基于Pytorch建立一个自定义的目标检测DataLoader
文章目录
- 前言
- 一、数据集File格式介绍
- 二、代码整体思路及展示
-
- 2.1 代码整体思路
- 2.2 代码整体展示
- 三、代码分块介绍
-
- 3.1 def load_imgnames
- 3.2 def \__init\__
- 3.3 def \__len\__
- 3.4 def \__getitem\__
- 四、代码测试
- 总结
前言
代码和文件夹免费公开,学习自取。链接!链接!链接!
本文介绍如何通过torch建立一个自己的目标检测数据集DataLoader。以WIDERFACE的部分图片与YOLO格式标注为例。本文分为以下4步介绍建立DataLoader的整体思路,具体还是要根据自己的数据集File格式进行调整:
- 数据集File格式介绍
- 代码整体思路及展示
- 代码分块介绍
- 代码测试
一、数据集File格式介绍
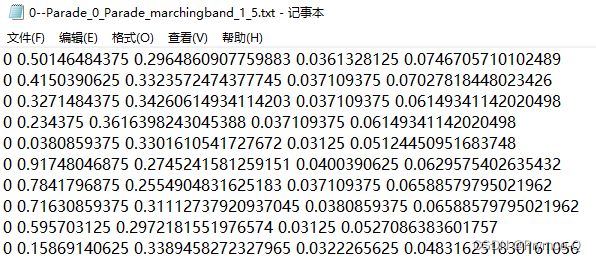
我们使用了4张WIDERFACE中的图片以及YOLO格式的标签来进行说明,整体的数据结构如下图,其中用来测试使用的代码文件DIY_DataLoader.ipynb也在同一目录下。

-
imgaes中存放.jpg图片;

-
labels中存放.txt的YOLO格式标注文件;

-
DIY_DataLoader.ipynb是测试用的代码文件; -
train.txt中罗列了图片的路径。

二、代码整体思路及展示
2.1 代码整体思路
自己的DIY的DataLoader需要重写其中的一些方法,主要包括:__int__、__len__、__getitem__。
__int__中保存一些数据集相关信息,最终为了得到:每一张图片路径、每一个标注路径、对图片进行的transform;__len__为了得到一共有多少张图片数量;__getitem__为了得到其中某一张图片的[image_array, gt_bbox]。
2.2 代码整体展示
import os
import numpy as np
from PIL import Image
from torch.utils.data import Dataset, DataLoader
class WIDERFACE(Dataset):
def __init__(self, root_dir, image_file, ann_file, ann_txt, transform=None):
self.root_dir = root_dir # Root file
self.image_file = image_file # Image file
self.ann_file = ann_file # Annotations file
self.imagenames = self.load_imgnames(ann_txt)
# Load imgs/annos file
self.imgs = [f'{x}.jpg' for x in [os.path.join(root_dir, image_file, image) for image in self.imagenames]]
self.annos = [f'{x}.txt' for x in [os.path.join(root_dir, ann_file, image) for image in self.imagenames]]
self.transform = transform
def __len__(self):
return len(self.imagenames)
def __getitem__(self, idx):
image = np.array(Image.open(self.imgs[idx]).getdata())
with open(self.annos[idx]) as f:
gt_bbox = [x.strip('\n').split('/')[-1] for x in f.readlines()] # x, y, width, height
sample = {'img': image, 'gt_bbox': gt_bbox}
if self.transform:
sample = self.transform(sample)
return sample
def load_imgnames(self, ann_txt):
with open(ann_txt) as f:
samples = [x.strip('\n').split('/')[-1] for x in f.readlines()]
names = [x.split('.')[0] for x in samples]
return names
三、代码分块介绍
这里将一块块地详细介绍下类中每一个方法的内容。
3.1 def load_imgnames
这块代码最终为了读取下每一张图片的名称,在我们的文件夹中,它的输入为train.txt。
def load_imgnames(self, ann_txt):
with open(self, ann_txt) as f:
samples = [x.strip('\n').split('/')[-1] for x in f.readlines()]
names = [x.split('.')[0] for x in samples]
return names
简单测试一下,就是

3.2 def _init_
这一块主要是保存并告诉一下DataLoader,图片文件的具体路径、图片标注框的具体路径、用了什么transform方法。
def __init__(self, root_dir, image_file, ann_file, ann_txt, transform=None):
self.root_dir = root_dir # Root file './'
self.image_file = image_file # Image file 'images/'
self.ann_file = ann_file # Annotations file 'labels/'
self.imagenames = self.load_imgnames(ann_txt) # 得到了每张图片的名称
# 基于self.imagenames,得到每张图片的 imgs/annos 具体的路径
self.imgs = [f'{x}.jpg' for x in [os.path.join(root_dir, image_file, image) for image in self.imagenames]]
self.annos = [f'{x}.txt' for x in [os.path.join(root_dir, ann_file, image) for image in self.imagenames]]
self.transform = transform
3.3 def _len_
self.imagenames是一个保存了所有图片名称的List,故使用len()方法可以知道一共有多少张图片。当然self.imagenames也可以替换成self.imgs或者self.annos,效果是一样的。
def __len__(self):
return len(self.imagenames)
3.4 def _getitem_
def __getitem__(self, idx):
# 根据图片路径打开图片并转化成np.array格式
image = np.array(Image.open(self.imgs[idx]).getdata())
# 保存图片对应的gt_bbox[x, y, width, height]
with open(self.annos[idx]) as f:
gt_bbox = [x.strip('\n').split('/')[-1] for x in f.readlines()]
# 使用dict对一张图片的信息进行包装
sample = {'img': image, 'gt_bbox': gt_bbox}
if self.transform:
sample = self.transform(sample)
return sample
四、代码测试
我们使用这个由4张图片组成的数据集进行一下DIY_WIDERFACE这个DataLoader的代码测试。
root_file = './'
image_file = 'images/'
ann_file = 'labels/'
ann_txt = './train.txt'
test = DIY_WIDERFACE(root_file, image_file, ann_file, ann_txt)
__init__方法中储藏的一些信息展示,如下:
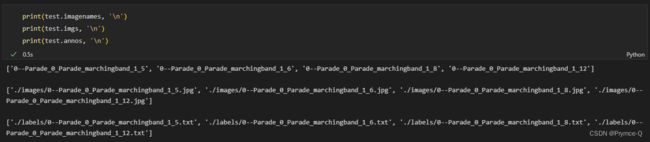
__len__方法表示的图片数量,如下:
![]()
__getitem__方法展示某一张图片的信息,包括图片的数组信息、gt_bbox,如下:

总结
本文就简单地带大家理解下DataLoader的构造思路。
欢迎批评指正。