4.Spark Streaming学习
复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间。
基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间。
基于实时数据流的数据处理(streaming data processing),通常的时间跨度在数百毫秒到数秒之间。
所以说流式处理是非常重要的,而Spark Streaming正是用于处理数据流的。
1.流式处理框架介绍
Samza
Samza 是一个分布式的流式数据处理框架(streaming processing),Linkedin 开源的产品, 它是基于 Kafka 消息队列来实现类实时的流式数据处理的。Samza 是在消息队列系统上的更高层的抽象,是一种应用流式处理框架在消息队列系统上的一种应用模式的实现。总的来说,Samza 与 Storm 相比,传输上完全基于 Apache Kafka,集群管理基于 Hadoop YARN,。由于受限于 Kafka 和 YARN,所以它的拓扑结构不够灵活。
Storm
Storm 是一个开源的、大数据处理系统,与其他系统不同,它旨在用于分布式实时处理且与语言无关。Storm 框架与其他大数据解决方案的不同之处,在于它的处理方式。Storm 支持创建拓扑结构来转换没有终点的数据流,这些转换从不会自动停止,它们会持续处理到达的数据,即 Storm 的流式实时处理方式。
Spark Streaming
Spark Streaming 类似于 Apache Storm,准确的说,Spark更像是微批处理,strom才是真正的批处理。Spark Streaming 有高吞吐量和容错能力强这两个特点。处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能
2.Storm与Spark Streaming比较
处理模型以及延迟
虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming可以在一个短暂的时间窗口里面处理多条(batches)Event。所以说Storm可以实现亚秒级时延的处理,而Spark Streaming则有一定的时延。容错和数据保证
Spark Streaming的容错为有状态的计算提供了更好的支持。在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保证每条记录最少被处理一次,但是允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。另一方面,Spark Streaming仅仅需要在批处理级别对记录进行追踪,所以他能保证每个批处理记录仅仅被处理一次,即使是node节点挂掉。虽然说Storm的 Trident library可以保证一条记录被处理一次,但是它依赖于事务更新状态,而这个过程是很慢的,并且需要由用户去实现。
实现和编程API
Storm主要是由Clojure语言实现,Spark Streaming是由Scala实现。Storm提供了Java API,同时也支持其他语言的API。 Spark Streaming支持Scala和Java语言(其实也支持Python)。批处理框架集成
Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以想使用其他批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询。这就减少了单独编写流批量处理程序和历史数据处理程序。3.Spark Streaming简介
Spark Streaming处理的数据流图:

Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
比较适用的场景:
- 历史数据和实时数据结合进行分析
- 对实时性要求不是很苛刻的场景
-
- 基础扫盲:
- 离散流(DStream):即我们处理的一个实时数据流,在Spark Streaming中对应于一个DStream 实例。
批数据(batch data):将实时流数据以时间片为单位进行分批,将流处理转化为时间片数据的批处理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流了。
时间片或批处理时间间隔( batch interval):以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个RDD实例。
窗口长度(window length):一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数,
滑动时间间隔:前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数
Input DStream :一个input DStream是一个特殊的DStream,将Spark Streaming连接到一个外部数据源来读取数据。
4、DStream
DStream(Discretized Stream)作为Spark Streaming的基础抽象,它代表持续性的数据流。这些数据流既可以通过外部输入源赖获取,也可以通过现有的Dstream的transformation操作来获得。在内部实现上,DStream由一组时间序列上连续的RDD来表示。每个RDD都包含了自己特定时间间隔内的数据流。DStream中在时间轴下生成离散的RDD序列如下图:

5.Spark Streaming使用步骤
1.构建 Streaming Context 对象:与 Spark 初始需要创建 SparkContext 对象一样,创建 StreamingContext 对象所需的参数,包括指明 master、设定名称等。需要注意的是参数 Second(1),制定处理数据的时间间隔,如 1s,那么 Spark Streaming 会以 1s 为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置,它的生命周期会伴随整个 StreamingContext 的生命周期且无法重新设置。
2.创建 InputDStream指明数据源。例如以套接字连接作为数据源读取数据,或者通过对输入流的转换获得。Spark Streaming 支持多种不同的数据源,包括 kafkaStream、flumeStream、fileStream、networkStream 等。
a.JavaReceiverInputDStream
b.JavaDStream
3.操作 DStream:对于从数据源得到的 DStream,用户可以在其基础上进行各种操作,如 WordCount 的操作单词计数执行流程,即对当前时间窗口内从数据源得到的数据进行分词,然后利用 MapReduce 算法映射和计算,最后使用 print() 输出结果。
4.启动 Spark Streaming,之前的所有步骤只创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计算,当 ssc.start() 启动后,程序才真正进行所有预期的操作。
上面第一步提到了时间窗口,Spark Streaming 有特定的窗口操作,窗口操作涉及两个参数:一个是滑动窗口的宽度(Window Duration);另一个是窗口滑动的频率(Slide Duration),这两个参数必须是 batch size 的倍数。例如以过去 5 秒钟为一个输入窗口,每 1 秒统计一下 WordCount,那么我们会将过去 5 秒钟的每一秒钟的 WordCount 都进行统计,然后进行叠加,得出这个窗口中的单词统计。离散数据流 (DStream) 作为 Spark Streaming 中的一个基本抽象,代表了一个数据流,这个数据流既可以从外部输入源获得,也可以通过对输入流的转换获得。在其内部,DStream 是通过一组时间序列上连续的 RDD 来表示的,每一个 RDD 都包含了特定时间间隔内的数据流。
程序示例:
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination() 注意:
JavaReceiverInputDStream
6.输入源
在Spark Streaming中所有的操作都是基于流的,而输入源是这一系列操作的起点。输入 DStreams 和 DStreams 接收的流都代表输入数据流的来源,在Spark Streaming 提供两种内置数据流来源:基础来源 在 StreamingContext API 中直接可用的来源。例如:文件系统、Socket(套接字)连接和 Akka actors;高级来源 如 Kafka、Flume、Kinesis、Twitter 等,可以通过额外的实用工具类创建。
7.DSTream操作
与RDD类似,DStream也提供了自己的一系列操作方法,这些操作可以分成三类:普通的转换操作、窗口转换操作和输出操作。
a、普通的转换操作
 两个比较特殊的操作
两个比较特殊的操作
transform(func)操作
该transform操作(转换操作)连同其其类似的 transformWith操作允许DStream 上应用任意RDD-to-RDD函数。它可以被应用于未在DStream API 中暴露任何的RDD操作。例如,在每批次的数据流与另一数据集的连接功能不直接暴露在DStream API 中,但可以轻松地使用transform操作来做到这一点,这使得DStream的功能非常强大。例如,你可以通过连接预先计算的垃圾邮件信息的输入数据流,然后基于此做实时数据清理的筛选。也可以在transform方法中使用机器学习和图形计算的算法。
updateStateByKey操作
该操作可以让你保持任意状态,同时不断有新的信息进行更新,可以做累加。要使用此功能,必须进行两个步骤 :
(1) 定义状态 - 状态可以是任意的数据类型。
(2) 定义状态更新函数 - 用一个函数指定如何使用先前的状态和从输入流中获取的新值 更新状态。
假设你要进行文本数据流中单词计数。在这里,正在运行的计数是状态而且它是一个整数。我们定义了更新功能如下:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}val runningCounts = pairs.updateStateByKey[Int](updateFunction _)b、窗口转换操作
Spark Streaming 还提供了窗口的计算,它允许你通过滑动窗口对数据进行转换,窗口转换操作如下:


