nlp自然语言处理
介绍 (Introduction)
Natural language processing (NLP) is an intimidating name for an intimidating field. Generating useful insight from unstructured text is hard, and there are countless techniques and algorithms out there, each with their own use-cases and complexities. As a developer with minimal NLP exposure, it can be difficult to know which methods to use, and how to implement them. I’m here to help.
自然语言处理(NLP)是令人生畏的字段的一个令人生畏的名称。 从非结构化文本中生成有用的见解是很困难的 ,并且存在无数的技术和算法,每种技术和算法都有自己的用例和复杂性。 作为具有最少NLP暴露的开发人员,可能很难知道要使用哪种方法以及如何实现它们。 我是来帮忙的。
If I were to offer perfect results for minimal effort, you would be right to be skeptical. Instead, using the 80/20 Principle, I’ll show you how to quickly (20%) deliver solutions, without significantly sacrificing outcomes (80%).
如果我以最小的努力提供完美的结果,那么您将持怀疑态度是正确的。 相反,我将使用80/20原理向您展示如何快速(20%)交付解决方案,而又不显着牺牲成果(80%)。
“The 80/20 Principle exerts that a minority of causes, inputs, or efforts usually leads to a majority of results, outputs, or rewards”
“ 80/20原则认为,少数原因,投入或努力通常会导致大部分结果,产出或回报”
-Richard Koch, author of The 80/20 Principle
-理查德·科赫(Richard Koch),《 80/20原理》的作者
How exactly will we achieve this goal? With some fantastic Python libraries! Instead of reinventing the wheel, we may stand on the shoulders of giants and innovate quickly. With pre-tested implementations and pre-trained models, we will focus on applying these methods and creating value.
我们究竟将如何实现这一目标? 拥有一些很棒的Python库! 与其重新发明轮子,不如我们站在巨人的肩膀上并Swift进行创新。 通过预测试的实现和预训练的模型,我们将专注于应用这些方法并创造价值。
This article is intended for developers looking to quickly integrate natural language processing into their projects. With an emphasis on ease of use and rapid results comes the downside of reduced performance. In my experience, 80% of cutting-edge is plenty for projects, but look elsewhere for NLP research :)
本文适用于希望将自然语言处理快速集成到其项目中的开发人员。 强调易用性和快速的结果是降低性能的不利方面。 根据我的经验,80%的尖端技术可以满足项目的需求,但是可以将其用于NLP研究:)
Without further ado, let’s begin!
事不宜迟,让我们开始吧!
什么是NLP? (What is NLP?)
Natural language processing is a subfield of linguistics, computer science, and artificial intelligence, allowing for the automatic processing of text by software. NLP gives machines the ability to read, understand, and respond to messy, unstructured text.
自然语言处理是语言学,计算机科学和人工智能的一个子领域,允许通过软件自动处理文本。 NLP使机器能够阅读,理解和响应杂乱的非结构化文本。
People often treat NLP as a subset of machine learning, but the reality is more nuanced.
人们通常将NLP视为机器学习的子集,但实际情况却更加细微。
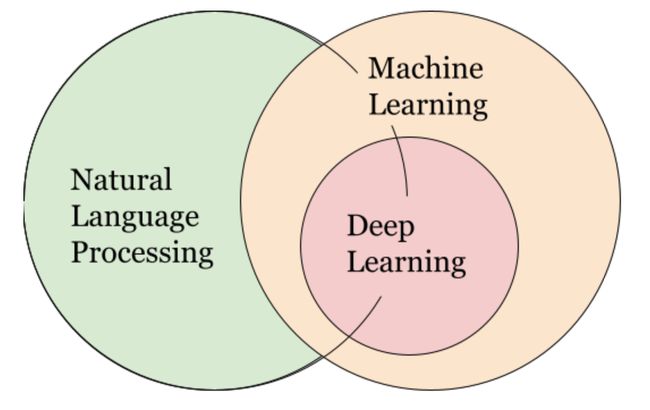
Some NLP tools rely on machine learning, and some even use deep learning. However these methods often rely on large datasets and are difficult to implement. Instead, we will focus on simpler, rule-based methods to speed up the development cycle.
