这个疯子整理的十万字Java面试题汇总,终于拿下40W offer!(JDK源码+微服务合集+并发编程+性能优化合集+
爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
收藏党可以通过百度网盘下载全部文档:
链接:https://pan.baidu.com/s/1nwlBO2tYXDDl7OjGhs4e4Q
提取码:1111
目录
爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
Java JDK源码合辑
HashMap篇
ConcurrentHashMap篇
常用主流框架面试合辑
Spring框架篇
SpringMVC原理篇
MyBatis框架篇
Netty篇
微服务面试合辑
Spring Boot篇
Dubbo篇
Spring Cloud篇
并发编程面试篇合辑
并发编程(上)
并发编程(下)
分布式中间件面试合辑
分布式调用RPC篇
分布式限流Zookeeper篇
分布式负载均衡Nginx篇
分布式消息通讯RabbitMQ篇
分布式消息通讯Kafka篇
分布式消息通讯ActiveMQ篇
分布式数据库Reids篇
分布式数据库MongoDB篇
分布式数据库Memcached
性能调优合集
JVM性能优化面试篇
Tomcat调优面试篇
MySQL调优面试篇
word文档下载地址:链接:https://pan.baidu.com/s/1BaUi8KUjvjJ6RPN7CmMSyw?
提取码:1111爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
HashMap篇
1、并发修改异常
原因
迭代器中修改数 和hashmap中的 modCount 不相等
目的
暴露异常,快速失败
出现场景
- 多线程,一个迭代器迭代,一个线程增删操作
- 迭代器迭代的时候,使用hashmap本身的remove方法
解决方案
- 多个线程,操作使用ConcurrentHashMap,或者hashTable
- 在迭代的时候,使用迭代器中的remove方法。保存修改数和modCount一致
2、HashMap底层数据结构
1.7:数组+链表
1.8:数组+链表+红黑树(其中红黑树,也是用了双向链表,主要是为了链表操作方便,在扩容,链表转红黑树,红黑树转链表的过程中都要操作链表。)
3、hash 数组的最大值
1 << 30
- 首先必须是2的倍数,方便计算对应的table下标,
- 为什么不是32位 高1位 为正负标识,不能占有。
- 为什么不是31位 他达不到231,因为Integer的最大值就是231-1,如果threadhold超过2^30,会把Integer的最大值赋给他。
4、hash 寻址算法
hash值 和 数组长度 -1 做与运算。
- 数组长度为2的幂次方
- 长度-1,那么低位全部为1,做运算那么下标 肯定落到数组长度范围内。
5、1.7 HashMap的put方法的实现过程
- 判断当前的数组是否为空,如果为空则初始化该数组
- 判断key是否为null
- 遍历tab[0],如果有key为null的entry,重新设置新值,返回oldValue。
- 没有找到则将key,value封装成entry,存到数组下标0的位置。返回null。
- 根据key做hash运算得到hashcode
- 根据hashCode和数组长度-1,逻辑与运算,算出hashcode基于当前数组对应的数组下标i
- 遍历tab[i]位置的链表,当找到节点的key和传入的key相同时,则重新设置为新值,返回oldValue。
- 没有找到这,说明是新的key,modCount++
- 再将hashcode,key,value,i 封装成Entry对象,通过头插法插入到改tab[i]位置
- 如果当前size是否大于等于阈值**,并且当前桶位不为null** 则进行扩容。
6、HashMap1.7 扩容机制
扩容条件:
当前容量大于等于阈值 并且 当前桶位不为null
扩容流程
- rehash,当容量大于等于我们设置的hash阈值,生成一个新的hash种子
- new 一个2倍长度的新数组
- 循环每个桶上的链表
- 重新计算hashcode,然后再和新的数组长度-1做与运算,得到新数组下标
- 判断新数组当tab[i]位置是否有元素
- 没有元素则直接封装成Entry对象赋值到当前tab[i]位置
- 有元素,则通过头插法插入到链表中,再赋值到tab[i]位置
8、HashMap1.7 扩容产生循环链表
场景
- 两个(多)线程同时转移同一个桶对应的链表
- 线程1依次将链表倒序方式转移到新数组中,
- 线程2此时转移比如当前指针指向 1节点,下个指针指向2节点。 而链表中2的next节点指向的是1节点。
- 当插入的时候会1节点会指向2节点,2节点指向1节点,形成环形链表。
影响
- put时候,会造成死循环。(需要循环判断链表中是否有相同的key)
- get时候,会造成死循环。
9、1.8 hash运算的实现方式
将hashcode 高16 和 低16位 异或,算出hash值。
然后再和 数组的长度 -1 比较。
要 高16和低16异或?
目的是当数组的的长度为 2的 小于等于 16次方,也是就是2进制 小于等于 16位,。两个key的hashcode运算出的低16位一样,而高16位不一样,如果高16低16位不做运算,那么他们做与运算等到的是通过样的数组下标。对每个hash值,在他的低16位中,让高低16位进行了异或,让他的低16位同时保持了高低16位的特征,尽量避免一些hash值后续出现冲突,大家可能会进入数组的同一个位置, key 更加散列。
10、1.8 HashMap的put方法的实现过程
- 根据key生成hash 值
- 判断当前hashMap对象的数组是否为空,如果为空则初始化该数组
- 根据逻辑与运算,算出hashcode基于当前数组对应的数组下标i
- 判断数组的第i个位置的元素(tab[i])是否为空
- 如果为空,则将key,value封装成Node对象赋值给tab[i]
- 如果不为空
- 如果put方法传入进来的key等于tab[i].key,那么证明存在相同的key
- 如果不等于tab[i].key,则:
- 如果tab[i]的类型是TreeNode,则表示数组的第i位置上是一颗红黑树,那么将key和value插入到红黑树中,并且在插入之前会判断在红黑树中是否存在相同的key
- 如果tab[i]的类型不是TreeNode,则表示数组的第i位子上是一个链表,那么遍历循环找是否存在相同的key,并且在遍历的过程中会对链表中的节点数进行计数,当遍历到最后一个节点时,会将key,value封装成Node插入到链表的尾部,同时判断在插入新节点之前的链表节点个数是不是大于等于8,并且table长度大于等64,如果是,则将链表改为红黑树
- 如果上述步骤中发现存在相同的key,则根据onlyIfAbsent标记来判断是否需要更新value值,然后返回oldValue
- modCount++
- hashMap的元素个数size加1
- 如果size大于扩容的阈值,则进行扩容
11、1.8 HashMap 扩容机制
扩容条件:
- 当前容量大于等于阈值
- 或 在树化之前,当前数组的长度小于64,链表长度大于等于8 也会发生扩容。
扩容流程:
- new 2倍数组长度的,新数组
- 节点对应的hashcode和新数组长度做与运算
- 结果为0,为低位链表,不为0为高位链表
- 低位插入新数组老下标位置(i),高位插入新数组的老数组长度+老下标位置。(oldLength+i)
- 判断是否进行树化。
12、1.8 HashMap 树化过程
树化条件:
链表的长度大于等于8 且 数组的长度大于等于64
树化实现:
- 现将单向链表转变为双向链表
- 再将双向链表,将头结点作为root节点,然后依次将next节点插入到根节点,转变红黑树。
- 再插入时候key比较
- 如果key实现了comparable接口,通过实现方式比较
- 否则比较key的hashCode
- 否则比较key的class.getName
- 否则比较key的System.identityHashCode比较
- 最后树化后,取出root节点(TreeNode),放到entry位置
13、1.8 HashMap 的get实现过程
- 根据key生成hashcode
- 如果数组为空,则直接返回空
- 如果数组不为空,则利用hashcode和数组长度-1通过逻辑与操作算出key所对应的数组下标i
- 如果数组的第i个位置上没有元素,则直接返回空
- 如果数组的第i个位置的元素的key等于get方法锁传进来的key,则返回该元素,并获取该元素的value。
- 如果不等于则判断该元素还有没有下个元素,如果没有返回空
- 如果有则判断钙元素的类型是链表节点还是红黑树节点
- 如果是链表则遍历链表
- 如果是红黑树则遍历红黑树
- 找到即返回元素,没找到则返回空
14、1.8 HashMap 的Remove实现过程
- 找到对应的位置(和get方式类似)
- 链表节点直接删除
- 红黑树节点
- 先删除链表的对应的节点,实现方式将上个节点指向下下个节点
- 然后再维护红黑树上的节点,可能会发生退化成链表
- modCount–
- size–
15、1.8 HashMap 为什么使用红黑树,不使用AVL树,二分查找树,链表
- 因为AVL树插入节点或者删除节点,整体的性能是不如红黑树的。AVL每个左右节点的高度是不能大于1的。所以维持这种结构比较消耗性能。
- 二分查找树,他的左右节点不平衡,一开始就固定了root,那么极端的情况下会成为链表结构。
- 链表长度越长,那么他的插入和查询效率都很低。
- 而红黑树他的整体查找,增删节点的效率都是比较高的。
16、1.8 HashMap 什么时候将链表转化成红黑树
- 当发现链表的元素个数大于8
- 并且当前的数组长度大于等于64的时候。
因为当数组比较小的时候,我们可以通过扩容的方式,将链表的长度变短。这样就用树化。
17、1.7 和 1.8 HashMap 不同点
- 结构:1.8使用了红黑树
- 插入法:1.7使用了头插法(多线程情况会出现循环链表,导致CPU飙升),1.8是用来尾插法(1.8中反正要去计算链表当前节点的个数,需要遍历链表,所以直接使用了尾插法。)
- hash算法复杂度:1.7 的hash算法比1.8钟的更复杂,hash算法越复杂,生成hashcode则更散列,那么hashmap中的元素则更散列,更散列则hashmap的查询性能更好,jdk7中没有红黑树,所以只能优化hash算法使元素更散列。1.8中重甲了红黑树,查询性能得到了保障,所以可以简化一下hash算法,毕竟hash算法越复杂越消耗CPU。
- 扩容的过程中:1.7可能会重新对key进行哈希(重新hash跟哈希种子有关系。),而1.8中没有这部分逻辑
- 扩容的条件不一样:1.7除了判断是否大于等于阈值,同时还判断了tab[i]是否为空,不为空才会进行扩容。1.8则没有这部分逻辑。
- 扩容的转移逻辑不一样:jdk7是每次转移一个元素,jdk8是先算出当前位置,高低位链表,再一次性转移过去
- jdk8 多了一个api :putIfAbsent(key,value)。
ConcurrentHashMap篇
1、JDK7 ConcurrentHashMap是怎么保证并发安全的?
主要利用了Unsafe操作+ReentrantLock+分段思想。
主要使用了Unsafe操作中的:
- compareAndSwapObject:通过cas的方式修改对象的属性
- putOrderedObeject:并发安全的给数组的某个位置赋值
- getObjectVolatile:并发安全的获取数组某个位置的元素
分段思想:
为了提高ConcurrentHashMap的并发量,分段数越高则支持的最大并发量越高,程序员可以通过concurrencyLevel参数来指定并发量。ConcurrentHashMap的内部类Segment就是用来表示某一个段的。
ReentrantLock:
每个Segement就是一个小型的 HashMap,当调用ConcurrentHashMap的put方法时,最终会调用到Segment的put方法,而Segment类继承了ReentrantLock,所以Segment自带可重入锁,当调用到Segment的put方法时,会先利用可重入锁加锁,加锁成功后再将待插入的key,value插入到小型HashMap中,插入完成后解锁。
2、JDK7 ConcurrentHashMap的底层原理
ConcurrentHashMap底层是由两层嵌套数组来实现的
- ConcurrentHashMap对象中有一个属性segments,类型为segment[];
- Segment对象中有一个属性table,类型为hashEntry[];
当调用ConcurrentHashMap的put方法时,先根据key计算出对应的Segment[]数组下标j,确定好当前key,value应该插入到哪个segment对象中,如果segments[j] 为空,则利用自旋锁的方式在j位置生成一个Segment对象。
然后调用Segment对象的put方法。
Segment对象的put方法会先加锁,然后也根据key计算出对应的HashEntry[]数组下标i,然后将key,value封装为Entry对象放入该位置,此过程和1,.7的put方法一样,然后解锁。
3、JDK7 ConcurrentHashMap的put实现过程
- 判断key不能为null
- 通过hashcode和segment数组长度-1,算出segment下标
- 判断segement是否为空,如果为空,从segment[0]原型中获取segment初始化的属性,用来初始化segment对象。
- tryLock,
- 获取锁,走类似put的插入逻辑。
- 没有获取锁,通过自旋的方式,找到head节点。
- 算出key对应的HashEntry数组下标i,走类似put的插入逻辑
4、JDK7 ConcurrentHashMap的扩容
特点:
局部扩容,只扩容segment中的hashEntry数组。并且在单线程下扩容,不会有并发问题。
条件:
当segment中hashEntry数组容量大于等于阈值就会发生扩容。
流程:
- new 2倍数组长度,得到新数组
- 循环hashEntry,处理每一个桶位链表。
- 循环链表,计算出每个节点新的数组的下标。这里会找到不间断的局部链表都在同一个下标位置。将从不变化的开始位置,到链表的尾部,一次性到转移到新的数组下标上。
- 再循环链表将其他的节点依次转移到新的数组中。
5、JDK7 ConcurrentHashMap的Size
- 第一层死循环
- 为每个segment加锁
- 第二层循环累加每个segment的modCount 和 size。
- 然后比较上次循环中的modCount总数和当前循环的modCount总和。
- 相等则跳出死循环,返回size总和
6、JDK8 ConcurrentHashMap是怎么保证并发安全的
主要利用Unsafe操作+synchronized关键字
主要使用了Unsafe操作中的:
- compareAndSwapObject:通过cas的方式修改对象的属性
- putOrderedObeject:并发安全的给数组的某个位置赋值
- getObjectVolatile:并发安全的获取数组某个位置的元素
Synchronized主要负责在需要操作某个位置时进行加锁(该位置不能为空),比如向某个位置的链表进行插入节点,向某个位置的红黑树插入节点
JDK中其实仍然有分段锁的思想,只不过JDK7中段数是可以控制的,而JDK8中是数组的每一个位置都有一把锁。
7、JDK8 ConcurrentHashMap的put实现过程
- 首先根据key计算对应的数组下标i,如果该位置没有元素,则通过自旋的方式去向该位置赋值
- 如果该位置有元素,则通过synchronized将tab[i] 元素加锁
- 加锁成功之后,再判断该元素的类型
- 如果是链表节点则进行添加节点到链表中
- 如果是红黑树则添加到红黑树中
- 添加成功后,走出了同步块,判断是否需要进行树化
- addCount,这个方法的意思是ConcurrentHashMap的元素个数加1,但是这个操作也是需要并发安全的,并且元素个数加1成功后,会继续判断是否需要进行扩容,如果需要,则会进行扩容,所以这个方法很重要。
- 同时一个线程在put时如果发现当前ConcurrentHashMap正则进行扩容则会去帮助扩容
8、JDK8 ConcurrentHashMap的树化
树化条件:
当发现链表的元素个数大于等于8 (hashmap还会判断数组大小大于等于64)
树化流程:
- 对当前tab[i]加锁,锁TreeBin对象
- 将链表转变成双向链表,目的是方便红黑树操作
- 将双向链表插入到TreeBin中
9、JDK8 ConcurrentHashMap的TreeBin
相当于红黑树的壳子,他本身就是红黑树,他有属性root表示根节点,无论树结构怎么变,treebin都不会变。
10、JDK8 ConcurrentHashMap的addCount
- 判断是否初始化了baseCount,没有通过自旋的方式去初始化
- 通过随机数,计算出对应的countCells下标i
- countCells数组不为空,判断当前conuntCells[i] 是否有值,有值自旋方式 conuntCells[i] 值+1.
- 为空,循环
- 先自旋方式 baseCount+1
- 不成功则初始化countCells数组
- 找到对应的countCells数组下标自旋方式 conuntCells[i] 值+1.
- 再不成功再自旋 baseCount+1
11、JDK8 ConcurrentHashMap的扩容
扩容条件
- 当一个线程自旋2次 为counterCells +1都失败
- 或 元素个数大于等于了阈值
特点
- 当线程在put的时候,发现有正在扩容标记的时候,他会加入协助扩容
- 扩容到一定程度就不会扩容了
扩容流程
- new 2倍数组长度,得到新数组
- 首先为线程设置固定长度的步长,分配起始位置和结束位置。每个线程都会扩容自己那部分
- 每个线程先锁住桶,依次将自己负责的桶转移到新数组中
- 节点对应的hashcode和新数组长度做与运算
- 结果为0,为低位链表,不为0为高位链表
- 低位插入新数组老下标位置(i),高位插入新数组的老数组长度+老下标位置。(oldLength+i)
- 这里会先找局部链表,该链表从头到尾节点的下标都一致,对应新数组的位置,直接转移过去。再将其他的节点转移过去。
- 判断是否进行树化。
12、JDK8 ConcurrentHashMap的size
累加countCells数组每个元素值,再加上baseCount。
13、JDK8 ConcurrentHashMap的remove
减size,不减容量
14、JDK7和JDK8 ConcurrentHashMap的区别
- jdk8中没有分段锁,而是使用了synchronize的来进行控制
- jdk8中的扩容性能更高,支持多线程同时扩容,实际上jdk7中也支持多线程扩容,因为jdk7中的扩容是针对每个Segment的,所以也可能多线程扩容,但是性能没有jdk8高,因为jdk8中对于任何一个线程都可以去帮助扩容
- jdk8的元素个数统计实现不一样,jdk8是 counterCell数组元素+baseCount。jdk7是通过循环 遍历每个segment对象加锁统计累加的modCount和累加的size,和上次得出modCount的结果比较。
- 外加hashmap中的不同点
Java JDK源码 word文档下载地址:链接:https://pan.baidu.com/s/1BaUi8KUjvjJ6RPN7CmMSyw?
提取码:1111爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
常用主流框架面试合辑
Spring框架篇
1、什么是 Spring 框架Spring 框架有哪些主要模块
Spring 框架是一个为 Java 应用程序的开发提供了综合、广泛的基础性支持的 Java 平台。Spring 帮助开发者解决了开发中基础性的问题,使得开发人员可以专注于应用程序的开发。
Spring 框架本身亦是按照设计模式精心打造,这使得我们可以在开发环境中安心的集成 Spring 框架,不必担心 Spring 是如何在后台进行工作的。Spring 框架至今已集成了 20多个模块。这些模块主要被分如下图所示的核心容器、数据访问/集成,、Web、AOP(面向切面编程)、工具、消息和测试模块。
2、使用 Spring 框架能带来哪些好处
下面列举了一些使用Spring 框架带来的主要好处:
Dependency Injection(DI)方法使得构造器和 JavaBean properties 文件中的依赖关系一目了然。
与 EJB 容器相比较,IoC 容器更加趋向于轻量级。这样一来 IoC 容器在有限的内存和 CPU 资源的情况下进行应用程序的开发和发布就变得十分有利。
Spring 并没有闭门造车,Spring利用了已有的技术比如ORM 框架、logging 框架、J2EE、Q uartz和JDK Timer,以及其他视图技术。
Spring 框架是按照模块的形式来组织的。由包和类的编号就可以看出其所属的模块,开发者仅仅需要选用他们需要的模块即可。
要测试一项用 Spring 开发的应用程序十分简单,因为测试相关的环境代码都已经囊括在框架中了。更加简单的是,利用 JavaBean 形式的 POJO 类,可以很方便的利用依赖注入来写入测试数据。
Spring 的 Web 框架亦是一个精心设计的 Web MVC 框架,为开发者们在web 框架的选择上提供了一个除了主流框架比如 Struts、过度设计的、不流行 web 框架的以外的有力选项。
Spring 提供了一个便捷的事务管理接口,适用于小型的本地事物处理(比如在单 DB 的环境下)和复杂的共同事物处理(比如利用 JTA 的复杂 DB 环境)。
3、什么是控制反转(IOC)什么是依赖注入
控制反转是应用于软件工程领域中的,在运行时被装配器对象来绑定耦合对象的一种编程技巧,对象之间耦合关系在编译时通常是未知的。在传统的编程方式中,业务逻辑的流程是由应用程序中的早已被设定好关联关系的对象来决定的。在使用控制反转的情况下,业务逻辑的流程是由对象关系图来决定的,该对象关系图由装配器负责实例化,这种实现方式还可以将对象之间的关联关系的定义抽象化。而绑定的过程是通过“依赖注入”实现的。
控制反转是一种以给予应用程序中目标组件更多控制为目的设计范式,并在我们的实际工作中起到了有效的作用。
依赖注入是在编译阶段尚未知所需的功能是来自哪个的类的情况下,将其他对象所依赖的功能对象实例化的模式。这就需要一种机制用来激活相应的组件以提供特定的功能,所以依赖注入是控制反转的基础。否则如果在组件不受框架控制的情况下,框架又怎么知道要创建哪个组件
在Java 中依然注入有以下三种实现方式:
1.构造器注入
2.Setter方法注入
3.接口注入
4、请解释下 Spring 框架中的 IoC
Spring中的org.springframework.beans包和org.springframework.context包构成了 Spring 框架 IoC 容器的基础。BeanFactory 接口提供了一个先进的配置机制,使得任何类型的对象的配置成为可能。
ApplicationContex 接口对 BeanFactory(是一个子接口)进行了扩展,在 BeanFactory 的基础上添加了其他功能,比如与 Spring 的AOP 更容易集成,也提供了处理 message resource 的机制(用于国际化)、事件传播以及应用层的特别配置,比如针对 Web 应用的WebApplicationContext。
org.springframework.beans.factory.BeanFactory 是 Spring IoC 容器的具体实现,用来包装和管理前面提到的各种 bean。BeanFactory 接口是 Spring IoC 容器的核心接口。
IOC:把对象的创建、初始化、销毁交给 spring 来管理,而不是由开发者控制,实现控制反转。
5、BeanFactory 和 ApplicationContext 有什么区别
BeanFactory 可以理解为含有 bean 集合的工厂类。BeanFactory 包含了种bean 的定义,以便在接收到客户端请求时将对应的 bean 实例化。BeanFactory 还能在实例化对象的时生成协作类之间的关系。此举将 bean 自身与 bean 客户端的配置中解放出来。BeanFactory 还包含了 bean 生命周期的控制,调用客户端的初始化方法(initialization methods)和销毁方法(destruction methods)。
从表面上看,application context 如同 bean factory 一样具有 bean 定义、bean 关联关系的设置,根据请求分发 bean 的功能。但 applicationcontext 在此基础上还提供了其他的功能。
1.提供了支持国际化的文本消息
2.统一的资源文件读取方式
3.已在监听器中注册的bean的事件
以下是三种较常见的ApplicationContext 实现方式:
1、ClassPathXmlApplicationContext:从 classpath 的 XML 配置文件中读取上下文,并生成上下文定义。应用程序上下文从程序环境变量中
ApplicationContext context = new ClassPathXmlApplicationContex t(“bean.xml”);
2、FileSystemXmlApplicationContext:由文件系统中的XML配置文件读取上下文。
ApplicationContext context = new FileSystemXmlApplicationConte xt(“bean.xml”);
3、XmlWebApplicationContext:由 Web 应用的 XML 文件读取上下文。
4、AnnotationConfigApplicationContext(基于 Java 配置启动容器)

6、Spring 有几种配置方式
将Spring 配置到应用开发中有以下三种方式:
1.基于XML的配置
2.基于注解的配置
3.基于Java的配置
7、如何用基于 XML 配置的方式配置 Spring
在Spring 框架中,依赖和服务需要在专门的配置文件来实现,我常用的XML 格式的配置文件。这些配置文件的格式通常开头,然后一系列的bean 定义和专门的应用配置选项组成。
SpringXML 配置的主要目的时候是使所有的 Spring 组件都可以用 xml 文件的形式来进行配置。这意味着不会出现其他的 Spring 配置类型(比如声明的方式或基于 Java Class 的配置方式)
Spring 的 XML 配置方式是使用被 Spring 命名空间的所支持的一系列的XML 标签来实现的。Spring 有以下主要的命名空间:context、beans、jdbc、tx、aop、mvc 和 aso。
如:

下面这个web.xml仅仅配置了DispatcherServlet,这件最简单的配置便能满足应用程序配置运行时组件的需求


8、如何用基于 Java 配置的方式配置 Spring
Spring 对 Java 配置的支持是由@Configuration 注解和@Bean 注解来实现的。由@Bean 注解的方法将会实例化、配置和初始化一个新对象,这个对象将由 Spring 的 IoC 容器来管理。@Bean 声明所起到的作用与 元素类似。被@Configuration 所注解的类则表示这个类的主要目的是作为 bean 定义的资源。被@Configuration 声明的类可以通过在同一个类的内部调用@bean 方法来设置嵌入 bean 的依赖关系。
最简单的@Configuration 声明类请参考下面的代码:

对于上面的@Beans 配置文件相同的 XML 配置文件如下:
上述配置方式的实例化方式如下:利用 AnnotationConfigApplicationContext
public static void main(String[] args)
{ ApplicationContext ctx = new
AnnotationConfigApplicationContext(AppConfig.class);
MyService myService = ctx.getBean(MyService.class);
myService.doStuff();
}
要使用组件组建扫描,仅需用@Configuration 进行注解即可:
@Configuration
@ComponentScan(basePackages = "com.somnus")
public class AppConfig {
... }
在上面的例子中,com.acme 包首先会被扫到,然后再容器内查找被@Component 声明的类,找到后将这些类按照 Sring bean 定义进行注册。
如果你要在你的web 应用开发中选用上述的配置的方式的话,需要用
AnnotationConfigWebApplicationContext 类来读取配置文件,可以用来配置Spring的Servlet监听器ContextLoaderListener或者Spring MVC 的
contextClass
org.springframework.web.context.support.AnnotationConfigWebApp licatio
nContext
contextConfigLocation
com.howtodoinjava.AppConfig
contextClass
org.springframework.web.context.support.AnnotationConfigWebApp
licatio nContext
contextConfigLocation
com.howtodoinjava.AppConfig
9、怎样用注解的方式配置 Spring
Spring 在 2.5 版本以后开始支持用注解的方式来配置依赖注入。可以用注解的方式来替代 XML 方式的 bean 描述,可以将 bean 描述转移到组件类的内部,只需要在相关类上、方法上或者字段声明上使用注解即可。注解注入将会被容器在 XML 注入之前被处理,所以后者会覆盖掉前者对于同一个属性的处理结果。
注解装配在 Spring 中是默认关闭的。所以需要在 Spring 文件中配置一下才能使用基于注解的装配模式。如果你想要在你的应用程序中使用关于注解的方法的话,请参考如下的配置。
在context:annotation-config/标签配置完成以后,就可以用注解
的方式在 Spring 中向属性、方法和构造方法中自动装配变量。下面是几种比较重要的注解类型:
1. @Required:该注解应用于设值方法。
2. @Autowired:该注解应用于有值设值方法、非设值方法、构造方法和变量。
3. @Qualifier:该注解和@Autowired 注解搭配使用,用于消除特定 bean 自动装配的歧义。
4.JSR-250Annotations:Spring支持基于JSR-250注解的以下注解,
@Resource、 @PostConstruct 和 @PreDestroy。
10、请解释 Spring Bean 的生命周期
Spring Bean 的生命周期简单易懂。在一个 bean 实例被初始化时,需要执行一系列的初始化操作以达到可用的状态。同样的,当一个 bean 不在被调用时需要进行相关的析构操作,并从 bean 容 器中移除。
Spring bean factory 负责管理在 spring 容器中被创建的 bean 的生命周期。Bean 的生命周期由两组回调(call back)方法组成。
1. 初始化之后调用的回调方法。
2. 销毁之前调用的回调方法。
Spring 框架提供了以下四种方式来管理 bean 的生命周期事件:
InitializingBean和DisposableBean回调接口
针对特殊行为的其他Aware接口
Bean配置文件中的Custominit()方法和destroy()方法
@PostConstruct和@PreDestroy注解方式
使用customInit()和customDestroy()方法管理bean生命周期的代码样例如下:
11、Spring Bean 的作用域之间有什么区别
Spring 容器中的 bean 可以分为 5 个范围。所有范围的名称都是自说明的,但是为了避免混淆,还是让我们来解释一下:
1. singleton:这种 bean 范围是默认的,这种范围确保不管接受到多少个请求,每个容器中只有一个 bean 的实例,单例的模式由 bean factory 自身来维护。
2. prototype:原形范围与单例范围相反,为每一个 bean 请求提供一个实例。
3. request:在请求 bean 范围内会每一个来自客户端的网络请求创建一个实例,在请求完成以后,bean 会失效并被垃圾回收器回收。
4.Session:与请求范围类似,确保每个session中有一个bean的实例,在
session 过期后,bean 会随之失效。
5. global- session:global-session 和 Portlet 应用相关。当你的应用部署在Portlet 容器中工作时,它包含很多 portlet。如果你想要声明让所有的portlet 共用全局的存储变量的话,那么这全局变量需要存储在 global- session 中。
全局作用域与 Servlet 中的 session 作用域效果相同。
12、什么是 Spring inner beans
在 Spring 框架中,无论何时 bean 被使用时,当仅被调用了一个属性。一个明智的做法是将这个 bean 声明为内部 bean。内部 bean 可以用 setter 注入“属性”和构造方法注入“构造参数”的方式来实现。
比如,在我们的应用程序中,一个 Customer 类引用了一个 Person 类, 我们的要做的是创建一个 Person 的实例,然后在 Customer 内部使用。
public class Customer{ private Person person;
//Setters and Getters
}
public class
Person{ private String name; private String address; private int age
内部bean 的声明方式如下:
13、Spring 框架中的单例 Beans 是线程安全的么
Spring 框架并没有对单例 bean 进行任何多线程的封装处理。关于单例bean 的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的 Spring bean 并没有可变的状态(比如 Serview 类和 DAO 类),所以在某种程度上说 Spring 的单例 bean 是线程安全的。如果你的 bean 有多种状态的话(比如 View Model 对象),就需要自行保证线程安全。
最浅显的解决办法就是将多态 bean 的作用域由“singleton”变更为“prototype”。
14、请举例说明如何在 Spring 中注入一个 Java Collection
Spring 提供了以下四种集合类的配置元素:
- 该标签用来装配可重复的 list 值。
- 该标签用来装配没有重复的 set 值。
- 该标签可用来注入键和值可以为任何类型的键值对
- 该标签支持注入键和值都是字符串类型的键值对。
下面看一下具体的例子:
INDIA
Pakistan
USA
UK
INDIA
Pakistan
USA
UK
[email protected]
[email protected]
15、如何向 Spring Bean 中注入一个 Java.util.Properties
第一种方法是使用如下面代码所示的标签:
[email protected]
[email protected]
也可用”util:”命名空间来从 properties 文件中创建出一个 propertiesbean,然后利用 setter 方法注入 bean 的引用。
16、请解释 Spring Bean 的自动装配
在 Spring 框架中,在配置文件中设定 bean 的依赖关系是一个很好的机制,Spring 容器还可以自动装配合作关系 bean 之间的关联关系。这意味着 Spring 可以通过向 Bean Factory 中注入的方式自动搞定 bean 之间的依赖关系。自动装配可以设置在每个 bean 上,也可以设定在特定的 bean 上。下面的XML 配置文件表明了如何根据名称将一个 bean 设置为自动装配:
除了 bean 配置文件中提供的自动装配模式,还可以使用@Autowired 注解来自动装配指定的 bean。在使用@Autowired 注解之前需要在按照如下的配置方式在 Spring 配置文件进行配置才可以使用。
也可以通过在配置文件中配置 AutowiredAnnotationBeanPostProcessor 达到相同的效果。
配置好以后就可以使用@Autowired 来标注了。
@Autowired
public EmployeeDAOImpl ( EmployeeManager manager ) { this.manager = manager;
}
17、请解释自动装配模式的区别
在 Spring 框架中共有 5 种自动装配,让我们逐一分析。
1. no:这是 Spring 框架的默认设置,在该设置下自动装配是关闭的,开发者需要自行在 bean 定义中用标签明确的设置依赖关系。
2. byName:该选项可以根据 bean 名称设置依赖关系。当向一个 bean 中自动装配一个属性时,容器将根据 bean 的名称自动在在配置文件中查询一个匹配的 bean。如果找到的话,就装配这个属性,如果没找到的话就报错。
3. byType:该选项可以根据 bean 类型设置依赖关系。当向一个 bean 中自动装配一个属性时,容器将根据 bean 的类型自动在在配置文件中查询一个匹配的 bean。如果找到的话,就装配这个属性,如果没找到的话就报错。
4. constructor:构造器的自动装配和 byType 模式类似,但是仅仅适用于与有构造器相同参数的 bean,如果在容器中没有找到与构造器参数类型一致的 bean,那么将会抛出异常。
5. autodetect:该模式自动探测使用构造器自动装配或者 byType 自动装配。首先,首先会尝试找合适的带参数的构造器,如果找到的话就是用构造器自动装配,如果在 bean 内部没有找到相应的构造器或者是无参构造器,容器就会自动选择 byTpe 的自动装配方式。
18、如何开启基于注解的自动装配
要使用@Autowired,需要注册AutowiredAnnotationBeanPostProcessor,可以
有以下两种方式来实现:
引入配置文件中的下引入context:annotation-config
class="org.springframework.beans.factory.annotation.AutowiredA nnotati
onBeanPostProcessor"/>
在bean配置文件中直接引入AutowiredAnnotationBeanPostProcessor
19、请举例解释@Required 注解
在产品级别的应用中,IoC容器可能声明了数十万了bean,bean与bean
之间有着复杂的依赖关系。设值注解方法的短板之一就是验证所有的属性
是否被注解是一项十分困难的操作。可以通过在中设置“dependency-check”来解决这个问题。
在应用程序的生命周期中,你可能不大愿意花时间在验证所有 bean 的属性是否按照上下文件正确配置。或者你宁可验证某个 bean 的特定属性是否被正确的设置。即使是用“dependency- check”属性也不能很好的解决这个问题,在这种情况下,你需要使用@Required 注解。
需要用如下的方式使用来标明bean 的设值方法:
public class EmployeeFactoryBean extends AbstractFactoryBean{
private String designation; public String getDesignation() {
return designation;
}
@Required
public void setDesignation(String designation)
{ this.designation = designation;
}
//more code here
}
RequiredAnnotationBeanPostProcessor 是 Spring 中的后置处理用来验证被@Required 注解的 bean 属性是否被正确的设置了。在使用RequiredAnnotationBeanPostProcesso 来验证 bean 属性之前,首先要在IoC 容器中对其进行注册:但是如果没有属性被用@Required 注解过的话,后置处理器会抛出一个BeanInitializationException 异常。
20、请举例解释@Autowired 注解
@Autowired 注解对自动装配何时何处被实现提供了更多细粒度的控制。@Autowired 注解可 以像@Required 注解、构造器一样被用于在 bean 的设置方法上自动装配 bean 的属性,一个参数或者带有任意名称或带有多个参数的方法。比如,可以在设值方法上使用@Autowired 注解来替代配置文件中的元素当Spring容器在setter方法上找到@Autowired 注解时,会尝试用 byType 自动装配。当然我们也可以在构造方法上使用@Autowired 注解。带有@Autowired 注解的构造方法意味着在创建一个bean时将会被自动装配,即便在配置文件中使用元素。
public class TextEditor {
private SpellChecker spellChecker; @Autowired
public TextEditor(SpellChecker spellChecker)
{
System.out.println("Inside TextEditor constructor." );
this.spellChecker = spellChecker;
}
public void spellCheck(){ spellChecker.checkSpelling();
下面是没有构造参数的配置方式:
21、请举例说明@Qualifier 注解
@Qualifier 注解意味着可以在被标注 bean 的字段上可以自动装配。Qualifier 注解可以用来取消 Spring 不能取消的 bean 应用。下面的示例将会在Customer 的 person 属性中自动装配 person 的值
public class Customer{ @Autowired
private Person person
下面我们要在配置文件中来配置 Person 类。
Spring 会知道要自动装配哪个 person bean 么不会的,但是运行上面的示例时,会抛出下面的异常:
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionExceptio n:
No unique bean of type [com.howtodoinjava.common.Person] is de fined: expected single matching bean but found2: [personA, pe rsonB]
要解决上面的问题,需要使用@Quanlifier注解来告诉Spring容器要装配哪个bean:
public class Customer{ @Autowired @Qualifier("personA") private Person person;
}
22、构造方法注入和设值注入有什么区别 请注意以下明显的区别:
1. 在设值注入方法支持大部分的依赖注入,如果我们仅需要注入int、 string和long型的变量,我们不要用设值的方法注入。对于基本类型,如果我们没有注入的话,可以为基本类型设置默认值。在构造方法 注入不支持大部分的依赖注入,因为在调用构造方法中必须传入正确的构造参数,否 则的话为报错。
2. 设值注入不会重写构造方法的值。如果我们对同一个变量同时使用了构造方法注入又使用了设置方法注入的话,那么构造方法将不能覆盖由设值方法注入的值。很明显,因为构造方法在对象被创建时调用。
3. 在使用设值注入时有可能还不能保证某种依赖是否已经被注入,也就是说这时对象的依赖关系有可能是不完整的。而在另一种情况下,构造器注入则不允许生成依赖关系不完整的对象。
4. 在设值注入时如果对象A和对象B互相依赖,在创建对象A时Spring会抛出 sObjectCurrentlyInCreationException 异常,因为在 B 对象被创建之前A 对象是不能被创建的,反之亦然。所以 Spring 用设值注入的方法解决了循环依赖的问题,因对象的设值方法是在对象被创建之前被调用的。
23、Spring 框架中有哪些不同类型的事件
Spring的ApplicationContext 提供了支持事件和代码中监听器的功能。我们可以创建bean用来监听在ApplicationContext 中发布的事件。ApplicationEvent类和在ApplicationContext接口中处理的事件,如果一个bean实现了ApplicationListener接口,当一个ApplicationEvent 被发布以后,bean 会自动被通知。
public class AllApplicationEventListener implements Applicatio nListener < ApplicationEvent >{
@Override
public void onApplicationEvent(ApplicationEvent applicatio nEvent)
{
//process event
}
}
Spring 提供了以下 5 种标准的事件:
1.上下文更新事件(ContextRefreshedEvent):该事件会在ApplicationContext被初始化或者更新时发布。也可以在调用 ConfigurableApplicationContext接口中的 refresh()方法时被触发。
2. 上下文开始事件(ContextStartedEvent):当容器调用ConfigurableApplicationContext的 Start()方法开始/重新开始容器时触发该事件。
3.上下文停止事件(ContextStoppedEvent):当容器调用ConfigurableApplicationContext的 Stop()方法停止容器时触发该事件。
4. 上下文关闭事件(ContextClosedEvent):当ApplicationContext被关闭时触发该事件。容器被关闭时,其管理的所有单例 Bean 都被销毁。
5.请求处理事件(RequestHandledEvent):在Web应用中,当一个http请求(request)结束 触发该事件。
public class CustomApplicationEvent extends ApplicationEvent{ public CustomApplicationEvent ( Object source, final String ms g ){
super(source);
System.out.println("Created a Custom event");
}
}
为了监听这个事件,还需要创建一个监听器:
public class CustomEventListener implements ApplicationListene r <
CustomApplicationEvent >{ @Override
public void onApplicationEvent(CustomApplicationEvent applicationEvent) {
//handle event
}
}
之后通过 applicationContext 接口的 publishEvent()方法来发布自定义事件。
CustomApplicationEvent customEvent = new
CustomApplicationEvent(applicationContext, "Test message");
applicationContext.publishEvent(customEvent);
24、FileSystemResource 和 ClassPathResource 有何区别
在 FileSystemResource 中需要给出 spring-config.xml 文件在你项目中的相对路径或者绝对路径。在 ClassPathResource 中 spring 会在 ClassPath 中自动搜寻配置文件,所以要把 ClassPathResource 文件放在 ClassPath下。
如果将 spring-config.xml 保存在了 src 文件央下的话,只需给出配置文件的名称即可,因为 src 文件央是默认。
简而言之,ClassPathResource 在环境变量中读取配置文件,
FileSystemResource 在配置文件中读取配置文件。
25、Spring 框架中都用到了哪些设计模式
Spring 框架中使用到了大量的设计模式,下面列举了比较有代表性的:
- 代理模式—在AOP和remoting中被用的比较多。
- 单例模式—在spring配置文件中定义的bean默认为单例模式。
- 模板方法—用来解决代码重复的问题。比如.RestTemplate,JmsTemplate,JpaTempl ate。
- 前端控制器—Spring提供了DispatcherServlet来对请求进行分发。
- 视图帮助(ViewHelper)—Spring提供了一系列的JSP标签,高效宏来辅助将分散的代码整合在视图里。
- 依赖注入—贯穿于BeanFactory/ApplicationContext接口的核心理念。
- 工厂模式—BeanFactory用来创建对象的实例
26、开发中主要使用 Spring 的什么技术
1.IOC容器管理各层的组件
2.使用AOP配置声明式事务
3.整合其他框架.
27、简述 AOP 和 IOC 概念 AOP:
Aspect Oriented Program, 面向(方面)切面的编程;Filter(过滤器) 也是一种AOP. AOP 是一种新的方法论, 是对传统 OOP(Object-Oriented Programming, 面向对象编程) 的补充. AOP 的 主要编程对象是切面(aspect), 而切面模块化横切关注点.可以举例通过事务说明.
IOC: Invert Of Control, 控制反转.也成为DI(依赖注入)其思想是反转资源获取的方向.传统的资源查找方式要求组件向容器发起请求查找资源.作为回应,容器适时的返回资源.而应用了IOC 之后,则是容器主动地将资源推送给它所管理的组件,组件所要做的仅是选择一种合适的方式来接受资源.这种行为也被称为查找的被动形式
28、在 Spring 中如何配置 Bean
Bean的配置方式:
- 通过全类名(反射)
- 通过工厂方法(静态工厂方法&实例工厂方法)
- FactoryBean
29、IOC 容器对 Bean 的生命周期:
1.通过构造器或工厂方法创建Bean实例
2.为Bean的属性设置值和对其他Bean的引用
3.将Bean实例传递给Bean后置处理器的postProcessBeforeInitialization方法
4.调用Bean的初始化方法(init-method)
5.将Bean实例传递给Bean后置处理器的postProcessAfterInitialization方法
6.Bean可以使用了
7.当容器关闭时,调用Bean的销毁方法(destroy-method)
下载链接:https://pan.baidu.com/s/1nwlBO2tYXDDl7OjGhs4e4Q
提取码:1111
SpringMVC原理篇
1、什么是 SpringMvc
SpringMvc 是 spring 的一个模块,基于 MVC 的一个框架,无需中间整合层来整合。
2、Spring MVC 的优点:
1.它是基于组件技术的.全部的应用对象,无论控制器和视图,还是业务对象之类的都是java组件.并且和Spring提供的其他基础结构紧密集成.
2.不依赖于ServletAPI(目标虽是如此,但是在实现的时候确实是依赖于Servlet的)
3.可以任意使用各种视图技术,而不仅仅局限于JSP
4.支持各种请求资源的映射策略
5.它应是易于扩展的
3、SpringMVC 工作原理
1.客户端发送请求到DispatcherServlet
2.DispatcherServlet查询handlerMapping找到处理请求的Controller
3.Controller调用业务逻辑后,返回ModelAndView 4.DispatcherServlet查询ModelAndView,找到指定视图5.视图将结果返回到客户端
4、SpringMVC 流程
1.用户发送请求至前端控制器 DispatcherServlet。
2.DispatcherServlet 收到请求调用 HandlerMapping 处理器映射器。
3. 处理器映射器找到具体的处理器(可以根据 xml 配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给 DispatcherServlet。
4. DispatcherServlet 调用 HandlerAdapter 处理器适配器。
5.HandlerAdapter 经过适配调用具体的处理器(Controller,也叫后端控制器)。
6.Controller 执行完成返回 ModelAndView。
7.HandlerAdapter 将 controller 执行结果 ModelAndView 返回给DispatcherServlet。
8. DispatcherServlet 将 ModelAndView 传给 ViewReslover 视图解析器。
9. ViewReslover 解析后返回具体 View。
10. DispatcherServlet 根据 View 进行渲染视图(即将模型数据填充至视图中)。
11. DispatcherServlet 响应用户。
5、SpringMVC的控制器是不是单例模式,如果是,有什么问题,怎么解决
是单例模式,所以在多线程访问的时候有线程安全问题,不要用同步,会影响性能的,解决方案是在控制器里面不能写字段。
6、如果你也用过 struts2.简单介绍下 springMVC 和 struts2 的区别有哪些
1.springmvc的入口是一个servlet即前端控制器,而struts2 入口是一个
filter 过滤器。
2. springmvc 是基于方法开发(一个 url 对应一个方法),请求参数传递到方法的形参,可以设计为单例或多例(建议单例),struts2 是基于类开发,传递参数是通过类的属性,只能设 计为多例。
3. Struts 采用值栈存储请求和响应的数据,通过 OGNL 存取数据, springmvc 通过参数解析器是将 request 请求内容解析,并给方法形参赋值,将数据和视图封装成 ModelAndView 对象,最后又将 ModelAndView 中的模型数据通过 reques 域传输到页面。Jsp 视图解析器默认使用 jstl。
7、SpringMVC中的控制器的注解一般用那个,有没有别的注解可以替代
一般用@Conntroller 注解,表示是表现层,不能用用别的注解代替。
8、 @RequestMapping 注解用在类上面有什么作用
是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
9、怎么样把某个请求映射到特定的方法上面
答:直接在方法上面加上注解@RequestMapping,并且在这个注解里面写上要拦截的路径
10、如果在拦截请求中,我想拦截 get 方式提交的方法,怎么配置
可以在@RequestMapping 注解里面加上 method=RequestMethod.GET
11、怎么样在方法里面得到 Request,或者 Session
直接在方法的形参中声明 request,SpringMvc 就自动把 request 对象传入
12、我想在拦截的方法里面得到从前台传入的参数,怎么得到
答:直接在形参里面声明这个参数就可以,但必须名字和传过来的参数一样
13、如果前台有很多个参数传入,并且这些参数都是一个对象的,那么怎么样快速得到这个对象
直接在方法中声明这个对象,SpringMVC 就自动会把属性赋值到这个对象里面。
14、SpringMVC中函数的返回值是什么
答:返回值可以有很多类型,有 String, ModelAndView,但一般用 String 比较好。
15、SpringMVC 怎么样设定重定向和转发的
在返回值前面加"forward:“就可以让结果转发,比如"forward:user.doname=method4”
在返回值前面加"redirect:"就可以让返回值重定向,比如redirect:http://www.baidu.com
16、SpringMVC用什么对象从后台向前台传递数据的
答:通过 ModelMap 对象,可以在这个对象里面用 put 方法,把对象加到里面, 前台就可以通过 el 表达式拿到。
17、SpringMVC中有个类把视图和数据都合并的一起的,叫什么
叫 ModelAndView。
18、怎么样把 ModelMap 里面的数据放入 Session 里面
可以在类上面加上@SessionAttributes 注解,里面包含的字符串就是要放入session 里面的 key
19、SpringMVC 怎么和 AJAX 相互调用的
通过Jackson 框架就可以把 Java 里面的对象直接转化成 Js 可以识别的Json 对象。
具体步骤如下 :
1.加入Jackson.jar
2.在配置文件中配置json的映射
3.在接受Ajax方法里面可以直接返回Object,List等,但方法前面要加上@ResponseBody 注解
20、当一个方法向 AJAX 返回特殊对象,譬如 Object,List 等,需要做什么处理
要加上@ResponseBody 注解
21、SpringMVC里面拦截器是怎么写的
有两种写法,一种是实现接口,另外一种是继承适配器类,然后在 SpringMvc
22、讲下 SpringMVC 的执行流程
系统启动的时候根据配置文件创建spring的容器, 首先是发送http请求到核心控制器 disPatherServlet,spring 容器通过映射器去寻找业务控制器,使用适配器找到相应的业务类,在进业务类时进行数据封装,在封装前可能会涉及到类型转换,执行完业务类后使用 ModelAndView 进行视图转发, 数据放在 model 中,用 map 传递数据进行页面显示。
MyBatis框架篇
1、什么是 MyBatis
MyBatis 是一个可以自定义 SQL、存储过程和高级映射的持久层框架。
2、讲下 MyBatis 的缓存
MyBatis的缓存分为一级缓存和二级缓存,一级缓存放在session里面,默认就有,二级缓存放在它的命名空间里,默认是不打开的,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置
3、Mybatis 是如何进行分页的分页插件的原理是什么
1. Mybatis 使用 RowBounds 对象进行分页,也可以直接编写 sql 先分页, 也可以使用 Mybatis 的分页插件。
2. 分页插件的原理:实现 Mybatis 提供的接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql。
select * from student
拦截sql 后重写为:
select t.* from (select * from student)t limit 0,10
4、简述 Mybatis 的插件运行原理以及如何编写一个插件
1. Mybatis 仅可以编写针对 ParameterHandler、ResultSetHandler、StatementHandler、 Executor 这 4 种接口的插件,Mybatis 通过动态代理,为需要拦截的接口生成代理对象以实 现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler 的 invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
2. 实现 Mybatis 的 Interceptor 接口并复写 intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
5、Mybatis 动态 sql 是做什么的都有哪些动态 sql能简述一下动态 sql的执行原理吗
1. Mybatis 动态 sql 可以让我们在 Xml 映射文件内,以标签的形式编写动态 sql,完成逻辑 判断和动态拼接 sql 的功能。
2.Mybatis提供了9种动态sql标签:
trim|where|set|foreach|if|choose|when|otherwise|bind。
3. 其执行原理为,使用 OGNL 从 sql 参数对象中计算表达式的值,根据表达式的值动态拼接 sql,以此来完成动态 sql 的功能。
6、#{}和${}的区别是什么
1.#{}是预编译处理,${}是字符串替换。
2.Mybatis在处理#{}时,会将sql中的#{}替换为号,调用PreparedStatement的set方法来赋值;
3.Mybatis在处理 时 , 就是把 {}时,就是把 时,就是把{}替换成变量的值。
4.使用#{}可以有效的防止SQL注入,提高系统安全性。
7、为什么说 Mybatis 是半自动 ORM 映射工具它与全自动的区别在哪里
Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而 Mybatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
8、Mybatis是否支持延迟加载如果支持它的实现原理是什么
1.Mybatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在Mybatis 配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false
2.它的原理是,使用 CGLIB 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调a.setB(b)于是a 的对象 b方法的属性性调用就有值了,接着完成a.getB().getName()。这就是延迟加载的基本原理。
9、MyBatis 与 Hibernate 有哪些不同
1. Mybatis 和 hibernate 不同,它不完全是一个 ORM 框架,因为 MyBatis 需要程序员自己编写 Sql 语句,不过 mybatis 可以通过 XML 或注解方式灵活配置要运行的 sql 语句,并将 java 对象和 sql 语句映射生成最终执行的sql,最后将 sql 执行的结果再映射生成 java 对象。
2.Mybatis学习门槛低,简单易学,程序员直接编写原生态 sql,可严格控制 sql 执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁, 一但需求变化要求成果输出迅速。但是灵活的前提是 mybatis 无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定 义多套 sql 映射文件,工作量大。
3. Hibernate 对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用 hibernate 开发可以节省很多代码,提高效率。但是 Hibernate 的缺点是学习门槛高,要精通门槛更高,而且怎么设计 O/R 映射,在性能和对象模型之间如何权衡,以及怎样用好 Hibernate 需要具有很强的经验和能力才行。总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。
10、MyBatis 的好处是什么
1. MyBatis 把 sql 语句从 Java 源程序中独立出来,放在单独的 XML 文件中编写,给程序的维护带来了很大便利。
2.MyBatis封装了底层JDBC API的调用细节,并能自动将结果集转换成Java Bean 对象,大大简化了 Java 数据库编程的重复工作。
3. 因为 MyBatis 需要程序员自己去编写 sql 语句,程序员可以结合数据库自身的特点灵活控制 sql 语句,因此能够实现比 Hibernate 等全自动 orm 框架更高的查询效率,能够完成复杂查询。
11、简述 Mybatis 的 Xml 映射文件和 Mybatis 内部数据结构之间的映射关系
Mybatis 将所有 Xml 配置信息都封装到 All-In-One 重量级对象Configuration内部。在Xml映射文件中,标签会被解析为ParameterMap对象,其每个子元素会 被解析为ParameterMapping对象。标签会被解析为ResultMap对象,其每个子元素会被解析为ResultMapping 对象。每一个、、、 标签均会被解析为 MappedStatement 对象,标签内的 sql 会被解析为 BoundSql 对象。
12、什么是 MyBatis 的接口绑定,有什么好处
接口映射就是在MyBatis 中任意定义接口,然后把接口里面的方法和SQL 语句绑定,我们直接调用接口方法就可以,这样比起原来了Sql Session提供的方法我们可以有更加灵活的选择和设置.
13、接口绑定有几种实现方式,分别是怎么实现的
接口绑定有两种实现方式,一种是通过注解绑定,就是在接口的方法上面加上@Select@Update等注解里面包含Sql语句来绑定,另外一种就是通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名.
14、什么情况下用注解绑定,什么情况下用 xml 绑定
当Sql 语句比较简单时候,用注解绑定;当SQL 语句比较复杂时候,用xml绑定,一般用xml 绑定的比较多
15、MyBatis 实现一对一有几种方式具体怎么操作的
有联合查询和嵌套查询,联合查询是几个表联合查询,只查询一次,通过在resultMap 里面配置 association 节点配置一对一的类就可以完成;嵌套查询是先查一个表,根据这个表里面的结果的外键 id,去再另外一个表里面查询数据,也是通过 association 配置,但另外一个表的查询通过 select 属性配置。
16、Mybatis能执行一对一、一对多的关联查询吗都有哪些实现方式以及它们之间的区别
能,Mybatis 不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,多对一查询,其实就是一对一查询,只需要把selectOne()修改为 selectList()即可;多对多查询,其实就是一对多查询,只需要把 selectOne()修改为 selectList()即可。
关联对象查询,有两种实现方式,一种是单独发送一个 sql 去查询关联对象,赋给主对象,然后返回主对象。另一种是使用嵌套查询,嵌套查询的 含义为使用 join 查询,一部分列是 A 对象的属性值,另外一部分列是关联对象 B 的属性值,好处是只发一个 sql 查询,就可以把主对象和其关联对象查出来。
17、MyBatis 里面的动态 Sql 是怎么设定的用什么语法
MyBatis 里面的动态 Sql 一般是通过 if 节点来实现,通过 OGNL 语法来实现,但是如果要写的完整,必须配合 where,trim 节点,where 节点是判断包含节点有内容就插入 where,否则不插入,trim 节点是用来判断如果动态语句是以 and 或 or 开始,那么会自动把这个 and 或者 or 取掉。
18、Mybatis 是如何将 sql 执行结果封装为目标对象并返回的都有哪些映射形式
第一种是使用标签,逐一定义列名和对象属性名之间的映射关系。
第二种是使用sql 列的别名功能,将列别名书写为对象属性名,比如T_NAME AS NAME,对象属性名一般是 name,小写,但是列名不区分大小写,Mybatis 会忽略列名大小写,只能找到与之对应对象属性名,你甚至可以写成T_NAME AS NAME,MyBatis一样可以正常工作。有了列名与属性名的映射关系后,Mybatis 通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
19、Xml 映射文件中除了常见的 select|insert|updae|delete 标签之外还有哪些标签
还有很多其他的标签,、、、、 ,加上动态 sql 的 9 个标签,
trim|where|set|foreach|if|choose|when|otherwise|bind等,其中为sql片段标签,通过标签引入sql片段为不支持自增的主键生成策略标签
20、当实体类中的属性名和表中的字段名不一样如果将查询的结果封装到指定 pojo
1. 通过在查询的 sql 语句中定义字段名的别名。
2.通过来映射字段名和实体类属性名的一一对应的关系。
21、模糊查询 like 语句该怎么写
1.在java中拼接通配符,通过#{}赋值
2.在Sql语句中拼接通配符(不安全会引起Sql注入)
22、通常一个 Xml 映射文件都会写一个 Dao 接口与之对应, Dao 的工作原理是否可以重载
不能重载,因为通过 Dao 寻找 Xml 对应的 sql 的时候权限名+方法名的保存和寻找策略。接口工作原理为 jdk 动态代理原理,运行时会为 dao 生成proxy,代理对象会拦截接口方法,去执行对应的 sql 返回数据。
23、Mybatis 映射文件中如果 A标签通过include引用了B 标签的内容请问B标签能否定义在A标签的后面还是说必须定义在A标签的前面
虽然 Mybatis 解析 Xml 映射文件是按照顺序解析的,但是,被引用的 B 标签依然可以定义在任何地方,Mybatis 都可以正确识别。原理是,Mybatis 解析 A 标签,发现 A 标签引用了 B 标签,但是 B 标签尚未解析到,尚不存在,此时,Mybatis 会将 A 标签标记为未解析状态,然后继续解析余下的标签,包含 B 标签,待所有标签解析完毕,Mybatis 会重新解析那些被标记为未解析的标签,此时再解析 A 标签时,B 标签已经存在,A 标签也就可以正常解析完成了。
24、Mybatis 的 Xml 映射文件中不同的 Xml 映射文件id 是否可以重复
不同的 Xml 映射文件,如果配置了 namespace,那么 id 可以重复;如果没有配置 namespace,那么 id 不能重复;毕竟 namespace 不是必须的,只是最佳实践而已。原因就是 namespace+id 是作为Map
25、Mybatis 中如何执行批处理
使用 BatchExecutor 完成批处理。
26、Mybatis 都有哪些 Executor 执行器它们之间的区别是什么
Mybatis 有三种基本的Excutor执行器,SimpleExecutor、ReuseExecutor、 BatchExecutor。
1、SimpleExecutor:每执行一次Updata或者select就开启一个statement对象,用完立刻关闭 Statement 对象.
2、ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map
3、BatchExecutor:完成批处理。
27、Mybatis 中如何指定使用哪一种 Executor 执行器
在 Mybatis 配置文件中,可以指定默认的 ExecutorType 执行器类型,也可以手动给 DefaultSqlSessionFactory 的创建 SqlSession 的方法传递ExecutorType 类型参数。
28、Mybatis 执行批量插入能返回数据库主键列表吗
能,JDBC 都能,Mybatis 当然也能。
29、Mybatis 是否可以映射 Enum 枚举类
Mybatis 可以映射枚举类,不单可以映射枚举类,Mybatis 可以映射任何对象到表的一列上。映射方式为自定义一个 TypeHandler,实现 TypeHandler的 setParameter()和 getResult()接口方法。
TypeHandler 有两个作用,一是完成从 javaType 至 jdbcType 的转换, 二是完成 jdbcType 至 javaType 的转换,体现为 setParameter()和 getResult()两个方法,分别代表设置 sql 问号占位符参数和获取列查询结果。
30、如何获取自动生成的(主)键值
配置文件设置usegeneratedkeys 为 true
31、在 mapper 中如何传递多个参数
1.直接在方法中传递参数,xml文件用#{0}#{1}来获取
2.使用@param注解:这样可以直接在xml文件中通过#{name}来获取
32、resultType resultMap 的区别
1.类的名字和数据库相同时,可以直接设置 resultType参数为Pojo 类
2.若不同,需要设置resultMap将结果名字和Pojo名字进行转换
33、使用 MyBatis 的 mapper 接口调用时有哪些要求
类型相同
1.Mapper接口方法名和mapper.xml中定义的每个sql的id 相同
2.Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql的parameterType的类型相同
3.Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType 的类型相同
4. Mapper.xml 文件中的 namespace 即是 mapper 接口的类路径。
34、Mybatis 比 IBatis 比较大的几个改进是什么
1.有接口绑定,包括注解绑定sql和xml绑定Sql
2.动态sql由原来的节点配置变成OGNL表达式
3.在一对一,一对多的时候引进了association,在一对多的时候引入了collection 节点,不过都是在 resultMap 里面配置
35、IBatis 和 MyBatis 在核心处理类分别叫什么
IBatis 里面的核心处理类叫SqlMapClient,MyBatis 里面的核心处理类叫做SqlSession。
36、IBatis 和 MyBatis 在细节上的不同有哪些
1. 在 sql 里面变量命名有原来的#变量#变成了#{变量}
2.原来的 变量 变量 变量变成了${变量}
3. 原来在 sql 节点里面的 class 都换名字叫 type
4.原来的queryForObjectqueryForList变成了selectOneselectList5)原来的别名设置在映射文件里面放在了核心配置文件里
Netty篇
1.BIO、NIO 和 AIO 的区别?
BIO:一个连接一个线程,客户端有连接请求时服务器端就需要启动一个线程进行处理。线程开销大。
**伪异步 IO:**将请求连接放入线程池,一对多,但线程还是很宝贵的资源。
**NIO:**一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 I/O 请求时才启动一个线程进行处理。
**AIO:**一个有效请求一个线程,客户端的 I/O 请求都是由 OS 先完成了再通知服务器应用去启动线程进行处理。
- BIO 是面向流的,NIO 是面向缓冲区的;
- BIO 的各种流是阻塞的。而 NIO 是非阻塞的;
- BIO 的 Stream 是单向的,而 NIO 的 channel 是双向的。
NIO 的特点:事件驱动模型、单线程处理多任务、非阻塞 I/O,I/O 读写不再阻塞,而是返回 0、基于 block 的传输比基于流的传输更高效、更高级的 IO 函数 zero-copy、IO 多路复用大大提高了 Java 网络应用的可伸缩性和实用性。基于 Reactor 线程模型。
在 Reactor 模式中,事件分发器等待某个事件或者可应用或个操作的状态发生,事件分发器 就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。如在 Reactor 中实现读:注册读就绪事件和相应的事件处理器、事件分发器等待事件、事件到 来,激活分发器,分发器调用事件对应的处理器、事件处理器完成实际的读操作,处理读到 的数据,注册新的事件,然后返还控制权。
2.NIO 的组成
**Buffer:**与Channel进行交互,数据是从Channel读入缓冲区,从缓冲区写入Channel中的flip方法:反转此缓冲区,将position给limit,然后将position置为0,其实就是切换读写模式
**clear方法:**清除此缓冲区,将position置为0,把capacity的值给limit。
**rewind方法:**重绕此缓冲区,将position置为0
DirectByteBuffer可减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,不可控,通常会用内存池来提高性能。直接缓冲区主要分配给那些易受基础系统的本机I/O操作影响的大型、持久的缓冲区。如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer,由JVM进行管理。
Channel:表示IO源与目标打开的连接,是双向的,但不能直接访问数据,只能与Buffer进行交互。通过源码可知,FileChannel的read方法和write方法都导致数据复制了两次!
**Selector:**可使一个单独的线程管理多个Channel,open方法可创建Selector,register方法向多路复用器器注册通道,可以监听的事件类型:读、写、连接、accept。注册事件后会产生一个SelectionKey:它表示SelectableChannel和Selector之间的注册关系,wakeup方法:使尚未返回的第一个选择操作立即返回,唤醒的原因是:注册了新的channel或者事件;channel关闭,取消注册;优先级更高的事件触发(如定时器事件),希望及时处理。
Selector在Linux的实现类是EPollSelectorImpl,委托给EPollArrayWrapper实现,其中三个native方法是对epoll的封装,而EPollSelectorImpl.implRegister方法,通过调用epoll_ctl向epoll实例中注册事件,还将注册的文件描述符(fd)与SelectionKey的对应关系添加到fdToKey中,这个map维护了文件描述符与SelectionKey的映射。
fdToKey有时会变得非常大,因为注册到Selector上的Channel非常多(百万连接);过期或失效的Channel没有及时关闭。fdToKey总是串行读取的,而读取是在select方法中进行的,该方法是非线程安全的。
Pipe:两个线程之间的单向数据连接,数据会被写到sink通道,从source通道读取NIO的服务端建立过程:Selector.open():打开一个Selector;ServerSocketChannel.open():创建服务端的Channel;bind():绑定到某个端口上。并配置非阻塞模式;register():注册Channel和关注的事件到Selector上;select()轮询拿到已经就绪的事件.
3.Netty的特点?
一个高性能、异步事件驱动的NIO框架,它提供了对TCP、UDP和文件传输的支持,使用更高效的socket底层,对epoll空轮询引起的cpu占用飙升在内部进行了处理,避免了直接使用NIO的陷阱,简化了NIO的处理方式。 采用多种decoder/encoder支持,对TCP粘包/分包进行自动化处理 可使用接受/处理线程池,提高连接效率,对重连、心跳检测的简单支持 可配置IO线程数、TCP参数,TCP接收和发送缓冲区使用直接内存代替堆内存,通过内存池的方式循环利用ByteBuf 通过引用计数器及时申请释放不再引用的对象,降低了GC频率 使用单线程串行化的方式,高效的Reactor线程模型 大量使用了volitale、使用了CAS和原子类、线程安全类的使用、读写锁的使用
4.Netty的线程模型?
Netty通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss 线程池和work线程池,其中boss线程池的线程负责处理请求的accept事件,当接收到accept 事件的请求时,把对应的socket封装到一个NioSocketChannel中,并交给work线程池,其中work线程池负责请求的read和write事件,由对应的Handler处理。
**单线程模型:**所有I/O操作都由一个线程完成,即多路复用、事件分发和处理都是在一个Reactor线程上完成的。既要接收客户端的连接请求,向服务端发起连接,又要发送/读取请求或应答/响应消息。一个NIO线程同时处理成百上千的链路,性能上无法支撑,速度慢,若线程进入死循环,整个程序不可用,对于高负载、大并发的应用场景不合适。
**多线程模型:**有一个NIO线程(Acceptor)只负责监听服务端,接收客户端的TCP连接请求;NIO线程池负责网络IO的操作,即消息的读取、解码、编码和发送;1个NIO线程可以同时处理N条链路,但是1个链路只对应1个NIO线程,这是为了防止发生并发操作问题。但在并发百万客户端连接或需要安全认证时,一个Acceptor线程可能会存在性能不足问题。
**主从多线程模型:**Acceptor线程用于绑定监听端口,接收客户端连接,将SocketChannel从主线程池的Reactor线程的多路复用器上移除,重新注册到Sub线程池的线程上,用于处理I/O的读写等操作,从而保证mainReactor只负责接入认证、握手等操作;
5.TCP粘包/拆包的原因及解决方法?
TCP是以流的方式来处理数据,一个完整的包可能会被TCP拆分成多个包进行发送,也可能把小的封装成一个大的数据包发送。
TCP粘包/分包的原因:
应用程序写入的字节大小大于套接字发送缓冲区的大小,会发生拆包现象,而应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包现象;进行MSS大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包 以太网帧的payload(净荷)大于MTU(1500字节)进行ip分片。
解决方法:
消息定长:FixedLengthFrameDecoder类包尾增加特殊字符分割:行分隔符类:LineBasedFrameDecoder或自定义分隔符类:
DelimiterBasedFrameDecoder 将消息分为消息头和消息体:LengthFieldBasedFrameDecoder类。分为有头部的拆包与粘包、长度字段在前且有头部的拆包与粘包、多扩展头部的拆包与粘包。
6.了解哪几种序列化协议?
序列化(编码)是将对象序列化为二进制形式(字节数组),主要用于网络传输、数据持久化等;而反序列化(解码)则是将从网络、磁盘等读取的字节数组还原成原始对象,主要用于网络传输对象的解码,以便完成远程调用。
影响序列化性能的关键因素:序列化后的码流大小(网络带宽的占用)、序列化的性能(CPU 资源占用);是否支持跨语言(异构系统的对接和开发语言切换)。
Java默认提供的序列化:无法跨语言、序列化后的码流太大、序列化的性能差
XML
优点:人机可读性好,可指定元素或特性的名称。缺点:序列化数据只包含数据本身以及类的结构,不包括类型标识和程序集信息;只能序列化公共属性和字段;不能序列化方法;文件庞大,文件格式复杂,传输占带宽。适用场景:当做配置文件存储数据,实时数据转换。
JSON
是一种轻量级的数据交换格式,优点:兼容性高、数据格式比较简单,易于读写、序列化后数据较小,可扩展性好,兼容性好、与XML相比,其协议比较简单,解析速度比较快。缺点:数据的描述性比XML差、不适合性能要求为ms级别的情况、额外空间开销比较大。适用场景(可替代XML):跨防火墙访问、可调式性要求高、基于Webbrowser的Ajax请求、传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
Fastjson
采用一种“假定有序快速匹配”的算法。优点:接口简单易用、目前java语言中最快的json库。
缺点:过于注重快,而偏离了“标准”及功能性、代码质量不高,文档不全。适用场景:协议交互、Web输出、Android客户端
Thrift
不仅是序列化协议,还是一个RPC框架。优点:序列化后的体积小,速度快、支持多种语言和丰富的数据类型、对于数据字段的增删具有较强的兼容性、支持二进制压缩编码。
缺点:使用者较少、跨防火墙访问时,不安全、不具有可读性,调试代码时相对困难、不能与其他传输层协议共同使用(例如HTTP)、无法支持向持久层直接读写数据,即不适合做数据持久化序列化协议。适用场景:分布式系统的RPC解决方案
Avro
Hadoop的一个子项目,解决了JSON的冗长和没有IDL的问题。
优点:支持丰富的数据类型、简单的动态语言结合功能、具有自我描述属性、提高了数据解析速度、快速可压缩的二进制数据形式、可以实现远程过程调用RPC、支持跨编程语言实现。
缺点:对于习惯于静态类型语言的用户不直观。适用场景:在Hadoop中做Hive、Pig和MapReduce的持久化数据格式。
Protobuf
将数据结构以.proto文件进行描述,通过代码生成工具可以生成对应数据结构的 POJO对象和Protobuf相关的方法和属性。
优点:序列化后码流小,性能高、结构化数据存储格式(XMLJSON等)、通过标识字段的顺序,可以实现协议的前向兼容、结构化的文档更容易管理和维护。
缺点:需要依赖于工具生成代码、支持的语言相对较少,官方只支持Java、C++、python。适用场景:对性能要求高的RPC调用、具有良好的跨防火墙的访问属性、适合应用层对象的持久化
protostuff
基于protobuf协议,但不需要配置proto文件,直接导包即可
Jbossmarshaling
可以直接序列化java类,无须实java.io.Serializable接口
Messagepack
一个高效的二进制序列化格式
Hessian
采用二进制协议的轻量级remotingonhttp工具
kryo
基于protobuf协议,只支持java语言,需要注册(Registration),然后序列化(Output),反序列化(Input)
7.如何选择序列化协议?
具体场景
- 对于公司间的系统调用,如果性能要求在100ms以上的服务,基于XML的SOAP协议是一个值得考虑的方案。
- 基于Webbrowser的Ajax,以及Mobileapp与服务端之间的通讯,JSON协议是首选。对于性能要求不太高,或者以动态类型语言为主,或者传输数据载荷很小的的运用场景,JSON 也是非常不错的选择。
- 对于调试环境比较恶劣的场景,采用JSON或XML能够极大的提高调试效率,降低系统开发成本。
- 当对性能和简洁性有极高要求的场景,Protobuf,Thrift,Avro之间具有一定的竞争关系。对于T级别的数据的持久化应用场景,Protobuf和Avro是首要选择。如果持久化后的数据存储在hadoop子项目里,Avro会是更好的选择。
- 对于持久层非Hadoop项目,以静态类型语言为主的应用场景,Protobuf会更符合静态类型语言工程师的开发习惯。由于Avro的设计理念偏向于动态类型语言,对于动态语言为主的应用场景,Avro是更好的选择。
- 如果需要提供一个完整的RPC解决方案,Thrift是一个好的选择。
- 如果序列化之后需要支持不同的传输层协议,或者需要跨防火墙访问的高性能场景,Protobuf可以优先考虑。protobuf的数据类型有多种:bool、double、float、int32、int64、string、bytes、enum、message。
**protobuf的限定符:**required:必须赋值,不能为空、optional:字段可以赋值,也可以不赋值、
repeated:该字段可以重复任意次数(包括0次)、枚举;只能用指定的常量集中的一个值作为其值;
**protobuf的基本规则:**每个消息中必须至少留有一个required类型的字段、包含0个或多个optional类型的字段;repeated表示的字段可以包含0个或多个数据;[1,15]之内的标识号在编码的时候会占用一个字节(常用),[16,2047]之内的标识号则占用2个字节,标识号一定不能重复、使用消息类型,也可以将消息嵌套任意多层,可用嵌套消息类型来代替组。
protobuf的消息升级原则:不要更改任何已有的字段的数值标识;不能移除已经存在的required字段,optional和repeated类型的字段可以被移除,但要保留标号不能被重用。新添加的字段必须是optional或repeated。因为旧版本程序无法读取或写入新增的required限定符的字段。编译器为每一个消息类型生成了一个.java文件,以及一个特殊的Builder类(该类是用来创建消息类接口的)
如:UserProto.User.Builder builder =UserProto.User.newBuilder();builder.build();
**Netty中的使用:**ProtobufVarint32FrameDecoder是用于处理半包消息的解码类;
ProtobufDecoder(UserProto.User.getDefaultInstance())这是创建的UserProto.java文件中的解码类;ProtobufVarint32LengthFieldPrepender对protobuf协议的消息头上加上一个长度为32 的整形字段,用于标志这个消息的长度的类;ProtobufEncoder是编码类将StringBuilder转换为ByteBuf类型:copiedBuffer()方法
8.Netty的零拷贝实现?
Netty的接收和发送ByteBuffer采用DIRECTBUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。堆内存多了一次内存拷贝,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才写入Socket中ByteBuffer由ChannelConfig分配,由ChannelConfig创建ByteBufAllocator默认使用DirectBufferCompositeByteBuf类可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了传统通过内存拷贝的方式将几个小Buffer合并成一个大的Buffer。
addComponents方法将header与body合并为一个逻辑上的ByteBuf,这两个ByteBuf在CompositeByteBuf内部都是单独存在的,CompositeByteBuf只是逻辑上是一个整体通过FileRegion包装的FileChannel.tranferTo方法实现文件传输,可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题。
通过wrap方法,我们可以将byte[]数组、ByteBuf、ByteBuffer等包装成一个NettyByteBuf对象,进而避免了拷贝操作。
**SelectorBUG:**若Selector的轮询结果为空,也没有wakeup或新消息处理,则发生空轮询,
CPU使用率100%,
**Netty的解决办法:**对Selector的select操作周期进行统计,每完成一次空的select操作进行一次计数,若在某个周期内连续发生N次空轮询,则触发了epoll死循环bug。重建Selector,判断是否是其他线程发起的重建请求,若不是则将原SocketChannel从旧的Selector上去除注册,重新注册到新的Selector上,并将原来的Selector关闭。
9.Netty的高性能表现在哪些方面?
心跳,对服务端:会定时清除闲置会话inactive(netty5),
对客户端:用来检测会话是否断开,是否重来,检测网络延迟,其中idleStateHandler类用来检测会话状态串行无锁化设计,即消息的处理尽可能在同一个线程内完成,期间不进行线程切换,这样就避免了多线程竞争和同步锁。表面上看,串行化设计似乎CPU利用率不高,并发程度不够。
但是,通过调整NIO线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列-多个工作线程模型性能更优。可靠性,链路有效性检测:链路空闲检测机制读/写空闲超时机制;内存保护机制:通过内存池重用ByteBuf;ByteBuf的解码保护;优雅停机:不再接收新消息、退出前的预处理操作、资源的释放操作。
Netty安全性:支持的安全协议:SSLV2和V3,TLS,SSL单向认证、双向认证和第三方CA认证。
高效并发编程的体现:volatile的大量、正确使用;CAS和原子类的广泛使用;线程安全容器的使用;通过读写锁提升并发性能。IO通信性能三原则:传输(AIO)、协议(Http)、线程(主从多线程)
流量整型的作用(变压器):防止由于上下游网元性能不均衡导致下游网元被压垮,业务流中断;防止由于通信模块接受消息过快,后端业务线程处理不及时导致撑死问题。
TCP参数配置:SO_RCVBUF和SO_SNDBUF:通常建议值为128K或者256K;
SO_TCPNODELAY:NAGLE算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算法;
10.NIOEventLoopGroup源码?
NioEventLoopGroup(其实是MultithreadEventExecutorGroup)内部维护一个类型为EventExecutorchildren[],默认大小是处理器核数*2,
这样就构成了一个线程池,初始化EventExecutor时NioEventLoopGroup重载newChild方法,所以children元素的实际类型为NioEventLoop。
- 线程启动时调用SingleThreadEventExecutor的构造方法,执行NioEventLoop类的run方法,首先会调用hasTasks()方法判断当前taskQueue是否有元素。如果taskQueue中有元素,执行selectNow()方法,最终执行selector.selectNow(),该方法会立即返回。如果taskQueue 没有元素,执行select(oldWakenUp)方法
- select(oldWakenUp)方法解决了Nio中的bug,selectCnt用来记录selector.select方法的执行次数和标识是否执行selector.selectNow(),若触发了epoll的空轮询bug,则会反复执行selector.select(timeoutMillis),变量selectCnt会逐渐变大,当selectCnt达到阈值(默认512),则执行rebuildSelector方法,进行selector重建,解决cpu占用100%的bug。
- rebuildSelector方法先通过openSelector方法创建一个新的selector。然后将oldselector的selectionKey执行cancel。最后将oldselector的channel重新注册到新的selector中。rebuild 后,需要重新执行方法selectNow,检查是否有已ready的selectionKey。
- 接下来调用processSelectedKeys方法(处理I/O任务),当selectedKeys!=null时,调用processSelectedKeysOptimized方法,迭代selectedKeys获取就绪的IO事件的selectkey存放在数组selectedKeys中,然后为每个事件都调用processSelectedKey来处理它,processSelectedKey中分别处理OP_READ;OP_WRITE;OP_CONNECT事件。
- 最后调用runAllTasks方法(非IO任务),该方法首先会调用fetchFromScheduledTaskQueue 方法,把scheduledTaskQueue中已经超过延迟执行时间的任务移到taskQueue中等待被执行,然后依次从taskQueue中取任务执行,每执行64个任务,进行耗时检查,如果已执行时间超过预先设定的执行时间,则停止执行非IO任务,避免非IO任务太多,影响IO任务的执行。
每个NioEventLoop对应一个线程和一个Selector,NioServerSocketChannel会主动注册到某一个NioEventLoop的Selector上,NioEventLoop负责事件轮询。
Outbound事件都是请求事件,发起者是Channel,处理者是unsafe,通过Outbound事件进行通知,传播方向是tail到head。Inbound事件发起者是unsafe,事件的处理者是Channel,是通知事件,传播方向是从头到尾。
内存管理机制,首先会预申请一大块内存Arena,Arena由许多Chunk组成,而每个Chunk默认由2048个page组成。Chunk通过AVL树的形式组织Page,每个叶子节点表示一个Page,而中间节点表示内存区域,节点自己记录它在整个Arena中的偏移地址。当区域被分配出去后,中间节点上的标记位会被标记,这样就表示这个中间节点以下的所有节点都已被分配了。大于8k的内存分配在poolChunkList中,而PoolSubpage用于分配小于8k的内存,它会把一个page分割成多段,进行内存分配。
**ByteBuf的特点:**支持自动扩容(4M),保证put方法不会抛出异常、通过内置的复合缓冲类型,实现零拷贝(zero-copy);不需要调用flip()来切换读/写模式,读取和写入索引分开;方法链;引用计数基于AtomicIntegerFieldUpdater用于内存回收;PooledByteBuf采用二叉树来实现一个内存池,集中管理内存的分配和释放,不用每次使用都新建一个缓冲区对象。UnpooledHeapByteBuf每次都会新建一个缓冲区对象。
并发编程面试合辑 word文档下载地址:链接:https://pan.baidu.com/s/1nwlBO2tYXDDl7OjGhs4e4Q
提取码:1111爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
微服务面试合辑
Spring Boot篇
1、什么是 Spring Boot
多年来,随着新功能的增加,spring 变得越来越复杂。只需访问https://spring.io/projects 页面,我们就会看到可以在我们的应用程序中使用的所有 Spring 项目的不同功能。如果必须启动一个新的 Spring 项目, 我们必须添加构建路径或添加 Maven 依赖关系,配置应用程序服务器, 添加 spring 配置。因此,开始一个新的 spring 项目需要很多努力,因为我们现在必须从头开始做所有事情。
Spring Boot 是解决这个问题的方法。Spring Boot 已经建立在现有 spring 框架之上。使用spring 启动,我们避免了之前我们必须做的所有样板代码和配置。因此,Spring Boot可以帮助我们以最少的工作量,更加健壮地使用现有的 Spring 功能。
2、Spring Boot 有哪些优点
Spring Boot 的优点有:
减少开发,测试时间和努力。
使用 JavaConfig 有助于避免使用 XML。避免大量的 Maven 导入和各种版本冲突。提供意见发展方法。
通过提供默认值快速开始开发。
没有单独的 Web 服务器需要。这意味着你不再需要启动 Tomcat,Glassfish 或其他任何东西。需要更少的配置因为没有 web.xml 文件。只需添加用@ Configuration 注释的类,然后添加用@Bean 注释的方法,Spring 将自动加载对象并像以前一样对其进行管理。您甚至可以将@Autowired 添加到 bean 方法中, 以使 Spring 自动装入需要的依赖关系中。基于环境的配置使用这些属性,您可以将您正在使用的环境传递到应用程序:- Dspring.profiles.active ={enviornment}。在加载主应用程序属性文件后,Spring 将在(application{environment} .properties)中加载后续的应用程序属性文件。
3、什么是 JavaConfig
Spring JavaConfig是Spring社区的产品,它提供了配置Spring IoC容器的纯Java方法。因此它有助于避免使用 XML 配置。使用 JavaConfig 的优点在于:
面向对象的配置。由于配置被定义为 JavaConfig 中的类,因此用户可以充分利用 Java 中的面向对象功能。一个配置类可以继承另一个,重写它的@Bean 方法等。
减少或消除 XML 配置。基于依赖注入原则的外化配置的好处已被证明。但是,许多开发人员不希望在 XML 和 Java 之间来回切换。JavaConfig 为开发人员提供了一种纯 Java 方法来配置与 XML 配置概念相似的 Spring 容器。从技术角度来讲,只使用 JavaConfig 配置类来配置容器是可行的,但实际上很多人认为将 JavaConfig 与 XML 混合匹配是理想的。类型安全和重构友好。JavaConfig 提供了一种类型安全的方法来配置 Spring 容器。由于 Java 5.0 对泛型的支持,现在可以按类型而不是按名称检索bean,不需要任何强制转换或 基于字符串的查找。
4、如何重新加载 Spring Boot 上的更改而无需重新启动服务器
这可以使用 DEV 工具来实现。通过这种依赖关系,您可以节省任何更改,嵌入式 tomcat 将重新启动。Spring Boot 有一个开发工具(DevTools)模块,它有助于提高开发人员的生 产力。Java 开发人员面临的一个主要挑战是将文件更改自动部署到服务器并自动重启服务器。开发人员可以重新加载Spring Boot上的更改,而无需重新启动服务器。这将消除每次手动部署更改的需要。Spring Boot 在发布它的第一个版本时没有这个功能。这是开发人员最需要的功能。DevTools 模块完全满足开发人员的需求。该模块将在生产环境中被禁用。它还提供 H2 数据库控制台以更好地测试应用程序。
org.springframework.boot spring-boot-devtools true
5、Spring Boot 中的监视器是什么
Spring boot actuator是spring启动框架中的重要功能之一。Spring boot监视器可帮助您访问生产环境中正在运行的应用程序的当前状态。有几个指标必须在生产环境中进行检查和监控。即使一些外部应用程序可能正在使用这些服务来向相关人员触发警报消息。监视器模块公开了一组可直接作为 HTTP URL 访问的 REST 端点来检查状态。
6、如何在 Spring Boot 中禁用 Actuator 端点安全性
默认情况下,所有敏感的 HTTP 端点都是安全的,只有具有 ACTUATOR 角色的用户才能访问它们。安全性是使用标准的HttpServletRequest.isUserInRole 方法实施的。我们可以使用management.security.enabled = false来禁用安全性。只有在执行机构端点在防火墙后访问时,才建议禁用安全性。
7、如何在自定义端口上运行 Spring Boot 应用程序
为了在自定义端口上运行Spring Boot 应用程序,您可以在application.properties 中指定端口。server.port = 8090
8、什么是 YAML
YAML 是一种人类可读的数据序列化语言。它通常用于配置文件。与属性文件相比,如果我们想要在配置文件中添加复杂的属性,YAML 文件就更加结构化,而且更少混淆。可以看出 YAML 具有分层配置数据。
9、如何实现 Spring Boot 应用程序的安全性
为了实现Spring Boot的安全性,我们使用 spring-boot-starter-security依赖项,并且必须添加安全配置。它只需要很少的代码。配置类将必须扩展WebSecurityConfigurerAdapter 并覆 盖其方法。
10、如何集成 Spring Boot 和 ActiveMQ
对于集成Spring Boot和ActiveMQ,我们使用spring-boot-starter-activemq
依赖关系。它只需要很少的配置,并且不需要样板代码。
11、如何使用 Spring Boot 实现分页和排序
使用 Spring Boot 实现分页非常简单。使用 Spring Data-JPA 可以实现将可分页的 org.springframework.data.domain.Pageable传递给存储库方法。
12、什么是 Swagger你用 Spring Boot 实现了它吗
Swagger 广泛用于可视化 API,使用 Swagger UI 为前端开发人员提供在线沙箱。Swagger 是用于生成 RESTful Web 服务的可视化表示的工具,规范和完整框架实现。它使文档能够以与服务器相同的速度更新。当通过Swagger 正确定义时,消费者可以使用最少量的实现逻 辑来理解远程服务并与其进行交互。因此,Swagger 消除了调用服务时的猜测。
13、什么是 Spring Profiles
Spring Profiles 允许用户根据配置文件(dev,test,prod 等)来注册 bean。因此,当应用程序在开发中运行时,只有某些 bean 可以加载,而在PRODUCTION 中,某些其他 bean 可以加载。假设我们的要求是Swagger 文档仅适用于 QA 环境,并且禁用所有其他文档。这可以使用配置文件来完成。Spring Boot 使得使用配置文件非常简单。
14、什么是 Spring Batch
Spring Boot Batch提供可重用的函数,这些函数在处理大量记录时非常重要,包括日志/跟 踪,事务管理,作业处理统计信息,作业重新启动,跳过和资源管理。它还提供了更先进的技术服务和功能,通过优化和分区技术,可以实现极高批量和高性能批处理作业。简单以及复杂的大批量批处理作业可以高度可扩展的方式利用框架处理重要大量的信息。
15、什么是 FreeMarker 模板
FreeMarker 是一个基于 Java 的模板引擎,最初专注于使用 MVC 软件架构进行动态网页生成。使用 Freemarker 的主要优点是表示层和业务层的完全分离。程序员可以处理应用程序代码,而设计人员可以处理 html 页面设计。最后使用 freemarker 可以将这些结合起来,给出最终的输出页面。
16、如何使用 Spring Boot 实现异常处理
Spring提供了一种使用ControllerAdvice处理异常的非常有用的方法。我们通过实现一个 ControlerAdvice 类,来处理控制器类抛出的所有异常。
17、您使用了哪些 starter maven 依赖项
使用了下面的一些依赖项
spring-boot-starter-activemq spring-boot-starter-security
spring-boot-starter-web 这有助于增加更少的依赖关系,并减少版本的冲突。
18、什么是 CSRF 攻击
CSRF 代表跨站请求伪造。这是一种攻击,迫使最终用户在当前通过身份验证的 Web 应用程序上执行不需要的操作。CSRF 攻击专门针对状态改变请求,而不是数据窃取,因为攻击者无法查看对伪造请求的响应。
19、什么是 WebSockets
WebSocket 是一种计算机通信协议,通过单个 TCP 连接提供全双工通信信道。
WebSocket 是双向的-使用 WebSocket 客户端或服务器可以发起消息发送。
WebSocket 是全双工的 -客户端和服务器通信是相互独立的。
单个TCP连接 -初始连接使用HTTP,然后将此连接升级到基于套接字的连接。然后这个单一连接用于所有未来的通信Light -与 http 相比,WebSocket 消息数据交换要轻得多。
20、什么是 AOP
在软件开发过程中,跨越应用程序多个点的功能称为交叉问题。这些交叉问题与应用程序的主要业务逻辑不同。因此,将这些横切关注与业务逻辑分开是面向方面编程(AOP)的 地方。
21、什么是 Apache Kafka
Apache Kafka 是一个分布式发布-订阅消息系统。它是一个可扩展的,容错的发布-订阅消息系统,它使我们能够构建分布式应用程序。这是一个Apache 顶级项目。Kafka 适合离线和在线消息消费。
22、我们如何监视所有 Spring Boot 微服务
Spring Boot 提供监视器端点以监控各个微服务的度量。这些端点对于获取有关应用程序的信息(如它们是否已启动)以及它们的组件(如数据库等)是否正常运行很有帮助。但是,使用监视器的一个主要缺点或困难是,我们必须单独打开应用程序的知识点以了解其状态或健康状况。想象一下涉及50 个应用程序的微服务,管理员将不得不击中所有 50 个应用程序的执行终端。
Dubbo篇
1、Dubbo 中 zookeeper 做注册中心如果注册中心集群都挂掉发布者和订阅者之间还能通信么
可以通信的,启动 dubbo 时,消费者会从 zk 拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用; 注册中心对等集群,任意一台宕机后,将会切换到另一台;注册中心全部宕机后,服务的提供者和消费者仍能通过本地缓存通讯。服务提供者无状态, 任一台宕机后,不影响使用;服务提供者全部宕机,服务消费者会无法使 用,并无限次重连等待服务者恢复; 挂掉是不要紧的,但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的。

