Hadoop的资源隔离
背景
最近在一个hadoop集群中发现,当接入的集群的用户较多跑MR相关的spark、hive等服务时,如果不做资源的管理与规划,那么整个Yarn的资源很容易被某一个用户提交的Application占满,其它任务只能等待,这种当然很不合理,我们希望每个业务都有属于自己的特定资源来运行MapReduce任务,这里我们通过Hadoop中提供的公平调度器–Fair Scheduler,来解决这个问题。
首先我们来认识下Yarn,
1、hadoop的yarn是什么
在古老的 Hadoop1.0 中,MapReduce 的 JobTracker 负责了太多的工作,包括资源调度,管理众多的 TaskTracker 等工作。这自然是不合理的,于是 Hadoop 在 1.0 到 2.0 的升级过程中,便将 JobTracker 的资源调度工作独立了出来,而这一改动,直接让 Hadoop 成为大数据中最稳固的那一块基石。,而这个独立出来的资源管理框架,就是 Yarn 。Yarn 的全称是 Yet Another Resource Negotiator,意思是“另一种资源调度器”,这种命名和“有间客栈”这种可谓是异曲同工之妙。这里多说一句,以前 Java 有一个项目编译工具,叫做 Ant,他的命名也是类似的,叫做 “Another Neat Tool”的缩写,翻译过来是 “另一种整理工具”。
2、Yarn 架构
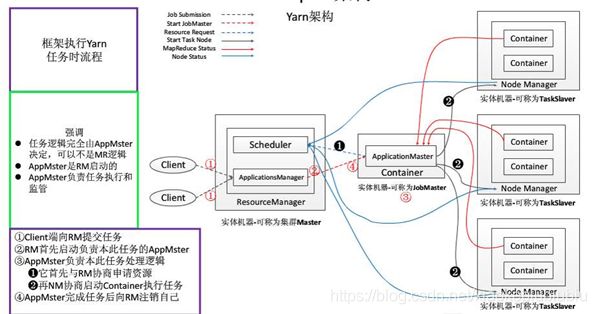
2.1 Container
容器(Container)这个东西是 Yarn 对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn 对资源的管理也是用到了这种思想。
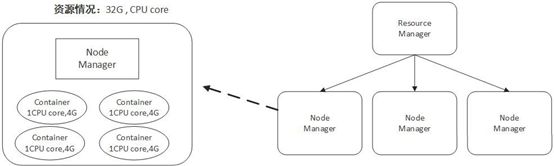
Yarn 将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
I: 容器由 NodeManager 启动和管理,并被它所监控。
II: 容器被 ResourceManager 进行调度。
(1) Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。它跟Linux Container没有任何关系,仅仅是YARN提出的一个概念(从实现上看,可看做一个可序列化/反序列化的Java类)。
(2) Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster;
(3) Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以使任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
(1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
2.2三个主要组件
2.2.1 ResourceManager
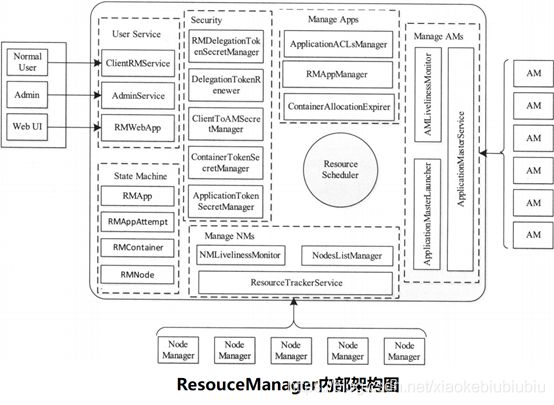
我们来说说ResourceManager(RM)。从名字上我们就能知道这个组件是负责资源管理的,整个系统有且只有一个 RM ,来负责资源的调度。它也包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当 Client 提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理 Client 用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
ResourceManager需通过两个RPC协议与NodeManager和AppMaster交互,具体如下 :
ResourceTracker : NodeManager通过该RPC协议向ResourceManager注册、汇报节点健康状况和Container运行状态,并领取ResourceManager下达的命令,这些命令包括重新初始化、清理Container等,在该RPC协议中,ResourceManager扮演RPCServer的角色,而NodeManager扮演RPCClient的角色,换句话说,NodeManager与ResourceManager之间采用了“pull模型”,NodeManager总是周期性地主动向ResourceManager发起请求,并通过领取下达给自己的命令
