Attacking Black-box Recommendations viaCopying Cross-domain User Profiles
摘要
旨在为用户提供个性化项目列表的推荐系统,已经引起了广泛的关注。事实上,许多这些最先进的推荐系统都是建立在深度神经网络(DNNs)上的。最近的研究表明,这些深度神经网络很容易受到攻击,比如数据中毒,它会产生虚假的用户来推广一组选定的物品。相应地,有效的防御策略已经被开发出来来检测这些产生的带有假个人资料的用户。因此,应该研究创建更“现实”的用户档案来推广一组项目的新策略,以进一步了解基于dnn的推荐系统的脆弱性。在这项工作中,我们提出了一个新的框架复制攻击。这是一种基于强化学习的黑盒攻击方法,通过将源用户的档案复制到目标域,从而利用来自源域的真实用户,目的是提升项目的子集。复制攻击可以有效地学习策略梯度网络,首先选择,然后从源域进一步细化/制作用户配置文件,并最终将它们复制到目标域。CopyAttack的目标是最大化目标域中用户的Top-k推荐列表中的目标项目的命中率。我们在两个真实数据集上进行了实验,并通过经验验证了该框架的有效性。复制攻击的实现可以在https://github.com/wenqifan03/CopyAttack上找到。
I.介绍
作为数据挖掘领域的一项重要任务,推荐系统旨在建议个性化的项目列表,用户可能交互(如点击或购买),特别是在许多面向用户的在线服务如电子商务(如亚马逊和淘宝)和社交媒体网站(如脸书和推特)[1],[2]。近年来,越来越多的人在努力采用深度神经网络进行推荐,如RNNs[3]和GNNs[4],[5]。这些基于深度神经网络的推荐系统已经取得了最先进的性能。然而,众所周知,深度神经网络(DNNs)非常容易受到[6]-[9]的对抗性攻击,其中对手倾向于操纵数据以降低预测性能。事实上,最近的研究表明,这些基于深度神经网络的推荐系统也很容易受到敌对攻击[10],[11]的攻击,对手打算为了用户的意愿而操纵用户的决策。攻击推荐系统最常用的方法之一是数据中毒攻击(也称为先令攻击)[10]-[14]。在这些攻击中,对手会在推荐系统中生成用户通过精心设计的个人资料来推广/降级一个精心挑选的项目子集,[11],[12],[15]。然而,最近的国防研究[13],[16]-[18]已经证明,这些虚假的个人资料用户很容易被检测到,因为他们呈现的模式与真实的个人资料非常不同。因此,如何向虚假用户注入与真实用户相似的配置文件,仍然是限制对基于深度神经网络的推荐系统执行成功攻击能力的一个关键挑战。
一些现实世界的推荐平台也有类似的功能,因此,它们有很多共同的信息。例如,电影推荐平台IMDb和Netflix分享了很多电影,而电子商务网站亚马逊和eBay有数百万个共同的产品。此外,来自这些具有相似功能的平台的用户也共享相似的行为模式/偏好。例如,漫威的粉丝可能会看漫威电影宇宙电影如“美国队长》、“钢铁侠”和“奇异博士”IMDB,用户喜欢电影《钢铁侠》在奈飞推荐看电影《奇异博士》或其他漫威电影(如《蜘蛛侠》、《黑豹》)。事实上,这些观察结果鼓励了大量旨在利用一个平台的信息来帮助另一个平台的推荐的工作,这就是众所周知的跨领域推荐[19]。回想一下,攻击推荐系统的主要障碍是如何生成具有尽可能接近真实配置文件的用户。为了应对这一挑战,在这项工作中,我们改变了我们的观点-我们建议不生成具有虚假档案的用户,而是从其他域复制具有真实档案的跨域用户。图1显示了一个说明性的例子,其中我们有一个目标域a和一个用于电影推荐的源域B。这两个域共享一组电影。要攻击(即提升/降级)目标域A中的目标项目vj,源域B中的用户uBn的配置文件{vj−1,vj}可以作为新用户uAm+1复制到目标域A中,这样电影vj就会被攻击为对手的愿望(即提升/降级)。此外,也可能存在两个电子商务平台相互竞争,其中一个平台可能想要攻击其竞争对手的推荐性能,如淘宝vs京东,或亚马逊vseBay。
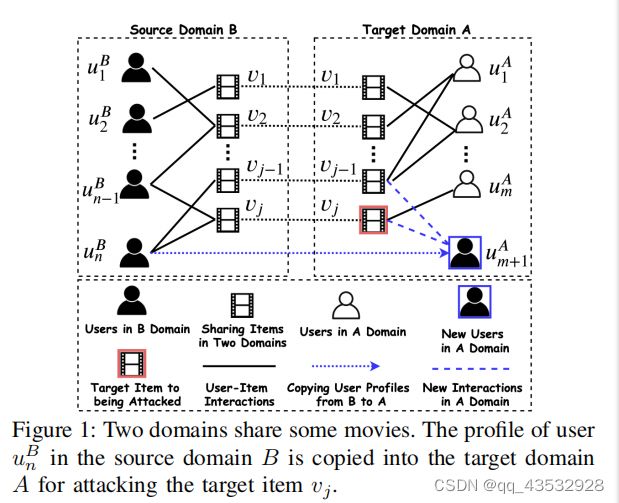
在本文中,我们的目标是通过复制跨域的用户配置文件来攻击黑盒建议。复制的用户配置文件从源域中自然是真实的。但是,如何在黑框设置下选择源域中的用户配置文件面临着巨大的挑战,因为在黑框设置中,我们只有对目标模型的查询访问权限,并且每个查询反馈都包含了针对特定用户[20]、[21]的Top-k推荐项目。此外,现有的大多数攻击方法都是在白盒设置下设计的,攻击者需要对目标模型(即模型架构和参数)和数据集[11]、[12]、[22]有充分的知识。这些现有的白盒方法,如这些基于投影梯度方法和随机梯度朗之万动力学[11],[12],不适用于我们的问题。此外,由于隐私和安全关键问题,期望这种类型的完全访问(即,模型架构和参数,以及数据集)是不现实的,也不是可用的。因此,我们提出了一种基于强化学习(RL)的攻击方法,该方法仅通过来自目标推荐系统的查询反馈来学习选择源域B中的用户档案。我们的主要贡献总结如下:
提出了一种新的策略,通过复制跨域用户档案来攻击目标推荐系统;
强化学习的攻击黑盒设置框架,可以有效地从源域选择跨域用户轮廓来攻击目标域;