2、dubbo 服务负载均衡策略
l Random LoadBalance
随机,按权重设置随机概率。在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比 较均匀,有利于动态调整提供者权重。(权重可以在 dubbo 管控台配置)
l RoundRobin LoadBalance
轮循,按公约后的权重设置轮循比率。存在慢的提供者累积请求问题,比如:第二台机器很慢,但没挂,当请求调
到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
l LeastActive LoadBalance
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。使慢的提供者收到更少请求,因为越慢的提供者的
调用前后计数差会越大。
l ConsistentHash LoadBalance
一致性 Hash,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。缺省只对第一个参数 Hash,如果要修改,请配置
3、 Dubbo 在安全机制方面是如何解决的
Dubbo 通过 Token 令牌防止用户绕过注册中心直连,然后在注册中心上管理授权。Dubbo 还提供服务黑白名单,来控制服务所允许的调用方。
4、dubbo 连接注册中心和直连的区别
在开发及测试环境下,经常需要绕过注册中心,只测试指定服务提供者, 这时候可能需要点对点直连,点对点直联方式,将以服务接口为单位,忽略注册中心的提供者列表,l Failsafe Cluster失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
[AppleScript] 纯文本查看复制代码
服务注册中心,动态的注册和发现服务,使服务的位置透明,并通过在消费方获取服务提供方地址列表,实现软负载均衡和 Failover
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推 送变更数据给消费者。服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者
注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外,注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
5. dubbo 服务集群配置(集群容错模式)
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。可以自行扩展集群容错策略 l Failover Cluster(默认)
失败自动切换,当出现失败,重试其它服务器。(缺省)通常用于读操作, 但重试会带来更长延迟。可通过 retries="2"来设置重试次数(不含第一次)。
cluster="failover"可以不用写,因为默认就是failover
l Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
dubbo:service cluster="failfast" />
或:
cluster="failfast"和把 cluster=“failover”、retries="0"是—样的效果,retries="0"就是不重试
l FailsafeCluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
l Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
l Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2"来设置最大并行数
配置:
服务端服务级别
- Eureka:服务注册中心
- Feign:服务调用
- Ribbon:负载均衡
- Zuul/Spring Cloud Gatway:网关
这么多的系统,电商系统包含了20个子系统,每个子系统有20个核心接口,一共电商系统有400个接口,这么多的接口,直接对外暴露,前后端分离的架构,难道你让前端的同学必须记住你的20个系统的部署的机器,他们去做负载均衡,记住400个接口微服务那块,网关
灰度发布、统一熔断、统一降级、统一缓存、统一限流、统一授权认证
Hystrix、链路追踪、stream、很多组件,Hystrix这块东西,其实是会放在高可用的环节去说的,并不是说一个普通系统刚开始就必须得用的,没有用好的话,反而会出问题,Hystrix线路熔断的框架,必须得设计对应的一整套的限流方案、熔断方案、资源隔离、降级机制,配合降级机制来做
2、Spring Cloud 组件原理
eureka 原理图
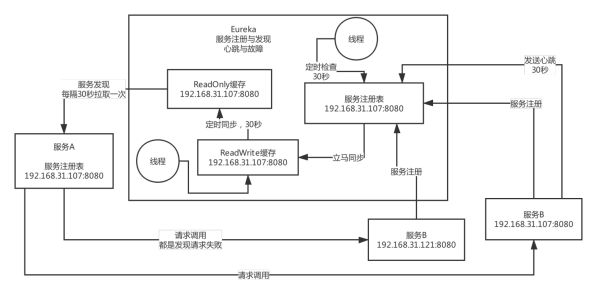
Eureka 缓存的设计目的
优化并发 并发冲突,如果操作服务注册表,读时加锁防止写,写时加锁不能读,效率降低。
Feign 原理
在配置类上,加上@EnableFeginClients,那么该注解是基于@Import注解,注册有关Fegin的解析注册类,这个类是实现 ImportBeanDefinitionRegistrar 这个接口,重写registryBeanDefinition 方法。他会扫描所有加了@FeginClient 的接口,然后针对这个注解的接口生成动态代理,然后你针对fegin的动态代理去调用他方法的时候,此时会在底层生成http协议格式的请求。
Ribbo 原理
底层的话,使用HTTP通信的框架组件,HttpClient,先得使用Ribbon去本地的Eureka注册表的缓存里获取出来对方机器的列表,然后进行负载均衡,选出一台机器,接着针对那台机器发送 Http请求过去即可
Zuul 原理
配置一下不同的请求路径和服务的对应关系,你的请求到了网关,他直接查找到匹配的服务,然后就直接把请求转发给服务的某台机器,Ribbon从Eureka本地的缓存列表里获取一台机器,负载均衡,把请求直接用HTTP通信扩建发送到指定机器上去。
3、Spring Cloud 和 Dubbo 的区别
Dubbo,RPC的性能比HTTP的性能更好,并发能力更强,经过深度优化的RPC服务框架,性能和并发能力是更好一些
很多中小型公司而言,其实稍微好一点的性能,Dubbo一次请求10ms,Spring Cloud耗费20ms,对很多中小型公司而言,性能、并发,并不是最主要的因素
Spring Cloud这套架构原理,走HTTP接口和HTTP请求,就足够满足性能和并发的需要了,没必要使用高度优化的RPC服务框架
Dubbo之前的一个定位,就是一个单纯的服务框架而已,不提供任何其他的功能,配合的网关还得选择其他的一些技术
Spring Cloud,中小型公司用的特别多,老系统从Dubbo迁移到Spring Cloud,新系统都是用Spring Cloud来进行开发,全家桶,主打的是微服务架构里,组件齐全,功能齐全。网关直接提供了,分布式配置中心,授权认证,服务调用链路追踪,Hystrix可以做服务的资源隔离、熔断降级、服务请求QPS监控、契约测试、消息中间件封装、ZK封装
胜是胜在功能齐全,中小型公司开箱即用,直接满足系统的开发需求
Spring Cloud原来支持的一些技术慢慢的未来会演变为,跟阿里技术体系进行融合,Spring Cloud Alibaba,阿里技术会融入Spring Cloud里面去
4、你们的服务注册中心进行过选型调研吗?对比一下各种服务注册中心!
Eureka、ZooKeeper
Dubbo作为服务框架的,一般注册中心会选择zk
Spring Cloud作为服务框架的,一般服务注册中心会选择Eureka
(1)服务注册发现的原理
集群模式
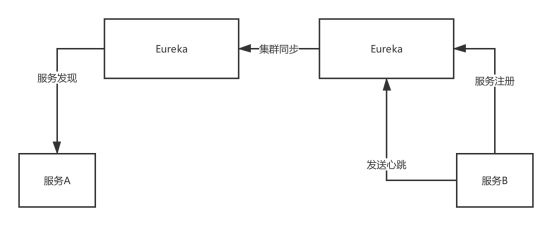
Eureka,peer-to-peer,部署一个集群,但是集群里每个机器的地位是对等的,各个服务可以向任何一个Eureka实例服务注册和服务发现,集群里任何一个Euerka实例接收到写请求之后,会自动同步给其他所有的Eureka实例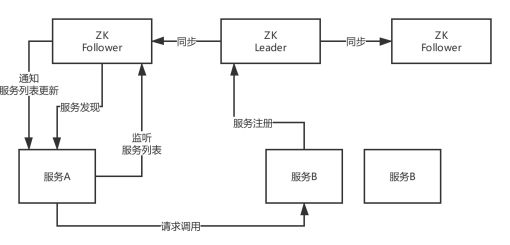
ZooKeeper,服务注册和发现的原理,Leader + Follower两种角色,只有Leader可以负责写也就是服务注册,他可以把数据同步给Follower,读的时候leader/follower都可以读
(2)一致性保障:CP or AP
CAP,C是一致性,A是可用性,P是分区容错性
CP,AP
ZooKeeper是有一个leader节点会接收数据, 然后同步写其他节点,一旦leader挂了,要重新选举leader,这个过程里为了保证C,就牺牲了A,不可用一段时间,但是一个leader选举好了,那么就可以继续写数据了,保证一致性
Eureka是peer模式,可能还没同步数据过去,结果自己就死了,此时还是可以继续从别的机器上拉取注册表,但是看到的就不是最新的数据了,但是保证了可用性,强一致,最终一致性
(3)服务注册发现的时效性
zk,时效性更好,注册或者是挂了,一般秒级就能感知到
eureka,默认配置非常糟糕,服务发现感知要到几十秒,甚至分钟级别,上线一个新的服务实例,到其他人可以发现他,极端情况下,可能要1分钟的时间,ribbon去获取每个服务上缓存的eureka的注册表进行负载均衡
服务故障,隔60秒才去检查心跳,发现这个服务上一次心跳是在60秒之前,隔60秒去检查心跳,超过90秒没有心跳,才会认为他死了,2分钟都过去
30秒,才会更新缓存,30秒,其他服务才会来拉取最新的注册表
三分钟都过去了,如果你的服务实例挂掉了,此时别人感知到,可能要两三分钟的时间,一两分钟的时间,很漫长
(4)容量
zk,不适合大规模的服务实例,因为服务上下线的时候,需要瞬间推送数据通知到所有的其他服务实例,所以一旦服务规模太大,到了几千个服务实例的时候,会导致网络带宽被大量占用
eureka,也很难支撑大规模的服务实例,因为每个eureka实例都要接受所有的请求,实例多了压力太大,扛不住,也很难到几千服务实例
之前dubbo技术体系都是用zk当注册中心,spring cloud技术体系都是用eureka当注册中心这两种是运用最广泛的,但是现在很多中小型公司以spring cloud居多,所以后面基于eureka说一下服务注册中心的生产优化
5、画图阐述一下你们的服务注册中心部署架构,生产环境下怎么保证高可用?

6、你们系统遇到过服务发现过慢的问题吗?怎么优化和解决的?
zk,一般来说还好,服务注册和发现,都是很快的
eureka,必须优化参数
·服务器到注册中心心跳时间设置
·注册中心定时检测心跳时间设置
·心跳失效时间设置
·readWrite缓存定更新到readOnly时间设置
·客户端定时拉取readWrite缓存时间设置
服务发现的时效性变成秒级,几秒钟可以感知服务的上线和下线
7、说一下自己公司的服务注册中心怎么技术选型的?生产环境中应该怎么优化?
l可用性
l时效性
l数据一致性 CP AP
l容量
通过集群保证可用性
8、你们对网关的技术选型是怎么考虑的?能对比一下各种网关技术的优劣吗?
网关的核心功能
(1)动态路由:新开发某个服务,动态把请求路径和服务的映射关系热加载到网关里去;服务增减机器,网关自动热感知
(2)灰度发布
(3)授权认证
(4)性能监控:每个API接口的耗时、成功率、QPS
(5)系统日志
(6)数据缓存
**(**7)限流熔断
几种技术选型
Kong、Zuul、Nginx+Lua(OpenResty)、自研网关
Kong:Nginx里面的一个基于lua写的模块,实现了网关的功能
Zuul:基于Java开发,核心网关功能都比较简单,但是比如灰度发布、限流、动态路由之类的,很多都要自己做二次开发。高并发能力不强,部署到一些机器上去,还要基于Tomcat来部署,Spring Boot用Tomcat把网关系统跑起来;Java语言开发,可以直接把控源码,可以做二次开发封装各种需要的功能
Nginx+Lua(OpenResty): 直接通过nginx来当做网关
自研网关:自己来写类似Zuul的网关,基于Servlet、Netty来做网关,实现上述所有的功能
9、如果网关需要抗每秒10万的高并发访问,你应该怎么对网关进行生产优化?

Zuul网关部署的是什么配置的机器,部署32核64G,对网关路由转发的请求,每秒抗个小几万请求是不成问题的,几台Zuul网关机器
每秒是1万请求,8核16G的机器部署Zuul网关,5台机器就够了
10、生产级的网关,应该具备我刚才说的几个特点和功能:
(1)动态路由:新开发某个服务,动态把请求路径和服务的映射关系热加载到网关里去;服务增减机器,网关自动热感知
(2)灰度发布:基于现成的开源插件来做
(3)授权认证
(4)限流熔断
(5)性能监控:每个API接口的耗时、成功率、QPS
(6)系统日志
(7)数据缓存
11、如果需要部署上万服务实例,现有的服务注册中心能否抗住?如何优化?
Eureka 和 ZK都是扛不住了,(可以主动说出注册中心的缺点)
eureka:peer-to-peer,每台机器都是高并发请求,有瓶颈
zookeeper:服务上下线,全量通知其他服务,网络带宽被打满,有瓶颈
1.可以加一个数据库层(或者是 redis缓存层),每个服务定时通过数据库(redis缓存层)来更新服务注册表,然后数据库(redis缓存层)定时拉取注册中心来更新注册表。
2.可以自研,类似于 redis 集群 加主备架构,将压力分散开。按需拉取局部的注册表。比如说服务A在,注册中心1,那么只用拉取注册中心1的注册表。而不用将注册中心1,2,3,4等等其他注册拉取过来。缓解压力。

12、说说生产环境下,你们是怎么实现网关对服务的动态路由的?
l通过数据库+网关定时拉取数据库 服务注册中心配置。
l首先开发注册中心配置系统,通过页面可以动态的将增加新老服务。写入到数据库。
l同时也可以通过拉取eureka来最新的服务注册中心配置。写入到数据库。
l网关定时10秒拉取数据库的最新配置。
这样好处减少了eureka的压力,同时当注册中心服务宕机,也不影响当前网关的路由。
13、你们是如何基于网关实现灰度发布的?说说你们的灰度发布方案?
1.准备一个数据库和一个表(也可以用Apollo配置中心、Redis、ZooKeeper,其实都可以),放一个灰度发布启用表
2.写一个zuul的filter,对每个请求,zuul都会调用这个filter
3.当尝试新版本发布,修改新服务的版本为 new
4.通过页面 修改配置中心,或者修改数据库表,开灰度发布。
5.开灰度发布 网关的 filter 就会随机 百分之1的请求 带上 new 版本。这样请求就会跑到新服务
6.当新服务使用一段时间没有问题,再将old服务全部替换成 new服务 版本设置为 current,关闭灰度发布。
14、说说你们一个服务从开发到上线,服务注册、网关路由、服务调用的流程?
spring cloud 原理图。
注册中心 eureka
网关 zuul
服务调用 fegin
负载均衡 ribbon
15、什么是 Spring Cloud
Spring cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。
16、使用 Spring Cloud 有什么优势
使用Spring Boot 开发分布式微服务时,我们面临以下问题
- 与分布式系统相关的复杂性-这种开销包括网络问题,延迟开销,带宽问题,安全问题。
- 服务发现-服务发现工具管理群集中的流程和服务如何查找和互相交谈。它涉及一个服务目录,在该目录中注册服务,然后能够查找并连接到该目录中的服务。
- 冗余-分布式系统中的冗余问题。
- 负载平衡–负载平衡改善跨多个计算资源的工作负荷,诸如计算机,计算机集群,网络链路,中央 处理单元,或磁盘驱动器的分布。
- 性能-问题由于各种运营开销导致的性能问题。
- 部署复杂性-Devops 技能的要求。
17、服务注册和发现是什么意思Spring Cloud 如何实现
当我们开始一个项目时,我们通常在属性文件中进行所有的配置。随着越来越多的服务开发和部署,添加和修改这些属性变得更加复杂。有些服务可能会下降,而某些位置可能会发生变化。手动更改属性可能会产生问题。Eureka 服务注册和发现可以在这种情况下提供帮助。由于所有服务都在 Eureka 服务器上注册并通过调用 Eureka 服务器完成查找,因此无需处理服务地点的任何更改和处理。
18、负载平衡的意义什么
在计算中,负载平衡可以改善跨计算机,计算机集群,网络链接,中央处理单元或磁盘驱动器等多种计算资源的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间并避免任何单一资源的过载。使用多个组件进行负载平衡而不是单个组件可能会通过冗余来提高可靠性和可用性。负载平衡通常涉及专用软件或硬件,例如多层交换机或域名系统服务器进程。
19、什么是 Hystrix它如何实现容错
Hystrix是一个延迟和容错库,旨在隔离远程系统,服务和第三方库的访问点,当出现故障是不可避免的故障时,停止级联故障并在复杂的分布式系统中实现弹性。
通常对于使用微服务架构开发的系统,涉及到许多微服务。这些微服务彼此协作。
思考一下微服务
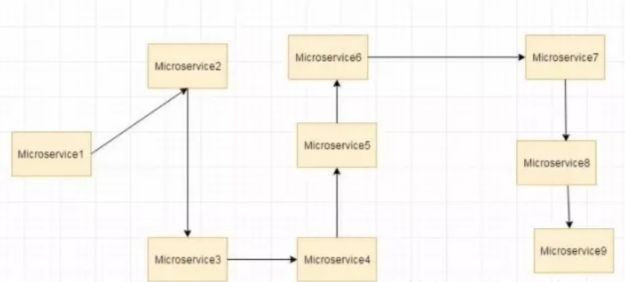
假设如果上图中的微服务 9 失败了,那么使用传统方法我们将传播一个异常。但这仍然会导致整个系统崩溃。
随着微服务数量的增加,这个问题变得更加复杂。微服务的数量可以高达1000.这是 hystrix 出现的地方, 我们将使用 Hystrix 在这种情况下的Fallback 方法功能。我们有两个服务 employee-consumer 使用由employee-consumer 公开的服务。

20、什么是 Hystrix 断路器我们需要它吗
由于某些原因,employee-consumer 公开服务会引发异常。在这种情况下使用 Hystrix 我们定义了一个 回退方法。如果在公开服务中发生异常,则回退方法返回一些默认值。

如果 firstPage method()中的异常继续发生,则 Hystrix 电路将中断,并且员工使用者将一起跳过 firtsPage 方法,并直接调用回退方法。断路器的目的是给第一页方法或第一页方法可能调用的其他方法留出时间,并导致异常恢复。可能发生的情况是,在负载较小的情况下,导致异常的问题有 更好的恢复机会。

21、什么是 Netflix Feign它的优点是什么
Feign 是受到 Retrofit,JAXRS-2.0和 WebSocket 启发的 java 客户端联编程序。Feign 的第一个目标是将约束分母的复杂性统一到 http apis,而不考虑其稳定性。在 employee-consumer 的例子中,我们使用了 employee- producer 使用 REST 模板公开的 REST 服务。
但是我们必须编写大量代码才能执行以下步骤
-
使用功能区进行负载平衡。
-
获取服务实例,然后获取基本 URL。
-
利用REST模板来使用服务。前面的代码如下
@Controller
public class ConsumerControllerClient {
@Autowired
private LoadBalancerClient loadBalancer;
public void getEmployee() throws RestClientException, IOExc eption {
ServiceInstance serviceInstance=loadBalancer.choose(“employ ee-producer”);
System.out.println(serviceInstance.getUri());
String baseUrl=serviceInstance.getUri().toString();
baseUrl=baseUrl+“/employee”;
RestTemplate restTemplate = new RestTemplate();
ResponseEntity response=null;
try{
response=restTemplate.exchange(baseUrl,
HttpMethod.GET, getHeaders(),String.class);
}catch (Exception ex)
{
System.out.println(ex);
}
System.out.println(response.getBody());
之前的代码,有像 NullPointer 这样的例外的机会,并不是最优的。我们将看到如何使用 Netflix Feign 使呼叫变得更加轻松和清洁。如果 Netflix Ribbon 依赖关系也在类路径中,那么 Feign 默认也会负责负载平衡。
22、什么是SpringCloudBus我们需要它吗
考虑以下情况:我们有多个应用程序使用 Spring Cloud Config 读取属性, 而 Spring Cloud Config 从 GIT 读取这些属性。
下面的例子中多个员工生产者模块从 Employee Config Module 获取Eureka 注册的财产。
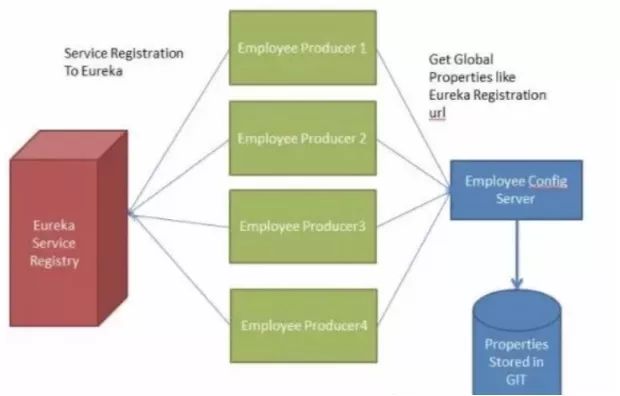
如果假设 GIT 中的 Eureka 注册属性更改为指向另一台 Eureka 服务器,会发生什么情况。在这种情况下,我们将不得不重新启动服务以获取更新的属性。
还有另一种使用执行器断点/刷新的方式。使我们将不得不为每个模块单独调用这个 url。例如,如果 Employee Producer1 部署在端口 8080上, 则调用 http:// localhost:8080/ refresh。同样对于 Employee Producer2 http:// localhost:8081 / refresh 等等。这又很麻烦。这就是 Spring Cloud Bus 发挥作用的地方。

