Python入门基础
1 变量和简单数据类型
变量命名格式:变量名 = “赋值”
1.1 变量使用规范
使用变量时,需要遵守一些规则。违反这些规则将引发错误。
~变量名只能包含数字、字母、下划线。变量名不能以数字开头以及不能包含空格。
~变量名不能将Python保留字和函数名作为变量名。如print等
如下是python3的33个保留字列表:
~变量名要简单又具有描述性。如name比n好,user_name比u_n好。
~慎用大写字母I和O,避免看错成数字1和0。
1.2 字符串
字符串就是一系列字符。在Python中,用引号括起的都是字符串,其中引号包括单引号和双引号。这种灵活性能够在字符串中包含引号和撇号,如:
>>> str = "I'm David" >>> str1 = 'I told my friend,"i love Python"'
常用字符串操作方法
以首字母大写的方式显示每个单词:
>>> name = "hello python world" >>> print(name.title()) Hello Python World
将字符串改为全部大写或全部小写:
>>> str1 = "I love python" >>> print(str1.upper()) #将字符串改为全部大写 I LOVE PYTHON >>> print(str1.lower()) #将字符串改为全部小写 i love python
字符串合拼(拼接)
Python使用加号(+)来合拼字符串,如:
>>> first_name = "Guido" >>> last_name = "van Rossum" >>> full_name = first_name + " " + last_name >>> print(full_name) Guido van Rossum
使用制表符\t或换行符\n添加空白:
>>> print("Languages:\n\tPython\n\tC++\n\tPHP")
Languages:
Python
C++
PHP
删除字符串的空格:
>>> name = " p y t h o n "
>>> print(name.rstrip()) #删除字符串右端空格
p y t h o n
>>> print(name.lstrip()) #删除字符串左端空格
p y t h o n
>>> print(name.strip()) #删除字符串两端空格
p y t h o n
>>> print(name.replace(' ','')) #删除字符串全部空格包括制表符和换行符
python
字符串的序号
字符串是字符的序列,可以按照单个字符或字符片段进行索引。
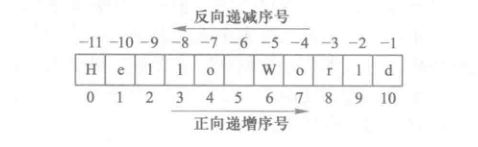
>>> name = "Hello World" >>> print(name[0]) H >>> print(name[0:-1]) Hello Worl >>> print(name[-1]) d >>> print(name[::]) Hello World >>> print(name[0:11]) Hello World
找到字符串中最低字符索引号:S.find(sub [,start [,end]]) -> int
失败时返回-1
>>> name = "hello world"
>>> print(name.find('d'))
10
返回某些字符出现的次数:S.count(sub[, start[, end]]) -> int
>>> name = "hello world"
>>> print(name.count('l'))
3
把字符串由分隔符返回一个列表:S.split([sep [,maxsplit]]) -> list of strings,如果给定maxsplit,则最多为maxsplit
>>> name = "hello world"
>>> print(name.split(' '))
['hello', 'world']
>>> print(name.split(' ',0))
['hello world']
字符串格式化输出(format和%用法)
%方法格式代码
>>> "{}:计算机{}的CPU占用率为{}%".format('2019-03-25','python',10) #S.format(*args, **kwargs) -> string
'2019-03-25:计算机python的CPU占用率为10%'
>>> "%s:计算机%s的CPU占用率为%d%%" % ('2019-03-25','python',10) #%用法
'2019-03-25:计算机python的CPU占用率为10%
小结:可以用help函数查看字符串的相关操作,比如help(str.find)
