使用 Apache Solr 实现更加灵巧的搜索,第 2 部分: 用于企业的 Solr
在本系列的 第 1 部分,我为您介绍了 Apache Solr,一种基于 HTTP 的开源搜索服务器,它可以很容易地与多种 Web 应用程序集成。我展示了 Solr 最基本的功能,包括索引、搜索和浏览,介绍了 Solr 模式并解释了它在配置 Solr 功能方面的作用。在本部分中,我将通过列举 Solr 作为大型生产环境中理想的解决方案时所具备的特性来完成对 Solr 的介绍。涵盖的主题包括管理、缓存、复制和可扩展性。
请参阅 第 1 部分 来获得安装和设置 Solr 的指导。
本部分介绍了可用于监视和控制 Solr 功能性的诸多选项,首先来看看 Solr 的 Administration Start Page,该页可在 http://localhost:8080/solr/admin/ 找到。一旦找到了起始页,在继续之前,请务必花些时间熟悉一下上面的各种菜单选项。在起始页中,根据这些选项所提供的信息的不同对它们进行了分组:
- Solr 给出了有关这种活动模式(请参见 第 1 部分)、配置以及当前部署的统计数据的详细信息。
- App server 给出了容器的当前状态,包括 threading 信息以及所有 Java 系统属性的列表。
- Make a Query 提供了调试查询所需的快捷界面以及到功能更加全面的查询界面的链接。
- Assistance 提供了到外部资源的有用链接以便理解和解决使用 Solv 可能遇到的一些问题。
如下的章节详细介绍了这些菜单选项并重点突出了其中的管理特性。
要使用 Solr 的配置选项,可以单击初始页上的 CONFIG 链接,这会显示当前的 solrconfig.xml 文件。您可以在 示例应用程序 的 dw-solr/solr/conf 目录找到该文件。现在,让我们先来看看与索引和查询处理有关的一些常见的配置选项,而与 缓存、复制 和 扩展 Solr 有关的配置选项则留到后面的章节再介绍。
mainIndex 标记段定义了控制 Solr 索引处理的低水平的 Lucene 因素。Lucene 基准发布(位于 Lucene 源代码的 contrib/benchmark之下)包含了很多可用来对这些因素的更改效果进行基准测试的工具。此外,请参阅 参考资料 一节中的 “Solr 性能因素” 来了解与各种更改相关的性能权衡。表 1 概括了可控制 Solr 索引处理的各种因素:
表 1. 对性能因素进行索引
| 因素 | 描述 |
|---|---|
| useCompoundFile | 通过将很多 Lucene 内部文件整合到单一一个文件来减少使用中的文件的数量。这可有助于减少 Solr 使用的文件句柄数目,代价是降低了性能。除非是应用程序用完了文件句柄,否则false 的默认值应该就已经足够。 |
| mergeFactor | 决定低水平的 Lucene 段被合并的频率。较小的值(最小为 2)使用的内存较少但导致的索引时间也更慢。较大的值可使索引时间变快但会牺牲较多的内存。 |
| maxBufferedDocs | 在合并内存中文档和创建新段之前,定义所需索引的最小文档数。段 是用来存储索引信息的 Lucene 文件。较大的值可使索引时间变快但会牺牲较多的内存。 |
| maxMergeDocs | 控制可由 Solr 合并的 Document 的最大数。较小的值 (< 10,000) 最适合于具有大量更新的应用程序。 |
| maxFieldLength | 对于给定的 Document,控制可添加到 Field 的最大条目数,进而截断该文档。如果文档可能会很大,就需要增加这个数值。然而,若将这个值设置得过高会导致内存不足错误。 |
| unlockOnStartup | unlockOnStartup 告知 Solr 忽略在多线程环境中用来保护索引的锁定机制。在某些情况下,索引可能会由于不正确的关机或其他错误而一直处于锁定,这就妨碍了添加和更新。将其设置为true 可以禁用启动锁定,进而允许进行添加和更新。 |
在 <query> 部分,有一些与 缓存 无关的特性,这一点您需要知道。首先,<maxBooleanClauses> 标记定义了可组合在一起形成一个查询的子句数量的上限。对于大多数应用程序而言,默认的 1024 就应该已经足够;然而,如果应用程序大量使用了通配符或范围查询,增加这个限值将能避免当值超出时,抛出 TooManyClausesException。
通配符和范围查询
* 和
?通配符运算符,而范围查询则要求匹配文档必须要在指定的范围之内。例如,若查找