Spring Cloud Bus 提供了跨多个实例刷新配置的功能。因此,在上面的示例中,如果我们刷新 Employee Producer1,则会自动刷新所有其他必需的模块。如果我们有多个微服务启动并运行,这特别 有用。这是通过将所有微服务连接到单个消息代理来实现的。无论何时刷新实例,此事件都会订阅到侦听此代理的所有微服务,并且它们也会刷新。可以通过使用端点/ 总线/刷新来实现对任何单个实例的刷新。
微服务面试合辑 word文档下载地址:链接:https://pan.baidu.com/s/1KdvrTt7bpxS2QMwlbhMErw
提取码:1111
爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
并发编程面试篇合辑
并发编程(上)
1、Synchronized用过吗其原理是什么?
这是一道Java面试中几乎百分百会问到的问题,因为没有任何写过并发程序的开发者会没听说或者没接触过Synchronized。Synchronized是由JVM 实现的一种实现互斥同步的一种方式,如果你查看被Synchronized修饰过的程序块编译后的字节码,会发现,被Synchronized修饰过的程序块,在 编译前后被编译器生成了monitorenter和monitorexit两个字节码指令。这两个指令是什么意思呢2在虚拟机执行到monitorenter指令时,首先要尝试获取对象的锁:如果这个对象没有锁定,或者当前线程已经拥有了这个对 象的锁,把锁的计数器+ 1;当执行monitorexit指令时将锁计数器-1;当计数器为0时,锁就被释放了。如果获取对象失败了,那当前线程就要阻塞 等待,直到对象锁被另外一个线程释放为止。Java中Synchronize通过在对象头设置标记,达到了获取锁和释放锁的目的。
2、你刚才提到获取对象的锁这个 “锁 ”到底是什么2如何确定对象的锁2
“锁”的本质其实是monitorenter和monitorexit字节码指令的一个Reference 类型的参数,即要锁定和解锁的对象。我们知道,使用Synchronized 可以修饰不同的对象,因此,对应的对象锁可以这么确定。
1. 如果 Synchronized 明确指定了锁对象,比如 Synchronized(变量名)、Synchronized(this)等,说明加解锁对象为该对象。
2.如果没有明确指定:
若Synchronized修饰的方法为非静态方法,表示此方法对应的对象为 锁对象;
若 Synchronized 修饰的方法为静态方法,则表示此方法对应的类对象 为锁对象。
注意,当一个对象被锁住时,对象里面所有用 Synchronized 修饰的方法都将产生堵塞,而对象里非 Synchronized 修饰的方法可正常被调用,不受锁影响。
3、什么是可重入性为什么说 Synchronized 是可重入锁
可重入性是锁的一个基本要求,是为了解决自己锁死自己的情况。比如下面的伪代码,一个类中的同步方法调用另一个同步方法,假如Synchronized 不支持重入,进入 method2 方法时当前线程获得锁,method2 方法里面执行 method1 时当前线程又要去尝试获取锁,这 时如果不支持重入,它就要等释放,把自己阻塞,导致自己锁死自己。
对 Synchronized 来说,可重入性是显而易见的,刚才提到,在执行monitorenter 指令时,如果这个对象没有锁定,或者当前线程已经拥有了这个对象的锁(而不是已拥有了锁则不能继续获取),就把锁的计 数器+1, 其实本质上就通过这种方式实现了可重入性。
4、JVM 对 Java 的原生锁做了哪些优化
在 Java 6 之前,Monitor 的实现完全依赖底层操作系统的互斥锁来 实现, 也就是我们刚才在问题二中所阐述的获取/释放锁的逻辑。
由于Java 层面的线程与操作系统的原生线程有映射关系,如果要将一个线程进行阻塞或唤起都需要操作系统的协助,这就需要从用户态切换 到内核态来执行,这种切换代价十分昂贵,很耗处理器时间,现代 JDK 中做了大量的优化。一种优化是使用自旋锁,即在把线程进行阻塞操作之前先让线程自旋等 待一段时间,可能在等待期间其他线程已经解锁,这时就无需再让线程 执行阻塞操作,避免了用户态到内核态的切换。
现代JDK 中还提供了三种不同的 Monitor 实现,也就是三种不同的锁:
偏向锁(BiasedLocking)
轻量级锁
重量级锁
这三种锁使得 JDK 得以优化 Synchronized 的运行,当 JVM 检测到不同的竞争状况时,会自动切换到适合的锁实现,这就是锁的升级、 降级。
当没有竞争出现时,默认会使用偏向锁。
JVM 会利用 CAS 操作,在对象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁,因 为在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定, 使用偏斜锁可以降低无竞争开销。
如果有另一线程试图锁定某个被偏斜过的对象,JVM 就撤销偏斜锁, 切换到轻量级锁实现。
轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功, 就使用普通的轻量级锁;否则,进一步升级为重量级锁。
5、为什么说 Synchronized 是非公平锁
非公平主要表现在获取锁的行为上,并非是按照申请锁的时间前后给等 待线程分配锁的,每当锁被释放后,任何一个线程都有机会竞争到锁, 这样做的目的是为了提高执行性能,缺点是可能会产生线程饥饿现象。
6、什么是锁消除和锁粗化
锁消除:指虚拟机即时编译器在运行时,对一些代码上要求同步,但被 检测到不可能存在共享数据竞争的锁进行消除。主要根据逃逸分析。
程序员怎么会在明知道不存在数据竞争的情况下使用同步呢很多不是程序员自己加入的。
锁粗化:原则上,同步块的作用范围要尽量小。但是如果一系列的连续 操作都对同一个对象反复加锁和解锁,甚至加锁操作在循环体内,频繁 地进行互斥同步操作也会导致不必要的性能损耗。
锁粗化就是增大锁的作用域。
7、为什么说 Synchronized 是一个悲观锁乐观锁的实现原理 又是什么什么是CAS它有什么特性
Synchronized 显然是一个悲观锁,因为它的并发策略是悲观的:不管是否会产生竞争,任何的数据操作都必须要加锁、用户态核心态转 换、维护锁计数器和检查是否有被阻塞的线程需要被唤醒等操作。随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略。先进行操作,如果没 有其他线程征用数据,那操作就成功了; 如果共享数据有征用,产生了冲突,那就再进行其他的补偿措施。这种乐观的并发策略的许多实现不需要线程挂起,所以被称为非阻塞同步。乐观锁的核心算法是CAS(Compareand Swap,比较并交换),它涉及到三个操作数:内存值、预期值、新值。当且仅当预期值和内存值相等时才将内存值修改为新值。这样处理的逻辑是,首先检查某块内存的值是否跟之前我读取时的一 样, 如不一样则表示期间此内存值已经被别的线程更改过,舍弃本次操 作,否则说明期间没有其他线程对此内存值操作,可以把新值设置给此 块内存。
CAS 具有原子性,它的原子性由 CPU 硬件指令实现保证,即使用 JNI 调用 Native 方法调用由 C++编写的硬件级别指令,JDK 中提供了 Unsafe 类执行这些操作。
8、乐观锁一定就是好的吗
乐观锁避免了悲观锁独占对象的现象,同时也提高了并发性能,但它也有缺点:
1. 乐观锁只能保证一个共享变量的原子操作。如果多一个或几个变量,乐观锁将变得力不从心,但互斥锁能轻易解决,不管对象数量多少及对象颗粒度大小。
2. 长时间自旋可能导致开销大。假如 CAS 长时间不成功而一直自旋,会给 CPU 带来很大的开销。
3. ABA 问题。CAS 的核心思想是通过比对内存值与预期值是否一样而判断内存值是否被改过,但这个判断逻辑不严谨,假如内存值原来是 A, 后来被一条线程改为 B,最后又被改成了 A,则 CAS 认为此内存值并没有发生改变,但实际上是有被其他线程改过的,这种情况对依赖过程值的情景 的运算结果影响很大。解决的思路是引入版本号,每次变量更新都把版本号加一。
9、跟 Synchronized 相比可重入锁 ReentrantLock 其实现 原理有什么不同
其实,锁的实现原理基本是为了达到一个目的: 让所有的线程都能看到某种标记。
Synchronized 通过在对象头中设置标记实现了这一目的,是一种 JVM 原生的锁实现方式,而 ReentrantLock 以及所有的基于 Lock 接口的实现类,都是通过用一个 volitile 修饰的 int 型变量,并保证每个线 程都能拥有对该 int 的可见性和原子修改,其本质是基于所谓的 AQS 框架。
10 、 那 么 请 谈 谈 AQS 框 架 是 怎 么 回 事 儿
AQS(AbstractQueuedSynchronizer 类)是一个用来构建锁和同步器的框架, 各种 Lock 包中的锁(常用的有 ReentrantLock、 ReadWriteLock) ,以及其他如 Semaphore、CountDownLatch, 甚至是早期的 FutureTask 等,都是基于 AQS 来构建。
1. AQS 在内部定义了一个 volatile int state 变量,表示同步状态:当线程调用 lock 方法时 ,如果 state=0,说明没有任何线程占有共享资源 的锁,可以获得锁并将 state=1;如果 state=1,则说明有线程目前正在 使用共享变量,其他线程必须加入同步队列进行等待。
2. AQS 通过 Node 内部类构成的一个双向链表结构的同步队列,来完成线程获取锁的排队工作,当有线程获取锁失败后,就被添加到队列末尾。
Node类是对要访问同步代码的线程的封装,包含了线程本身及其状态叫
waitStatus(有五种不同取值,分别表示是否被阻塞,是否等待唤醒, 是否已经被取消等),每个 Node 结点关联其 prev 结点和 next 结点,方便线程释放锁后快速唤醒下一个在等待的线程,是一个 FIFO 的过程。
Node 类有两个常量,SHARED 和 EXCLUSIVE,分别代表共享模式和独占模式。所谓共享模式是一个锁允许多条线程同时操作(信号量Semaphore 就是基于 AQS 的共享模式实现的),独占模式是同一个时间段只能有一个线程对共享资源进行操作,多余的请求线程需要排队等待(如 ReentranLock)。
3. AQS 通过内部类 ConditionObject 构建等待队列(可有多个),当Condition 调用 wait()方法后,线程将会加入等待队列中,而当Condition 调用 signal()方法后,线程将从等待队列转移动同步队列中进行锁竞争。
4.AQS和Condition各自维护了不同的队列,在使用Lock和Condition
的时候,其实就是两个队列的互相移动。
11、请尽可能详尽地对比下 Synchronized 和 ReentrantLock 的异同
ReentrantLock 是 Lock 的实现类,是一个互斥的同步锁。从功能角度, ReentrantLock 比 Synchronized 的同步操作更精细(因为可以像普通对象一样使用),甚至实现 Synchronized 没有的高级功能,如:
等待可中断:当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,对处理执行时间非常长的同步块很有用。
带超时的获取锁尝试:在指定的时间范围内获取锁,如果时间到了仍然无法获取则返回。
可以判断是否有线程在排队等待获取锁。
可以响应中断请求:与 Synchronized 不同,当获取到锁的线程被中断时,能够响应中断,中断异常将会被抛出,同时锁会被释放。
可以实现公平锁。
从锁释放角度,Synchronized 在 JVM 层面上实现的,不但可以通过一些监控工具监控 Synchronized 的锁定,而且在代码执行出现异常时,JVM 会自动释放锁定;但是使用 Lock 则不行,Lock 是通过代码实现的,要保证锁定一定会被释放,就必须将 unLock()放到 finally{}中。
从性能角度,Synchronized 早期实现比较低效,对比ReentrantLock,大多数场景性能都相差较大。
但是在 Java 6 中对其进行了非常多的改进,在竞争不激烈时, Synchronized 的性能要优于 ReetrantLock;在高竞争情况下, Synchronized 的性能会下降几十倍,但是 ReetrantLock 的性能能维持常态。
12、ReentrantLock 是如何实现可重入性的
ReentrantLock 内部自定义了同步器 Sync(Sync 既实现了 AQS, 又实现了 AOS,而 AOS 提供了一种互斥锁持有的方式),其实就是 加锁的时候通过CAS 算法,将线程对象放到一个双向链表中,每次获 取锁的时候,看下当前维护的那个线程 ID 和当前请求的线程 ID 是否一样,一样就可重入了。
13、除了 ReetrantLock你还接触过 JUC 中的哪些并发工具
通常所说的并发包(JUC)也就是java.util.concurrent及其子包,集中了Java并发的各种基础工具类,具体主要包括几个方面:
提供了 CountDownLatch、CyclicBarrier、Semaphore等,比Synchronized 更加高级,可以实现更加丰富多线程操作的同步结构。
提供了ConcurrentHashMap、有序的ConcunrrentSkipListMap,或者通过类似快照机制实现线程安全的动态数组CopyOnWriteArrayList等各种线程安全的容器。
提供了ArrayBlockingQueue、SynchorousQueue或针对特定场景的
PriorityBlockingQueue 等,各种并发队列实现。
强大的 Executor 框架,可以创建各种不同类型的线程池,调度任务运行等。
14、请谈谈ReadWriteLock和StampedLock)
虽然 ReentrantLock 和 Synchronized 简单实用,但是行为上有一定局限性,要么不占,要么独占。实际应用场景中,有时候不需要大量 竞争的写操作,而是以并发读取为主,为了进一步优化并发操作的粒度,Java 提供了读写锁。读写锁基于的原理是多个读操作不需要互斥,如果读锁试图锁定时,写锁是被某个线程持有,读锁将无法获得,而只好等待对方操作 结束,这样就可以自动保证不会读取到有争议的数据。

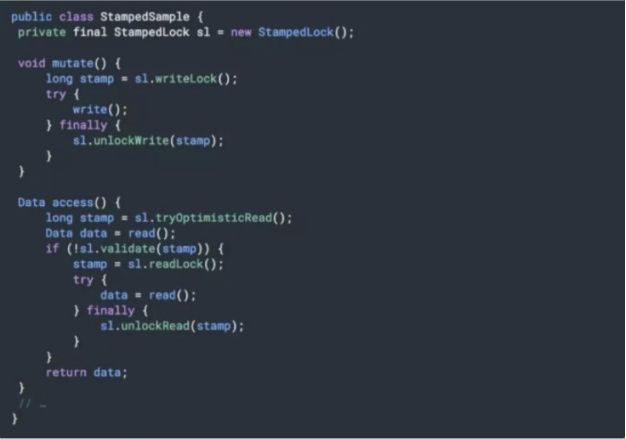
读写锁看起来比 Synchronized 的粒度似乎细一些,但在实际应用 中,其表现也并不尽如人意,主要还是因为相对比较大的开销。所以,JDK 在后期引入了 StampedLock,在提供类似读写锁的同时,还支持优化读模式。优化读基于假设,大多数情况下读操作并不会和写 操作冲突,其逻辑是先试着修改,然后通过 validate 方法确认是否进入了写模式,如果没有进入,就成功避免了开销;如果进入,则尝试获取读锁。
15、如何让 Java 的线程彼此同步你了解过哪些同步器请分别介绍下
JUC 中的同步器三个主要的成员:CountDownLatch、CyclicBarrier 和Semaphore,通过它们可以方便地实现很多线程之间协作的功能。CountDownLatch 叫倒计数,允许一个或多个线程等待某些操作完成。看几个场景:
跑步比赛,裁判需要等到所有的运动员(“其他线程”)都跑到终点(达到目标),才能去算排名和颁奖。
模拟并发,我需要启动 100个线程去同时访问某一个地址,我希望它 们能同时并发,而不是一个一个的去执行。
用法:CountDownLatch 构造方法指明计数数量,被等待线程调用countDown 将计数器减 1,等待线程使用 await 进行线程等待。一个简单的例子:

CyclicBarrier 叫循环栅栏,它实现让一组线程等待至某个状态之后再全部同时执行,而且当所有等待线程被释放后,CyclicBarrier 可以被重复使用。CyclicBarrier 的典型应用场景是用来等待并发线程结束。CyclicBarrier 的主要方法是 await(),await()每被调用一次,计数便会减少 1,并阻塞住当前线程。当计数减至0时,阻塞解除,所有在 此 CyclicBarrier 上面阻塞的线程开始运行。
在这之后,如果再次调用 await(),计数就又会变成 N-1,新一轮重新开始,这便是 Cyclic 的含义所在。CyclicBarrier.await() 带有返回值,用来表示当前线程是第几个到达这个 Barrier 的线程。
举例说明如下:

Semaphore,Java版本的信号量实现,用于控制同时访问的线程个数,来
达到限制通用资源访问的目的,其原理是通过 acquire()获取一个许可,如果没有就等待,而 release() 释放一个许可。
如果Semaphore 的数值被初始化为1,那么一个线程就可以通过 acquire进入互斥状态,本质上和互斥锁是非常相似的。
但是区别也非常明显,比如互斥锁是有持有者的,而对于 Semaphore 这种计数器结构,虽然有类似功能,但其实不存在真正意义的持有者,除非我们进行扩展包装。
16、CyclicBarrier 和 CountDownLatch 看起来很相似请对比下呢
它们的行为有一定相似度,区别主要在于:
CountDownLatch 是不可以重置的,所以无法重用,CyclicBarrier 没有这种限制,可以重用。
CountDownLatch 的基本操作组合是 countDown/await,调用 await 的线程阻塞等待 countDown 足够的次数,不管你是在一个线程还是多个线程里 countDown,只要次数足够即可。CyclicBarrier 的基本操作组合就是await,当所有的伙伴都调用了 await,才会继续进行任务,并自动进行重置。
CountDownLatch 目的是让一个线程等待其他 N 个线程达到某个条件后, 自己再去做某个事(通过 CyclicBarrier 的第二个构造方法 public CyclicBarrier(int parties, Runnable barrierAction),在新线程里做事可以达到同样的效果)。而 CyclicBarrier 的目的是让 N 多线程互相等待直到所有的都达到某个状态,然后这 N 个线程再继续执行各自后续(通过CountDownLatch 在某些场合也能完成类似的效果)。
17、Java 中的线程池是如何实现的
在Java中,所谓的线程池中的“线程”,其实是被抽象为了一个静态 内部类Worker,它基于AQS实现,存放在线程池的HashSet workers 成员变量中;
而需要执行的任务则存放在成员变量 workQueue(BlockingQueue workQueue)中。
这样,整个线程池实现的基本思想就是:从 workQueue 中不断取出 需要执行的任务,放在 Workers 中进行处理。
18、创建线程池的几个核心构造参数
Java 中的线程池的创建其实非常灵活,我们可以通过配置不同的参 数,创建出行为不同的线程池,这几个参数包括:
corePoolSize:线程池的核心线程数。
maximumPoolSize:线程池允许的最大线程数。
keepAliveTime:超过核心线程数时闲置线程的存活时间。
workQueue:任务执行前保存任务的队列,保存由execute方法提交的Runnable 任务 。
19、线程池中的线程是怎么创建的是一开始就随着线程池的启动创建好的吗
显然不是的。线程池默认初始化后不启动 Worker,等待有请求时才启动。
每当我们调用execute() 方法添加一个任务时,线程池会做如下判 断:
如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列;
如果这时候队列满了,而且正在运行的线程数量小于
maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常 RejectExecutionException。当一个线程完成任务时,它会从队列中取下一个任务来执行。当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断。
如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
20、既然提到可以通过配置不同参数创建出不同的线程池那么Java中默认实现好的线程池又有哪些呢请比较它们的异同)
1.SingleThreadExecutor线程池
这个线程池只有一个核心线程在工作,也就是相当于单线程串行执行所 有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来 替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
- corePoolSize:1,只有一个核心线程在工作。
- maximumPoolSize: 1。
- keepAliveTime:0L。
- workQueue:newLinkedBlockingQueue()其缓冲队列是无界的
2.FixedThreadPool线程池
FixedThreadPool 是固定大小的线程池,只有核心线程。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
FixedThreadPool 多数针对一些很稳定很固定的正规并发线程,多用于服务器。
- corePoolSize:nThreads
- maximumPoolSize:nThreads
- keepAliveTime:0L
- workQueue:newLinkedBlockingQueue()其缓冲队列是无界的
3.CachedThreadPool线程池
CachedThreadPool 是无界线程池,如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)线程,当 任务数增加时,此线程池又可以智能的添加新线程来处理任务。线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。SynchronousQueue 是一个是缓冲区为 1 的阻塞队列。缓存型池子通常用于执行一些生存期很短的异步型任务,因此在一些面向连接的 daemon 型 SERVER 中用得不多。但对于生存期短的异步任务,它是 Executor 的首选。
- corePoolSize: 0
- maximumPoolSize:Integer.MAX_VALUE
- keepAliveTime: 60L
- workQueue:newSynchronousQueue()
一个是缓冲区为1 的阻塞队列。
4.ScheduledThreadPool线程池
ScheduledThreadPool核心线程池固定,大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。创建一个周期性执行任务的线程池。如果闲置,非核心线程池会在DEFAULT_KEEPALIVEMILLIS时间内回收
- corePoolSize: corePoolSize
- maximumPoolSize:Integer.MAX_VALUE
- keepAliveTime:DEFAULT_KEEPALIVE_MILLIS
- workQueue:newDelayedWorkQueue()
21、如何在 Java 线程池中提交线程
线程池最常用的提交任务的方法有两种:
1.execute():ExecutorService.execute方法接收一个例,它用来执行一个任务:

2. submit(): ExecutorService.submit()方法返回的是 Future 对象。可以用
isDone()来查询 Future 是否已经完成,当任务完成时, 它具有一个结果, 可以调用 get()来获取结果。也可以不用 isDone() 进行检查就直接调用get(),在这种情况下,get() 将阻塞,直至结果准备就绪。

22、什么是 Java 的内存模型Java 中各个线程是怎么彼此看到对方的变量的
Java 的内存模型定义了程序中各个变量的访问规则,即在虚拟机中将 变量存储到内存和从内存中取出这样的底层细节。此处的变量包括实例字段、静态字段和构成数组对象的元素,但是不包括局部变量和方法参数, 因为这些是线程私有的,不会被共享,所以不存在竞争问题。
Java 中各个线程是怎么彼此看到对方的变量的呢Java中定义了主内存与工作内存的概念:
所有的变量都存储在主内存,每条线程还有自己的工作内存,保存了被 该线程使用到的变量的主内存副本拷贝。
线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,不能直接读写主内存的变量。不同的线程之间也无法直接访问对方工作内存的变量,线程间变量值的传递需要通过主内存。
23、请谈谈 volatile 有什么特点为什么它能保证变量对所有线程的可见性
关键字 volatile 是 Java 虚拟机提供的最轻量级的同步机制。当一个变量被定义成 volatile 之后,具备两种特性:
1. 保证此变量对所有线程的可见性。当一条线程修改了这个变量的值,新值对于其他线程是可以立即得知的。而普通变量做不到这一点。
2. 禁止指令重排序优化。普通变量仅仅能保证在该方法执行过程中,得到正确结果,但是不保证程序代码的执行顺序。
Java 的内存模型定义了 8 种内存间操作:
lock 和 unlock
把一个变量标识为一条线程独占的状态。
把一个处于锁定状态的变量释放出来,释放之后的变量才能被其他线程锁定。
read 和 write
把一个变量值从主内存传输到线程的工作内存,以便 load。
把 store 操作从工作内存得到的变量的值,放入主内存的变量中。
load 和 store
把 read 操作从主内存得到的变量值放入工作内存的变量副本中。
把工作内存的变量值传送到主内存,以便 write。
use 和 assgin
把工作内存变量值传递给执行引擎。
将执行引擎值传递给工作内存变量值。
volatile 的实现基于这 8 种内存间操作,保证了一个线程对某个 volatile 变量的修改,一定会被另一个线程看见,即保证了可见性。
24、既然 volatile 能够保证线程间的变量可见性是不是就意味着基于volatile变量的运算就是并发安全的
显然不是的。基于 volatile 变量的运算在并发下不一定是安全的。volatile 变量在各个线程的工作内存,不存在一致性问题(各个线程的工作内存中volatile 变量,每次使用前都要刷新到主内存)。
但是 Java 里面的运算并非原子操作,导致 volatile 变量的运算在并发下一样是不安全的。
25、请对比下 volatile 对比 Synchronized 的异同)
Synchronized 既能保证可见性,又能保证原子性,而 volatile 只能保证可见性,无法保证原子性。
ThreadLocal 和 Synchonized 都用于解决多线程并发访问,防止任务在共享资源上产生冲突。但是 ThreadLocal 与 Synchronized 有本质的区别。Synchronized 用于实现同步机制,是利用锁的机制使变量或代码块在某一时刻只能被一个线程访问,是一种 “以时间换空间” 的方式。
而 ThreadLocal 为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,根除了对变量的共享,是一种“以空间换时间”的方式。
26、请谈谈 ThreadLocal 是怎么解决并发安全的
ThreadLocal 这是 Java 提供的一种保存线程私有信息的机制,因为 其在整个线程生命周期内有效,所以可以方便地在一个线程关联的不同业务模块之间传递信息,比如事务 ID、Cookie 等上下文相关信息。ThreadLocal 为每一个线程维护变量的副本,把共享数据的可见范围限 制在同一个线程之内,其实现原理是,在 ThreadLocal 类中有一个 Map,用于存储每一个线程的变量的副本。
27、很多人都说要慎用 ThreadLocal谈谈你的理解使用ThreadLocal 需要注意些什么
使用ThreadLocal 要注意 remove!
ThreadLocal 的实现是基于一个所谓的 ThreadLocalMap,在ThreadLocalMap 中,它的 key 是一个弱引用。
通常弱引用都会和引用队列配合清理机制使用,但是 ThreadLocal 是个例外,它并没有这么做。
这意味着,废弃项目的回收依赖于显式地触发,否则就要等待线程结束, 进而回收相应 ThreadLocalMap!这就是很多 OOM 的来源,所 以通常都会建议,应用一定要自己负责 remove,并且不要和线程池配 合,因为worker 线程往往是不会退出的。
并发编程(下)
1、Java start 如何调用到run方法
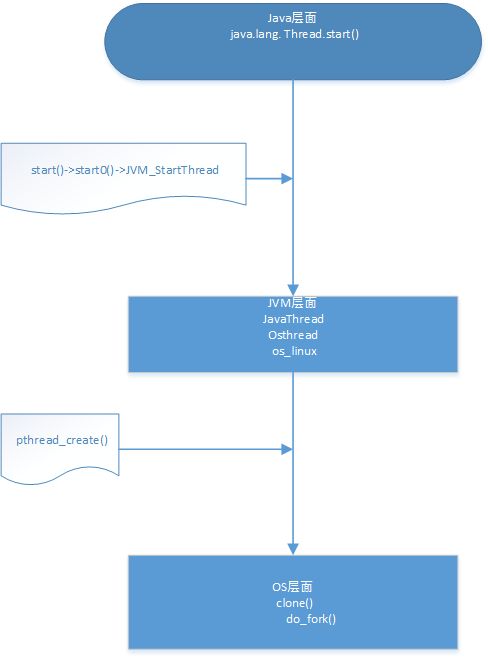
java层面: start -> start0() -> native start0()
C(jvm)层面: JVM_StartThread()
OS层面: pthread_create() 这里会回调jvm的run方法
java调用 native方法,native 方法对应着 头文件,头文件会动态链接到 c文件,c文件会调用 系统函数。
2、synchronized 关键字的底层原理,synchronize锁是如何实现的?
-
首先每个类都由Objec派生出,每个对象都有ObjectMonitor,当线程发生同步,会去尝试将ObjectMonitor 的 owner 设置为自己,如果没有获得就会进入entryList中。
-
获取锁,monitor 的计数器就会加1,owner 就指向当前线程。同时synchronized 是支持重入锁,也就是同一个线程对同一个对象多次加锁。每加锁一次,计数器就会加1。
-
获取锁,线程进入同步块,虚拟机就会设置 monitorenter进入同步块,退出同步就会设置为monitorexit,为了防止同步中出现异常,设置了第二个monitorexit。
-
当退出同步,计数器就变为 0,owner 设置为 null,entryList中线程就会CAS去竞争获取对象monitor关联的锁。只有一个线程可以获取到锁。
-
当遇到wait就将同步的线程放入waitSet中。
-
当对象调用notify,就会随机从waitSet取一个线程,放到entryList中,然后线程去竞争monitor。
-
当对象调用notifyAll,就会从waitSet将持有该对象的所有的线程,放到entryList中,然后线程去竞争monitor。
wait
wait 会将线程从entryList 放回到waitSet中。
3、notify 区别和 notifyAll
notify 会从waitSet《等待队列》中随机拿取那一个线程放到entryList《阻塞队列》中
notifyAll 会将waitSet所有线程都放到entryList中,唤醒哪个不确定,因为不确定谁竞争到了monitor。
4、synchronize锁优化锁膨胀过程?
首先synchronize的锁的状态在对象头中。
64位jdk 对应的 对象头中一共128个字节。 64个字节为 mark word 64个字节为klass word。我们主要看 mark word 结构。
无锁:主要的头信息 lock(锁状态) : 01 2个字节,biased_lock(是否偏向锁)1个字节:0,年轻代年龄:4个字节(用于晋升到老年代阈值),indentity_hashcode:对象标识hash码 25个字节 剩下的 26字节没有用。
偏向锁:主要的头信息 lock: 01,biased_lock:1,thread:54位 当先线程id,age:4字节
轻量锁:主要的头信息 lock:00
重量锁:主要的头信息 lock:10
GC:主要的头信息 lock:11
对象头****我们可以使用 openjdk 的 jol插件测试打印头信息。
- 从无锁到偏向锁
- 默认开启延迟偏向锁,jvm运行默认超过4s,那么对象就会开启偏向锁。
当第一个线程来访问它的时候,它会修改 ThreadId 改为当前线程的id,之后再访问这个对象时,只要对比ThreadID,一样就不会再CAS。
他默认第一次会调用os加锁。可以修改 os上锁函数 打印系统线程id,再修改C文件 打印 c的线程id。当开启一个线程,然后同步只打印一次 系统线程id和 c的线程id。而开启两个线程,对同一个对象加锁,会发现 系统线程id和c的线程id 同步打印。
多个线程通过CAS来获取锁,偏向上个拥有的线程,是乐观锁。
一般是单个线程执行
- 从偏向锁到轻量级锁
- 当前为无锁,直接修改为轻量级锁。
- 当前为偏向锁,并且偏向的线程不是当前线程,他会判断该锁的偏向线程是否存活,没有存活,将偏向锁变为无锁。然后变为轻量级锁。
多个线程,通过CAS来获取锁,是乐观锁。
一般是多个线程,交替执行。
- 从轻量级锁到重量级锁
- 轻量级锁自旋一定次数或者一个线程在持有锁,一个在自旋,另外一个线程来访时,轻量级膨胀为重量级锁。
- 对象调用了wait()也会变为重量级锁。
重量级锁,是调用了os函数加锁,使除了拥有锁的线程以为的线程都是阻塞,防止 CPU 空转,是悲观锁。
一般是多个线程,竞争执行。
5、AQS原理
AQS 全称 AbstractQueuedSynchronizer 抽象的队列同步器。他是一个抽象类。
AQS 通过 CLH 队列 一个带有虚拟头节点的双向链表,来唤醒线程是否可以竞争获取锁。
他主要有两种方式:一种是独占方式:只有一个线程能执行;一种是共享方式,多个线程可以同时执行。
我主要研究了独占方式的AQS 实现,ReentrantLock的实现方式。
ReentrantLock中 有个 内部类也就 sync 类,他继承了 AQS抽象类。
AQS 结构:head 头结点,tail 尾结点,state 加锁次数,exclusiveOwnerThread 当前占有锁的线程。
Node 结构: pre 上个节点,next 下个节点,waitState 节点等待状态,node当前线程。
lock加锁步骤:整体步骤 尝试加锁 tryAcquire(),封装线程为node 初始化队列,唤醒队列竞争锁,重置interrupt状态。
尝试加锁 tryAcquire()
- 首先调用tryAcquire ,主要判断 aqs 中的 state 是否 0 ,为0 两种情况一种是 长时间为自由锁状态,一种是 短暂刚释放锁到自由锁状态
- 如果为 0 ,判断是否有 head 和 head 是否有 next 节点 并且 node 线程是否是当前线程 。主要目的就是判断是否有队列,以及第二节点是否为当前节点。
- 如果没有队列或者下个node 当前线程,直接CAS 尝试获取锁。获取锁成功返回 true,失败返回fasle。
- 然后判断是否是重入锁,也就是判断当前线程是否是 aqs 中占有锁的线程。如果是重入锁 state +1 返回 true
- 其他情况,有队列且不是重入锁,且第二个节点线程不是当前线程,返回false。
封装线程为node 初始化队列
-
先将当前线程,封装成 node。
-
判断 head 是否为 null。
-
不为 null 说明已经存在队列,直接设置 node pre 为 tail,自己设置为新 tail。
-
为 null 说明不存在队列,直接死循环进行以下步骤
-
- 先判断 tail 是否为null,为 null 通过 CAS 设置一个空节点, 赋值给 head。同时 tail = head。
- 如果 tail 不为 null ,将 node 的 pre 设置为 tail,同时 CAS 将 node 设置为 新 tail。跳出循环
唤醒队列竞争锁
-
死循环,判断当前节点 pre 是否是 head ,目的是判断自己是否为 队列的第二个节点。
-
如果是 队列的第二个节点,就CAS 尝试获取锁,走 tryAcquire()方法。
-
- 获取锁成功,aqs 就是当前node的线程,设置 当前 node 为head ,旧的 head 断开连接,方便 gc回收。
- 获取失败走下面步骤。
-
获取失败 或者 不是第二个节点
-
- 首先将 上个节点 设置为 waitState 为 -1,默认waitState 为 0。目的是为了解锁用。
- 然后再次循环到这里,执行LockSupport.park(),等待被唤醒。
-
如果被唤醒,会调用 Thread.interrupted(),这个方法对lock()没什么作用,主要是为了lockInterruptor()方法,他会抛异常。
-
被唤醒后继续走,循环逻辑尝试获取锁。
-
出现异常,会走 finally 曲线当前线程获取锁。
重置 interrupt,当Thread.interrupted 为true,主要目的是为了保持线程的 interrupt 的状态一直。
非公平锁会上来就尝试获取锁,获取锁失败就走公平锁逻辑,也就是一朝排队,永久排队。
unlock解锁步骤:公平锁和非公平锁一直。
-
unLock(),调用AQS的 release(1),解锁。
-
尝试解锁,tryRelease(),该方法返回 true 解锁成功,false 解锁失败。
-
- 首先 state -1 得到 c。
- 当前线程不是 AQS 中占有锁的线程,直接抛异常。
- c = 0 解锁成功。将 AQS 的 站有锁的线程设置为null,其他情况 返回 false。(比如重入锁 state -1 可能大于 0)
-
解锁成功,则需要判断是否需要唤醒其他节点。
-
- 通过 是否有 head 判断是否存在队列,因为只有一个线程 可能不会初始化队列。没有队列不需要唤醒。
- 有队列,再判断 head 的waitState 是否为 0,不等于 0 说明 队列还有其他节点需要唤醒, 等于 0, head 为 tail ,队列不需要唤醒。
- 在判断head next 节点正常情况是 next node 不为 null,且waitState 为 <= 0 ,直接LockSupport.unPack()唤醒下个一个节点。
- 极端情况 next node 可能为 null 或者 next node 的 > 0(比如放弃索取线程。),那么我们可以通过从链表尾往前遍历,找到离当前 node 后面最近的节点,且该node 的 waitState <= 0;
7、ReentrantLock 和 synchronized 区别
相同点
- 都实现了多线程同步和内存可见性语义。
- 都是可重入锁。
不同点
- 同步实现机制不同
synchronized 通过 Java 对象头锁标记和 Monitor 对象实现同步。
- ReentrantLock 通过CAS、AQS(AbstractQueuedSynchronizer)和 LockSupport(用于阻塞和解除阻塞)实现同步。
- 使用方式不同
synchronized 可以修饰实例方法(锁住实例对象)、静态方法(锁住类对象)、代码块(显示指定锁对象)。ReentrantLock 显示调用 tryLock 和 lock 方法,需要在 finally 块中释放锁。- 功能丰富程度不同
synchronized 不可设置等待时间、不可被中断(interrupted)。
- ReentrantLock 提供有限时间等候锁(设置过期时间)、可中断锁(lockInterruptibly)、condition(提供 await、signal 等方法)等丰富功能
- 锁类型不同
synchronized 只支持非公平锁。
- ReentrantLock 提供公平锁和非公平锁实现。
8、Lock 高级功能?
CountDownLatch
减法计数器,减为0,执行本线程任务
场景: 某个线程,需要等其他线程执行完,再继续执行。(当设置了await时间,那么时间到了主线程就继续执行了。)
CyclicBarrier
加分计数器,循环屏障
场景:当前线程任务,需要等其他线程全部到达,再一起执行。
Semaphore
停车场
场景: 同一时间可执行固定数量的线程。(acquire()是并发执行,如果是tryAcquire()则不一定是并发执行,可能会串行执行)
读写锁
不同线程,读读不互斥,其他都互斥。
9、简述下CAS?
CAS有三个参数,第一个参数是指针(原来的值),第二参数是预期值,第三个参数是新值。
首先拿到旧值,然后比较交换的时候,判断预期值是不是旧值,如果一样就赋值为新值,否则就不交换。
因为CAS在主要是 MESI协议,将高速缓存区的对应要修改的条目加独占锁,通过总线通知其他的处理器,然后来比较修改。
CAS虽然高效的解决了原子操作问题,但仍然存在三大问题:
1.ABA问题:如果变量V初次读取的时候值是A,后来变成了B,然后又变成了A,你本来期望的值是第一个A才会设置新值,第二个A跟期望不符合,但却也能设置新值。
针对这种情况,java并发包中提供了一个带有标记的原子引用类AtomicStampedReference,它可以通过控制变量值的版本号来保证CAS的正确性,比较两个值的引用是否一致,如果一致,才会设置新值。 打一个比方,如果有一家蛋糕店,为了挽留客户,绝对为贵宾卡里余额小于20元的客户一次性赠送20元,刺激消费者充值和消费。但条件是,每一位客户只能被赠送一次。此时,如果很不幸的,用户正好正在进行消费,就在赠予金额到账的同时,他进行了一次消费,使得总金额又小于20元,并且正好累计消费了20元。使得消费、赠予后的金额等于消费前、赠予前的金额。这时,后台的赠予进程就会误以为这个账户还没有赠予,所以,存在被多次赠予的可能,但使用 AtomicStampedReference 就可以很好的解决这个问题。
2.无限循环问题(自旋):看源码可知,Atomic类设置值的时候会进入一个无限循环,只要不成功,就会不停的循环再次尝试。在高并发时,如果大量线程频繁修改同一个值,可能会导致大量线程执行compareAndSet()方法时需要循环N次才能设置成功,即大量线程执行一个重复的空循环(自旋),造成大量开销。
解决无线循环问题可以使用java8中的LongAdder, 有点像1.8的ConcurrentHashMap。高并发情况,new 一个 2的幂次方的数组,最大为cpu的核数。采用对数组分段CAS的方式,进行修改每个数组下标值。获取总数的时候采用原值 + 数组每个下标值的累加。
3.多变量原子问题:只能保证一个共享变量的原子操作。一般的Atomic类,只能保证一个变量的原子性,但如果是多个变量呢?
可以用AtomicReference,这个是封装自定义对象的,多个变量可以放一个自定义对象里,然后他会检查这个对象的引用是不是同一个。如果多个线程同时对一个对象变量的引用进行赋值,用AtomicReference的CAS操作可以解决并发冲突问题。 但是如果遇到ABA问题,AtomicReference就无能为力了,需要使用AtomicStampedReference来解决。
11、interrupt()方法 中断几种 区别
-
interrupt() 线程标记为中断,抛异常.
-
Interrupted() 判断线程是否中断,并且重置为false.
-
isInterrupted() 判断线程是否中断.
12、Runnale 和 Callable 区别
-
callable 执行的 call,runnable 执行的是 run
-
callable 可以获取future 对象,可以获取返回值。run 方法不行。
13、线程的几种状态?
-
新建(new)新建一个线程对象
-
可运行(runnable)调用 start 的方法,但是没有湖区 cpu 使用权。
-
运行(running)调用run方法,获得cpu使用权
-
阻塞(blocked)调用了sleep(),wait()或者运行时 等待获取锁。
-
死亡(dead)线程执行完了,或者异常退出了 run()方法。
14、线程池几种状态?
-
running 新建线程池
-
shutdown 调用 shutdown()不在接受新任务,但是会继续执行已经添加的任务。
-
stop 调用 shutdownNow()不在接受新任务,同时不会执行已添加任务,并且终止正在执行的线程。
-
tidying 任务线程停止 和 队列为空的状态。
-
terminated 在 tidying 状态调用 terminated()方法,线程池销毁。
15、线程池参数介绍?
核心线程数
最大线程数
线程空闲时间
阻塞队列
饱和策略
线程工厂
16、线程池的分发
-
新任务,先判断核心线程数是否全部再执行,没有就新建一个执行。
-
核心线程数全部在执行,那么就去判断队列中是否已满,未满添加到队列中
-
已满,就判断是否达到了最大线程数,没有达到就新建线程去执行当前线程。
-
已经达到了,就调用线程池的饱和策略
17、几种线程池
一般是使用 ThreadPoolExecutor 自己根据业务,CPU核数设置。
CPU 密集型,一般是 核心线程数和CPU核数+1,因为 CPU一直在运行,CPU 利用率高。
IO 密集型,一般是 2倍核数+1,CPU 利用低,其他线程可以继续使用CPU,提高CPU利用率。
- 固定核心线程数,无线队列,没有空闲时间的。适合压力较大的服务器,可以控制线程数,合理利用资源。
- 单一线程,无线队列,没有空闲时间。适合串型任务,按顺序执行的任务。
- 没有核心线程数,只有 maxInteger 大的 最大核心线程数,无线队列,有较短的空闲时间。适合并发高,周期短的任务。
- 定时线程,固定线程数,采用延迟或定时的方式来执行任务。
18、线程池的饱和策略
-
不处理,抛异常
-
不处理,不抛异常
-
让调用者的线程处理任务
-
丢弃队列头消息,接下来直接执行当前任务
-
自己实现 rejectExcutionHandler 接口,自定义策略。
19、submit() 和 execut()区别?
-
接受参数不同,execut 参数为 runnable,submit 可用时 runnable,callable
-
submit 可以通过 futureTask 获取返回值,execut 是没有返回值的
-
submit 最终也是 调用了 execut。
20、线程池是如何做到线程复用的?
-
通过 Work 的 runWork 方法。
-
该方法 第一次 通过 Work 的 firstTask 获取任务,
-
之后会 循环通过 getTask 从 workQueue 中不停地获取任务
-
并直接调用task的( task 是实现了runnable ) run 方法来执行任务,这样就保证了每个线程都始终在一个循环中,反复获取任务,然后执行任务,从而实现了线程的复用。
-
当 getTask 返回 null,就会销毁线程。
21、空闲线程超时销毁如何实现的?
-
首先线程池会将 新建的 work 放进 一个 set集合里,works。
-
getTask时候,先判读 works大小 是否超过核心线程数
-
超过核心线程数,使用 poll() + 空闲时间,去获取 task,poll()他是非阻塞的。
- 没用超过核心线程数,使用的是 take() take 是阻塞的,一直等待回去线程。
-
当 poll 空闲时间到了也没有获取到任务,返回null。
-
runWork 循环条件不成立,跳出循环,最终会调用 销毁 work 逻辑。
19、FutureTask
FutureTask是Future接口的一个唯一实现类。
FutureTask实现了Runnable,因此它既可以通过Thread包装来直接执行,也可以提交给ExecuteService来执行。
FutureTask实现了Futrue可以直接通过get()函数获取执行结果,该函数会阻塞,直到结果返回。
20、Threadlocal起什么作用?
线程隔离,保证线程安全。
21、Threadlocal内部实现原理
-
每个 Thread 都有 ThreadLocalMap。
-
ThreadLocalMap 内部为 entry数组,entry 对象 key 为ThreadLocal 变量,value 是存的变量的值。
-
entry 的 key 也就是 ThreadLocal 为 弱引用。
-
那么也就是说 ThreadLocal,容易被GC 回收掉。
-
set 会判断是否初始化了 map,没有就初始化,同时将当前 threadLocal 作为 key, 变量值作为 value 存入。同时可能会触发回收 失效的值。
-
get 也会判断是否初始化 map,没有就初始化。
-
初始化 默认 entry 长度为 16。阈值为 2/3 长度。
22、ThreadLocal 引发的内存泄漏问题
Entry 的 key 是弱引用,那么就是说 ThreadLocal 容易被 GC 回收掉。
当 key 被 GC 为 null,但是 Entry 本身被 Map 引用着,而 Entry 又 引用着 不为null 的 Value。
我们线程一直存活,且一直不调用 get,set, remove 方法,那么这条链一直存在,不会被 GC 回收,导致内存泄漏。
所以最好一旦数据不使用,最好直接 remove 掉。
其实,ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施:在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有key为null的value。
ThreadLocal 什么时候可能会出现线程不安全问题。
当 Entry 的 value ,为共享变量的时候,比如加了 static 。那么就会出现不安全问题。
23、JMM
Java的内存模型是分为主内存和线程的工作内存两部分进行工作的,
工作内存从主内存read数据,
load到工作内存中,
线程对数据进行use,
然后将数据assign到工作内存,
从工作内存store处理过的数据,
最后将新数据write进主内存。
24、硬件层面原理
主内存
CPU寄存器:
CPU写缓冲器:暂存修改的变量,发送消息给总线通知就完事。等到总线通知其他处理器全部返回了收到ack,它会修改高速缓存。优化了CPU不需要串行等待其他CPU返回 ack,再写入高速缓存。
CPU无效队列:缓存失效变量,立刻返回ack给总线收到消息。优化了CPU不需要串行等待变更高速缓存,再发送ack通知到总线。
CPU高速缓存:缓存着主内存的数据
总线:接受发送通知每个处理器
工作流程
- 某个CPU 对本地内存数据需要修改,先在写缓存器修改,然后发送 invalidate 消息到总线。其他CPU处理器会不停的嗅探总线,当嗅探到变量需要变更,会将变量放到无效队列里,返回 invalidate ack 消息给总线。之后会根据无效队列,将对应高速缓存变量标记为失效标记 I。
- 当 CPU 收到所有其他的CPU发来的 invalidate ack 消息,就会从 写缓冲器 取出数据,锁定高速缓存中的条目 标记 E 独占锁,然后将写缓存器的数据写到 高速缓存(主内存),标记为 M。
解决可见性:
Store屏障(flush操作):强制要求写操作必须阻塞等待到其他的处理器返回 invalidate ack 之后,加锁,然后修改数据到 高速缓存。效果就是,要求一个西曹佐必须刷到高速缓存(或者主内存),不能停留在写缓存中。
Load屏障(refresh操作):从高速缓存中读取数据的时候,如果发现无效队列里面有一个 invalidate 消息,此时会立马强制根据那个 invalidate 消息把自己本地高速缓存的数据,设置为 I(过期),然后就可以强制从其他处理器的高速缓存中加载最新的值。
解决有序性:
Acquire屏障(StoreStore屏障):会强制让写数据的操作全部按照顺序写入写缓冲器里,他不会让你第一个写到写缓冲器去,第二个写直接修改高速缓存。
Resource屏障(StoreLoad屏障):他会强制先将写缓冲器里的数据写入高速缓存中,接着读数据的时候强制清空无效队列,对立面的 validate 消息全部过期掉高速缓存中的条目,然后强制从主内存里重新加载数据。
25、你知道Java内存模型中的原子性、有序性、可见性是什么吗?
可见性:**是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的,**也就是一个线程修改的结果,另一个线程马上就能看到。(加 Load屏障执行 refresh指令,加Store屏障执行 flush操作。)
原子性:线程必须是独立执行的,没有人影响我的,一定是我自己执行成功之后,别人才可以执行。(ObjectMonitor对象 加锁)
有序性:
java ->javac(静态编译)->class -> jit(动态编译)-> 机器码指令 -> 处理器。 (为了加速程序的执行速度,在一定规则的情况下发生指令重排序。 javac, jit ,处理器 三个层次都会发生指令重排。)
代码必须是按顺序执行的,不能重排序。(在进入代码加Acquire屏障和之后加Release屏障,保证代码块的不和屏障之外的代码发送指令重排)
synchronized关键字,同时可以保证原子性、可见性以及有序性的
- 原子性:加锁和释放锁的机制,ObjectMonitor,保证只有一个线程能进入同步块。(加锁和释放锁)
- 可见性,在monitorenter 之后 Load 屏障, monitorexit 之后加 Store 屏障,他在同步代码块对变量做的写操作,都会在释放锁的时候,全部强制执行flush操作,在进入同步代码块的时候,对变量的读操作,全部会强制执行refresh的操作。(内存屏障+MESI协议。)
- 有序性,同步开始加 Acquire 屏障 ,同步之后加 Release 屏障,通过内存屏障来保证同步代码内部的指令可以重排,但是同步代码块内部的指令和外面的指令是不能重排的。(内存屏障)
26、volatile关键字有什么作用?
先说jmm抽象原理 -> 硬件原理 -> MESI协议 -> 内存屏障保证了可见性(load屏障 refresh操作,store屏障 flush操作),有序性(acquire,release屏障 保证指令之间不能重排)-> 原子性(ObjectMonitor 结构,加锁原理。)
讲清楚volatile关键字,直接问你volatile关键字的理解,对前面的一些问题,这个时候你就应该自己去主动从内存模型开始讲起,原子性、可见性、有序性的理解,volatile关键字的原理
volatile关键字是用来解决可见性和有序性,大量用在开源项目。主要用在有读有写的多线程场景。
- **可见性:**volatile 读之前加 Load 屏障, 写 之后加 Store 屏障,保证读之前 MESI缓存一致性协议执行 refresh操作,写之后执行 flush 操作。
- **有序性:**volatile修饰的变量读写前面加 Acquire 屏障和之后加 Release 屏障,保证代码块的不和屏障之外的代码发送指令重排,避免前后的读写操作发生指令重排。
27、double check单例实践
线程1: MyObject myObj = new MyObject(); => 这个是我们自己写的一行代码
步骤1:以MyObject类作为原型,给他的对象实例分配一块内存空间,objRef就是指向了分配好的内存空间的地址的引用,指针
objRef = allocate(MyObject.class);
步骤2:就是针对分配好内存空间的一个对象实例,执行他的构造函数,对这个对象实例进行初始化的操作,执行我们自己写的构造函数里的一些代码,对各个实例变量赋值,初始化的逻辑
invokeConstructor(objRef);
步骤3:上两个步骤搞定之后,一个对象实例就搞定了,此时就是把objRef指针指向的内存地址,赋值给我们自己的引用类型的变量,myObj就可以作为一个类似指针的概念指向了MyObject对象实例的内存地址
myObj = objRef;
有可能JIT动态编译为了加速程序的执行速度,因为步骤2是在初始化一个对象实例,这个步骤是有可能很耗时的,比如说你可能会在里面执行一些网络的通信,磁盘文件的读写,都有可能JIT动态编译,指令重排,为了加速程序的执行性能和效率,可能会重排为,步骤1 -> 步骤3 -> 步骤2
线程1,刚刚执行完了步骤1和步骤3,步骤2还没执行,此时myObj已经不是null了,但是MyObject对象实例内部的resource是null
线程2,直接调用myObj.execute()方法, 此时内部会调用resource.execute()方法,但是此时resource是null,直接导致空指针
如果加了 Volatile 关键字,步骤1,2,3是需要一起完成。其他线程才可使用。
防止指令重排序有什么好处?如何实现防止指令重排序的?
防止指令重排序好处:保证代码的有序性。规则制定了在一些特殊情况下,不允许编译器、指令器对你写的代码进行指令重排,必须保证你的代码的有序性。(这句话要说,然后找个几条happen-before 原则说说就可以了。)
happen-before 原则
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作,比如说在代码里有先对一个lock.lock(),lock.unlock(),lock.lock()
- volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个volatile变量的读操作,volatile变量写,再是读,必须保证是先写,再读
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作,thread.start(),thread.interrupt()
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
并发编程面试合辑 word文档下载地址:链接:https://pan.baidu.com/s/1nwlBO2tYXDDl7OjGhs4e4Q
提取码:1111
爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
分布式中间件面试合辑
分布式调用RPC篇
1 什么是 RPC ?
- RPC (Remote Procedure Call)即远程过程调用,是分布式系统常见的一种通信方法。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。
- 除 RPC 之外,常见的多系统数据交互方案还有分布式消息队列、HTTP 请求调用、数据库和分布式缓存等。
- 其中 RPC 和 HTTP 调用是没有经过中间件的,它们是端到端系统的直接数据交互。
简单的说
- RPC就是从一台机器(客户端)上通过参数传递的方式调用另一台机器(服务器)上的一个函数或方法(可以统称为服务)并得到返回的结果。
- RPC会隐藏底层的通讯细节(不需要直接处理Socket通讯或Http通讯)。
- 客户端发起请求,服务器返回响应(类似于Http的工作方式)RPC在使用形式上像调用本地函数(或方法)一样去调用远程的函数(或方法)。
2 为什么我们要用RPC
RPC 的主要目标是让构建分布式应用更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。为实现该目标,RPC 框架需提供一种透明调用机制让使用者不必显式的区分本地调用和远程调用。
3 RPC需要解决的三个问题
RPC要达到的目标:远程调用时,要能够像本地调用一样方便,让调用者感知不到远程调用的逻辑。
- Call ID映射。我们怎么告诉远程机器我们要调用哪个函数呢?在本地调用中,函数体是直接通过函数指针来指定的,我们调用具体函数,编译器就自动帮我们调用它相应的函数指针。但是在远程调用中,是无法调用函数指针的,因为两个进程的地址空间是完全不一样。所以,在RPC中,所有的函数都必须有自己的一个ID。这个ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个ID。然后我们还需要在客户端和服务端分别维护一个 {函数 <–> Call ID} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的Call ID必须相同。当客户端需要进行远程调用时,它就查一下这个表,找出相应的Call ID,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
- 序列化和反序列化。客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用C++,客户端用Java或者Python)。这时候就需要客户端把参数先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
- 网络传输。远程调用往往是基于网络的,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把Call ID和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。尽管大部分RPC框架都使用TCP协议,但其实UDP也可以,而gRPC干脆就用了HTTP2。Java的Netty也属于这层的东西。
4 实现高可用RPC框架需要考虑到的问题
- 既然系统采用分布式架构,那一个服务势必会有多个实例,要解决如何获取实例的问题。所以需要一个服务注册中心,比如在Dubbo中,就可以使用Zookeeper作为注册中心,在调用时,从Zookeeper获取服务的实例列表,再从中选择一个进行调用;
- 如何选择实例呢?就要考虑负载均衡,例如dubbo提供了4种负载均衡策略;
- 如果每次都去注册中心查询列表,效率很低,那么就要加缓存;
- 客户端总不能每次调用完都等着服务端返回数据,所以就要支持异步调用;
- 服务端的接口修改了,老的接口还有人在用,这就需要版本控制;
- 服务端总不能每次接到请求都马上启动一个线程去处理,于是就需要线程池;
5 理论结构模型
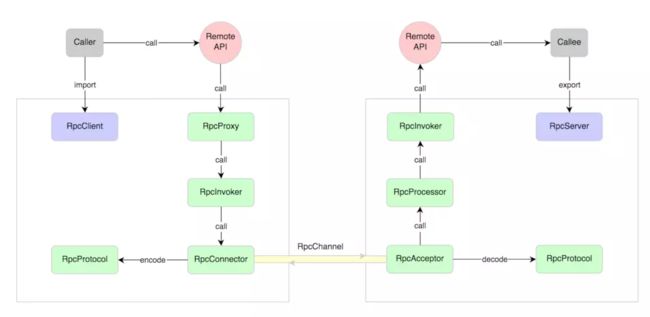
RPC 服务端通过RpcServer去导出(export)远程接口方法,而客户端通过RpcClient去导入(import)远程接口方法。客户端像调用本地方法一样去调用远程接口方法,RPC 框架提供接口的代理实现,实际的调用将委托给代理RpcProxy。代理封装调用信息并将调用转交给RpcInvoker去实际执行。在客户端的RpcInvoker通过连接器RpcConnector去维持与服务端的通道RpcChannel,并使用RpcProtocol执行协议编码(encode)并将编码后的请求消息通过通道发送给服务端。
RPC 服务端接收器RpcAcceptor接收客户端的调用请求,同样使用RpcProtocol执行协议解码(decode)。
解码后的调用信息传递给RpcProcessor去控制处理调用过程,最后再委托调用给RpcInvoker去实际执行并返回调用结果。
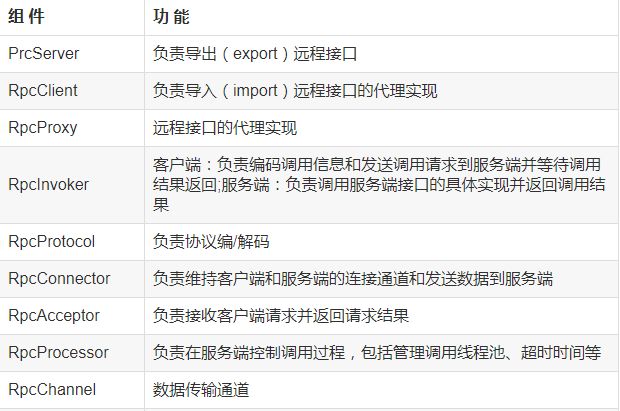
分布式限流Zookeeper篇
1.ZooKeeper是什么
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是Google 的 Chubby 一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
客户端的读请求可以被集群中的任意一台机器处理,如果读请求在节点上注册了监听器,这个监听器也是由所连接的 zookeeper 机器来处理。对于写请求,这些请求会同时发给其他 zookeeper 机器并且达成一致后,请求才会返回成功。因此,随着 zookeeper 的集群机器增多,读请求的吞吐会提高但是写请求的吞吐会下降。
有序性是 zookeeper 中非常重要的一个特性,所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,这个时间戳称为 zxid(Zookeeper Transaction Id)。而读请求只会相对于更新有序,也就是读请求的返回 结果中会带有这个 zookeeper 最新的 zxid。
2.ZooKeeper提供了什么
1、文件系统
2、通知机制
3.Zookeeper文件系统
Zookeeper 提供一个多层级的节点命名空间(节点称为 znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点 可以存放数据而目录节点不行。Zookeeper 为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得 Zookeeper 不能用于存放大量的数据,每个节点的存放数据上限为 1M。
4.说一说四种类型的znode
1、PERSISITENT-持久化目录节点
客户端与 zookeeper 断开连接后,该节点依旧存在
2、PERSISITENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与 zookeeper 断开连接后,该节点依旧存在,只是 Zookeeper 给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与 zookeeper 断开连接后,该节点被删除
4、EPHEMERALSE_QUENTIAL-临时顺序编号目录节点
客户端与 zookeeper 断开连接后,该节点被删除,只是 Zookeeper 给该节点名称进行顺序编号
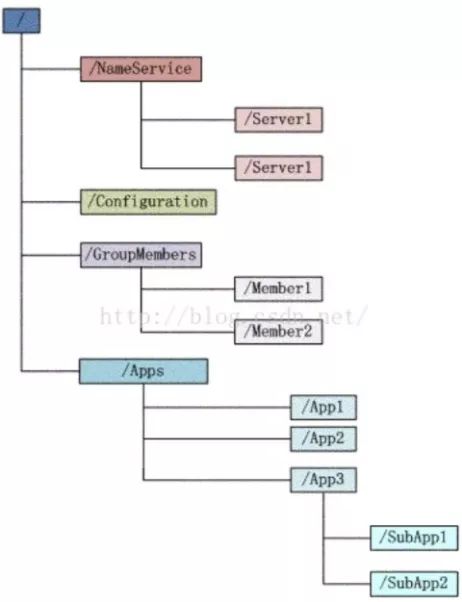
5.Zookeeper通知机制
client 端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些 client 会收到 zk 的通知,然后 client 可以根据 znode 变化来做出业务上的改变等。
6.Zookeeper做了什么
1、命名服务
2、配置管理
3、集群管理
4、分布式锁
5、队列管理
7.zk的命名服务(文件系统)
命名服务是指通过指定的名字来获取资源或者服务的地址,利用 zk 创建一个全局的路径,即是唯一的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
8.zk的配置管理(文件系统、通知机制)
程序分布式的部署在不同的机器上,将程序的配置信息放在 zk 的 znode 下,当有配置发生改变时,也就是 znode 发生变化时,可以通过改变 zk 中某个目录节点的内容,利用 watcher 通知给各个客户端,从而更改配置。
9.Zookeeper集群管理(文件系统、通知机制)
所谓集群管理不外乎两点:是否有机器退出和加入、选举 master。
对于第一点,所有机器约定在父目录下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper 的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。
新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount 又有了,对于第二点,我们稍微改变 一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为 master 就好。
10.Zookeeper分布式锁(文件系统、通知机制)
有了 zookeeper 的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将 zookeeper 上的一个 znode 看作是一把锁,通过createznode 的方式来实现。所有客户端都去创建/distribute_lock节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock节点就释放出锁。
对于第二类,/distribute_lock已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
11.获取分布式锁的流程

