RNN模型与NLP应用笔记(4):LSTM模型详解与完整代码实现
一、写在前面
书接上回,本文开始讲解LSTM的基础内容,同时讲解使用Keras实现LSTM的关键代码以及完整实现。同样是参考李沐大佬和王树森教授的相关课程内容。
目录
一、写在前面
二、引言
三、LSTM基础知识
四、核心代码详解
五、完整代码实现
六、总结
七、参考文献
二、引言
Long short-term memory LSTM是一种RNN模型,是对Simple RNN的改进,LSTM可以避免梯度消失的问题,可以有更长的记忆。
LSTM的论文在1997年发表,也是一种循环神经网络,原理跟simple RNN差不多。如图,每当读取一个新的输入x就会更新状态h,LSTM的结构比Simple RNN要复杂很多,Simple RNN只有一个参数矩阵,LSTM有四个参数矩阵,接下来我们具体来看的LSTM的内部结构。

三、LSTM基础知识
如图,LSTM最重要的设计是这个传输带,记为向量c,过去的信息通过传输带直接送到下一个时刻,不会发生太大的变化,LSTM就是靠传输带来避免梯度消失的问题。

如图,LSTM中有很多个Gate,可以有选择的让信息通过,先来看一下forget gate(遗忘门),遗忘门有sigmoid函数和Elementwise multiplication两部分组成。
(1)Sigmoid函数
输入sigmoid的是一个向量a,sigmoid作用到向量a的每一个元素上,把每一个元素都压到[0,1]之间

举个例子,假如a是下图的向量1,3,0,-2,那么sigmoid函数分别作用在这四个元素上,分别输出0.73、0.95、0.5、0.12这四个数。
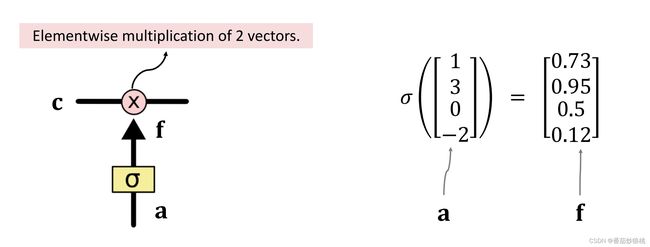
输入的向量a与输出的向量f应该有相同的维度。这个例子里,向量a是4维的,向量f也是四维的。
(2)Elementwise multiplication
算出f向量之后,计算传输带向量c和遗忘门向量f的Elementwise multiplication。
Elementwise multiplication的计算方法如下(举例):
c和f(有输入a经过sigmoid激活函数得到)都是四维的向量,把它们的每一个元素分别乘起来就行,0.9乘以0.5等于0.45,0.2乘以0等于0,-0.5乘以1等于-0.5以此类推,可以看出Elementwise multiplication的计算结果也是四维的向量。
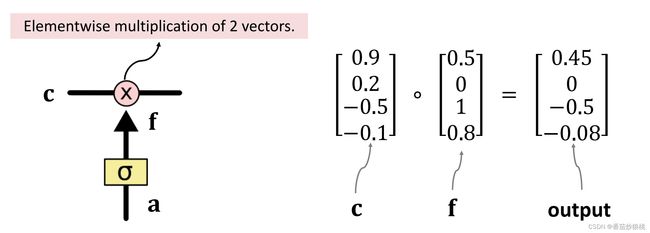
遗忘门f,有选择的让传输带c的值通过,假如f的一个元素是0,那么 c对应的元素就不能通过对应的输出是0。假如f的一个元素是1,那么c对应的元素就全部通过,对应的输出是c本身。
(3)遗忘门
遗忘门f的计算方法如下,看下面的结构图,ft是上一个状态ht-1与当前输入x的函数,状态ht-1与输入xt做串联操作得到更高维的向量,然后算矩阵Wf与这个向量的乘积,得到一个向量,再用sigmoid的函数得到向量ft。ft的每一个元素都介于0和1之间。