并在两个真实世界数据集上进行了全面的实验,以证明所提出的攻击黑盒框架的有效性。
2相关工作
在本节中,我们简要回顾深度神经网络对抗攻击和推荐系统攻击的相关工作。
A. 对深度神经网络(DNNs)的对抗性攻击在各个领域都取得了巨大的成功,包括计算机版本(CV)[23]、自然语言处理(NLP)[24]和推荐系统[3]、[25]、[26]。此外,基于深度神经网络的应用程序可以在安全和安全关键环境中广泛使用,如自动驾驶汽车、恶意软件检测和金融欺诈检测系统[7]。然而,最近的研究表明,现有的dnn非常容易受到对抗性攻击[6],[9],这对使用dnn进行安全关键任务提出了重大关注。更具体地说,对手可以巧妙地操纵合法的输入,这可能无法察觉,但可以迫使训练的模型产生不正确的输出[7]。例如,攻击者可能会在路标上贴上贴纸,从任何视点[27]混淆自动驾驶汽车的图像识别系统。因此,深度神经网络的安全关键问题已成为一个重要的研究领域。
B. 推荐系统的对抗性攻击推荐系统技术是数据挖掘领域中最成功的商业应用程序,并在阿里巴巴和亚马逊[28]等许多电子商务平台上贡献了大部分的收入和流量。推荐系统的目标是帮助用户缓解信息过载的问题,并向他们推荐一个可能被点击或购买的个性化物品列表。由于恶意目的(例如,经济激励、恶意竞争对手),一些对手可能会注入虚假数据攻击推荐系统,这样推荐结果就可以被操纵,用户对项目的信念/决策可能会尽可能多地影响[11]、[13]、[15]。提出了一些研究这个方向的方法。子分解的协同滤波的情况下,对数据中毒攻击模型进行优化。在[11]中,引入了一个两步对抗框架来攻击推荐系统,它们首先通过生成对抗网络(GAN)生成假用户,然后应用投影梯度法进一步制作具有合适对抗意图的假用户档案。在[29]中,他们将推荐系统中的数据中毒攻击表述为一个非凸整数优化问题,并开发了一种基于梯度的方法,对虚假用户的评分进行逐个优化。然而,许多这些数据中毒方法从根本上依赖于白盒模型,在该模型中,攻击者需要对目标模型(即模型架构和参数)或访问数据集[11]、[12]、[29]。也就是说,它们关键需要直接访问目标模型,以及推荐系统中的数据集。事实上,由于推荐系统中的隐私和安全问题,期望这种完全的访问是不可能和不现实的。因此,在推荐系统中,需要研究黑盒攻击,因为攻击者对目标模型和数据集没有充分的攻击知识。在本文中,我们提出了一个在黑盒设置下攻击推荐系统的新框架来填补这一空白。
3问题陈述
将目标推荐系统A定义为具有一组用户UA=u1A、u2A、...,unAA和一组项目VA={v1、v2、...,vmA},其中nA是用户的数量,mA是项目的数量。此外,用户项目交互表示为矩阵YA∈RnA×mA,其中交互yijA表示用户uiA与项目vj交互(例如,点击/购买),否则为0。此外,我们将用户uAi在YA中交互的项目集(即他们的用户配置文件)定义为:
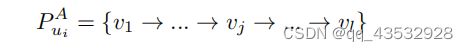
其中→表示与uAi交互的l项的顺序(长度l可以因用户而不同)。然后我们将目标域A中所有用户配置文件表示为![]()
我们类似地定义了一个源推荐系统B,包括nB用户UB集、mB项VB集、交互矩阵YB∈RnB×mB集和用户配置文件PUB集。注意,源域B选择之间有重叠项目目标域和源域B。换句话说,存在一组项目V=VA∩VB,在||6=∅和重叠(即V)被认为足够大。因此,我们为vj∈V定义了一个项目配置文件PAvj,它是a与YA中与vj交互(例如,点击/购买)的用户集,如下所示:
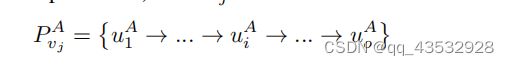
与vj交互过的用户。
其中o是项目配置文件中的用户数(项目不同)。设![]() 表示目标域A中的项配置文件集。
表示目标域A中的项配置文件集。
现在,给定目标和源推荐系统的符号A和B,我们正式定义目标推荐系统的目标。总的来说,A的目标(我们表示规则(·,·))是预测用户是否喜欢(即将交互)项目vjyij=转速(PuAiPvAj)。因此,在不丧失一般性的情况下,目标推荐系统的任务是为每个用户预测一个Topk排序的潜在项目列表。更正式地说,本建议的定义如下:
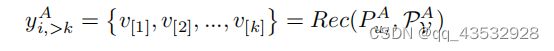
其中,yAi,>k=v[1],v[2],...,v[k]表示用户uAi的Top-k候选项。为了完整起见,我们注意到yAi,>k中的这些候选项目是按Rec(·,·)排序的,其中用户uAi更有可能点击/购买项目v[i],而不是v[i+1]。
最后,我们定义黑盒注入攻击的问题来促进目标项目v∗∈V通过复制一组用户(配置文件)UB→={uBi}4i=1={PuBi}4i=1从源域到目标域,其中4是预算给攻击者(跨域用户配置文件的数量复制)。请注意,攻击导致目标域有一组被污染的用户UA0=UA∪UB→A,从而也污染了交互矩阵YA。更准确地说,YA的污染是由于引入复制的跨域用户配置文件会导致他们与项目V集的交互,从而破坏了A中用户和项目之间的关系。此外,更具体地说,我们定义的推广目标项目v∗这个项目出现在Top-k推荐用户列表之前(注入复制跨域用户UB→及其相关交互)没有v∗Top-k推荐列表。请注意,攻击者还可能希望降级目标项,这可以被视为攻击推荐系统的升级的特殊情况。