ApplicationMasterProtocol :应用程序的ApplicationMaster通过该RPC协议向ResourceManager注册、申请资源和释放资源。在该协议中,ApplicationMaster扮演RPC Client的角色,而ResourceManager扮演RPC Server的角色,换句话说,ResourceManager与ApplicationMaster之间采用了“pull模型”
ApplicationClientProtocol :应用程序的客户端通过该RPC协议向ResouceManager提交应用程序、查询应用程序状态和控制应用程序等。在该协议中,应用程序客户端扮演RPC Client的角色,而ResourceManager扮演RPC Server的角色。
ResourceManager主要完成以下4个功能 :
- 与客户端交互,处理来自客户端的请求
- 启动和管理AppicationMaster,并在它运行失败时重新启动它
- 管理NodeManager,接收来自NodeManager的资源汇报信息,并向NodeManager下达管理指令
- 资源管理与调度,接收来自AppMaster的资源申请请求,并为之分配资源
2.2.2 ApplicationMaster
每当 Client 提交一个 Application 时候,就会新建一个 ApplicationMaster 。由这个 ApplicationMaster 去与 ResourceManager 申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话山不过来,我就过去。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
2.2.3 NodeManager
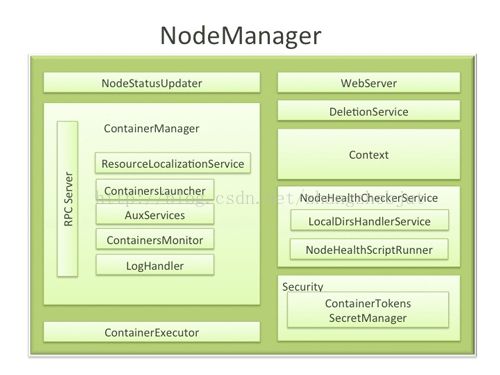
介绍一下NodeManager内部的组织结构和主要的模块
(1) NodeStatusUpdater
NodeStatusUpdater是NodeManager与ResourceManager通信的唯一通道。当NodeManager启动时,该组件向ResourceManager注册,并汇报节点上可用的资源(该值在运行过程中不再汇报);之后,该组件周期性与ResourceManager通信,汇报各个Container的状态更新,包括节点上正运行的Container、已完成的Container等信息,同时ResouceManager会返回待清理Container列表、待清理应用程序列表、诊断信息、各种Token等信息。
(2)ContainerManager
ContainerManager是NodeManager中最新核心的组件之一,它由多个子组件构成,每个子组件负责一部分功能,它们协同工作组件用来管理运行在该节点上的所有Container,其主要包含的组件如下:
RPCServer 实现了ContainerManagementProtocol协议,是AM和NM通信的唯一通道。ContainerManager从各个ApplicationMaster上接受RPC请求以启动新的Container或者停止正在运行的Contaier。
ResourceLocalizationService 负责Container所需资源的本地化。能够按照描述从HDFS上下载Container所需的文件资源,并尽量将他们分摊到各个磁盘上以防止出现访问热点。此外,它会为下载的文件添加访问控制权限,并为之施加合适的磁盘空间使用份额。
ContainerLaucher 维护了一个线程池以并行完成Container相关操作。比如杀死或启动Container。 启动请求由AM发起,杀死请求有AM或者RM发起。
AuxServices NodeManager允许用户通过配置附属服务的方式扩展自己的功能,这使得每个节点可以定制一些特定框架需要的服务。附属服务需要在NM启动前配置好,并由NM统一启动和关闭。典型的应用是MapReduce框架中用到的Shuffle HTTP Server,其通过封装成一个附属服务由各个NodeManager启动。
ContainersMonitor 负责监控Container的资源使用量。为了实现资源的隔离和公平共享,RM 为每个Container分配一定量的资源,而ContainerMonitor周期性的探测它在运行过程中的资源利用量,一旦发现Container超过它允许使用的份额上限,就向它发送信号将其杀死。这可以避免资源密集型的Container影响到同节点上的其他正在运行的Container。
注:YARN只有对内存资源是通过ContainerMonitor监控的方式加以限制的,对于CPU资源,则采用轻量级资源隔离方案Cgroups.。