在获取分布式锁的时候在 locker 节点下创建临时顺序节点,释放锁的时候删除该临时节点。客户端调用 createNode 方法在 locker 下创建临时顺序节点,
然后调用 getChildren(“locker”)来获取 locker 下面的所有子节点,注意此时不用设置任何 Watcher。客户端获取到所有的子节点 path 之后,如果发现自己创建的节点在所有创建的子节点序号最小,那么就认为该客户端获取到了锁。如果发现自己创建的节点并非 locker 所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,然后对其调用 exist()方法,同时对其注册事件监听器。之后,让这个被关注的节点删除,则客户端的 Watcher 会收到相应通知,此时再次判断自己创建的节点是否是 locker 子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。当前这个过程中还需要许多的逻辑判断。
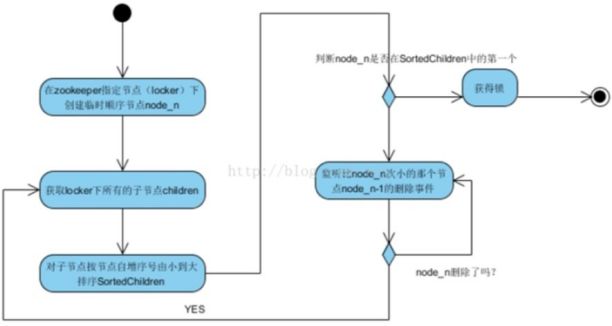
代码的实现主要是基于互斥锁,获取分布式锁的重点逻辑在于BaseDistributedLock,实现了基于 Zookeeper 实现分布式锁的细节。
12.Zookeeper队列管理(文件系统、通知机制)
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号, 出列按编号。在特定的目录下创建 PERSISTENT_SEQUENTIAL 节点,创建成功时 Watcher 通知等待的队列,队列删除序列号最小的节点用以 消费。此场景下 Zookeeper 的 znode 用于消息存储,znode 存储的数据就是消息队列中的消息内容,SEQUENTIAL 序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必担心队列消息的丢失问题。
13.Zookeeper数据复制
Zookeeper 作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能:让客户端本地访问就近的节点,提高用户访问速度。从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。
对 zookeeper 来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立 observer 的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
14.Zookeeper工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个 Server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 Server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 Server 具有相同的系统状态。
15. Zookeeper是如何保证事务的顺序一致性的
zookeeper 采用了递增的事务 Id 来标识,所有的 proposal(提议)都在被提出的时候加上了 zxid,zxid 实际上是一个 64 位的数字,高 32 位是 epoch(时期;纪元;世;新时代)用来标识 leader 是否发生改变,如果有 新的leader 产生出来,epoch 会自增,低 32 位用来递增计数。当新产生proposal 的时候,会依据数据库的两阶段过程,首先会向其他的 server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会 开始执行。
16.Zookeeper下Server工作状态
每个Server 在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻LEADING:当前Server即为选举出来的leaderFOLLOWING:leader已经选举出来,当前Server与之同步
17.zookeeper是如何选取主leader的
当leader 崩溃或者 leader 失去大多数的 follower,这时 zk 进入恢复模式,恢复模式需要重新选举出一个新的 leader,让所有的 Server 都恢复到一个正确的状态。Zk 的选举算法有两种:
一种是基于basic paxos 实现的,
另外一种是基于 fast paxos 算法实现的。系统默认的选举算法为 fast paxos。
1、Zookeeper 选主流程(basic paxos)
(1)选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
(2)选举线程首先向所有Server发起一次询问(包括自己);
(3)选举线程收到回复后,验证是否是自己发起的询问(验证 zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
(4)收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
(5)线程将当前zxid最大的Server设置为当前Server要推荐的Leader,
(6)如果此时获胜的 Server 获得 n/2 + 1 的 Server 票数,设置当前推荐的 leader 为获胜的 Server,将根据获胜的 Server 相关信息设置自己的状态,否则, 继续这个过程,直到 leader 被选举出来。通过流程分析我们可以得出:要使 Leader 获得多数 Server 的支持,则 Server 总数必须是奇数 2n+1,且存活的 Server 的数目不得少于 n+1. 每个 Server 启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的 server 还会从磁盘快照中恢复数据和会话信息,zk 会记录事务日志并定期进行快照, 方便在恢复时进行状态恢复。
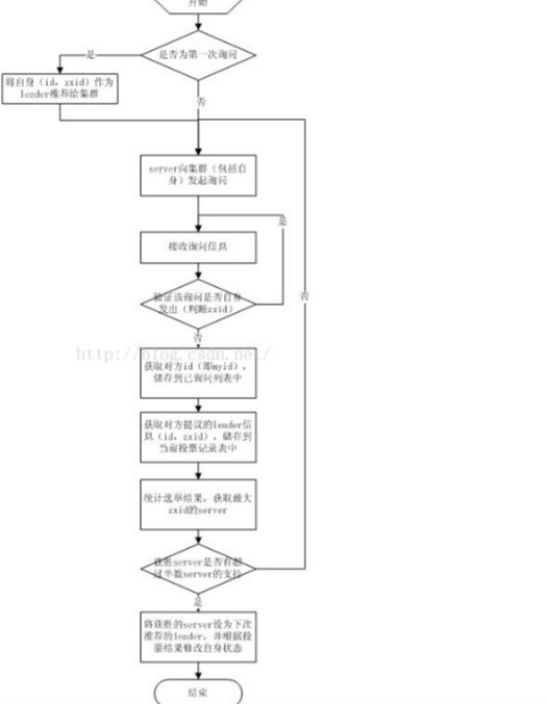
2、Zookeeper 选主流程(basic paxos)
fast paxos 流程是在选举过程中,某 Server 首先向所有 Server 提议自己要成为 leader,当其它 Server 收到提议以后,解决 epoch 和 zxid 的冲突, 并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流 程,最后一定能选举出 Leader。
18.Zookeeper同步流程
选完 Leader 以后,zk 就进入状态同步过程。
1、Leader 等待 server 连接;
2、Follower连接leader,将最大的zxid发送给leader;
3、Leader根据follower的zxid 确定同步点;
4、完成同步后通知 follower 已经成为 uptodate 状态;

