伯乐:一个易用、强大的PyTorch推荐系统开源库

是否还在为推荐模型无法复现而怀疑人生?是否还在为不知如何入门推荐而踌躇不前?是否还在为数据处理纷繁复杂而不知所措?
赶紧来看看这个新发布的推荐算法框架吧!

RecBole (中文名称:"伯乐",意取"世有伯乐,然后有千里马"),由中国人民大学的 AI Box 团队与北京邮电大学、华东师范大学的科研团队联合开发出品。
该框架实现了推荐领域不同任务的推荐模型,拥有从数据处理、模型开发、算法训练到科学评测的一站式全流程托管。
在 RecBole 框架中,用户只需设置几个简单的配置参数(文件、命令行、运行时参数多种方式任你选择)即可快速在不同数据集上实现各个模型,同时其简洁的开发接口十分方便相关的研究人员进行二次开发和添加新的模型支持。此框架目前已经开源了代码和相应论文。
话不多说,直接来看功能!我们支持:
53 种模型(绝大部分为最新的深度学习模型)
27 个数据集合(涵盖了四种任务下最常用的实验数据集合)
多种评测方式(涵盖所有主流的评测方式,支持一键设置)
自动调参(内嵌实用超参搜索算法,支持灵活设置范围)
这个工具包可以满足大部分推荐相关的科研需求。
"伯乐"推荐系统库将承诺持续开发维护,保持版本稳定,同时不断规划更多实用、强大的功能。

论文地址:
https://arxiv.org/abs/2011.01731
项目主页地址:
https://recbole.io
项目Github地址:
https://github.com/RUCAIBox/RecBole
项目交流邮件组:
框架介绍
RecBole 框架具有五大核心特色。
1. 基于PyTorch的统一模型框架
RecBole 在设计上尽可能的简化了推荐模型的开发难度,将最简洁、方便的开发使用接口暴露给用户,整个框架基于 Python 进行开发,尽最大可能避免繁杂的版本依赖和环境配置,让使用者真正专注于模型的开发和测试中。与其他的功能相近的框架相比,此框架只需在 Python 下一键安装即可享受最完整的模型和数据集支持。
2. 高度灵活及拓展性强的数据结构
数据方面,此框架为完全托管模式,用户只需要将原始数据以规定格式给出(或使用提供的脚本进行处理),再进行简洁的参数配置,便可以由框架自动实现对数据的清洗、分割、准备,同时将每一步所需的数据以用户友好的方式打包,用户只需要关注模型中的前向数据流即可完成新模型的开发和评测。
在本框架中,整体的数据流为:Raw Input →Atomic Files →Dataset → Dataloader → Algorithms 。其中对于原始数据的管理基于 Pandas 实现,支持各类筛选和切割方式,用户可以直接对高层训练数据进行操作而将底层数据处理完全托管给框架解决。在整个的数据流中,本框架新设计了两种数据格式,下面将一一详细介绍。
本框架基于 torch.Tensor 数据类型进一步设计了一个内部数据结构 Interaction,此结构可以看作是一个由 Tensor 组成的字典,用户可以直接通过特征名来得到一个 Batch 的数据,直接喂给模型进行训练,同时可以如 Tensor 一样调用各类方法来定制化。

