基于MediaPipe实现智能人机交互(python实现)
目录
1系统简介
2 需求分析
3 基本原理
4 方案设计
5 详细设计
6 系统实现
7 测试及评估结果
4.1 手势识别——数字识别
4.2 手势识别——隔空画画
4.3 手势识别——远程鼠标控制
4.4 手势识别——音量控制
8 总结
9.实现代码如下:
1.FingerCounter.py
2.HandTrackingModule.py
3.其他相关代码私聊博主获取
1系统简介
本次课程设计主要包含三个部分:1.手势数字识别 2.隔空画画 3.手势音量控制
1.手势数字识别
通过对手的节点建模,识别笔画的手势所代表的数字。
2.隔空画画
通过手势选取画笔,并且将手当作画笔进行隔空画画。
3.手势音量控制
通过手势控制音量
4.手势控制鼠标运动和操作
通过手势控制鼠标移动。
2 需求分析
分析设计需求,包括功能和性能,实现什么目的,以及对软硬件平台的要求等。
人机交互指的是人与计算机之间使用的某种对话语言,以一定的交互方式,为完成确定任务的人与计算机之间的信息交换过程。随着计算机性能的发展,人机交互越来越频繁。在工程应用方面,计算机通过对手势的分析理解,可以进一步开发出相应的远程操控系统,在疫情当下,可以更好的实现零接触操作。同时通过手势也可以进一步了解人的表情与情感,例如在警匪影片中,通过手势的微小变化,对罪犯的阐述进行分析判断,但这只是更深层次的系统设想。在未来,随着虚拟现实、增强现实、物联网等技术的进一步发展,我们对虚拟现实技术的需求会日益增大。
人机交互是一门研究系统与用户之间的交互关系的学问。在工程应用中,最重要的也是最基本的需求是实时性,这保证了系统能对人体的行为做出及时的响应。这不仅可以提供良好的用户交互体验,更能防止信息的堆叠或者丢失。因此,在已有的功能基础上,实时性是最重要的性能要求。
为此,我们组采用轻量级的机器学习架构——MediaPipe。MediaPipe是一个用于构建机器学习管道的框架,用于处理视频、音频等时间序列数据。这个跨平台框架适用于桌面/服务器、Android、iOS和嵌入式设备,如Raspberry Pi和Jetson Nano。
在我们组工程实现中,我们借助NVIDIA-MAX350进行试验,虽然只是轻量级入门独立显卡,但依然取得了较好的效果——达到了实时性的要求。
3 基本原理
3.1手势识别手掌检测
目前现阶段手势识别的研究方向主要分为:基于穿戴设备的手势识别和基于视觉方法的手势识别。基于穿戴设备的手势识别主要是通过在手上佩戴含有大量传感器的手套获取大量的传感器数据,并对其数据进行分析。该种方法相对来虽然精度比较高,但是由于传感器成本较高很难在日常生活中得到实际应用,同时传感器手套会造成使用者的不便,影响进一步的情感分析,所以此方法更多的还是应用在一些特有的相对专业的仪器中。而本项目关注点放在基于视觉方法的手势研究中,在此特地以Mediapipe的框架为例,方便读者更好的复现和了解相关领域。
基于视觉方法的手势识别主要分为静态手势识别和动态手势识别两种。从文字了解上来说,动态手势识别肯定会难于静态手势识别,但静态手势是动态手势的一种特殊状态,我们可以通过对一帧一帧的静态手势识别来检测连续的动态视频,进一步分析前后帧的关系来完善手势系统。
MediaPipe在训练手掌模型中,使用的是单阶段目标检测算法SSD。同时利用三个操作对其进行了优化:1.NMS;2.encoder-decoder feature extractor;3.focal loss。NMS主要是用于抑制算法识别到了单个对象的多个重复框,得到置信度最高的检测框;encoder-decoder feature extractor主要用于更大的场景上下文感知,甚至是小对象(类似于retanet方法);focal loss是有RetinaNet上提取的,主要解决的是正负样本不平衡的问题,这对于开放环境下的目标检测是一个可以涨点的技巧。利用上述技术,MediaPie在手掌检测中达到了95.7%的平均精度。在没有使用2和3的情况下,得到的基线仅为86.22%。增长了9.48个点,说明模型是可以准确识别出手掌的。而至于为啥做手掌检测器而不是手部,主要是作者认为训练手部检测器比较复杂,可学习到的特征不明显,所以做的是手掌检测器。