19.分布式通知和协调实现方式
对于系统调度来说:操作人员发送通知实际是通过控制台改变某个节点的状态,然后zk将这些变化发送给注册了这个节点的watcher的所有客户端。
对于执行情况汇报:每个工作进程都在某个目录下创建一个临时节点。并携带工作的进度数据,这样汇总的进程可以监控目录子节点的变化获得工作进度的实时的全局情况。
20.机器中为什么会有leader
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,于是就需要进行 leader 选举。
21.zk节点宕机如何处理
Zookeeper 本身也是集群,推荐配置不少于 3 个服务器。Zookeeper 自身也要保证当一个节点宕机时,其他节点会继续提供服务。
- 如果是一个Follower 宕机,还有 2 台服务器提供访问,因为 Zookeeper上的数据是有多个副本的,数据并不会丢失;
- 如果是一个 Leader 宕机,Zookeeper 会选举出新的 Leader。
ZK 集群的机制是只要超过半数的节点正常,集群就能正常提供服务。只有在 ZK 节点挂得太多,只剩一半或不到一半节点能工作,集群才失效。所以
- 3 个节点的 cluster 可以挂掉 1 个节点(leader 可以得到 2 票>1.5)
- 2个节点的cluster就不能挂掉任何1 个节点了(leader可以得到1 票<=1)
22. Zookeeper负载均衡和nginx负载均衡区别
zk 的负载均衡是可以调控,nginx 只是能调权重,其他需要可控的都需要自己写插件;但是 nginx 的吞吐量比 zk 大很多,应该说按业务选择用哪种方式。
23.Zookeeperwatch机制
Watch 机制官方声明:一个 Watch 事件是一个一次性的触发器,当被设置了 Watch 的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch 的客户端,以便通知它们。
Zookeeper 机制的特点:
1、一次性触发数据发生改变时,一个 watcher event 会被发送到 client,但是 client 只会收到一次这样的信息。
2、watcher event异步发送watcher的通知事件从server发送到client 是异步的,这就存在一个问题,不同的客户端和服务器之间通过socket进行通信,由于网络延迟或其他因素导致客户端在不通的时刻监听到事件,由于 Zookeeper 本身提供了 ordering guarantee,即客户端监听事件后, 才会感知它所监视 znode 发生了变化。所以我们使用 Zookeeper 不能期望能够监控到节点每次的变化。Zookeeper 只能保证最终的一致性,而无法保证强一致性。
3、数据监视 Zookeeper 有数据监视和子数据监视 getdata() and exists()设置数据监视,getchildren()设置了子节点监视。
4、注册 watchergetData、exists、getChildren
5、触发watcher create、delete、setData
6、setData()会触发 znode 上设置的 data watch(如果 set 成功的话)。一个成功的 create()操作会触发被创建的 znode 上的数据 watch,以及其父节点上的 child watch。而一个成功的 delete()操作将会同时触发一个 znode 的 data watch 和 child watch(因为这样就没有子节点了),同时也会触发其父节点的 child watch。
7、当一个客户端连接到一个新的服务器上时,watch 将会被以任意会话事件触发。当与一个服务器失去连接的时候,是无法接收到 watch 的。而当 client 重新连接时,如果需要的话,所有先前注册过的 watch,都会被重新注册。通常这是完全透明的。只有在一个特殊情况下,watch 可能会丢失:对于一个未创建的 znode 的 exist watch,如果在客户端断开连接期间被创建了,并且随后在客户端连接上之前又删除了,这种情况下,这个watch 事件可能会被丢失。
8、Watch是轻量级的,其实就是本地JVM的Callback,服务器端只是存了是否有设置了Watcher 的布尔类型
分布式负载均衡Nginx篇
1、请解释一下什么是 Nginx
Nginx 是一个 web 服务器和反向代理服务器,用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。
2、请列举 Nginx 的一些特性
Nginx 服务器的特性包括:
反向代理/L7 负载均衡器嵌入式 Perl 解释器
动态二进制升级
可用于重新编写URL,具有非常好的 PCRE 支持
3、请解释 Nginx 如何处理 HTTP 请求
Nginx 使用反应器模式。主事件循环等待操作系统发出准备事件的信号, 这样数据就可以从套接字读取,在该实例中读取到缓冲区并进行处理。单个线程可以提供数万个并发连接。
4、在 Nginx 中如何使用未定义的服务器名称来阻止处理请求
只需将请求删除的服务器就可以定义为:
Server {listen 80;server_name “ “ ;return 444;
}
这里,服务器名被保留为一个空字符串,它将在没有“主机”头字段的情况下匹配请求,而一个特殊的Nginx的非标准代码444被返回,从而终止连接
5、 使用“反向代理服务器”的优点是什么
反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和 web 服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web 托管服务时。
6、请列举 Nginx 服务器的最佳用途
Nginx 服务器的最佳用法是在网络上部署动态 HTTP 内容,使用 SCGI、WSGI 应用程序服务器、用于脚本的 FastCGI 处理程序。它还可以作为负载均衡器。
7、请解释 Nginx 服务器上的 Master 和 Worker 进程分别是什么
Master 进程:读取及评估配置和维持
Worker 进程:处理请求
8、请解释你如何通过不同于 80 的端口开启 Nginx
为了通过一个不同的端口开启Nginx,你必须进入/etc/Nginx/sites- enabled/,如果这是默认文件,那么你必须打开名为“default”的文件。编辑文件,并放置在你想要的端口:
Like server { listen 81; }
9、请解释是否有可能将 Nginx 的错误替换为 502 错误、503
502 =错误网关 503 =服务器超载有可能,但是可以确保fastcgi_intercept_errors被设置为ON,并使用错误页面指令。
Location / {fastcgi_pass 127.0.01:9001;fastcgi_intercept_error s on;
error_page 502 =503/error_page.html;#...}
10、在 Nginx 中解释如何在 URL 中保留双斜线
要在URL中保留双斜线,就必须使用merge_slashes_off;
语法:merge_slashes[on/off]
默认值: merge_slashes on
环境:http,server
11、请解释ngx_http_upstream_module的作用是什么
用于定义可通过 fastcgi 传递、proxy 传递、uwsgi 传递、memcached 传递和 scgi 传递指令来引用的服务器组。
12、请解释什么是 C10K 问题
C10K 问题是指无法同时处理大量客户端(10,000)的网络套接字。
13、请陈述stub_status和sub_filter 指令的作用是什么
stub_status指令:该指令用于了解 Nginx 当前状态的当前状态,如当前的活动连接,接受和处理当前读/写/等待连接的总数
Sub_filter指令:它用于搜索和替换响应中的内容,并快速修复陈旧的数据
14、解释 Nginx 是否支持将请求压缩到上游
您可以使用 Nginx 模块 gunzip 将请求压缩到上游。gunzip 模块是一个过滤器,它可以对不支持“gzip”编码方法的客户机或服务器使用“内容编 码:gzip”来解压缩响应。
15、解释如何在 Nginx 中获得当前的时间
要获得Nginx的当前时间,必须使用SSI模块、 d a t e _ g m t 和 date\_gmt和 date_gmt和date_local的变量
Proxy_set_header THE-TIME $date_gmt;
16、用 Nginx 服务器解释-s 的目的是什么
用于运行 Nginx -s 参数的可执行文件。
17、解释如何在 Nginx 服务器上添加模块
在编译过程中,必须选择 Nginx 模块,因为 Nginx 不支持模块的运行时间选择
分布式消息通讯RabbitMQ篇
1、RabbitMQ 中的 broker 是指什么cluster 又是指什么
broker 是指一个或多个 erlang node 的逻辑分组,且 node 上运行着RabbitMQ 应用程序。cluster 是在 broker 的基础之上,增加了 node 之间共享元数据的约束。
2、什么是元数据元数据分为哪些类型包括哪些内容与 cluster 相关的元数据有哪些元数据是如何保存的元数据在 cluster 中是如何分布的
在非 cluster 模式下,元数据主要分为 Queue 元数据(queue 名字和属性等)、 Exchange 元数据(exchange 名字、类型和属性等)、Binding 元数据(存放路由关系的查找表)、Vhost 元数据(vhost 范围内针对前三者的名字空间约束和安全属性设置)。在 cluster 模式下,还包括 cluster 中 node 位置信息和 node 关系信息。元数据按照 erlang node 的类型确定是仅保存于RAM 中,还是同时保存在 RAM 和 disk 上。元数据在 cluster 中是全 node 分布的。
3、RAM node 和 disk node 的区别
RAM node 仅将 fabric(即 queue、exchange 和 binding等 RabbitMQ基础构件)相关元数据保存到内存中,但 disk node 会在内存和磁盘中均进行存储。RAM node 上唯一会存储到磁盘上的元数据是 cluster 中使用的 disk node 的地址。要求在 RabbitMQ cluster 中至少存在一个 disk node 。
4、RabbitMQ 上的一个 queue 中存放的 message 是否有数量限制
可以认为是无限制,因为限制取决于机器的内存,但是消息过多会导致处理效率的下降。
5、vhost 是什么起什么作用
vhost 可以理解为虚拟 broker ,即 mini-RabbitMQ server。其内部均含有独立的 queue、exchange 和 binding 等,但最最重要的是,其拥有独立的权限系统,可以做到 vhost 范围的用户控制。当然,从 RabbitMQ 的全局角度,vhost 可以作为不同权限隔离 的手段(一个典型的例子就是不同的应用可以跑在不同的 vhost 中)。
6、在单 node 系统和多 node 构成的 cluster 系统中声明 queue、exchange 以及进行 binding 会有什么不同
当你在单node 上声明 queue 时,只要该 node 上相关元数据进行了变更,你就会得到 Queue.Declare-ok 回应;而在 cluster 上声明 queue ,则要求 cluster 上的全部 node 都要进行元数据成功更新,才会得到Queue.Declare-ok 回应。另外,若 node 类型为 RAM node 则变更的数据仅保存在内存中,若类型为 disk node 则还要变更保存在磁盘上的数据。
7、客户端连接到 cluster 中的任意 node 上是否都能正常工作
是的。客户端感觉不到有何不同。
8、若 cluster 中拥有某个 queue 的 owner node 失效了且该 queue 被声明具有 durable 属性是否能够成功从其他 node 上重新声明该queue
不能,在这种情况下,将得到 404 NOT_FOUND 错误。只能等 queue 所属的 node 恢复后才能使用该 queue 。但若该 queue 本身不具有 durable 属性,则可在其他 node 上重新声明。
9、cluster 中 node 的失效会对 consumer 产生什么影响若是在cluster 中创建了 mirrored queue 这时 node 失效会对 consumer 产生什么影响
若是 consumer 所连接的那个 node 失效(无论该 node 是否为 consumer 所订阅 queue 的 owner node),则 consumer 会在发现 TCP 连接断开时, 按标准行为执行重连逻辑,并根据“Assume Nothing”原则重建相应的fabric 即可。若是失效的 node 为 consumer 订阅 queue 的owner node,则 consumer 只能通过 Consumer Cancellation Notification 机制来检测与该 queue 订阅关系的终止,否则会出现傻等却没有任何消息来 到的问题。
10、能够在地理上分开的不同数据中心使用 RabbitMQ cluster 么
不能。
第一,你无法控制所创建的queue实际分布在cluster里的哪个node 上 (一般使用HAProxy+cluster 模型时都是这样),这可能会导致各种跨地域访问时的常见问题;
第二,Erlang的OTP通信框架对延迟的容忍度有限,这可能会触发各种超时,导致业务疲于处理;
第三,在广域网上的连接失效问题将导致经典的“脑裂”问题,而
RabbitMQ 目前无法处理(该问题主要是说 Mnesia)。
11、为什么 heavy RPC 的使用场景下不建议采用 disk node
heavy RPC 是指在业务逻辑中高频调用 RabbitMQ 提供的 RPC 机制,导致不断创建、销毁 reply queue ,进而造成 disk node 的性能问题(因为会针对元数据不断写盘)。所以在使用 RPC 机制时需要考虑自身的业务场景。
12、向不存在的 exchange 发 publish 消息会发生什么向不存在的queue 执行consume 动作会发生什么
都会收到 Channel.Close 信令告之不存在(内含原因 404 NOT_FOUND)。
13、routing_key和binding_key的最大长度是多少
255字节
14、RabbitMQ 允许发送的 message 最大可达多大
根据 AMQP 协议规定,消息体的大小由 64-bit 的值来指定,所以你就可以知道到底能发多大的数据了。
15、什么情况下 producer 不主动创建 queue 是安全的
1.message是允许丢失的;
2. 实现了针对未处理消息的 republish 功能(例如采用 Publisher Confirm 机制)。
16、“dead letter”queue 的用途
当消息被 RabbitMQ server 投递到 consumer 后,但 consumer 却通过Basic.Reject 进行了拒绝时(同时设置 requeue=false),那么该消息会被放入“dead letter”queue 中。该 queue 可用于排查 message 被 reject 或undeliver 的原因。
17、为什么说保证 message 被可靠持久化的条件是 queue 和 exchange
具有durable 属性同时 message 具有 persistent 属性才行
binding 关系可以表示为 exchange – binding – queue 。从文档中我们知道,若要求投递的 message 能够不丢失,要求 message 本身设置persistent 属性,要求 exchange 和 queue 都设置 durable 属性。其实这问题可以这么想,若 exchange 或 queue 未设置 durable 属性,则在其crash 之后就会无法恢复,那么即使 message 设置了 persistent 属性,仍然存在 message 虽然能恢复但却无处容身的问题;同理,若 message 本身未设置 persistent 属性,则 message 的持久化更无从谈起。
18、什么情况下会出现 blackholed 问题
blackholed 问题是指,向 exchange 投递了 message ,而由于各种原因导致该 message 丢失,但发送者却不知道。可导致 blackholed 的情况:
1.向未绑定queue的exchange发送message;
2.exchange以binding_key key_A绑定了queue queue_A,但向该exchange 发送 message 使用的routing_key却是key_B
19、如何防止出现blackholed问题
没有特别好的办法,只能在具体实践中通过各种方式保证相关 fabric 的存在。另外,如果在执行 Basic.Publish 时设置 mandatory=true ,则在遇到可能出现 blackholed 情况时,服务器会通过返回 Basic.Return 告之当前message 无法被正确投递(内含原因 312 NO_ROUTE)。
20、Consumer Cancellation Notification 机制用于什么场景
用于保证当镜像 queue 中 master 挂掉时,连接到 slave 上的 consumer 可以收到自身 consume 被取消的通知,进而可以重新执行 consume 动作从新选出的 master 出获得消息。若不采用该机制,连接到 slave 上的consumer 将不会感知 master 挂掉这个事情,导致后续无法再收到新master 广播出来的 message 。另外,因为在镜像 queue 模式下,存在将message 进行 requeue 的可能,所以实现 consumer 的逻辑时需要能够正确处理出现重复 message 的情况。
21、Basic.Reject 的用法是什么
该信令可用于 consumer 对收到的 message 进行 reject 。若在该信令中设置 requeue=true,则当 RabbitMQ server 收到该拒绝信令后,会将该message 重新发送到下一个处于 consume 状态的 consumer 处(理论上仍可能将该消息发送给当前 consumer)。若设置 requeue=false ,则RabbitMQ server 在收到拒绝信令后,将直接将该 message 从 queue 中移除。
另外一种移除queue 中 message 的小技巧是,consumer 回复 Basic.Ack但不对获取到的 message 做任何处理。而Basic.Nack 是对 Basic.Reject 的扩展,以支持一次拒绝多条 message的能力。
22、为什么不应该对所有的 message 都使用持久化机制
首先,必然导致性能的下降,因为写磁盘比写 RAM 慢的多,message 的吞吐量可能有 10 倍的差距。
其次,message 的持久化机制用在RabbitMQ 的内置 cluster 方案时会出现“坑爹”问题。矛盾点在于,若message 设置了 persistent 属性,但 queue 未设置 durable 属性,那么当该 queue 的 owner node 出现异常后,在未重建该 queue 前,发往该queue 的 message 将被 blackholed ;若 message 设置了 persistent 属性, 同时 queue 也设置了 durable 属性,那么当 queue 的 owner node 异常且无法重启的情况下,则该 queue 无法在其他 node 上重建,只能等待其owner node 重启后,才能恢复该 queue 的使用,而在这段时间内发送给该 queue 的 message 将被 blackholed 。
所以,是否要对 message 进行持久化,需要综合考虑性能需要,以及可能遇到的问题。若想达到100,000条/秒以上的消息吞吐量(单 RabbitMQ 服务器),则要么使用其他的方式来确保 message 的可靠 delivery ,要么使用非常快速的存储系统以支持全持久化(例如使用 SSD)。另外一种处理原则是:仅对关键消息作持久化处理(根据业务重要程度),且应该保证关键消息的量不会导致性能瓶颈。
23、RabbitMQ 中的 cluster、mirrored queue以及 warrens 机制分别用于解决 什么问题存在哪些问题
cluster是为了解决当 cluster 中的任意 node 失效后,producer 和consumer 均可以 通过其他 node 继续工作,即提高了可用性;另外可以通过增加 node 数量增加 cluster 的消息吞吐量的目的。cluster 本身不负责message 的可靠性问题(该问题由 producer 通 过各种机制自行解决);cluster 无法解决跨数据中心的问题(即脑裂问题)。
另外,在 cluster 前使用 HAProxy 可以解决 node 的选择问题,即业务无需知道 cluster 中多个 node 的 ip 地址。可以利用 HAProxy 进行失效 node 的探测,可以作负载均衡。
Mirrored queue 是为了解决使用 cluster 时所创建的 queue 的完整信息仅存在于单一 node 上的问题,从另一个角度增加可用性。若想正确使用该功能,需要保证:
1.consumer 需要支持 Consumer Cancellation Notification 机制;
2.consumer 必须能够正确处理重复 message 。
Warrens是为了解决 cluster 中 message 可能被 blackholed 的问题,即不能接受 producer 不停 republish message 但 RabbitMQ server 无回应的情况。
Warrens 有两种构成方式:
一种模型是两台独立的 RabbitMQ server + HAProxy ,其中两个 server 的状态分别为 active 和 hot-standby 。该模型的特点为:两台 server 之间无任何数据共享和协议交互,两台 server 可以基于不同的 RabbitMQ 版本。
另一种模型为两台共享存储的 RabbitMQ server + keepalived,其中两个server 的状态分别为 active 和 cold-standby。
该模型的特点为:两台 server 基于共享存储可以做到完全恢复,要求必须基于完全相同的 RabbitMQ 版本。
Warrens 模型存在的问题:
对于第一种模型,虽然理论上讲不会丢失消息,但若在该模型上使用持久化机制,就会出现这样一种情况:
即若作为 active 的 server 异常后,持久化在该 server 上的消息将暂时无法被 consume ,因为此时该 queue 将无法在作为 hot- standby 的 server 上被重建,所以,只能等到异常的 active server 恢复后,才能从其上的 queue 中获取相应的 message 进行处理。而对于业务来说,需要具有:a.感知 AMQP 连接断开后重建各种 fabric 的能力;b.感知 active server 恢复的能力;c.切换回 active server 的时机控制,以及切回后,针对 message 先后顺序产生的变化进行处理的能力。
对于第二种模型,因为是基于共享存储的模式,所以导致 active server 异常的条件,可能同样会导致 cold-standby server 异常;另外,在该模型下, 要求 active 和 cold-standby 的 server 必须具有相同的 node 名和 UID ,否则将产生访问权限问题;最后,由于该模型是冷备方案,故无法保证 cold- standby server 能在你要求的时限内成功启动。
分布式消息通讯Kafka篇
1.Kafka 的设计是什么样的呢
Kafka 将消息以 topic 为单位进行归纳
将向Kafka topic 发布消息的程序成为 producers.
将预订topics 并消费消息的程序成为 consumer.
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.producers通过网络将消息发送到Kafka集群,集群向消费者提供消息
2.数据传输的事物定义有哪三种
数据传输的事务定义通常有以下三种级别:
(1)最多一次:消息不会被重复发送,最多被传输一次,但也有可能一次不传输
(2)最少一次:消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
(3)精确的一次(Exactlyonce):不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的
3.Kafka判断一个节点是否还活着有那两个条件
(1)节点必须可以维护和ZooKeeper 的连接,Zookeeper通过心跳机制检查每个节点的连接
(2)如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久
4.producer是否直接将数据发送到broker的leader(主节点)
producer 直接将数据发送到 broker 的 leader(主节点),不需要在多个节点进行分发,为了帮助 producer 做到这点,所有的 Kafka 节点都可以及时的告知:哪些节点是活动的,目标 topic 目标分区的 leader 在哪。这样producer 就可以直接将消息发送到目的地了
5、Kafa consumer 是否可以消费指定分区消息
Kafa consumer消费消息时,向broker 发出"fetch"请求去消费特定分区的消息,consumer 指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset 的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
6、Kafka 消息是采用 Pull 模式还是 Push 模式
Kafka 最初考虑的问题是,customer 应该从 brokes 拉取消息还是 brokers 将消息推送到 consumer,也就是 pull 还 push。在这方面,Kafka 遵循了一种大部分消息系统共同的传统的设计:producer 将消息推送到 broker, consumer 从 broker 拉取消息.
一些消息系统比如 Scribe 和 Apache Flume 采用了 push 模式,将消息推送到下游的 consumer。这样做有好处也有坏处:由 broker 决定消息推送的速率,对于不同消费速率的 consumer 就不太好处理了。消息系统都致力于让 consumer 以最大的速率最快速的消费消息,但不幸的是,push 模式下,当 broker 推送的速率远大于 consumer 消费的速率时, consumer 恐怕就要崩溃了。最终Kafka 还是选取了传统的 pull 模式.
Pull 模式的另外一个好处是 consumer 可以自主决定是否批量的从 broker 拉取数据。Push 模式必须在不知道下游 consumer 消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer 崩溃而采用较低的推送速率,将可能导致一 次只推送较少的消息而造成浪费。Pull 模式下,consumer 就可以根据自己的消费能力去决定这些策略
Pull 有个缺点是,如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询, 直到新消息到 t 达。为了避免这点,Kafka 有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
7.Kafka存储在硬盘上的消息格式是什么
消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和 CRC32 校验码。
消息长度:4bytes(value:1+4+n)
版本号:1byte
CRC 校验码: 4 bytes
具体的消息:nbytes
8.Kafka高效文件存储设计特点:
(1).Kafka 把 topic 中一个 parition 大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
(2).通过索引信息可以快速定位 message 和确定 response 的最大大小。
(3).通过 index 元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。
(4).通过索引文件稀疏存储,可以大幅降低 index 文件元数据占用空间大小。
9.Kafka与传统消息系统之间有三个关键区别
(1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性
(3).Kafka 支持实时的流式处理
10.Kafka创建Topic时如何将分区放置到不同的Broker中
副本因子不能大于Broker的个数;
第一个分区(编号为0)的第一个副本放置位置是随机从brokerList选择的;
其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有 5 个 Broker,5个分区,假设第一个分区放在第四个 Broker上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推;
剩余的副本相对于第一个副本放置位置其实是由nextReplicaShift决定的,而这个数也是 随机产生的
11.Kafka新建的分区会在哪个目录下创建
在启动Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。
当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个目录下创建文件要用于存放数据。
但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件央中创建分区目录呢 答案是:Kafka 会在含有分区目录最少的文件央中创建新的分区目录,分区目录名为 Topic 名+分区 ID。注意,是分区文件要总数最少的目录,而不是磁盘使用量最少的目录!也就是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
12.partition的数据如何保存到硬盘
topic中的多个partition以文件央的形式保存到broker,每个分区序号从0递增,且消息有序
Partition文件下有多个segment(xxx.index,xxx.log)
segment文件里的大小和配置文件大小一致可以根据要求修改默认为1g如果大小大于1g时,会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名
13.kafka的ack机制
request.required.acks 有三个值 0 1 -1
0:生产者不会等待 broker 的 ack,这个延迟最低但是存储的保证最弱当server 挂掉的时候就会丢数据
1:服务端会等待 ack 值 leader 副本确认接收到消息后发送 ack 但是如果leader 挂掉后他不确保是否复制完成新 leader 也会导致数据丢失
-1:同样在1的基础上服务端会等所有的follower的副本受到数据后才会受到leader发出的ack,这样数据不会丢失
14.Kafka的消费者如何消费数据
消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置 等到下次消费时,他会接着上次位置继续消费
15.消费者负载均衡策略
一个消费者组中的一个分片对应一个消费者成员,他能保证每个消费者成员都能访问,如果组中成员太多会有空闲的成员
16.数据有序
一个消费者组里它的内部是有序的
消费者组与消费者组之间是无序的
17.kafaka生产数据时数据的分组策略
生产者决定数据产生到集群的哪个partition中每一条消息都是以(key,value)格式
Key是由生产者发送数据传入所以生产者(key)决定了数据产生到集群的哪个partition
分布式消息通讯ActiveMQ篇
1.什么是 ActiveMQ
activeMQ是一种开源的,实现了JMS1.1规范的,面向消息(MOM)的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信
2.ActiveMQ服务器宕机怎么办
这得从 ActiveMQ 的储存机制说起。在通常的情况下,非持久化消息是存储在内存中的,持久化消息是存储在文件中的,它们的最大限制在配置文件的节点中配置。但是,在非持久化消息堆积到一定程度,内存告急的时候,ActiveMQ 会将内存中的非持久化消息写入临时文件中,以腾出内存。虽然都保存到了文件里,但它和持久化消息的区别是,重启后持久化消息会从文件中恢复,非持久化的临 时文件会直接删除。那如果文件增大到达了配置中的最大限制的时候会发生什么我做了以下实验:
设置 2G 左右的持久化文件限制,大量生产持久化消息直到文件达到最大限制,此时生产者阻塞,但消费者可正常连接并消费消息,等消息消费掉 一部分,文件删除又腾出空间之后,生产者又可继续发送消息,服务自动恢复正常。
设置 2G 左右的临时文件限制,大量生产非持久化消息并写入临时文件, 在达到最大限制时,生产者阻塞,消费者可正常连接但不能消费消息,或 者原本慢速消费的消费者,消费突然停止。整个系统可连接, 但是无法提供服务,就这样挂了。
具体原因不详,解决方案:尽量不要用非持久化消息,非要用的话,将临时文件限制尽可能的调大。
3.丢消息怎么办
这得从 java 的 java.net.SocketException 异常说起。简单点说就是当网络发送方发送一堆数据,然后调用 close 关闭连接之后。这些发送的数据都在接收者的缓存里,接收者如果调用 read 方法仍旧能从缓存中读取这些数据,尽管对方已经关闭了连接。但是当接收者尝试发送数据时,由于此时连接已关闭,所以会发生异常,这个很好理解。不过需要注意的是,当发生 SocketException 后,原本缓存区中数据也作废了,此时接收者再次调用 read 方法去读取缓存中的数据,就会报 Software caused connection abort: recv failed 错误。
通过抓包得知,ActiveMQ 会每隔 10秒发送一个心跳包,这个心跳包是服务器发送给客户端的,用来判断客户端死没死。如果你看过上面第一条, 就会知道非持久化消息堆积到一定程度会写到文件里,这个写 的过程会阻塞所有动作,而且会持续 20到 30秒,并且随着内存的增大而增大。当客户端发完消息调用 connection.close()时,会期待服务器对于关闭连接的回答,如果超过 15 秒没回答就直接调用 socket 层的 close 关闭 tcp 连接了。这时客户端发出的消息其实还在服务器的缓存里等待处理,不过由于服务器心跳包的设置,导致发生了 java.net.SocketException 异常,把缓存里的数据作废了,没处理的消息全部丢失。
解决方案:用持久化消息,或者非持久化消息及时处理不要堆积,或者启动事务,启动事务后,commit()方法会负责任的等待服务器的返回,也就不 会关闭连接导致消息丢失了。
4.持久化消息非常慢如何处理
默认的情况下,非持久化的消息是异步发送的,持久化的消息是同步发送的,遇到慢一点的硬盘,发送消息的速度是无法忍受的。但是在开启事务的情况下,消息都是异步发送的,效率会有 2 个数量级的提升。所以在发送持久化消息时,请务必开启事务模式。其实发送非持久化消息时也建议开启事务,因为根本不会影响性能。
5消息的不均匀消费
有时在发送一些消息之后,开启 2 个消费者去处理消息。会发现一个消费者处理了所有的消息,另一个消费者根本没收到消息。原因在于 ActiveMQ 的 prefetch 机制。当消费者去获取消息时,不会一条一条去获取,而是一次性获取一批,默认是 1000条。这些预获取的消息,在还没确认消费之前,在管理控制台还是可以看见这些消息的,但是不会再分配给其他消费者,此时这些消息的状态应该算作“已分配未消费”,如果消息最后被消费,则会在服务器端被删除,如果消费者崩溃,则这些消息会被 重新分配给新的消费者。但是如果消费者既不消费确认,又不崩溃,那这些消息就永远躺在消费者的缓存区里无法处理。更通常的情况是,消费这些消息非常耗时,你开了 10个消费者去处理,结果发现只有一台机器吭哧吭哧处理,另外 9 台啥事不干。
解决方案:将 prefetch 设为 1,每次处理 1 条消息,处理完再去取,这样也慢不了多少。
6. 死信队列如果你想在消息处理失败后,不被服务器删除,还能被其他消费者处理或重试,可以关闭AUTO_ACKNOWLEDGE,将 ack 交由程序自己处理。那如果使用了AUTO_ACKNOWLEDGE,消息是什么时候被确认的,还有没有阻止消息确认的方法?
有,两种。
一种是调用 consumer.receive()方法,该方法将阻塞直到获得并返回一条消息。这种情况下,消息返回给方法调用者之后就自动被确认了。
另一种方法是采用 listener 回调函数,在有消息到达时,会调用 listener 接口的 onMessage 方法。在这种情况下,在 onMessage 方法执行完毕后,消息才会被确认,此时只要在方法中抛出异常,该消息就 不会被确认。
那么问题来了,如果一条消息不能被处理,会被退回服务器重新分配,如果只有一个消费者,该消息又会重新被获取,重新抛异常。就算有多个消费者,往往在一个服务器上不能处理的消息,在另外的服务器上依然不能被处理。难道就这么退回 --获取–报错死循环了吗在重试 6 次后,ActiveMQ 认为这条消息是“有毒”的,将会把消息丢到死信队列里。如果你的消息不见 了,去 ActiveMQ.DLQ 里找找,说不定就躺在那里。
7.ActiveMQ中的消息重发时间间隔和重发次数吗
ActiveMQ:是 Apache 出品,最流行的,能力强劲的开源消息总线。是一个完全支持 JMS1.1 和 J2EE 1.4 规范的 JMS Provider 实现。JMS(Java 消息服务):是一个 Java 平台中关于面向消息中间件 (MOM)的 API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。
首先,我们得大概了解下,在哪些情况下,ActiveMQ服务器会将消息重发给消费者,这里为简单起见,假定采用的消息发送模式为队列(即消息发送者和消息接收者)。
1、如果消息接收者在处理完一条消息的处理过程后没有对 MOM进行应答,则该消息将由 MOM重发.
2、如果我们对某个队列设置了预读参数(consumer.prefetchSize),如果消息 接收者在处理第一条消息时(没向 MOM 发送消息接收确认)就宕机了,则预读数量的所有消息都将被重发!
3、如果 Session 是事务的,则只要消息接收者有一条消息没有确认,或发送消息期间 MOM 或客户端某一方突然宕机了,则该事务范围中的所有消息 MOM 都将重发。
4、说到这里,大家可能会有疑问,ActiveMQ 消息服务器怎么知道消费者客户端到底是消息正在
处理中 还没来得急对消息进行应答还是已经处理完成了没有应答或是宕机了根本没机会应答呢其实在所有的客户端机器上, 内存中都运行着一套客户端的 ActiveMQ 环境,该环境负责缓存发来的消息,负责维持着 和 ActiveMQ 服务器的消息通讯,负责失效转移(fail-over) 等,所有的判断和处理都是由这套客户端环境来完成的。我们可以来对 ActiveMQ的重发策略(RedeliveryPolicy)来进行自定义配置,其中的配置参数主要有以下几个:可用的属性默认值说明
- l collisionAvoidanceFactor 默认值 0.15 , 设置防止冲突范围的正负百分比,只有启用 useCollisionAvoidance 参数时才生效。
- l maximumRedeliveries 默认值 6 , 最大重传次数,达到最大重连次数后抛出异常。为-1 时不限制次数,为 0 时表示不进行重传。
- l maximumRedeliveryDelay 默认值-1, 最大传送延迟,只在useExponentialBackOff 为 true时有效 (V5.5),假设首次重连间隔为10ms,倍数为 2,那么第二次重连时间间隔为 20ms,第三次重连时间间隔为 40ms,当重连时间间隔大的最大重连时间间隔时,以后每次重连时间间隔都为最大重连时间间隔。
- l initialRedeliveryDelay 默认值 1000L, 初始重发延迟时间
- l redeliveryDelay 默认值 1000L, 重发延迟时间,当 initialRedeliveryDelay=0时生效(v5.4)
- l useCollisionAvoidance 默认值 false, 启用防止冲突功能,因为消息接收时是可以使用多线程并发处理的,应该是为了重发的安全性,避开所有并发 线程都在同一个时间点进行消息接收处理。所有线程在同一个时间点处理 时会发生什么问题呢应该没有问题,只是为了平衡 broker处理性能,不会有时很忙,有时很空闲。
- l useExponentialBackOff 默认值 false, 启用指数倍数递增的方式增加延迟时间。
- l backOffMultiplier 默认值 5, 重连时间间隔递增倍数,只有值大于 1 和启用 useExponentialBackOff 参数时才生效。
分布式数据库Reids篇
1、redis 和 memcached 什么区别为什么高并发下有时单线程的redis比多线程的memcached 效率要高
区别:
1. mc 可缓存图片和视频。rd 支持除 k/v 更多的数据结构;
2. rd 可以使用虚拟内存,rd 可持久化和 aof 灾难恢复,rd 通过主从支持数据备份; 3.rd 可以做消息队列。
原因:mc 多线程模型引入了缓存一致性和锁,加锁带来了性能损耗。
2、redis 主从复制如何实现的redis 的集群模式如何实现redis 的 key是如何寻址的
主从复制实现:主节点将自己内存中的数据做一份快照,将快照发给从节 点,从节点将数 据恢复到内存中。之后再每次增加新数据的时候,主节点以类似于 mysql 的二进制日志方式将语句发送给从节点,从节点拿到主节点发送过来的语句进行重放。
分片方式:
-客户端分片
-基于代理的分片
●Twemproxy
●codis
-路由查询分片
● Redis-cluster(本身提供了自动将数据分散到 Redis Cluster 不同节点的能力,整个数据集合的某个数据子集存储在哪个节点对于用户来说是透明的) redis-cluster 分片原理:Cluster 中有一个 16384 长度的槽(虚拟槽),编号分别为0-16383。每个 Master 节点都会负责一部分的槽,当有某个 key 被映射到某个 Master 负责的槽,那么这个 Master 负责为这个 key 提供服务,至于哪个 Master 节点负责哪个槽,可以由用户指定,也可以在初始化的时候自动生成,只有 Master 才拥有槽的所有权。Master 节点维护着一个 16384/8 字节的位序列,Master 节点用 bit 来标识对于某个槽自己是否拥有。比如对于编号为 1 的槽,Master 只要判断序列的第二位(索引从0开始)是不是为 1 即可。这种结构很容易添加或者删除节点。比如如果我想新添加个节点 D, 我需要从节点 A、B、 C 中的部分槽到 D 上。
3、使用 redis 如何设计分布式锁说一下实现思路使用 zk 可以吗如何实现这两种有什么区别
redis:
1. 线程 A setnx(上锁的对象,超时时的时间戳 t1),如果返回 true,获得锁。
2.线程B用get获取t1,与当前时间戳比较,判断是是否超时,没超时false,
若超时执行第3 步;
3. 计算新的超时时间 t2,使用 getset 命令返回 t3(该值可能其他线程已经修改过),如果 t1==t3,获得锁,如果 t1!=t3 说明锁被其他线程获取了。
4. 获取锁后,处理完业务逻辑,再去判断锁是否超时,如果没超时删除锁,如果已超时,不用处理(防止删除其他线程的锁)。
zk:
1.客户端对某个方法加锁时,在zk上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点node1;
2. 客户端获取该路径下所有已经创建的子节点,如果发现自己创建的node1 的序号是最小的,就认为这个客户端获得了锁。
3. 如果发现 node1 不是最小的,则监听比自己创建节点序号小的最大的节点,进入等待。
4. 获取锁后,处理完逻辑,删除自己创建的 node1 即可。区别:zk 性能差一些,开销大,实现简单。
4、知道 redis 的持久化吗底层如何实现的有什么优点缺点
RDB(Redis DataBase:在不同的时间点将 redis 的数据生成的快照同步到磁盘等介质上):内存到硬盘的快照,定期更新。
缺点:耗时,耗性能(fork+io 操作),易丢失数据。
AOF(Append Only File:将redis所执行过的所有指令都记录下来,在下次redis重启时,只需要执行指令就可以了):写日志。
缺点:体积大,恢复速度慢。
bgsave 做镜像全量持久化,aof 做增量持久化。因为 bgsave 会消耗比较长的时间,不够实时,在停机的时候会导致大量的数据丢失,需要 aof 来配合,在 redis 实例重启时,优先使用 aof 来恢复内存的状态,如果没有aof 日志,就会使用 rdb 文件来恢复。Redis 会定期做 aof 重写,压缩 aof 文件日志大小。Redis4.0之后有了混合持久化的功能,将 bgsave 的全量和 aof 的增量做了融合处理,这样既保证了恢复的效率又兼顾了数据的安全性。bgsave 的原理,fork 和 cow, fork 是指 redis 通过创建子进程来进行 bgsave 操作,cow 指的是 copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
5、redis 过期策略都有哪些LRU 算法知道吗写一下 java 代码实现
过期策略:
定时过期(一 key 一定时器),惰性过期:只有使用 key 时才判断 key 是否已过期,过期则清除。定期过期:前两者折中。
LRU:new LinkedHashMap(capacity, DEFAULT_LOAD_FACTORY, true);
//第三个参数置为 true,代表 linkedlist 按访问顺序排序,可作为 LRU 缓存
;设为 false 代表 按插入顺序排序,可作为 FIFO 缓存
LRU 算法实现:
1.通过双向链表来实现,新数据插入到链表头部;
2.每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候 , 将 链 表 尾 部 的 数 据 丢 弃 。LinkedHashMap:HashMap 和双向链表合二为一即是 LinkedHashMap。HashMap 是无序的,LinkedHashMap 通过维护一个额外的双向链表保证了迭代顺序。该迭代顺序可以是插入顺序(默认),也可以是访问顺序。
6、缓存穿透、缓存击穿、缓存雪崩解决方案
缓存穿透:指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。
解决方案:
1.查询返回的数据为空,仍把这个空结果进行缓存,但过期时间会比较短;
2. 布隆过滤器:将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对 DB 的查询。
缓存击穿:对于设置了过期时间的 key,缓存在某个时间点过期的时候,恰好这时间点对这个 Key 有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案:
1. 使用互斥锁:当缓存失效时,不立即去load db,先使用如Redis的setnx去设置一个互斥锁,当操作成功返回时再进行load db的操作并回设缓存,否则重试get缓存的方法。
2. 永远不过期:物理不过期,但逻辑过期(后台异步线程去刷新)。
**缓存雪崩:**设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多 key,击穿是某一个 key 缓存。
解决方案:将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值, 比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
7、在选择缓存时什么时候选择 redis什么时候选择 memcached
选择redis 的情况:
1、复杂数据结构,value 的数据是哈希,列表,集合,有序集合等这种情况下,会选择 redis, 因为 memcache 无法满足这些数据结构,最典型的的使用场景是,用户订单列表,用户消息,帖子评论等。
2、需要进行数据的持久化功能,但是注意,不要把 redis 当成数据库使用,如果 redis 挂了,内存能够快速恢复热数据,不会将压力瞬间压在数据库上,没有 cache 预热的过程。对于只读和数据一致性要求不高的场景可以采用持久化存储
3、高可用,redis 支持集群,可以实现主动复制,读写分离,而对于memcache 如果想要实现高可用,需要进行二次开发。
4、存储的内容比较大,memcache 存储的 value 最大为 1M。
选择memcache 的场景:
1、纯 KV,数据量非常大的业务,使用 memcache 更合适,原因是
a、memcache 的内存分配采用的是预分配内存池的管理方式,能够省去内存分配的时间,redis 是临时申请空间,可能导致碎片化。
b、虚拟内存使用,memcache将所有的数据存储在物理内存里,redis有自己的vm机制,理论上能够存储比物理内存更多的数据,当数据超量时,引发swap,把冷数据刷新到磁盘上,从这点上,数据量大时,memcache 更快
c、网络模型,memcache使用非阻塞的IO复用模型,redis也是使用非阻塞的IO复用模型,但是redis还提供了一些非KV存储之外的排序,聚合功能,复杂的CPU计算,会阻塞整个 IO 调度,从这点上由于 redis 提供的功能较多,memcache 更快些。
d、线程模型,memcache使用多线程,主线程监听,worker子线程接受请 求,执行读写,这个过程可能存在锁冲突。redis 使用的单线程,虽然无锁冲突,但是难以利用多核的特性提升吞吐量。
8、缓存与数据库不一致怎么办
假设采用的储存分离,读写分离的数据库,
如果一个线程 A 先删除缓存数据,然后将数据写入到主库当中,这个时候,主库和从库同步没有完成,线程 B 从缓存当中读取数据失败,从从库当中读取到旧数据,然后更新至缓存,这个时候,缓存当中的就是旧的数据。
发生上述不一致的原因在于,主从库数据不一致问题,加入了缓存之后,主从不一致的时间被拉长了
处理思路:在从库有数据更新之后,将缓存当中的数据也同时进行更新,即当从库发生了数据更新之后,向缓存发出删除,淘汰这段时间写入的旧数 据。
