go并发之道学习总结
go并发之道
- 并发概述
-
- 为什么并发很难?
- 竞争条件
- 原子性
- 内存访问同步
- 死锁、活锁和饥饿
-
- 死锁
- 活锁
- 饥饿
- 对代码进行建模:通信顺序进程
-
- 并发与并行的区别
- 什么是CSP
- Go 语言的并发哲学
- Go 语言并发组件
-
- goroutine
- sync 包
-
- WaitGroup
- 互斥锁和读写锁
- cond
- once
- Pool(池)
- channel
- select 语句
- Go 语言的并发模式
-
- 约束
- for-select 循环
-
- 向 channel发送迭代变量
- 循环等待停止
- 防止 goroutine 泄漏
- or-channel
- 错误处理
- pipeline
- 构建 pipeline 的最佳实践
- 扇入,扇出
- or-done-channel
- tee-channel
- conttext 包
- 大规模并发
-
- 异常传递
- 超时和取消
- 心跳
- 复制请求
- 速率限制
- 治愈异常的 goroutine
- goroutine 和 Go 语言运行时
-
- 工作窃取
- 窃取任务还是续体
并发概述
为什么并发很难?
并发代码是很难构建的。它通常需要完成几个迭代才能让它按预期的方式工作,即使是这样,在某些时间点(更高的磁盘利用率、更多的用户登录到系统等)到达之前,bug在代码中存在数年的事情也不少见,以至于以前未被发现的bug在后面暴露出来。
竞争条件
当两个或多个操作必须按正确的顺序执行,而程序未能保证这个顺序,就会发生竞争条件。
大多数情况下,这将在所谓的数据中出现,其中一个并发操作尝试读取一个变量,而在某个不确定的时间,另一个并发操作试图写入同一个变量。
在大多数情况下,引入数据竞争的原因是因为开发人员在用顺序的思维来思考问题。我们假设,某一行代码在另一个之前就会先运行。
竞争条件是最难以发现的并发 类型之 ,因为它 可能在代码投入生产多年之后才出现。通常代码正在执行时环境产生变化,或发生了某些罕见的事情,都有可能使其浮现出来。往往代码只是看上去在用正确的方式来执行,但是事实上只是执行的顺序是正确的这件事本身的概率比较大而己,最终早晚有可能会出现些意想之外的结果。
原子性
当某些东西被认为是原子的,或者具有原子性的时候,这意味着在它运行的环境中,它是不可分割的或不可中断的。
那么这到底意味着什么,为什么在使用并发代码时知道这点很重要?
第一件非常重要的事情是“上下文( context )”这个词。可能在某个上下文
中有些东西是原子性的,而在另一个上下文中却不是。在进程上下文中进行原子操作在操作系统的上下文中可能就不是原子操作;在操作系统环境中原子操作在机器环境中可能就不是原子的,在机器上下文中原子操作在应用程序的上下文中可能不是原子的。换句话说,操作的原子性可以根据当前定义的范围而改变。这种特性有利有弊。
在考虑原子性时,经常第一件需要做的事就是定义上下文或范围,然后再考虑这些操作是否是原子性的一切都应当遵循这个原则。
内存访问同步
假设有这样一个数据竞争:两个并发进程试图访问相同的内存区域,它们访问内存的方式不是原子的。
死锁、活锁和饥饿
死锁
死锁程序是所有并发进程彼此等待的程序。在这种情况下,如果没有外界的干预,这个程序将永远无陆恢复。
Coffman条件(产生死锁的四个条件):
- 互斥条件:并发进程同时拥有资源的独占权。
- 等待和保持条件:并发进程必须同时有拥有一个资源,并等待额外的资源。
- 不可剥夺条件:并发进程拥有的资源只能被该进程释放。
- 循环等待:一个并发进程(P1)必须等待其他并发进程(P2),这些并发进程同时也在等待(P1),这样便满足了这个最终条件。
活锁
活锁是正在主动执行并发操作的程序,但是这些操作无法向前推进程序的状态。
就像我们在走廊走向另一个人吗?她移动到左边让我们通过,但我们也做 了同样的事情,所以我们转到右边,但她也是这样做的。想象一下这个情形永远持续下去,就明白了活锁。
饥饿
饥饿是在任何情况下,并发进程都无法获得执行工作所需的所有资源。
饥饿通常意味着有一个或多个贪婪的并发进程,它们不公平地阻止一个或多个进程,以尽可能有效地完成工作,或者阻止全部并发进程。
对代码进行建模:通信顺序进程
并发与并行的区别
并发与并行的区别在于我们对代码进行建模的时候一个非常强力的抽象,而Go语言充分利用了这一点。我们从一个很简单的陈述开始:
- 并发属于代码;并行属于运行中的程序。
什么是CSP
CSP 即通信顺序进程,既是一个技术名词,也是介绍这种技术的的论文名字。
Go 语言是最早将 CSP 的原则纳入其核心的语,并将这种并发编程风格引入到大众中 。
内存访问同步并不是天生就不好。但是,共内存模型很难正确地使用,特别是在大型或复杂的程序中。正是由于这个原因,并发被认为是 Go 语言的 势之 ,它从一开始就建立在 CSP 的原则之上,因此很易阅读、编写和推理。
通常来说一种语言会将它们的抽象链结束在系统线程和内存访问同
步的层级。 Go 语言采用了一个不同的路线,并使用 goroutin chann 来代
替这些概念。
如果要画一个关于这两种并发代码的抽象画,我们很可能将 goruntine 比成
线程, 把一个channel 类比成一个mutex (这些原语只是有相似之处,但愿这些对比可以帮助你找对方向)。
goroutine 把我们从必须按照并行的方式 中解放出来,作为替它允许按照更为自然的等级对问题进行建模。
goro utin 是很轻量级的,我们通常情况下并不需要为创建新的 goroutin 的代价而担心。会有合适的机会让我们去思考系统中有多少运行中的 gorou tine ,但是过早考虑的话,则是完完全全地过早优化。把这个和线程对比一下,就会发现提前考虑这些事情很明智。
Go 语言的运行时自动地将 goro utine 映射到系统的线程上,并为我们管理它 之间 的调度。这也就意味着对于运行时的优化可以在不改动我们如何对问题建模方式的情况下进行随着并行技术的发展,Go 语言的运行时也会改进,程序的性能也进步,所有的这些都是自然而然。
并发与井行的解耦还有另一个好处:因为 Go 语言的运行时为我们管理
goroutin 映射的调度,它可以在像 goroutin 阻塞等待I/O 之类的事情上进行
内省,从而智能地把 OS 的线程重新分配给没有被阻塞的 goroutine 。这也提高了我们的代码性能。
问题空间与 Go语言代码之间的自然映射带来的另一个好处就是将问题空间建模为并发方式的数量增加了。因为我们作为开发者去解决问题,经常自然而然地按照并发的方式去处理。相比于我们可能使用的其他语言,在使用 Go语言的时候我们会在更细的颗粒度级别编写并发代码。例如,如果回 到网络服务器的例子上,现在在处理用户请求的时候都有一个独立的 goro utin ,而不是将链接绑定到一个线程池。 更精细的粒度级别使我们的程序可以在运行到主机可能承载的并行数量的时候,可以动态地缩放, Amda hl 法则的实践!这是非常惊人的。
goroutine 仅仅是这个拼图的一部分。而其他来自 CSP 的概念, channel与select 语句增加了它的价值。
比如说, chnnel 可以天然地和其他 chnnel 进行组合。这就使得编写大规模系统变得更加简单。因为可以通过轻松地组合输出来协调多个子系统的输入。可以将输入的 channel 与超时、取消或者消息组合到其他的子系统。而协调互斥体则是一个更加艰难的命题。
Go语言的select `是对 channel的一个补充,井且使多个通道组合的所有
难点得以实现。 select 语句使我们可以高效的等待事件,从 一个竞争的 channel 中均匀、随机地选择一个消息,并在没有消息的时候继续等待。
这个由CSP 以及支撑运行时所启发的 “漂亮挂毯”就是驱动 Go 语言的动力
所在。
Go 语言的并发哲学
CSP 一直都是Go语言设计的重要组成部分。然而, Go 语言还支持通过内存访问同步和遵循该技术的原语来编写并发代码的传统方式。 sync 与其他包中的结构体与方法可以让你执行锁,创建资源池取代 goroutine 等。
能够在 CSP 原语和内存访问同步之间选择对于我们来说很棒,因为它让我们去编写解决问题的并发代码上有了更多选择,但这可能显得有些莫名其妙。 Go的初学者总是认为 CSP 样式编写并发代码是 Go 编写并发代码的唯一方式。比如说,在 sync 包的文档中,有如下描述:
sync 包提供了基本的同步基元,如互斥锁 除了 Once 类型和 WaitGroup
类型,大部分都是适用低水平程序线程,高水平的同步使用 chann 通信。
在Go 言的 FAQ 中, 有如下陈述:
为了尊重 mutex, sync 包实现了 mutex ,但是我们希望 Go 语言的编程风格将会激励人们尝试更高等级的技巧。尤其是考虑构建你的程序,以便一次只有一个 goroutine 负责某个特定的数据。
Go 语言的一个庄右铭是, 使用通信来共享内存,而不是通过共享内存 来通信 。
这就是说,Go 语言确实在sync 包中提供了传统的锁机制。大多数的锁问题都可以通过channel 或者传统的锁两者之一来解决。
所以说,该用哪个?使用最好描述和最简单的那个方式。
这是很好的建议,也是我们在使用Go 语言时经常看到的的准则,但它有点含糊。我们如何理解什么更具有表现力、更简单?应该使用什么标准?幸运的是,我们可以使用一些标准来帮助我们做正确的事情。正如我们将看到的那样,主要的区分方式来自试图管理并发的地方:主观地想象一个狭窄的范围,或者在我们的系统外部。下图展示了这些用来创建决策数的准则。

让我们来逐步了解这些决策:
-
你想要转让数据的所有权么?
如果你有一块产生计算结果并共享这个结果给其他代码块的代码,你所做的实际的事情就是传递了数据的所有权。如果你对内存所有制且不支持GC 的语言很熟悉的话,对于整个概念应该是很熟悉的:数据拥有所有
者,并发程序安全就是保证同时只有一个并发上下文拥有数据的所有权。
channel 通过将这个意图编写进channel 类型本身来帮助我们表达这个意图。
这么做的一个很大的好处就是可以创建一个带缓存的channel来实现一个低成本的在内存中的队列来解耦我们的生产者和消费者;另一个好处就是通过使用channel 确保我们的并发代码可以和其他代码进行组合。
-
你是否视图在保护某个结构的内部状态?
这时候内存访问同步原语的一个很好的选择,也是一个不应该使用channel的很好示例。通过使用内存访问同步原语,可以为调用者隐藏关于重要代码块的实现细节。下面是一个线程安全的小例子,且不会给调用者带来复杂性:
type Counte struct { mu sync.Mutex value int } func (c *Counte) Incer(){ c.mu.Lock() defer c.mu.Unlock() c.value++ }记住这里的关键词是“内部的”。如果发现自己正在将锁暴露在一个类型之外,这时候就应该注意了。试着将锁放在一个小的字典范围内。
-
你是否试图协调多个逻辑片段?
请记住, chhannel 本质上比内存访问同步原语更具可组合性。将锁分散在整个对象图中听起来像是一场噩梦,但是将channel编写的随处可见是被鼓励以及期待的!我们可以组合channel,但是不轻易组合锁或者有返回值的方法。
我们会发现,因为Go语言的 select 语句,以及channel 可以当做队列使用和被安全的随意传递。所以当在使用channel的时候,可以更简单的控制系统中出现的激增的复杂性。如果你发现正在挣扎着理解你的井发代码是如何工作的,为什么会出现死锁以及竞争,而你正在只用原语,这是一个应该切换到channel的好示例。
-
这是一个对性能要求很高的临界区吗?
