Xilinx-Verilog-学习笔记(17):异步并口通信
Xilinx-Verilog-学习笔记(17):异步并口通信
一、异步并口通信
1、异步并口应用
CPU类的芯片与FPGA的数据交互,数据速率一般在100Mbps之内,数据总线不大于16bit。
非CPU类的功能芯片与FPGA通过并口进行数据交互,譬如配置寄存器等。
2、并口信号说明
Chip select: 片选信号,简写为cs_n,此信号低有效,当被拉低时表示此器件的并口被激活。
Write enable: 写使能信号,简写为we_n,此信号低有效,当被拉低时表示此时地址总线和数据总线的地址数据是写入操作的。
Read enable: 读使能信号,简写为rd_n,此信号低有效,当被拉低时表示此时地址总线和数据总线的地址和数据是读取操作的。
Addr[7:0]: 地址总线,表示读写的地址。
Data[15:0]: 数据总线,此总线是双向总线,读操作时数据总线上是读取的数据,而写操作时数据总线上是写入的数据。
3、写操作时序图

【补充知识点:建立时间和保持时间】
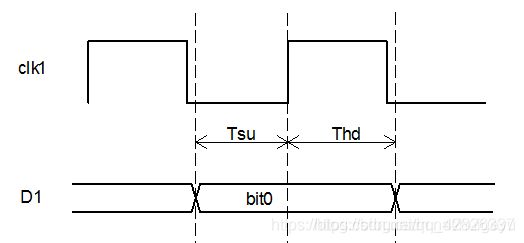
建立时间(Tsu):时钟上升沿到来之前,输入端数据已经到来并稳定持续的时间间隔。
保持时间(Thd):时钟上升沿到来之后,输入端数据继续保持稳定并持续的时间间隔。
Tsu、Thd、Tclk三者的数学关系:Tsu+Thd=Tclk.
这里setup time为建立时间,hold time为保持时间。
当片选信号和写使能信号都拉低后,开始数据的写入。
4、读操作时序图
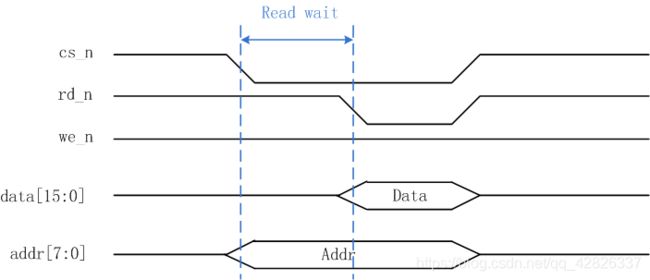
当片选信号和读使能信号都拉低后,开始读取数据。
二、verilog代码实现
1、design文件
跨时钟域问题分析
由于异步时序设计指的是在设计中有两个或以上的时钟, 且时钟之间是同频不同相或不同频率的关系。而异步时序设计的关键就是把数据或控制信号正确地进行跨时钟域传输。
每一个触发器都有其规定的建立(setup)和保持(hold)时间参数, 在这个时间参数内, 输入信号在时钟的上升沿是不允许发生变的。 如果在信号的建立时间中对其进行采样, 得到的结果将是不可预知的,即亚稳态。
处理跨时钟域的数据有单bit和多bit之分,而打两拍的方式常见于处理单bit数据的跨时钟域问题。打两拍本质就是定义两级寄存器对数据进行延拍。
module parall_interf(
input wire sclk,
input wire rst_n,
input wire cs_n,
input wire rd_n,
input wire wr_n,
inout tri [15:0] data,
input wire [7:0] addr
);
reg [15:0] data_0,data_1,data_2,data_3,
data_4,data_5,data_6,data_7;//8个16bit的寄存器组
reg [2:0] cs_n_r,rd_n_r,wr_n_r;
reg [47:0] data_r;
reg [23:0] addr_r;
reg [15:0] rdata;
//降低亚稳态出现的概率把cs_n rd_n wr_n;单比特信号打两拍
always @(posedge sclk or negedge rst_n)
if(rst_n == 1'b0)
{cs_n_r,rd_n_r,wr_n_r} <= 9'h1ff;
else
{cs_n_r,rd_n_r,wr_n_r} <= {{cs_n_r[1:0],cs_n},{rd_n_r[1:0],rd_n},{wr_n_r[1:0],wr_n}};
always @(posedge sclk or negedge rst_n)
if(rst_n == 1'b0)begin
data_r <= 48'd0;
addr_r <= 24'd0;
end
else begin
data_r <= {data_r[31:0],data};
addr_r <= {addr_r[15:0],addr};
end
//写
always @(posedge sclk or negedge rst_n)
if(rst_n == 1'b0) begin
data_0 <= 8'd0;
data_1 <= 8'd0;
data_2 <= 8'd0;
data_3 <= 8'd0;
data_4 <= 8'd0;
data_5 <= 8'd0;
data_6 <= 8'd0;
data_7 <= 8'd0;
end
else if(cs_n_r[2] == 1'b0 && rd_n_r[2] == 1'b1 && wr_n_r[2] == 1'b0) begin
case(addr_r[23:16])
8'd0:data_0 <= data_r[47:32];
8'd1:data_1 <= data_r[47:32];
8'd2:data_2 <= data_r[47:32];
8'd3:data_3 <= data_r[47:32];
8'd4:data_4 <= data_r[47:32];
8'd5:data_5 <= data_r[47:32];
8'd6:data_6 <= data_r[47:32];
8'd7:data_7 <= data_r[47:32];
default: begin
data_0 <= data_0;
data_1 <= data_1;
data_2 <= data_2;
data_3 <= data_3;
data_4 <= data_4;
data_5 <= data_5;
data_6 <= data_6;
data_7 <= data_7;
end
endcase
end
//读
always @(posedge sclk or negedge rst_n)
if(rst_n == 1'b0)
rdata <= 'd0;
else if(cs_n_r[2] == 1'b0 && wr_n_r[2] == 1'b1)begin
case(addr_r[23:16])
8'd0:rdata <= data_0;
8'd1:rdata <= data_1;
8'd2:rdata <= data_2;
8'd3:rdata <= data_3;
8'd4:rdata <= data_4;
8'd5:rdata <= data_5;
8'd6:rdata <= data_6;
8'd7:rdata <= data_7;
default:rdata <= 16'd0;
endcase
end
//三态门
assign data=(cs_n_r[2] == 1'b0 && rd_n_r == 1'b0)?rdata:16'hzzzz;
endmodule
在design文件中对信号以及数据全部做了打两拍处理。定义了8个16bit位宽的数据用于8路并行读写。
2、testbench文件
`timescale 1ns/1ns
module tb_parall_interf();
parameter setup_time=2;
parameter hold_time=2;
parameter data_time=4;
parameter read_wait=2;
reg sclk;
reg rst_n;
reg cs_n,rd_n,wr_n;
reg [15:0] data;
reg [7:0] addr;
tri [15:0] w_data;
initial begin
sclk = 0;
rst_n = 0;
#200
rst_n = 1;
end
initial begin
cs_n=1;
rd_n=1;
wr_n=1;
data=0;
addr=0;
@(posedge rst_n);
#100;
write_data();
#100;
read_data();
end
always #10 sclk = ~sclk;
//测试激励的三态门
assign w_data = (wr_n==1'b0)?data:16'hzzzz;
//写数据任务
task write_data();
integer i;
begin
for(i=0;i<8;i=i+1)
begin
cs_n=0;
data=i[15:0];
addr=i[7:0];
setup_dly();
wr_n=0;
data_dly();
wr_n=1;
hold_dly();
//cs_n=1;
end
cs_n=1;
end
endtask
//读数据任务
task read_data();
integer i;
begin
for(i=0;i<8;i=i+1)
begin
cs_n=0;
addr=i[7:0];
read_dly();
rd_n=0;
data_dly();
$display("read data addr is %d = %d",i,w_data);
rd_n=1;
end
cs_n=1;
end
endtask
parall_interf parall_interf_inst(
.sclk (sclk),
.rst_n (rst_n),
.cs_n (cs_n),
.rd_n (rd_n),
.wr_n (wr_n),
.data (w_data),
.addr (addr)
);
//基本的延时任务
task setup_dly();
integer i;
begin
for(i=0;i<setup_time;i=i+1)
begin
@(posedge sclk);
end
end
endtask
task hold_dly();
integer i;
begin
for(i=0;i<hold_time;i=i+1)
begin
@(posedge sclk);
end
end
endtask
task data_dly();
integer i;
begin
for(i=0;i<data_time;i=i+1)
begin
@(posedge sclk);
end
end
endtask
task read_dly();
integer i;
begin
for(i=0;i<read_wait;i=i+1)
begin
@(posedge sclk);
end
end
endtask
endmodule
通过写task的方式来定义延时函数,譬如要使得建立时间保持2个时钟周期,那么通过执行两次 @(posedge sclk) 的方式来实现。
对于读任务来说,每次读取数据时,先将cs_n拉低,然后等到读等待时间完成后,将rd_n拉低,实现数据读取。
对于写任务来说,每次写数据时,先将cs_n拉低,然后等满足建立时间后,将we_n拉低,实现数据写入,然后将we_n拉高完成写入,并在之后要具有一段保持时间以保证数据写入的可靠性。
3、do文件
quit -sim
.main clear
vlib work
vmap work work
vlog ./tb_parall_interf.v
vlog ./../design/parall_interf.v
vsim -voptargs=+acc work.tb_parall_interf
add wave tb_parall_interf/parall_interf_inst/*
run 1us
4、仿真实现
(1)打两拍