2 组合数据类型
2.1 集合类型
集合的定义及操作
~集合用大括号{}表示,元素间用逗号分隔;
~建立集合类型用{}或set();
~建立空集合类型,必须用set();
~集合元素之间无序;
~集合中每个元素唯一,不存在相同元素
>>> A = {"python",'666',("wenwei-blog",666)}
{'python', '666', ('wenwei-blog', 666)}
>>> B = set("pypy")
{'y', 'p'}
>>> C = {"python",123,"python",123}
{'python', 123}
集合操作符
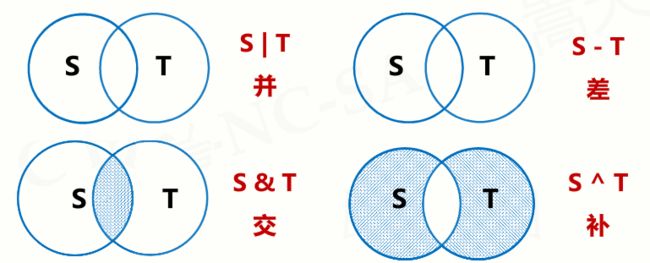
6个操作符
4个增强操作符

集合操作方法

集合应用场景
包含关系比较;数据去重。
2.1 序列类型定义
~序列是具有先后关系的一组元素
~序列是一个基类类型(基本数据类型)
~序列类型分为字符串、列表、元组类型
2.2 序列类型之列表
列表由一系列按特定顺序排列的元素组成,用方括号[]来表示列表。
列表的增删改查相关操作
| 函数或方法 |
描述 |
实例 |
| L[i]=x |
替换列表L第i数据项为x |
>>> L = ['Python','PHP','JavaScript','C++'] >>> L[1] = 'Java' >>> L ['Python', 'Java', 'JavaScript', 'C++'] |
| L[i:j]=L1 |
用列表L1替换列表L中第i到j项数据 |
>>> L |
| del L[i:j:k] |
删除列表L第i到第j项以k为步数的数据 |
>>> L |
| L+=L1或L.extend(L1) |
将列表L1元素增加到列表L中 |
>>> L;L1 ['C', 'JavaScript', 'Java', 'Ruby', 'Lua'] |
| L*=n |
将L列表的元素重复n次 |
>>> L1*=2 |
| L.append(x) |
在L列表最好添加元素x |
>>> L |
| L.clear() |
删除列表L的所有元素 |
>>> L |
| L1 = L.copy() |
复制L列表生成新的L1列表 |
>>> L |
| L.insert(i,x) |
在列表L的第i位置增加元素x |
>>> L |
| L.pop(i) |
将列表L中的第i项元素删除 |
>>> L;L.pop(2); |
| L.remove(x) |
将列表的第一个x元素删除 |
>>> L |
| L.reverse(x) |
将列表L中的元素反转 |
>>> L;L.reverse();L |
| L.sort() |
将列表L的元素按首字母顺序排序 |
>>> L.sort() |
| L.index(x) |
获取列表L的x元素的索引号 |
>>> L.index('Python') |
对列表数字执行简单统计计算
>>> digits = [1,23,434,55,44,67] >>> min(digits) 1 >>> max(digits) 434 >>> sum(digits) 624
列表相关练习
练习1:创建一个列表,其中包含数字1-100并打印出来然后计算列表数字的总值。
>>> digits = [value for value in range(1,101)];sum(digits) 5050
练习2:求1-20的奇数
>>> for i in range(1,21,2):
print(i)
练习3: 输出3-30以内能被3整除的数字
>>> lists = [n for n in range(3,31)]
>>> lists
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30]
>>> for i in lists:
if i % 3 == 0:
print(i)
2.3 序列类型之元组
元组其实跟列表差不多,也是存一组数据,只不过它一旦创建便不能修改,所以又叫只读列表
它只有两个方法,一个是count(统计元组某个元素出现的次数tuple.count('str')),一个是index(查看某个元素的索引号tuple.index('str'))
>>> names = ('zhiwenwei','zhouyouxian')
>>> names.index('zhiwenwei')
0
>>> names.count('zhiwenwei')
1
元组练习题
有如下变量,请实现要求的功能
tu = ("alex", [11, 22, {"k1": 'v1', "k2": ["age", "name"], "k3": (11,22,33)}, 44])
a. 请问tu变量中的第一个元素 “alex” 是否可被修改?
