姿态估计 从原理到实践
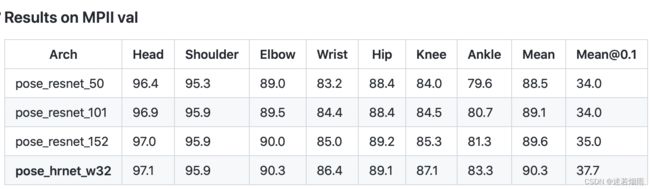
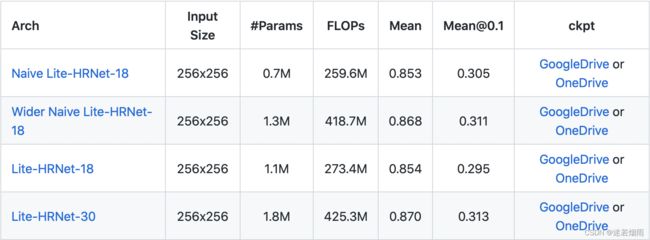 Results on MPII val set
Results on MPII val set
从上面几个表中不难总结出以下结论
- 大模型在MPII上PCK为90左右,在COCO上AP为75左右
- 小模型在MPII上PCK为85左右,在COCO上AP为67左右
基于OpenCV的深度学习人体姿态估计之单人篇:Deep Learning based Human Pose Estimation using OpenCV
基于OpenCV使用OpenPose进行多个人体姿态估计
CVPR 2022 | Lite Pose:用于 2D 人体姿态估计的高效架构设计 - 知乎
HRNet 的高分辨率分支对于低计算区域的模型是多余的,删除它们可以提高效率和性能
只有 25% 的计算增量,7x7 kernel在 CrowdPose 数据集上比 3x3 kernel实现 +14.0 mAP。在移动平台上,与之前最先进的高效姿态估计模型相比,LitePose 在不牺牲性能的情况下将延迟降低了高达 5.0 倍,推动了边缘实时多人姿态估计的SOTA


多人姿态估计三部曲
1.AlphaPose: Reginal Multi-Person Pose Estimation
主要解决检测框质量不高,影响SPPE性能和重复框检测造成重复姿态检测问题
2.CrowdPose
解决密集人群的姿态估计问题
3.PoseFlow
设计了一种在线优化框架来建立跨帧之间的pose的联系解决连续姿态估计问题
使用深度学习和OpenCV进行手部关键点检测:Hand Keypoint Detection using Deep Learning and OpenCV
Deep Learning-Based Human Pose Estimation: A Survey
人体姿态估计的过去,现在,未来
Heatmap的方式被广泛使用在人体骨架的问题里面,这个跟人脸landmark有明显的差异,一般人脸landmark会直接使用回归(fully connected layer for regression)出landmark的坐标位置。首先人脸landmark的问题往往相对比较简单,对速度很敏感,所以直接回归相比heatmap来讲速度会更快,另外直接回归往往可以得到sub-pixel的精度,但是heatmap的坐标进度取决于在spatial图片上面的argmax操作,所以精度往往是pixel级别(同时会受下采样的影响)。 但是heatmap的好处在于空间位置信息的保存,这个非常重要。一方面,这个可以保留multi-modal的信息,比如没有很好的context信息的情况下,是很难区分左右手的,所以图片中左右手同时都可能有比较好的响应,这种heatmap的形式便于后续的cascade的进行refinement优化。另外一个方面,人体姿态估计这个问题本身的自由度很大,直接regression的方式对自由度小的问题比如人脸landmark是比较适合的,但是对于自由度大的姿态估计问题整体的建模能力会比较弱。相反,heatmap是比较中间状态的表示,所以信息的保存会更丰富。后续2D的人体姿态估计方法几乎都是围绕heatmap这种形式来做的(3D姿态估计将会是另外一条路),通过使用神经网络来获得更好的feature representation,同时把关键点的空间位置关系隐式的encode在heatmap中进行学
RLE重铸回归方法的荣光后,回归和热图的异同究竟在何方?