MediaPipe通过对整个图像进行手掌检测后,使用手部关键点模型通过回归对被检测手部区域内的21个三维手部关节坐标进行精确的关键点定位,即直接进行坐标预测。标记点如图所示:

4 方案设计
本方案最终采用经典的VGG16实现SSD手掌检测算法,主要是因为其网络结构在计算机视觉上足够经典,且已经验证效果足够优秀。SSD的网络框图如下:
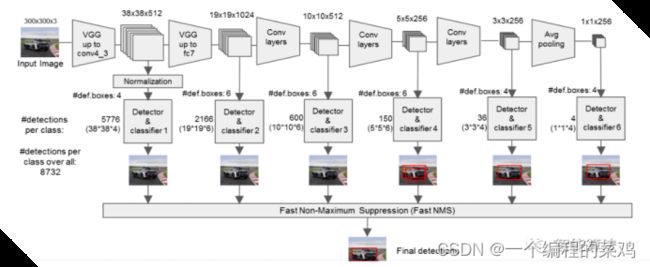
实现方法:

5 详细设计
通过对算法的可行性和准确度的综合考虑,我们计划通过opencv+mediapipe识别手掌关键点,然后通过关键点的一些位置值和相互关系实现特定应用。具体框图如下:

其中,MediaPipe的具体框架如下:
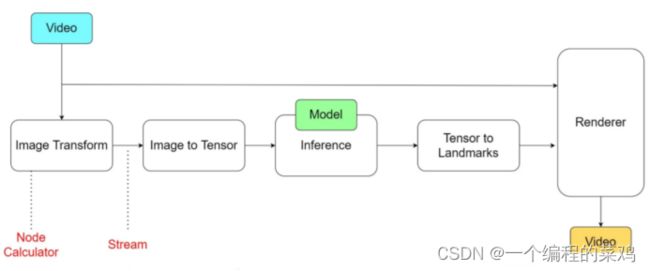
在计算机科学术语中,图由边连接的节点组成。在MediaPipe Graph内部,节点称为Calculators,边缘称为Streams。每个流都携带一个时间戳递增的数据包序列
在上图中,我们用矩形块表示Calculators,用箭头表示Streams。图像传入后,经过图像处理模块,转化成计算机容易处理的张量(Tensor),再经过我们的模型处理,处理后通过输出模块再转化为视频流,最终可以得到我们的预期结果。
数字识别模块:在数字识别模块中,我们通过mediapipe返回的关键点位置,计算每个手指之间的角度和手指距离掌心的距离,通过不同角度和距离的组合判断手比的是数字几。
比如当每个手指之间角度大于5度且长度都较长时为5,当角度相同但大拇指长度短的时候判断为4.
画画模块:在画画模块中,需要分为两个模式。一个是选画笔模式,一个是画画模式。当我们用一个手指时表示画画模式,两个手指表示选画笔模式。
音量控制模块:首先通过mediapipe返回的关键点信息识别出食指和拇指位置,通过关键点之间的距离控制音量。
远程鼠标模块:通过mediapipe实现对关键点的识别,然后利用食指控制鼠标移动,或者加入点击之类的操作。
6 系统实现
包括开发环境等描述,以及代码结构、调用关系、代码源文件与各模块的对应关系等。
开发环境:
Win10+Python3.7
代码结构以及调用关系如下:
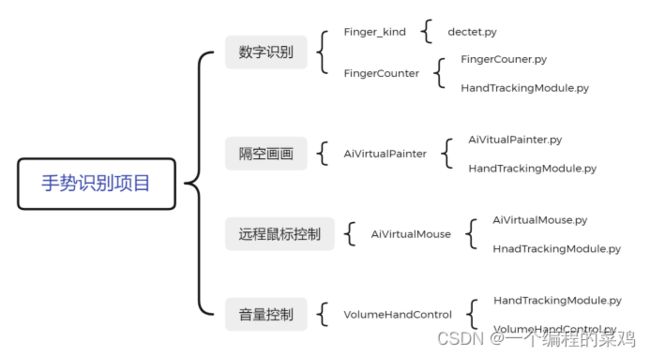
7 测试及评估结果
4.1 手势识别——数字识别
| 测试结果如下:
结果评测: 在展示视频(1),用户通过展示10种不同的数字手势(0到9)以及多种不同含义的手势(比如GOOD)等等,计算机都可以轻松快速地识别出来并给出响应。由此来看,实验效果符合我们的预期。 |

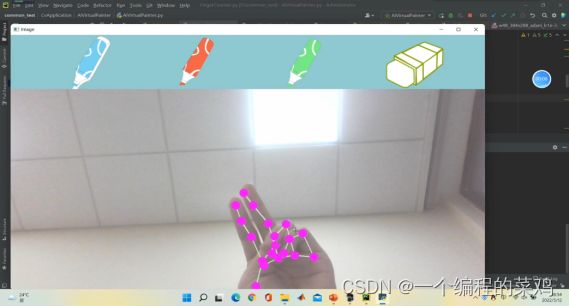
4.2 手势识别——隔空画画
| 测试结果如下:
结果评估: 在展示视频(2)中,画笔能够准确地跟踪到食指的位置,并可以完成实时的画画功能。此外,我们还提供了画笔的选择功能(包括不同颜色的画笔和橡皮擦),这个过程同样可以通过手指隔空点击来实现。由此,我们完成了该部分的全部功能,实现效果较好。 |
4.3 手势识别——远程鼠标控制
| 测试结果如下:
结果评估: 在展示视频(3)中,鼠标能够紧跟视频中食指位置的变化而变化,处理的帧率也相对较高,可以达到实时跟踪的效果。由此来看,鼠标远程跟踪效果符合预期,表现较好。 |
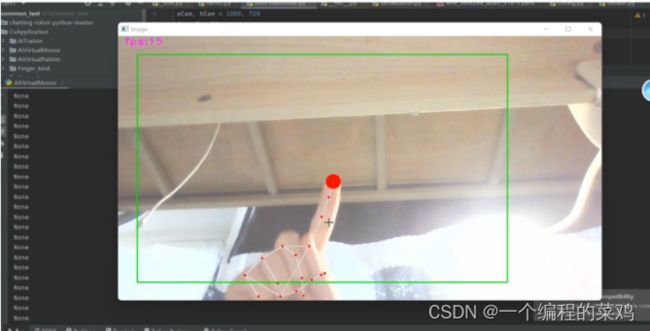
4.4 手势识别——音量控制
| 测试结果如下:
结果评估: 在展示视频(4)中,计算机可以捕捉用户的收拾并计算出用户的大拇指与食指之间的距离,以此来衡量音量大小进而对音量进行控制。通过演示视频,我们可以看到实验效果良好,符合我们的预期。 |
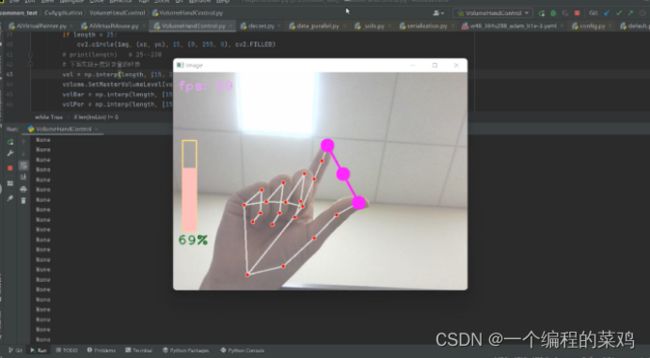
8 总结
对本课设遇到的困难、收获和进一步展望等进行总结;
在本次实验中,我们遇到的困难主要有环境搭建、硬件限制等。
在环境搭建方面,我们最初打算使用Github开源项目“Wukong”,但由于其环境搭建困难,包括插件的安装、路径添加、API接口调用、各版本库函数难以兼容等困难难以处理,我们最终使用MediaPipe手势识别的项目,在解决了各种环境搭建的问题之后,我们完成了本项目。
在硬件限制方面,虽然可以完成实时性的要求,但帧率方面依然难以令人满意,我们通过改进代码架构,优化代码内容,更换硬件条件等等措施,最终增了处理帧率,提高了视频的流畅程度。