对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔(window duration)决定,而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。除了窗口的长度,窗口操作还有另一个重要的参数就是滑动间隔(slide duration),它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。在这里必须注意的一点是滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍。
如批处理间隔示意图所示,批处理间隔是1个时间单位,窗口间隔是3个时间单位,滑动间隔是2个时间单位。对于初始的窗口time 1-time 3,只有窗口间隔满足了才触发数据的处理。这里需要注意的一点是,初始的窗口有可能流入的数据没有撑满,但是随着时间的推进,窗口最终会被撑满。当每个2个时间单位,窗口滑动一次后,会有新的数据流入窗口,这时窗口会移去最早的两个时间单位的数据,而与最新的两个时间单位的数据进行汇总形成新的窗口(time3-time5)。
对于窗口操作,批处理间隔、窗口间隔和滑动间隔是非常重要的三个时间概念,是理解窗口操作的关键所在。
c、输出操作
Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。以下表列出了目前主要的输出操作: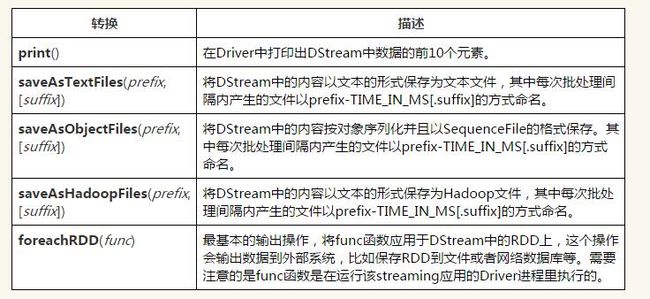
dstream.foreachRDD是一个非常强大的输出操作,它允将许数据输出到外部系统。但是 ,如何正确高效地使用这个操作是很重要的,下面展示了如何去避免一些常见的错误。
通常将数据写入到外部系统需要创建一个连接对象(如 TCP连接到远程服务器),并用它来发送数据到远程系统。出于这个目的,开发者可能在不经意间在Spark driver端创建了连接对象,并尝试使用它保存RDD中的记录到Spark worker上,如下面代码:
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}这是不正确的,这需要连接对象进行序列化并从Driver端发送到Worker上。连接对象很少在不同机器间进行这种操作,此错误可能表现为序列化错误(连接对不可序列化),初始化错误(连接对象在需要在Worker 上进行需要初始化) 等等,正确的解决办法是在 worker上创建的连接对象。
通常情况下,创建一个连接对象有时间和资源开销。因此,创建和销毁的每条记录的连接对象可能招致不必要的资源开销,并显著降低系统整体的吞吐量 。一个更好的解决方案是使用rdd.foreachPartition方法创建一个单独的连接对象,然后使用该连接对象输出的所有RDD分区中的数据到外部系统。
这缓解了创建多条记录连接的开销。最后,还可以进一步通过在多个RDDs/ batches上重用连接对象进行优化。一个保持连接对象的静态池可以重用在多个批处理的RDD上将其输出到外部系统,从而进一步降低了开销。
需要注意的是,在静态池中的连接应该按需延迟创建,这样可以更有效地把数据发送到外部系统。另外需要要注意的是:DStreams延迟执行的,就像RDD的操作是由actions触发一样。默认情况下,输出操作会按照它们在Streaming应用程序中定义的顺序一个个执行
8、一些调优方式:
1. 优化运行时间
增加并行度 确保使用整个集群的资源,而不是把任务集中在几个特定的节点上。对于包含shuffle的操作,增加其并行度以确保更为充分地使用集群资源;
减少数据序列化,反序列化的负担 Spark Streaming默认将接受到的数据序列化后存储,以减少内存的使用。但是序列化和反序列话需要更多的CPU时间,因此更加高效的序列化方式(Kryo)和自定义的系列化接口可以更高效地使用CPU;
合理的batch duration(批处理时间间) 在Spark Streaming中,Job之间有可能存在依赖关系,后面的Job必须确保前面的作业执行结束后才能提交。若前面的Job执行的时间超出了批处理时间间隔,那么后面的Job就无法按时提交,这样就会进一步拖延接下来的Job,造成后续Job的阻塞;
减少因任务提交和分发所带来的负担 通常情况下,Akka框架能够高效地确保任务及时分发,但是当批处理间隔非常小(500ms)时,提交和分发任务的延迟就变得不可接受了。使用Standalone和Coarse-grained Mesos模式通常会比使用Fine-grained Mesos模式有更小的延迟。
2. 优化内存使用
控制batch size(批处理间隔内的数据量) Spark Streaming会把批处理间隔内接收到的所有数据存放在Spark内部的可用内存区域中,因此必须确保当前节点Spark的可用内存中少能容纳这个批处理时间间隔内的所有数据,否则必须增加新的资源以提高集群的处理能力;
及时清理不再使用的数据 因为Spark Streaming会将接受的数据全部存储到内部可用内存区域中。通过设置合理的spark.cleaner.ttl时长来及时清理超时的无用数据,这个参数需要小心设置以免后续操作中所需要的数据被超时错误处理;
观察及适当调整GC策略 GC会影响Job的正常运行,可能延长Job的执行时间,引起一系列不可预料的问题。观察GC的运行情况,采用不同的GC策略以进一步减小内存回收对Job运行的影响。
kafka:http://blog.csdn.net/stark_summer/article/details/44038247
详细示例:http://blog.csdn.net/jianghuxiaojin/article/details/51452593
图:http://www.cnblogs.com/Leo_wl/p/3530464.html