b*,可能导致潜在的数千个不同项都组合进这个查询,进而会导致
TooManyClausesException。
接下来,若应用程序预期只会检索 Document 上少数几个 Field,那么可以将 <enableLazyFieldLoading> 属性设置为 true。懒散加载的一个常见场景大都发生在应用程序返回和显示一系列搜索结果的时候,用户常常会单击其中的一个来查看存储在此索引中的原始文档。初始的显示常常只需要显示很短的一段信息。若考虑到检索大型 Document 的代价,除非必需,否则就应该避免加载整个文档。
最后,<query> 部分负责定义与在 Solr 中发生的事件相关的几个选项。首先,作为一种介绍的方式,Solr(实际上是 Lucene)使用称为Searcher 的 Java 类来处理 Query 实例。Searcher 将索引内容相关的数据加载到内存中。根据索引、CPU 以及可用内存的大小,这个过程可能需要较长的一段时间。要改进这一设计和显著提高性能,Solr 引入了一种 “温暖” 策略,即把这些新的 Searcher 联机以便为现场用户提供查询服务之前,先对它们进行 “热身”。<query> 部分中的<listener> 选项定义 newSearcher 和 firstSearcher 事件,您可以使用这些事件来指定实例化新搜索程序或第一个搜索程序时应该执行哪些查询。如果应用程序期望请求某些特定的查询,那么在创建新搜索程序或第一个搜索程序时就应该反注释这些部分并执行适当的查询。
solrconfig.xml 文件的剩余部分,除 <admin> 之外,涵盖了与 缓存、复制 和 扩展或定制 Solr 有关的项目。admin 部分让您可以定制管理界面。有关配置 admin 节的更多信息,请参看 Solr Wiki 和 solrconfig.xml 文件中的注释。
在 http://localhost:8080/solr/admin 的管理页,有几个菜单条目可以让 Solr 管理员监视 Solr 过程。表 2 给出了这些条目:
表 2. 用于监视、记录和统计数据的 Solr 管理选项
| 菜单名 | Admin URL | 描述 |
|---|---|---|
| Statistics | http://localhost:8080/solr/admin/stats.jsp | Statistics 管理页提供了与 Solr 性能相关的很多有用的统计数据。这些数据包括:
|
| Info | http://localhost:8080/solr/admin/registry.jsp | 有关正在运行的 Solr 的版本以及在当前实现中进行查询、更新和缓存所使用的类的详细信息。此外,还包括文件存于 Solr subversion 存储库的何处的信息以及对该文件功能的一个简要描述。 |
| Distribution | http://localhost:8080/solr/admin/distributiondump.jsp | 显示与索引发布和复制有关的信息。更多信息,请参见 “发布和复制” 一节。 |
| Ping | http://localhost: 8080/solr/admin/ping | 向服务器发出 ping 请求,包括在 solrconfig.xml 文件的 admin 部分定义的请求。 |
| Logging | http:// localhost:8080/solr/admin/logging.jsp | 让您可以动态更改当前应用程序的日志记录等级。更改日志记录等级对于调试在执行过程中可能出现的问题非常有用。 |
| Java properties | http: //localhost:8080/solr/admin/get-properties.jsp | 显示当前系统正在使用的所有 Java 系统属性。Solr 支持通过命令行的系统属性替换。有关实现此特性的更多信息,请参见 solrconfig.xml 文件。 |
| Thread dump | http://localhost:8080/solr/admin/threaddump.jsp | thread dump 选项显示了在 JVM 中运行的所有线程的堆栈跟踪信息。 |
经常地,当创建搜索实现时,您都会输入一个应该匹配特定文档的搜索,但它不会出现在结果中。在大多数情况下,故障都是由如下两个因素之一引起的:
- 查询分析和文档分析不匹配(虽然不推荐,但对文档的分析可能会与对查询的分析不同)。
Analyzer正在修改不同于预期的一个或多个条目。