这绝对不意味着“我想让我的程序拥有高性能,因此,我应该只是用mutex“。当然,如果你程序中的某部分,事实证明是一个主要的性能瓶颈,比程序的其他部分慢几个数量级,使用内存访问同步原语可能会帮助这个重要的部分在负载下执行。这是因为channel 使用内存访问同步来操作因此它们只能更慢。然而,在我们考虑这一点之前,性能至关重要的程序部分可能暗示着需要重新规划我们的程序。
Go 语言的并发性哲学可以这样总结:追求简洁,尽量使用 channel ,并且认为 goroutine 的使用是没有成本的。
Go 语言并发组件
goroutine
goroutine 是Go 语言程序中最基本的组织单位之一,所以我们要了解它们是什么以及如何工作。事实上每个Go语言程序都至少有一个goroutine:main goroutine,它在进程开始时自动创建并启动。
简单地说,goroutine 是一个并发的函数(记住:不一定是并行的),与其他代码一起运行。
goroutine 的独特之处在于它们与Go 语言的运行时的深度集成。goroutine 没有定义自己的赞同方法或再运行点。Go 语言的运行时会观察 goroutine的运行行为,并在它们阻塞时自动挂起它们,然后在它们不被阻塞时恢复它们。在某种程序上,这使它们成为可抢占的,但只是在goroutine 被阻塞的情况。在运行时和goroutine的逻辑之间,是一种优雅的伙伴关系。因此goroutine可以被认为是一种特殊类型的协程。
协程和goroutine都是隐式并发结构,但并发并不是协程的属性:必须同时托管多个协程,并给每个协程一个执行的机会。否则,它们就不并发!请注意,这并意味着协程是隐式并行的。当然有可能有几个协程按顺序并行执行的假象,事实上,这种情况一直在发生。
Go语言的主机托管机制是一个名为M:N 调度器的实现,这意味着它将M 个绿色线程映射到 N 个 OS 线程。然后将goroutine 安排在绿色线程上。当我们的goroutine数量超过可用的绿色线程时,调度程序将处理分布在可用线程上的goroutine,并确保当这些goroutine被阻塞时,其他的goroutine可用运行。
Go 语言遵循一个称为 fork-join 的并发模型。fork这个词指的是在程序中的任意一点,它可以将执行的子分支与其他父分节点同时运行。join 这个词指的是,在将来某个时候,这些并发的执行分支将会合并在一起。下面有个示意图,来帮助我们描绘它:
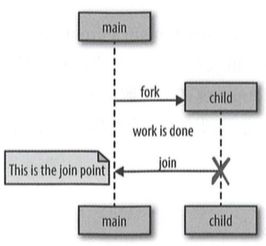
goroutine 的另一个好处是它们非常轻。下面是“ Go 语言 FAQ”的摘录:
一个新创建的 goroutine被赋予了几千字节,这在大部分情况都是足够的。 当它不运行时, Go 语言运行时就会自动增长(缩小)存储堆校的内存,允许许多 goroutine 存在适当的内存中。每个函数调用 CPU 的开销平均为 3 个廉价指令。在同一个地址空间中创建成千上万的 goroutine是可行的。 如果 goroutine 只是线程,系统的资源消耗会更小。
每个 goroutine 几千字节,这并没有什么问题!让我们来验证一下。但是在我们开始之前,我们必须讨论 一个关于 goroutine 有趣的 事情: 被丢弃的 goroutine。 如果我写如下代码:
go func(){
// 将永远阻塞的操作
}()
//开始工作
这里的 goroutine 将 一 直存在直到进程退出。
在下面的例子中,我们将 goroutine 不被 GC 的事实与运行时的自省能力结合起来,并测算在 goroutine 创建之前和之后分配 的内存数量 :
memConsumed := func () uint64{
runtime.GC()
var s runtime.MemStats
runtime.ReadMemStats(&s)
return s.Sys
}
var c <-chan interface{}
var wg sync.WaitGroup
noop := func(){ //1
wg.Done()
<-c
}
const numGoroutines = 1e4 //2
wg.Add(numGoroutines)
before := memConsumed() //3
for i:= numGoroutines; i > 0; i--{
go noop()
}
wg.Wait()
after := memConsumed() //4
fmt .Printf("%.3fkb", float64(after-before)/numGoroutines/1000)
- 我们需要一个永远不会退出的 goroutine,这样就可以在内存中保留一 段时间用于测算。不要担心我们是如何实现这个目标的,只要了解这个 goroutine 不 会退出,直到进程结束。
- 定义了要创建的 goroutine 的数量。我们将用大数定律 ,惭惭地接近一个 goroutine 的大小 。
- 算在创建 goroutine 之前消耗的内存总量。
- 测算在创建 goroutine 之后消耗的内存总量。
结果如下:
0.059kb
看起来文档是正确的!这些都是空的 goroutine,什么都不做,但它仍然让我 们知 道可能创造的 goroutine 的数量。下表给出了 一 些粗略的估计,在不使 用交换空间的情况下你可以使用 64 位 CPU 创建多少 goroutine。
| 内存(GB) | goroutines(#/100000) | 数量级 |
|---|---|---|
| 2^0 | 3.718 | 3 |
| 2^1 | 7.436 | 3 |
| 2^2 | 14.873 | 6 |
| 2^3 | 29.746 | 6 |
| 2^4 | 59.492 | 6 |
| 2^5 | 118.983 | 6 |
| 2^6 | 237.967 | 6 |
| 2^7 | 475.934 | 6 |
| 2^8 | 951.867 | 6 |
| 2^9 | 1903 .735 | 9 |
这些数字相当大! 8GB 的内存,这意味着理论上可以在不使用交换空间的情况下启动数百万的 goroutine。当然,忽略了在计算机上运行的其他东西,以及 goroutine 的实际内容, 但是这个快速的计算表明了 goroutine 是 多么的轻量级!
可能会影响性能的是上下文切换,即当一个被托管的并发进程必须保存它的状态以切换到一个不同的运行并发进程时。如果我们有太多的并发进程,可能会将所有的 CPU 时间消耗在它们之间的上下文切换上,而没有资源完成任何真正需要 CPU 的工作 。在操作系统 别,使用线程可能非常昂贵。 OS 线程必须保存如寄存器值、查找表和内存映射之类的东西, 以便能够在有限的时间内成功地切换回当前线程。 然后,它必须为传入的线程加载相同的信息 。
软件中的上下文切换相对来说要廉价得多。在一个软件定义的调度器下,运 行时可以更有选择性地保存数据用 于检索 ,如何持久化,以及何时需要持久化。 让我们来看看在 OS 线程和 goroutine之间切换的上下文的相对性能。
我们将使用 Go 语言构建一个类似的基准。下面的示例将创建两个 goroutine并在它们之间发送一条消息:
func BenchmarkContextSwitch(b *testing.B){
var wg sync.WaitGroup
begin := make(chan struct{})
c := make(chan struct{})
var token struct{}
sender := func(){
defer wg.Done()
<-begin //1 阻塞 等待,直到被告知开始执行 。我们对上下文切换度量的时候, 不需要考虑设置和启动每个 goroutine 的成本。
for i := 0; i < b.N; i++{
c <- token //2 我们将消息发送到接收器 goroutine。 一个 struct{}{}被称为一个空结构, 它没有内存占用,因此,我们只是在发出信号的时候记录时间。
}
}
receiver := func() {
defer wg.Done()
<-begin //1 阻塞等待,等待通知运行
for i := 0; i < b.N; i++{
<-c //3收到 一条信息,但什么也不做。
}
}
wg.Add(2)
go sender()
go receiver()
b.StartTimer() //4 开始计时 。
close(begin) //通知两个 goroutine开始运行
wg.Wait()
}
- 我们在这里等待,直到被告知开始执行 。我们对上下文切换度量的时候, 不需要考虑设置和启动每个 goroutine 的成本。
- 我们将消息发送到接收器 goroutine。 一个 struct{}{}被称为一个空结构, 它没有内存占用,因此,我们只是在发出信号的时候记录时间。
- 收到 一条信息,但什么也不做。
- 开始计时 。
- 告诉两个 goroutine开始运行。
运行基准测试,假设我们只使用一个 CPU,让我们来看看结果:
go test -bench=. -cpu=1 fig-ctx-switch_test.go
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i5-5287U CPU @ 2.90GHz
BenchmarkContextSwitch 5388067 199.9 ns/op
PASS
ok command-line-arguments 1.315s
每个上下文切换需要199.9ns。很难断言有多少 goroutine 会导致上下文切换过于频繁,但是可以很轻松地说,上限很可能不会成为使用 goroutine的任何障碍。
sync 包
sync 包包含对低级别内存访问同步最有用的并发原语。如果你使用的语言主要通过内存访问同步来处理并发,那么你可能已经熟悉了这些类型。 Go 语言和这些语言之间的区别在于, Go 语言已经在内存访问同步原语之上构建 一组新的并发原语,以向你提供一组扩展的工作。
WaitGroup
当我们不关心并发操作的结 果 ,或者有其他方法来收集它们的结果时, WaitGroup是等待一组并发操作完成的好方法 。 如果这两个条件都不满足, 建议使用 channel和 select语句。 下面是一个使用 WaitGroup等待 goroutine完成的基 本例子:
var wg sync.WaitGroup
wg.Add(1) //1
go func() {
defer wg.Done() //2
fmt.Println("1st goroutine sleeping...")
time.Sleep(1)
}()
wg.Add(1) //1
go func() {
defer wg.Done() //2
fmt.Println("2nd goroutine sleeping...")
time.Sleep(2)
}()
wg.Wait() //3
fmt.Println("all goroutine complete. ")
- 用 Add,参数为 1,表示一个 goroutine开始了。
- 使用 defer关键字来确保在 goroutine退出之前执行 Done操作,我们向WaitGroup 表明我们已经退 出了 。
- 执行Wait操作,这将阻塞main goroutine,直到所有goroutine表明它们已经退出。
输出如下:
2nd goroutine sleeping...
1st goroutine sleeping...
all goroutine complete.
我们可以将 WaitGroup视为一个并发 一安全的计数器:调用通过传人的整数执行 add 方法增加计数器的增量,并调用 Done 方法对计数器进行递减。 Wait 阻塞,直到计数器为零。
注意,添加的调用是在他们帮助跟踪的 goroutine之外完成的。如果我们不这样做,我们就会引入一种竞争条件,因为在本章前面“ goroutines”中,我们不能保证 goroutine何时会被调度,可以在 goroutine开始调度前调用 Wait 方法。 如果将调用 Add 的方法添加到 goroutine 的闭包中,那么 Wait 调用可能会直 接返回,而且不会阻塞,因为 Add 调用不会发生。
通常情况下,都要尽可能地向它们正在帮助追踪的 goroutine 中添加尽可能多的信息,但有时你会发现只调用一次 Add 来追踪一组 goroutine。我通常在这样的循环之前执行这种操作:
hello := func(wg *sync.WaitGroup, id int) {
defer wg.Done()
fmt.Printf("Hello from %v!\n", id)
}
const numGreeters = 5
var wg sync.WaitGroup
wg.Add (numGreeters)
for i := o; i < numGreeters; i++ {
go hello(&wg, i+1)
}
wg. Wait()
输出如下:
Hello from S!
Hello from 4!