零基础看懂RLE(Residual Log-likelihood Estimation)|姿态估计ICCV 2021 Oral
2D姿态估计整理:从DeepPose到HRNet
Part Affinity Fields论文理解
传统的自顶向下的姿态估计算法都是采用先定位到人,再做单人关键点检测。这种方法的缺点在于:图像中人的数量、位置、尺度大小都是未知的,人与人之间的交互遮挡可能会影响检测效果,最最重要的是,运行时间复杂度随着图像中个体数量的增加而增长,无法实时检测. PAF的基本原理是在两个相邻关键点之间,建立一个有向场,比如左手腕,左手肘。我们把CPM找到的所有的左手腕以及左手肘拿出来建立一个二分图,边权就是基于PAF的场来计算的。然后进行匹配,匹配成功就认为是同一个人的关节。依次类别,对所有相邻点做此匹配操作,最后就得到每个人的所有关键点

2D关键点检测之CPM:Convolutional Pose Machines
CPM就是将PM中的特征提取和上下文信息提取用CNN来实现了,以heatmap的形式表示预测结果(能够保留空间信息),在全卷积的结构下使用中间监督进行端到端的训练和测试,极大提高了关键点检测的准确率。
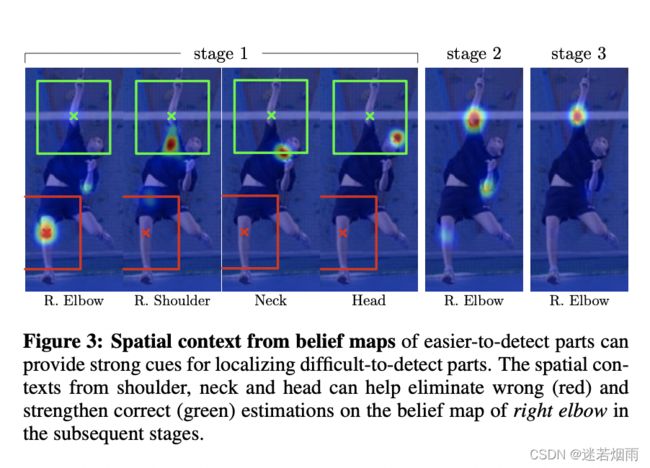
Wing Loss:
目前主流的热图损失函数都是均方误差(MSE),在本文中则根据Wing Loss的启发,提出了一种新的针对热图的损失函数----Adaptive Wing Loss。为了解决前景像素和背景像素之间的不平衡问题,还提出了Weighted Loss Map
wing loss是人脸关键点回归方式的loss,预测值的范围为0-1。wing loss在error特别大时,梯度为常数,当error比较小时,梯度比L1和MSE都要大。因此在小的error时能够放大,从而得到更好的结果。
但是Wing Loss无法克服在0处梯度不连续的问题,导致相较于L1 Loss,更难收敛。这个属性导致Wing loss不适合应用在heatmap regression方法上。因为热图有很多error极小的背景像素,不成比例。实验显示,在热图上使用Wing Loss从来没有正常收敛过
Fine Grained Head Pose Estimation Without Keypoint
姿态估计算法,主要用以估计输入目标的三维欧拉角,其大致可分为两类:一类是通过2D标定信息来估计3D姿态信息的算法,如先计算人脸的关键点,然后选取一个参考系(平均正脸的关键点),计算关键点和参考系的变换矩阵,然后通过迭代优化的算法来估计人脸的姿态(可参考opencv中的SolvePnP算法), 另一类就是通过数据驱动的方式训练一个回归器,由该回归器对输入人脸的块进行一个直接的预测。两类方法各有利弊,第一类算法为landmark-based,第二类为landmark-free
deep-high-resolution-net.pytorch: 论文阅读 代码理解
一文读懂HRNet

Numerical Coordinate Regression
Numerical Coordinate Regression with Convolutional Neural Networks
integral-human-pose 论文解读
awesome-hand-pose-estimation
openpose OpenPose:实时多人2D姿态估计、训练自己的数据集模型、训练过程解析
Convolutional Pose Machine
Cascaded Pyramid Network for Multi-Person Pose Estimation
Stacked Hourglass Networks for Human Pose Estimation
基于热图方法的两大缺点
- “取最大值taking-maximum”操作是不可微分的non-differentiable,并且阻止了端到端的训练。 只能对热图进行监督。
- 低分辨率热图,网络中下采样环节会造成量化误差 quantization errors,热图分辨率比输入分辨率低的多。 提高分辨率,虽然会提升精度,但是会造成计算和存储的高要求
基于回归关键点(regression methods)的两大优点
- 端到端学习,推断和训练的目的一致。
- 输出是连续,理论上可以达到任意的定位精准度。(与heatmap中的量化误差相反)
数据集
- LSP:2k人,14points,全身,单人
- FLIC:2w,9points,全身,单人
- MPII Human Pose Dataset:25k images,40k pose,16points,~12GB.全身,单人/多人
- MSCOCO:30W+,18points,全身,多人,keypoints on 10W people
一共17个骨骼关节标注点,相关标注顺序以及关节名的对应可参考下表:
| 序号 | 数据集标注顺序 | 关节名 | 中文名 |
|---|---|---|---|
| 0 | 0 | nose | 鼻子 |
| 1 | 1 | L eye | 左眼 |
| 2 | 2 | R eye | 右眼 |
| 3 | 3 | L ear | 左耳 |
| 4 | 4 | R ear | 右耳 |
| 5 | 5 | L shoulder | 左肩 |
| 6 | 6 | R shoulder | 右肩 |
| 7 | 7 | L elbow | 左手肘 |
| 8 | 8 | R elbow | 右手肘 |
| 9 | 9 | L wrist | 左手腕 |
| 10 | 10 | R wrist | 右手腕 |
