目标检测中One-stage检测算法 -> SSD
点击上方“码农的后花园”,选择“星标” 公众号
精选文章,第一时间送达
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,Wei Liu2009年本科就读于南京大学本科,后来是北卡罗莱娜大学博士。
ECCV的全称是European Conference on Computer Vision(欧洲计算机视觉国际会议) ,两年一次,是计算机视觉三大会议(另外两个是ICCV和CVPR)之一。每次会议在全球范围录用论文300篇左右,主要的录用论文都来自美国、欧洲等顶尖实验室及研究所,中国大陆的论文数量一般在10-20篇之间。ECCV2010的论文录取率为27%。
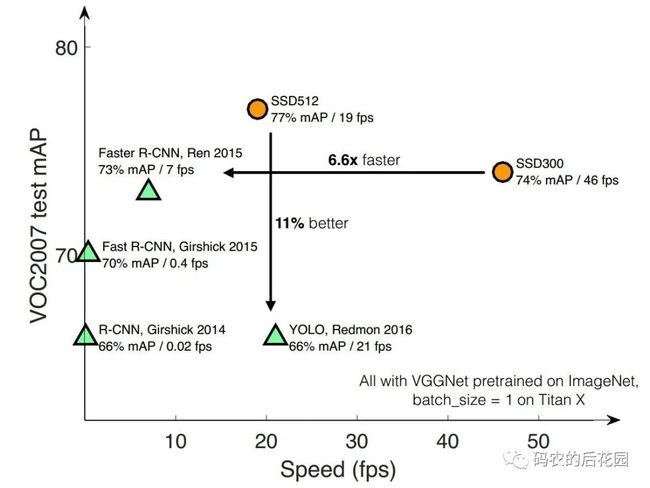
在VOC2007测试数据集上,我们可以看出,SSD有两个图片输入尺寸:300*300和512*512,相比Faster RCNN有明显的速度优势,相比YOLOv0又有明显的mAP优势(不过已经被CVPR 2017的YOLO9000超越,也就是YOLOv2), 如下图所示。
一、SSD主干特征提取网络
YOLOv0每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。
针对YOLOv0中的这些不足,SSD在这两方面都有所改进,同时兼顾了mAP和实时性的要求。其思路就是Faster R-CNN+YOLOv0,利用YOLOvo的思路和Faster R-CNN的anchor box的思想。
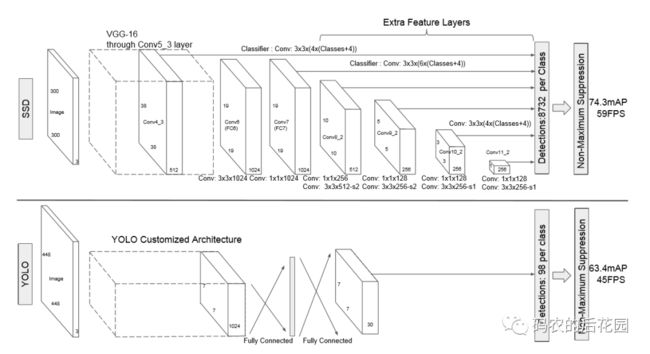
如上图,SSD网络的原始输入图片尺寸是300*300, 主干特征提取网络(backbone)采用Vgg16部分网络然后进行修改和添加。
经过SSD特征提取后,输出38*38、19*19、10*10、5*5、3*3、1*1 总共6个尺度的有效特征层。前面3个浅层的尺寸的有效特征层用于检测小目标,后面深层的有效特征层用于检测大目标物体。
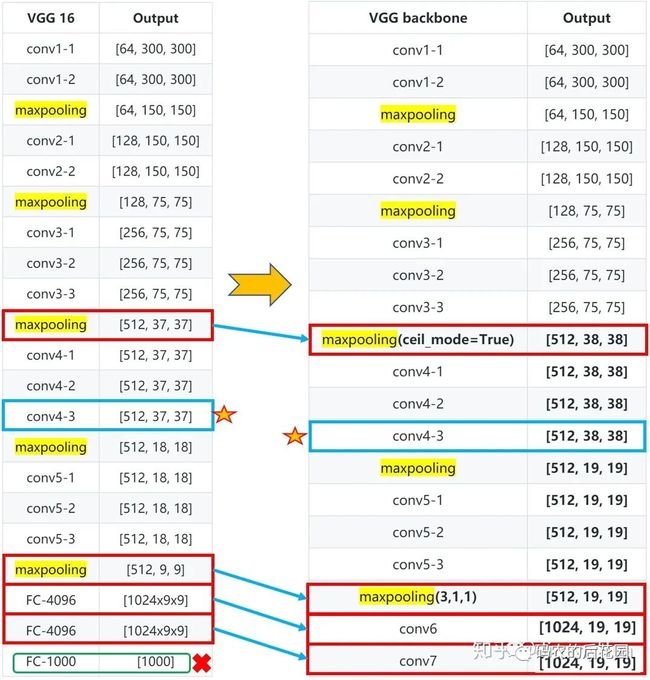
SSD特征提取网络结构主要是利用VGG16网络的前4个部分的卷积块,然后再conv4-3卷积块后输出有效特征层38*38,然后将VGG16网络的最后的3个全连接层丢弃,用两个卷积层Con6和Conv7进行代替,输出有效特征19*19层,如下图所示。
✏️ 值得注意:
1.将Vgg16的conv4-1前面一层的maxpooling的ceil_mode=True,使得输出有效特征层为38x38;
2. Conv4-3网络是需要输出多尺度的网络层:38*38;
3. 将Vgg16的Conv5-3后面的一层maxpooling参数为(kernel_size=3, stride=1, padding=1),不进行下采样,即经过该层输出后的特征图尺寸不改变。