Hello from 3!
Hello from 2!
Hello from 1!
互斥锁和读写锁
Mutex 是“互斥”的意思,是保护程序中临界区的一种方式 。临界区是程序中需要独占访问共享资源的区域。 Mutex提供了一种安全的方式来表示对这些共享资源的独占访问。为了使用一个资源, channel 通过通信共享内存,而 Mutex 通过开发人员的约定同步访问共享内存。下面有一个简单的例子,两个 goroutine试图增加和减少一个共同的值,它们使用 Mutex 互斥锁来同步访问:
var count int
var lock sync.Mutex
increment := func (){
lock.Lock() //1
defer lock.Unlock() //2
count++
fmt.Println("Incrementing: %d\n",count)
}
decrement := func(){
lock.Lock() //1
defer lock.Unlock() //2
count--
fmt.Println("Decrementing : %d\n",count)
}
//增量
var arithmetic sync.WaitGroup
for i:=0; i <= 5; i++{
arithmetic.Add(1)
go func() {
defer arithmetic.Done()
increment()
}()
}
//减量
for i := 0; i <= 5; i++{
arithmetic.Add(1)
go func() {
defer arithmetic.Done()
decrement()
}()
}
arithmetic.Wait()
fmt.Println("Arithmetic complete .")
- 我们请求对临界区的独占(这个例子里的计数器)使用互斥锁来解决。
- 我们指出已经完成了对临界区锁定的保护。
输出如下:
Incrementing: %d
1
Decrementing : %d
0
Decrementing : %d
-1
Decrementing : %d
-2
Decrementing : %d
-3
Decrementing : %d
-4
Incrementing: %d
-3
Incrementing: %d
-2
Incrementing: %d
-1
Incrementing: %d
0
Incrementing: %d
1
Decrementing : %d
0
Arithmetic complete .
你会注意到,我们总是在 deferi吾句中调用 Unlock。这是一个十分常见的习惯用法,它使用问Mutex互斥锁来确保即使出现了 panic,调用也总是发生。 如果不这样做 ,可能会导致程序陷入死锁。
关键部分之所以如此命名 ,是因为它们反映了程序中的瓶颈 。 进入和退出一个临界区是有消耗的,所以一般人会尽量减少在临界区的时间 。
这样做的一个策略是减少临界区的范围 。可能存在需要在多个并发进程之间共享内存的情况,但可能这些进程不是都需要读写此内存。如果是这样,可以利用不同类型的互斥对象 : sync.RWMutex。
sync.RWMutex 在概念上和互斥是一样的:它守卫着对内存的访问,然而, RWMutex 让你对内存有了更多控制。你可以请求一个锁用于读处理,在这种情况下你将被授予访问权限,除非该锁被用于写处理。这意味着,任意数量的读消费者可以持有一个读锁 ,只要没有其他事物持有一个写锁。
cond
对于 cond 类型的注释确实很好地描述了它的用途:
······一个 goroutine 的集合点,等待或发布一个 event。
在这个定义中, 一个“event”是两个或两个以上的 goroutine之间的任意信号, 除了它已经发生的事实外,没有任何信息。通常情况下,在 goroutine继续执 行之前,你需要等待其中一个信号。如果我们要研究如何在没有 Cond 类型的 情况下实现这一 目标, 一个简单的方住就是使用无限循环:
for conditionTrue() == false {
}
然而,这将悄耗 一 个 CPU 核心的所有周期 。 为了解决这个问题,我们可以引入一个 time.Sleep。
for conditio「1True() == false {
time.Sleep(1*time. 问illisecond)
}
这样更好,但它仍然是低效的,而且你必须弄清楚要等待多久:太长,会人为地降低性能 ; 太短,会不必要地消耗太多的 CPU 时间。如果有 一种方法可以让 goroutine 有效地等待, 直到它发出信号并检查它的状态,那就更好了。这正是 Cond 类型为我们所做的。使用 Cond,我们可以这样编写前面例子的 代码:
c := sync.NewCond(&sync.Mutex{}) //1
c.L.Lock() //2
for conditionTrue () == false {
c.wait() //3
}
c.L.Unlock() //4
- 我们实例化一个新的 cond。 NewCond 函数创建一个类型,满足 sync. Locker 接口。这使得 cond 类型能够以一种井发安全的方式与其 他 goroutine 协调。
- 我们锁定了这个条件。这是必要的,因为在进入 Locker 的时候,执行 Wait 会自动 执行 Unlock。
- 等待通知 ,条件已经发生。这是一个阻塞通信, goroutine将被暂停。
- 我们为这个条件 Locker 执行解锁操作 。 这是必要的,因为当执行 Wait 退出操作的时候,它会在 Locker 上调用 Lock 方法。
这种方法效率更高 。注意 ,调用 Wait 不只是阻塞,它挂起了当前的 goroutine,允许其他 goroutine 在 OS 线程上运行 。当你调用 Wait 时, 会发生一些其他事情:进入 Wait后,在 Cond变量的 Locker上调用 Unlock方法, 在退出 Wait时,在 Cond变量的 Locker上执行 Lock方法。
让我们扩展这个例子,并显示等式的两边 : 等待信号的 goroutine 和发送信号 的 goroutine。假设我们有一个固定长度为 2的队列,还有 10个我们想要推送到队列中的项目。我们想要在有房间的情况下尽快排队,所以就希望在队列中有空间时能立即得到通知。让我们尝试使用 Cond来管理这种调度:
c := sync.NewCond(&sync.Mutex{}) //1
queue := make([]interface{}, 0, 10) //2
removeFromQueue := func(delay time.Duration) {
time.Sleep(delay)
c.L.Lock() //8
queue = queue[1:] //9
fmt.Println("Removed from queue")
c.L.Unlock() //10
c.Signal() //11
}
for i := 0; i < 10; i++{
fmt.Println("queue:",queue)
c.L.Lock() //3
for len(queue) == 2{ //4
c.Wait() //5
}
queue = append(queue,i)
go removeFromQueue(1 * time.Second) //6
c.L.Unlock() //7
}
- 首先,我们使用标准的 sync.Mutex作为锁。
- 接下来,我们创建一个长度为0的切片。因为我们最终会添加10个项目, 所以用 10的容量实例化它。
- 我们通过在条件的锁存器上调用锁来进入临界区。
- 检查一个循环中队列的长度。这很重要,因为在这种情况下的信号并不一定意味着是你所等待的信号,也可能只是发生了什么 。
- 调用Wait, 这将暂停main goroutine直到一个信号的条件已经发送。
- 创建了一个新的 goroutine,它将在一秒钟后删除一个元素。
- 退出条件的临界区,因为我们已经成功地进入了一个项目。
- 再次进入临界区,以便我们可以修改与条件相关的数据。
- 通过将切片的头 部重新分配到第二个项目来模拟对一个项目的排队。
- 退出条件的临界区,因为我们已经成功地删除了一个项目。
- 我们让一个正在等待的 goroutine知道发生了什么事情。
输出如下:
Adding to queue
Adding to queue
Removed from queue
Adding to queue
Removed from queue
Adding to queue
Removed from queue
Removed from queue
Adding to queue
Adding to queue
Removed from queue
Adding to queue
Removed from queue
Adding to queue
Removed from queue
Removed from queue
Adding to queue
Adding to queue
queue: [8 9]
如你所见 ,该程序成功地将所有 10 个项目添加到队列中(并且在它有机会将前两项删除之前退出) 。 它 也总是等待,直到至少有一个项目被排入队列, 然后再进行另一个项目 。
在这个例子中,我 们还有 一 个新方法,Signal。 这是 Cond 类型提供的两种方法中的一种,它提供通知 goroutine 阻塞的调用 Wait ,条件已经被触发 。 另 一种方法叫做 Broadcast。运行时内部维护一个 FIFO列表,等待接收信号; Signal 发现等待最长时间的 goroutine 并通知它,而 Broadcast 向所有等待 的 goroutine 发送信号。 Broadcast 可以说是这两种方法中比较有趣的一种, 因为它提供了一种同时与多个 goroutine通信的方法。可以通过 channel 对信号进行简单的复制,但是重复调用 Broadcast 的行为将会更加困难。 此外, 与利用 channel 相比, Cond 类型的性能要高很多。
为了了解使用 Broadcast 的方法,让我们假设正在创建一个带有按钮的 GUI 应用程序。我 们想注册任意数量的函数,当该按钮被单击时,它将运行。Cond 可以完美胜任,因为我们可以使用它的 Broadcast 方法通知所有注册的处理程序。让我们看看它的例子:
type Button struct { //1
Clicked *sync.Cond
}
button := Button {Clicked: sync.NewCond(&sync.Mutex{})}
subscribe := func (c *sync.Cond,fn func()){ //2
var goroutineRunning sync.WaitGroup
goroutineRunning.Add(1)
go func(){
goroutineRunning.Done()
c.L.Lock()
defer c.L.Unlock()
c.Wait()
fn()
}()
goroutineRunning.Wait()
}
var clickRegistered sync.WaitGroup //3
clickRegistered.Add(3)
subscribe(button.Clicked, func() { //4
fmt.Println ("Maximizing window.")
clickRegistered.Done()
})
subscribe(button.Clicked, func() { //5
fmt.Println("Displaying annoying dialog box !")
clickRegistered.Done()
})
subscribe(button.Clicked, func() { //6
fmt.Println("Mouse clicked.")
clickRegistered.Done()
})
button.Clicked.Broadcast() //7
clickRegistered.Wait()
1.定义了一个 Button 结构体,它包含一个结构, Clicked。
2. 定义了一个便利构造函数,它允许我们注册函数处理来自条件的信号。 每个处理程序都在自己的goroutine上运行,并且订阅不会退出,直到 goroutine 被确认运行为止。
3. 我们为鼠标按键事件设置了一个处理程序。它反过来调用 Cond 上的 Broadcast ,让所有的处理程序都知道鼠标按键已经被单击了(更健壮的 实现将首先检查它是否已经被抑制) 。
4. 创建一个 WaitGroup。这只是为了确保我们的程序在写入 stdout之前不会退出。
5. 注册一个处理程序,当单击按键时,它将模拟最大化按钮的窗口。
6. 注册一个处理程序,该处理程序在单击鼠标时模拟显示对话框。
7. 接下来,我们模拟一个用户通过单击应用程序的按钮来单击鼠标按键。
输入如下:
Mouse clicked.
Maximizing window.
Displaying annoying dialog box !
