pytorch学习笔记一:model.train()与model.eval()
- model.train()与model.eval()的用法
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train(),在测试时添加model.eval()。其中model.train()是保证BN层用每一批数据的均值和方差,而model.eval()是保证BN用全部训练数据的均值和方差;而对于Dropout,model.train()是随机取一部分网络连接来训练更新参数,而model.eval()是利用到了所有网络连接。 - Dropout
dropout常常用于抑制过拟合,pytorch也提供了很方便的函数。设置Dropout时,torch.nn.Dropout(0.5), 这里的 0.5 是指该层(layer)的神经元在每次迭代训练时会随机有 50% 的可能性被丢弃(失活),不参与训练
a = torch.randn(10,1)
torch.nn.Dropout(0.5)(a)
- nn.Linear浅析
对输入数据进行线性变换
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
需要实现的内容:![]()
参数说明:
Args:
in_features: size of each input sample 输入的二维张量的大小
out_features: size of each output sample 输出的二维张量的大小
bias: If set to ``False``, the layer will not learn an additive bias.
Default: ``True``
举个例子:
>>> m = nn.Linear(20, 30)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size())
torch.Size([128, 30])
张量的大小由 128 x 20 变成了 128 x 30
执行的操作是:
[128,20]×[20,30]=[128,30]
- torch.nn.Conv2d() 用法讲解
Conv2d(in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1,bias=True, padding_mode=‘zeros’)
- in_channels:输入的通道数目 【必选】
- out_channels: 输出的通道数目 【必选】
- kernel_size:卷积核的大小,类型为int 或者元组,当卷积是方形的时候,只需要一个整数边长即可,卷积不是方形,要输入一个元组表示 高和宽。【必选】
- stride: 卷积每次滑动的步长为多少,默认是 1 【可选】
- padding: 设置在所有边界增加 值为 0 的边距的大小(也就是在feature map 外围增加几圈 0 ),例如当 padding =1 的时候,如果原来大小为 3 × 3 ,那么之后的大小为 5 × 5 。即在外围加了一圈 0 。【可选】
- dilation:控制卷积核之间的间距(什么玩意?请看例子)【可选】
如果我们设置的dilation=0的话,效果如图:(蓝色为输入,绿色为输出,卷积核为3 × 3)
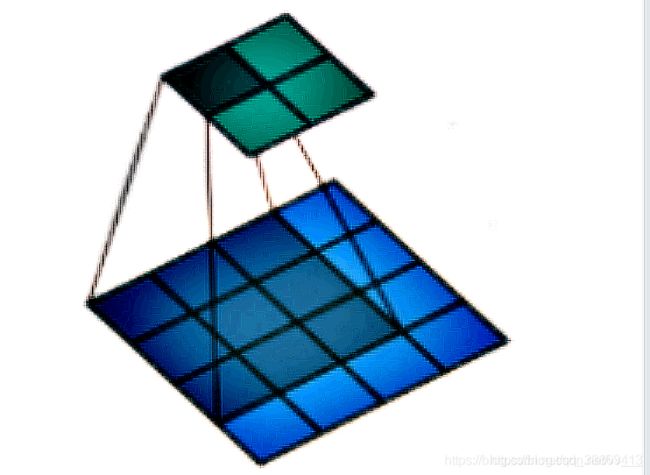
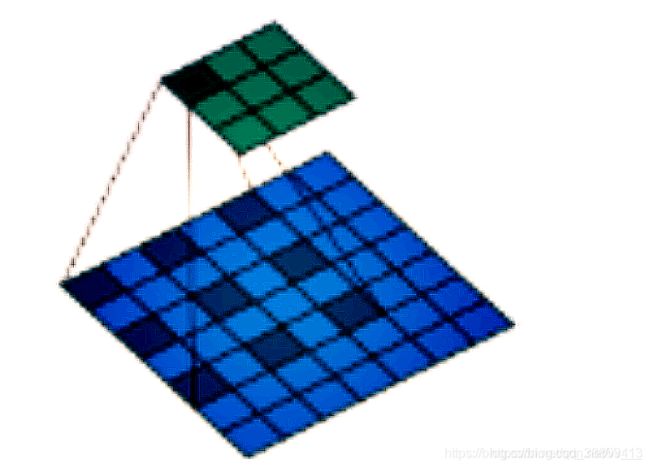
如果设置的是dilation=1,那么效果如图:(蓝色为输入,绿色为输出,卷积核仍为 3 × 3 。)但是这里卷积核点与输入之间距离为1的值相乘来得到输出。
举例来说:
比如 groups 为1,那么所有的输入都会连接到所有输出
当 groups 为 2的时候,相当于将输入分为两组,并排放置两层,每层看到一半的输入通道并产生一半的输出通道,并且两者都是串联在一起的。这也是参数字面的意思:“组” 的含义。
需要注意的是,in_channels 和 out_channels 必须都可以整除 groups,否则会报错(因为要分成这么多组啊,除不开你让人家程序怎么办?)
- bias: 是否将一个 学习到的 bias 增加输出中,默认是 True 。【可选】
- padding_mode : 字符串类型,接收的字符串只有 “zeros” 和 “circular”。【可选】
注意:参数 kernel_size,stride,padding,dilation 都可以是一个整数或者是一个元组,一个值的情况将会同时作用于高和宽 两个维度,两个值的元组情况代表分别作用于 高 和 宽 维度。
torch.nn.Conv2d() 中的卷积核是怎么定义的
开始时候是随机初始化的,之后是可学习的
- torch.nn.Conv2d 为什么只定义卷积核的大小,而不定义卷积核的具体数值