9、主从数据库不一致如何解决
场景描述,对于主从库,读写分离,如果主从库更新同步有时差,就会导致主从库数据的不一致
1、忽略这个数据不一致,在数据一致性要求不高的业务下,未必需要时时一致性
2、强制读主库,使用一个高可用的主库,数据库读写都在主库,添加一个缓存,提升数据读取的性能。
3、选择性读主库,添加一个缓存,用来记录必须读主库的数据,将哪个库,哪个表,哪个主键,作为缓存的 key,设置缓存失效的时间为主从库同步的时间,如果缓存当中有这个数据,直接读取主库,如果缓存当中没有这个主键,就到对应的从库中读取。
10、Redis 常见的性能问题和解决方案
1、master 最好不要做持久化工作,如 RDB 内存快照和 AOF 日志文件
2、如果数据比较重要,某个 slave 开启 AOF 备份,策略设置成每秒同步一次
3、为了主从复制的速度和连接的稳定性,master 和 Slave 最好在一个局域网内
4、尽量避免在压力大的主库上增加从库
5、主从复制不要采用网状结构,尽量是线性结构,Master<–Slave1<----Slave2 …
11、Redis 的数据淘汰策略有哪些
voltile-lru 从已经设置过期时间的数据集中挑选最近最少使用的数据淘汰
voltile-ttl 从已经设置过期时间的数据库集当中挑选将要过期的数据
voltile-random从已经设置过期时间的数据集任意选择淘汰数据allkeys-lru从数据集中挑选最近最少使用的数据淘汰
allkeys-random从数据集中任意选择淘汰的数据no-eviction 禁止驱逐数据
12、Redis 当中有哪些数据结构
字符串 String、字典 Hash、列表 List、集合 Set、有序集合 SortedSet。如果是高级用户,那么还会有,如果你是 Redis 中高级用户,还需要加上下面几种数据结构 HyperLogLog、 Geo、Pub/Sub。
13、假如 Redis 里面有 1 亿个 key其中有 10w 个 key 是以某个固定的已知的前缀开头的如果将它们全部找出来
使用 keys 指令可以扫出指定模式的 key 列表。
对方接着追问:如果这个 redis 正在给线上的业务提供服务,那使用 keys指令会有什么问题
这个时候你要回答 redis 关键的一个特性:redis 的单线程的。
keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客 户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
14、使用 Redis 做过异步队列吗是如何实现的
使用 list 类型保存数据信息,rpush 生产消息,lpop 消费消息,当 lpop 没有消息时,可以 sleep 一段时间,然后再检查有没有信息,如果不想sleep 的话,可以使用 blpop, 在没有信息的时候,会一直阻塞,直到信息的到来。redis 可以通过 pub/sub 主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
15、Redis 如何实现延时队列
使用 sortedset,使用时间戳做 score, 消息内容作为 key,调用 zadd 来生产消息,消费者使用 zrangbyscore 获取 n 秒之前的数据做轮询处理。
16、什么是 Redis简述它的优缺点
Redis 本质上是一个 Key-Value 类型的内存数据库,很像 memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush 到硬盘上进行保存。
因为是纯内存操作,Redis 的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的 Key-Value DB。Redis 的出色之处不仅仅是性能,Redis 最大的魅力是支持保存多种数据
结构,此外单个 value 的最大限制是 1GB,不像 memcached 只能保存1MB 的数据,因此 Redis 可以用来实现很多有用的功能。
比方说用他的 List 来做 FIFO 双向链表,实现一个轻量级的高性 能消息队列服务,用他的 Set 可以做高性能的 tag 系统等等。
另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一个功能加强版的memcac hed 来用。Redis 的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
17、Redis 相比 memcached 有哪些优势
(1)memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2)redis的速度比memcached快很多
(3)redis可以持久化其数据
18、Redis 支持哪几种数据类型
String、List、Set、Sorted Set、hashes
19、Redis 主要消耗什么物理资源
内存。
20、Redis 的全称是什么
Remote Dictionary Server。
21、Redis 有哪几种数据淘汰策略
noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL 和几个例外)
allkeys-lru:尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
allkeys-random: 回收随机的键使得新添加的数据有空间存放。
volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
22、Redis 官方为什么不提供 Windows 版本
因为目前Linux 版本已经相当稳定,而且用户量很大,无需开发 windows版本,反而会带来兼容性等问题。
23、一个字符串类型的值能存储最大容量是多少
512M
24、为什么 Redis 需要把所有数据放到内存中
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。
所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I/O 速度会严重影响 redis 的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
25、Redis 集群方案应该怎么做都有哪些方案
1. codis。
目前用的最多的集群方案,基本和twemproxy一致的效果,但它支持在 节点数量改变情况下,旧节点数据可恢复到新 hash 节点。
2. redis cluster3.0自带的集群,特点在于他的分布式算法不是一致性hash,而是hash槽的概念,以及自身支持节点设置从节点。具体看官方文档介绍。
3. 在业务代码层实现,起几个毫无关联的 redis 实例,在代码层,对key 进行hash计算,然后去对应的 redis 实例操作数据。这种方式对 hash 层代码要求比较高,考虑部分包括,节点失效后的替代算法方 案,数据震荡后的自动脚本恢复,实例的监控,等等。
26、Redis 集群方案什么情况下会导致整个集群不可用
有 A,B,C 三个节点的集群,在没有复制模型的情况下,如果节点 B 失败了,那么整个集群就会以为缺少 5 501-11000 这个范围的槽而不可用。
27、MySQL 里有 2000w 数据redis 中只存 20w 的数据如何保证redis 中的数据都是热点数据
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
28、Redis有哪些适合的场景
(1)会话缓存(SessionCache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Mem cached)的优势在于:Redis 提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车 信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台 Magento 也提供 Redis 的插件。
(2)全页缓存(FPC)
除基本的会话 token 之外,Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地 FPC。再次以 Magento 为例,Magento 提供一个插件来使用 Redis 作为全页缓存后端。此外,对 WordPress 的用户来说,Pantheon 有一个非常好的插件 wp- redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
如果你快速的在 Google 中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是 利用 Redis 创建非常好的后端工具,以满足各种队列需求。例如,Celery 有一个后台就是使用 Redis 作为 broker,你可以从这里去查看。
(4)排行榜/计数器
Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的 10 个用户–我们称之为“user_scores”我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games 就是一个很好的例子,用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的,你可以在这里看到。
(5)发布/订阅
最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用 Redis 的发布/订阅功能来建 立聊天系统!
29、Redis 支持的 Java 客户端都有哪些官方推荐用哪个
Redisson、Jedis、lettuce 等等,官方推荐使用 Redisson。
30、Redis 和 Redisson 有什么关系
Redisson 是一个高级的分布式协调 Redis 客服端,能帮助用户在分布式环境中轻松实现一些 Java 的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, List Multimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, Atomi cLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
31、Jedis 与 Redisson 对比有什么优缺点
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持;
Redisson 实现了分布式和可扩展的 Java 数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等 Redis 特性。Redisson 的宗旨是促进使用者对 Redis 的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
32、Redis如何设置密码及验证密码
设置密码:configsetrequirepass123456授权密码:auth123456
33、说说 Redis 哈希槽的概念
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
34、Redis 集群的主从复制模型是怎样的
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用, 所以集群使用了主从复制模型,每个节点都会有 N-1 个复制品.
35、Redis 集群会有写操作丢失吗为什么
Redis 并不能保证数据的强一致性,这意味在实际中集群在特定的条件下可能会丢失写操作。
36、Redis 集群之间是如何复制的
异步复制
37、Redis 集群最大节点个数是多少
16384 个。
38、Redis 集群如何选择数据库
Redis 集群目前无法做数据库选择,默认在 0 数据库。
39、怎么测试 Redis 的连通性
ping
40、Redis 中的管道有什么用
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读 取该答复。这就是管道(pipelining),是一种几十年来广泛使用的技术。
例如许多 POP3协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
41、怎么理解 Redis 事务
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
42、Redis 事务相关的命令有哪几个
MULTI、EXEC、DISCARD、WATCH
43、Redis key的过期时间和永久有效分别怎么设置
EXPIRE 和 PERSIST 命令。
44、Redis 如何做内存优化
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的 web 系统中有一个用户对象,不要为这个用户的名称,姓氏, 邮箱,密码设置单独的 key,而是应该把这个用户的所有信息存储到一张散列表里面。
45、Redis 回收进程如何工作的
一个客户端运行了新的命令,添加了新的数据。
Redis检查内存使用情况,如果大于 maxmemory 的限制, 则根据设定好的策略进行回收。一个新的命令被执行,等等。
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
分布式数据库MongoDB篇
1.你说的NoSQL数据库是什么意思NoSQL与RDBMS直接有什么区别为什么要使用和不使用NoSQL数据库说一说NoSQL数据库的几个优点
NoSQL 是非关系型数据库,NoSQL = Not Only SQL。
关系型数据库采用的结构化的数据,NoSQL 采用的是键值对的方式存储数据。在处理非结构化/半结构化的大数据时;在水平方向上进行扩展时;随时应对动态增加的数据项时可以优先考虑使用 NoSQL 数据库。
在考虑数据库的成熟度;支持;分析和商业智能;管理及专业性等问题时,应优先考虑关系型数据库。
2.NoSQL数据库有哪些类型
例如:MongoDB,Cassandra,CouchDB,Hypertable,Redis,Riak,Neo4j,HBASE,Couchbase,MemcacheDB,RevenDBandVoldemortarethe examples of NoSQLdatabases.
3.MySQL与MongoDB之间最基本的差别是什么
MySQL 和 MongoDB 两者都是免费开源的数据库。MySQL 和 MongoDB 有许多基本差别包括数据的表示(data representation),查询,关系,事务,schema 的设计和定义,标准化(normalization),速度和性能。
通过比较 MySQL 和 MongoDB,实际上我们是在比较关系型和非关系型数据库,即数据存储结构不同。
4.你怎么比较MongoDB、CouchDB及CouchBase
MongoDB 和 CouchDB 都是面向文档的数据库。MongoDB 和 CouchDB 都是开源 NoSQL 数据库的最典型代表。除了都以文档形式存储外它们没有其他的共同点。MongoDB 和 CouchDB 在数据模型实现、接口、对象存储以及复制方法等方面有很多不同。
5.MongoDB成为最好NoSQL数据库的原因是什么
以下特点使得MongoDB 成为最好的 NoSQL 数据库:
●面向文件的
●高性能
●高可用性
●易扩展性
●丰富的查询语言
6.32位系统上有什么细微差别
journaling 会激活额外的内存映射文件。这将进一步抑制 32 位版本上的数据库大小。因此,现在 journaling 在 32 位系统上默认是禁用的。
7.journal回放在条目(entry)不完整时(比如恰巧有一个中途故障了)会遇到问题吗
每个 journal (group)的写操作都是一致的,除非它是完整的否则在恢复过程中它不会回放。
8.分析器在MongoDB中的作用是什么
MongoDB 中包括了一个可以显示数据库中每个操作性能特点的数据库分析器。通过这个分析器你可以找到比预期慢的查询(或写操作);利用这一信息,比如,可以确定是否需要添加索引。
9.名字空间(namespace)是什么
MongoDB 存储 BSON 对象在丛集(collection)中。数据库名字和丛集名字以句点连接起来叫做名字空间(namespace)。
10.如果用户移除对象的属性该属性是否从存储层中删除
是的,用户移除属性然后对象会重新保存(re-save())。
11.能否使用日志特征进行安全备份
是的。
12.允许空值null吗
对于对象成员而言,是的。然而用户不能够添加空值(null)到数据库丛集(collection)因为空值不是对象。然而用户能够添加空对象{}。
13.更新操作立刻fsync到磁盘
不会,磁盘写操作默认是延迟执行的。写操作可能在两三秒(默认在 60 秒内)后到达磁盘。例如,如果一秒内数据库收到一千个对一个对象递增的操作,仅刷新磁盘一次。(注意,尽管 fsync 选项在命令行和经 过getLastError_old 是有效的)(译者:也许是坑人的面试题)。
14.如何执行事务/加锁
MongoDB 没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能。可以把它类比成 MySQL MylSAM 的自动提交模式。通过精简对事务的支持,性能得到了提升,特别是在一个可能会穿过多个服务器的系统里。
15.为什么我的数据文件如此庞大
MongoDB 会积极的预分配预留空间来防止文件系统碎片。
16.启用备份故障恢复需要多久
从备份数据库声明主数据库宕机到选出一个备份数据库作为新的主数据库将花费 10到 30 秒时间。这期间在主数据库上的操作将会失败–包括写入和强一致性读取(strong consistent read)操作。然而,你还 能在第二数据库上执行最终一致性查询(eventually consistent query)(在 slaveOk 模式下),即使在这段时间里。
17.什么是master或primary
它是当前备份集群(replica set)中负责处理所有写入操作的主要节点/成员。在一个备份集群中,当失效备援(failover)事件发生时,一个另外的成员会变成 primary。
18.什么是secondary或slave
Seconday 从当前的 primary 上复制相应的操作。它是通过跟踪复制
oplog(local.oplog.rs)做到的。
19.我必须调用getLastError来确保写操作生效了么
不用。不管你有没有调用 getLastError(又叫"Safe Mode")服务器做的操作都一样。调用 getLastError 只是为了确认写操作成功提交了。当然,你经常想得到确认,但是写操作的安全性和是否生效不是由这个决定的。
20.我应该启动一个集群分片(sharded)还是一个非集群分片的MongoDB环境
为开发便捷起见,我们建议以非集群分片(unsharded)方式开始一个MongoDB 环境,除非一台服务器不足以存放你的初始数据集。从非集群分片升级到集群分片(sharding)是无缝的,所以在你的数据集还不 是很大的时候没必要考虑集群分片(sharding)。
21.分片(sharding)和复制(replication)是怎样工作的
每一个分片(shard)是一个分区数据的逻辑集合。分片可能由单一服务器或者集群组成,我们推荐为每一个分片(shard)使用集群。
22.数据在什么时候才会扩展到多个分片(shard)里
MongoDB 分片是基于区域(range)的。所以一个集合(collection)中的所有的对象都被存放到一个块(chunk)中。只有当存在多余一个块的时候,才会有多个分片获取数据的选项。现在,每个默认块的大小 是 64Mb,所以你需要至少 64 Mb 空间才可以实施一个迁移。
23. 当我试图更新一个正在被迁移的块(chunk)上的文档时会发生什么
更新操作会立即发生在旧的分片(shard)上,然后更改才会在所有权转移(ownership transfers)前复制到新的分片上。
24.如果在一个分片(shard)停止或者很慢的时候我发起一个查询会怎样
如果一个分片(shard)停止了,除非查询设置了“Partial”选项,否则查询会返回一个错误。如果一个分片(shard)响应很慢,MongoDB 则会等待它的响应。
25.我可以把moveChunk目录里的旧文件删除吗
没问题,这些文件是在分片(shard)进行均衡操作(balancing)的时候产生的临时文件。一旦这些操作已经 完成,相关的临时文件也应该被删除掉。但目前清理工作是需要手动的,所以请小心地考虑再释放这些文件的空间。
26.怎么查看Mongo正在使用的链接
db._adminCommand("connPoolStats");
27.如果块移动操作(moveChunk)失败了我需要手动清除部分转移的文档吗
不需要,移动操作是一致(consistent)并且是确定性的(deterministic);一次失败后,移动操作会不断重试; 当完成后,数据只会出现在新的分片里(shard)。
28.如果我在使用复制技术(replication)可以一部分使用日志(journaling)而其他部分则不使用吗
可以。
29.当更新一个正在被迁移的块(Chunk)上的文档时会发生什么
更新操作会立即发生在旧的块(Chunk)上,然后更改才会在所有权转移前复制到新的分片上。
30.MongoDB在A:{B,C}上建立索引查询A:{B,C}和A:{C,B}都会使用索引吗
不会,只会在 A:{B,C}上使用索引。
31如果一个分片(Shard)停止或很慢的时候发起一个查询会怎样
如果一个分片停止了,除非查询设置了“Partial”选项,否则查询会返回一个错误。如果一个分片响应很慢,MongoDB 会等待它的响应。
32.MongoDB支持存储过程吗如果支持的话怎么用
MongoDB 支持存储过程,它是 javascript 写的,保存在 db.system.js 表中。
33.如何理解MongoDB中的GridFS机制MongoDB为何使用GridFS来存储文件
GridFS 是一种将大型文件存储在 MongoDB 中的文件规范。使用 GridFS 可以将大文件分隔成多个小文档存放,这样我们能够有效的保存大文档, 而且解决了 BSON 对象有限制的问题。
分布式数据库Memcached
1、memcached是怎么工作的
Memcached的神奇来自两阶段哈希(two-stagehash)。Memcached就像一个巨大的、存储了很多对的哈希表。通过key,可以存储或查询任意的数据。
客户端可以把数据存储在多台 memcached 上。当查询数据时,客户端首先参考节点列表计算出 key 的哈希值(阶段一哈希),进而选中一个节点;客户端将请求发送给选中的节点,然后 memcached 节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)。
举个列子,假设有3 个客服端 1 2 3 台 memcached A,B,C。
Client 1 想把数据”barbaz”以key “foo”存储。Client 1 首先参考节点列表(A,B,C)计算 key “foo”的哈希值,假设 memcached B 被选中。接着,Client 1 直接 connect 到memcached B 通过 key “foo”把数
据”barbaz”存储进去。Client 2 使用与 Client 1 相同的客户端库(意味着阶段一的哈希算法相同),也拥有同样的 memcached 列表(A,B,C)。于是,经过相同的哈希计算(阶段一),Client 2 计算出 key “foo”在 memcached B 上,然后它直接请求 memcached B,得到数据”barbaz”。各种客户端在 memcached 中数据的存储形式是不同的(perl Storable php serialize,java hibernate,JSON等)。一些客户端实现的哈希算法也不一样。但是,memcached 服务器端的行为总是一致的。
最后,从实现的角度看,memcached 是一个非阻塞的、基于事件的服务器程序。这种架构可以很好地解决 C10K problem,并具有极佳的可扩展性。
可以参考A Story of Caching,这篇文章简单解释了客户端与memcached
是如何交互的。
2、memcached 最大的优势是什么
请仔细阅读上面的问题(即 memcached 是如何工作的)。Memcached 最大的好处就是它带来了极佳的水平可扩展性,特别是在一个巨大的系统中。由于客户端自己做了一次哈希,那么我们很容易增加大量 memcached 到集群中。memcached 之间没有相互通信,因此不会增加 memcached 的负载;没有多播协议,不会网络通信量爆炸(implode)。memcached 的集群很好用。内存不够了增加几台 memcached 吧;CPU 不够用了再增加几台吧;有多余的内存在增加几台吧,不要浪费了。
基于 memcached 的基本原则,可以相当轻松地构建出不同类型的缓存架构。除了这篇 FAQ,在其他地方很容易找到详细资料的。
3、memcached 和 MySQL 的query cache 相比有什么优缺点
把 memcached 引入应用中,还是需要不少工作量的。MySQL 有个使用方便的 query cache,可以自动地缓存 SQL 查询的结果,被缓存的 SQL 查询可以被反复地快速执行。Memcached 与之相比,怎么样呢 MySQL 的 query cache 是集中式的,连接到该 query cache 的 MySQL 服务器都会受益。
●当您修改表时,MySQL 的query cache 会立刻被刷新(flush)。存储一个memcached item 只需要很少的时间,但是当写操作很频繁时,MySQL 的query cache 会经常让所有缓存数据都失效。
●在多核 CPU 上 MySQL 的 query cache 会遇到扩展问题(scalability issues)。在多核 CPU 上 query cache 会增加一个全局锁(global lock)、由于需要刷新更多的缓存数据,速度会变得更慢。
●在 MySQL 的 query cache 中,我们是不能存储任意的数据的(只能是SQL 查询结果)。而利用 memcached,我们可以搭建出各种高效的缓存。比如,可以执行多个独立的查询,构建出一个用户对象(user object),然后将用户对象缓存到 memcached 中,而 query cache 是 SQL 语句级别的, 不可能做到这一点。在小的网站中,query cache 会有所帮助,但随着网站规模的增加,query cache 的弊将大于利。
● query cache 能够利用的内存容量受到 MySQL 服务器空闲内存空间的限制。给数据库服务器增加更多的内存来缓存数据,固然是很好的。但是, 有了 memcached,只要您有空闲的内存,都可以用来增加 memcached 集群的规模,然后您就可以缓存更多的数据。
4、memcached和服务器的local cache(比如PHP的APC、mmap文件等,相比有什么优缺点2
首先,local cache 有许多与上面(query cache)相同的问题。local cache 能够利用的内存容量受到(单台)服务器空闲内存空间的限制。不过,local cache 有一点比 memcached 和 query cache 都要好,那就是它不但可以存储任意的数据,而且没有网络存取的延迟。
● local cache 的数据查询更快。考虑把 highly common 的数据放在 local cache 中吧。如果每个页面都需要加载一些数量较少的数据,考虑把它们放在 local cache 吧。
● local cache 缺少集体失效(group invalidation)的特性,在 memcached 集群中,删除或更新一个key 会让所有的观察者觉察到。但是在 local cache 中我们只能通知所有的服务器刷新 cache(很慢,不具扩展性),或者仅仅依赖缓存超时失效机制。
● local cache 面临着严重的内存限制,这一点上面已经提到。
5、memcached 的 cache 机制是怎样的
Memcached 主要的 cache 机制是 LRU 最近最少用)算法+超时失效。当存数据到 memcached 中,可以指定该数据在缓存中可以呆多久 Which is forever,or some time in the future。如果 memcached 的内存不够用了,过期的 slabs 会优先被替换,接着就轮到最老的未被使用的 slabs
6、memcached 如何实现冗余机制
不实现!我们对这个问题感到很惊讶。Memcached 应该是应用的缓存层。它的设计本身就不带有任何冗余机制。如果一个 Memcached 节点失去了所有数据,您应该可以从数据源(比如数据库)再次获取到数据。您应该特别注意,您的应用应该可以容忍节点的失效。不要写一些糟糕的查询代 码,寄希望于 memcached 来保证一切!如果您担心节点失效会大大加重数据库的负担,那么您可以采取一些办法。比如您可以增加更多的节点(来减少丢失一个节点的影响),热备节点(在其他节点 down 了的时候接管 IP)等等。
7、memcached 如何处理容错的
不处理!在 memcached 节点失效的情况下,集群没有必要做任何容错处理。如果发生了节点失效,应对的措施完全取决于用户。节点失效时,下面列出几种方案供您选择:
●忽略它!失效节点被恢复或替换之前,还有很多其他节点可以应对节点失效带来的影响。
●把失效的节点从节点列表中移除。做这个操作千万要小心!在默认情况下(余数式哈希算法),客户端添加或移除节点,会导致所有的缓存数据 不可用!因为哈希参照的节点列表变化了,大部分 key 会因为哈希值的改变而被映射到(与原来)不同的节点上。
●启动热节点,接管失效节点所占用的 IP,这样可以防止哈希紊乱(hashing chaos)。
●如果希望添加和移除节点,而不影响原先的哈希结果,可以使用一致性 哈希算法(consistent hashing)。您可以百度一下一致性哈希算法。支持一致性哈希的客户端已经很成熟,而且被广泛使用。去尝试一下吧!
●两次哈希(reshing)。当客户端存取数据时,如果发现一个节点(down) 了,就再做一次哈希(哈希算法与前一次不同),重新选择另一个节点(需要注意的时,客户端并没有把 down 的节点从节点列表中移除,下次还是有可能先哈希到它)。如果某个节点时好时坏,两次哈希的方法就有风险了, 好的节点和坏的节点上都可能存在脏数据(stale data)。
8、如何将 memcached 中 item 批量导入导出
您不应该这样做!Memcached 是一个非阻塞的服务器。任何可能导致memcached 暂停或瞬时拒绝服务的操作都应该值得深思熟虑。向memcached 中批量导入数据往往不是您真正想要的!想象看,如果缓存数据在导出导入之间发生了变化,您就需要处理脏数据了;如果缓存数据在导出导入之间过期了,您又怎么处理这些数据呢
因此,批量导出导入数据并不像您想象中的那么有用。不过在一个场景倒是很有用。如果您有大量的从不变化的数据,并且希望缓存很快热(warm) 起来,批量导入缓存数据是很有帮助的。虽然这个场景并不典型,但却经常发生,因此我们会考虑在将来实现批量导出导入的功能。
9、我需要把 memcached 中的 item 批量导出导入怎么办
如果需要批量导出导入,最可能的原因一般是重新生成缓存数据需要消耗很长的时间,或者数据库坏了让您饱受痛苦。如果一个 memcached 节点 down 了让您很痛苦,那么您还会陷入其他很多麻烦。您的系统太脆弱了。您需要做一些优化工作。比如处理“集群”问题(比如 memcached 节点都失效了,反复的查询让您的数据库不堪重负… 这个问题在 FAQ 的其他提到过),或者优化不好的查询。记住,Memcached 并不是您逃避优化查询的借口。如果您的麻烦仅仅是重新生成缓存数据需要消耗很长时间(15 秒到超过 5分钟),您可以考虑重新使用数据库。这里给出一些提示:
●使用 MogileFS (或者 CouchDB 等类似的软件)在存储 item。把 item 计算出来并 dump 磁盘上。MogileFS 可以很方便地覆写 item,并提供快速地访问。您甚至可以把 MogileFS 中的 item 缓存在 memcached 中,这样可以加快读取速度。MogileFS+Memcached 的组合可以加快缓存不命中时的响应速度,提高网站的可用性。
●重新使用 MySQL。MySQL 的 InnoDB 主键查询的速度非常快。如果大部分缓存数据都可以放到 VARCHAR 字段中,那么主键查询的性能将更好。从 memcached 中按 key 查询几乎等价于 MySQL 的主键查询:将 key 哈希到 64-bit 的整数,然后将数据存储到 MySQL 中。您可以把原始(不做哈希)的 key 存储都普通的字段中,然后建立二级索引来加快查询…key 被动地失效,批量删除失效的 key,等等。
●上面的方法都可以引入 memcached,在重启 memcached 的时候仍然提供很好的性能。由于不需要当心”hot”的 item 被 memcached LRU 算法突然淘汰,用户再也不用花几分钟来等待重新生成缓存数据(当缓存数据突然从内存中消失时),因此上面的方法可以全面提高性能。
10、memcached 是如何做身份验证的
没有身份认证机制!memcached 是运行在应用下层的软件(身份验证应该是应用上层的职责)。memcached 的客户端和服务器端之所以是轻量级的, 部分原因就是完全没有实现身份验证机制。这样,memcached 可以很快地创建新连接,服务器端也无需任何配置。
如果您希望限制访问,您可以使用防火墙,或者让 memcached 监听 unix domain socket。
11、memcached 的多线程是什么如何使用它们
线程就是定律(threads rule)!在 Steven Grimm 和 Facebook 的努力下, memcached 1.2 及更高版本拥有了多线程模式。多线程模式允许memcached 能够充分利用多个 CPU,并在 CPU 之间共享所有的缓存数据。memcached 使用一种简单的锁机制来保证数据更新操作的互斥。相比在同一个物理机器上运行多个 memcached 实例,这种方式能够更有效地处理 multi gets。
如果您的系统负载并不重,也许您不需要启用多线程工作模式。如果您在运行一个拥有大规模硬件的、庞大的网站,您将会看到多线程的好处。简单地总结一下:命令解析(memcached 在这里花了大部分时间)可以运行在多线程模式下。memcached 内部对数据的操作是基于很多全局锁的(因此这部分工作不是多线程的)。未来对多线程模式的改进,将移除大量的全局锁,提高 memcached 在负载极高的场景下的性能。
12、memcached 能接受的 key 的最大长度是多少
key 的最大长度是 250 个字符。需要注意的是,250是 memcached 服务器端内部的限制,如果您使用的客户端支持”key 的前缀”或类似特性,那么key(前缀+原始 key)的最大长度是可以超过250个字符的。我们推荐使用使用较短的 key ,因为可以节省内存和带宽。
13、memcached 对 item 的过期时间有什么限制
过期时间最大可以达到 30天.memcached 把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached 就把 item 置为失效状态。这是一个简单但 obscure 的机制。
14、memcached 最大能存储多大的单个 item
1MB。如果你的数据大于 1MB,可以考虑在客户端压缩或拆分到多个 key
分布式中间件面试合辑 word文档下载地址:链接:https://pan.baidu.com/s/1TGkSSnUoRjBXGTm0teXkeA
提取码:1111
爆肝一周,不眠不休!就为 点赞+好评+收藏 三连
性能调优合集
JVM性能优化面试篇
1、描述下Java类加载过程
Java类加载需要经历以下7个过程∶
1.加载
加载是类加载的第一个过程,在这个阶段,将完成以下三件事情∶
- 通过一个类的全限定名获取该类的二进制流。
- 将该二进制流中的静态存储结构转化为方法去运行时数据结构。
- 在内存中生成该类的 Class 对象,作为该类的数据访问入口。
2.验证
验证的目的是为了确保 CLass 文件的字节流中的信息不回危害到虚拟机.
在该阶段主要完成以下四钟验证∶
- 文件格式验证∶ 验证字节流是否符合 Class 文件的规范,如主次版本号是否在当前虚拟机范围内,常量池中的常量是否有不被支持的类型.
- 元数据验证∶对字节码描述的信息进行语义分析,如这个类是否有父类,是否集成了不被继承的类等。
- 字节码验证∶ 是整个验证过程中最复杂的一个阶段,通过验证数据流和控制流的分析,确定程序语义是否正确,主要针对方法体的验证。如∶方法中的类型转换是否正确,跳转指令是否正确等。
- 符号引用验证∶ 这个动作在后面的解析过程中发生,主要是为了确保解析动作能正确执行。
3.准备
准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在Java 堆中。
pubLic static int value=123;//在准备阶段value初始值为0 。在初始化阶段才会变为123 。
4.解析
该阶段主要完成符号引用到直接引用的转换动作。解析动作并不一定在初始化动作完成之前,也有可能在初始化之后。
5.初始化
初始化是类加载的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中的定义的iava程序代码。
6.使用
7.卸载
2、Java内存分配
- 寄存器∶我们无法控制。
- 静态域∶ static定义的静态成员。
- 常量池∶ 编译时被确定并保存在.class 文件中的(finaU)常量值和一些文本修饰的符号引用(类和接口的全限定名、字段的名称和描述符,方法和名称和描述符)。
- 非 RAM 存储∶硬盘等永久存储空间。
- 堆内存∶new 创建的对象和数组,由Java 虚拟机自动垃圾回收器管理,存取速度慢。
- 栈内存∶ 基本类型的变量和对象的引用变量(堆内存空间的访问地址),速度快,可以共享,但是大小与生存期必须确定,缺乏灵活性。
1.Java 堆的结构是什么样子的什么是堆中的永久代(Perm Gen space)
- JVM 的堆是运行时数据区,所有类的实例和数组都是在堆上分配内存。它在 JVM 启动的时候被创建。对象所占的堆内存是由自动内存管理系统也就是垃圾收集器回收。
- 堆内存是由存活和死亡的对象组成的。存活的对象是应用可以访问的,不会被垃圾回收。死亡的对象是应用不可访问尚且还没有被垃圾收集器回收掉的对象。一直到垃圾收集器把这些对象回收掉之前,他们会一直占据堆内存空间。
3、描述一下JVM加载Class文件的原理机制
Java 语言是一种具有动态性的解释型语言,类(Class)只有被加载到JVM 后才能运行。当运行指定程序时,JVM 会将编译生成的 .class文件按照需求和一定的规则加载到内存中,并组织成为—个完整的,Java 应用程序。这个加载过程是由类加载器完成,具体来说,就是由ClassLoader 和它的子类来实现的。类加载器本身也是一个类,其实质是把类文件从硬盘读取到内存中。
类的加载方式分为隐式加载和显示加载。隐式加载指的是程序在使用new等方式创
建对象时,会隐式地调用类的加载器把对应的类加载到JVM 中。显示加载指的是通过直接调
用 class.forName() 方法来把所需的类加载到JVM中。
任何一个工程项目都是由许多类组成的,当程序启动时,只把需要的类加载到JVM 中,其他类只有被使用到的时候才会被加载,采用这种方法一方面可以加快加载速度,另一方面可以节约程序运行时对内存的开销。此外,在Java 语言中,每个类或接口都对应一个class 文件,这些文件可以被看成是一个个可以被动态加载的单元,因此当只有部分类被修改时,只需要重新编译变化的类即可,而不需要重新编译所有文件,因此加快了编译速度。
在Java 语言中,类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是保证程序运行的基础类(例如基类)完全加载到JVM中,至于其他类,则在需要的时候才加载。类加载的主要步骤∶
- 装载。根据查找路径找到相应的class 文件,然后导入。
- 链接。链接又可分为3个小步∶
- 检查,检查待加载的class 文件的正确性。
- 准备,给类中的静态变量分配存储空间。
- 解析,将符号引用转换为直接引用这一步可选)
- 初始化。对静态变量和静态代码块执行初始化工作。
4、GC 是什么为什么会有GC
要有 GCGC 是垃圾收集的意思(GabageCollection),内存处理是编程 人员容易出现问题
的地方,忘记或者错误的内存回收会导致程序或 系统的不稳定甚至崩溃,Java 提供的 GC 功
能可以自动监测对象 是否超过作用域从而达到自动回收内存的目的,Java 语言没有提 供释放
已分配内存的显示操作方法。
5、简述 Java 垃圾回收机制。
在 Java 中,程序员是不需要显示的去释放一个对象的内存的,而 是由虚拟机自行执行。在 JVM中,有一个垃圾回收线程,它是低 优先级的,在正常情况下是不会执行的,只有在虚拟机空闲或者当 前堆内存不足时,才会触发执行,扫面那些没有被任何引用的对象。并将它们添加到要回收的集合中,进行回收。
6、如何判断一个对象是否存活(或者 GC 对象的判定方法)
判断一个对象是否存活有两种方法∶
1.引用计数法
所谓引用计数法就是给每一个对象设置一个引用计数器,每当有— 个地方引用这个对象时,
就将计数器加一,引用失效时,计数器就 减一。当一个对象的引用计数器为零时,说明此对
象没有被引用, 也就是"死对象",将会被垃圾回收.
引用计数法有一个缺陷就是无法解决循环引用问题,也就是说当对 象 A引用对象 B,对象 B 又引用者对象 A,那么此时 A、B 对 象的引用计数器都不为零,也就造成无法完成垃圾回收,所以主流的虚拟机都没有采用这种算法。
2.可达性算法(引用链法)
该算法的思想是∶从一个被称为 GC,Roots 的对象开始向下搜索,如果一个对象到 GC Roots 没有任何引用链相连时,则说明此对 象不可用。在 Java 中可以作为 GC Roots的对象有以下几种∶
- 虚拟机栈中引用的对象
- 方法区类静态属性引用的对象
- 方法区常量池引用的对象
- 本地方法栈 JNl 引用的对象
虽然这些算法可以判定一个对象是否能被回收,但是当满足上述条件时,一个对象并不一定会被回收。当一个对象不可达 GC Root 时,这个对象并不会立马被回收,而是处于一个死缓的阶段,若要 被真正的回收需要经历两次标记.
如果对象在可达性分析中没有与 GC Root 的引用链,那么此时就 会被第一次标记并且进行一次筛选,筛选的条件是是否有必要执行
finalize()方法。当对象没有覆盖 finalize()方法或者已被虚拟机调用过,那么就认为是没必要的。如果该对象有必要执行 finalize()方法,那么这个对象将会放在一个称为 F-Queue 的对 队列中,虚拟机会触发一个 FinaLize()线程去执行,此线程是低 优先级的,并且虚拟机不会承诺一直等待它运行完,这是因为如果 finalize() 执行缓慢或者发生了死锁,那么就会造成 F-Queue 队列一直等待,造成了内存回收系统的崩溃。GC 对处于F-Queue 中的对象进行第二次被标记,这时,该对象将被移除"即将回收"集合,等待回收。
7、垃圾回收的优点和原理。并考虑 2 种回收机制。
Java 语言中一个显著的特点就是引入了垃圾回收机制,使 C+ 程序员最头疼的内存管理的问题迎刃而解,它使得 Java 程序员在 编写程序的时候不再需要考虑内存管理。由于有个垃圾回收机制, Java 中的对象不再有"作用域"的概念,只有对象的引用才有"作用域"。垃圾回收可以有效的防止内存泄露,有效的使用可以使 用的内存。垃圾回收器通常是作为—个单独的低级别的线程运行, 不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的 对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对 象或所有对象进行垃圾回收。
回收机制有分代复制垃圾回收和标记垃圾回收, 增量垃圾回收。
8、垃圾回收器的基本原理是什么垃圾回收器可以马上回收内存吗有什么办法主动通知虚拟机进行垃圾回收
对于 GC 来说,当程序员创建对象时,GC就开始监控这个对象 的地t,大小以及使用情况。通常,GC采用有向图的方式记录和 管理堆(heap)中的所有对象。通过这种方式确定哪些对象是"可达的",哪些对象是"不可达的"。当 GC 确定一些对象为"不 可达"时,GC 就有责任回收这些内存空间。可以。程序员可以手动执行 System.gc(),通知 GC运行,但是 Java 语言规范并不 保证 GC 一定会执行。
9、Java 中会存在内存泄漏吗,请简单描述。
所谓内存泄露就是指一个不再被程序使用的对象或变量一直被占 据在内存中。Java 中有垃圾回收机制,它可以保证一对象不再被引用的时候,即对象变成了孤儿的时候,对象将自动被垃圾回收器 从内存中清除掉。由于 Java 使用有向图的方式进行垃圾回收管理, 可以消除引用循环的问题,例如有两个对象,相互引用,只要它们 和根进程不可达的,那么 GC 也是可以回收它们的,例如下面的 代码可以看到这种情况的内存回收∶
import java.io.IOException; public class GarbageTest {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub try { gcTest();
} catch (IOException e) {
// TODO Auto-generated catch block e.printStackTrace();
}
System.out.println("has exited gcTest!"); System.in.read();
System.in.read(); System.out.println("out begin gc!"); for(int i=0;i<100;i++)
{
System.gc(); System.in.read(); System.in.read(); }
}
private static void gcTest() throws IOException { System.in.read();
System.in.read();
Person p1 = new Person(); System.in.read(); System.in.read();
Person p2 = new Person(); p1.setMate(p2); p2.setMate(p1);
System.out.println("before exit gctest!"); System.in.read(); System.in.read();
System.gc(); System.out.println("exit gctest!");
}
private static class Person {
oid setMate(Person other) {
mate = other;
}
}
}
Java 中的内存泄露的情况:长生命周期的对象持有短生命周期对 象的引用就很可能发生内存泄露,尽管短生命周期对象已经不再需 要,但是因为长生命周期对象持有它的引用而导致不能被回收,这 就是 Java 中内存泄露的发生场景,通俗地说,就是程序员可能创 建了一个对象,以后一直不再使用这个对象,这个对象却一直被引 用,即这个对象无用但是却无法被垃圾回收器回收的,这就是 java 中可能出现内存泄露的情况,例如,缓存系统,我们加载了一个对 象放在缓存中 (例如放在一个全局 map 对象中),然后一直不再 使用它,这个对象一直被缓存引用,但却不再被使用。
检查 Java中的内存泄露,一定要让程序将各种分支情况都完整执 行到程序结束,然后看某个对象是否被使用过,如果没有,则才能判定这个对象属于内存泄露。
如果一个外部类的实例对象的方法返回了一个内部类的实例对象, 这个内部类对象被长期引用了,即使那个外部类实例对象不再被使用,但由于内部类持久外部类的实例对象,这个外部类对象将不会 被垃圾回收,这也会造成内存泄露。
下面内容来自于网上(主要特点就是清空堆栈中的某个元素,并不是彻底把它从数组中拿掉,而是把存储的总数减少,本人写得可以比这个好,在拿掉某个元素时,顺便也让它从数组中消失,将那个元素所在的位置的值设置为 null 即可):
我实在想不到比那个堆栈更经典的例子了,以致于我还要引用别人的例子,下面的例子不是我想到的,是书上看到的,当然如果没有在书上看到,可能过一段时间我自己也想的到,可是那时我说是我 自己想到的也没有人相信的
public class Stack {
private Object[] elements=new Object[10]; private int size = 0;
public void push(Object
e){ ensureCapacity();
elements[size++] = e;
}
public Object pop(){
if( size == 0) throw new EmptyStackException(); return element
s[--size];
}
private void ensureCapacity(){ if(elements.length == size){ Object[] oldElements = elements;
elements = new Object[2 * elements.length+1]; System.arraycopy (oldElements,0, elements, 0,
size);
}
}
}
上面的原理应该很简单,假如堆栈加了 10 个元素,然后全部弹 出来,虽然堆栈是空的,没有我们要的东西,但是这是个对象是无 法回收的,这个才符合了内存泄露的两个条件:无用,无法回收。但是就是存在这样的东西也不一定会导致什么样的后果,如果这个 堆栈用的比较少,也就浪费了几个 K内存而已,反正我们的内存都上G了,哪里会有什么影响,再说这个东西很快就会被回收的,有什么关系。
public class Bad{
public static Stack s=Stack(); static{ s.push(new Object());
s.pop(); //这里有—个对象发生内存泄露
s.push(new Object()); //上面的对象可以被回收了,等于是自 愈了
}
}
下面看两个例子。
因为是static,就一直存在到程序退出,但是我们也可以看到它有自愈功能,就是说如果你Stack最多有100个对象,那么最多也就只有100个对象无法被回收其实这个应该很容易理解,Stack内部持有100个引用,最坏的情况就是他们都是无用的,因为我们一旦放新的进取,以前的引用自然消失!