(3) NodeHealthCheckservice
结点健康检查,NodeHealthCheckSevice通过周期性地运行一个自定义的脚步和向磁盘写文件检查节点健康状况,并通过NodeStatusUpdater传递给ResouceManager.而ResouceManager则根据每个NodeManager的健康状况适当调整分配的任务数目。一旦RM发现一个节点处于不健康的状态,则会将其加入黑名单,此后不再为它分配任务,直到再次转为健康状态。需要注意的是,节点被加入黑名单后,正在运行的Container仍会正常运行,不会被杀死。
第一种方式通过管理员自定义的Shell脚步。(NM上专门有一个周期性任务执行该脚步,一旦该脚步输出以"ERROR"开头的字符串,则认为结点处于不健康状态)
第二种是判断磁盘好坏。(NM上专门有一个周期性任务检测磁盘的好坏,如果坏磁盘数据达到一定的比例,则认为结点处于不健康的状态)。
(4) DeleteService
NM 将文件的删除功能服务化,即提供一个专门的文件删除服务异步删除失效文件,这样可以避免同步删除文件带来的性能开销。
(5) Security
安全模块是NM中的一个重要模块,它由两部分组成,分别是ApplicationACLsManager 确保访问NM的用户是合法的,ContainerTokenSecretManger:确保用户请求的资源是被RM授权过的。
(6) WebServer
通过Web界面向用户展示该节点上所有应用程序运行状态、Container列表、节点健康状况和Container产生的日志等信息。
3、提交一个 Application 到 Yarn 的流程
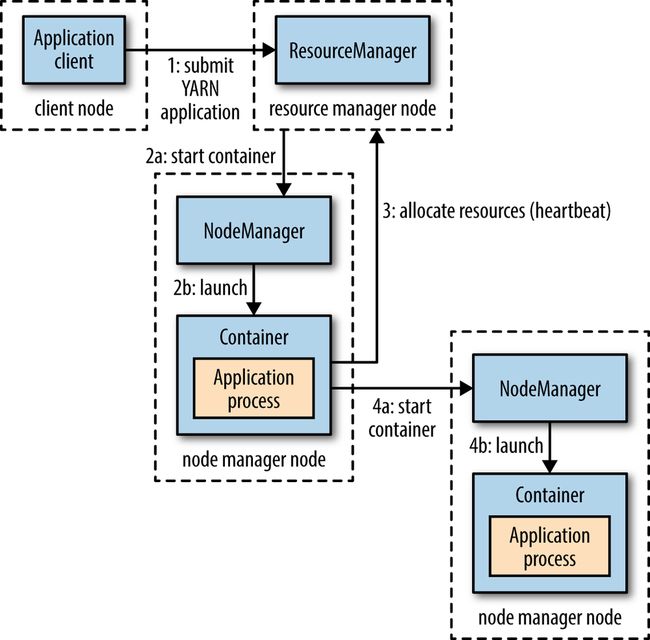
上图说明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程:
(1)Client向Yarn 提交Application,这里我们假设是一个MapReduce 作业。
(2)ResourceManager 向NodeManager 通信,为该Application分配第一个容器。并在这个容器中运行这个应用程序对应的ApplicationMaster。
(3)ApplicationMaster 启动以后,对作业(也就是 Application)进行拆分,拆分 task 出来,这些task可以运行在一个或多个容器中。然后向 ResourceManager 申请要运行程序的容器,并定时向ResourceManager发送心跳。
(4)申请到容器后,ApplicationMaster会去和容器对应的NodeManager 通信,而后将作业分发到对应的NodeManager 中的容器去运行,这里会将拆分后的 MapReduce 进行分发,对应容器中运行的可能是Map任务,也可能是Reduce任务。
(5)容器中运行的任务会向ApplicationMaster发送心跳,汇报自身情况。当程序运行完成后, ApplicationMaster再向ResourceManager注销并释放容器资源。
4、资源隔离
下面来说说,yarn的Fair Scheduler是如何解决我们的资源使用问题的。
Fair Scheduler将整个Yarn的可用资源划分成多个资源池,每个资源池中可以配置最小和最大的可用资源(内存和CPU)、最大可同时运行Application数量、权重、以及可以提交和管理Application的用户等。
- 根据用户名分配资源池
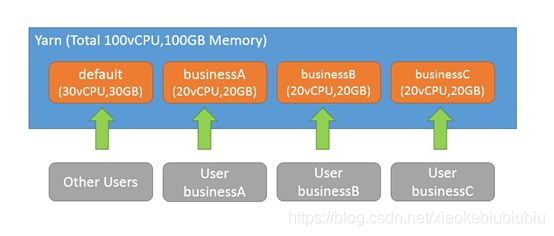
如上图所示,假设整个Yarn集群的可用资源为100vCPU,100GB内存,现有3个业务各自一个资源池,另外,默认的一个default资源池,用于运行其他用户和业务提交的任务。如果没有在任务中指定资源池(通过参数mapreduce.job.queuename),那么可以配置使用用户名作为资源池名称来提交任务,即用户businessA提交的任务被分配到资源池businessA中,用户businessC提交的任务被分配到资源池businessC中。除了配置的固定用户,其他用户提交的任务将会被分配到资源池default中。
这里的用户名,就是提交Application所使用的Linux/Unix用户名。(很多应用的人员一直问我是不是集群分配的,这里我想说,就是主机用户名,是应用在提交资源申请和接入的时候提供的)
另外,每个资源池可以配置允许提交任务的用户名,比如,在资源池businessA中配置了允许用户businessA和用户lxw1234提交任务,如果使用用户lxw1234提交任务,并且在任务中指定了资源池为businessA,那么也可以正常提交到资源池businessA中。