4框架
在本节中,我们将首先给出所提议的框架的概述,然后提供所提议的框架中的每个组件的详细信息,最后讨论如何学习模型参数。
A.对所建议的框架的概述
为了在黑箱设置下的推荐系统中执行攻击,传统的基于梯度的[11]、[12]技术既不适用也不现实,因为它们在理想情况下假设可以访问目标推荐系统和数据集。因此,我们提出了一个基于强化学习(RL)的攻击框架,复制攻击,以学习复制跨域用户配置文件的策略。这是因为强化学习可以提供一种自然的方式来与黑盒推荐系统交互,并获得奖励来优化框架[30],[31]。CopyAtatack的架构如图2所示,它包括三个主要组件:用户配置文件选择、用户配置文件制作、注入攻击和查询。
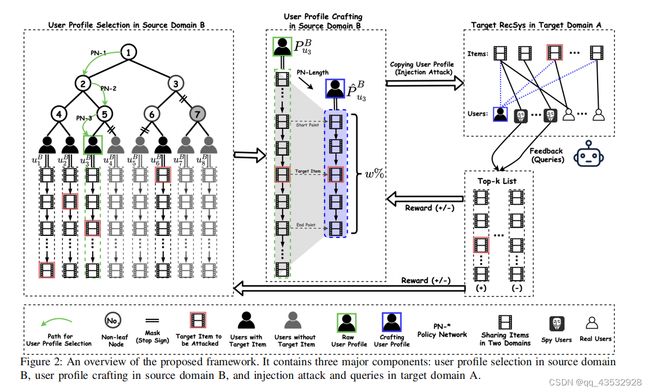
图2:对建议的框架的概述。它包含三个主要组件:源域B中的用户配置文件选择,源域B中的用户配置文件制作,以及目标域A中的注入攻击和查询。
第一个组件是对特定的目标项目攻击执行用户配置文件选择,建议从PUB中选择用户配置文件(即从源域B的用户配置文件)。这可以在图2的左侧看到。然而,使用强化学习技术在有限的资源(即目标推荐系统允许的查询数量(或交互))下建模这个选择过程是相当具有挑战性的,因为源域B中大量的用户概要文件(即大规模离散动作空间)可能同时导致效率低下和无效。此外,并不是所有的用户配置文件都有助于帮助攻击目标推荐系统中的特定目标项。为了解决这些挑战,我们建议采用具有掩蔽机制的分层结构策略梯度网络,有效地学习在大规模离散行动空间中有效选择跨域用户档案的策略,从而最大化长期回报。
接下来,一旦从第一个组件中选择了跨域用户轮廓,第二个组件就用于轮廓制作。在这里,轮廓制作旨在通过考虑降低攻击成本和噪声来进一步修改用户轮廓,这可以在图2的中心部分看到。我们注意到,用户可以拥有包含不同长度(即与他们交互过的项目数量)的用户配置文件。因此,它可以并不是用户在用户配置文件中提供的所有交互都是有帮助的。此外,过长的用户配置文件长度可能会包含一些噪声,并增加攻击成本(即,复制的用户需要在目标域中执行的交互数量)。因此,希望在攻击之前仔细设计选定的跨域用户配置文件。然而,精心制作用户配置文件并不是很简单的,因为精心制作的用户配置文件应该包含关于目标项目的有用信号,并保留它们的现实(即,对目标推荐系统来说是不可检测的虚假信号)。为了解决这些挑战,我们引入了第二步策略梯度网络,通过考虑这个攻击成本问题来设计用户档案。更具体地说,这第二步策略梯度网络将决定在目标项v∗周围的用户配置文件的百分比。
最后,第三个组件的第一个目标是通过复制精心制作的跨域用户配置文件(即那些来自源域的用户配置文件)来攻击目标推荐系统。在复制了精心制作的跨域用户配置文件后,对目标推荐系统进行查询,以Top-k推荐的形式获得一些反馈。然后,这种反馈被用来形成一个优化整个框架的奖励(即,更新第一和第二个组成部分的策略梯度网络)。这个组件可以在图2的右侧看到。
接下来,我们将讨论我们的基于黑盒强化学习的框架的攻击环境的概述。
B.攻击性的环境概述
攻击的黑箱框架可以被建模为一个马尔可夫决策过程(MDP)[32]-[34]。MDP的定义包含状态空间S、动作集A、转移概率P、奖励R和折扣因子γ(即(S、A、P、R、γ)),定义如下:
状态S。状态st包含所有中间注入的用户配置文件和状态t处的目标项目。
动作A。动作有两个组件,定义为A=(aut,alt)。更具体地说,攻击者首先从状态为t的跨域(即源域)系统B中选择一个用户或。然后,攻击者可以修改uBi的原始配置文件PuBi,以制作一个具有可能更短长度的配置文件,从而生成alt=PˆBui。请注意,这个精心制作的用户配置文件将最终被注入到目标推荐系统中。(两步:第一步在源域中选择一个用户的配置文件,第二部修改配置文件)
转移概率p.转移概率|(st+1|,|)定义了攻击者采取行动时状态从当前st转移到下一个状态的概率。
攻击者的目标是攻击目标推荐系统Rec(·,·)中的目标项目v∗(如该目标项目的提升/降级)。在这项工作中,我们主要关注升级攻击,即攻击者试图向尽可能多的用户推荐目标项目。为基于RL的方法定义奖励的一种自然的方法是基于排名评价措施。我们注意到,这种基于排名评估的奖励功能是相当普遍,可以使用对于晋升或降级的攻击。因此,基于排名的奖励功能,我们分配一个积极的奖励行动当目标项目v∗属于Topk推荐列表uAi∗∈U∗A⊂U。更具体地说,用户U∗是一组间谍用户,攻击者已经在目标域中建立了注入攻击(如图2所示)。我们注意到,这些间谍用户只存在于目标推荐系统中,因此攻击者可以使用它们作为代理,以确定其复制的用户配置文件在向UA中的所有用户推广目标项目方面的有效性。我们使用命中率(HR@K)作为我们的奖励函数r(st,at)中对给定状态st和行动的排名评估,我们将其定义如下:

其中HR(uAi∗,v∗,k)返回间谍用户uAi顶部列表中目标项目v∗的命中率(即,v∗是否在yuAi∗集合中,>k)。奖励是U∗A中所有间谍用户的命中率.