进一步展望:我们希望可以进一步完善现有代码,并采用其他的代码架构,取得效果之后与当前MediaPipe进行横向分析对比进而方便我们在实际应用中进行对比分析。
9.实现代码如下:
1.FingerCounter.py
import cv2
import HandTrackingModule as htm
import time
#############################
wCam, hCam = 640, 480
#############################
cap =cv2.VideoCapture(0,cv2.CAP_DSHOW) # 若使用笔记本自带摄像头则编号为0 若使用外接摄像头 则更改为1或其他编号
cap.set(3, wCam)
cap.set(4, hCam)
pTime = 0
detector = htm.handDetector()
while True:
success, img = cap.read()
img = detector.findHands(img)
lmList = detector.findPosition(img, draw=False)
pointList = [4, 8, 12, 16, 20]
if len(lmList) != 0:
countList = []
# 大拇指
if lmList[4][1] > lmList[3][1]:
countList.append(1)
else:
countList.append(0)
# 余下四个手指
for i in range(1, 5):
if lmList[pointList[i]][2] < lmList[pointList[i] - 2][2]:
countList.append(1)
else:
countList.append(0)
# print(countList)
count = countList.count(1) # 对列表中含有的1计数
#HandImage = cv2.imread(f'FingerImg/{count}.jpg')
#HandImage = cv2.resize(HandImage, (150, 200))
#h, w, c = HandImage.shape
#img[0:h, 0:w] = HandImage
cv2.putText(img, f'{int(count)}', (15, 400), cv2.FONT_HERSHEY_PLAIN, 15, (255, 0, 255), 10)
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, f'fps: {int(fps)}', (500, 40), cv2.FONT_HERSHEY_PLAIN, 2, (255, 0, 0), 2)
cv2.imshow("Image", img)
cv2.waitKey(1)2.HandTrackingModule.py
import cv2
import mediapipe as mp
import time
import math
class handDetector():
def __init__(self, mode=False, maxHands=2, model_complexity=1,detectionCon=0.8, trackCon=0.8):
self.mode = mode
self.maxHands = maxHands
self.detectionCon = detectionCon
self.trackCon = trackCon
self.model_complexity = model_complexity
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxHands,self.model_complexity, self.detectionCon, self.trackCon)
self.mpDraw = mp.solutions.drawing_utils
self.tipIds = [4, 8, 12, 16, 20]
def findHands(self, img, draw=True):