一些NLP工具依赖于机器学习,有些甚至使用深度学习。 但是,这些方法通常依赖于大型数据集,并且难以实现。 相反,我们将专注于基于规则的更简单方法,以加快开发周期。
术语 (Terminology)
Starting with the smallest unit of data, a character is a single letter, number, or punctuation. A word is a list of characters, and a sentence is a list of words. A document is a list of sentences, and a corpus is a list of documents.
从最小的数据单位开始, 字符是单个字母,数字或标点符号。 单词是字符列表, 句子是单词列表。 文档是句子列表,而语料库是文档列表。
预处理 (Pre-Processing)
Pre-processing is perhaps the most important step to a NLP project, and involves cleaning your inputs so your models can ignore the noise and focus on what matters most. A strong pre-processing pipeline will improve the performance of all your models, so I cannot stress it’s value enough.
预处理可能是NLP项目最重要的步骤,涉及清理输入内容,以便模型可以忽略噪声并集中精力处理最重要的事情。 强大的预处理管道将改善您所有模型的性能,因此我无法强调它的价值。
Below are some common pre-processing steps:
以下是一些常见的预处理步骤:
Segmentation: Given a long list of characters, we might separate documents by white space, sentences by periods, and words by spaces. Implementation details will vary based on the dataset.
细分 :给定一长串字符,我们可以按空格分隔文档,按句点分隔句子,并按空格分隔单词。 实施细节将根据数据集而有所不同。
Make Lowercase: Capitalization generally does not add value, and makes string comparison trickier. Just make everything lowercase.
小写 :大写通常不会增加价值,并使字符串比较棘手。 只需将所有内容都小写即可。
Remove Punctuation: We may want to remove commas, quotes, and other punctuation that does not add to the meaning.
删除标点符号 :我们可能希望删除逗号,引号和其他不会增加含义的标点符号。
Remove Stopwords: Stopwords are words like ‘she’, ‘the’, and ‘of’ that do not add to the meaning of a text, and can distract from the more relevant keywords.
删除停用词:停用词是“ she”,“ the”和“ of”之类的词,它们不会增加文本的含义,并且会分散相关性。
Remove Other: Depending on your application, you may want to remove certain words that do not add value. For example, if evaluating course reviews, words like ‘professor’ and ‘course’ may not be useful.
删除其他 :根据您的应用程序,您可能希望删除某些不会增加价值的单词。 例如,如果评估课程评论,则“教授”和“课程”之类的词可能没有用。
Stemming/Lemmatization: Both stemming and lemmatization generate the root form of inflected words (ex: ‘running’ to ‘run’). Stemming is faster, but does not guarantee the root is an English word. Lemmatization uses a corpus to ensure the root is a word, at the expense of speed.
词干/词法化 :词干和词法化都会产生词尾的词根形式(例如:“运行”到“运行”)。 词干速度更快,但不能保证词根是英语单词。 词法化使用语料库来确保词根是单词,但要牺牲速度。
Part of Speech Tagging: POS tagging marks words with their part of speech (nouns, verbs, prepositions) based on definition and context. For example, we can focus on nouns for keyword extraction.
词性标注 :POS标记根据定义和上下文用词性(名词,动词,介词)标记单词。 例如,我们可以专注于名词以进行关键字提取。
For a more thorough introduction to these concepts, check out this amazing guide:
有关这些概念的更全面介绍,请查看此出色的指南:
These steps are the foundation of a successful pre-processing pipeline. Depending on your dataset and task, you may skip certain steps or add new ones. Manually observe your data through pre-processing, and correct issues as they arise.
