论文阅读_关系抽取_CASREL
介绍
英文题目:A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
中文题目:抽取关系三元组的级联二元标注框架
论文地址:https://aclanthology.org/2020.acl-main.136.pdf
领域:自然语言处理,知识抽取
发表时间:2019
作者:Zhepei Wei, 吉林大学
出处:ACL
被引量:3
代码和数据:
https://github.com/xiangking/ark-nlp
https://github.com/weizhepei/CasRel
阅读时间:2022.06.17
读后感
主要解决了三元组重叠问题,相较之前模型,在架构上进行了大调整。
介绍
知识抽取 Information extraction (IE)是从文本构建知识图谱的重要环节。具体操作是从文中抽取关系三元组,它包含:主语s,关系r,宾语o。早期一般使用管道 pipeline 方法:先识别句中的实体,然后对每个实体对建立关系,这可能引起错误的传播;后来出现了基于人工构建特征的,抽取实体和关系的联合模型;在深度学习模型流行之后,模型可自行构建特征,使关系抽取得到了进一步发展。
三元组重叠问题,即:一句中的多个关系三元组共用同一实体。该问题一直没得到很好地解决,因为,它打破了早期为简化问题提出的假设:每个token只被标记一次,以及每个实体对只包含一种关系。

图-1包含三种情况:Normal情况下,被识别的两个三元组互不重叠;EPO情况下,两个实体之间包含多种关系;SEO情况下,存在多个相互重叠的三元组。
之前的方法分离了实体标注和提取关系,忽略了两步之间的相互作用。由于关系类别分布不均,且对于单一的关系,实体对在多数情况下都不满足指定的关系,形成了大量负例,还有缺少各类别足够实例的问题。另外,分离的逻辑处理重叠三元组效果也不好。
为解决上术问题,文中提出文中提出了CASREL框架,将关系作为主语到宾语的映射函数。具体分为两步:第一步识别句中所有可能的主语;第二步针对每个主题探测各种关系及其对应的宾语。最终设计了一个端到端的级联双标签(主语标签,关系宾语标签)框架。
方法
设D为训练集,x为单条训练数据,T为其中包含的所有三元组:

通过链式法则推导,最终,将抽取三元组拆分成三部分,首先,搜索其中的主语s;然后在文本x和s的条件下,遍历所有可能的关系r,计算对应宾语o发生的概率;右边的部分中,R\Tj|s表示没有发生的关系,o∅为空宾语,也就是说不可能发生的关系也找不到对应宾语。
这样做,第一可以直接优化最终三元组层面的评价标准,第二允许了实体充当多个三元组成份,互不干扰,支持了重叠;第三,由式(3)启发了一种新的抽取方法,把实体对的分类问题,变成了映射问题。
BERT编码器
使用预训练的BERT作为特征抽取器,将文本转换成向量。详见BERT论文。
级联解码器
核心思想是通过两步级联抽取三元组:先找主语,再找每个主语对应的关系和宾语。
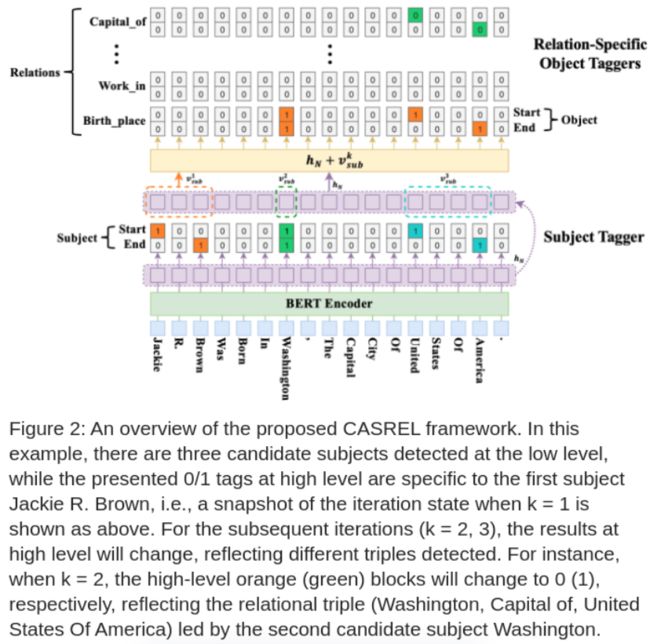
标记主语
图的下面部分用于识别输入句中所有主语,通过BERT编码成向量h,然后传入Subject Tagger,对每个token分别检测是否为主题的开始位置或结束位置。

对于多主题检测,需要对开始和结束位置配对,使用最近start-end匹配的方法,忽略end在start之前的情况。在预测正确的情况下,start与end将成对出现。
指定关系标记宾语
图的上半部分展示了识别宾语的过程,图-2中,颜色区分了识别到的不同主语,比如橙色 Jackie R. Brown 被识别成主语时,它是一个人名,所以不存在Capital of 的关系,虽然有可能存在 Work in 关系,但句中没有提及。因此,反应在图上部同样是橙色,对 Birth_place 关系找到了两个可能的宾语,分别是 Washington 和 United States Of America。
除了BERT输出的向量表示,计算时还考虑到了主语的向量表示 v:

对每个主题,使用相同的解码器。由于主题可能是多个词,长度不固定,使用对向量取均值的方法来计算上式中主语的向量v。
在关系不存在的情况下,概率计算方法如下:

对于空的宾语,每个起止位置的标记y都为0。如图-2中 Work in 对应的所有位置都是0(详见图下面的说明)。
目标函数
目标函数J(Θ) 计算方法如下:
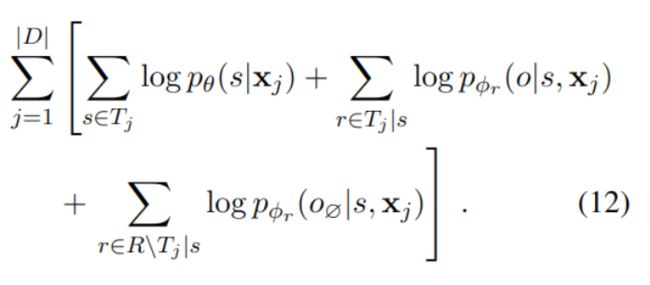
实验
数据集
实验使用了两个公开数据集NYT和WebNLG。关系类型分布不同:

实验结果
为了比较不同编码器的效果,在CASREL中测试了三种编码器,最下面是使用预训练的BERT,效果最好,random是不使用预训练的BERT模型,LSTM不使用BERT。即使不使用预测训练的BERT,CASREL模型效果也优于其它模型,预训练的BERT进一步提升了模型效果。
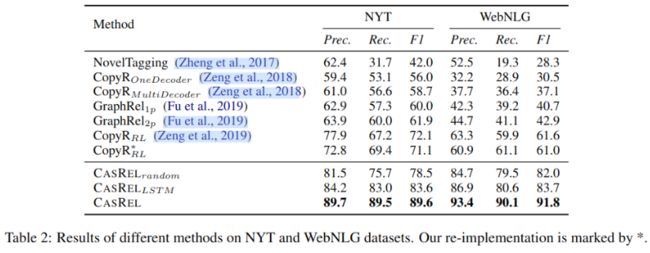
在三元组重叠及句中包含多个三元组的情况下,CASREL效果尤其明显。