致命的攻击过程有两个停止条件。首先,如果达到最大预算(即,复制的跨域用户配置文件的数量),它将停止。此外,如果复制较少的用户配置文件能够成功地满足升级任务,那么它可以在达到预算之前停止。
C. 通过层次结构的策略渐变来选择用户配置文件(重点)
他们的用户配置文件注入到目标推荐系统的用户UA集中,以实现推广一组项的目标。这里的主要挑战是如何处理一个大规模的离散动作空间(即所有用户配置文件集)以及获得满意的结果在有限的资源下与目标(黑盒)推荐系统a.大多数现有的RL技术不能处理这样一个大的离散行动空间问题决策的时间复杂性是线性的大小[30],[31],[33],[35],[36]。为了解决这些挑战,我们引入了一个层次结构的策略梯度网络来建模选择用户配置文件的过程(如图2的左部分所示)。更具体地说,我们在跨域用户配置文件上构造了一个层次聚类树,其中每个叶节点表示为一个用户配置文件,每个非叶节点是一个策略梯度网络。在此层次集群树中选择一个用户配置文件是为了寻找从根到树的某个叶的路径。此外,为了进一步减少动作空间,我们引入了一种掩蔽机制来定位信息丰富的跨域用户配置文件。
跨域用户配置文件上的1)层次聚类树:在层次聚类树中,每个叶节点表示为一个跨域用户配置文件,而每个非叶节点是一个策略网络。然而,如何构建聚类树还是一个问题。因此,我们建议采用一种自上而下的分裂方法,将每个聚类反复划分为小的子聚类,其中聚类树中同一非叶节点下的叶节点应该比来自另一个非叶节点的叶节点更相似。我们注意到,这个过程从聚类树的根处的整个节点集开始。
在构建我们的层次聚类树时,我们进一步添加了应该平衡的约束,以确保适当的加速(因为在最坏的情况下,不平衡的聚类树可能会导致用户数量的策略网络链表)。因此,我们使用K-means聚类方法,并对其进行进一步修改,使其形成相同大小的集群(最多由单个用户关闭)。为了实现这一点,在构建树(自上而下)的每个非叶节点上,我们首先对当前用户集应用传统的K-means聚类,获得c质心集。请注意,在分层聚类树中,集群中心的数量(即质心)被设置为相同数量的子节点。然后,我们根据用户的欧几里德距离,一次将用户重新分配给这些c质心,以确保我们有一组平衡的集群(根据它们的大小)。
在构造聚类树时,一个主要的考虑因素是如何平衡每个节点的子节点的数量与树的高度。为了更好地理解层次聚类树的深度d、叶节点数|UB|和子节点数c之间的关系,我们可以观察到以下几点:

而该树的非叶节点数为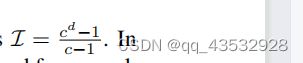 。在第五节中,我们对我们提出的框架CopyAttack进行了分析,我们在c和d之间改变这个平衡。
。在第五节中,我们对我们提出的框架CopyAttack进行了分析,我们在c和d之间改变这个平衡。
为了执行分层集群,我们注意到用户的许多特性可以用于他们的表示,如用户属性、审查评论和用户-项目交互。在本工作中,我们采用用户-项交互YB来表示用户,因为用户的属性和评论评论等辅助信息不可用。我们使用通过矩阵分解(MF)[37]学习的用户表示pB∈Re来度量用户之间的相似性。
2)掩蔽机制:虽然跨域用户配置文件包含项目的信息信号,但由于目标推荐系统中的查询数量有限,并不是所有的跨域用户配置文件都可以用于攻击特定的目标项目。实际上,只有与特定目标项相关的用户配置文件才会有用。因此,我们需要使用掩蔽机制来调整分层聚类树,以定位目标项的相关跨域用户配置文件的某些百分比。更具体地说,对于每个目标项,我们采用了一种屏蔽不包括目标项的跨域用户配置文件的方法。如在中的左侧部分所示在图2中,从非叶节点3到节点7的路径被屏蔽了,因为用户uB7和uB8的跨域配置文件不包括目标项目(用粉红色)。因此,RL代理无法探索这些跨域用户配置文件(即uB7和uB8),这可能进一步有助于减少操作空间。这种操作空间的减少反过来又可以有效地定位有用的跨域用户配置文件来执行有效的攻击。我们再次注意到,目标项目v∗来自于集合v=VA∩VB。换句话说,目标项存在于源域中,因此屏蔽永远不会导致整个树被屏蔽。
3)层次结构策略梯度:使用(掩码)层次聚类树,用户配置文件选择的目的是学习策略|(aut|sut)来寻找从根到某个叶的路径(即用户)。树中的每个非叶节点都是一个策略梯度网络,它可以被建模为一个多层感知器(MLP)。因此,在层次聚类树中存在一个具有θ={θ1,θ2,...,θI}的策略梯度网络(即非叶节点)。
特别是,nodei处的策略网络(MLP参数表示为θi)首先以当前状态作为输入,并输出nodei的所有子节点的概率分布。然后,根据概率选择其中一个子元素(动作)进行移动。然后,选择过程继续沿着策略网络的聚类树移动,直到到达一个叶节点(即用户配置文件),它可以形成从根到叶节点的长度为d的路径,如下所示: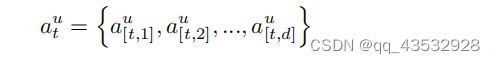
这个选择过程可以根据所选路径分解为多个步骤,如下:
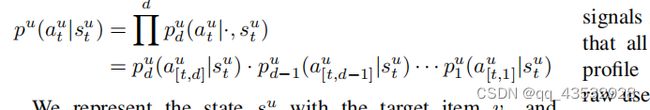
我们用目标项v∗和以前选择的用户UtB→A={uB1,...,uBi,...,uBt}来表示状态。我们将它们与一个多层感知器(MLP)结合在一起。通过估计在nodei时对儿童的概率分布(即由θi参数化的策略网络)的概率分布,来决定我们将移动到哪条路径,如下所示:
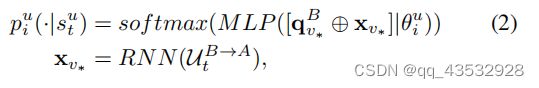
qBv∗∈Re预训练项目表示通过矩阵分解(MF)来自源域b同时,我们引入利用递归神经网络(RNN)模型编码选择跨域用户UtB→状态st低维表示,这样攻击者和目标推荐系统之间的历史交互可以提取。这里我们使用⊕来表示连接操作。此外,在这里,我们通过随机选择动作au0(即注入目标推荐系统的第一个用户)来播种这个过程,因为当时U0B→A是空的,不会提供来自RNN的任何见解。我们将其留给未来的工作来研究播种这一过程的其他方法,尽管随机操作在实践中通常是这样执行的。
图2的左侧部分显示了选择跨域用户配置文件的过程的示例说明。我们有8个用户配置文件,并在源域b中构建一个深度为3的平衡层次聚类树。对于给定的状态st,状态点最初位于根节点(节点1),并根据根节点(节点1)给出的概率分布移动到其中一个子节点(节点2)。当状态点到达树中的叶节点时,选择过程可以停止;在这种情况下,是用户uB3的配置文件。请注意,在状态点节点5上,从节点5到叶节点uB4的路径被屏蔽了,因为源域用户uB4的轮廓不包括当前攻击的目标项。此选择的示例路径是aut=节点1、节点2、节点5、uB3,作为图中具有绿色的路径。
虽然我们现在有了一种有效的机制来选择攻击者将复制到目标域的源域用户集,但我们在这里再次注意到,直接将这些跨域用户配置文件复制到目标推荐系统中可能会出现一些问题。更具体地说,可能并不是用户配置文件中的所有项目在升级攻击中都有用,而且可能只会注入噪音和/或增加攻击成本。因此,我们接下来将引入另一个策略梯度网络,它将学习如何通过减少用户配置文件中的项目数量(即与他们交互过的项目)来制作用户配置文件。
D. 用户配置文件
生成选定的跨域用户配置文件包含有关目标项的信息信号。但是,跨域用户配置文件中的所有交互都是有用的。事实上,仅仅将整个原始用户配置文件注入到目标推荐系统中,不仅可能增加攻击预算,还可能包括一些噪声。因此,我们希望在注入攻击之前精心制作和细化所选的跨域用户配置文件。
我们注意到,当考虑如何制作用户配置文件时,可能有一些选项可以选择如何减少用户配置文件的长度。例如,直观地随机选择一个要保留的子集没有意义,因为它会失去与目标项目在同一时间由给定用户交互的项目的时间/顺序关系。此外,如果我们可能是基于从用户的配置文件中选择与目标节点最相似的节点,那么这可能会导致一个更不真实的用户配置文件,这可能更容易被检测到。因此,我们选择在目标项周围裁剪窗口大小为w的跨域用户配置文件,似乎确实是一种裁剪的逻辑机制。原因如下:1)用户对项目的行为包含顺序模式,并且在目标项目周围的正向和向后交互的项目不是独立的,而且更多2)按顺序排序的用户交互接近于真实的用户行为,更有可能逃避目标系统的检测。例如,《权力的游戏》的粉丝们会一季接一季地看电视剧,如果用户没有看过前一季,那么只看《权力的游戏:第八季》通常是没有意义的。因此,我们引入将用户配置文件的长度离散为10个不同的级别(窗口大小),如:W={10%、20%、30%、40%、50%、60%、70%、80%、90%、100%}。
更具体地说,引入了一个策略梯度网络来从集合中选择动作来决定我们保持的长度(即所选用户配置文件的交互数量)。由于原始选择的跨域用户配置文件包含目标项目v∗,因此原始用户配置文件将以窗口大小w围绕目标项目进行裁剪。因此,我们可以考虑与前向和向后相关的项,并保留真实用户配置文件的自然顺序行为。例如,所选择的10项用户uBi的原始配置文件如下:
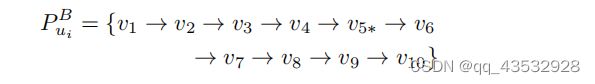
如果策略梯度网络采取了50%的操作,那么通过剪切操作的新用户配置文件可以保持大约50%的原始用户配置文件,如下:
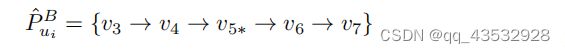
模型裁剪操作的状态slt可以由选定的用户ui和目标项v∗来决定。我们用状态slt估计在整个集合W上选择动作al的概率,如下(softmax将实数范围内的分类结果--转化为-->0-1之间的概率):
![]()
其中,pBi∈Re和qBv∗∈Re分别是在源域中通过MF预先训练过的用户和项目表示。
E. 注入攻击和查询