这些步骤是成功的预处理流程的基础。 根据您的数据集和任务,您可以跳过某些步骤或添加新步骤。 通过预处理手动观察数据,并在出现问题时进行纠正。
Python库 (Python Libraries)

Let’s take a look at a couple leading Python libraries for NLP. These tools will handle most of the heavy lifting during and especially after pre-processing
让我们看一下几个领先的NLP Python库。 这些工具将在预处理过程中以及在预处理之后处理大部分繁重的工作
NLTK (NLTK)
The Natural Language Tool Kit is the most widely-used NLP library for Python. Developed at UPenn for academic purposes, NLTK has a plethora of features and corpora. NLTK is great for playing with data and running pre-processing.
自然语言工具包是Python使用最广泛的NLP库。 NLTK由UPenn开发,用于学术目的,具有许多功能和语料库。 NLTK非常适合处理数据和运行预处理。
Here is an example from the NLTK website showing how simple it is to tokenize a sentence and tag parts of speech.
这是NLTK网站上的示例,显示标记句子和标记语音部分有多简单。
空间 (SpaCy)
SpaCy is a modern and opinionated package. While NLTK has multiple implementations of each feature, SpaCy keeps only the best performing ones. Spacy supports a wide range of features, read the docs for more details:
SpaCy是一种现代且自以为是的软件包。 尽管NLTK每种功能都有多种实现,但SpaCy仅保留性能最佳的功能。 Spacy支持多种功能,请阅读文档以获取更多详细信息:
In just a few lines, we are able to perform Named Entity Recognition with SpaCy. Many other tasks can be accomplished quickly using the SpaCy API.
仅需几行,我们就可以使用SpaCy执行命名实体识别。 使用SpaCy API可以快速完成许多其他任务。
GenSim (GenSim)
Unlike NLTK and SpaCy, GenSim specifically tackles the problem of information retrieval (IR). Developed with an emphasis on memory management, GenSim contains many models for document similarity, including Latent Semantic Indexing, Word2Vec, and FastText.
与NLTK和SpaCy不同,GenSim专门解决信息检索(IR)问题。 GenSim着重于内存管理,它包含许多用于文档相似性的模型,包括潜在语义索引,Word2Vec和FastText。
Below is an example of a pre-trained GenSim Word2Vec model that finds word similarities. Without worrying about the messy details, we can quickly get results.
以下是发现单词相似性的预训练GenSim Word2Vec模型的示例。 无需担心混乱的细节,我们可以快速获得结果。
和更多… (And More…)
This list is by no means comprehensive, but covers a range of features and use-cases. I recommend checking this repository for more tools and references.
该列表绝不是全面的,而是涵盖了一系列功能和用例。 我建议检查此存储库以获取更多工具和参考。
应用领域 (Applications)
Now that we have discussed pre-processing methods and Python libraries, let’s put it all together with a few examples. For each, I’ll cover a couple of NLP algorithms, pick one based on our rapid development goals, and create a simple implementation using one of the libraries.
现在我们已经讨论了预处理方法和Python库,让我们将其与一些示例放在一起。 对于每种方法,我将介绍几种NLP算法,根据我们的快速开发目标选择一种,并使用其中一种库创建简单的实现。
应用程序1:预处理 (Application #1: Pre-Processing)
Pre-processing is a critical part of any NLP solution, so let’s see how we can speed up the process with Python libraries. In my experience, NLTK has all the tools we need, with customization for unique use cases. Let’s load a sample corpus.
预处理是任何NLP解决方案的关键部分,因此让我们看看如何使用Python库加快处理速度。 以我的经验,NLTK拥有我们需要的所有工具,并且可以针对独特的用例进行定制。 让我们加载样本语料库。
Following the pipeline defined above, we can use NLTK to implement segmentation, removing punctuation and stopwords, performing lemmatization, and more. Look how easy it is to remove stopwords:
按照上面定义的管道,我们可以使用NLTK来实现分段,删除标点和停用词,执行词形化等等。 看看删除停用词有多么容易:
The entire pre-processing pipeline took me less than 40 lines of Python. See the full code here. Remember, this is a generalized example, and you should modify the process as needed for your specific use case.