- 根据权重获得额外的空闲资源
在每个资源池的配置项中,有个weight属性(默认为1),标记了资源池的权重,当资源池中有任务等待,并且集群中有空闲资源时候,每个资源池可以根据权重获得不同比例的集群空闲资源。举个例子,资源池businessA和businessB的权重分别为2和1,这两个资源池中的资源都已经跑满了,并且还有任务在排队,此时集群中有30个Container的空闲资源,那么,businessA将会额外获得20个Container的资源,businessB会额外获得10个Container的资源。
这个设置,可以根据应用的使用情况,对不同业务的不同用户进行设置,保障需要的用户够用,不需要太多资源的用户不浪费资源。
- 最小资源保证
在每个资源池中,允许配置该资源池的最小资源,这是为了防止把空闲资源共享出去还未回收的时候,该资源池有任务需要运行时候的资源保证。举个例子,资源池businessA中配置了最小资源为(5vCPU,5GB),那么即使没有任务运行,Yarn也会为资源池businessA预留出最小资源,一旦有任务需要运行,而集群中已经没有其他空闲资源的时候,这个最小资源也可以保证资源池businessA中的任务可以先运行起来,随后再从集群中获取资源。
- 动态更新资源配额
Fair Scheduler除了需要在yarn-site.xml文件中启用和配置之外,还需要一个XML文件来配置资源池以及配额, 而该XML中每个资源池的配额可以动态更新, 之后使用命令:yarn rmadmin -refreshQueues 来使得其生效即可(一般是多刷几遍,保证在集群里都生效),不用重启Yarn集群。不过,这个命令动态更新只支持修改资源池配额,如果是新增或减少资源池,则需要重启Yarn集群。
- Fair Scheduler配置示例
开始干正事,下面配置,那我们用上面的业务场景为例
5.1 yarn-site.xml
|
具体的参数,我这边解释下, (1)yarn.resourcemanager.scheduler.class 配置Yarn使用的调度器插件类名; (2)Fair Scheduler对应的是: org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler (3)yarn.scheduler.fair.allocation.file 配置资源池以及其属性配额的XML文件路径(本地路径); (4)yarn.scheduler.fair.preemption 开启资源抢占。 (5)yarn.scheduler.fair.user-as-default-queue 设置成true,当任务中未指定资源池的时候,将以用户名作为资源池名。这个配置就实现了根据用户名自动分配资源池。 (6)yarn.scheduler.fair.allow-undeclared-pools 是否允许创建未定义的资源池。如果设置成true,yarn将会自动创建任务中指定的未定义过的资源池。设置成false之后,任务中指定的未定义的资源池将无效,该任务会被分配到default资源池中。
|
5.2 fair-scheduler.xml
|
解释下各参数意义
(1)minResources 最小资源 (2)maxResources 最大资源 (3)maxRunningApps 最大同时运行application数量 (4)weight 资源池权重 (5)aclSubmitApps 允许提交任务的用户名和组; 格式为: 用户名 用户组 当有多个用户时候,格式为:用户名1,用户名2 用户名1所属组,用户名2所属组 (6)aclAdministerApps 允许管理任务的用户名和组;
|
5.3 web UI
上面的文件都配置好了之后,我们可以在ResourceManager的WEB监控页面上看到。
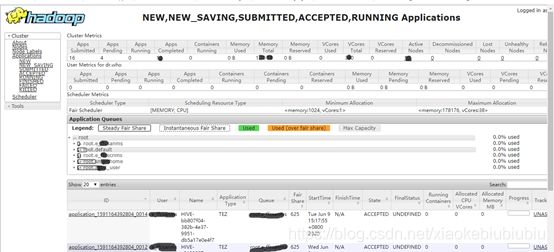
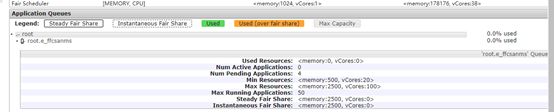
可以看到所有用户具体的application和资源使用情况。
- application夯死处理
场景1:应用反馈hive提交的spark任务无法执行。
检查:我登上resource manage UI,查看,发现大量的running在申请资源,排了很长的队列。
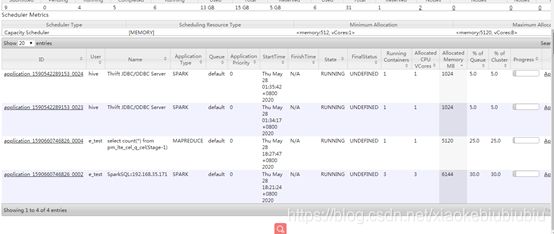
处理:和应用确认后,决定将提交的application进程kill掉,释放内存,并提升这个用户的权重,分配更多的资源给他。
结果:应用反馈使用正常。