内存泄露的另外一种情况:当一个对象被存储进 HashSet 集合中 以后,就不能修改这个对象中的那些参与计算哈希值的字段了否则,对象修改后的哈希值与最初存储进 HashSet集合中时的哈希值就不同了,在这种情况下,即使在 contains 方法使用该对象的当前引用作为的参数去 HashSet 集合中检索对象,也将返回找不到对象的结果,这也会导致无法合中检索对象,也将返回找不 到对象的结果,这也会导致无法从 HashSet 集合中单独删除当前对象,造成内存泄露。
10、什么是深拷贝、什么是浅拷贝
简单来讲就是复制、克隆。
Person p=new Person(“张三”);
浅拷贝就是对对象中的数据成员进行简单赋值,如果存在动态成员或者指针就会报错。
深拷贝就是对对象中存在的动态成员或指针重新开辟内存空间。
11、System.gc() 和 Runtime.gc() 会做什么事情
这两个方法用来提示 JVM 要进行垃圾回收。但是,立即开始还是 延迟进行垃圾回收是取决于 JVM 的。
12、finalize() 方法什么时候被调用析构函数 (finalization) 的 目的是什么
垃圾回收器(garbage colector)决定回收某对象时,就会运行该 对象的finalize() 方法 但是在 Java 中很不幸,如果内存总是充 足的,那么垃圾回收可能永远不会进行,也就是说 filalize() 可能 永远不被执行,显然指望它做收尾工作是靠不住的。那么 finalize() 究竟是做什么的呢 它最主要的用途是回收特殊渠道 申请的内存。Java 程序有垃圾回收器,所以一般情况下内存问题 不用程序员操心。但有一种 JNI(Java Native Interface)调用non-Java 程序(C 或 C++), finalize() 的工作就是回收这部 分的内存。
13、如果对象的引用被置为 null垃圾收集器是否会立即释放对象占 用的内存
不会,在下一个垃圾回收周期中,这个对象将是可被回收的。
14、什么是分布式垃圾回收(DGC)它是如何工作的
DGC 叫做分布式垃圾回收。RMI 使用 DGC 来做自动垃圾回收。因为 RMI 包含了跨虚拟机的远程对象的引用,垃圾回收是很困难 的。DGC 使用引用计数算法来给远程对象提供自动内存管理。
15、串行(serial)收集器和吞吐量(throughput)收集器的区别是什么
吞吐量收集器使用并行版本的新生代垃圾收集器,它用于中等规模 和大规模数据的应用程序。而串行收集器对大多数的小应用(在 现代处理器上需要大概 100M 左右的内存)就足够了。
16、在 Java 中对象什么时候可以被垃圾回收
当对象对当前使用这个对象的应用程序变得不可触及的时候,这个 对象就可以被回收了。
17、简述 Java 内存分配与回收策率以及 Minor GC 和 Major GC)
- 对象优先在堆的 Eden 区分配
- 大对象直接进入老年代
- 长期存活的对象将直接进入老年代
当 Eden 区没有足够的空间进行分配时,虚拟机会执行一次 Minor GC。Minor GC 通常发生在
新生代的 Eden 区,在这个区 的对象生存期短,往往发生 Gc 的频率较高,回收速度比较快; FullGC/Major GC 发生在老年代,一般情况下,触发老年代 GC 的时候不会触发 Minor GC,但是通过
配置,可以在 Full GC 之 前进行一次 Minor GC 这样可以加快老年代的回收速度。
18、JVM 的永久代中会发生垃圾回收么
垃圾回收不会发生在永久代,如果永久代满了或者是超过了临界值, 会触发完全垃圾回收(Full GC)。
注: Java 8 中已经移除了永久代,新加了一个叫做元数据区的 native 内存区。
19、Java 中垃圾收集的方法有哪些
标记 - 清除:这是垃圾收集算法中最基础的,根据名字就可以知道,它的思想就是标记哪些要被回收的对象,然后统一回收。这种方法很简单,但是会有两个主要问题:
1. 效率不高,标记和清除的效率都很低;
2. 会产生大量不连续的内存碎片,导致以后程序在分配较大的对象时,由于没有充足的连续内存而提前触发一次 GC 动作。
复制算法:为了解决效率问题,复制算法将可用内存按容量划分为相等的两部分,然后每次只使用其中的一块,当一块内存用完时,就将还存活的对象复制到第二块内存上,然后一次性清楚完第一块内存,再将第二块上的 对象复制到第一块。但是这种方式,内存的代价太高,每次基本上都要浪 费一般的内存。于是将该算法进行了改进,内存区域不再是按照 1:1 去划分,而 是将内存划分为 8:1:1 三部分,较大那份内存交 Eden 区,其余是两块较小的内存区叫 Survior 区。每次都会优先使用 Eden 区, 若 Eden 区满,就将对象复制到第二块内存区上,然后清除 Eden 区,如果此时存活的对象太多,以至于 Survivor 不够时,会将这 些对象通过分配担保机制复制到老年代中。(java 堆又分为新生代和老年代)
标记 - 整理:该算法主要是为了解决标记 - 清除,产生大量内存 碎片的问题;当对象存活率较高时,也解决了复制算法的效率问题。它的不同之处就是在清除对象的时候现将可回收对象移动到一端, 然后清除掉端边界以外的对象,这样就不会产生内存碎片了。
分代收集:现在的虚拟机垃圾收集大多采用这种方式,它根据对象的生存周期,将堆分为新生代和老年代。在新生代中,由于对象生存期短,每次回 收都会有大量对象死去,那么这时就采用复制算法。老年代里的对象存活率较高,没有额外的空间进行分配担保。
20、什么是类加载器类加载器有哪些
实现通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。 主要有一下四种类加载器:
- 启动类加载器(BootstrapClassLoader)用来加载Java核 心类库,无法被Java 程序直接引用。
- 扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类 加载器在此目录里面查找并加载 Java 类。
- 系统类加载器(system class loader):它根据 Java 应用 的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过 ClassLoader.getSystemClassLoader() 来获取它。
- 用户自定义类加载器,通过继承 java.lang.ClassLoader 类 的方式实现。
21、类加载器双亲委派模型机制
当一个类收到了类加载请求时,不会自己先去加载这个类,而是将其委派给父类,由父类去加载,如果此时父类不能加载,反馈给子类,由子类去完成类的加载。
22、一个新系统开发完毕之后如何设置JVM参数?
首先应该估算一下自己负责的系统每个核心接口每秒多少次请求,每次请求会创建多少个对象,每个对象大概多大,每秒钟会使用多少内存空间?
这样接着就可以估算出来Eden区大概多长时间会占满?
然后就可以估算出来多长时间会发生一次Young GC,而且可以估算一下发生Young GC的时候,会有多少对象存活下来,会有多少对
象升入老年代里,老年代对象增长的速率大概是多少,多久之后会触发一次Full GC。
通过一连串的估算,就可以合理的分配年轻代和老年代的空间,还有Eden和Survivor的空间
原则就是:尽可能让每次Young GC后存活对象远远小于Survivor区域,避免对象频繁进入老年代触发Full GC。
最理想的状态下,就是系统几乎不发生Full GC,老年代应该就是稳定占用一定的空间,就是那些长期存活的对象在躲过15次Young
GC后升入老年代自然占用的。然后平时主要就是几分钟发生一次Young GC,耗时几毫秒。
23、在压测之后合理调整JVM参数
任何一个新系统上线都得进行压测,此时在模拟线上压力的场景下,可以用jstat等工具去观察JVM的运行内存模型:
Eden区的对象增长速率多块?
Young GC频率多高?
一次Young GC多长耗时?
Young GC过后多少对象存活?
老年代的对象增长速率多高?
Full GC频率多高?
一次Full GC耗时?
压测时可以完全精准的通过jstat观察出来上述JVM运行指标,让我们对JVM运行时的情况了如指掌。然后就可以尽可能的优化JVM的内
存分配,尽量避免对象频繁进入老年代,尽量让系统仅仅有Young GC。
24、线上系统的监控和优化
系统上线之后,务必进行一定的监控,高大上的做法就是通过Zabbix、Open-Falcon之类的工具来监控机器和JVM的运行,频繁Full
GC就要报警。
比较差一点的做法,就是在机器上运行jstat,让其把监控信息写入一个文件,每天定时检查一下看一看。
一旦发现频繁Full GC的情况就要进行优化,优化的核心思路是类似的:通过jstat分析出来系统的JVM运行指标,找到Full GC的核心问
题,然后优化一下JVM的参数,尽量让对象别进入老年代,减少Full GC的频率。
25、线上频繁Full GC的几种表现
其实通过之前的各种案例,大家可以总结出来,一旦系统发生频繁Full GC,大概看到的一些表象如下:
机器CPU负载过高;
频繁Full GC报警;
系统无法处理请求或者处理过慢
所以一旦发生上述几个情况,大家第一时间得想到是不是发生了频繁Full GC。
26、频繁Full GC的几种常见原因
频繁Full GC的原因:
系统承载高并发请求,或者处理数据量过大,导致Young GC很频繁,而且每次Young GC过后存活对象太多,内存分配不合理,
Survivor区域过小,导致对象频繁进入老年代,频繁触发Full GC。
系统一次性加载过多数据进内存,搞出来很多大对象,导致频繁有大对象进入老年代,必然频繁触发Full GC
系统发生了内存泄漏,莫名其妙创建大量的对象,始终无法回收,一直占用在老年代里,必然频繁触发Full GC
Metaspace(永久代)因为加载类过多触发Full GC
误调用System.gc()触发Full GC
其实常见的频繁Full GC原因无非就上述那几种,所以大家在线上处理Full GC的时候,就从这几个角度入手去分析即可,核心利器就是
jstat。
如果jstat分析发现Full GC原因是第一种,那么就合理分配内存,调大Survivor区域即可。
如果jstat分析发现是第二种或第三种原因,也就是老年代一直有大量对象无法回收掉,年轻代升入老年代的对象病不多,那么就dump
出来内存快照,然后用MAT工具进行分析即可
通过分析,找出来什么对象占用内存过多,然后通过一些对象的引用和线程执行堆栈的分析,找到哪块代码弄出来那么多的对象的。接
着优化代码即可。
如果jstat分析发现内存使用不多,还频繁触发Full GC,必然是第四种和第五种,此时对应的进行优化即可。
27、发生FullGC
- youngGC 之前 ,空间担保机制,老年代的连续空间小于 新生代所有对象总大小 和 历次晋升的平均大小
- youngGC 之后 新生代幸存的对象大小 老年代放不下了。
- 大对象放不下老年代
- 老年代的大小 达到阈值了
- 元空间满了
- 你调用了 System.gc
28、可能发生OOM的地方
元空间(class太多了)
第一种原因,很多工程师他不懂JVM的运行原理,在上线系统的时候对Metaspace区域直接用默认的参数,即根本不设置其大小
这会导致默认的Metaspace区域可能才几十MB而已,此时对于一个稍微大型一点的系统,因为他自己有很多类,还依赖了很多外
部的jar包有有很多的类,几十MB的Metaspace很容易就不够了
第二种原因,就是很多人写系统的时候会用cglib之类的技术动态生成一些类,一旦代码中没有控制好,导致你生成的类过于多的
时候,就很容易把Metaspace给塞满,进而引发内存溢出
栈内存
出现了死循环调用,或者是无限制的递归调用,
堆内存
对象太多,且都是存活的,即使GC过后还是没有空间了,此时放不下新的对象
29、如何定位OOM
- jvm 需要加上 打印 gc.log ,配置内存溢出参数, 内存溢出的时候导出来一份内存快照到我们指定的位置
- 发生oom 会推送通知。
- 然后看日志
- 看看到底是堆内存溢出?还是栈内存溢出?或者是Metaspace内存溢出?首先得确定一下具体的溢出类型
- 看看是哪个线程运行代码的时候内存溢出了。因为Tomcat运行的时候不光有自己的工作线程,我们写的代码也可能会创建一些线程出来
- 接着通过 mat 分析dump 是什么对象导致的,找到对应的代码行。
使用工具
jstat 查看 fgc ygc 次数 时长,每个空间的使用大小
jmap dump 文件
mat 查看堆的分配大小
jstack 查看死锁
30、生成环境如何设置堆内存大小
- QPS * 对象的大小 * 对象数量 算出 每秒产生的大小,比如每秒20M
- 每个事件大概可以处理的时间,比如1秒。
- 那么可以算出大概每秒产生 20M 的垃圾。
- 比如2核4G的机器
- 分配2GJVM,1.5G堆。可以设置500兆 年轻代,其中设置比例为8:1:1,每个 survivor区为 50M,Eden区400兆,700兆老年代,300兆元空间。
- 元空间设置,防止我们用了反射,默认几十兆不够用。
31、jvm内存分为哪几块
java虚拟机栈,本地方法栈,堆,程序计数器,方法区
32、说说JVM的垃圾回收算法?
复制
标记清除
标记整理
分代算法
收集器
- serial
- ParNew
- cms
- g1
CMS流程
- 初始标记,会发生 STW ,主要标记GC ROOT。
- 并发标记,比较费时间,主要是从GC ROOT 追踪那些引用的对象,也就是标记那些存活的对象和不存活的对象
- 重新标记,会发生 STW ,重新标记下在第二阶段里新创建的一些对象,还有一些已有对象可能失去引用变成垃圾的情况
- 并发清除。
33、G1是什么
- 他最大的一个特点,就是把Java堆内存拆分为多个大小相等的Region。
- 每个region为 2的 倍数,比如 1M,2M。
- 然后G1也会有新生代和老年代的概念,但是只不过是逻辑上的概念,最开始默认新生代5%。
- G1还有一个特点,就是可以让我们设置一个垃圾回收的预期停顿时间。在一个时间内,垃圾回收导致的系统停顿时间不能超过多久,G1全权给你负责,保证达到这个目标。
- 他会追踪每个Region里的回收价值,也就是计算每个region 需要耗费多长时间,可以回收掉多少垃圾
- 新生代的 Eden 区和 Survivor 区,也是可以设置比例的,大小随着空间变化。新生代达到了60%,就会发生ygc。
- 老年代达到了 45% ,会发生 mixedGC,新生代和老年代一起GC。
34、G1流程
- 初始标记
- 并发标记
- 最终标记
- 混合回收(回收老年代,新生代)可以设置分几次回收。默认8次。当回收到5%(可配置)就不回收了。
35、对象什么时候转移到老年代?
- 大对象
- ygc之后年轻代放不下
- 动态年龄机制,ygc之后对象的生命从小到大排序,当超过survivor区的一半,就将年龄大的对象放到老年代。
- 连续15次 ygc之后,对象放到老年代
36、常量存储在哪里?
运行时常量存在方法区,字符串常量存在堆区。
37、自定义加载器
- 创建一个类继承ClassLoader抽象类
- 重写findClass()方法
- 在findClass()方法中调用defineClass()
Tomcat调优面试篇
1、你会怎样给Tomcat进行调优
1.JVM参数调优
-Xms表示 JVM 初始化堆的大小, Xmx表示 JVM 堆的最大值。这两个值的大小一般根据需要进行设置。当应用程序需要的内存超出堆的最大值时虚拟机就会提示内存溢出,并且导致应用服务崩溃。因此一般建议堆的最大值设置为可用内存的最大值的80%。在catalina.bat 中,设置 JAVA_OPTS=‘-Xms256m- Xmx512m’,表示初始化内存为256MB,可以使用的最大内存为512MB。
2.禁用DNS查询
当web应用程序想要记录客户端的信息时,它也会记录客户端的IP地址或者通过域名服务器查找机器名转换为IP地址。DNS查询需要占用网络,并且包括可能从很多很远的服务器或者不起作用的服务器上去获取对应的IP的过程,这样会消耗一定的时间。为了消除DNS查询对性能的影响我们可以关闭DNS查询,方式是修改 server.xmL 文件中的lenableLookups,参数值:
Tomcat4
3.调整线程数
通过应用程序的连接器 (Connector)进行性能控制的的参数是创建的处理请求的线程数。Tomcat 使用线程池加速响应速度来处理请求。在 Java中线程是程序运行时的路径,是在一个程序中与其它控制线程无关的、能够独立运行的代码段。它们共享相同的地址空间。多线程帮助程序员写出CPU最大利用率的高效程序,使空闲时间保持最低,从而接更多的请求。Tomcat4中可以通过修改 minProcessors 和 maxProcessors 的值来控制线程数。这些值在安装后就已经设定为默认值并且是足够使用的,但是随着站点的扩容而改大这些值。minProcessors 服务器启动时创建的处理请求的线程数应该足够处理一个小量的负载。也就是说,如果一天内每秒仅发生5次单击事件, 并且每个请求任务处理需要1秒钟,那么预先设置线程数为5就足够了。但在你的站点访问量较大时就需要设置更大的线程数,指定为参数 maxProcessors 的值。maxProcessors 的值也是有上限的,应防止流量不可控制(或者恶意的服务攻击),从而导致超出了虚拟机使用内存的大小。如果要加大并发连接数,应同时加大这两个参数。web server允许的最大连接数还受制于操作系统的内核参数设置,通常Windows是2000个左右,Linux是1000个左右。
在 Tomcat5 对这些参数进行了调整,请看下面属性∶
- maxThreads Tomcat 使用线程来处理接收的每个请求。这个值表示 Tomcat可创建的最大的线程数。
- acceptCount 指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理。
- connnection Timeout 网络连接超时,单位∶ 毫秒。设置为0表示永不超时,这样设置有隐患的。通常可设置为30000毫秒。
- minSpareThreadsTomcat 初始化时创建的线程数。
- maxSpareThreads 一旦创建的线程超过这个值,Tomcat 就会关闭不再需要的 socket 线程。
最好的方式是多设置几次并且进行测试,观察响应时间和内存使用情况。在不同的机器、操作系统或虚拟机组合的情况下可能会不同,而且并不是所有人的web站点的流量都是一样的,因此没有一刀切的方案来确定线程数的值。
2、如何加大Tomcat连接数
在 Tomcat 配置文件 server,xmL 中的 配置中,和连接数相关的参数有∶
- minProcessors ∶ 最小空闲连接线程数,用于提高系统处理性能,默认值为10∶
- maxProcessors: 最大连接线程数,即∶ 并发处理的最大请求数,默认值为75
- acceptCount∶允许的最大连接数,应大于等于maxProcessors,默认值为100
- enabLeLookups∶是否反查域名,取值为∶ true或false。为了提高处理能力,应设置为falseconnection
- connectionTimeout∶网络连接超时,单位∶ 毫秒。设置为0表示永不超时,这样设置有隐患的。通常可设置为30000
- web server :允许的最大连接数还受制于操作系统的内核参数设置,通常Windows是2000个左右,Linux是1000个左右。
tomcat5的配置参数:
对于其他端口的侦听配置,以此类推。
3、怎样加大Tomcat的内存
首先检查程序有没有陷入死循环这个问题主要还是由这个问题
java.Lang.0utOfMemoryError∶Java heap space引起的。第一次出现这样的的问题以后,
引发了其他的问题。在网上一查可能是JAVA的堆栈设置太小的原因。根据网上的答案大致有
这两种解决方法∶
1、设置环境变量
解决方法∶手动设置 Heap size
修改 TOMCAT_HOME/bin/catalina. sh
setJAVA_OPTS=-Xms32m-Xmx512m
可以根据自己机器的内存进行更改。
2、java-Xms32m-Xmx800m classNamel
在执行JAVA类文件时加上这个参数,其中className是需要执行的全类路径名。这个解决问题了。而且执行的速度比没有设置的时候快很多。如果在测试的时候可能会用
Eclispe这时候就需要在 Eclipse->run-arguments 中的 WM arguments 中输入-Xms32m-Xmx800m 这个参数就可以了。
后来在Ecilpse中修改了启动参数,在VMarguments加入了 -Xms32m-Xmx800m,问题解决。
一、java.lang.0utOfMemoryError∶PermGen space
PermGen space 的全称是 Permanent Generation space ,是指内存的永久保存区域,
这块内存主要是被JVM存放Class和Meta信息的,Class在被Loader时就会被放到 PermGen space 中,它和存放类实例(nstance)的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对 PermGen space进行清理,所以如果你的应用中有很多CLASS的话,就很可能出现 PermGen space 错误,这种错误常见在web服务器对JSP进行 preco mpile 的时候。如果你的 WEB APP 下都用了大量的第三方jar,其大小超过了jvm默认的大小(4M)那么就会产生此错误信息了。
解决方法∶
手动设置MaxPermSize大小修改TOMCAT_H0ME/bin/catalina.sh在 "echo"Using
CATALINA_BASE∶$CATALINA_BASE"“上面加入以下行∶JAVA_OPTS=”-server-
XX∶PermSize=64M-XX∶MaxPermSize=128m
建议∶将相同的第三方jar文件移置到tomcat/shared/Lib目录下,这样可以达到减少jar文档重复占用内存的目的。
二、java.Lang.0ut0fMemoryError:Java heap space Heap size 设置
JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置 Heap sizel的值,其初始空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1/4。可以利用JVM提供的一-Xmn-Xms-Xmx 等选项可进行设置。Heap size 的大小是 Young Generation 和 TenuredGeneraion之和。
提示∶ 在JVM中如果98%的时间是用于GC且可用的 Heap size 不足2%的时候将抛出此异常信息。
提示∶ Heap Size 最大不要超过可用物理内存的80%,一般的要将 Xms 和-Xmx选项设置为相同,而-Xmn 为1/4的 -Xmx值。
解决方法∶ 手动设置 Heap size修改 TOMCAT_HOME/bin/catalina.sh在"echo"Using CATALINABASE∶$CATALINA_BASE"“上面加入以下行∶ JAVA_OPTS=”-server-Xms800m-Xmx800m-XX:MaxNewSize=256m"
三、实例给出以下1G内存环境下java jvml的参数设置参考∶
JAVA_OPTS="-server-Xms800m-Xmx800m-XX:PermSize=64M-XX:MaxNewSize=256m-XX:MaxPermSize=128m- Djava.awt. headless=true"很大的web工程,用tomcat默认分配的内存空间无法启动,如果不是在 myeclipse中启动tomcat可以对tomcat这样设置∶
T0MCAT_HOME/bin/cataLina.bat 中添加这样一句话∶
set JAVA_OPTS=-server-Xms2048m-Xmx4096m-XX:PermSize=512M-XX:MaxPermSize=1024M-Duser.timezone=GMT+08或者set JAVA_OPTS=-Xmx1024M-Xms512M-XX:MaxPermSize=256m如果要在myeclipse中启动,上述的修改就不起作用了,可如下设置∶ Myeclipse->preferences->myeclipse->servers->tomcat->tomcat×.x->JDK 面板中的 0ptional Java WM arguments 中添加∶Xmx1024M-Xms512M-XX:MaxPermSize=256m
以上是转贴,但本人遇见的问题是∶ 在myeclipse中启动Tomcat时,提示"Java.Lang.0utOfMemoryError∶Java heap space",
解决办法就是∶
MyecLipse->preferences→>myecLipse>servers->tomcat->tomcat×.×->JDK 面板中的Optional Java VM arguments 中添加∶-Xmx1024M-Xms512M- XX:MaxPermSize=256m
4、tomcat中如何禁止列目录下的文件
在 {tomcat_home}/conf/web.xmL中,把listings参数设置成false即可,
如下∶
<φparam-name>listingsfalse
Listings false
5、Tomcat有几种部署方式 tomcat中四种部署项目方法
第一种方法∶
在 tomcat 中的 conf目录中,在 server.xml中的,
至于 Context 节点属性,可详细见相关文档。
第二种方法∶
将 web 项目文件件拷贝到 webapps 目录中。
第三种方法∶
在conf目录中,新建 CataLinaLoca Lhost 目录,在该目录中新建一个xmL 文件,名字可以随意取,只要和当前文件中的文件名不重复就行了,该 xmL 文件的内容为∶
第3个方法有个优点,可以定义别名。服务器端运行的项目名称为 path,外部访问的 URL 则使用XML的文件名。这个方法很方便的隐藏了项目的名称,对一些项目名称被固定不能更换,但外部访问时又想换个路径,非常有效。
第2、3还有优点,可以定义一些个性配置,如数据源的配置等。
第四种方法∶
可以用 tomcat在线后台管理器,一般 tomcat 都打开了,直接上传 warl就可以。
6、Tomcat的优化经验
Tomcat 作为 web 服务器,它的处理性能直接关系到用户体验,下面是种常见的优化措施∶
- 去掉对 web.xmL的监视,把 jsp 提前编辑成 ServLet,存的情况,加大 tomcat 使用的 jvm 的内存。
- 服务器资源:服务器所能提供CPU、内存、硬盘的性能对处理能力有决定性影响。
- 对于高并发情况下会有大量的运算,那么CPU的速度会直接影响到处理速度。
- 内存在大量数据处理的情况下,将会有较大的内存容量需求,可以用-Xmx-Xms-XX∶MaxPermSize 等参数对内存不同功能块进行划分。我们之前就遇到过内存分配不足,导致虚拟机一直处于 fuLL GC ,从而导致处理能力严重下降。
- 硬盘主要问题就是读写性能,当大量文件进行读写时,磁盘极容易成为性能瓶颈。最好的办法还是利用下面提到的缓存。
- 利用缓存和压缩
对于静态页面最好是能够缓存起来,这样就不必每次从磁盘上读。这里我们采用了Nginx作为缓存服务器,将图片、css、js文件都进行了缓存,有效的减少了后端tomcat的访问。另外,为了能加快网络传输速度,开启 gzip压缩也是必不可少的。但考虑到tomcat已经需要处理很多东西了,所以把这个压缩的工作就交给前端的Nginx来完成。
除了文本可以用gzip压缩,其实很多图片也可以用图像处理工具预先进行压缩,找到一个平衡点可以让画质损失很小而文件可以减小很多。曾经我就见过一个图片从300多kb压缩到几十kb,自己几乎看不出来区别。
- 采用集群
单个服务器性能总是有限的,最好的办法自然是实现横向扩展,那么组建 tomcat集群是有效提升性能的手段。我们还是采用了Nginx来作为请求分流的服务器,后端多个tomcat共享session来协同工作。可以参考之前写的《利用nginx+tomcat+memcached组建web服务器负载均衡》。
- 优化tomcat参数
这里以tomcat7的参数配置为例,需要修改conf/server.xml文件,主要是优化连接配置,关闭客户端dns查询。
MySQL调优面试篇
1、为什么要分库分表(设计高并发系统的时候,数据库层面该如何设计)?
分表
比如你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?
就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
分库
分库是啥意思?
就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
分库分表前
分库分表后
并发支撑情况
MySQL 单机部署,扛不住高并发
MySQL从单机到多机,能承受的并发增加了多倍
磁盘使用情况
MySQL 单机磁盘容量几乎撑满
拆分为多个库,数据库服务器磁盘使用率大大降低
SQL 执行性能
单表数据量太大,SQL 越跑越慢
单表数据量减少,SQL 执行效率明显提升
这就是所谓的分库分表。
2、用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?
Sharding-jdbc
当当开源的,属于 client 层(项目直接依赖jar)方案,目前已经更名为 ShardingSphere(后文所提到的 Sharding-jdbc,等同于 ShardingSphere)。确实之前用的还比较多一些,因为 SQL 语法支持也比较多,没有太多限制。支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从 2017 年一直到现在,是有不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
Mycat
属于 proxy 层(类似于中间件)方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
总结
Sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,
缺点但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合Sharding-jdbc 的依赖;
Mycat 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用 Sharding-jdbc,client 层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;但是中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即可
3、你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
好了,无论分库还是分表,上面说的那些数据库中间件都是可以支持的。就是基本上那些中间件可以做到你分库分表之后,中间件可以根据你指定的某个字段值,比如说 userid,自动路由到对应的库上去,然后再自动路由到对应的表里去。
4、你的项目里该如何分库分表?
一般来说,垂直拆分,你可以在表层面来做,对一些字段特别多的表做一下拆分;水平拆分,你可以说是并发承载不了,或者是数据量太大,容量承载不了,你给拆了,按什么字段来拆,你自己想好;分表,你考虑一下,你如果哪怕是拆到每个库里去,并发和容量都 ok 了,但是每个库的表还是太大了,那么你就分表,将这个表分开,保证每个表的数据量并不是很大。
分库分表的方式(水平拆分)
一种是按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
或者是按照某个字段 hash 一下均匀分散,这个较为常用。
range 来分,好处在于说,扩容的时候很简单,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用 range,要看场景。
hash 分发,好处在于说,可以平均分配每个库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表。
5、现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表上?
停机迁移方案:
1.网站或者app 挂个公告,0-6点进行运维,无法访问。
2.接着到0点停机,系统停掉,没有有流量写入了,此时老的单库单表数据库静止了。然后通过写好一个导数的一次性工具系统,然后直接启动连接到新的分库分表上去,开多台机器执行。
3.修改服务的新的数据库地址配置信息,重新发布系统。然后验证一下,就完事了。如果有问题,没到3点重试,否则直接回滚到单表。第二天凌晨重试。
4.600万数据 可以通过 开3台机器(每个机器每小时大概可以迁移180万的数据量) 每台机器多线程开20个线程跑。
不停机双写迁移方案
1、简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改,这就是所谓的双写,同时写俩库,老库和新库。
2、然后系统部署之后,新库数据差太远,用之前说的导数工具,跑起来读老库数据写新库,写的时候要根据 gmt_modified 这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。
3、导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。
4、接着当数据完全一致了,就 ok 了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有几个小时的停机时间,很稳。所以现在基本玩儿数据迁移之类的,都是这么干的。
6、如何设计可以动态扩容缩容的分库分表方案?
一开始上来就是 32 个库,每个库 32 个表,那么总共是 1024 张表。
我可以告诉各位,这个分法,
第一,基本上国内的互联网肯定都是够用了
第二,第二,无论是并发支撑还是数据量支撑都没问题。
每个库正常承载的写入并发量是 1000,那么 32 个库就可以承载 32 * 1000 = 32000 的写并发,如果每个库承载 1500 的写并发,32 * 1500 = 48000 的写并发,接近 5 万每秒的写入并发,前面再加一个MQ,削峰,每秒写入 MQ 8 万条数据,每秒消费 5 万条数据。
有些除非是国内排名非常靠前的这些公司,他们的最核心的系统的数据库,可能会出现几百台数据库的这么一个规模,128 个库,256 个库,512 个库。
1024 张表,假设每个表放 500 万数据,在 MySQL 里可以放 50 亿条数据。
每秒 5 万的写并发,总共 50 亿条数据,对于国内大部分的互联网公司来说,其实一般来说都够了
刚开始的时候,这个库可能就是逻辑库,建在一个数据库上的,就是一个 MySQL 服务器可能建了 n 个库,比如 32 个库。后面如果要拆分,就是不断在库和 MySQL 服务器之间做迁移就可以了。然后系统配合改一下配置即可。
比如说最多可以扩展到 32 个数据库服务器,每个数据库服务器是一个库。如果还是不够?最多可以扩展到 1024 个数据库服务器,每个数据库服务器上面一个库一个表。因为最多是 1024 个表。
这么搞,是不用自己写代码做数据迁移的,都交给 DBA 来搞好了,但是 DBA 确实是需要做一些库表迁移的工作,但是总比你自己写代码,然后抽数据导数据来的效率高得多吧。
哪怕是要减少库的数量,也很简单,其实说白了就是按倍数缩容就可以了,然后修改一下路由规则。
这里对步骤做一个总结:
1.设定好几台数据库服务器,每台服务器上几个库,每个库多少个表,推荐是 32 库 * 32 表,对于大部分公司来说,可能几年都够了。
2.路由的规则,orderId 模 32 = 库,orderId / 32 模 32 = 表
3.扩容的时候,申请增加更多的数据库服务器,装好 MySQL,呈倍数扩容,4 台服务器,扩到 8 台服务器,再到 16 台服务器。
4.由 DBA 负责将原先数据库服务器的库,迁移到新的数据库服务器上去,库迁移是有一些便捷的工具的。
5.我们这边就是修改一下配置,调整迁移的库所在数据库服务器的地址。
6.重新发布系统,上线,原先的路由规则变都不用变,直接可以基于 n 倍的数据库服务器的资源,继续进行线上系统的提供服务。
7、分库分表之后,id 主键如何处理?
数据库自增id
l通过单独的获取id服务器,获取id
优点:可以确保每个id是唯一的,
缺点:高并发的话,就会有瓶颈
适合的场景:这种适合数据量大,但是并发量比较低的场景。
l设置数据库 sequence 或者表自增字段步长
比如说,现在有 8 个服务节点,每个服务节点使用一个 sequence 功能来产生 ID,每个 sequence 的起始 ID 不同,并且依次递增,步长都是 8。
适合的场景:可以防止产生的ID重复时,这种方案实现起来比较简单,也能到达性能目标。但是服务节点固定,步长也固定,将来还要增加服务节点,就不好搞了。
UUID
好处就是本地生成,不要基于数据库来了;不好之处就是,UUID 太长了、占用空间大,作为主键性能太差了;更重要的是,UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作(连续的 ID 可以产生部分顺序写),还有,由于在写的时候不能产生有顺序的 append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显。
适合的场景:如果你是要随机生成个什么文件名、编号之类的,你可以用 UUID,但是作为主键是不能用 UUID 的。
获取系统当前时间
这个就是获取当前时间即可,但是问题是,并发很高的时候,比如一秒并发几千,会有重复的情况,这个是肯定不合适的。基本就不用考虑了。
适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个 id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号。
snowflake 算法
snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala语言实现,id 是 64 位 long 型的。
l1 bit:不用,代表是正数
l41 bits:代表的是时间戳,单位是毫秒。换算成年大概是69年
l10 bits:记录工作机器id,最多可以不是 2^10 机器 1024,其中 5 bits 代表机房id 32个机房,5 bits 代表机器id 32台机器
l12 bits:这里用来记录同一个毫秒内产生的不同id,12 bits 可以代表的最大正整数是 2^12 - 1 = 4096,也就是说可以用这个 12 bits 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
获取id流程:
首先自己搞一个服务,然后对每个机房的每个机器都初始化这么一个id,刚开始这个机房的这个机器的序号就是 0。然后每次接收到一个请求,说这个机房的这个机器要生成一个 id,你就找到对应的 Worker 生成。
通过 synchronized保证线程安全 获取 id ,41 bit是当前毫秒单位的一个时间戳,然后传进来的32以内的机房 id和32以内的机器 id,
1.如果跟上次生成 id 的时间还在一个毫秒内,毫秒内存序列+1;毫秒内序列溢出,超过 4096 ,序列重置为 0,阻塞到下一个毫秒,重新获取时间戳。
2.如果发生了系统时间回调,也就是当前时间戳大于上一次的时间戳。
l方案一是发现时钟回拨后,算出来回拨多少,保存为时间偏移量,然后后面每次获取时间戳都加上偏移量,每回拨一次更新一次偏移量
l方案二是,只在第一次生成id或启动时获取时间戳并保存下来,每生成一个id,就计下数,每个毫秒数能生成的id数是固定的,到生成满了,再把时间戳加一,这样就不依赖于系统时间了,每个毫秒数的使用率也最高
优点:
高性能高可用:不依赖数据库,完全纯内存
容量大:每秒中能生成数百万的自增ID。
ID自增:存入数据库中,索引效率高。
缺点:
严重依赖系统时间,系统时间被回调,或者改变,可能会造成id冲突或者重复。
8、如何实现 MySQL 的读写分离?
就是基于主从复制架构,简单来说,就是搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
9、MySQL 主从复制原理的是啥?
主要原理
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 日志中。接着从库中有一个 SQL 线程从 relay日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
延时问题
这里有过一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。
压测过,大概 主库并发量 1000/s 延时 几毫秒,2000/s 延时 几十毫秒,当达到4000 , 5000/s,主库都快死了,此时从库 延时会达到几秒钟。
大概在 mysql5.6版本之后, 从库 IO线程,读取主库的binlog 日志的时候,也可以支持多线程读取。
宕机问题,对应的 半同步复制 和 并行复制
场景:当主库突然宕机,然后恰好数据还没有同步到从库,那么有些数据可能从库上是还没有的,有些数据可能就丢失了。
所以 MySQL 实际上在这一块有两个机制,一个是半同步复制,用来解决主库数据丢失问题;一个是并行复制,用来解决主从同步延时问题。
半同步复制
也就是 semi-sync复制,指的是主库写入 bingo 日志之后吗,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 主库,主库接收到至少一个从库的 ack 之后才会认为操作完成了。
并行复制
指的是从库开启多个 SQL 线程,并行读取 relay log 中不同 库的日志, 然后并发重放不同库的日志,这是库级别的并行。
10、MySQL 主从同步延时问题(精华)
场景:先插入一条数据,再把它查出来,然后更新这个条数据。在生产环境达到 2000/s,这个时候,主从复制延迟大概是小几十毫秒。那么一些数据,在高峰期时候没有更新。因为延时,导致查询从库不能立刻查到。(查询时候 没有数据为null ,更新 通过id =null,导致更新失败)
l重写代码,写代码的时候,插入之后,直接更新。不要查询再更新。
l如果必须要查询,插入之后,设置直连主库查询,再更新。(不推荐这种方法,这种读写分离的意义就丧失了)
l分库,将一个主库分为多个主库,每个主库的写并发就减少了几倍,此时主从延时可以忽略不计。
l打开 MySQL 支持的并发复制,多个库并行复制。但是这种,在高并发,某个库单库并发达到 2000/s,并发复制还是没有意义的。
11、事务特性
l原子性
l一致性
l隔离性
l持久性
12、事务的隔离级别
隔离性存在的问题
l脏写:两个事务都更新一个数据,结果有个一人回滚了把另外一个人更新的数据也回滚没了。
l脏读:一个事务读到了另外一个事务没有提交的时候修改数据,结果另外一个事务回滚了,下次读就读不到了。
l不可重复读:就是多次读一条数据,别的事务老是修改数据值还提交了,多次读到的值不同。
l幻读:就是范围查询,每次查到的数据不同,有时候别的事务插入了新的值,就会读到更多的数据。
几种隔离级别
lRU:可以读到别人没有提交的事务修改的数据,只能避免脏写。
lRC:可以读到人家提交的事务修改过的数据,避免的脏读、脏写。
lRR:不会读到别的已经提交事务修改的数据,避免了脏读,脏写,不可重复读。
l串行:让事务都串行执行,可以避免所有问题。
Mysql实现MVCC机制,是基于 undo log 多版本链条+ReadView机制来做的,默认RR隔离级别,就可以避免以上所有问题。
undo log
每次开启事务,增删改操作都会记录一下当前事务的id,修改的值 同时会指向 上个事务的 undo log。
ReadView
m_ids:当前所有未提交的事务id。
min_trx_id:当前未提交的最小的事务id。
max_trx_id:当前未提交的下一次的事务id。
creator_id:当前事务的id。
Mysql 在 RC情况下,避免了脏读,脏写,但是没有避免不可重复读
在一个事务里,每次查询都会重新开启 readView,当readView 有其他事务提交之后。下次再开启 readView,那么未提交的事务 ids 中就没有刚刚提交的事务id。那么顺着 undo log 版本链读取的时候,会读刚刚已经提交的事务。
RR情况,避免了 脏写,脏读,不可重复读,幻读。
在一个事务里,只会开启一个 readView,每次查询都会按照相同的 readView,这样读取 undo log 版本链得到的结果都一样。
避免脏写
通过锁机制,来避免的脏写。
当多个事务同时想对一条数据写的时候,第一个事务会创建一个锁,里面包含着自己的 事务id 和 等待状态 fasle,然后把锁跟这行事务关联在一起。
另一个事务过来想的时候,发现这条记录被加锁,那么他就会排队等待,同时他也生成一个锁,里面 包含自己的 事务id 和 等待状态为 true。
当第一个事务提交了,释放锁,他会唤醒排在他后面的锁,改为fasle。那么后面的事务就获取到锁了。
13、MySQL存储引擎
myisam
不支持事务,不支持外键约束,二级(复制)索引,索引文件和数据文件分开的。适用于那种少量的插入,大量的查询的场景。
innodb
支持事务,走聚簇索引,支持高并发,高可用等成熟的数据库架构。比如分库分表,读写分离,主备架构。
14、聚簇索引和二级索引
l聚簇索引:叶子节点存的是完整的数据。像innodb的主键索用的就是聚簇索引。
l二级索引:叶子节点存的是索引,如果是myisam存储引擎,他最终叶子节点存的还有地址值,他还要回表到一个hash表中找到具体的数据。innodb 他存的是索引数据和主键id,他要回表到主键索引,找到完整的数据。
15、MySQL索引结构
B- 树
l根节点至少包含2个孩子。
l每个节点最多含有m个孩子(m>=2,m 代表几阶,也就是每个节点最多可以存储几个关键字)
l除了根节点和叶节点外,其他节点至少有 ceil(m/2)个孩子。
l所有的叶子结点都在同一层。
l非叶子结点存储数据(关键字)的个数=指向儿子的指针个数-1;
l数据(关键字)集合分布在整棵树中,任何一个数据(关键字)出现且只出现在一个节点中。(数据分散,对磁盘读写更加随机,代价比较高)
l搜索可能在非叶子节点结束。(搜索,不稳定)
B+树
l非叶子结点的子树指针和节点存储的索引个数相同,同时指针P[i]的区间在P[i] 到 P[i+1],前闭后开。(B树是前开,后开。)
l相比B - 树, 所有叶子结点增加一个指针,指向下个一个叶子结点。(这样有利于对数据库的扫描,可以支持范围搜索)
l所有关键字都在叶子结点。(1. 稳定的查找效率,每次都是从根节点找到叶子结点 2. 这样都同一在同一个板块存数据,这样磁盘读写代价更低。)
B+树好处:
l每次从根节点查找,查找效率稳定。
l叶子结点顺序相连,有利于数据库的扫描。
l数据都存储在叶子结点,有利于磁盘的读写。
16、索引优化
排查慢sql
l慢查询的开启并捕获或开启全局日志
lexplain + 慢SQL分析
合理使用索引
l主键自动建立唯一索引
l频繁作为查询条件的字段应该创建索引
l频繁更新的字段不适合创建索引—因为每次更新不单单是更新了记录还会更新索引
l单键/组合索引的选择问题,who (在高并发下倾向创建组合索引)
l组合索引,遵守最左匹配原则
l查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
l利用索引字符串值的前缀(如果是字符串,使用字符串前缀)
l尽量使用覆盖索引进行查询,避免回表带来的性能损耗。
l联合索引,like/范围查/存在函数无效
17、索引优缺点
索引优势
IO成本优势
类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本
CPU消耗低
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
索引缺点
空间上的代价
一个索引都为对应一棵B+树,树中每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,所以一个索引也是会占用磁盘空间的。
时间上的代价
索引是对数据的排序,那么当对表中的数据进行增、删、改操作时,都需要去维护修改内容涉及到的B+树索引。所以在进行增、删、改操作时可能需要额外的时间进行一些记录移动,页面分裂、页面回收等操作来维护好排序。
18、锁机制
读锁与写锁
l读锁:共享锁、Shared Locks、S锁。
l写锁:排他锁、Exclusive Locks、X锁。
读操作
select …lock in share mode; (显示锁)
将查找到的数据加上一个S锁,允许其他事务继续获取这些记录的S锁,不能获取这些记录的X锁(会阻塞)
select … for update; (显示锁)
将查找到的数据加上一个X锁,不允许其他事务获取这些记录的S锁和X锁。
写操作
lDELETE:删除一条数据时,先对记录加X锁,再执行删除操作。
lINSERT:插入一条记录时,会先加隐式锁来保护这条新插入的记录在本事务提交前不被别的事务访问到。
lUPDATE
1.如果被更新的列,修改前后没有导致存储空间变化,那么会先给记录加X锁,再直接对记录进行修改。
2.如果被更新的列,修改前后导致存储空间发生了变化,那么会先给记录加X锁,然后将记录删掉,再Insert一条新记录。
隐式锁:一个事务插入一条记录后,还未提交,这条记录会保存本次事务id,而其他事务如果想来读取这个记录会发现事务id不对应,所以相当于在插入一条记录时,隐式的给这条记录加了一把隐式锁。
19、什么是悲观锁、乐观锁
l悲观锁: 用的就是数据库的行锁,认为数据库会发生并发冲突,直接上来就把数据锁住,其他事务不能修改,直至提交了当前事务。
l乐观锁: 其实是一种思想,认为不会锁定的情况下去更新数据,如果发现不对劲,才不更新(回滚)。在数据库中往往添加一个version字段来实现。
行锁范围分类
lLOCK_REC_NOT_GAP: 单个行记录上的锁。行锁
lLOCK_GAP:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读 ,出现幻读的情况。(间隙锁会锁从你查的id到最近小的id之间会锁住)
lLOCK_ORDINARY:(Next_Key) 锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。
20、如何做到避免死锁
l尽量控制事务大小,减少锁定资源量和时间长度
l合理设计索引,尽量缩小锁的范围
l在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率降
l尽可能低级别事务隔离
性能优化面试合辑 word文档下载地址:链接:https://pan.baidu.com/s/1E8Tl7Hm0-diPQvJchglciw
提取码:1111
爆肝一周,不眠不休!就为 点赞+好评+收藏 三连