深度学习图像增强和模型微调
目录
- 1 常用的图像增强方法
- 2 tf.image进行图像增强
-
- 2.1 翻转和裁剪
- 2.2 颜色变换
- 3 使用ImageDataGenerator()进行图像增强
- 4 模型微调
-
- 4.1 微调
- 4.2 热狗识别
-
- 4.2.1 获取数据集
- 4.3 模型构建与训练
- 5 总结
1 常用的图像增强方法
大规模数据集是成功应用深度神经网络的前提。例如,我们可以对图像进行不同方式的裁剪,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。我们也可以调整亮度、色彩等因素来降低模型对色彩的敏感度。可以说,在当年AlexNet的成功中,图像增强技术功不可没
图像增强(image augmentation)指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。图像增强的意义是通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模,而且随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
常见的图像增强方式可以分为两类:几何变换类和颜色变换类
- 几何变换类,主要是对图像进行几何变换操作,包括翻转,旋转,裁剪,变形,缩放等。

- 颜色变换类,指通过模糊、颜色变换、擦除、填充等方式对图像进行处理
实现图像增强可以通过tf.image来完成,也可以通过tf.keras.imageGenerator来完成。
2 tf.image进行图像增强
导入所需的工具包并读取要处理的图像:
# 导入工具包
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 读取图像并显示
cat = plt.imread('./cat.jpg')
plt.imshow(cat)
2.1 翻转和裁剪
左右翻转图像是最早也是最广泛使用的一种图像增广方法。可以通过tf.image.random_flip_left_right来实现图像左右翻转。
# 左右翻转并显示
cat1 = tf.image.random_flip_left_right(cat)
plt.imshow(cat1)

创建tf.image.random_flip_up_down实例来实现图像的上下翻转,上下翻转使用的较少。
# 上下翻转
cat2 = tf.image.random_flip_up_down(cat)
plt.imshow(cat2)

随机裁剪出一块面积为原面积10%∼100%的区域,且该区域的宽和高之比随机取自0.5∼2,然后再将该区域的宽和高分别缩放到200像素。
# 随机裁剪
cat3 = tf.image.random_crop(cat,(200,200,3))
plt.imshow(cat3)

2.2 颜色变换
另一类增广方法是颜色变换。我们可以从4个方面改变图像的颜色:亮度、对比度、饱和度和色调。接下来将图像的亮度随机变化为原图亮度的50%(即1−0.5)∼150%(即1+0.5)。
cat4=tf.image.random_brightness(cat,0.5)
plt.imshow(cat4)

类似地,我们也可以随机变化图像的色调
cat5 = tf.image.random_hue(cat,0.5)
plt.imshow(cat5)

3 使用ImageDataGenerator()进行图像增强
ImageDataGenerator()是keras.preprocessing.image模块中的图片生成器,可以在batch中对数据进行增强,扩充数据集大小,增强模型的泛化能力。比如旋转,变形等,如下所示:
keras.preprocessing.image.ImageDataGenerator(
rotation_range=0, #整数。随机旋转的度数范围。
width_shift_range=0.0, #浮点数、宽度平移
height_shift_range=0.0, #浮点数、高度平移
brightness_range=None, # 亮度调整
shear_range=0.0, # 裁剪
zoom_range=0.0, #浮点数 或 [lower, upper]。随机缩放范围
horizontal_flip=False, # 左右翻转
vertical_flip=False, # 垂直翻转
rescale=None # 尺度调整
)
来看下水平翻转的结果:
# 获取数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 将数据转换为4维的形式
x_train = X_train.reshape(X_train.shape[0],28,28,1)
x_test = X_test.reshape(X_test.shape[0],28,28,1)
# 设置图像增强方式:水平翻转
datagen = ImageDataGenerator(horizontal_flip=True)
# 查看增强后的结果
for X_batch,y_batch in datagen.flow(x_train,y_train,batch_size=9):
plt.figure(figsize=(8,8)) # 设定每个图像显示的大小
# 产生一个3*3网格的图像
for i in range(0,9):
plt.subplot(330+1+i)
plt.title(y_batch[i])
plt.axis('off')
plt.imshow(X_batch[i].reshape(28,28),cmap='gray')
plt.show()
break