元组不可直接被修改,需要转换成列表或字典
b. 请问tu变量中的"k2"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 “Seven”
k2是字典的键,对应的值是列表可修改:tu[1][2]['k2']='Seven'
c. 请问tu变量中的"k3"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 “Seven”
k3是字典的键,对应的值是元组不可修改
2.4 字典类型
字典是包含0个或多个键值对的集合,没有长度限制,可以根据键索引值的内容。
Python语言中通过字典实现映射,通过大括号{}建立,建立模型如下:
{键1:值1,键2:值2,...}
>>> city = {'中国':'北京','美国':'纽约','法国':'巴黎'}
>>> city
{'中国': '北京', '美国': '纽约', '法国': '巴黎'}
拓展:字典是无序的。python语言中,字符串、列表、元组都是采用数字索引,字典采用字符索引。
字典的函数和方法
字典的基本原则
字典是一个键值对的集合,该集合以键为索引,一个键对应一个值信息
字典中的元素以键信息为索引访问
字典长度是可变的,可以通过对键信息赋值实现增加或修改键值对。
2.5 jieba库基本介绍
jieba库提供三种分词模式,最简单只需要掌握一个函数;
jieba是优秀的中文分词第三方库,需额外安装
jieba库的安装方法
pip install jieba
jieba分词的三种模式
精确模式:把文本精确切分,不存冗余单词
>>> word1 = jieba.lcut("python无所不能!除了生不出孩子,我们应该学习使用它!")
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 1.832 seconds.
Prefix dict has been built succesfully.
>>> print(word1,type(word1))
['python', '无所不能', '!', '除了', '生不出', '孩子', ',', '我们', '应该', '学习', '使用', '它', '!']
2.6 实例:文本词频统计
英文文本:hamlet,统计出现最多的英文单词
https://python123.io/resources/pye/hamlet.txt
代码实现:
#Hamlet词频统计
def getText():
txt = open("hamlet",'r').read()
txt = txt.lower() #大写字母转换小写
for word in '~!@#$%^&*()_+-={}[],./:";<>?':
txt = txt.replace(word," ")#把多余符号转换为空格
return txt
hamletTxt = getText()
words = hamletTxt.split() #以空格拆分为列表
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1 #以每个词为键,值默认0,,每出现一次累加1
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True) #[1]按照第二维排序,reverse=True表示降序
for i in range(10):
word,count = items[i]
print("{0:<10}{1:5}".format(word,count))
中文文本:三国,分析人物
https://python123.io/resources/pye/threekingdoms.txt
import jieba
txt = open("Threekingdoms", 'r', encoding="utf-8").read()
excludes = {'将军','却说','荆州','二人','不可','不能','如此'}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
#书中同一人物多个名字统一改为一个名字
elif word == '诸葛亮' or word == '空明日':
rword = "孔明"
elif word == '关公' or word == '云长':
rword = "关羽"
elif word == '玄德' or word == '玄德日':
rword = "刘备"
elif word == '孟德' or word == '丞相':
rword = "曹操"
else:
rword = word
counts[word] = counts.get(word, 0) + 1
for word in excludes:
del counts[word] #去重
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
3 程序的控制结构
3.1 程序的分支结构
根据判断条件结果而选择不同向前路径的运行方式
单分支结构
if <条件> :
<语句块>
示例:
guess = eval(input("请输入数字:"))
if guess == 88:
print("猜对了")
二分支结构
if <条件> :
<语句块>
else:
<语句块>
guess = eval(input("请输入数字:"))
if guess == 88:
print("猜对了")
else:
print("猜错了")
多分支结构
if <条件1> :
<语句块1>
elif <条件2> :
<语句块2>
...
else:
<语句块N>
示例
age = 25
count = 0
while count < 3:
guess_age = int(input("guess_age:"))
if guess_age == age:
print("yes,you got it!!!")
break
elif guess_age > age:
print("think smaller...")
else:
print("think bigger...")