可以使用位于 http://localhost:8080/solr/admin/analysis.jsp 的 Solr 分析管理功能来深入调查这两个问题。Analysis 页可接受用于查询和文档的文本片段以及能确定文本该如何分析并返回正被修改的文本的逐步结果的 Field 名称。图 1 显示了分析句子 “The Carolina Hurricanes are the reigning Stanley Cup champions, at least for a few more weeks” 以及相关的查询 “Stanley Cup champions” 的部分结果,正如为示例应用程序 schema.xml 中指定的 content Field 分析的那样:
图 1. 对分析进行调试
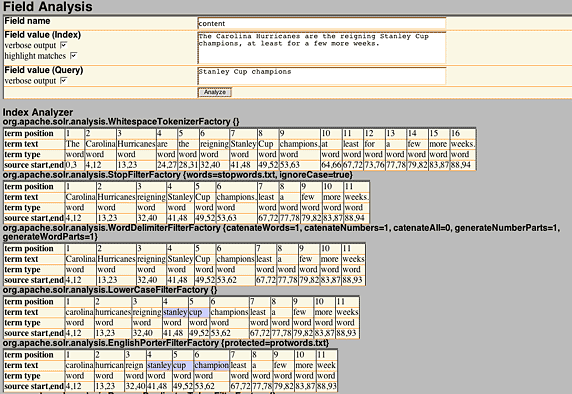
分析屏幕显示了每个条件在被上述表结果 Tokenizer 或 TokenFilter 处理后的结果。比如,StopFilterFactory 会删除字 The、are和 the。EnglishPorterFilterFactory 会将字 champions 提取为 champion,将 Hurricanes 提取为 hurrican。紫色的醒目显示表明在特定文档中查询条件在何处有匹配。
admin 页的 Make a Query 部分提供了可输入查询并查看结果的搜索框。这个输入框接受 第 1 部分 中讨论到的 Lucene 查询解析器语法,而 Full Interface 链接则提供了对更多搜索特性的控制,比如返回的结果的数量、在结果集中应该包括哪些字段以及如何格式化输出。此外,该界面还可用来解释文档的计分以更好地理解哪些条件得到了匹配以及这些条件是如何得分的。要实现这一目的,可以查看 Debug: enable 选项并滚动到搜索结果的底端来查看相关解释。
智能缓存是让 Solr 得以成为引人瞩目的搜索服务器的一个关键性能特征。例如,Solr 在提供缓存服务之前可通过使用旧缓存中的信息来自热缓存,以便在服务于现有用户的同时改进性能。Solr 提供了四种不同的缓存类型,所有四种类型都可在 solrconfig.xml 的<query> 部分中配置。表 3 根据在 solrconfig.xml 文件中所用的标记名列出了这些缓存类型:
表 3. Solr 缓存类型
| 缓存标记名 | 描述 | 能否自热? |
|---|---|---|
| filterCache | 通过存储一个匹配给定查询的文档 id 的无序集,过滤器让 Solr 能够有效提高查询的性能。缓存这些过滤器意味着对 Solr 的重复调用可以导致结果集的快速查找。更常见的场景是缓存一个过滤器,然后再发起后续的精炼查询,这种查询能使用过滤器来限制要搜索的文档数。 | 可以 |
| queryResultCache | 为查询、排序条件和所请求文档的数量缓存文档 id 的有序 集合。 | 可以 |
| documentCache | 缓存 Lucene Document,使用内部 Lucene 文档 id(以便不与 Solr 惟一 id 相混淆)。由于 Lucene 的内部Document id 可以因索引操作而更改,这种缓存不能自热。 |
不可以 |
| Named caches | 命名缓存是用户定义的缓存,可被 Solr 定制插件 所使用。 | 可以,如果实现了org.apache.solr.search.CacheRegenerator的话。 |
每个缓存声明都接受最多四个属性:
class是缓存实现的 Java 名。size是最大的条目数。initialSize是缓存的初始大小。autoWarmCount是取自旧缓存以预热新缓存的条目数。如果条目很多,就意味着缓存的 hit 会更多,只不过需要花更长的预热时间。
而对于所有缓存模式而言,在设置缓存参数时,都有必要在内存、CPU 和磁盘访问之间进行均衡。统计信息管理页 对于分析缓存的 hit-to-miss 比例以及微调缓存大小的统计数据都非常有用。而且,并非所有应用程序都会从缓存受益。实际上,一些应用程序反而会由于需要将某个永远也用不到的条目存储在缓存中这一额外步骤而受到影响。
对于收到大量查询的应用程序,单一一个 Solr 服务器恐怕不足以满足性能上的需求。因而,Solr 提供了跨多个服务器复制 Lucene 索引的机制,这些服务器必须是负载均衡的查询服务器的一部分。复制过程由 solrconfig.xml 文件启动的事件侦听程序和几个 shell 脚本(位于示例应用程序的 dw-solr/solr/bin)处理。
在复制架构中,一个 Solr 服务器充当主服务器,负责向一个或多个处理查询请求的从服务器提供索引的副本(称为 snapshot)。索引命令发送到主服务器,查询则发送到从服务器。主服务器可以手动创建快照,也可以通过配置 olrconfig.xml 的 <updateHandler> 部分(请参见清单 1)来触发接收到 commit 和/或 optimize 事件时的快照创建。无论是手动创建还是事件驱动的创建,都会在主服务器上调用 snapshooter 脚本,这会在名为 snapshot.yyyymmddHHMMSS(其中的 yyyymmddHHMMSS 代表实际创建快照的时间)的服务器上创建一个目录。之后,从服务器使用 rsync 来只复制 Lucene 索引中的那些已被更改的文件。
清单 1. 更新句柄侦听程序
<listener event="postCommit" class="solr.RunExecutableListener"> <str name="exe">snapshooter</str> <str name="dir">solr/bin</str> <bool name="wait">true</bool> <arr name="args"> <str>arg1</str> <str>arg2</str> </arr> <arr name="env"> <str>MYVAR=val1</str> </arr> </listener> |
清单 1 显示了在收到 commit 事件后,在主服务器上创建快照所需的配置。同样的配置也同样适用处理 optimize 事件。在这个示例配置中,在 commit 完成后,Solr 调用位于 solr/bin 目录的 snapshooter 脚本,传入指定的参数和环境变量。wait 实参告知 Solr 在继续之前先等待线程返回。有关执行 snapshooter 和其他配置脚本的详细信息,请参见 Solr 网站上的 “Solr Collection and Distribution Scripts” 文档(请参见 参考资料)。
在从服务器上,使用 snappuller shell 脚本从主服务器上检索快照。snappuller 从主服务器上检索了所需文件后,snapinstallershell 脚本就可用来安装此快照并告知 Solr 有一个新的快照可用。根据快照创建的频率,最好是安排系统定期执行这些步骤。在主服务器上,rsync 守护程序在从服务器获得快照之前必须先行启动。rsyn 守护程序可用 rsyncd-enable shell 脚本启用,然后再用rsyncd-start 命令实际启动。在从服务器上,snappuller-enable shell 脚本必须在调用 snappuller shell 脚本之前运行。
虽然,我们已经竭尽全力地对索引更新的发布进行了优化,但还是有几个常见的场景会为 Solr 带来问题:
- 优化大型索引可能会非常耗时,而且应该在索引更新不是很频繁的情况下才进行。 优化会导致多个 Lucene 索引文件合并成一个单一文件。这就意味者从服务器必须要复制整个索引。然而,这种方式的优化还是比在每个从服务器上进行优化要好很多。这些服务器可能与主服务器不同步,导致新副本再次被检索。
- 如果从主服务器中获取新快照的频率过高,则从服务器的性能可能会降低,这种降低源于使用
snappuller复制更改的开销以及在安装新索引时的缓存预热。有关频繁的索引更新方面的性能均衡的详细信息,请参见 参考资料 中的 “Solr Performance Factors”。
最终,向从服务器添加、提交和获取更改的频繁程度完全取决于您自己的业务需求和硬件能力。仔细测试不同的场景将会帮助您定义何时需要创建快照以及何时需要从主服务器中获取这些快照。有关设置和执行 Solr 发布和复制的更多信息,请参看 参考资料 中的 “Solr Collection and Distribution” 文档。
Solr 提供了几个插件点,您可以在这里添加定制功能来扩展或修改 Solr 处理。此外,由于 Solr 是开源的,所以如果需要不同的功能,您尽可以更改源代码。有两种方式可以向 Solr 添加插件:
- 打开 Solr WAR,在
WEB-INF/lib目录下添加新的库,重新打包这些文件,然后将 WAR 文件部署到 servlet 容器。 - 将 JAR 放入 Solr Home
lib目录,然后启动 servlet 容器。这种方法使用了定制ClassLoader且有可能不适用于某些 servlet 容器。
接下来的几个章节突出介绍了可能希望扩展 Solr 的几个领域。