可以看到,在Clicked Cond上调用 Broadcast,所有三个处理程序都将运行。 如果不是 clickRegistered 的 WaitGroup,我们可以调用 button.Clicked. Broadcast () 多次, 并且每次都调用 三个处理程序 。 这是 channel 不太容易做到的,因此是利用 Cond类型的主要原因之一。
与 sync包中所包含的大多数其他东西一样, Cond的使用最好被限制在一个 紧凑的范围中,或者是通过封装它的类型来暴露在更大范围内。
once
下面这段代码会输出什么?
count := 0
increment := func() {
count++
}
once := sync.Once{}
increments := sync.WaitGroup{}
increments.Add(100)
for i := 0; i < 100; i++{
go func() {
defer increments.Done()
once.Do(increment)
}()
}
increments.Wait()
fmt.Println("count is ",count)
很容易认为结果将是 Count is 100, 但我肯定你已经注意到了 sync.Once 变量,在某种程度上通过 Do 方法把调用增加了一次。事实上,这段代码将打印以下内容:
count is 1
顾名思义,sync.Once是一种类型,它在内部使用一些 sync 原语,以确保即使在不同的 goroutine 上,也只会调用一次 Do 方也处理传递进来的函数 。 这确实是因为我们将调用 sync.Once 方式执行 Do 方法。
把这种函数只能调用一次的功能放入标准包中似乎是件很奇怪的事情,但事实证明,这种需求经常出现。
使用 sync.Once有几件事需要注意。 让我们看另一个例子,你认为它会打印什么?
count := 0
incremenmt := func() {
count++
}
decrement := func() {
count --
}
once := sync.Once{}
once.Do(decrement)
once.Do(incremenmt)
fmt.Println("count: ",count)
输出如下:
count: -1
令人惊讶的是,输出显示的是 -1,而不是0?这是因为 sync.Once 只计算调用 Do方法的次数,而不是多少次唯一惆用 Do方法。这样, sync.Once的副本与所要调用的函数紧密偶合, 我们再次看到如何在一 个严格的范围内合理使用 sync 包中的类型以发挥最佳效果。建议通过将 sync.Once 包装在一个小的语法块中来形式化这种耦合:要么是一个小函数, 要么是将两者包装在一个结构体中 。
Pool(池)
池(Pool)是 Pool模式的并发安全实现。在较高的层次上, Pool 模式是一种创建和提供可供使用的固定数 量实例或 Pool 实例的方法。 它通常用于约束创建昂贵的场景 (如数据库连接),以便只创建固定数量的实例,但不确定数量的操作仍然可以请求访问这些场 景。 对于 Go语言的 sync.Pool,这种数据类型可以被多个 goroutine安全地使用 。
Pool 的主接口是它的 Get 方法。当调用时, Get 将首先检查池中是否有可用的实例返回给调用者,如果没有, 调用它的 new 方法来创建一个新实例 。当完成时,调用者调用 Put方法把工作的实例归还到池中,以供其他进程使用。下面有 一 个简单的例子来说明:
myPool := &sync.Pool{
New : func() interface{} {
fmt.Println("Create new instance.")
return "new my"
},
}
myPool.Get() //1
instance := myPool.Get() //1
myPool.Put(instance) //2
myPool.Get() //3
- 在这里调用 Pool 的 get 方陆。这些i周用将执行 Pool 中定义的 new 函数, 因为实例还没有实例化。
- 我们将先前检索到的实例放在池中,这就增加了实例的可用数量。
- 在执行此调用时,我们将重用以前分配的实例并将其放回池中。 New将不会被调用。
我们只看到两个对New 函数的调用:
Create new instance.
Create new instance.
那么,为什么要使用Pool,而不只是在运行时实例对象呢?Go语言是有GC的,因此实例化的对象将被自动清理。
另一种常见的情况是,用 Pool 来尽可能快地将预先分配的对象缓存加载启动。 在这种情况下,我们不是试图通过限制创建的对象的数量来节省主机的内存, 而是通过提前加载获取引用到另一个对象所需的时间,来节省消费者的时间。 这在编写高吞吐量网络服务器时十分常见,服务器试图快速响应请求。
然而,有些情况下要谨慎决定你是否应该使用 Pool:如果你使用 Pool 代码所需要的东西不是大概同质的,那么从 Pool 中转化检索到所需要的内容的时间可能比重新实例化内容要花费的时间更多。例如,如果你的程序需要随机和可变长度的切片,那么 Pool 将不会对你有多大帮助。你直接从 Pool 中获得一个 正确的切片的概率是很低的。
所以当你使用 Pool 工作时,记住以下几点:
- 当实例化 sync.Pool,使用 new方法创建一个成员变量,在i周用时是线程安全的。
- 当收到一个来自 Get 的实例时,不要对所接收的对象的状态做出任何假设。
- 当用完了一个从 Pool 中取出来的对象时, 一 定要调用 Put ,否则, Pool就无法复用这个实例了。通常情况下,这是用 defer 完成的。
- Pool 内的分布必须大致均匀。
channel
channel 是由 Hoare 的 CSP 派生的同步原语之 一。 虽然它们可以用来同步内存访问,但它们最好用于在 goroutine 之间传递信息。
就像河流一样, 一个 channel充当着信息传送的管道,值可以沿着 channel传递,然后在下游读出。当使用 channel 时,会将一个值传递给一个 channel 变量,然后在程序中的某个地方将它从 channel 中读出。程序中不同的部分不需要相互了解,只需要在 channel 所在的内存中引用相同的位置即可 。这可以通过对程序上下游 的 channel 引用来完成。
要声明一个单向 channel,只需包含<-操作符。要声明和实例化一个只能读取 的 channel,将<-操作符放在左侧,就像这样:
var dataStream <-chan interface{}
dataStream := make(<-chan interface{})
要声明并创建一个只能发送的 channel,将 <-操作符放在右侧,就像这样:
var dataStream chan<- interface{}
dataStream := make(chan<- interface{})
通常不会看到单向 channel 实例化,但是会经常看到它们用作函数参数和返回类型 ,和我们看到的一样,这是非常有用的。因为当需要时, Go语言会隐式地将双向 channel转换为单向 channel。下面有一个例子:
var receiveChan <-chan interface{}
var sendChan chan<- interface{}
dataStream := make(chan interface{})
//有效的语法
receiveChan = dataStream
sendChan = dataStream
channel 操作的结果给出了 channel 的状态:
| 操作 | channel 状态 | 结果 |
|---|---|---|
| Read | nil | 阻塞 |
| 打开且非空 | 输出值 | |
| 打开但空 | 阻塞 | |
| 关闭的 | <默认值>,false | |
| 只写 | 编译错误 | |
| 只写 | 编译错误 | |
| Write | nil | 阻塞 |
| 打开的但填满 | 阻塞 | |
| 打开的且不满 | 写入值 | |
| 关闭的 | panic | |
| 只读 | 编译错误 | |
| close | nil | panic |
| 打开且非空 | 关闭channel;读取成功,直到通道耗尽,然后读取产生值的默认值 | |
| 打开但空 | 关闭channel;读到生产者的默认值 | |
| 关闭的 | panic | |
| 只读 | 编译错误 |
如果检查这张表,我们会看到 一些可能导致麻烦的数据。我们有 三种操作可 以导致 goroutine 阻塞, 三种操作会导致程序 panic!乍一看,似乎 channel 可 能会有问题,但在研究了具体执行结果并确定了 channel 的使用方式之后,它 就变得不那么可怕了,并且开始变得有意义了。
我们应该做的第一件事是在正确的环境中配置 channel, 即分配 channel 所有权。我将把所有权定义为实例化、写入和关闭 channel 的 goroutine。就像没有 GC 的语言的内存一样,重要的是要弄清楚哪个 goroutine 拥有 channel, 以便从逻辑上推演我们的程序。单向 channel 声明的是一种工具,它将允许我 们区分 channel的拥有者和 channel的使用者:channel所有者对 channel (chan 或 chan<-) 有一个写访问视图,而 channel使用者只对 channel有一个只读视 图(<-chan) 。 一旦我们将 channel 所有者和非 channel 所有者区分开来,前面的表的结果自然就会很清晰,我们可以开始将责任分配给那些拥有 channel 的 goroutine和不拥有 channel 的 goroutine。
让我们从 channel 的所有者开始。 拥有 channel 的 goroutine应该具备如下:
- 实例化 channel。
- 执行写操作,或将所有权传递给另一个 goroutine。
- 关闭 channel。
- Ecapsulate 在此列表中的前三件事,并通过一个只读 channel 将它们暴露 出来。
通过将这些责任分配给 channel 所有者, 一 些事情发生了:
- 因为我们初始化了 channel,所以我们将死锁的风险转移到 nil channel 上。
- 因为我们初始化了 channel,所以我们通过关闭 一 个 nil channnel 来消除 panic 的风险 。
- 因为我们决定了 channel 何时关闭,所以我们通过写入一个关闭的 channel 来消除 panic。
- 因为我们决定了 channel 何时关闭,所以我们不止 一 次关闭 channel,从而消除了 panic 的风险。
- 我们在编译时使用类型检查器,以防止写入 channel 异常。
在读取 channel 时可能发生的阻塞操作。作为 一 个 channel 的消费者,只需要担心两件事:
- 知道 channel 是何时关闭的。
- 正确的处理阻塞 。
为了解决第一个问题,我们只需像之前说的那样从 read操作中检查第二个返回值。第二点更难定义,因为它取决于你的算法,可能想要超时,可能想要 停止消费,或者可能只是对阻塞进程的生命周期有需求。重要的是,作为二个消费者,应该知道读取是阻塞的事实。
select 语句
select 语句是将 channel 绑定在一起的黏合剂 ,这就是我们如何在一个程序中组合 channel 以形成更大的抽象事务的方式。如果 channel 是将 goroutine 连接在一起的黏合剂,那么声明 select的语句是做什么的呢?声明 select语句是一个具有并发性的 Go 语言程序中最重要的事情之一 ,这并不是夸大其词。在一个系统中两个或多个组件的交集中,可以在本地、单个函数或类型以及全局范围内找到 select语句绑定在一起的 channel。除了连接组件之外,在程序中的这些关键节点上 , select 语句可以帮助安全地将 channel 与诸如取消、 超时、等待和默认值之类的概念结合在一起。
那么这些强大的 select 语句是什么呢?我们如何使用它们,它们是如何工作的?让我们先把它放出来。这里有 一 个很简单的例子:
var c1, c2 <-chan interface{}
var c3 chan<- interface{}
select{
case <-c1:
//从c1读取 执行相关逻辑
case <-c2:
//从c2读取 执行相关逻辑
case c3 <- struct{}{}
//写入到c3 执行相关逻辑
}
它看起来有点像一个选择模块,不是吗?就像一个选择模块, 一个 select 模块包含一系列的 case语句,这些语句可以保护一系列语句。然而,这就是相似之处。与 switch 块不同, select 块中的 case 语句没有测试顺序,如果没有满足任何条件,执行也不会失败。
相反,所有的 channel 读取和写入都需要查看是否有任何一个已准备就绪可以用的数据:在读取的情况下关闭 channel,以及写入不具备下游消费能力的 channel。 如果所有 channel 都没有准备好,则执行 整个 select 语句模块 。当一个 channel 准备好了,这个操作就会继续,它相应的语句就会执行。来看一下下面的简单例子:
start := time.Now()
c := make(chan interface{})
go func(){
time.Sleep(5 * time.Second)
close(c)
fmt.Println("close ch")
}()
fmt.Println("Blocking on read ...")
select {
case <-c :
fmt.Printf("Unblocked %v later.\n",time.Since(start))
}
- 在等待 5s后关闭 channel。
- 尝试在 channel 上读取数据 。
输出如下:
Blocking on read ...
close ch
Unblocked 5.001251995s later.
如你所见,在进入 select 模块后大约 5 秒,我们就会解锁。这是一种简单而有效的方法来阻止我们等待某事的发生,但如果我们思考一下,我们可以提出一些问题:
- 当多 个 channel 有数据可供给下游读取的时候 会发生什么?
- 如果没有任何可用的 channel 怎 么办?
- 如果我们想要做一些事情,但是没有可用的 channels 怎么办?