count += 1
3.2 程序的循环结构
遍历循环
语法结构:
for <循环变量> in <循环结构>:
<语句块>
无限循环
由条件控制的循环运行方式
语法结构:
while <条件>:
<语句块>
循环控制保留字
break 和 continue
-break 跳出并结束当前整个循环,执行循环后的语句
-continue 结束当次循环,继续执行后续次数循环
循环的拓展

当循环没有被break语句退出时,执行else语句。
else语句作为“正常”完成循环的奖励
3.3 异常处理
异常处理的基本使用
示例
try:
num = eval(input("请输入数字"))
print(num**2)
except:
print("你输入的不是数字")
异常处理的高级使用
try:
语句块1
except:
语句块2
else:
语句块3(不发生异常时执行)
finally
语句块4(最终会执行)
3.4 实例:身体质量指数BMI
体质指数(BMI)= 体重(kg)÷ 身高²(m)
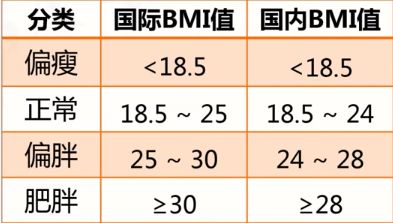
代码实例:
height,weight = eval(input("请输入身体(米)和体重(公斤)[逗号分开]:"))
bmi = weight / pow(height,2)
print("BMI数值为:{:.2f}".format(bmi))#.2f#保留两位小数
who,nat = "",""
if bmi < 18.5:
who,nat = "偏瘦","偏瘦"
elif 18.5 <= bmi < 24:
who,nat = "正常","正常"
elif 24 <= bmi < 25:
who,nat = "正常","偏胖"
elif 25 <= bmi < 28:
who,nat = "偏胖","偏胖"
elif 28 <= bmi <30:
who,nat = "偏胖","肥胖"
else:
who,nat = "肥胖","肥胖"
print("BMI指标为:国际'{}',国内'{}'".format(who,nat))
结果展示:
4 函数和代码复用
4.1 函数的定义和作用
def 函数名(o个或多个参数):
函数体
return 返回值
-函数是一段代码的表示
-函数是一段具有特定功能的、可重用的语句组
-函数是一种功能的抽象,一般函数表达特定功能
两个作用:降低编程难度和代码重用
函数的调用

4.2 函数的参数传递
可选参数传递
函数定义时可以为某些参数定义默认值,构成可选参数。
def test(n,m=1): #m为可选参数
s = 1
for i in range(1,n+1):
s *= i
print(s//m)
test(10)
test(10,2)
结果:
可变参数传递
def test(n,*args):#args为可变参数,也可以命名其他值
s = 1
for i in range(1,n+1):
s += i
for item in args:
s += item
print(s)
test(10,3)
test(10,3,1,5)
函数执行结果:
![]()
参数组合:*args和**kwargs
def test(*args,**kwargs):
print("args =",args)
print("kwargs =",kwargs)
print("----------------------------------")
if __name__ == '__main__':
test(1,5,94,564)
test(a=1,b=2,c=3)
test(1,2,3,4,a=1,b=2,c=3)
test('I love python',1,None,a=1,b=2,c=3)
函数执行结果:
参数传递的两种方式:位置传递和名称传递

小结:
函数可以有参数也可以没有,但必须保持括号。*args是可变参数,args接收的是一个tuple;**kw是关键字参数,kw接收的是一个dict。在同时使用*args和**kwargs时,必须*args参数列要在**kwargs前面。
4.3 lambda函数
lambda函数是一种匿名函数,即没有名字的函数;lambda函数用于定义简单的、能够在一行内表示的函数。
g = lambda x,y:x*y print(g(4,5))
6 文件和数据格式化
5.1 文件的使用
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
常用语法格式
变量名 = open(文件路径(相对或绝对路径),打开模式,encoding=None)
打开模式
| 打开的文件模式 | 描述 |
| ‘r’ | 只读模式,默认值,文件不存在返回FileNotFoundError |
| ‘w’ | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| ‘x’ | 创建写模式,文件不存在则创建,存在则返回FileExistsError |
| ‘a’ | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| '+' | 与r/w/x/a一同使用,在原功能基础上增加同时读写功能 |
file对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数
| file对象 | 描述 |
| f.read(size) | 读入全部内容,如果给出参数,读入前size长度 |
| f.readline() | 读取整行,包括 "\n" 字符。 |
| f.readlines(sizeint) | 读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| f.write(s) | 将字符串或字节流写入文件 |
| f.writelines(lines) | 将元素全为字符串的列表写入文件 |
| f.close() | 关闭文件 |
| f.seed(offset) | 调整当前文件操作指针的位置,0-文件开头;1-文件当前位置;2-文件末尾位置 |
| f.flush() | 刷新文件内部缓冲,数据立刻写入文件 |
5.2 wordcloud库的使用
词云以词语为基本单位,更加直观和艺术第展示文件。