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.results = self.hands.process(imgRGB)
print(self.results.multi_handedness) # 获取检测结果中的左右手标签并打印
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms, self.mpHands.HAND_CONNECTIONS)
return img
def findPosition(self, img, draw=True):
self.lmList = []
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
for id, lm in enumerate(handLms.landmark):
h, w, c = img.shape
cx, cy = int(lm.x * w), int(lm.y * h)
# print(id, cx, cy)
self.lmList.append([id, cx, cy])
if draw:
cv2.circle(img, (cx, cy), 12, (255, 0, 255), cv2.FILLED)
return self.lmList
def fingersUp(self):
fingers = []
# 大拇指
if self.lmList[self.tipIds[0]][1] > self.lmList[self.tipIds[0] - 1][1]:
fingers.append(1)
else:
fingers.append(0)
# 其余手指
for id in range(1, 5):
if self.lmList[self.tipIds[id]][2] < self.lmList[self.tipIds[id] - 2][2]:
fingers.append(1)
else:
fingers.append(0)
# totalFingers = fingers.count(1)
return fingers
def findDistance(self, p1, p2, img, draw=True, r=15, t=3):
x1, y1 = self.lmList[p1][1:]
x2, y2 = self.lmList[p2][1:]
cx, cy = (x1 + x2) // 2, (y1 + y2) // 2
if draw:
cv2.line(img, (x1, y1), (x2, y2), (255, 0, 255), t)
cv2.circle(img, (x1, y1), r, (255, 0, 255), cv2.FILLED)
cv2.circle(img, (x2, y2), r, (255, 0, 255), cv2.FILLED)
cv2.circle(img, (cx, cy), r, (0, 0, 255), cv2.FILLED)
length = math.hypot(x2 - x1, y2 - y1)
return length, img, [x1, y1, x2, y2, cx, cy]
def main():
pTime = 0
cTime = 0
cap = cv2.VideoCapture(0)
detector = handDetector()
while True:
success, img = cap.read()
img = detector.findHands(img) # 检测手势并画上骨架信息
lmList = detector.findPosition(img) # 获取得到坐标点的列表
if len(lmList) != 0:
print(lmList[4])
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, 'fps:' + str(int(fps)), (10, 70), cv2.FONT_HERSHEY_PLAIN, 3, (255, 0, 255), 3)
cv2.imshow('Image', img)
cv2.waitKey(1)
if __name__ == "__main__":
main()