遗忘门有一个参数矩阵Wf, 需要通过反向传播从训练数据里学习
刚才讲了遗忘门,现在来看一看input gate输入门
(4)输入门
下面这张结构处理输入门 it依赖于旧的状态向量ht-1和新的输入xt,输入门it的计算很类似遗忘门,把旧的状态ht-1与新的输入xt做串联,得到更高为的向量 然后算矩阵Wi与这个向量的乘积得到一个向量,最后再用sigmoid函数得到向量it,it的每一个元素都介于0和1之间。
输入门也有自己的参数矩阵,记为wi,wi也需要从训练数据中学习,还需要算new value它是个向量计算,跟遗忘门和输入门都很像,也是把旧状态ht-1,与新输入xt做串联操作,再乘以参数矩阵。区别在于激活函数不是Sigmoid,而是双区正切函数tanh,所以算出的向量的元素都介于[-1,1]之间,同时如图可知计算该向量ct’也需要单独的一个参数矩阵,记作wc
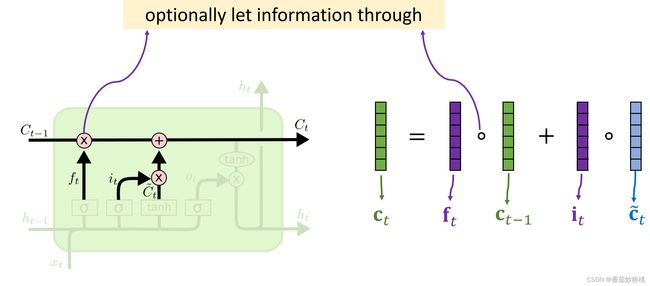
在介绍了上面的步骤以后,如上图,我们已经可以知道遗忘门ft,输入门it,以及New value:ct’,还知道传输带旧的值ct-1,现在可以更新传输带c了。
(5)ct的计算
传输带ct的更新如下:用遗忘门ft和传送带旧的值ct-1算Elementwise multiplication。

遗忘门ft和传送带ct-1是维度相同的向量,算出的成绩也是个向量,遗忘门ft 可以选择性的遗忘ct-1中的一些元素
如果ft中的一个元素是0那么ct-1相应的元素就会被遗忘,刚才选择性遗忘掉了传数带ct-1的一些元素,现在要往传输带上添加新的信息。
计算输入门it和新的值ct’的Elementwise multiplication、输入门it和新的值ct’,都是维度相同的向量,它们的乘积也是维度相同的向量,把乘积加到传送带上就行了。这样就完成了对传送带的一轮更新,用遗忘门删除了传送带上的一些信息,然后加入新的信息,得到了传输带新的值ct’,现在已经更新完传送带c了。
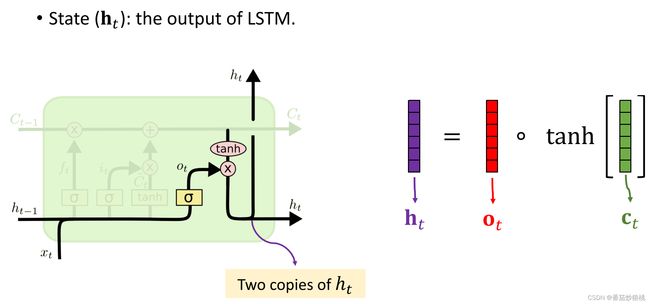
最后一步是计算LSTM的输出,也就是状态向量ht,ht是这么计算的呢?
(5)LSTM的输出ht的计算
首先计算outpuit gate输出门的向量Ot,输出门的向量Ot跟前面的遗忘门、输入门的计算基本一样, 把旧的状态ht-1与新的输入st做串联,得到更高为的向量,然后算矩阵wo与这个向量的乘积得到一个向量,最后再用sigmoid函数得到向量Ot。Ot的每一个元素都介于0和1之间。
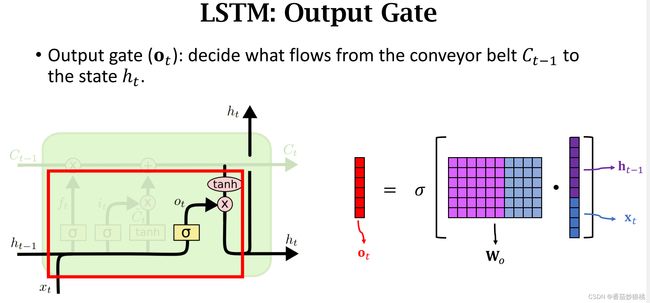
输出门也有自己的参数矩阵wo,也需要从训练数据中学习
如下图,现在计算状态向量ht,对传输带ct的每一个元素求双区正切函数,把元素全都压到[-1,1]的区间,然后求这两个向量的Elementwise multiplication,下如的红色向量是刚刚求出的输出门ot,这样就得到了状态向量ht
看一下结构图ht它有两份copies,一份copy传输到了下一步,另一份copy成了LSTM的输出。
可见目前位置,一共有7个向量 x输入了LSTM,可以认为,所有这些x向量的信息都积累在了状态ht里面。
我们来算一下LSTM的参数数量
LSTM有遗忘门、输入门、 new value以及输出门,这四个模块都有各自的参数矩阵w,所以一共有四个参数矩阵。矩阵的行数是h的维度,列数是h的维度+上x的维度,所以l s tm参数的数量是4×h的维度×(h的维度+x的维度)。
四、核心代码详解
利用Keras实现,代码关键步骤详解