SSD剩下的4个有效特征层提取,也就是后续的多尺度提取是基于在VGG16 Backbone后面添加了卷积网络块: Conv8_2、Conv9_2、Conv10_2、Conv11_2,分别输出有效特征层10*10、5*5、3*3、1*1。


PS: 红框的网络输出是有效特征层,用于获取模型预测结果。
二、SSD从特征获取预测结果
从主干特征提取网络,我们可以看出SSD一共有6层多尺度提取的网络,输出6个有效特征层,分别对每层进行位置 loc 和 类别置信度 conf 进行卷积,得到相应的预测输出。
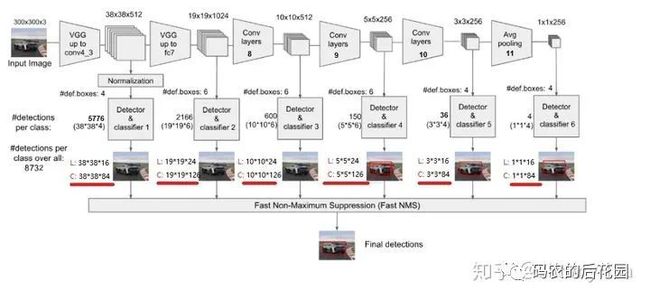
从上图我们可以知道,我们分别取conv4的第三次卷积的特征、fc7的特征、conv8的第二次卷积的特征、conv9的第二次卷积的特征、conv10的第二次卷积的特征、conv11的第二次卷积的特征,为了和普通特征层区分,我们称之为有效特征层,来获取预测结果。
与 Yolov0最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对获取到的每一个有效特征层三步走:进行一次num_priors x 4的卷积用于获取框位置loc、一次num_priors x num_classes的卷积用于获取类别conf、并需要计算每一个有效特征层对应那些尺寸的先验框。而num_priors指的是该特征层所拥有的先验框数量,对应代码如下:
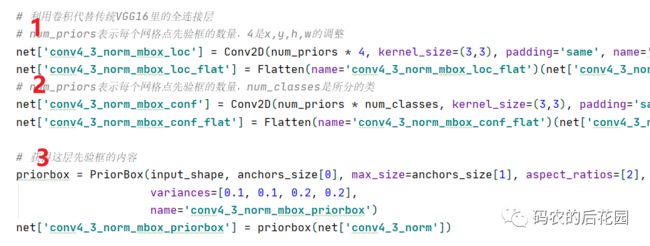
✏️ 值得注意:
1.num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为ssd的预测结果是结合先验框获得预测框,预测结果就是先验框的变化情况,4代表先验框的位置调整参数)。
2.num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类,SSD预测种类为voc数据集的20类+背景=21。
3.每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的多个框,从上图我们知道6个有效特征图依次设定了4、6、6、6、4、4个先验框。