整个预处理流程占用了我不到40行Python。 在此处查看完整代码。 请记住,这是一个概括的示例,您应根据特定用例的需要修改流程。
应用程序2:文档聚类 (Application #2: Document Clustering)
Document clustering is a common task in natural language processing, so let’s discuss some ways to do it. The general idea here is to assign each document a vector representing the topics discussed:
文档聚类是自然语言处理中的常见任务,因此让我们讨论一些方法。 这里的总体思路是为每个文档分配一个表示所讨论主题的向量:

If the vectors are two dimensional, we can visualize the documents, like above. In this example, we see documents A and B are closely related, while D and F are loosely related. Using a distance metric, we can calculate similarity even when these vectors are three, one hundred, or one thousand dimensional.
如果向量是二维的,我们可以像上面那样可视化文档。 在此示例中,我们看到文档A和B紧密相关,而D和F松散相关。 使用距离度量,即使这些向量是3维,100维或1000维,我们也可以计算相似度。
The next question is how to construct these vectors for each document, using the unstructured text input. Here there are a few options, from simplest to most complex:
下一个问题是如何使用非结构化文本输入为每个文档构造这些向量。 这里有一些选项,从最简单到最复杂:
Bag of Words: Assign each unique word a dimension. The vector for a given document is the frequency each word occurs.
单词袋 :为每个唯一的单词分配一个维度。 给定文档的向量是每个单词出现的频率。
Term Frequency — Inverse Document Frequency (TF-IDF): Scale the Bag of Words representation by how common a word is in other documents. If two documents share a rare word, they are more similar than if they share a common one.
术语频率-反向文档频率(TF-IDF) :根据单词在其他文档中的普遍程度来缩放“词袋”表示。 如果两个文档共享一个稀有单词,则比共享一个公共文档更相似。
Latent Semantic Indexing (LSI): Bag of Words and TF-IDF can create highly dimensional vectors, which makes distance measures less accurate. LSI collapses these vectors to a more manageable size while minimizing information loss.
潜在语义索引(LSI) :单词袋和TF-IDF可以创建高维向量,这会使距离度量的准确性降低。 LSI将这些向量压缩到更易于管理的大小,同时最大程度地减少了信息丢失。
Word2Vec: Using a neural network, learn word associations from a large text corpus. Then add up the vectors for each word to get a document vector.
Word2Vec :使用神经网络从大型文本语料库学习单词联想。 然后将每个单词的向量相加以获得文档向量。
Doc2Vec: Building upon Word2Vec but using a better method to approximate the document vector from its list of word vectors.
Doc2Vec :建立在Word2Vec的基础上,但使用更好的方法从其单词向量列表中近似文档向量。
Word2Vec and Doc2Vec are quite complicated and require large datasets to learn word embeddings. We could use pre-trained models, but they may not scale well to tasks within niche fields. Instead, we will use Bag of Words, TF-IDF, and LSI.
Word2Vec和Doc2Vec相当复杂,需要大量数据集才能学习单词嵌入。 我们可以使用经过预训练的模型,但它们可能无法很好地适应利基领域内的任务。 相反,我们将使用单词袋,TF-IDF和LSI。
Now to choose our library. GenSim is specifically built for this task and contains easy implementations of all three algorithms, so let’s use GenSim.
现在选择我们的图书馆。 GenSim是专门为此任务而构建的,并且包含所有三种算法的简单实现,因此让我们使用GenSim。
For this example, let’s use the Brown corpus again. It has 15 documents for categories of text, such as ‘adventure’, ‘editorial’, ‘news’, etc. After running our NLTK pre-processing routine, we can begin applying the GenSim models.