4 模型微调
4.1 微调
如何在只有6万张图像的MNIST训练数据集上训练模型。学术界当下使用最广泛的大规模图像数据集ImageNet,它有超过1,000万的图像和1,000类的物体。然而,我们平常接触到数据集的规模通常在这两者之间。假设我们想从图像中识别出不同种类的椅子,然后将购买链接推荐给用户。一种可能的方法是先找出100种常见的椅子,为每种椅子拍摄1,000张不同角度的图像,然后在收集到的图像数据集上训练一个分类模型。另外一种解决办法是应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。例如,虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
微调由以下4步构成。
- 在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
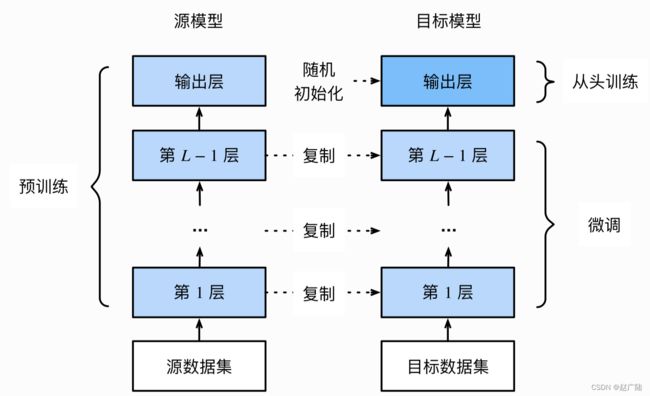
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
4.2 热狗识别
接下来我们来实践一个具体的例子:热狗识别。将基于一个小数据集对在ImageNet数据集上训练好的ResNet模型进行微调。该小数据集含有数千张热狗或者其他事物的图像。我们将使用微调得到的模型来识别一张图像中是否包含热狗。
首先,导入实验所需的工具包。
import tensorflow as tf
import numpy as np
4.2.1 获取数据集
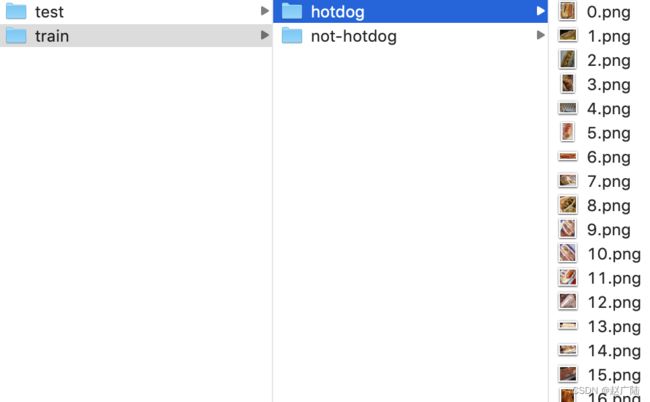
每个类别文件夹里面是图像文件。
上一节中我们介绍了ImageDataGenerator进行图像增强,我们可以通过以下方法读取图像文件,该方法以文件夹路径为参数,生成经过图像增强后的结果,并产生batch数据:
flow_from_directory(self, directory,
target_size=(256, 256), color_mode='rgb',
classes=None, class_mode='categorical',
batch_size=32, shuffle=True, seed=None,
save_to_dir=None)
主要参数:
- directory: 目标文件夹路径,对于每一个类对应一个子文件夹,该子文件夹中任何JPG、PNG、BNP、PPM的图片都可以读取。
- target_size: 默认为(256, 256),图像将被resize成该尺寸。
- batch_size: batch数据的大小,默认32。
- shuffle: 是否打乱数据,默认为True。
我们创建两个tf.keras.preprocessing.image.ImageDataGenerator实例来分别读取训练数据集和测试数据集中的所有图像文件。将训练集图片全部处理为高和宽均为224像素的输入。此外,我们对RGB(红、绿、蓝)三个颜色通道的数值做标准化。
# 获取数据集
import pathlib
train_dir = 'transferdata/train'
test_dir = 'transferdata/test'
# 获取训练集数据
train_dir = pathlib.Path(train_dir)
train_count = len(list(train_dir.glob('*/*.jpg')))
# 获取测试集数据
test_dir = pathlib.Path(test_dir)
test_count = len(list(test_dir.glob('*/*.jpg')))
# 创建imageDataGenerator进行图像处理
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
# 设置参数
BATCH_SIZE = 32
IMG_HEIGHT = 224
IMG_WIDTH = 224
# 获取训练数据
train_data_gen = image_generator.flow_from_directory(directory=str(train_dir),
batch_size=BATCH_SIZE,
target_size=(IMG_HEIGHT, IMG_WIDTH),
shuffle=True)
# 获取测试数据
test_data_gen = image_generator.flow_from_directory(directory=str(test_dir),
batch_size=BATCH_SIZE,
target_size=(IMG_HEIGHT, IMG_WIDTH),
shuffle=True)
下面我们随机取1个batch的图片然后绘制出来。
import matplotlib.pyplot as plt
# 显示图像
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10,10))
for n in range(15):
ax = plt.subplot(5,5,n+1)
plt.imshow(image_batch[n])
plt.axis('off')
# 随机选择一个batch的图像
image_batch, label_batch = next(train_data_gen)
# 图像显示
show_batch(image_batch, label_batch)