每一个有效特征层对应的预测结果的shape如下:
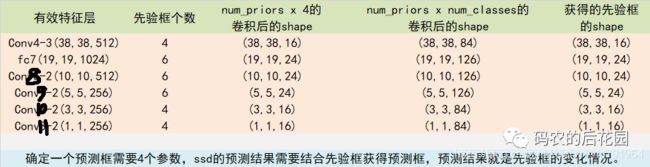
这里预测的loc和conf的最后一个维度大小取决于该有效特征层上预先设定先验框的数量,比如38*38有效特征层,位置卷积后的shape为(38,38,16),16=4*先验框的调整的4个表示参数(Cx,Cy,Cw,Ch),而类别卷积后的shape为(38,38,84). 84=4*21=84。
6个有效特征层总共预先设定先验框的数量为:38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732个先验框,我们最终也将获得8732个框的loc和conf预测结果。
三、有效特征层的先验框生成
一、先验框的尺寸(大小)生成
对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加,计算公式如下:
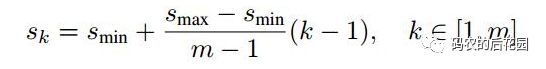

1.对于第一个特征图,它的先验框尺度比例设置为Smin/2 =0.1 ,则其尺度为 300 * 0.1 = 30;
2.对于后面的5个特征图,先验框尺度按照上面公式线性增加,但是为了方便计算,先将尺度比例先扩大100倍,最后向下取整,则此时增长步长为:
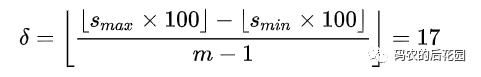
3.根据上面的公式,得到先验框尺寸计算公式:
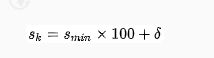
则有先验框大小尺寸为:![]() (比如:37= 20+【90-20】/ 4 * 1 = 20+17 =37 )。
(比如:37= 20+【90-20】/ 4 * 1 = 20+17 =37 )。
4. 然后再将它们的值除以100,然后再乘回原图的大小300,再综合第一个特征图的先验框尺寸,则可得各个特征图的先验框大小尺寸为:
![]() ,比如:20/100 *300 = 60.
,比如:20/100 *300 = 60.
5.最后一个特征图需要参考一个虚拟 ![]() 来计算
来计算 ![]() ,也就是最后先验框大小尺寸为
,也就是最后先验框大小尺寸为![]() ={30,60,111,162,213,264,315}.
={30,60,111,162,213,264,315}.
二、先验框的长宽比设置
先验框的长宽比ar一般有两个设置,如下:

第一个设置针对特征层上每个网格点有4个先验框,第二个设置为特征层上每个网格点有6个先验框。
先验框的宽高计算公式:
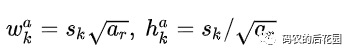
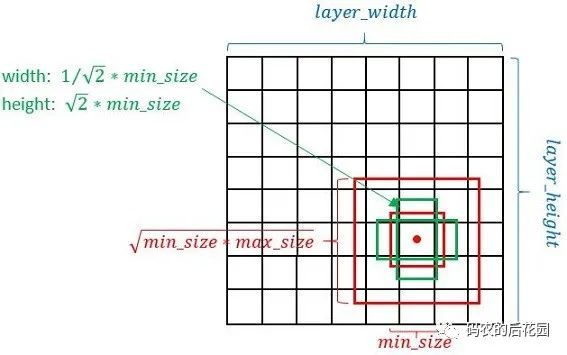
从而我们知道,对于特征图上每个网格点有4个先验框的,先验框的形状为两个红色正方形,长宽比为1,两个绿色的长宽大致相反的长方形:长宽比一个为![]() ,一个为
,一个为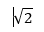 , 如下图,这里的minsize和maxsiz是根据先验框的大小尺寸得到的。
, 如下图,这里的minsize和maxsiz是根据先验框的大小尺寸得到的。
三、先验框中心的设置
每个单元的先验框的中心点分布在各个单元的中心,计算公式如下:
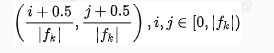
其中 为特征图的大小,然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置。
每一个有效特征层将整个图片分成与其长宽对应的网格,如conv10_2的特征层就是将整个图像分成3x3个网格;然后从每个网格中心建立多个先验框,如下图3*3的有效特征图的中心点在原始图像上的第一个坐标的生成 :(0.5/ 3 *300 , 0.5/3 *300 ) = (50,50)

