自然语言处理(十五):Transformer介绍
自然语言处理笔记总目录
论文地址:Attention Is All You Need
Transformer的优势
- Transformer能够利用分布式GPU进行并行训练,提升模型训练效率
- 在分析预测更长的文本时,捕捉间隔较长的语义关联效果更好
Transformer网络架构

Transformer模型分为输入、输出、编码器、解码器四个部分,其中最主要的分别是编码器和解码器的部分,编码器负责把自然语言序列映射成为隐藏层,含有自然语言序列的数学表达,然后解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题。如情感分类、命名实体识别、语义关系抽取、摘要生成、机器翻译等等
Transformer编码器
我们重点来解析一下Transformer编码器的结构:
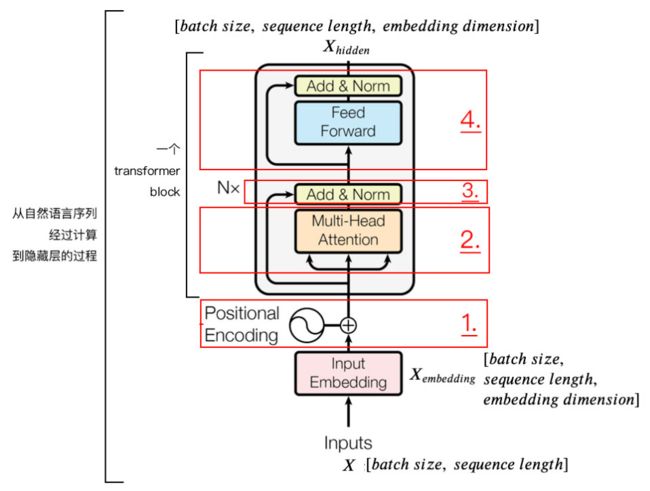
位置编码(Positional Encoding)
首先输入的维度为[batch_size, seq_len],首先经过词嵌入层,变成了[batch_size, seq_len, d_model],这里d_model就是词嵌入的维度
接下来就是位置编码了,为什么需要位置编码呢?
由于Transformer模型没有RNN的迭代操作,所以我们必须提供所有字的位置信息给Transformer,,才能识别出语言中的顺序关系,这样就需要Positional Encoding了,位置编码的目的就是要理解输入语句中单词的顺序,有很多的计算方式,在《Attention is all you need》论文中使用的是正余弦位置编码,位置编码通过不同频率的正余弦生成,然后与对应位置的词向量相加。位置编码计算公式如下:
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d model ) \begin{aligned} P E_{(p o s, 2 i)} &=\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \\ P E_{(p o s, 2 i+1)} &=\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \end{aligned} PE(pos,2i)PE(pos,2i+1)=sin(pos/100002i/dmodel )=cos(pos/100002i/dmodel )
pos代表单词在句子中的位置,比如第一个单词为0,第二个单词就为1;
d_model代表词嵌入的维度,比如d_model = 512
i控制奇偶性,比如由于d_model = 512,那么i=0,1,2,....,255,则2i=0,2,4,...,510代表偶数列的编码,2i+1=1,3,5,...,511代表奇数列的编码
代码:自然语言处理(十六):Transformer输入部分实现
掩码张量
常见的Mask有两种
- Padding-mask:用于处理不定长的输入
- sequence-mask:防止未来的信息不被泄露
Padding-mask
Padding-mask用于Encoder部分,主要是在self-attention的过程中,由于每次是进行一个 m i n i _ b a t c h mini\_batch mini_batch 的计算,也就是一次运算多句话,由于每句话的长度是不一的,所以我们就需要按照这个 m i n i _ b a t c h mini\_batch mini_batch 中最大的句长进行补齐长度,一般用0来填充,得到mask矩阵,如下示例:
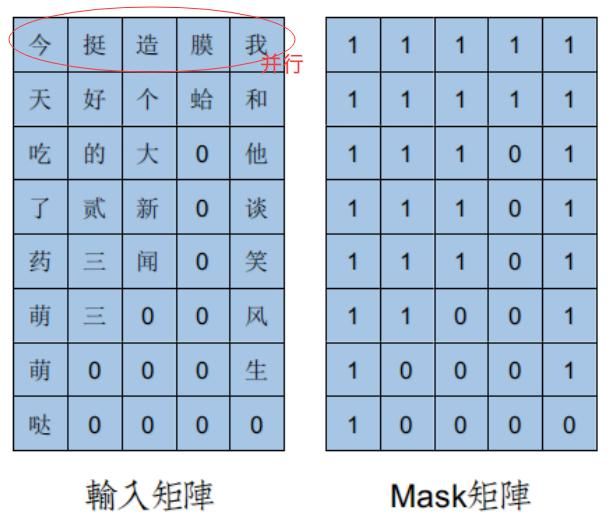