为了降低跨时钟域出现的亚稳态概率,这里将所有信号进行了打两拍处理。所谓打两拍就是将信号延迟2个时钟周期,由于原信号不能直接进行延迟,所以这里定义了新的信号,并通过移位寄存器的方式来实现。譬如对cs_n信号进行打两拍处理,将其赋值给cs_n_r寄存器,并通过一个时钟周期移1位的方式,判断最高位实现延时效果。
(2)整体功能


首先进行写操作,按照地址顺序将数据写入到data_0到data_7,然后再按照地址顺序将data_0到data_7中的数据一个一个读到rdata中。
(3)写数据
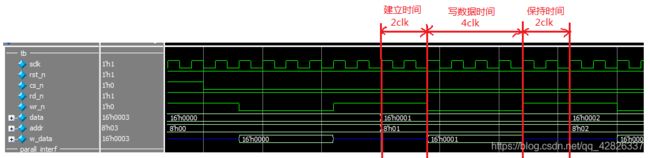
首先经历2个时钟周期的建立时间,然后将wr_n信号拉低,开始写入数据,将data中的内容写到w_data中,写入数据的时间持续4个时钟周期,写完毕后将wr_n信号拉高完成写数据,为了保证写入的准确性,有2个时钟周期的保持时间。在这一大段时间内,data值一直为1,从而确保w_data不会写入前面的0或后面的2。
(4)读数据

首先经历2个时钟周期的读等待时间,这段时间用来等待上一次读完并且下一次读准备好。然后就是4个时钟周期的读,将地址对应的data读出来。这一大段时间对应的地址都为4,从而确保读出数据的准确性。