多个 channel 同时是可用的这个问题似乎很有趣。 让我们试试, 看看会发生什么!
c1 := make(chan interface{});close(c1)
c2 := make(chan interface{});close(c2)
var c1Count,c2Count int
for i := 1000; i >= 0; i--{
select {
case <-c1:
c1Count++
case <-c2:
c2Count++
}
}
fmt.Printf("c1Count:%d\n c2Count:%d\n",c1Count,c2Count)
输出如下:
c1Count:500
c2Count:501
在 一千次选代中,大约有 一半的 时间从 c1读取 select 语句,大约一半的时间从c2读取。这看起来很有趣,也许有点太巧了。事实如此! Go 语言运行时将在一组 case 语句中执行伪随机选择。这就意味着,在 case 语句集合中,每一个都有一个被执行的机会。
乍一看,这似乎并不重要,但背后的原因却非常有趣。让我们先做一个很明显的阐述: Go 语言运行时无法解析 select 语句的意图, 也就是说,它不能推断出问题空间,或者说为什么将一组 channel 组合到 一 个 select 语句中。正因为如此,运行时所能做的最好的事情就是在平均情况下运行良好。 一 种很好的方法是将一个随机变量引入到等式中(在这种情况下, select 后续的 channel)。通过加权平均每个 channel 被使用的机会,所有使用 select 语句的程序将在平均情况下表现良好。
关于第二个问题:如果没有任何 channel 可用, 会发生什么?如果所有的 channel 都被阻塞了,如果没有可用的,但是你可能不希望永远阻塞,可能需要超时机制。 Go语言的 time包提供了一种优雅的方式,可以在 select语句中很好地使用 channel。下面里有一个例子:
var c <-chan int
select{
case <-c: //这个 case 语句永远不会被解锁,因为我们是从 nil channel 读取的。
case <- time.After(2 * time.Second):
fmt.Println("Time out.")
}
输出如下:
Time out.
time.After 函数通过传入time.Duration参数返回一个数值井写入 channel, 该 channel 会返回执行后的时间。这为 select 语句提供了一种简明的方法。
最后一个问题:当没有可用 channel 时,我们需要做些什么?像 case 语句一 样, select 语句也允许默认的语句default。当“select”语句中的所有 channel 都被阻塞的时候,“select”语句也允许调用default语句。
Go 语言的并发模式
约束
在编写并发代码的时候,有以下几种不同的保证操作安全的方告。我 们已经学习了其中两个:
- 用于共享内存的同步原语(如 sync.Mutex)。
- 通过通信共享内存来进行同步( 如 channel) 。
但是,在并发处理中还有其他几种情况也是隐式并发安全的:
- 不会发生改变的数据。
- 受到保护的数据。
从某种意义上讲,不可变数据是理想的,因为它是隐式地井行安全的。每个并发进程可能对相同的数据进行操作,但不能对其进行修改。如果要创建新数据, 则必须创建具有所需修改的数据的新副本。这不仅可以减轻开发人员的认知负担,并且可以使程序运行得更快,这将使程序的临界区减少(或者完全消除临界区)。在 Go语言中,可以通过编写利用值的副本而不是指向内 存值的指针的代码来实现此目的。“约束”还可以使开发人员减少临界区的长度以及 承担更小的认知负担。约束并发值的技术比简单传递值的副本要复杂一点。
“约束”是一种确保了信息只能从一个并发过程中获取到的简单且强大的方法。达到此目的时,并发程序隐式安全,不需要同步。有两种可能的约束:特定约束和词法约束。特定约束是指通过公约实现约束时 ,无论是由语言社区、 你所在的团队,还是你的代码库设置 。但是,坚持约束很难在任何规模的项目上进行协调,除非有工具在每次有人提交代码时对你的代码进行静态分析。
词主主约束涉及使用词住作用域仅公开用于多个并发进程的正确数据和并发原语。这使得做错事是不可能的。
for-select 循环
在 Go 语言程序中你会一遍又一遍地看到 for-select循环。它不过是这样的:
for { //要不就无限循环 , 要不就使用 日nge 语句循环
select {
// 使用channel进行作业
}
}
有以下几种情况你可以见到这种模式:
向 channel发送迭代变量
通常情况下,你需要将可迭代的内容转换为 channel 上的值。这不是什么幻想,通常看起来像这样:
for _,s := range []string{"a","b","c"}{
select {
case <- done:
return
case stringStream <- s:
}
}
循环等待停止
创建循环,无限循环直到停止的 goroutine很常见。这个有一些变化。选择哪一个纯粹是一种个人爱好。
第一种变体保持 select 语句尽可能短:
for{
select {
case <-done:
return
default:
}
//进行非抢占式任务
}
如果已经完成的 channel 未关闭,我们将退出 select 语句并继续执行 for 循环的其余部分。
第二种变体将工作嵌入到选择语句的default子句中:
for{
select{
case <-done:
return
default:
//进行非抢占式任务
}
}
当我们输入 select 语句时,如果完成的 channel 尚未关闭,我们将执行 default 子句。
这种模式没有什么别的了,但它在任何地方都会被用到,所以值得一提。
防止 goroutine 泄漏
oroutine廉价且易于创建,这是让 Go 语言这么富有成效的原因之一 。运行时将多个 goroutine 复用到任意数 量 的操作系统线程,以使我们不必担心该抽象级别 。但是 goroutine 还是需要消耗资源,而且 goroutine 不会被运行时垃圾回收,所以无论 goroutine 所占用的内存有多么的少,我们都不希望我们的进程对此没有感知。那么我们如何去确保他们被清理干净?
让我们从头开始,逐步思考这个问题:为什么一个 goroutine需要存在呢?我们确定 goroutine代表可能或不可能相互平行运转的工作单位。goroutine 有以下几种方式被终止 :
- 当它完成了它的工作 。
- 因为不可恢复的错误,它不能继续工作 。
- 当它被告知需要终止工作 。
我们可以很简单地使用前两种方法,因为这两种方法就隐含在我们的算法中, 但是“取消工作”又是怎样工作的呢?由于网络的影响, 事实证明这是最重要的一点:如果开始了一 个 goroutine,最有可能以某种有组织的方式与其 他几个 goroutine 合作。我们甚至可以将这种相互连接表现为一个图表 : 子goroutine 是否应该继续执行可能是以许多其他 goroutine 状态的认知为基础的。
goroutine(通常是 main goroutine)具有这种完整的语境知识应该能够告诉其子 goroutine 终止 。 现在让我们考虑如何确保一个子 goroutine 被清理。让我们从一个简单的 goroutine 泄漏开始:
doWork := func(strings <-chan string) <-chan interface{}{
completed := make(chan interface{})
go func(){
defer fmt.Println("doWork exited.")
defer close(completed)
for s := range strings{
fmt.Println(s)
}
}()
return completed
}
doWork(nil)
fmt.Println("Done.")
在这里,我们看到 main goroutine将一个空的 channel传递给了 doWork。因此, 子符串 channel 永远不会写入任何字符串,并且包含 doWork 的 goroutine将在此过程的整个生命周期中保留在内存中(如果我 们在 doWork 和 main goroutine 中加入了 goroutine,甚至会死锁)。
在这个例子中,这个过程的生命周期很短,但是在一个真正的程序中, goroutine 可以很容易地在一个长期生命的程序开始时启动 。在最糟糕的情况下, main goroutine可能会在其生命周期内持续的将其他的 goroutine设置为自旋,这会导致内存利用率的下降。
成功减轻这种情况的方法是在父 goroutine 和其子 goroutine 之间建立一个信号,让父 goroutine 向其 子 goroutine 发出信号通知。按照惯例,这个信号通常是一个名为 done 的只读 channel。父 goroutine 将 该 channel 传递给子 goroutine,然后在想要取消子 goroutine 时关闭该 channel。 例如:
doWork := func(done <-chan interface{},strings <-chan string) <-chan interface{} { //1
terminated := make(chan interface{})
go func() {
defer fmt.Println("doWork exited.")
defer close(terminated)
for {
select {
case s:= <-strings:
fmt.Println("s:",s)
case <-done: //2
fmt.Println("close")
return
}
}
}()
return terminated
}
done := make(chan interface{})
terminated := doWork(done, nil)
go func(){ //3
time.Sleep(2 * time.Second) //2秒后取消本操作
fmt.Println("Canceling doWork goroutine...")
close(done)
}()
<-terminated //4
fmt.Println("Done.")
- 在这里,我们将完成的 chann巳l传递给 doWork 函数。作为惯例,这个channel 是第一个参数。
- 在这一行上,我们看到了在实际编程中无处不在的 select模式。我们的一个案例陈述是检查我们的 done channel 是否已经发出信号。如果有的话, 我们从 goroutine返回。
- 在这里我们创建另一个goroutine,如果超过2s就会取消doWork中产生 的 goroutine。
- 这就是我们加入从 main goroutine的 doWork 中产生的 goroutine的地方。
Canceling doWork goroutine...
close
doWork exited.
Done.
可以看到,尽管我们给字符串 channel 中传递了 nil,我们的 goroutine 仍然成功退出。与之前的例子不同,在这个例子中,我们加入了两个 goroutine, 但没有造成死锁。这是因为在我们加入两个 goroutine 之 前,我们创建了第三个 goroutine来在 doWork执行 2s之后取消 doWork 中的 goroutine。我们已经成功消除了我们的 goroutine 泄漏!
前面的例子很好地处理了在 channel 上接收 goroutine 的情况,但是如果我们正在处理相反的情况:一 个 goroutine 阻塞了向 channel 进行写人的请求?以下是演示此问题的简单示例:
newRandStream := func()<-chan int{
randStream := make(chan int)
go func(){
defer fmt.Println("newRandStream closure exited.") //1
defer close(randStream)
for{
randStream <- rand.Int()
}
}()
return randStream
}
randStream := newRandStream()
fmt.Println("3 random ints:")
for i := 1; i <= 3; i++{
fmt.Printf("%d: %d\n",i,<-randStream)
}
- 这里我们在 goroutine成功终止时打印出一条消息。
运行此代码会产生:
3 random ints:
1: 5577006791947779410
2: 8674665223082153551
3: 6129484611666145821
可以从输出中看到 defer 语句中的 fmt.Println 语句永远不会运行。在循环的第三次迭代之后,我们的 goroutine试图将下一个随机整数发送到不再被读取的 channel。我们无法告诉生产者它可以停止。 解决方案就像接收案例一样, 为生产者 goroutine提供一个通知它退出的 channel:
newRandStream := func(done <-chan interface{})<-chan int{
randStream := make(chan int)
go func(){
defer fmt.Println("newRandStream closure exited.") //1
defer close(randStream)
for{
select {
case randStream <- rand.Int():
case <-done:
return
}
}
}()
return randStream
}
done := make(chan interface{})
randStream := newRandStream(done)
fmt.Println("3 random ints:")
for i := 1; i <= 3; i++{
fmt.Printf("%d: %d\n",i,<-randStream)
}
close(done)
time.Sleep(1 * time.Second)
输出如下:
3 random ints:
1: 5577006791947779410
2: 8674665223082153551
3: 6129484611666145821
newRandStream closure exited.