但是softmax这样就会有问题了,详情回顾一下softmax计算方式,这里如果补0的话,在softmax计算的时候 e 0 = 1 e^0 = 1 e0=1 ,这样padding部分就会参与运算,即无效部分参与了运算。因此,我们一般在掩码张量对应值为0的部分,即无效区域,给一个很大的负数,也就是:
z illegal = z illegal + bias illegal bias illegal → − ∞ e z illegal → 0 \begin{array}{c} z_{\text {illegal }}=z_{\text {illegal }}+\text { bias }_{\text {illegal }} \\ \text { bias }_{\text {illegal }} \rightarrow-\infty \\ e^{z_{\text {illegal }}} \rightarrow 0 \end{array} zillegal =zillegal + bias illegal bias illegal →−∞ezillegal →0
此时可以看到无效区域再进行softmax计算时几乎为0,这就避免了无效区域参与运算。
sequence-mask
sequence-mask用于Decoder部分,作用是为了防止未来的信息不被泄露即在 t 时刻不能看到 t 时刻及之后的信息,解码器的的输出不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的。因此,未来的信息可能被提前利用,所以要进行遮掩。
sequence-mask细节使用代码讲解
代码:自然语言处理(十七):Transformer掩码张量
多头自注意力机制
我们现在经过了词向量矩阵以及位置嵌入,回顾上面的结构图,接下来我们就要来看一看注意力机制了
假设现在我们有一些句子X:[batch_size, sequence_length],经过词嵌入以及位置嵌入,得到的X的维度为:[batch_size, sequence_length, embedding_dimension],下一步,为了学到多重含义的表达,也就是分配三个权重Q、K、V
W Q , W K , W V ∈ R embed_dim ∗ embed_dim W_{Q}, W_{K}, W_{V} \in \mathbb{R}^{\text {embed\_dim} * \text { embed\_dim }} WQ,WK,WV∈Rembed_dim∗ embed_dim
线性映射之后,形成三个矩阵Q、K、V,和线性变换前的维度一样
Q = Linear ( X embedding ) = X embedding W Q K = Linear ( X embedding ) = X embedding W K V = Linear ( X embedding ) = X embedding W V \begin{array}{l} Q=\text { Linear }\left(X_{\text {embedding }}\right)=X_{\text {embedding }} W_{Q} \\ K=\text { Linear }\left(X_{\text {embedding }}\right)=X_{\text {embedding }} W_{K} \\ V=\text { Linear }\left(X_{\text {embedding }}\right)=X_{\text {embedding }} W_{V} \end{array} Q= Linear (Xembedding )=Xembedding WQK= Linear (Xembedding )=Xembedding WKV= Linear (Xembedding )=Xembedding WV