若现有的功能不能满足业务需求,Solr 允许应用程序实现其自身的请求处理功能。比如,您可能想要支持您自己的查询语言或想要将 Solr 与您的用户配置文件相集成来提供个性化的效果。SolrRequestHandler 接口定义了实现定制请求处理所需的方法。实际上,除了第 1 部分 所使用的那些默认的 “标准” 请求处理程序之外,Solr 还定义了其他几个请求处理程序:
- 默认的
StandardRequestHandler使用 Lucene Query Parser 语法处理查询,添加了排序和层面浏览。 DisMaxRequestHandler被设计用来通过更为简单的语法来跨多个Field进行搜索。它也支持排序(使用与标准处理程序稍有不同的语法)和层面浏览。IndexInfoRequestHandler可以检索有关索引的信息,比如索引中的文档数或Field数。
请求处理程序是由请求中的 qt 参数指定的。Solr servlet 使用参数值来查找给定的请求处理程序并将输入用于请求处理程序的处理。请求处理程序的声明和命名通过 solrconfig.xml 中的 <requestHandler> 标记指定。要添加其他的内容,只需实现定制的SolrRequestHandler 线程安全的实例即可,将其添加到 上述 定义好的 Solr,并将其包括到 如前所述 的类路径中,之后就可以通过HTTP GET 或 POST 方法开始向其发送请求了。
与请求处理类似,也可以定制响应输出。必须要支持老式的搜索输出或必须要使用二进制或加密输出格式的应用程序可以通过实现QueryResponseWriter 来输出所需的格式。 然而,在添加您自己的 QueryResponseWriter 之前,需要先深入研究一下 Solr 所自带的实现,如表 4 所示:
表 4. Solr 的查询响应书写器
| 查询响应书写器 | 描述 |
|---|---|
| XMLResponseWriter | 这个最为常用的响应格式以 XML 格式输出结果,如 第 1 部分 的博客应用程序所示。 |
| XSLTResponseWriter | XSLTResponseWriter 将 XMLResponseWriter 的输出转换成指定的 XSLT 格式。请求中的 tr参数指定了要使用的 XSLT 转换的名称。指定的转换必须存在于 Solr Home 的 conf/xslt 目录。有关 XSLT Response Writer 的更多内容,请参见 参考资料。 |
| JSONResponseWriter | 用 JavaScript Object Notation (JSON) 格式输出结果。JSON 是一种简单、人类可读的数据转换格式,而且非常易于机器解析。 |
| RubyResponseWriter | RubyResponseWriter 是对 JSON 格式的扩展以便在 Ruby 中安全地使用结果。若有兴趣将 Ruby 和 Solr 结合使用,可以参考 参考资料 中给出的到 acts_as_solr 和 Flare 的链接。 |
| PythonResponseWriter | 对 JSON 输出格式的扩展以便在 Python eval 方法中安全地使用。 |
QueryResponseWriter 通过 <queryResponseWriter> 标记及其附属属性被添加至 Solr 的 solrconfig.xml 文件。响应的类型通过 wt 参数在请求中指定。默认值是 “标准”,即在 solrconfig.xml 中设定为 XMLResponseWriter。最后要强调的是,QueryResponseWriter 的实例必须提供用来创建响应的 write() 和 getContentType() 方法的线程安全的实现。
Analyzer、Tokenizer、TokenFilter 和 FieldType
借助新的 Analyzer、Tokenizer、TokenFilter 可以定制 Solr 的索引输出以提供新的分析功能。自身需要 Tokenizer 或 TokenFilter的应用程序必须实现其自身的 TokenizerFactory 和 TokenFilterFactory,这两者使用 <tokenizer> 或 <filter> 标记(作为<analyzer> 标记的一部分)在 schema.xml 中声明。如果您从之前的应用程序中已经获得了一个 Analyzer,那么就可以在<analyzer> 标记的 class 属性中声明它并进行使用。您无需创建新的 Analyzer,除非是想要在其他 Lucene 应用程序中使用这些分析器 —— 在 schema.xml 中使用 <analyzer> 标记声明 Analyzer 真是容易呀!