为了在黑盒设置中执行攻击,我们只能对目标模型进行查询访问,并且可以获得由特定用户的Top-k推荐项目组成的查询反馈。因此,在CopyAttack的最后一个阶段,我们实际上是将所选用户配置文件的精心制作的版本从源域注入/复制到目标域。然后,一旦注入,攻击者可以利用他们在目标域中建立的间谍用户U∗A来评估注入用户配置文件的有效性,并定义相应的奖励。更具体地说,这里我们使用了等式中定义的奖励函数(1),其中有效性是根据目标项目v∗(即U∗A)的顶级建议的命中率(HR@K)定义的。我们注意到这些Top-k的建议是执行目标系统a查询时的结果/反馈。一旦获得奖励,它就被用来更新配置文件选择和配置文件制作复制攻击组件。
v.实验
在本节中,我们将进行实验来验证我们的模型的有效性。我们首先介绍实验设置,然后讨论不同基线的结果(即性能比较),最后研究不同组件对我们的模型的影响。
A.实验设置1)数据集:我们在实验中使用两个跨域的真实数据集来验证复制攻击的性能。
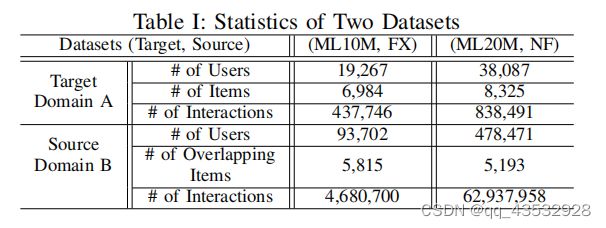
• MovieLen10M1&Flixster2 (ML10M-FX).这两个数据集都是电影推荐服务的流行在线平台,其中他们有数百万部电影。这两个平台的用户可以观看它们并给出个人评论(例如,评级)。在这里,我们以Movielen10M(ML10M)数据集作为我们试图攻击的目标域。Flixster(FX)数据集被视为源域,用于复制一些用户配置文件,以攻击Movielen10M(ML10M)目标域。在这两个数据集中,它们有很多共同的项,其中重叠的项可以通过电影名称对齐。我们只保留评分5分的互动,并转化为隐性反馈。经过过滤后,这个跨域数据集(ML10M-FX)有5,815个重叠的项。
• MovieLen20M3&Netflix4 (ML20M-NF).这两个数据集也是电影推荐服务的在线平台。我们以Movielen20M(ML20M)数据集作为目标域,以Netflix(NF)为源域。我们确定了同名电影和出版年份的电影。然后,我们执行类似于ML10M-FX数据集的过滤操作。在这个跨域的数据集中,我们有5,193个重叠的项。
这些数据集的统计数据如表1所示。请注意,我们只保留源域中的重叠项。
2)评估指标:为了评估推荐系统中攻击任务的质量,我们对topk推荐使用了两个流行的精度指标:命中率(HR@K)和归一化贴现累积获得(NDCG@K)。我们把K设为20、10和5。HR@K和NDCG@K的值越高,表示攻击性能越好,其中目标项目推荐给更多的用户进行升级攻击。排名任务太耗时排名所有项目的所有用户,我们随机抽样500测试用户没有与目标项目,对于每个测试用户,我们随机抽样100(负)项目,测试用户没有交互,然后排名目标项目[2]。
3)攻击环境-目标推荐系统:攻击可发生在[9]两个阶段,即模型测试和模型训练,可分为以下两类:
Evasion Attack(逃逸攻击).:这种攻击发生在目标模型经过良好训练或处于测试阶段之后。一旦目标推荐系统的训练完成,目标推荐系统的架构和参数就无需再训练而被冻结(因为真实世界的系统通常不会实时再训练或更新)。为了实现这一目标,我们采用了基于归纳图神经网络(GNNs)的推荐系统[5],[38]作为我们在此设置下的目标模型,其中用户和项目表示可以通过聚合它们的本地邻居(项目/用户)来学习。基于gnn的技术在图结构数据的表示学习中取得了显著的性能提高,并已成功地应用于推荐系统[5]、[38]。PinSage是最流行的基于gnn的推荐系统之一,它以归纳的方式聚合本地邻居(用户/项目),并已成功应用于行业[38],[39]。在训练完成后,在测试集w.r.tHR@10上的最终性能分别为ML10M数据集为0.5490,ML20M数据集为0.5474。然后,我们将这个训练有素的模型作为一个黑箱攻击环境,并评估不同的攻击方法的性能。在实验中,我们采用该方法作为目标推荐系统来进行攻击。
Poisoning Attack. :攻击发生在目标推荐系统模型被训练之前。攻击者可以在模型训练数据中添加虚假的用户档案,让训练后的模型受到恶意攻击。在此情况下,我们采用NeuMF[2]作为实验的目标推荐系统。NeuMF是最具代表性的基于深度神经网络的推荐算法,它被提出用于学习用户和项目之间的非线性交互。
我们随机抽取50个交互作用少于10个的目标项目,对目标域进行攻击。没有特别提到,升级任务的主要预算是我们注入到目标系统中的用户配置文件的数量(用户的填充项目),其中我们将最大预算设置为30。U∗A中的间谍用户数量都设置为50人。为了从目标系统获得反馈(奖励)(参见公式1),我们在每次3次注入后对目标系统进行间谍用户查询。请注意,目标推荐系统对攻击者来说是不可知的,包括详细的模型体系结构、参数和数据集。
4)参数设置:为了训练目标推荐系统,我们随机分割目标域数据集,其中我们有80%作为学习参数的训练集,10%作为调整超参数的验证集,10%作为测试集。采用早期停止策略来训练目标推荐系统,如果验证集上的HR@10连续5次下降,我们就停止训练时代。对于所有的神经网络方法,我们用高斯分布随机初始化模型参数,其中均值和标准差分别为0和0.1。学习速率和嵌入大小分别设置为0.001和8。对于所有的推荐算法和比较的攻击方法,没有额外提到,我们使用在他们的论文中给出的默认参数。