| 11 | 11 | L hip | 左臀部 |
| 12 | 12 | R hip | 右臀部 |
| 13 | 13 | L knee | 左膝盖 |
| 14 | 14 | R knee | 右膝盖 |
| 15 | 15 | L ankle | 左脚踝 |
| 16 | 16 | R ankle | 右脚踝 |
 COCO点位图
COCO点位图
5.AI Challenge: 网盘下载(密码: 9t16) 21W Training, 3W Validation, 3W Testing,14points,全身,多人,38W people

2D人体姿态识别-对Human3.6M数据集预处理
2D人体姿态识别-Human3.6M与COCO数据集中,各人体骨骼关键点可视化及对应关节标注顺序(heatmap可视化,热力图和原图融合显示)
 Human3.6M和COCO两个数据集中共同的身体部位及其关键点
Human3.6M和COCO两个数据集中共同的身体部位及其关键点  COCO数据集中19个人体关键点可视化及含义
COCO数据集中19个人体关键点可视化及含义
人体姿态估计-评价指标
3D 人体姿态估计简述
评估指标
关键点估计之 PCK, PCKh, PDJ 评价度量
PCK
- 计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值的比例。
- FLIC 中是以躯干直径(torso size) 作为归一化参考.
- MPII 中是以头部长度(head length) 作为归一化参考,即PCKh.
OKS
- 关键点相似度,在人体关键点评价任务中,对于网络得到的关键点好坏,并不是仅仅通过简单的欧氏距离来计算的,而是有一定的尺度加入,来计算两点之间的相似度
AP
- 计算出groundtruth与检测得到的关键点的相似度oks为一个标量,然后人为的给定一个阈值T,然后可以通过所有图片的oks计算AP
移动端
- MobilePose
- pose_demo_android tiny_pose
- 视频多目标跟踪高级
- people-counting-pose
mediapipe: 谷歌出品,速度极快,跨平台,适合快速上手实验,但效果差强人意,还需要很多的优化. 安装方法 pip install mediapipe
-
import cv2 import mediapipe as mp mp_drawing = mp.solutions.drawing_utils mp_pose = mp.solutions.pose pose = mp_pose.Pose( min_detection_confidence=0.5, min_tracking_confidence=0.5) cap = cv2.VideoCapture(0) while cap.isOpened(): success, image = cap.read() if not success: break # Flip the image horizontally for a later selfie-view display, and convert # the BGR image to RGB. image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB) # To improve performance, optionally mark the image as not writeable to # pass by reference. image.flags.writeable = False results = pose.process(image) # Draw the pose annotation on the image. image.flags.writeable = True image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) mp_drawing.draw_landmarks( image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS) cv2.imshow('MediaPipe Pose', image) if cv2.waitKey(5) & 0xFF == 27: break pose.close() cap.release()C++版:
export EXAMPLE=hand_tracking # export EXAMPLE=object_detection # export EXAMPLE=hair_segmentation # export EXAMPLE=face_mesh # export EXAMPLE=upper_body_pose_tracking # export EXAMPLE=iris_tracking # export EXAMPLE=hair_segmentation bazel build -c opt --define MEDIAPIPE_DISABLE_GPU=1 mediapipe/examples/desktop/${EXAMPLE}:${EXAMPLE}_cpu GLOG_logtostderr=1 bazel-bin/mediapipe/examples/desktop/${EXAMPLE}/${EXAMPLE}_cpu --calculator_graph_config_file=mediapipe/graphs/${EXAMPLE}/${EXAMPLE}_desktop_live.pbtxt