我们发现现在 goroutine 已经被正确地清理了。
现在我们知道如何确保 goroutine 不泄漏,我们可以规定一个约定:如果 goroutine 负责创建 goroutine,它也负责确保它可以停止 goroutine。这个约定有助于确保程序在组合和扩展时可以扩展。
or-channel
有时我们可能会发现自己希望将一个或多个完成的 channel合并到一个完成的 channel 中,该 channel 在任何组件 channel 关闭时关闭。编写一个执行这种耦合的选择语句是完全可以接受的,尽管很冗长 。但是,有时我们无法知道我们在运行时使用的已完成的 channel 的数量。在这种情况下,或者如果我们只喜欢单线程,就可以使用 or-channel 模式将这些 channel 组合在一起。
这种模式通过递归和 goroutine 创建一个复合 done channel。我们来看一下:
var or func(channels ...<-chan interface{}) <-chan interface{}
or = func(channels ...<-chan interface{}) <-chan interface{}{ //1
switch len(channels) {
case 0: //2
return nil
case 1: //3
return channels[0]
}
orDone := make(chan interface{})
go func(){ //4
defer close(orDone)
switch len(channels) {
case 2: //5
select {
case <-channels[0]:
case <-channels[1]:
default: //6
select {
case <-channels[0]:
case <-channels[1]:
case <-channels[2]:
case <-or(append(channels[3:],orDone)...):
}
}
}
}()
return orDone
}
- 这里,我们有我们的函数,或者,它采用可变的 channel 切片并返回单 个 channel。
- 由于这是一个递归函数,我们必须设置终止标准。首先,如果可变切片是空的,我们只返回一个空 channel。这是由于不传递 channel 的观点所产生的,我们不希望复合的 channel 做任何事情。
- 我们的第二个终止标准是如果我们的变量切片只包含一个元素,我们只返回该元素。
- 这是函数的主体,以及递归发生的地方。我们创建了一个 goroutine,以便我们可以不受阻塞地等待我们 channel 上的消息。
- 基于我们进行迭代的方式,每一次迭代调用都将至少有两个 channel。在 这里我们为需要两个 channel 的情况采用了约束 goroutine 数目的优化方法。
- 这里,我们在循环到我们存放所有 channel 的 slice 的第三个索引的时候, 我们创建了一个 or-channel 并从这个 channel 中选择了一个。这将形成一个由现有 slice 的剩余部分组成的树并且返回第一个信号量。为了使在建立这个树的 goroutine 退出的时候在树下的 goroutine 也可以跟着退出,我们将这个 orDone channel 也传递到了调用中。
这是一个相当简洁的函数,使我们可以将任意数量 的 channel 组合到单个 channel 中,只要任何组件 channel 关闭或写入, 该 channel 就会关闭。
这种模式在我们的系统中的模块交汇处非常有用。在这些交汇处,我们的调用堆中应该有复数种的用来取消 goroutine 的决策树 。 使用 or 函数,可以简单地将它们组合在一起并将其传递给堆栈。
错误处理
在并发程序中,错误处理可能难以正确进行。有时候,我们花了很多时间思考我们的各种 stage如何共享信息和进行协调,我们忘记考虑它们如何优雅地处理错误的状态。当 Go语言避开了流行的错误异常模型时,它声明错误处理非常重要,并且在开发我们的程序时,我 们应该给出我们的错误路径给予我们的 算法也同样的关注。
思考错误处理时最根本的问题是, “谁应该负责处理错误?”在某些时候 , 程序需要停止将错误输出来,并且实际上对它做了些什 么。这么做的目的是什么?
在并发进程中,这个问题变得更复杂一些 。因为并发进程独立于其父进程或兄弟进程运行,所以它可能很难推断出错是正确的 。看下面的代码以查看此问题的示列:
checkStatus := func(done <-chan interface{},urls ...string)<-chan *http.Response{
responses := make(chan *http.Response)
go func(){
defer close(responses)
for _,url := range urls{
resp,err := http.Get(url)
if err != nil{
fmt.Println("url-err:",err) //1
continue
}
select {
case <-done:
return
case responses <- resp:
}
}
}()
return responses
}
done := make(chan interface{})
defer close(done)
urls := []string{"https://www.baidu.com","https://www.google.com","https://www.csdn.net"}
for response := range checkStatus(done,urls...){
fmt.Printf("Response:%v\n",response.Status)
}
- 在这里,我们看到 goroutine在尽最大努力表示出现错误。它还能做什么?在去传回!有多少错误才是太多?它是否继续提出要求?
运行代码输出如下:
Response:200 OK
url-err: Get "https://www.google.com": dial tcp 142.251.43.4:443: i/o timeout
Response:200 OK
这里,我们看到在这个问题上 goroutine 没有选择。它不能简单地吞下错误, 因此它只能做出明智的事情:它会打印错误并希望某些内容被关注。不要把我们的 goroutine 放在这个尴尬的位置。我们应该分开我们的顾虑:一般来说,并发进程应该把他们的错误发送到程序的另一部分 ,它有程序状态的完整信息,并可以做出更明智的决定做什么。以下示例演示了此问题的正确解决方案:
type Result struct { //1
Error error
Response *http.Response
}
checkStatus := func(done <-chan interface{},urls ...string)<-chan Result{//2
results := make(chan Result)
go func() {
defer close(results)
for _,url := range urls{
resp,err := http.Get(url)
result := Result{ //3
Error: err,
Response:resp,
}
select {
case <- done:
return
case results <- result: //4
}
}
}()
return results
}
done := make(chan interface{})
defer close(done)
urls := []string{"https://www.baidu.com","https://www.csdn.net","https://www.google.com"}
for result := range checkStatus(done,urls...){
if result.Error != nil{ //5
fmt.Printf("error: %v",result.Error)
continue
}
fmt.Printf("Response: %v\n",result.Response.Status)
}
- 在这里 ,我们创建一个包含 * http. Response 和从我们的 goroutine 中的 循环迭代中可能出现的错误的类型。
- 该行返回一个可读取的 channel,以检索循环迭代的结果。
- 在这里,我们创建一个 Result 实例,并设置错民和响应宇段。
- 这是我们将结果写入我们的 channel 的地方。
- 在这里 ,在我们的 main goroutine 中,我们能够智能地处理由 checkStatus 启动的 goroutine 中出现的错误,以及更大程序的完整背景。
输出如下:
Response: 200 OK
Response: 200 OK
error: Get "https://www.google.com": dial tcp 142.251.43.4:443: i/o timeout%
这里要注意的关键是我们如何将潜在的结果与潜在的错误结合起来。这表示从 goroutine checkStatus 创建的完整可能结果集,并且允许我们的主要常规关于发生错误时做什么的决定。 从更广泛的角度来说,我们已经成功地将错误处理的担忧从我们的生产者 goroutine 中分离出来。这是可取的,因为生成 goroutine 的 goroutine(在这种情况下是我们的 main goroutine)具有更多关于正在运行的程序的上下文,并且可以做出关于如何处理错误的更明智的决定。
pipeline
当我们编写一个程序时,可能不会坐下来写一个长函数,也不推荐这样做! 应该以函数、结构体、方法等形式构造抽象。为什么要这样做?部分是为了抽象出与大流量无关的细节,另一部分是为了能够在不影响其他区域的情况下处理一个代码区域。我们有没有必要对系统进行更改并发现我们必须触及多个领 域才能做出一个合乎逻辑的改变?这可能是因为该系统有糟糕的抽象 。
pipeline 是我们可以用来在系统中形成抽象的另一种工具。特别是,当我们的程序需要流式处理或批处理数据时,它是一个非常强大的工具。pipeline 只不过是一系列将数据输入,执行操作并将结果数据传回的系统。我们称这些操作都是 pipeline 的一个 stage。
通过使用 pipeline,我们可以分离每个 stage 的关注点,这提供了许多好处。我们可以相互独立地修改 各个 stage,我们可以混合搭配 stage 的组合方式,而无需修改stage,我们可以将每个 stage 同时处理到上游或下游 stage,并且可以扇出或限制部分我们的 pipeline。
如前所述,一个 stage 只是将数据输入,对其进行转换并将数据发回 。这是一 个可以被视为 pipeline stage 的函数:
multiply := func(values []int, multiplier int)[] int{
multipliedValues := make([]int,len(values))
for i,v := range values{
multipliedValues[i] = v * multiplier
}
return multipliedValues
}
构建 pipeline 的最佳实践
channel 非常适合 在 Go 语言中构建 pipeline,因为它们满足了我们所有的基本要求。它们可以接受和产生值,可以安全地同时使用 ,还可以被放弃,它们被语言所证实。我们看一下下面的例子:
func generator (done <-chan interface{},integers ...int)<-chan int{
intStream := make(chan int)
go func(){
defer close(intStream)
for _,i := range integers{
select {
case <-done:
return
case intStream <- i:
}
}
}()
return intStream
}
func multiply(done <-chan interface{},intStream <-chan int,multiplier int)<-chan int{
multipliedStream := make(chan int)
go func(){
defer close(multipliedStream)
for i := range intStream{
select {
case <-done:
return
case multipliedStream <- i*multiplier:
}
}
}()
return multipliedStream
}
func add(done <-chan interface{},intStream <-chan int,additive int) <-chan int{
addStream := make(chan int)
go func(){
defer close(addStream)
for i := range intStream{
select {
case <- done:
return
case addStream <- i+additive:
}
}
}()
return addStream
}
done := make(chan interface{})
defer close(done)
intStream := generator(done,1,2,3,4)
pipeline := multiply(done,add(done,multiply(done,intStream,2),1),2)
for v := range pipeline{
fmt.Println(v)
}
输出如下:
6
10
14
18
我们来看看我们写的是什么。我们现在有三个函数,而不是两个。它们都看起来像是在他们的函数体内开始了 一 个 goroutine,并使用了“防止goroutine泄露”中建立的模式。通过一个channel表示该 goroutine应该退出。它们看起来都像是返回 channel, 其中一些看起来像 是在另外一个 channel 中 。 很有趣!让我们开始进一步分解 :
done := make(chan interface{})
defer close(done)
我们的程序所做的第一件事是创建一个 done channel,并在 defer语句中关闭它。这可以确保我 们的 程序干净地离开,不会泄漏 goroutine。接下来,我们来看看函数 generator:
func generator (done <-chan interface{},integers ...int)<-chan int{
intStream := make(chan int)
go func(){
defer close(intStream)
for _,i := range integers{
select {
case <-done:
return
case intStream <- i:
}
}
}()
return intStream
}
generator 函数接受一个可变的整数切片,构造一个缓存长度等于输入整数片段的整数 channel,启动一个 goroutine井返回构造的 channel。 然后,在创建的 goroutine 上, generator 函数使用 range 语句遍历传入的可变切片,并在其创建的 channel 上发送切片的值。
请注意, channel 上的发送与完成 channel上的选择共享一条 select 语句。再一次,就是防止 goroutine泄漏”中建立的模式,以防止泄 漏 goroutines。
简而言之, generator函数将一组离散值转换为一个channel上的数据流。适 当地说,这种类型的功能称为生成器。在使用流水线时,会经常看到这一点, 因为在流水线开始时, 我们总是会有一些需要转换为 channel 的数据。接下来, 构建我们的 pipeline:
pipeline := multiply(done, add(done, multiply(done, intStream, 2), 1), 2)
这与我们一直在努力的流水线相同:对于一串数字,我们将它们乘以 2,加 1,然后将结果乘以 2。这个 channel 与我们前面例子中使用函数的 channel,但 它在很重要的方面有所不同 。
首先,我们正在使用 pipeline。这是显而易见的,因为它允许两件事情:在我们的 pipeline 的末尾,我们可以使用范围语句来提取值, 并且在每个 stage 我们可以安全地同时执行,因为我们的输入和输出在 并发上下文中是安全的。
这给我们带来了第二个不同之处:pipeline的每个stage都在执行控制。这意味着任何 stage 只需要等待其输入,并且能够发送其输出 。事实证明 ,这会产生巨大 的影响。
扇入,扇出
有时候, pipeline 中的各个 stage 可能在计算上特别昂贵 。 发生这种情况时, 我们的 pipeline 中的上游 stage 可能会被阻塞,同时等待昂贵的 stage 来完成。不仅如此, pipeline 本身可能需要很长时间才能全部执行。我们如何解决这个问题?