对于此示例,让我们再次使用Brown语料库。 它有15个文本类别的文档,例如“冒险”,“编辑”,“新闻”等。运行NLTK预处理例程后,我们可以开始应用GenSim模型。
First, we create a dictionary mapping tokens to unique indexes.
首先,我们创建一个字典,将令牌映射到唯一索引。
Next, we iteratively apply Bag of Words, Term Frequency — Inverse Document Frequency, and Latent Semantic Indexing:
接下来,我们迭代地应用单词袋,术语频率-逆文档频率和潜在语义索引:
In just ~10 lines of Python, we handled three separate models, and extracted vector representations for our documents. Using cosine similarity for vector comparison, we can find the most similar documents.
在大约10行Python中,我们处理了三个单独的模型,并提取了文档的矢量表示。 使用余弦相似度进行矢量比较,我们可以找到最相似的文档。
And just like that, we have results! Adventure texts are most similar to fiction and romance, while editorials are similar to news and government. It checks out. Check the full code here.
这样,我们就可以取得结果! 冒险文本与小说和浪漫史最相似,而社论与新闻和政府相似。 它签出。 在此处检查完整代码。
应用程序3:情感分析 (Application #3: Sentiment Analysis)
Sentiment analysis is the interpretation of unstructured text as positive, negative, or neutral. Sentiment analysis is a useful tool for analyzing reviews, measuring brand, building AI chatbots, and more.
情感分析是将非结构化文本解释为肯定,否定或中性的内容。 情绪分析是一种有用的工具,可用于分析评论,评估品牌,构建AI聊天机器人等。
Unlike document clustering, where pre-processing was applied, we do not use pre-processing in sentiment analysis. The punctuation, flow, and context of a passage can reveal a lot about the sentiment, so we do not want to remove them. Instead, we jump straight into the models.
与文档聚类不同,文档聚类应用了预处理,因此在情感分析中我们不使用预处理 。 段落的标点,流和上下文可以揭示很多有关情绪的信息,因此我们不想删除它们。 相反,我们直接进入模型。
Keeping things simple and effective, I recommend using pattern-based sentiment analysis. By searching for specific keywords, sentence structure, and punctuation marks, these models measure the text’s polarity. Here are two libraries with built-in sentiment analyzers:
为了使事情简单有效,我建议使用基于模式的情感分析。 通过搜索特定的关键字,句子结构和标点符号,这些模型可以测量文本的极性。 这是两个带有内置情绪分析器的库:
VADER Sentiment Analysis:
VADER情绪分析 :
VADER stands for Valence Aware Dictionary and sEntiment Recognizer, and is an extension of NLTK for sentiment analysis. It uses patterns to calculate sentiment, and works especially well with emojis and texting slang. It’s also super easy to implement.
VADER代表Valence Aware词典和情感识别器,并且是NLTK用于情感分析的扩展。 它使用模式来计算情感,并且特别适用于表情符号和短信语。 它也超级容易实现。
TextBlob Sentiment Analysis:
TextBlob情绪分析 :
A similar tool is TextBlob for sentiment analysis. TextBlob is actually a versatile library similar to NLTK and SpaCy. Regarding its sentiment analysis tool, it differs from VADER in reporting both polarity and subjectivity. From my personal experience, I prefer VADER, but each has its own strengths and weaknesses. TextBlob is also exceedingly easy to implement:
类似的工具是TextBlob,用于情感分析。 实际上,TextBlob是类似于NLTK和SpaCy的通用库。 关于情感分析工具,它在报告极性和主观性方面与VADER不同。 从我的个人经验来看,我更喜欢VADER,但每个人都有自己的优点和缺点。 TextBlob也非常容易实现:
Note: Pattern based models do not perform well on such small texts as in the examples above. I recommend sentiment analysis on texts averaging four sentences. For a quick demonstration of this, refer to the Jupyter Notebook.