除此之外,为了实现对各个数据集的统一管理、统一使用,本框架中制定了一个新的数据存储格式,能够支持所有常用数据集并实现高效的存储和加载,共包含可选的 6 种文件类型,和 4 种数据类别。对于用户私有的数据集,只需处理为此文件格式即可自动在本框架下进行数据管理。
目前 RecBole 支持 6 种原子文件,他们通过后缀名进行区分。
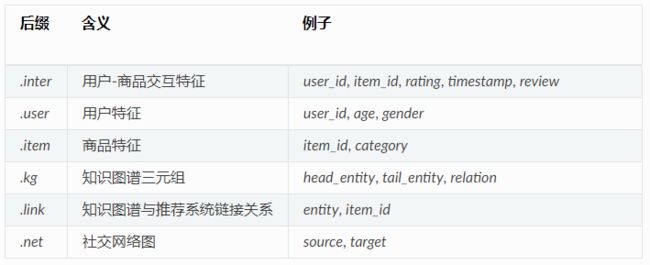
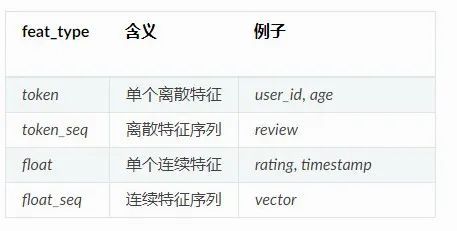
每个原子文件可以被看作 m 行 n 列的表格(不计表头),代表该文件存储了 n 种不同的特征,共 m 条记录。文件第一行为表头,表头中每一列的形式为 feat_name:feat_type,标示了该列特征的名字及类型。约定特征为四种类型之一,他们都可以被方便地转化为按 batch 组织的张量。
3. 丰富的模型和数据集
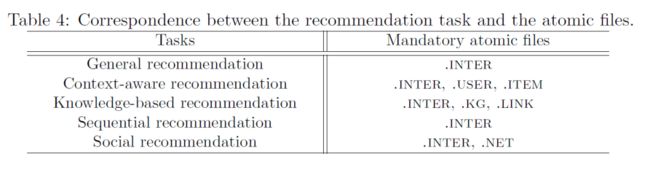
目前研究中最火的5种推荐场景均可以采用上述的数据结构和存储格式进行适配(Social recommendation 将于近期支持),本框架可以自动根据模型类别选择相应的数据文件,用户也可以开发新的组合方式,实现属于自己的独特推荐模型。
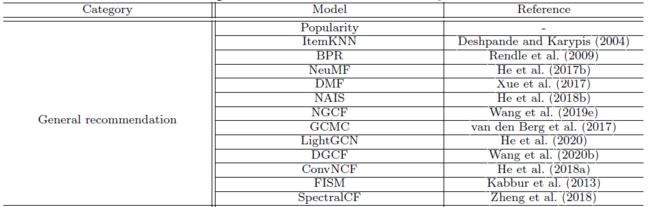
本框架目前集成了四大类的 53 种推荐模型以及 27 个学界常用的推荐任务评测数据集,提供了最广泛和统一的模型评测和比较标准。目前此框架包含的模型如下:
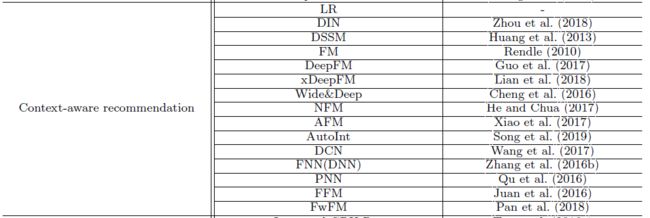
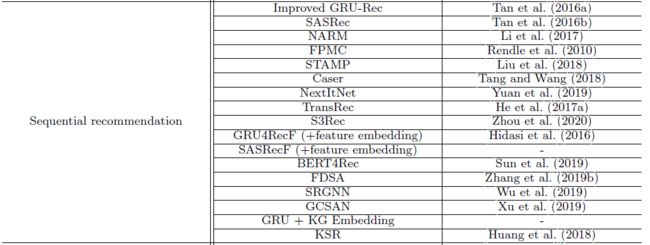

支持的数据集如下(用户需要自己下载原始数据 copy,然后使用本框架提供的预处理脚本处理或直接在提供的地址下载处理好的数据集):

4. 基于GPU加速的高效评测
与其他库将 C++ 作为评测加速方式不同,本框架完全基于 Python 实现,在评测部分充分使用 GPU 的并行张量运算进行优化,基本将整个评测过程放置在 GPU 上,实现了简洁与高效的完美统一。
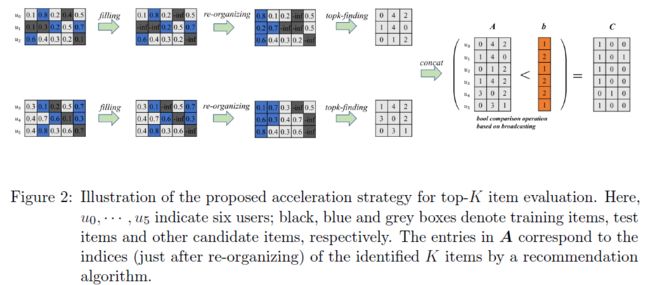
目前推荐任务中评测指标多为 TopK 指标,计算这类指标时需要对每一个用户取其前 K 个结果,这一步是相当耗时的,针对这个问题,本框架尝试使用矩阵并行化这个过程,使用 Mask 和 Padding 技术将所有的评测样本构建在一个 n×m 的矩阵中,使用基于 CUDA 的 Topk() 方法来加速这个过程,之后再将使用 NumPy 广播机制来对比计算推荐矩阵和目标矩阵,得到各个指标的值,整个过程中计算量最大的部分可以完全放在 GPU 上面执行,极大的减轻了 CPU 的评测压力,也提升了整体评测速度。加速具体方法的可视化过程如下图所示。
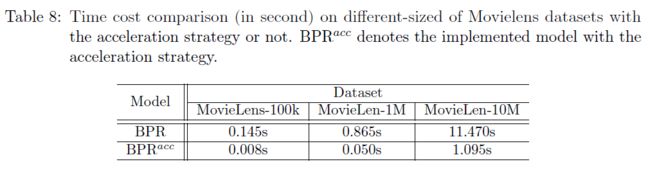
针对目前多个研究提到的采样偏差问题,本框架支持使用高效实现的全排序评测来进行消除,为此,本框架在评测部分专门针对全排序设计了优化算法,并开辟专门接口给需要进行全排序评测的模型,经过实际测试,在全排序评测中本框架优势非常明显(注:以下测速均为开发成员本机测试结果)。
5. 标准且丰富的评测方式
面对高级用户和二次开发者,同时提供了非常灵活的评测接口,用户可以使用简单的代码和参数来实现不同组合的采样和数据分割方式,并将常用的组合进行打包,实现快速的配置。据我们所知,这是当前支持最为全面评测方式的推荐开源框架。支持不同的数据集合切分方式、采样方式等。各个评测方式的详细含义和区别可以参考我们最新 CIKM 的短文 [2]。