pipeline 的一个有趣属性是它们能够让你使用独立的,并且可以常常重新排序的 stage 的组合来操作数据流。甚至可以多次重复使用 pipeline 的各个 stage。在多个 goroutine 上重用我们的 pipeline 的单个 stage 以试图并行化来自上游 stage 的 pull 是不是很有趣?也许这将有助于提高 pipeline 的性能。
事实上,事实证明它可以,而这种模式有一个名字:扇人,扇出 。
扇出是一个术语,用于描述启动多个 goroutines 以处理来自 pipeline 的输入的过程,并且扇人是描述将多个结果组合到一个 channel 的过程中的术语 。
那么什么时候一个 pipeline 的 stage 适合利用这种模式呢?如果以下两种情况适用,你可以考虑在某个 stage 使用:
- 它不依赖于之前 stage计算的值。
- 运行需要很长时间。
循序独立性很重要,因为我们无法保证我们的 stage 的并发副本队何种顺序运行,也无法保证其返回的顺序 。
简而言之,扇入涉及创建用户将读取的多路复用 channel,然后为每个传人 channel启动一个 goroutine,以及在传入 chann巳l全部关闭时关闭复用 channel 的 goroutine。由于我们要创建一个等待 N 个其他分区完成的 goroutine,创建 一个 sync.WaitGroup 来协调是很有意义的。多路复用功能还通知 WaitGroup 它己完成。
or-done-channel
有时候,我们需要处理来自系统各个分散部分的 channel 与 pipeline 所不同的是,我们不能对一个被 done channel所取消的 channel将会进行什么行为做任何的断言。 也就是说,我们不知道我们的 goroutine是否被取消,这意味着我们正在读取的 channel 将被取消 。 出于这个原因,我们需要用channel中的select语句来包装我们的读操作,并从已完成的channel中进行选择。这样做需要的代码很容易读取,如下所示:
for val := range myChan{
}
tee-channel
有时候我们可能想分割一个来自channel 的 值,以便将它们发送到我们的代码两个独立区域中。设想一下,一个传递用户指令的channel:可能想要在一个channel上接收一系列用户指令,将它们发送给相应的执行器,并将它们发送给记录命令以供日后审计的东西。
从类 UNIX 系统中的tee 命令中获得它的名字,tee-channel就是这样的做的。可以将它传递给一个读channel,并且返回两个单独的channel,以获得相同的值。
conttext 包
在并发程序中,由于超时,取消或系统其他部分的故障往往需要抢占操作。我们已经看过了创建 done channel 的习惯用法,该channel在我们的程序中流动并取消所有阻塞的并发操作。这很好,但它也是有限的。
如果我们可以在简单的通知上附加传递额外的信息以取消:为什么取消发生,或者我们的函数是否有需要完成的最后期限(超时),这将非常有用。
事实证明,对于任何规模的系统来说,使用这些信息来包装已完成的频道是非常常见的,因此 Go 语言的作者们决定为此创建一个标准模式。它起源于一 个在标准库之外的实验功能,但是在 Go 1.7 中, context 包被引入标准库中, 这使得它成为考虑并发问题时的一个标准的风格 。
如果看一下上下文包,我们看到它非常简单:
var Canceled = errors.New(context canceled")
var DeadlineExceeded error = deadline.ExceededError{}
type CancelFunc type Context
func Background() Context
func TODO() Context
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc) func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) func WithValue(parent Context, key, val interface{}) Context
context 类型,这是通过系统流动的类型,就想done channel一样。如果是使用上下文包,那么位于顶级并发调用下游的每个函数都将会context作为其第一个参数。类型如下所示:
type Context interface {
// 当为该 context工作的川rk被取消时, deadline将返回时间。在没有设定期限的情况下, //deadline 返回 ok==false。连续的 i用用 deadline 返回相同的结果
Deadline() (deadline time.Time, ok bool)
// 当为该 context 工作的 work 被取消肘,返回一个关闭的 channel。 如果这个 context // 不能被取消,那么 Done 可能返回 niL 连续调用完成返回相同的值
Done ( ) <-chan struct {}
// Err 在完成后返回一个 non-nil 值。如果 context 被取消,或者在 context
//的 deadline 结束时,如果 context 被取消 , Err 将被取消。没有定义 Err 的其他值 。连续惆 //结束后 , 用 Err 返回相同的值
Err() error
//值返回与此context关联的key或者nil,如果没有与键关联的值, 则返回值为nil。
//连续惆用具有相同 key的值将返回相同的结果
Value(key interface{}) interface{}
这看起来也很简单。有一个 Done 方法返回当我们的函数被抢占时关闭的 channel。还有一些新的但易于理解的方法 : 一个 Deadline 函数,用于指示在一定时间之后 goroutine是否会被取消,以及一个 Err方怯,如果 goroutine 被取消,将返回非零。但 Value 方法看起来似乎有点不合适。这是为了什么呢?
Go 语言作者们注意到, goroutine 的主要用途之一是为请求提供服务的程序 。 通常在这些程序中,除了抢占信息之外,还需要传递特定于请求的信息。这 是 Value 函数的目的。 我们需要知道上下文包有两个主要目的:
- 提供一个可以取消你的调用图中分支的 API。
- 提供用于通过呼叫传输请求范围数据的数据包。
让我们关注第一个方面:取消 。
函数中的取消有三个方面:
- goroutine 的 父 goroutine 可能想要取消它。
- 一 个 goroutine 可能想要取消它的子 goroutine。
- goroutine 中的任何阻塞操作都必须是可抢占的,以便它可以被取消。
context 包帮助管理所有这 三个东西。
正如我们所提到的 , context 类型将是函数的第一个参数。 如果你看看 context 接口上的方法,就会发现没有任何东西可以改变底层结构的状态。 此外,接收 context 的函数并不能取消它。这保护了调用堆枝上的函数被子函数取消上下文的情况。结合 done channel 提供的完成函数,这允许上下文类型安全地管理其前件的取消。
这就产生了一个问题:如果 context是不可变的,那么我们如何影响调用堆栈中当前函数下面的函数中的取消行为?
这是 context 包中的功能变得重要的地方。让我们再看看其中的几个,来刷新我们的印 象:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
请注意,所有这些函数都接受 一 个 Context 参数,并且返回 一 个 Context。 其中一些还有其他的参数,如截止时间和超时参数。这些函数都使用与这些函数相关的选项来生成 Context 的新实例。
WithCancel返回一个新的 Context,它在调用返回的 cancel 函数时关闭其 done channel。 WithDeadline返回一个新的 Context,当机器的时钟超过给定的最后期限时,它关闭完成的 channel。 WithTimeout返回一个新的 Context ,它在给定的超时时间后关闭其完成的 channel。
如果我们的函数需要以某种方式在调用图中取消它后面的函数 ,它将调用其中一个函数并传递给它的上下文,然后将返回的上下文传递给它的子元素。如果我们的函数不需要修改取消行为,那么函数只传递给定的上下文。
通过这种方式,调用图的连续图层可以创建符合其需求的上下文,而不会影响其父母节点。这为如何管理调用图的分支提供了 一个非常可组合的优雅解决方案。
context 包就是本着这种精神来串联起我们程序的调用图的。在面向对象的范例中,通常将对经常使用的数据的引用存储为成员变 量 ,但重要的是不要使 用 context.Context 的实例来执行此操作。 context.Context 的实例可能与外部看起来相同,但在内部它们 可能会在每个校帧更改。出于这个原因,总是将 context 的实例传递给我们的函数是很重要的。通过这种方式,函数具有用于它的上下文,而不是用于堆栈 N 的上下文。
在异步调用图的顶部,我们的代码可能不会传递上下文。要启动链,上下文包提供了两个函数来创建上下文的空实例:
func Background() Context
func TODO() Context
Background() 只是返回 一个空的上下文。 TODO() 不是用于生产,而是返回一个空的上下文。 TODO () 的预期目的是作为 一 个占位符,当不知道使用哪个上下文,或者希望代码被提供一个上下文,但上游代码还没有提供。
大规模并发
异常传递
编写并发代码,特别是在分布式系统中,系统中非常容易出现一些奇怪问题,并且难以理解为什么会发生这种情况。为了将自己、团队、用户从众多的痛苦中拯救出来,需要仔细考虑异常( error)是如何通过 分布式系统传递的,以及问题最终将如何呈现给使用者。
许多开发人员有个误解,认为在系统流程中异常的传递并不是那么重要。他们通常会谨慎的考虑数据会如何经过系统,但是却轻易的容忍异常,未经过思考就将异常从栈中抛出,最终导致异常直接展示在了用户面前。 Go 语言试图纠正这种不良习惯,强制开发人员处理调用栈上的每个关键点的异常,但是在系统控制流中将异常视为不太重要仍然 是一种常见的行为 。其实只需要一点计划和非常小的代价,就可以将异常控制在系统范围内,优化我们的用户体验。
首先让我们来明确异常是什么,什么时候发生,提供了那些好处。
出现异常表示着我们的系统进入了 一 个无怯满足用户操作的状态,这个操作可能是显式的,也可能是隐式的。这时’系统需要传达几个关键的信息:
-
发生了什么
这部分异常信息包含了对异常事件的描述。例如: “磁盘已楠’,“连接被重置”, “证书过期”。这些信息可能是被一些代码隐式的表达出来的, 可以用 一些上下文来修饰这些信息来帮助用户理解发生了什么问题。
-
发生在什么时间、什么位置
异常应当总是包含完整的检轨迹信息,从调用的启动方式开始,以异常的实例结尾。栈轨迹信息不应该包含在异常消息中(这一点尤为重要),但当需要处理栈中的异常时应该很容易被找到。
更进一步讲,异常应当包含有关其内部运行的上下文信息。例如,在分布式系统中,异常应该有一些字段用来识别发生异常的机器。发生异常后, 这些信息会对诊断系统故障原因非常有价值 。
此外, 异常还应包含对应机器上的时间,并且最好是 UTC 时间。
-
对用户友好的信息
应当对展现给用户的异常信息进行自定义,以适应系统和用户。这些信息应该只包含前两点的概述以及相关信息。对用户友好的信息是从用户的角度考虑,给出一些信息,说明这些问题是否是暂时的,并且最好是一行以内的文本。
-
告诉用户如何获得更多的信息
在某些情况下,用户希望知道当异常发生时,具体发生了哪些故障。
给用户的异常信息应当提供一个 ID,利用这个 ID 可以查询到对应的详细日志。这个详细日志应显示异常的完整信息:发生异常的时间(而不是异常记录的时间),异常创建时完整的堆栈调用。包含一个堆栈轨迹的 hash 也有助于聚合这些异常,就像 bug 追踪器那样跟踪问题。
默认状态下,如果我们不介入,异常信息不会包含上述所有的信息。因此,我们应当保持这样一种观念,任何展现给用户的异常信息如果没包含这些信息, 不是出错了就是有 bug。这引出了一个可以用来处理异常的通用模型。所有的异常都几乎都能归为以下两种分类之一:
- Bug
- 已知信息(例如:网络连接端口,磁盘写入失败等)。
超时和取消
在井发代码运行时,超时(Timeouts)和取消(Cancellation)会频繁出现。
那么,我们为什么希望我们的并发程序支持超时呢?这里有几个原因:
-
系统饱和
如果我们的系统已经饱和(即它的处理请求的能力刚好足够处理),我们可能希望超出的请求返回超时, 而不是花很长的时间等待响应。采取的应对方式取决于我们的问题空间, 下面是一些关于何时应当超时的一般性指导:
- 请求在超时时不太可能重复。
- 没有资源来存储请求 (例如,内存队列的内存,持久队列的磁盘空间) 。
- 如果对系统的响应或请求发送数据有时效性的要求。如果一 个请求可能会重复,超时会额外增加一个请求和超时的消耗。如果开销超过我们系统的容量,这可能会导致系统若机。不管怎样,如果我们缺少将请求存储在队列中所需的系统资橱,那也是没有意义的。即便我们符合这两个指导方针,只要我们能及时处理, 让请求进入排队中意义 也不大。这给我们带来了下一个支持超时的理由。
-
陈旧的数据
数据通常有一个窗口期, 一般是在这个窗口中必须先处理更多的相关数据, 或者处理数据的需求已经过期。 如果一个并发进程处理数据需要的时间比这个窗口期更长,我们会想返回超时并取消并发进程。例如,如果我们的并发进程在长时间的等待之后 响应请求,则在排队中的请求或其数据可能已经过时。
如果事先知道这个窗口时间,那么将 cont ext.W ithDeadline或context.WithTimeout 创建的 context.Context 传递给我们的并发进程是有意义的。如果事先不知道窗口,我们希望并发进程的父节点能够在请求不再需要时取消并发进程 。 context.WithCancel 是达到这个目的的最佳选择。
-
试图防止死锁
在大型系统中,尤其是分布式系统中,有时难以理解数据流动的方式,或者可能出现的罕见情况。为了保证系统不会发生死锁,建议在所有并发操作中增加超时处理。超时时间不一定要接近执行并发操作所需的实际时间。 不过超时的目的只是为了防止死锁,所以需要它足够短,使死锁的系统在合理的时间内解除阻塞即可。
以上内容使我们知道了,尝试通过设置超时可以将一个死锁系统转变为一 个活锁系统。不过,在大型系统中,由于存在更多灵活的组件,在系统死锁后,我们的系统更可能会遇到时序配置不同步的情况。因此,最好是在允许的时间内尽可能修复活锁,好过发生死锁后只有通过重新启动才能恢复系统。
请注意,这不是如何正确构建系统的建议,而是关于如何建立一个对时间问题有容错 能力的系统,这些错误在开发和测试过程中可能不容易遇到。 建议将超时设置在适当的位置,但是目标应该是在没有触发超时的情况下处理完所有的请求。
现在我们已经掌握应当何时使用超时了,让我们把注意力转向取消,以及如何建立一个并发处理来优雅地处理取消 。并发进程可能被取消的原因有很多:
-
超时
超时是隐式取消。
-
用户干预
为了获得良好的用户体验,通常建议维持一个长链接,然后以轮询问隔将 状态报告给用户,或允许用户查看他们认为合适的状态。 当用户使用并发程序时,有时需要允许用户取消他们已经开始的操作。
-
父进程取消
对于这个问题,如果任何一种井发操作的父进程停止,那子进程也将被取消。
-
复制请求
我们可能希望将数据发送到多个并发进程,以尝试从其中一个进程获得更快的响应。 当第一个回来的时候,我们就会取消其余的进程。
心跳
心跳是并发进程向外界发出信号的一种方式。在设计井发程序时,一定要考虑到超时和取消。
在井发编程中,有几个的原因使心跳变得格外有趣。它允许我们对系统有深入的了解,当系统工作不正常肘,它可以对系统进行测试。
下面我们将学习两种不同类型的心跳:
- 在一段时间间隔内发出的心跳。
- 在工作单元开始时发出的心跳 。
在一段时间间隔上发出的心跳对并发代码很有用,尤其是当它在处于等待状态。 因为我们不知道新的事件什么时候会被触发,我们的 goroutine可能会在等待某件事情发生的时候挂起。 心跳是告诉监听程序一切安好的一种方式,而静默状态也是预料之中的。
下面的代码演示了一个会发出心跳的 goroutine:
package main
import (
"fmt"
"time"
)
func main(){
done := make(chan interface{})
time.AfterFunc(10 * time.Second,func(){close(done)}) //1 声明一个标准的 done channel,并在 10秒后关闭。这给了我们的 goroutine 做一些工作的时间 。
const timeout = 2 * time.Second //2 设置了超时时间。 我们使用此方法将心跳间隔与超时时间联系起来。
heartbeat, results := doWork(done,timeout/2) //3 在这里 timeout/2。这使我们的心跳有额外的响应时间,以便我们的 超时不太敏感。
for{
select {
case _,ok := <-heartbeat: //4 在这里,我们处理心跳 。当 没有消息时,我们至少知道每过 timeout/2 的 时间 会从 心跳 channel 发出 一条 消息。如果我们什么都没有收到,我们便 知道是 goroutine 本身出了问题 。
if ok == false{
return
}
fmt.Println("pulse")
case r,ok := <-results: //5 在这里,我们处理 results channel;这里没什么特别的 。
if ok == false{
return
}
fmt.Printf("results %v\n",r.Second())
case <-time.After(timeout): //6如果我们没有收到心跳或其他消息,就 会超 时 。
return
}
}
}
func doWork(done <-chan interface{},pulseInterval time.Duration)(<-chan interface{},<-chan time.Time){
heartbeat := make(chan interface{}) // 1 我们建立了一个发送心跳的 channel 。 我们把这个返回给 doWork。
results := make(chan time.Time)
go func(){
defer close(heartbeat)
defer close(results)
pulse := time.Tick(pulseInterval) //2 我们设定心跳的问隔时间为我们接到的 pulselnterval。 每隔 一 个 pulselnterval 的时长都会有一些东西读取这个 channel。
workGen := time.Tick(2 * pulseInterval) //3 这 是另一个用来模 拟滴 答声的 channel。 我们选择的持 续 时间 大于 pulseInterval,这样我们就能看到从 goroutine 中发出的一些心跳。
sendPulse := func(){
select {
case heartbeat <- struct{}{}:
default: // 4 注意,这里我们加入了一个默认语句。 我们必须时刻警惕这样一个事实: 可能会没有人接收我们的心跳。从 goroutine 发出的信息是 重要 的,但心 跳却不一定重要。
}
}
sendResult := func(r time.Time){
for {
select{
case <-done:
return
case <-pulse: //5 就像 done channel 一样,当你执行发送或接收时 , 你也需要包含一个发送心跳的分支。
sendPulse()
case results <- r:
return
}
}
}
for {
select {
case <-done:
return
case <-pulse: //5
sendPulse()
case r := <- workGen:
sendResult(r)
}
}
}()
return heartbeat,results
}
复制请求
对于某些应用来说,尽可能快地接收晌应是重中之重。 例如,程序正在处理用户的 HTTP 请求,或者检索 一个数据块。在这些情况下,可以进行权衡 : 可以将请求分发到多个处理程序(无论是 goroutine,进程,还是服务器), 其中一个将比其他处理程序返回更快,就可以立即返回结果。 缺点是为了维持多个实例的运行,将不得不消耗更多的资源。
如果这种复制是在内存中进行的,消耗则没有那 么 大 , 但是如果多个处理程序需要多个进程,服务器甚至是数据中心,那可能会变得相当昂贵。 所以我们需要决定这么做是否值得。
速率限制
如果你曾经使用过一个API服务, 那么你可能了解过速率限制,它限制了某种资源在某段时间内被访问的次数。资源可以是任何东西:API 连接,磁盘 读写,网络包,异常。
为什么要在服务中加入速率限制?为什么不允许不受限制地访问系统?通常对系统进行限速,可以避免我们的系统被攻击。 如果恶意用户可以在资漉允许的情况下频繁访问系统,他们可以做各种各样的事情。
例如,他们可以使用日志或有效请求来占满服务器的磁盘。如果错误地配置了日志转发,它们甚至可以在执行一些恶意的操作后发出足够的请求,将所有的恶意操作记录从日志中挤出,转发到/ dev/null l书。他们可能试图暴力访问资源,或者他们仅仅是执行分布式拒绝服务攻击( DDoS)。重点是:如果不对系统进行限速,则无法轻松保护它。
可能被恶意利用不是唯一的原因。在分布式系统中,即使是合法用户,如果他们正在以足够大的量级执行操作或者正在运行的代码是异常的, 也可能会降低系统的可用性,从而对其他用户的使用造成影响。通常情况下,我们希望向用户提供某种类型的性能保证,这些性能可以保持一致。如果任意一个用户都可以影响这个平衡,那无疑是非常糟糕的。正常情况下用户对系统的访问应当被沙盒化,既不会影响其他用户的活动,也不会受到其他用户的影响。如果打破了这种思维模式,会使用户感觉我们的系统设计不够好。
治愈异常的 goroutine
在长期运行的后台程序中,经常会有一些长时间运行的 goroutine。这些 goroutine 经常处于阻塞状态, 等待数据以某种方式到达,然后唤醒它们,进行一些处理,再返回一些数据。有时候,这些 goroutine依赖于一些控制不太好的资源。也许一个 goroutine 需要从接收到的请求中提取数据,或者它正在监听一个临时文件。问题在于,如果没有外部干预,一个 goroutine 很容易进入一个不正常的状态,井且无法恢复。 抛开这些担忧 , 甚至可以说, goroutine本身不应该关心其如何从一个异常状态回复过来。在一个长期运行的程序中,建立一个机制来监控我们的 goroutine是否处于健康的状态是很用的, 当他们变得异常时 ,就可以尽快重启。我们将这个重启 goroutine的过程称为“治 愈”( Healing) 。
为了治愈 goroutine ,我们需要使用心跳模式来检查我们正在监控的 goroutine 是否活跃。 心跳的类型取决于你想要监控的内容,但是如果你的goroutine有 可能 会产生活锁,确保心跳包含某些信息, 表明该 gouroutine 在正常的工作而不仅仅是活着 。
我们把监控 goroutine 的健康这段逻辑称为管理员,它监视一个管理区的 goroutine。如果有 goroutine变得不健康,管理员将负责重新启动这个管理区 的 goroutine。 为此, 需要引用一个可以启动 goroutine 的函数。
goroutine 和 Go 语言运行时
工作窃取
Go 语言将为我们调度多个 goroutine,使其在系统线程上运行。它使用的算也被称 为工作窃取策略。怎么理解这个概念呢?
首先,我们来看一下在跨多处理器共享工作的朴素策略,有时也被称为公平调度策略 。 为了确保所有 CPU 有相同的使用率,我们可以在所有可用的处理器之间平均分配负载。
Go 语言遵循 fork-join 模型进行并发。在 goroutine 开 始的时候 fork, join 点是两个或更多的 goroutine 通过 channel 或 sync 包中的类型进行同步时。工作窃取算法遵循一些基本原则。对于给定的线程:
-
在 fork 点,将任务添加到与线程关联的双端队列的尾部。
-
如果线程空闲,则在取一个随机的线程,从它关联的双端队列头部窃取工作。
-
如果在未准备好的 join 点(即与其同步的 goroutine 还没有完成),则将工作从线程的双端队列尾部出栈。
-
如 果线程的双端队列 空的,则:
a. 暂停加入。
b. 从随机线程关联的双端队列中窃取工作。
窃取任务还是续体
事实上我们掩盖了一个问题,那就是我们应该让什么样的任务进行排队和窃取。在 fork-join 模式下,有两种选择:新任务和续体。
Go 语言的调度器有三个主要的概念:
-
G
goroutine。
-
M
OS 线程 (在惊代码中也被称为机器)。
-
P
上下 文 (在惊代码中也被称为处理 器 ) 。
在我们关于工作窃 取的讨论中, M 等于T, GOMAXPROCS这个环境变量,可以改变分配数量) 。 G是一个 goroutine,但是 记住它只代表 goroutine 的当前状态,最明显的是它的程序计数器( PC)。 G 相当于一个计算续体,使 Go语言可以实现续体窃取。
在 Go 语言的运行时中,首先启动 M ,然后是 P,最后是调度运行 G:
