矩阵其实就是一个共现矩阵,记录了各个标签之间的共现情况,且对角线为0,因为每一个标签不会和自身共现。若直接使用该矩阵会出现问题,因此需要对该矩阵进行特殊的处理,具体处理方式如下:
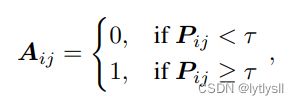
上式中,t为阈值,也就是说当共现矩阵中的值小于阈值时,将它设置为0,大于等于阈值时,将它设置为1,在论文中t为0.4,我们也将其设置为0.4核心代码如下:
file=open(r"ad_matrix\ad_martix.txt")
file_list=file.readlines()
length=len(file_list)
to_martix=np.zeros((length,7))
index=0
file=open(r"ad_matrix\ad_martix.txt")
thshold=0.4
p=0.25
for data in file.readlines():
data = data.strip('\n')
nums = data.split(" ")
x_nums=[]
for x in nums:
if float(x) <thshold:
x=0
else:
x=1
x_nums.append(float(x))
to_martix[index,:] = x_nums[:]
index +=1
print(to_martix)
print(type(to_martix))
在上述代码中,读出的txt文件,是已经构建好的共现矩阵,大家可以根据自己的数据集写好脚本,下面这段循环就将分段函数做的事情做完了。此时的矩阵理论上就可以投入应用了,但是作者指出这个矩阵还会产生平滑问题,会影响性能,因此需要对其进行重参数化,重参数方案如下:
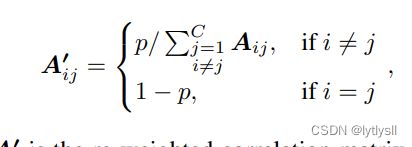
根据这个重参数方案写出代码即可,核心代码如下:
adj=to_martix*p/(to_martix.sum(0,keepdims=True)+1e-6)
adj=adj+np.identity(7,np.int)
print("adj",adj)
到此论文中构建共现矩阵的方案已经结束了,这个矩阵已经可以作为GCN的邻接矩阵使用。我们也可以对其进一步进行操作,方案如下:

根据上述公式可写出代码:
D=np.power(adj.sum(1),-0.5)
D=np.diag(D)
adj_martix=np.matmul(np.matmul(D,adj),D)
至此,邻接矩阵构建完毕,那么整理下creat_adj_martix.py的内容,整体内容如下:
file=open(r"ad_matrix\ad_martix.txt")
file_list=file.readlines()
length=len(file_list)
to_martix=np.zeros((length,7))
index=0
file=open(r"ad_matrix\ad_martix.txt")
thshold=0.4
p=0.25
for data in file.readlines():
data = data.strip('\n')
nums = data.split(" ")
x_nums=[]
for x in nums:
if float(x) <thshold:
x=0
else:
x=1
x_nums.append(float(x))
to_martix[index,:] = x_nums[:]
index +=1
print(to_martix)
print(type(to_martix))
adj=to_martix*p/(to_martix.sum(0,keepdims=True)+1e-6)
adj=adj+np.identity(7,np.int)
print("adj",adj)
D=np.power(adj.sum(1),-0.5)
D=np.diag(D)
adj_martix=np.matmul(np.matmul(D,adj),D)
print(to_martix)
print(adj_martix)
np.save("final_maritx.npy",adj_martix)
我自建数据集的邻接矩阵输出为:
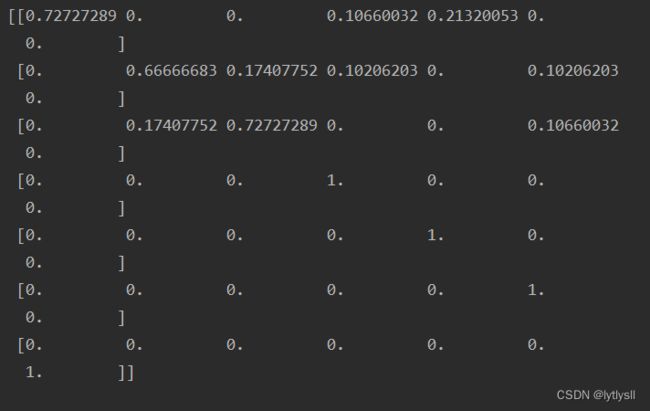
该邻接矩阵包含了所有标签(节点)的特征,可以利用该矩阵进行GCN的训练了。
### 2.3 数据读取器的建立
由于本人比较懒,想使用Keras内置的API进行模型的训练,那么就需要根据Keras内置的格式来编写数据生成器,data_generator.py内容如下:
class DataGenerator(Sequence):
def __init__(self, list_IDs, batch_size=1, img_size=(224, 224), *args, **kwargs):
"""
self.list_IDs:存放所有需要训练的图片文件名的列表。
"""
self.list_IDs = list_IDs
self.batch_size = batch_size
self.img_size = img_size
self.on_epoch_end()
def __len__(self):
return int(math.ceil(len(self.list_IDs) / self.batch_size))
def __getitem__(self, index):
indices = self.indices[index * self.batch_size:(index + 1) * self.batch_size]
list_IDs_temp = [self.list_IDs[k,] for k in indices]
image,word_embding,adj_martix,label = self.__data_generation(list_IDs_temp)
return {"image":image,"word_embding":word_embding,"adj_martix":adj_martix},label
def on_epoch_end(self):
self.indices = np.arange(len(self.list_IDs))
np.random.shuffle(self.indices)
def __data_generation(self, list_IDs_temp):
X = np.empty((self.batch_size, *self.img_size, 3))