简单上手
说了这么多,上手会不会很难啊?
一点都不难,让我们一起从 tutorial 中看看怎么上手这个框架吧!
1. 安装
RecBole 作为基于 Python 的开源库,与我们最常用的库一样提供 Conda、Pip、源代码三种安装方式,同时支持 Linux 和 Windows 的运行平台, 用户可以通过下面的简单命令进行安装使用:
conda install -c aibox recbole
或
pip install recbole
或
git clone https://github.com/RUCAIBox/RecBole.git && cd RecBole
pip install -e . --verbose
2. 一键运行
我们在 Github 提供了一键运行的脚本,如果你选择从源码安装,则可以直接调用:
python run_recbole.py --model=BPR
通过这个命令就可以直接在 ml-100k 数据集上进行 BPR 模型的训练和测试。
如果你想运行别的模型和数据集,可以使用命令行调用:
python run_recbole.py --dataset=[dataset_name] --model=[model_name]
如果你使用 pip 或 conda 安装,只需要新建一个 run.py 文件,在其中加入如下两行代码即可实现模型和数据集的定制化运行。
from recbole.quick_start import run_recbole
run_recbole(dataset='ml-100k', model='BPR')
3. 评测
同时,RecBole 提供了丰富的 API。当前推荐系统模型层出不穷,但是往往没有进行统一的评测设置,导致难以相互比较。考虑到资深研究者和二次开发人员的特殊功能需求,我们设计了 EvalSetting 类,并提供了方便的 API 实现统一的评测设置。
一个通用的流程如下:
dataset = Dataset(config) # 加载原始数据集
es = EvalSetting(config) # 声明一个评测设置
es.group_by_user() # Group 设置
es.temporal_ordering() # Order 设置
es.leave_one_out() # Split 设置
es.neg_sample_by(1000) # 评测时 1:1000 负采样
builded_datasets = dataset.build(es) # 数据集
声明EvalSetting 类的对象后,调用 API,完成对 Group、Order、Split、NegSample 的设置。比如上述例子实现的配置为:分割数据前按用户分组、交互记录根据时间戳排序、留一法划分数据、1:1000进行负采样生成测试数据。之后调用 Dataset 类的 build 方法,传入已经配置好的 EvalSetting 类,即可按照此评测配置进行数据集的处理,返回若干已处理好的 Dataset 对象。
当然,针对一些通用的评测设置,我们支持一键添加预设。比如上述例子也可以写成:
dataset = Dataset(config) # 加载原始数据集
es = EvalSetting(config) # 声明一个评测设置
es.TO_LS()
es.uni1000()
builded_datasets = dataset.build(es) # 数据集
4. 自动调参
最后,还有一个惊喜等着大家,本框架内嵌了一个自动调参工具,可以完美支持在各个模型上的超参搜索,在设定搜索范围之后一键即可自动实现参数寻找和保存。
from recbole.trainer import HyperTuning
from recbole.quick_start import objective_function
hp = HyperTuning(objective_function, algo='exhaustive',
params_file=params_file, fixed_config_file_list=config_file_list)
hp.run()
hp.export_result(output_file='hyper_example.result')
是不是再也不用为玄学的调参而苦恼了呢?赶紧来尝试尝试吧,后续还会有更强大的功能等着大家哦!
还在等什么呢?点击阅读原文,赶紧装上 RecBole 框架,复现一下经典的推荐模型吧!
同时,我们正公开招募开发团队成员,从贡献单一代码到核心模块的开发,都欢迎大家的加入。
参考文献
[1] Wayne Xin Zhao, Shanlei Mu, Yupeng Hou, Zihan Lin, Kaiyuan Li, Yushuo Chen,Yujie Lu, Hui Wang, Changxin Tian, Xingyu Pan, Yingqian Min, Zhichao Feng,Xinyan Fan, Xu Chen, Pengfei Wang, Wendi Ji, Yaliang Li, Xiaoling Wang, andJi-Rong Wen. 2020. RecBole: Towards a Unified, Comprehensive and EfficientFramework for Recommendation Algorithms.arXiv preprint arXiv:2011.01731(2020).
[2] Wayne Xin Zhao, Junhua Chen, Pengfei Wang, Qi Gu, and Ji-Rong Wen. Revisiting Alternative Experimental Settings for Evaluating Top-N Item Recommendation Algorithms. In CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, October 19-23, 2020, Mathieu d’Aquin, Stefan Dietze, Claudia Hauff, Edward Curry, and Philippe Cudré-Mauroux (Eds.). ACM, 2329–2332.
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