这里我们用到的注意力机制的公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention (Q,K,V)=softmax(dkQKT)V
也就是下图左边的操作
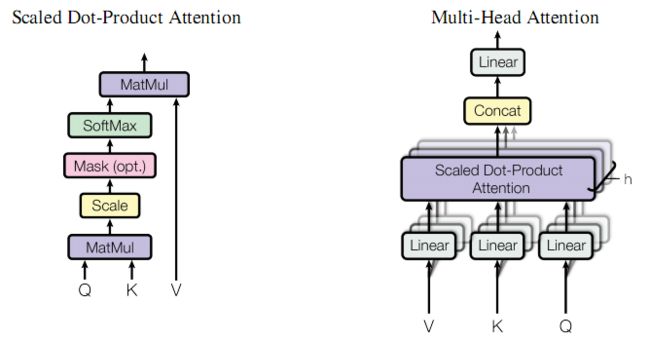
而多头注意力机制即把embedding_dimension分割成了h份,也就是头的个数,上图右边即为多头注意力机制,阴影层数即为头数,中间的紫色操作即为图左的操作,之后再进行多头拼接以及线性操作
分割后Q、K、V的维度为[batch_size, sequence_length, h, embedding_dimension / h]
之后再把第1,2维互换一下位置,即进行转置,方便后续的及计算
转置后Q、K、V的维度为[batch_size, h, sequence_length, embedding_dimension / h]
代码:自然语言处理(十八):Transformer多头自注意力机制
前馈全连接层
在Transformer中前馈全连接层具有两层线性层,由于注意力机制可能对复杂过程的拟合度不够,因此增加两层线性层来增强模型的能力
代码:自然语言处理(十九):Transformer前馈全连接层
规范化层
即Layer Normalizaiton,对比BN,BN可以理解为对一批次的数据进行规范化,而LN是对一个数据进行规范化,比如一行代表一个数据的一个矩阵,那么行为批次,列为特征,那么LN就是在一行上进行求均值方差,而BN是在一列上进行求均值方差,本质其实都是起到加速收敛的效果
过程:
以行为单位求均值: μ i = 1 m ∑ i = 1 m x i j \mu_{i}=\frac{1}{m} \sum_{i=1}^{m} x_{i j} μi=m1i=1∑mxij
以行为单位求方差: σ j 2 = 1 m ∑ i = 1 m ( x i j − μ j ) 2 \sigma_{j}^{2}=\frac{1}{m} \sum_{i=1}^{m}\left(x_{i j}-\mu_{j}\right)^{2} σj2=m1i=1∑m(xij−μj)2
LN操作:
LayerNorm ( x ) = α ⊙ x i j − μ i σ i 2 + ϵ + β \text { LayerNorm }(x)=\alpha \odot \frac{x_{i j}-\mu_{i}}{\sqrt{\sigma_{i}^{2}+\epsilon}}+\beta LayerNorm (x)=α⊙σi2+ϵxij−μi+β
一般我们初始化 α \alpha α为全1, β \beta β为全0,这里 ⊙ \odot ⊙表示元素相乘而不是点积
代码:自然语言处理(二十):Transformer规范化层
子层连接结构
子层连接,不管是Self-Attention还是全连接层,都首先是LayerNorm,然后是Self-Attention/Dense,然后是Dropout,最后是残差连接。这里面有很多可以重用的代码,我们把它封装成SublayerConnection
代码:自然语言处理(二十一):Transformer子层连接结构
编码器层 & 编码器
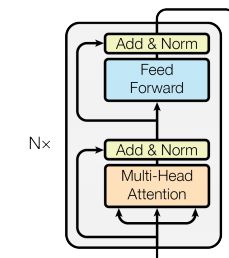
首先构建编码器层,编码器一共由N个编码器层堆叠而成
代码:自然语言处理(二十二):Transformer编码器构建
Transformer解码器
解码器层 & 解码器
解码器部分:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接

输出部分实现
代码:自然语言处理(二十三):Transformer解码器构建
Transformer模型构建
通过上面的部分,我们已经完成了Transformer所有组件的实现,现在就需要将这些组件进行拼接,实现完整的编码器-解码器结构
代码:自然语言处理(二十四):Transformer模型构建