注意:基于模式的模型在上述示例中的小文本上效果不佳。 我建议对平均四个句子的文本进行情感分析。 有关此内容的快速演示,请参阅Jupyter Notebook 。
其他应用 (Other Applications)
Here are a couple of additional topics and some useful algorithms and tools to accelerate your development.
这里有几个其他主题以及一些有用的算法和工具,可以加快您的开发速度。
Keyword Extraction: Named Entity Recognition (NER) using SpaCy, Rapid Automatic Keyword Extraction (RAKE) using ntlk-rake
关键字提取:使用SpaCy的命名实体识别(NER),使用ntlk-rake的快速自动关键字提取(RAKE)
Text Summarization: TextRank (similar to PageRank) using PyTextRank SpaCy extension, TF-IDF using GenSim
文字摘要 :使用PyTextRank SpaCy扩展名的TextRank(类似于PageRank),使用GenSim的TF-IDF
Spell Check: PyEnchant, SymSpell Python ports
拼写检查 :PyEnchant,SymSpell Python端口
Hopefully, these examples help demonstrate the plethora of resources available for natural language processing in Python. Regardless of the problem, chances are someone has developed a library to streamline the process. Using these libraries can yield great results in a short time frame.
希望这些示例有助于说明Python中用于自然语言处理的大量资源。 不管出现什么问题,都有可能有人开发了一个库来简化流程。 使用这些库可以在很短的时间内产生很好的结果。
技巧和窍门 (Tips and Tricks)
With an introduction to NLP, an overview of Python libraries, and some example applications, you’re almost ready to tackle your own challenges. Finally, I have a few tips and tricks to make the most of these resources.
通过介绍NLP,Python库概述和一些示例应用程序,您几乎已经准备好应对自己的挑战。 最后,我有一些技巧和窍门,可以充分利用这些资源。
Python Tooling: I recommend Poetry for dependency management, Jupyter Notebook for testing new models, Black and/or Flake8 for linting, and GitHub for version management.
Python工具 :我建议使用Poetry进行依赖关系管理,建议使用Jupyter Notebook来测试新模型,使用Black和/或Flake8进行linting,以及GitHub进行版本管理。
Stay organized: It can be easy to jump around from library to library, copying in code to test a dozen ideas. Instead, I recommend a more measured approach. You don’t want to miss a great solution in your haste.
保持井井有条 :可以轻松地从一个库跳到另一个库,复制代码以测试十几个想法。 相反,我建议采用一种更严格的方法。 您不想在匆忙中错过一个很好的解决方案。
Pre-Processing: Garbage in, garbage out. It’s super important to implement a strong pre-processing pipeline to clean your inputs. Visually check the processed text to ensure everything is working as expected.
预处理 :垃圾进,垃圾出。 实施强大的预处理管道来清理您的输入非常重要。 目视检查已处理的文本,以确保一切正常。
Presenting Results: Choosing how to present your results can make a huge difference. If your outputted text look a little rough, consider presenting aggregate statistics or numeric results instead.
呈现结果 :选择如何呈现结果会产生巨大的变化。 如果输出的文本看起来有些粗糙,请考虑显示汇总统计信息或数字结果。
You should be well equipped to tackle some real-world NLP projects now. Good luck, and happy coding :)
您现在应该有能力应对一些实际的NLP项目。 祝您好运,并祝您编程愉快:)
If you do anything cool with this information, leave a response in the comments. If you have any feedback or insights, feel free to connect with me on LinkedIn. Thanks for reading!
如果您对这些信息感兴趣,请在评论中留下答复。 如果您有任何反馈或见解,请随时在 LinkedIn 上与我联系 。 谢谢阅读!
翻译自: https://towardsdatascience.com/natural-language-processing-nlp-dont-reinvent-the-wheel-8cf3204383dd
nlp自然语言处理