我们在张量流的基础上实现了该方法。学习率、行动的大小和贴现因子分别设置为0.001、8和0.6。为Flixster数据集,分层聚类树设置为3层,为Netflix数据集设置为6层。预先训练的用户和项目表示是通过矩阵分解技术获得的,其中我们使用相同的超参数进行训练(例如,学习率、嵌入大小等)。所有模型的所有其他超参数都是通过网格搜索精心选择的。
5)基线:推荐系统中的大多数攻击方法都是在白盒设置下进行的,它们假设攻击者可以对目标模型(如模型架构和参数)有全面的了解,并访问数据集。然而,期望这种完全的访问是不现实和可用的。因此,在我们的任务中,我们的目标是通过复制跨域用户档案来攻击黑盒推荐系统。我们建立了一些基线来评估攻击的表现如下:
RL-Generative::受中毒[40]的启发,我们采用强化学习技术学习在目标域选择项目的策略,而不考虑源域的信息。
随机攻击:该基线提出了随机采样跨域用户档案来攻击目标推荐系统。
TargetAttack40:不是从源域随机抽样用户配置文件,而是从源域随机抽样将要被攻击的目标项的用户配置文件。此外,我们应用用户配置文件制作操作作为我们提出的模型,以保留40%的用户配置文件。
TargetAttack70:这个基线与TargetAttack40相似,同时将用户配置文件的长度设置为70%。
TargetAttack100:该方法用于随机抽样用户配置文件,包括来自源域的目标项,而无需进一步制作选定的用户配置文件,如目标攻击40和目标攻击70。
此外,我们还通过强化学习技术,基于我们提出的方法建立了一些基线,如下:
策略网络[30]:该方法直接利用普通策略梯度网络来选择源域B中的用户配置文件,而不考虑在较大的离散动作空间上的层次聚类树。
复制攻击-掩蔽:该方法通过去除掩蔽机制来评估掩蔽机制的有效性。换句话说,攻击可以选择源域中的任何用户配置文件。请注意,此基线中的用户配置文件制作操作也将被删除,因为攻击在没有目标项的情况下选择用户配置文件的可能性更大。
复制攻击-长度:在我们提出的框架中,该方法用于评估用户配置文件制作操作的有效性,其中我们删除了在选定的跨域用户配置文件上的用户配置文件制作操作,并直接将原始用户配置文件注入到目标推荐系统中。
B.推荐系统的攻击性能比较
首先比较了基于GNN的推荐系统的攻击性能。表二显示了在ML10M-FK和ML20M-NF数据集上,不同方法w.r.tHR@K和NDCG@K的总体攻击性能。我们有以下主要的发现。

随机攻击的性能接近于无攻击的性能,这意味着在没有任何策略的情况下随机抽样跨域用户档案,由于用户档案数量多,不能帮助提升目标项目。当使用采样策略对用户配置文件进行采样时,用户配置文件应该包括目标项(即tat攻击-40/70/100)时,性能可以显著提高。此外,当我们将采样的跨域用户配置文件范围限制为包含目标项的用户时,这种方法可以获得更好的性能。这表明具有目标项的用户配置文件可以提供信息来帮助执行攻击。
当考虑跨域用户专业文件的长度时,没有目标项目约束的方法的项目预算非常低(小于50)。当利用不同的目标攻击40/70/100时,我们发现用户配置文件上的方法性能更差,因为目标攻击40和目标攻击70的性能都好于目标攻击100。这意味着引入用户配置文件制作对于降低攻击成本和噪声非常重要。在下一节中,我们将从跨域用户配置文件的数量的角度进一步分析预算。
为了更好地理解文案攻击,我们将其与策略网络、文案攻击屏蔽和文案攻击长度进行了比较。我们可以看到,对于策略网络方法,当消除了层次聚类树的影响时,复制攻击的性能会下降。请注意,ML20M-NF上的策略网络方法不起作用,因为我们不能在48小时内获得其结果,而我们可以在几个小时内获得其他方法的结果。这些观察结果表明了层次聚类树的威力。在下一节中进一步研究层次聚类树的影响。
同时,当我们删除用户配置文件制作组件时,推广性能降低,项目预算非常大,因为所选择的用户配置文件可能会引入太多的噪音,降低性能。此外,当屏蔽机制在复制攻击长度上被删除时,复制攻击掩蔽的性能要差得多(几乎和随机攻击一样差)。这些结果支持了掩蔽机制和用户配置文件制作组件有利于选择强用户配置文件,并降低了每个用户配置文件的攻击成本和噪声。
与生成假用户配置文件(即rl生成)的方法相比,在大多数情况下,复制用户配置文件策略(如目标攻击-40/70/100、策略网络、复制攻击屏蔽和复制攻击长度)在ML10M-FX数据集上表现更好,而rl生成方法在ML20M-NF数据集上的性能优于其他方法。请注意,我们提出的方法复制攻击可以执行超过rl生成。此外,我们还将在表三中报告在跨域用户配置文件和生成式用户配置文件之间检测假用户的性能。
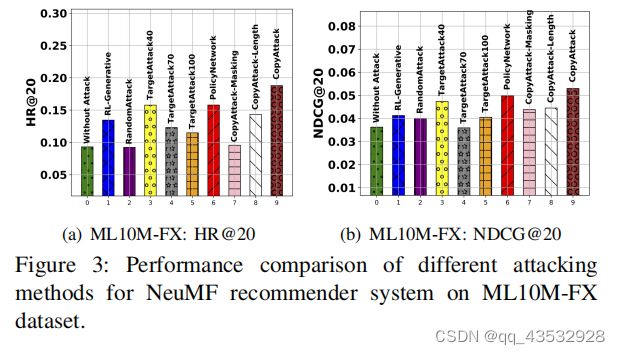