wordcloud库官网:WordCloud for Python documentation — wordcloud 1.8.1 documentation
github地址:GitHub - amueller/word_cloud: A little word cloud generator in Python
wordcloud下载安装
pip install wordcloud
wordcloud常规方法
w = wordcloud.WordCloud()
| 方法 | 描述 | 例子 |
| w.generate(text) | 向wordcloud对象w加载文本text | w.generate("Python by WordCloud") |
| w.to_file(filename) | 将词云输出.png或.jpg图像文件 | w.to_file("outfile.png") |
实例
import wordcloud
w = wordcloud.WordCloud() #设置wordcloud对象
w.generate("Python by WordCloud,is fun and powerful!") #配置对象参数并加载词云文本
w.to_file("outfile.png") #输出词云文件
执行生成图片:

程序执行过程报错:ModuleNotFoundError: No module named 'matplotlib'
解决报错:安装python画图工具第三方库matplotlib:pip install matplotlib
wordcloud工作流程
-
-
- 分割:以空格分割单词
- 统计:单词出现次数并过滤
- 字体:根据统计配置字号
- 布局:颜色环境尺寸
-
配置对象参数
w.wordcloud.WordCloud(<参数>)
| 参数 | 描述 | 例子 |
| width | 指定生成图片宽度,默认400像素 | width=500 |
| height | 指定生成图片高度,默认200像素 | height=300 |
| min_font_size | 指定词云字体最小字号,默认4号 | min_font_size=20 |
| max_font_size | 指定词云字体最大字号,根据高度自动调节 | max_font_size=40 |
| font_step | 指定词云单词步进间隔,默认1 | font_step=6 |
| font_path | 指定文件字体的路径,默认None | font_path="msyh.ttc" |
| max_words | 指定词云显示最多单词数量,默认200 | max_words=5 |
| stopwords | 指定词云排除列表,即不显示的单词列表 | stopwords={"python"} |
| mask | 指定词云形状,默认长方形,修改需应用imread函数 | from scripy.misc import imread mk=imread("pic.png") mask=mk |
| background_color | 指定词云图片背景颜色,默认黑色 | background_color="white" |
实例1
import wordcloud
w = wordcloud.WordCloud()
text = "life is short, you need python"
w = wordcloud.WordCloud(background_color="white",width=500,height=300,
min_font_size=20,max_font_size=40,font_step=6,
max_words=5)
w.generate(text)
w.to_file("outfile2.png")
实例2
import wordcloud
import jieba
text = """
wordcloud是python非常优秀的第三方库,词云以词语为基本单位更加直观和艺术的展示文本词云图,\
也叫文字云,是对文本中出现频率较高的关键词予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,\
使得浏览者只要一眼扫过文本就可领略文本的主旨。基于Python的词云生成类库,好用功能强大。\
在做统计分析的时候有着很好的应用。
"""
w = wordcloud.WordCloud(width=800,height=400,font_path="msyh.ttc")
w.generate(" ".join(jieba.lcut(text))) #中文需要先分词并组成空格分隔字符串
w.to_file("outfile3.png")

实例3
常规图词云
https://python123.io/resources/pye/新时代中国特色社会主义.txt
import wordcloud
import jieba
f = open("新时代中国特色社会主义","r",encoding="utf-8")
text = jieba.lcut(f.read())
text = " ".join(text)
f.close()
w = wordcloud.WordCloud(background_color='white',width=800,height=400,font_path="msyh.ttc")
w.generate(text)
w.to_file("outfile4.png")
实例4
不常规图词云:生成下图五角星形状
import wordcloud
import jieba
from scipy.misc import imread
#图片必须是白色背景色
mask = imread('five-pointed star.png')
f = open("新时代中国特色社会主义","r",encoding="utf-8")
text = jieba.lcut(f.read())
text = " ".join(text)
f.close()
w = wordcloud.WordCloud(background_color='white',width=1000,height=700,font_path="msyh.ttc",mask=mask)
w.generate(text)
w.to_file("outfile5.png")
效果
