在CV/NLP/DL领域中,有哪些修改一行代码或者几行代码提升性能的算法?

文章转载自知乎,仅作学术分享,著作权归属原作者,如有侵权请联系删除!
圈圈回答:
想起来些非常经典的东西
1. relu:用极简的方式实现非线性激活,还缓解了梯度消失
x = max(x, 0)
2. normalization:提高网络训练稳定性
x = (x - x.mean()) / x.std()
3. gradient clipping:直击靶心 避免梯度爆炸hhh
grad [grad > THRESHOLD] = THRESHOLD # THRESHOLD是设定的最大梯度阈值
4. dropout:随机丢弃,抑制过拟合,提高模型鲁棒性
x = torch.nn.functional.dropout(x, p=p, training=training) # 哈哈哈调皮了,因为实际dropout还有很多其他操作# 不够仅丢弃这一步确实可以一行搞定x = x * np.random.binomial(n=1, p=p, size=x.shape) # 这里p是想保留的概率,上面那是丢弃的概率
5. skip connection(residual learning):提供恒等映射的能力,保证模型不会因网络变深而退化
F(x) = F(x) + x
6. focal loss:用预测概率对不同类别的loss进行加权,缓解类别不平衡问题
loss = -np.log(p) # 原始交叉熵损失, p是模型预测的真实类别的概率,loss = (1-p)**GAMMA * loss # GAMMA是调制系数
7. attention mechanism:用query和原始特征的相似度对原始特征进行加权,关注想要的信息
attn = torch.softmax(torch.matmul(q, k), dim) #用Transformer里KQV那套范式为例v = torch.matmul(attn, v)
8. subword embedding(char或char ngram):基本解决OOV(out of vocabulary)问题、分词问题。这个对encode应该比较有效,但对decode不太友好
x = [char for char in sentence] # char-level
想起来别的简单有效的操作再来更新~

年年的铲屎官回答:
其他答主回答的很棒,我来说几个NLP相关的trick,主要集中于NLG,也就是自然语言生成
1, 只改1行代码,bleu提高2个点
用pytorch的时候,计算loss,使用最多的是label_smoothed_cross_encropy或者cross_encropy,推荐把
设置reduction为'sum',效果可能会比默认的reduction='mean'好一些(我自己的尝试是可以提高2个BLEU左右),以最常用的cross_entropy为例:
from torch import nnself.criterion = nn.CrossEntropyLoss(ignore_index=pad_id) # reduction默认为'mean'
改为
from torch import nnself.criterion = nn.CrossEntropyLoss( ignore_index=pad_id, reduction='sum')
发生的变化,实际上就是计算一个sequence的所有token,其loss是否平均(字不好看,请见谅~):

我的理解(不对请轻喷),这个trick之所以在一些任务中有用,是因为其在多任务学习中平衡了不同的loss的权重,至少在我自己做的image caption任务中看到的结果是这样的。
2,beam search添加length_penalty
这一点多亏
@高一帆
的提醒,解码阶段,如果beam search不加任何约束,那么很容易导致生成的最终序列长度偏短,效果可能还不如greedy search。原因的话就是beam size大于1,比较容易在不同的beam中生成较短的序列,且短序列得分往往比长序列高。举个例子的话请看下图(假设beam size为2):

那么我们需要对较短的序列进行惩罚,我们只需一行代码就可以改善这个问题:
# 假设原始生成序列的最终累积得分为accumulate_score,length_penalty是超参数,默认为1accumulate_score /= num_tokens ** length_penalty
3, 假设encoder输出为encoder_out,是一个tensor(比如一个768的embedding,而非一组embedding),那么我们喂给rnn的输入,input除了上一步的 , 拼接上encoder_out,效果会涨不少。即:
->
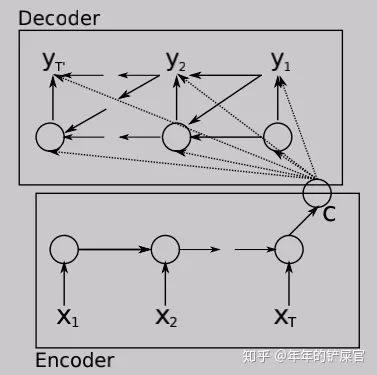
我自己的实验,每一个timestep给rnn的输入都拼接encoderout,bleu提高3个点(数据量4万)。
4,针对多层rnn,比如多层lstm,input feeding也是一个能提高模型表现的trick
就是lstm的第一层,其输入除了前一时刻的输出,还有最高一层前一时刻的隐状态 ,用图来表示就是:

变为:

表现在代码上,就是:
input = torch.cat((y[t-1], hiddens[t-1]), dim=1) # 原始的只有y[t-1]
陀飞轮回答:
自问自答,前面两位高赞的回答的很好了,我就补充一下自己知道的。尽量避开优化器、激活函数等改进。。
1. VGGNet -> ResNet

ResNet相比于VGGNet多了一个skip connect,网络优化变的更加容易
H(x) = F(x) + x
2. BN -> GN

在小batch size下BN掉点严重,而GN更加鲁棒,性能稳定。
x = x.view(N, G, -1)mean, var = x.mean(-1, keepdim=True), x.var(-1, keepdim=True)x = (x - mean) / (var + self.eps).sqrt()x = x.view(N, C, H, W)
3. NMS -> Soft-NMS

Soft-NMS将重叠率大于设定阈值的框分类置信度降低,而不是直接置为0,可以增加召回率。
#以线性降低分类置信度为例if iou > threshold: weight = 1 - io
4. CE loss -> Focal loss

Focal loss对CE loss增加了一个调制系数来降低容易样本的权重值,使得训练过程更加关注困难样本。
loss = -np.log(p) # 原始交叉熵损失, p是模型预测的真实类别的概率,loss = (1-p)**GAMMA * loss # GAMMA是调制系数
5. Hard label -> Label smoothing

label smoothing将hard label转变成soft label,使网络优化更加平滑。
targets = (1 - label_smooth) * targets + label_smooth / num_classes
6. IOU loss -> GIOU loss

GIOU loss避免了IOU loss中两个bbox不重合时Loss为0的情况,解决了IOU loss对物体大小敏感的问题。
#area_C闭包面积,add_area并集面积end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重giou = iou - end_area
推荐阅读
微软副总裁沈向洋:三十年科研路,我踩过的那些坑
告别CNN?一张图等于16x16个字,计算机视觉也用上Transformer了
对于2020入学的计算机视觉研究生,研究生如何学才能毕业找到一份好工作?