如果应用程序有特定的数据需求,您可能需要添加一个 FieldType 来处理数据。比如,可以添加一个 FieldType 来处理来自旧的应用程序的二进制字段,在 Solr 中应该可以搜索到这个应用程序。只需使用 <fieldtype> 声明将 FieldType 添加到 schema.xml 并确保它在类路径中可用。
虽然 Solr 可以开箱即用,但还是有几个技巧可有助于让它更易于使用。与任何应用程序一样,仔细考虑您对数据访问的具体业务需求任重而道远。比如,添加的已索引 Field 越多,对内存的需求就越多、索引就越大、优化该索引所需的时间也越长。同样的,检索已存储的 Field 会因为太多的 I/O 处理而减慢服务器的速度。使用懒散字段加载或在他处存储大型内容可以为搜索请求释放 CPU 资源。
在搜索层面上,您应该考虑所支持的查询类型。很多应用程序都不需要 Lucene Query Parser 语法的全部,尤其是使用通配符和其他高级查询类型的情况下就更是如此。若能分析日志和确保常用的查询被缓存,将会非常有帮助。为一般的查询使用 Filter 对于减少服务器的负载也非常有用。与任何应用程序一样,全面地测试应用程序可确保 Solr 能够满足您的性能需求。有关 Lucene(和 Solr)性能的更多信息,请参阅 参考资料 中给出的 ApacheCon Europe 的 “Advanced Lucene” 幻灯片演示。
构建于 Lucene 的速度和强大功能之上,Solr 本身就证明了它完全可以成为企业级的搜索解决方案。它吸引了大量活跃的社区使用者,这些使用者已经将它用到了各种大型的企业环境。Solr 也获得了开发人员的衷心支持,他们还一直在寻找提高它的途径。
在这个包含两部分的文章,您了解了 Solr,包括它开箱即用的索引和搜索功能以及用来配置其功能的 XML 模式。另外,您还浏览了让 Solr 得以成为企业架构的理想选择的配置和管理特性。最后,您还获悉了采用 Solr 时的性能考虑以及可用来扩展它的架构。有关 Solr 的更多信息,请参阅 参考资料 中的文档。
下载
| 描述 | 名字 | 大小 | 下载方法 |
|---|---|---|---|
| 示例 Solr 应用程序 | j-solr2.zip | 500KB | HTTP |
学习
- 您可以参阅本文在 developerWorks 全球站点上的 英文原文 。
- “使用 Apache Solr 实现更加灵巧的搜索,第 1 部分: 基本特性和 Solr 模式”(Grant Ingersoll,developerWorks,2007 年 5 月):将 Solr 细致的全文本搜索功能添加到您的 Web 应用程序。
- “Beef up Web search applications with Lucene”(Deng Peng Zhou,developerWorks,2006 年 8 月):了解关于 Lucene 搜索库的更多信息,该库用作 Solr 的基础库。
- “Parsing, indexing, and searching XML with Digester and Lucene”(Otis Gospodnetic,developerWorks,2003 年 6 月):Lucene 初探。
- Solr 主页:学习教程、浏览 Javadocs 并随时关注 Solr 社区。
- Solr Wiki:查看 Wiki 获取关于 Solr 运作的众多文档,包括:
- “Solr Performance Factors”
- “Solr Collection and Distribution Scripts”
- “Analyzers, Tokenizers, and Token Filters”(Analysis 调试)
- “The Solr XSLT Response Writer”
- Public Websites using Solr:使用 Solr 功能的 Web 站点的清单。
- acts_as_solr:一种 Rails 插件,支持 Ruby on Rails 全文本的功能;也可参考 Flare:一个使用基于 Rails 的用户界面来对 Solr 进行扩展的项目。
- “Advanced Lucene”(Grant Ingersoll,ApacheCon Europe,2007):了解更多有关 Solr 和 Lucene 的性能。
- Lucene QueryParser Syntax:进一步学习 Solr(和 Lucene)的查询解析器语法。
- JSON:一种简单、人类可读的数据转换格式,也很易于机器解析。
- Lucene In Action (Otis Gospodneti 和 Erik Hatcher;Manning,2004 年):对 Lucene 有兴趣的人的必读之作。
- developerWorks Java 技术专区:关于 Java 编程各个方面的数百篇文章。