BN和LN

covariate shift 是分布不一致假设之下的分支问题,指源空间和目标空间的条件概率是一致的,但边缘概率不同;而统计机器学习中的经典假设是 “源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。
ICS导致的问题:每个神经元的输入数据不再是 “独立同分布”。
其一,上层参数需要不断适应新的输入数据分布,降低学习速度。
其二,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。

由于 ICS 问题的存在,x 的分布可能相差很大。要解决独立同分布的问题,“理论正确” 的方法就是对每一层的数据都进行白化操作。
白化就是去除输入数据的冗余信息。
如训练数据是图像,由于图像中相邻像素之间具有很强的相关性,
用于训练时输入是冗余的;白化的目的就是降低输入的冗余性。
输入数据集X,经过白化处理后,新的数据X'满足两个性质:
(1)特征之间相关性较低;
(2)所有特征具有相同的方差。
PCA不用作降维,而是求特征向量,把数据 X 映射到新特征空间,这一映射过程就是满足白化的第一个性质:除去特征之间的相关性。白化算法实现第一步就是PCA,求出新特征空间中 X 的新坐标,再对新的坐标进行方差归一化操作。

PCA 白化保证数据各维度的方差为1,而ZCA白化保证数据各维度的方差相同。PCA白化可以用于降维也可以去相关性,而ZCA白化主要用于去相关性,且尽量使白化后的数据接近原始输入数据。
标准的白化操作代价高昂,且不可微不利于反向传播更新梯度,所以提出了如 BN 等方法替代白化,其基本思想是:在将 x 送给神经元之前,先对其做平移和伸缩变换, 将 x 的分布规范化成在固定区间范围的标准分布。
平移缩放的作用:为了保证模型的表达能力不因为规范化而下降。
规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力,降低了神经网络的表达能力,而再变换可以将数据从线性区变换到非线性区,恢复模型的表达能力。
平移与再平移参数:平移参数,x 的均值取决于下层神经网络的复杂关联;
再平移参数去除了与下层计算的密切耦合,容易通过梯度下降来学习参数,简化神经网络训练。
BN在batch维度的归一化,也就是对于每个batch,该层相应的output位置归一化所使用的mean和variance都是一样的。
BN 的学习参数包含rescale和shift两个参数。
1、BN在单独的层级之间使用比较方便,比如CNN。而RNN层数不定,直接用BN不太方便,需要对每一层(每个time step)做BN,并保留每一层的mean和variance。由于RNN输入不定长(time step长度不定),会有validation 或 test的 time step 比 train 里面的任何数据都长,造成mean和variance不存在的情况。
2、BN会引入噪声(因为是mini batch而不是整个training),对噪声敏感的方法(如RL)不太适用。
BN(Batch Normalization)并不适用于RNN等动态网络和batch size较小的时候效果不好。
Layer Normalization(LN) 的提出有效的解决BN的这两个问题。
LN和BN不同点是归一化的维度是互相垂直的。
LayerNorm实际就是对隐含层做层归一化,即对某一层的所有神经元的输入进行归一化。(每hidden_size个数求平均/方差)
1、在training 和 inference 时没有区别,只需要对当前隐藏层计算mean and variance,不需要保 存每层的moving average mean and variance。
2、不受batch size限制,可通过online learning的方式一条一条的输入训练数据。
3、LN可以方便的在RNN中使用。
4、LN增加了gain和bias作为学习的参数。
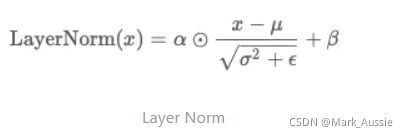
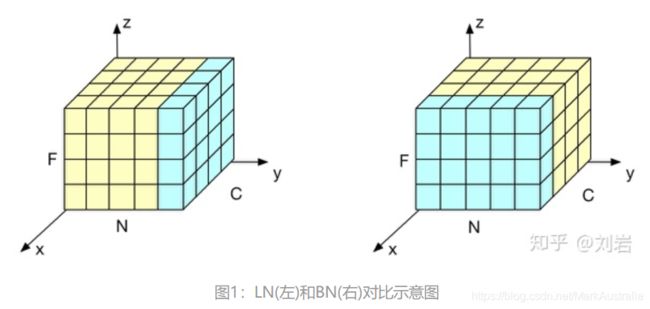
在图1中 N 表示样本轴, C表示通道轴,F是每个通道的特征数量。
BN如右侧所示,取不同样本的同一个通道的特征做归一化;
LN则是如左侧所示,取同一个样本的不同通道做归一化。
BN是按照样本数计算归一化统计量的,当样本数很少时,如有 4 个样本,这 4 个样本的均值和方差便不能反映全局的统计分布息,所以基于少量样本的 BN 的效果会变得很差。
RNN可以展开成一个隐藏层共享参数的MLP,随着时间片的增多,展开后的MLP的层数也在增多,最终层数由输入数据的时间片的数量决定,所以RNN是一个动态的网络。在一个batch中,通常各个样本的长度都是不同的,当统计到比较靠后的时间片时,基于这个样本的统计信息不能反映全局分布,这时BN的效果并不好。
BN的两个缺点的产生原因均是因为计算归一化统计量时计算的样本数太少。
LN是一个独立于batch size的算法,所以无论样本数多少都不会影响参与LN计算的数据量,从而解决BN的两个问题。
BN优点
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
(4)BN具有一定的正则化效果
参考:
模型优化之Layer Normalization - 知乎
Batch Norm和Layer Norm - 简书
https://blog.csdn.net/u013146742/article/details/51798826(白化)