此外,我们还评估了广泛使用的代表性推荐系统NeuMF[2]的攻击性能。由于空间的限制,我们只在ML10M-FX数据集上显示结果。结果如图3所示。我们可以观察到,在HR@20和NDCG@20条件下,我们的方法始终优于其他方法。例如,我们的CopyAttack对目标项目的攻击性能分别提高了16%和4%,w.r.tHR分别为@20和NDCG@20。
C. 检测假的用户配置文件
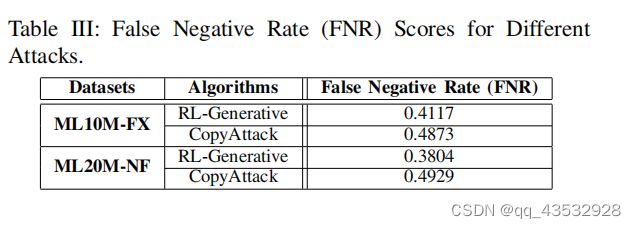
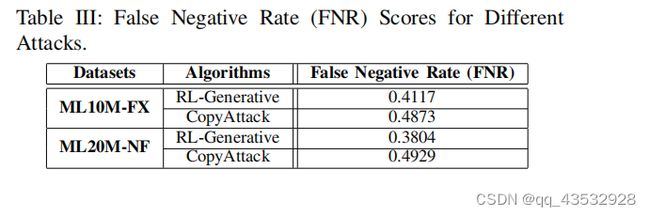
为了在目标推荐系统中成功地执行攻击,拥有尽可能真实的(假)用户档案是至关重要的,这样这些假用户档案就能够逃避目标系统的检测。因此,为了分析从源域B中选择的用户配置文件和通过rl生成的生成用户配置文件在目标域A中是否难以区分,我们使用训练过的SVM分类器来检测虚假的用户配置文件[29]。在我们的实验中,对于每个攻击者,我们生成800个假用户配置文件,并采样800个普通用户配置文件作为训练数据集。我们使用假阴性率(FNR)来衡量检测性能。特别是,FNR是被预测为正常和逃避检测的假用户的比例。请注意,我们只将我们提出的复制攻击与rl生成攻击进行比较,因为其他攻击(即随机攻击、目标攻击40/70/100,策略网络、复制攻击和复制攻击)通过复制用户域屏蔽/长度来获取用户配置文件。
Tabel III报告了在ML10M-FX和ML20MNF数据集上的FNR。我们可以观察到,我们的方法优于rl生成的方法,这意味着生成的用户配置文件更有可能被检测为假的。换句话说,由于它在执行制作阶段后仍然不会被发现,我们提出的方法通过对抗性攻击增强了其对目标项目的提升性能提高的强度。
D. 模型分析
在本小节中,我们将研究模型组件和模型超参数的影响。
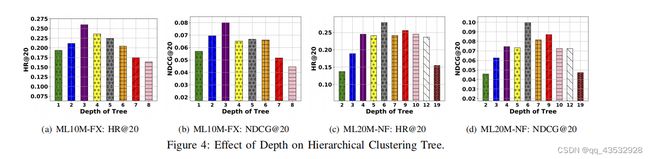
1)深度对层次聚类树的影响:如层次聚类树,在第四节-C1中讨论的,在这里研究,我们展示了当改变树的深度(即d的值)时的性能。我们可以在图4中观察到,对于ML10M-FXd,=3在HR@20和NDCG@20方面表现最好。类似地,在ML20M-NFd中,=6的性能最好。这样做的原因被认为是在集群的详细程度和层次集群树中的策略网络的数量方面的权衡。这是因为,随着树的越深入,我们就需要学习更多的政策网络。相比之下,较浅的树具有较少的策略网络,但可以利用运行时方面的效率和拥有一些大型集群来指导源用户配置文件选择的能力。
2)预算效应(假用户档案的数量):要在黑盒攻击下执行攻击,预算是非常重要的。在本小节中,我们将研究预算如何影响不同攻击方法的性能。图5和图6显示了在ML10M-FX和ML20M-NF数据集上在不同预算下的性能。我们首先注意到,无论有多少用户配置文件,随机攻击都保持稳定。当预算值增加时,将用户配置文件注入目标项的方法的性能往往会首先增加。然后目标攻击40,目标攻击70,目标攻击100,和rl生成不能继续增加,当预算太大,而复制攻击不断增长,因为这种方法执行查询并获得越来越多的奖励来训练攻击。此外,我们还可以观察到,在攻击ML10M-FX数据集的早期状态下,通过RL-生成方法生成的假用户配置文件是无用的,甚至伤害了升级攻击。
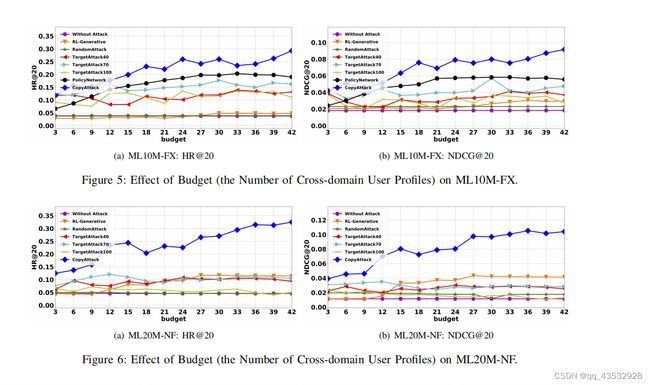
我们再次注意到,在ML20M-NF数据集中,策略网络基线无法在48小时的合理时间限制内完成,因此我们不报告它们的性能。与所有用户的整个动作空间(源域)的单一策略梯度网络相比,这也进一步加强了层次集群树的有效性,因为CopyAttack只在几个小时(例如,大约3小时)内获得结果。
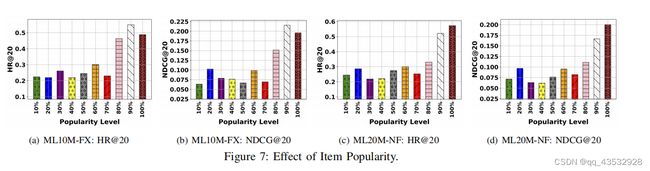
E. 商品流行程度的影响
在本小节中,我们将研究哪些物品容易受到攻击。为了实现这一点,我们根据目标域中的项目的受欢迎程度对其进行分组。具体来说,我们有10个不同的组,其中每个组占目标域中项目的10%。然后,我们分别从这10个不同的组中抽取50个目标项目。最后,我们评估了它们上的性能。结果如图7所示。我们注意到,具有高人气的目标项目很容易受到攻击,而我们的复制攻击可以在前30%的项目中获得更好的攻击性能。我们认为,这是因为大多数相对受欢迎的产品已经相当“热门”和有吸引力,因此,与不太受欢迎(“冷启动”)产品相比,文案攻击更容易在预算有限的情况下将它们推到顶端。
六结论
许多面向用户的在线服务利用基于深度学习的推荐系统,为用户提供个性化的互动列表。虽然研究表明这些模型容易受到攻击,但最近的研究表明,最先进的防御策略能够检测到推荐系统中的数据中毒攻击。这主要是因为注入的假用户配置文件很容易被检测到。因此,在这项工作中,我们提出了一种跨域的方法,将用户配置文件从源域复制到目标域,以促进某些目标项目。更具体地说,我们引入了基于强化学习黑盒方法,利用策略梯度网络首先选择用户复制,改进/工艺的配置文件,最后注入他们在目标领域,我们可以观察一些反馈的Top-k建议我们的间谍用户。然后,这些间谍用户被用来确定更新模型参数的奖励。