Y = np.empty((self.batch_size, 7), dtype=np.float32)
word_embding=np.empty((self.batch_size,7,300),dtype=np.float32)
adj_matrix = np.load("ad_matrix/final_maritx.npy")
adj_matrix=adj_matrix.reshape((49,))
new_adj_matrix=np.empty((self.batch_size,49,))
for i,x in enumerate(list_IDs_temp):
X[i,]=cv2.imread(x[0])
label=np.zeros((7,))
for j in x[1:-1]:
if j!="NULL":
label[int(j)]=1
Y[i,]=label
graph_feature = np.load(x[-1])
word_embding[i,]=graph_feature
new_adj_matrix[i,]=adj_matrix
X=X/255
return X,word_embding,new_adj_matrix,Y
由于我们的任务需要输入3个量,那么我们就需要重写数据生成器,使其可以回传4个值*(图像数据,词向量,邻接矩阵,标签)。其中__data_generation*方法是用来生成batch数据的,on_epoch_end方法是用来打乱数据顺序的, *getitem*方法是用来将数据传入model.fit()中的核心方法,回传了4个值,且前3个神经网络的输入要用大括号连接且神经网络输入层的名字要与回传字典中的名字一致。
### 2.4 模型的训练
在所有准备工作都做好后就可以开始对模型进行训练了,train.py内容如下所示:
os.environ["CUDA_VISIBLE_DEVICES"]="0"
if __name__ == "__main__":
batch_size=2
# 模型保存的位置
log_dir = "./logs/"
# 打开数据集的txt
with open(r"train\train4.txt","r") as f:
lines = f.readlines()
data_list=[]
for i in range(len(lines)):
data_list.append(lines[i].strip("\n").split(" "))
data_list=np.array(data_list)
data_list=data_list.reshape((len(lines),5))
# 90%用于训练,10%用于估计
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
model = ML_GCN(inputs_shape1=(224,224,3),inputs_shape2=(7,300),inputs_shape3=(49,),num_class=7)
print(model.summary())
# 保存的方式,3代保存一次
checkpoint_period = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
save_best_only=True,
period=3
)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
model.compile(loss = 'categorical_crossentropy',
optimizer = SGD(lr=1e-3,momentum=0.9),
metrics = ['accuracy'])
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
train_generator = DataGenerator(data_list[:num_train], batch_size)
varl_generator = DataGenerator(data_list[num_train:], batch_size)
history=model.fit(train_generator,
steps_per_epoch=max(1, num_train // batch_size),
validation_data=varl_generator,
validation_steps=max(1, num_val // batch_size),
epochs=100,
initial_epoch=0,
callbacks=[checkpoint_period, reduce_lr,early_stopping],
verbose=1)
model.save_weights(log_dir + 'last1.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, ls='-', color='purple', lw=1, label='Training accuracy')
plt.plot(epochs, val_acc, ls='-', color='red',lw=1, label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, ls='-', color='purple', lw=1,label='Training loss')
plt.plot(epochs, val_loss, ls='-', color='red', lw=1,label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
上述代码中值得重点说一下的是,train.txt的内容,这里面的内容为*(图像路径,标签1,标签2,…,标签n,词向量路径),*为了直观给大家展示里面的情况,给大家截了一下里面的内容,内容如下:

上述代码中剩下的写法都与Keras训练其他任务一致,都是比较套路性的写法。
3.总结及可应用环境
本人使用的tensorflow版本为2.4,tensorflow-gpu版本为2.4,显卡为3060。写这篇文章也是为了记录这次复现CVPR代码的过程以及主要踩坑的地方,并在此总结。由于本人很喜欢用Keras来完成各种任务,因此本次使用Keras来完成这篇论文代码的编写,但是Keras封装性太好,导致此库可扩展性差,希望这篇文章可以帮助大家来利用Keras来构建多标签任务,在本人整理完项目后,会将该项目放入自己的github上,希望大家可以多多关注!最后,若是这篇文章有些错的地方,也希望大家指正!谢谢大家!