虽然LSTM的结构非常复杂,但是用Keras实现起来非常简单,跟simple RNN的实现几乎完全一样。

拿LSTM来判断电影评论是正面还是负面,跟用sim RNN一样,让LSTM只输出最后一个状态向量ht,ht就是从一段500个词的电影评论中提取的特征向量,然后输入线性分类器来判断评论是正面的还是负面的。
Kearas代码是这样的, 跟用simple RNN完全一样,只是把这个层的名字换成了LSTM而已, 其余地方全都一样。

下图神经网络的结构,这是LSTM层,让LSTM只输出最后一个状态向量h,所以这一层的输出是一个32维的向量。
来算一下模型参数,每个参数矩阵是h的维度32乘以h的维度32+ x的维度32。Keras默认使用偏移量,所以参数里还有个32维的向量,一个矩阵和一个向量加起来总共有2080个参数,

LSTM一共有四个参数矩阵和四个Intersect向量,所以参数的数量等于2080*4=8320

下图是在IMDB电影评论数据上的结果,训练准确率是91.8%,validation和测试的准确率都是88.6%左右,这比simple RNN有些提升,simple RNN的测试准确率是84%。
Dropout也可以用在LSTM层上,具体方法比较复杂,但实现很简单,如下图

只需要加上Dropout等于某个0-1之间的数字就行了,然而做实验的时候发现使用Dropout并没有提升测试准确率,原因是这样的:虽然训练的时候出现了过拟合,但是过拟合不是由LSTM层造成的,而是由Embedding造成的。
LSTM有8000多个参数,而引白领层却有32万个参数,在这里对LSTM使用Dropout没有帮助的,因为过拟合不是由LSTM层造成的。
五、完整代码实现
此处完整代码实现部分的数据处理内容和上篇内容一致,此处直接给出。
代码大部分内容和Simple RNN相同,仅需稍加改变模型定义模块
'数据预处理模块'
'数据集读取与预处理'
# 此处使用Keras库自带函数进行简洁实现(从零开始实现请看上一节)
# 使用keras的embedding层处理文字数据(同样使用imdb数据集)
from keras.datasets import imdb
from keras import preprocessing
max_feature = 10000 # 词汇量(作为特征的单词个数)
maxlen = 500 # 在500个单词以后截断文本
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_feature)
# y_train、y_test分别表示训练集和测试集的标签
# max_words=10000:只考虑数据集中前10000个最常见的单词
print(len(input_train), 'train sequences')
print(len(input_test), 'test sequences')
print('sequence 格式:(samples*time)')
input_train = preprocessing.sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = preprocessing.sequence.pad_sequences(input_test, maxlen=maxlen)
# 此处相当于对齐序列(补0或者阶段评论)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
'LSTM层的应用'
from keras.layers import Dense, LSTM, Embedding
from keras.models import Sequential
model = Sequential()
model.add(Embedding(max_feature, 32))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(
input_train, y_train,
epochs = 10,
batch_size = 128,
validation_split = 0.2
)
model.summary()
'查看模型最终性能'
loss_and_acc = model.evaluate(input_test, y_test)
print('loss=' + str(loss_and_acc[0]))
print('acc=' + str(loss_and_acc[1]))
代码运行结果如下

六、总结
总结一下本文内容,本文讲了LSTM模型和用Keras的实现
(1)LSTM和simpleRNN主要的区别是用了一条传输带,让过去的信息可以很容易传输到下一时刻,这样就有了更长的记忆。LSTM的表现总是比simple RNN要好,所以想用RNN的时候,就用LSTM模型,而不要用Simple RNN模型。
(2)LSTM有四个组件,分别是遗忘门,输入门,new value新的输入,以及输出门,这四个组建各自有一个参数矩阵,所以一共有四个参数矩阵。
(3)LSTM参数的数量是4×h的维度×(h的维度+x的维度),
即4 × shape(h) × [shape(h)+shape(x)]
下一篇内容讲Bidirectional RNN
七、参考文献
Tensorflow+Keras入门练习(六):文字处理(嵌入层,RNN,LSTM) - 知乎
GitHub - wangshusen/DeepLearning