四、真实框处理编码
SSD模型训练时结合真实框和先验框得到预测结果中先验框的调整参数:
先验框位置 :
![]()
真实框位置
![]()
![]() 用于调整检测值
用于调整检测值
真实框编码: 得到预测结果:相对于先验框default box的偏移量 。

如何确定真实框和先验框的匹配关系?从而知道是根据那个真实框调整先验框,从而得到训练时先验框应该有的正确调整参数。
先验框和真实框的匹配
✔️ 在训练过程中,首先需要确定训练图片中的 ground truth 与哪一个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
✔️ SSD的先验框和ground truth匹配原则主要两点:1. 对于图片中的每个真实框gt,找到与其IOU最大的先验框,该先验框与其匹配,这样可以保证每个真实框gt一定与某个先验框prior匹配。2. 对于剩余未匹配的先验框priors,若某个真是一框gt的IOU大于某个阈值(一般0.5),那么该prior与这个gt匹配。
✏️ 值得注意:
1.通常称与gt匹配的prior为正样本,反之,若某一个prior没有与任何一个gt匹配,则为负样本。
2. 某个gt可以和多个prior匹配,而每个prior只能和一个gt进行匹配。
3. 如果多个gt和某一个prior的IOU均大于阈值,那么prior只与IOU最大的那个进行匹配。

四、SSD预测结果解码
从上一步步获得预测结果我们知道:
1.对于每一个有效特征层进行一次num_priors*4卷积获取该特征层 上每一个网格点上的先验框位置调整参数。
2.一次num_priors*num_classes卷积获取有效特征层上每一个网络点上每一个预测框所对应的种类
3.再计算每一个有效特征层对应那些尺寸大小的的先验框。
那这里主要就是需要我们根据预测结果中 num_priors x 4的卷积结果 与 每一个有效特征层上每个网格点所对应的先验框进行调整 ,从而获得最终预测框的真实位置。(也就是利用预测的先验框的调整参数来调整我们预设的原始先验框,获得我们最终预测框的位置)。
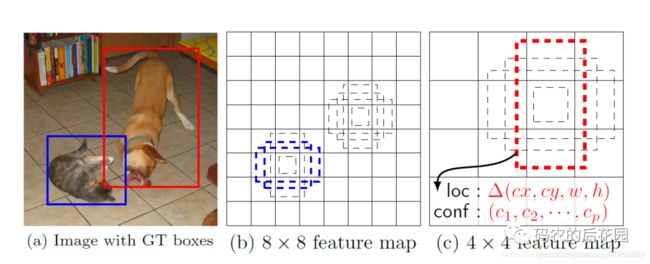
num_priors x 4中的num_priors表示了这个网格点所包含的先验框数量,其中的4表示了先验框x_offset、y_offset、h和w的调整情况。x_offset与y_offset代表了真实框距离先验框中心的xy轴偏移情况;h和w代表了真实框的宽与高相对于先验框的变化情况。
SSD预测结果解码过程就是将每个网格的中心点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
预测位置结果解码:根据预测结果中先验框调整参数得到最终预测边框的真实值,计算公式:
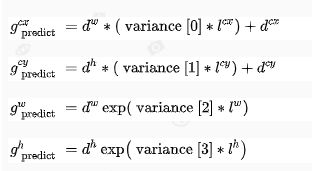
五、SSD预测结果解码后筛选
对6个有效特征层总共生成的8732个先验框进行调整后还要进一步筛选,得到最终图片预测框和分类结果。主要是进行种类得分排序和非极大值抑制NMS框筛选,主要是为了获得最终最准确的预测的分类种类和检测框。
我们首先选出预测结果中某个种类得分最高所对应的框(调整后的先验框),然后对根据这个得分最高的框去和其它调整后的先验框,计算面积的交并比IOU,然后再进行非极大值抑制NMS,从而将其它得分不高的调整后的先验框删除,具体过程如下:

举例说明:
如下图,我们已经识别出了5个候选框,但是我们只需要最后保留两个人脸。
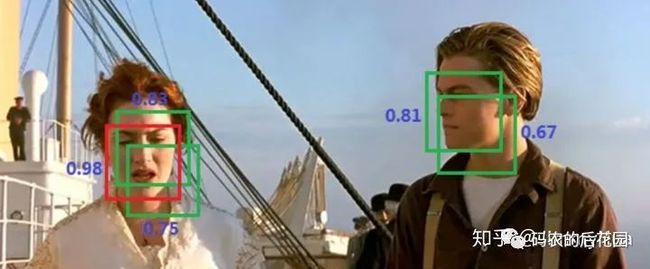
首先选出分数最大的框(0.98),然后遍历剩余框,计算 IoU,会发现露丝脸上的两个绿框都和 0.98 的框重叠率很大,都要去除。
然后只剩下杰克脸上两个框,选出最大框(0.81),然后遍历剩余框(只剩下0.67这一个了),发现0.67这个框与 0.81 的 IoU 也很大,去除。
至此所有框处理完毕,算法结果:

✔️ NMS算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,具体的实现思路如下:

六、得到最终预测结果框在原图片上绘制
在第四步中我们获得了预测框在原图上的位置,而且这些预测框都是经过筛选的。这些筛选后的框可以直接绘制在图片上,就可以获得结果了。
七、SSD模型训练时损失函数

一、位置损失函数
从预测部分我们知道,每个特征层的预测结果,num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。也就是说:我们直接利用ssd网络预测到的结果,并不是预测框在图片上的真实位置,需要解码才能得到真实位置。
而在训练的时候,我们需要计算位置损失loss函数:这个loss函数是相对于ssd网络的预测结果的:也就是种类、先验框中心和宽高调整参数。因此当我们需要把图片输入到当前的ssd网络中,得到预测结果;与此同时我们还需要把真实框的信息进行编码,这个编码是把真实框的位置信息格式转化为ssd预测结果的格式信息:Cx,Cy,Cw,Ch,这样才能计算我们的损失函数。
也就是说:我们需要找到 每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,得到我们的预测结果应该是怎么样的:也就是先验框真正的调整参数应该是怎么样的。
根据SSD网络预测位置loc结果调整先验框,从而获得图片预测最终真实框的过程被称作解码。而从训练数据集中的真实框获得预测结果(得到训练时先验框真正的调整参数)的过程就是编码程-真实框编码。解码过程逆过来就是编码过程了。
解码和编码的过程是为了计算位置损失函数loss,从而进行反向传播,进行模型训练。
二、位置损失函数 Lconf
置信度损失函数,即类别置信度损失函数。
总结:
用处理完的真实框与对应图片的预测结果计算loss:

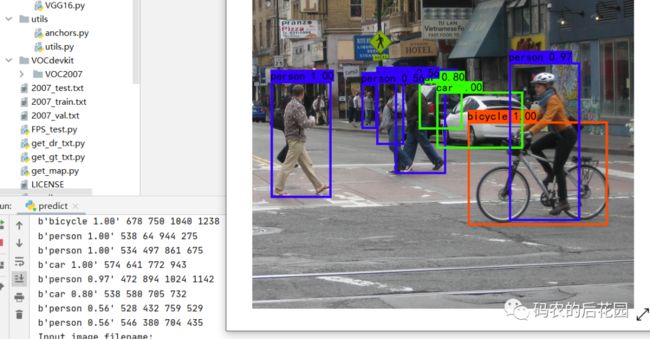
八、SSD模型检测结果展示
九、SSD模型性能评估




十、SSD算法改进DDSD
高层网络感受野比较大,也就是网络最底部的几个有效特征层,比如:3*3、1*1有效特征层。

微信公众号:码农的后花园,在后台回复关键字:项目实战,即可下载获取SSD相关源代码和SSD论文,后期提供相应的SSD模型训练测试教程。
论文地址:https://arxiv.org/abs/1512.02325
Caffe版SSD源码地址:https://github.com/weiliu89/caffe/tree/ssd
Tensorflow版本SSD地址:https://github.com/bubbliiiing/ssd-tf2
参考:
https://zhuanlan.zhihu.com/p/79854543
https://zhuanlan.zhihu.com/p/79933177
https://blog.csdn.net/thisiszdy/article/details/89576389-
https://blog.csdn.net/weixin_44791964/article/details/107289289

更多优质内容?等你点在看