4.3 模型构建与训练
我们使用在ImageNet数据集上预训练的ResNet-50作为源模型。这里指定weights='imagenet'来自动下载并加载预训练的模型参数。在第一次使用时需要联网下载模型参数。
Keras应用程序(keras.applications)是具有预先训练权值的固定架构,该类封装了很多重量级的网络架构,如下图所示:
实现时实例化模型架构:
tf.keras.applications.ResNet50(
include_top=True, weights='imagenet', input_tensor=None, input_shape=None,
pooling=None, classes=1000, **kwargs
)
主要参数:
- include_top: 是否包括顶层的全连接层。
- weights: None 代表随机初始化, ‘imagenet’ 代表加载在 ImageNet 上预训练的权值。
- input_shape: 可选,输入尺寸元组,仅当 include_top=False 时有效,否则输入形状必须是 (224, 224, 3)(channels_last 格式)或 (3, 224, 224)(channels_first 格式)。它必须为 3 个输入通道,且宽高必须不小于 32,比如 (200, 200, 3) 是一个合法的输入尺寸。
在该案例中我们使用resNet50预训练模型构建模型:
# 加载预训练模型
ResNet50 = tf.keras.applications.ResNet50(weights='imagenet', input_shape=(224,224,3))
# 设置所有层不可训练
for layer in ResNet50.layers:
layer.trainable = False
# 设置模型
net = tf.keras.models.Sequential()
# 预训练模型
net.add(ResNet50)
# 展开
net.add(tf.keras.layers.Flatten())
# 二分类的全连接层
net.add(tf.keras.layers.Dense(2, activation='softmax'))
接下来我们使用之前定义好的ImageGenerator将训练集图片送入ResNet50进行训练。
# 模型编译:指定优化器,损失函数和评价指标
net.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 模型训练:指定数据,每一个epoch中只运行10个迭代,指定验证数据集
history = net.fit(
train_data_gen,
steps_per_epoch=10,
epochs=3,
validation_data=test_data_gen,
validation_steps=10
)
123456789101112
Epoch 1/3
10/10 [==============================] - 28s 3s/step - loss: 0.6931 - accuracy: 0.5031 - val_loss: 0.6930 - val_accuracy: 0.5094
Epoch 2/3
10/10 [==============================] - 29s 3s/step - loss: 0.6932 - accuracy: 0.5094 - val_loss: 0.6935 - val_accuracy: 0.4812
Epoch 3/3
10/10 [==============================] - 31s 3s/step - loss: 0.6935 - accuracy: 0.4844 - val_loss: 0.6933 - val_accuracy: 0.4875
5 总结
- 常用的图像增强方法:几何和颜色
- 在tf,keras中可以通过:tf.image和ImageDataGenerator()完成图像增强
- 微调是目标模型复制了源模型上除了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参数。而目标模型的输出层需要从头训练。
- 利用tf.keras中的application实现迁移学习