从自监督到全监督!Google 提出新损失函数SupCon,准确率提升2%!
转自新智元
来源:Google AI Blog
编辑:LRS
【导读】监督学习中一个重要的模块就是损失函数了,而最常见的损失函数就是交叉熵了。Google在NIPS2020上提出了一个损失函数SupCon,只需换掉交叉熵,准确率立刻提升2%,快来了解一下吧!
近年来,由于对比学习的应用,自监督表征(self-supervised representation learning)学习在各种图像和视频任务中得到了显著的发展。
对比学习方法通常指导模型在嵌入空间中将目标图像(anchor)和匹配图像(positive)的表征结合起来,同时将anchor从许多非匹配图像(即negative图像)中分离出来。
这种操作基于一个假设,即标签在自监督学习过程中是不可用的,positive图像通常是一个anchor的数据增强,negative图像通常从minbatch的训练中选取。
然而,由于这种随机抽样,false negatives(negative图像是从anchor同一类样本中生成的)会导致表征质量的下降。
此外,如何确定最佳的方法产生positive的图像仍然是一个有挑战性的研究领域。
与自监督的方法相反,全监督(fully-supervised)的方法可以使用标记数据从现有的同类示例中生成positive图像,与通常仅仅增加anchor所能达到的效果相比,提供了更多的预训练可变性。然而,对比学习在全监督领域的成功应用还很少。
在 NeurIPS 2020展示的“Supervised Contrastive Learning”中,Google Research提出了一种新的损失函数,称为 SupCon,它弥补了自监督学习和完全监督式学习学习之间的差距,并使对比学习能够应用于监督环境。

通过利用标记数据,SupCon 鼓励将来自同一类的规范化嵌入拉得更近,而将来自不同类的嵌入拉得更远。这简化了positive图像选择的过程,同时避免了潜在的错误否定。
由于每个anchor可以容纳多个positive示例,这种方法可以改进正面示例的选择,这些示例更加多样化,同时仍然包含语义相关的信息。
SupCon还允许标签信息在表征学习中发挥积极作用,而不是像传统的对比学习那样仅限于在下游训练中使用。
研究团队声称,这是第一次使用对比损失在大规模图像分类问题上比常见的使用交叉熵损失训练模型方法要更好。更重要的是,SupCon易于实现,训练稳定,对一些数据集和体系结构(包括Transformer类模型)的 top-1精度提供了一致的改进,并且对图像损坏和超参数变化具有鲁棒性。
对比损失: 自我监督的对比损失即对比每个anchor(即同一图像的增强版)一个positive样例与一组negative样例,后者包括整个minibatch的剩余部分。
然而,本文中考虑的监督对比损失,将来自同一类别的所有样本作为正的样本集与来自同一个batch剩余样本的负的样本集进行对比学习。

有监督的对比学习框架
监督式对比学习框架支持系统可以看作是 SimCLR 和 N-pair 损失的一般化形式,前者使用与anchor程序相同的样本产生的positive样本,后者利用已知类标签从不同样本产生的positive样本。
对每个anchor使用大量的positive和negative样本,使之能够达到sota性能,而不需要hard negative mining(即寻找类似anchor点的负样本挖掘) ,可能难以调参。

这种方法在结构上类似于自监督对比学习,只是改进了监督分类。给定一个输入批数据,我们首先应用数据扩展两次,以获得该批数据中每个样本的两个副本或“视图”(尽管可以创建和使用任意数量的扩展视图)。
两个副本通过编码器网络进行前向传播,最终嵌入到 l2标准化。根据标准实践,通过可选的投影网络进一步传播该表示,以帮助识别有意义的特性。对于投影网络的归一化输出,计算有监督的对比损失。
锚的正面包括来自与锚相同的批处理实例的表示,或者来自与锚相同标签的其他实例的表示; 负面则包括所有其余实例。为了测量下游任务的性能,固定上游向量表示后,在上面训练一个线性分类器。

在 CIFAR-10和 CIFAR-100以及 ImageNet 数据集上,与交叉熵、边缘分类器(使用标签)和自监督对比学习技术相比,SupCon都能够提高了top1的准确率。
通过使用 SupCon,在使用 ResNet-50和 ResNet-200架构的 ImageNet 数据集上实现了极好的1级精度。

在 ResNet-200上,实现了81.4% 的top1准确率,这比使用同一架构的最先进的交叉熵损失提高了0.8% (这对 ImageNet 来说是一个重大进步)。
除此之外,还比较了基于 transformer 的 ViT-B/16模型中的交叉熵和支持熵,发现在相同的数据增强机制下(没有任何更高分辨率的微调) ,交叉熵有一致的改善(ImageNet 为77.8% 对76% ,CIFAR-10为92.6% 对91.6%)。

我们还分析论证了损失函数的梯度鼓励我们从硬正面和硬负面中学习。来自硬正/负的梯度贡献很大,而那些容易正/负的梯度贡献很小。这种隐性特性使得对比损失可以避开显性硬挖掘的需要,而显式的hard mining是许多损失中微妙但关键的一部分,如triplet损失。
在论文的补充材料种有完整的推导过程。
对于噪声、模糊和 JPEG 压缩等自然的破坏,SupCon系统也更具有鲁棒性。与基准 ImageNet-C 数据集相比,平均损坏错误(mean Corruption Error, mCE)度量了性能的平均降低程度。
与交叉熵模型相比,SupCon模型在不同损坏情况下的最小均方误差(mCE)值较低,显示出更强的鲁棒性。
同时,通过实验证明,在一定的超参数范围内,支持熵损失的敏感性小于交叉熵损失。
通过增强、优化和学习率的变化,我们观察到对比损失的输出方差显著降低。此外,在保持所有其他超参数不变的情况下,应用不同的批量大小,可以使得在每个批量大小时,SupCon的 top-1精度始终比 cross-entropy 的精度高。
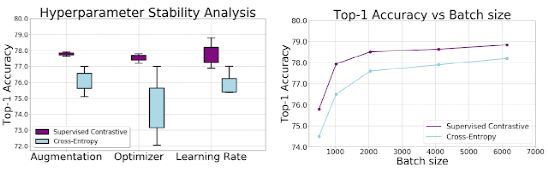
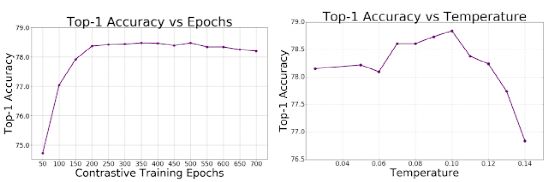
这项工作提供了在监督分类领域的技术进步。有监督的对比学习可以以最小的复杂度提高分类器的准确性和鲁棒性。经典的交叉熵损失可以看作是一个特殊的情况下,视图对应的图像和学习嵌入在最终的线性层对应的标签。
可以注意到,SupCon从大的batch size中获益更多,如何能够在小batch中训练模型也是未来研究的一个重要课题。
文中涉及的代码已经上传在了github上。

参考资料:https://ai.googleblog.com/2021/06/extending-contrastive-learning-to.html

备注:自监督

自监督/无监督学习交流群
关注最新最前沿的自监督、无监督学习技术,
若已为CV君其他账号好友请直接私信。
